
嵌入式视频处理考虑(二)

引言:
作为消费者,我们对于各种形式的视频系统都已经非常熟悉了。但是从嵌入式开发人员的角度来看,视频就好像是一张纷繁复杂的网络,里面充满了各种不同的分辨率、格式、标准与显示等。
视频算法分类
视频处理算法基本上可以分为两个大类:空域算法和时域算法。要想了解在每种情况下如何有效的处理数据,就必须熟悉各种不同的视频处理方法。许多算法将空域处理技术和时域处理技术结合起来(称为“时空处理”),以实现算法要求的结果。
空域处理可以按像素顺序进行,也可以基于宏块进行。每一个像素的处理都是在空域局部进行的。按照顺序对每一个像素做处理然后产生一个输出,从前一个或下一个像素产生输出不会有结果累计效应。一个按像素顺序处理的例子是从RGB到YCbCr的颜色空间转换。通常,这种类型的计算可以在运行过程中数据到来时执行,而不必将源图像数据存储到外部存储器中。
虽然是在空域局部进行,基于宏块的算法一般需要一组像素数据才能产生结果。一个简单的例子就是计算平均值,也就是说,用某个像素周围相邻的像素计算平均值对该像素进行低通滤波。一个更复杂的例子是,用5*5的二维卷积内核检测图像中的边缘信息,并从周围大量的像素中绘制出相关信息。在这些基于宏块的算法中,需要将源图像爱你个数据存储在存储器中,但是并不需要存储整个视频,因为每次只对几行视频数据进行运算也是可以接受的。如果这样计算的话,用外部的SDRAM存储视频帧数据,和使用片内的更快、更小的一级缓存或者二级缓存作为行缓存相比,两者有比较显著的差异。
到目前为止,我们仅仅考虑了空域局部处理。而另一类算法则涉及空域全局处理。这些方法每次针对整个图像或视频帧进行处理,通常需要在L3帧缓存和L1源图像数据存储器和中间结果之间进行数据传输。空域全局算法的例子包括离散余弦变换DCT、搜索图像内线段的Hough变换,以及直方图均衡化算法(该算法依赖于在根据分析结构修改图像之前对整幅图像的分析)。
时域处理算法则尽量寻找各帧之间特定像素或像素区域中出现变化或者相似的地方。时域处理的一个例子是,通过行加倍或者滤波,将隔行场转换为逐行扫描格式。这里,我们假定两个隔行场在时间上足够相近,这样可以用一个场的内容产生“遗失”的一个场。如果不是这种情况,例如,有一个运动边界或者场景改变,此时视频输出中会出现错误,但是预处理通常会弱化这种问题。
另一个例子也说明了时域处理的重要性,那就是视频监控系统。在这样的系统中,每一帧都要和前一帧进行比较,以确定两者是否有足够的差异达到“警报条件”。换句话说,这是一种算法,用来确定是否有物体在非预期的情况下发生跨越多个帧的移动、消失或者出现。
绝大多数视频压缩算法都将空域处理和时域处理结合起来,形成一个新的类别,称为“时空处理”。在空域中,每个图像帧被分解为若干个宏块,也就是说16*16个像素的一个区域。然后再对这些宏块进行跟踪、逐帧比较,从中提取出运动估计和补偿的近似值。
带宽计算
为了揭示与运动估计需要的吞吐量有关的一些重要概念,让我们花一点时间来粗略计算一下视频的带宽需求。
首先,我们来看逐行扫描VGA(640*480)CMOS传感器,该传感器连接到处理器的视频接口,以每秒30帧的速率发送8比特4:2:2的YCbCr数据。
(640*480像素/帧) (2字节/像素) (30帧/秒)=18.4MB/秒
这就是进入处理器的原始数据的吞吐量。通常。每一行中还会有一些空白数据需要传输,这样算来,实际的像素时钟频率大约为24MHz。通过使用每次输出16比特(亮度和色度数据在同一时钟周期输出)的传感器模式,需要的时钟周期将变为原来的一半,但是总的数据吞吐量保持不变,因为视频接口每个时钟周期传输的数据是原来的两倍。
现在,我们要转向显示这一方面,看一个可以显示“RGB565”图像的VGALCD显示器。也就是说,每一个RGB像素值被封包为两个字节,然后在LCD显示屏上显示出来。这里有一个细微的差别,LCD通常需要一个刷新率,一般在50-80Hz。因此除非我们使用单独的具有片内帧存储器的LCD控制器芯片,否则就需要以这个刷新率不断的刷新显示器,即使传感器的数据变化率仅有30帧/秒。所以有下面的例子:
(640*480像素/帧) (2字节/像素) (75帧/秒)=46.08MB/秒
由于通常在每个时钟周期内传输一个并行的RGB565数据,所以像素时钟大约是25MHz。
视频应用
下图系统所示,在嵌入式视频应用中,某些基本的视频处理步骤是如何以各种组合形式存在的。在图中,一个隔行扫描CMOS传感器通过处理器的视频接口发送一路4:2:2YCbCr格式的视频流,然后经过去隔行处理和扫描速率转换,再传递给某些处理算法,为输出到LCD面板做好准备。这些准备包括色度重采样、伽马校正、颜色转换、缩放、图像混合,然后封包为适当的输出格式以便在LCD面板上显示。需要注意的是,这个系统仅仅是一个例子,在实际的系统中并不是所有的元件都是必需的。另外,图中这些处理步骤也可能以不同的顺序出现。
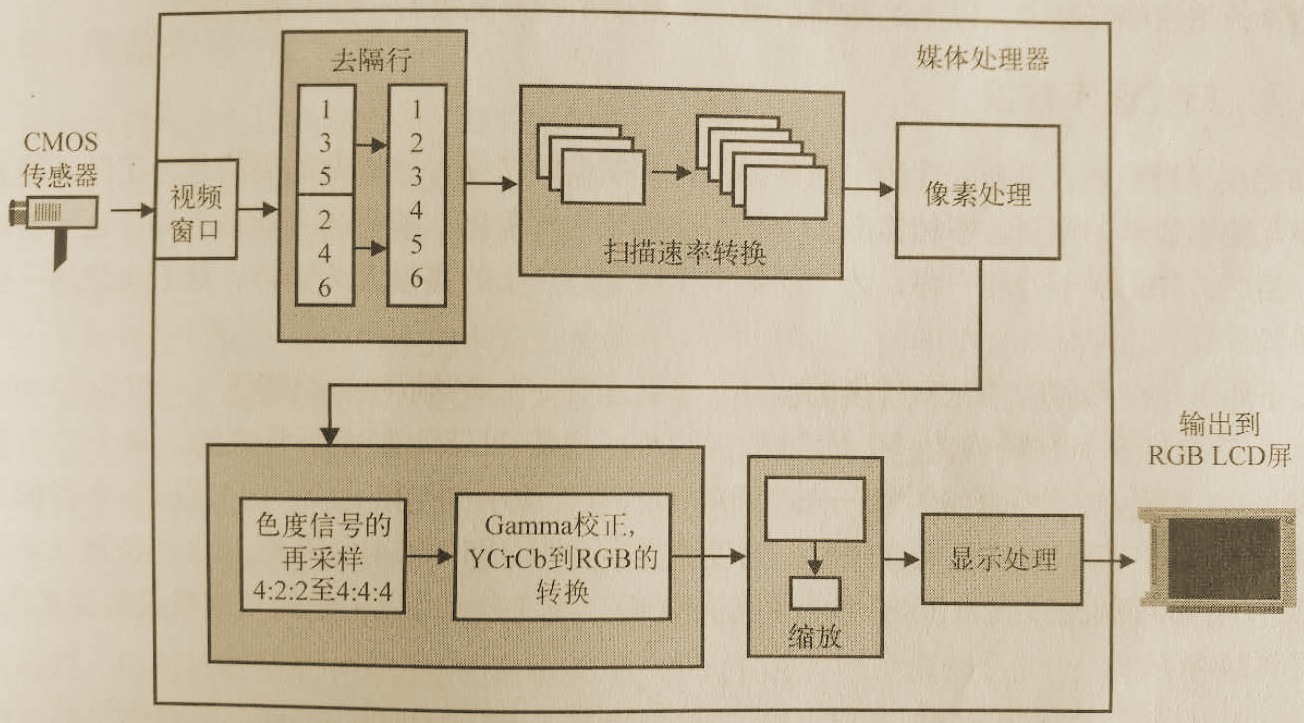
视频流输入到LCD输出的流程实例,包括了各个处理阶段
去隔行处理
当我们从一台输出隔行NTSC数据的相机中得到视频源数据时,通常需要对数据进行去隔行处理。这样,奇数行和偶数行就交织排列在存储器中,而不是分别在两个独立的视频场缓存中。不仅高效的基于宏块的视频处理需要去隔行,而且以逐行扫描格式显示隔行视频时也是需要的。有许多种方法可以完成去隔行处理,每一种都有自身的优缺点。在这里介绍其中的一些方法。
或许最明显的解决方案是源数据的场1(奇数扫描行)和场2(偶数扫描行),然后将两个缓存数据交织在一起产生一个顺序的扫描输出缓存。虽然这种称为编织的技术很常用,但是其缺点明显,因为两个场在时间上相隔大约60Hz,相当于16.7ms。因此这种技术仅仅适合于相对静态的图像帧,在具有高速运动内容的场景中是不合适的。
为了减弱这种人为的瑕疵,并降低系统带宽,有时候只读入场1,然后将其复制到场2所在的位置,并存储到输出缓存中,这往往也是可以接受的。这种“行复制”方法显然降低了图像分辨率,并会引起输出图像出现的放块效应,所以通常会使用一些具有更多处理的方法。这些方法包括线性插值法、中值滤波法以及运动补偿法等。
平均行,也称为bob,就是对邻近的奇数行上相同水平位置的像素取平均值,作为偶数行上对应位置的像素。这种方法还可以推广到线性插值上,也就是对邻近行上的像素取加权平均值(最高的权重分配给最近的像素),从而产生缺失的一行像素。这与垂直方向上的FIR滤波器是相似的。
除了FIR滤波器之外,利用中值滤波器也可以产生更好的去隔行结果。中值滤波是值用周围相邻的像素中处于中间的一个灰度级来代替每一个像素的亮度值,以此来消除图像中的高频噪声。还有一种备选的去隔行方法是运动检测和补偿,利用这种方法可以基于一系列帧中运动的物体来改造去隔行技术。以上这些都是现在通常使用的最高级的一些去隔行技术。
扫描转换速率
完成了视频的去隔行处理后,就需要进行扫描率的转换,这样做的目的是为了保证输入帧速率与输出显示的刷新速率相匹配。为了实现两者的均衡化,某些场可能被丢弃,也可能被复制。当然,和去隔行处理一样,为了消除突发帧传输产生的高频人为噪声,最好使用一些滤波器。
下面是一个具体的帧速率转换的例子,也就是讲一个24帧/秒的视频流转换为30帧/秒的视频流,这是NTSC制式所要求的,属于3:2下拉(pulldown)。例如,如果电影中每一帧在NTSC视频系统中仅使用一次,那么一24帧/秒的速度录制的电影在NTSC视频系统放映时的速度将提高25%(即30/24)。因此,3:2下拉被认为是一个将24帧/秒视频流转换为30帧/秒视频流的过程。实现方式是以一定的周期模式重复某些帧,如下图:
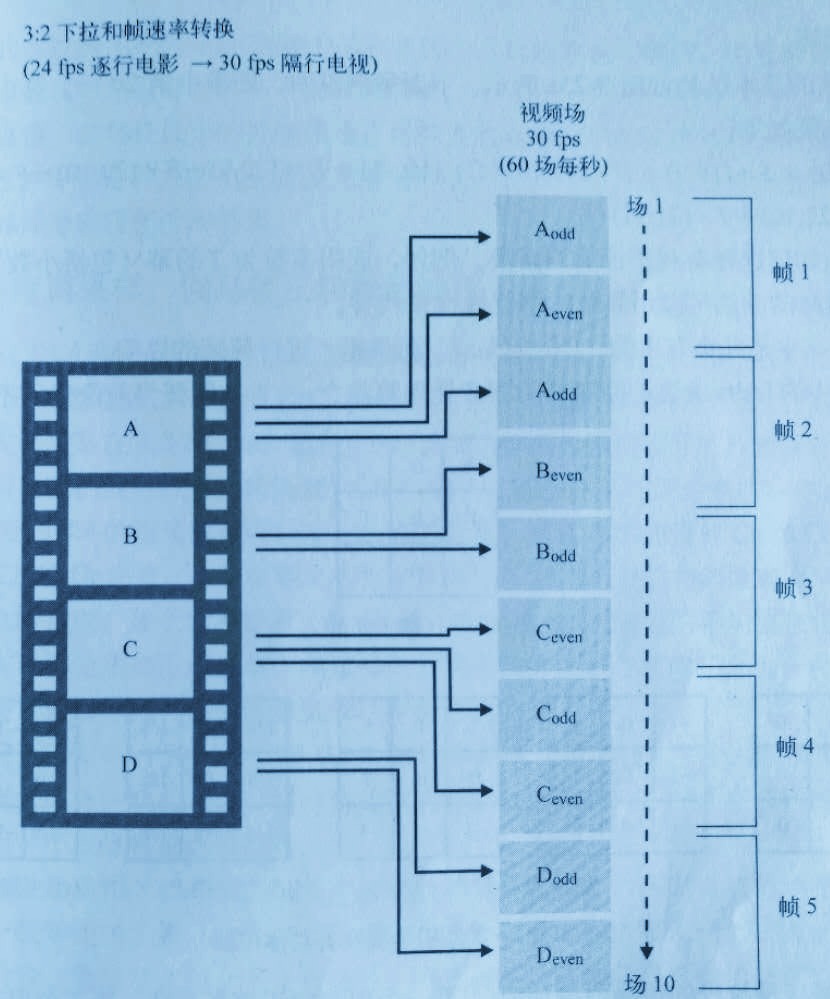
3:2下拉帧重复模式
像素处理
正如上面讨论的那样,通常使用的视频算法有许多种,基本可以分为空域和时域两大类。一种特别常见的视频算子是二维(2D)卷积内核,该算子常被应用于多种不同的图像滤波中。
二维卷积
由于视频流实际上是以特定速率运动的图像序列,因此,图像滤波器必须以足够快的速度运算以便跟上输入图像的速度。这样,就必须对图像滤波器内核进行优化,以使其以最少的处理器周期执行图像滤波。下面用一个基于二维卷积的简单图像滤波器为例进行详细说明。
卷积是图像处理中基本的运算之一。在二维卷积运算中,某个像素值是通过对其周围最接近的像素亮度值加权和得到的。由于模板(mask)的周围都是特定的像素,因此模板一般是奇数维数。模板的大小通常要比图像小很多,常用的是3*3模板,因为该木板的计算量相对比较合理,但对检测图像的边缘也足够大了。不过,也应该注意到,5*5、7*7以及更大的模板也被广泛应用。例如,相机的图像处理中就用了11*11的内核来执行极其复杂的滤波运算。
3*3内核的基本结构如下图a,下面举例说明,图像中第20行,第10列的像素卷积计算输出结果如下:
Out(20,10)=A*(19,9)+B*(19,10)+ C*(19,11)+ D*(20,9)+ E*(20,10)+F*(20,11)+ G*(21,9)+ H*(21,10)+ I*(21,11)
重要的是如何选择有利于计算的系数,例如,选择系数为2的幂(包括小数)时是非常有利的,因为这时的乘法可以用简单的以为操作来代替。
下图b~e中是几个有用的3*3内核。
b中的Delta函数是最简单的图像处理算法之一,直接保留当前像素而不做任何改动。
c是两种流行的边缘检测模板,第一个用来检测垂直边缘,第二个用来检测水平边缘。输出值越大,则代表着图像中边缘的梯度越大。
d中的内核是一个平滑滤波器,对周围8个像素取平均值,然后将平均值放在当前像素位置上。这种操作会产生一种“平滑”的效果,或者说是对图像进行低通滤波。
e中的滤波器被称为“锐化模板”算子,该模板可以产生一种边缘增强的图像,主要方法是用当前像素减去该像素的平滑版本(通过计算周围8个像素的平均值得到)。
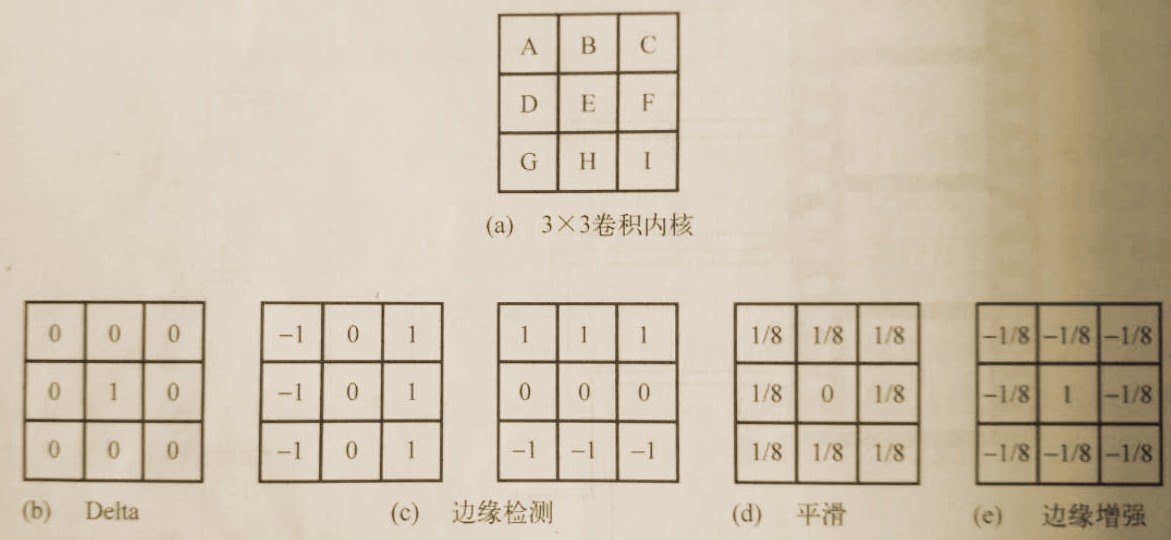
3*3卷积模板及其具体方法
处理图像边界
当类似于二维卷积运算的处理发生在图像边界区域时,会出现什么情况?为了正确的进行像素的滤波,就需要一些处于边界之外的像素信息。对于这种情况,有一些校正的措施,最简单的就是忽略这些边缘区域。也就是说,一个5*5卷积内核需要当前像素上下左右各2行(或列)像素才能正确的计算。因此,为什么不忽略每个方向的两行图像数据,以保证内核总是对真是的数据执行运算呢?当然这也不总是理想的方法,因为它忽略了一些真是的图像数据。另外,当几种滤波器串联在一起使用以产生更复杂的像素处理算法时,这种策略就会不断的缩窄输入到下一级滤波器的输入图像。
处理图像边界的其他一些较为流行的方法是复制几行或几列像素,或者从左边界(上边界)绕回到前面的右边界(下边界)。这些方法在实践中是比较容易实现的,但他们会产生原来不存在的数据,因而在一定程度上破坏了滤波的结果。
或许最直接、破坏性最小的处理图像边界的方法是将位于实际图像外部的所有像素看作全0值,即黑色。尽管这种方法也会使滤波结果产生一定的失真,但是却不会像产生一些随机的非零值像素那样带来侵害性的结果。
色度重采样、伽马校正和颜色转换
前面已经讨论过如何在4:4:4 YCbCr和RGB颜色空间之间进行转换,转换方式是3*3的矩阵乘法。但是,到目前为止,像素的格式仍然是在4:2:2YCbCr颜色空间。因此需要对色度信号进行重采样,以得到4:4:4格式。然后就可以直接转换到RGB空间了,就和前面已经看到的一样。
从4:2:2到4:4:4的重采样过程涉及一些插值运算,就是在那些没有Cb和Cr色度分量的Y样本处插入Cr和Cb分量。一种很明显的重采样方法是根据最近的相邻像素取平均值作为遗失的色度值。也就是说,某个像素处遗失的Cb值用最近的两的Cb的平均值来代替。在这些应用中,可能有必要使用高阶滤波器,但通常这种简化的方法已经足够了。另一种方法是复制邻近像素的相关色度值作为当前像素遗失的对应色度值。
一般情况下,从4:1:1空间转换到4:2:2或4:4:4格式只需要使用一个一维滤波器。而从4:2:0格式重采样转换到4:2:2或4:4:4格式则涉及垂直采样,因此必须使用一个二维卷积滤波内核。
由于色度重采样和YCbCr到RGB空间转换都是线性操作,所以有可能将多个步骤组合在一起构成一个数学处理步骤,这样就可以更加有效的完成4:2:2YCbCr到RGB的转换。
在这个阶段,伽马校正通常也是必须的。因为伽马校正的非线性特性,所以最有效的实现方法是利用查找表,在颜色空间转换之前进行伽马校正。随后,转换过程的结果就会产生伽马校正过的RGB分量,这是适合于输出显示的格式。
缩放与剪切
所谓缩放,就是输出视频流的分辨率与输入视频流不一致。在理想情况下,为了避免输入视频流和输出视频流之间任意的缩放操作,固定的缩放比例(输入视频分辨率和输出面板分辨率)是事先定好的。
根据应用的不同,缩放可以是缩小,也可以是放大。很重要的一点是要理解要缩放的图像的内容(例如,是否存在文本和细线)。不适合的缩放可能会导致文本无法识别,或者引起缩放后的图像中原来的水平线消失了。
将输入帧大小调整为更小的输出帧,最容易的方法是剪切图像。例如,如果输入帧的大小是720*480像素,而输出是VGA帧(640*480像素),你就可以剪切掉每一行中的前40个像素和后40个像素。这样做的好处是,不管剪切还是复制图像,都不会引入人为的干扰。当然,这样也有缺点,就是每帧的内容会丢失80个像素(约11%)。有时候,这也不是什么严重的问题,因为屏幕的最左边和最右边包括最上边和最下边通常受显示器边框的影响而显得很模糊。
如果不做剪切,还有其他几种方法可以下采样(减少像素或者行数)或者上采样(增加像素或者行数)一副图像,这样允许在处理的复杂度和最终图像质量之间进行权衡。
增加或减少每行的像素
一种直接的缩放方法是剪切像素(下采样)或者复制现有像素(上采样)。也就是说,当向下缩小到一个更低的分辨率时,每一行中有些像素(或某一帧中某些行)就被抛弃掉了。这确实降低了处理的负荷,但结果也会有一定的损失。
再复杂一点,使用线性插值可以改善图像的质量。例如,缩小图像时,对水平方向或者垂直方向进行滤波将得到一个新的输出像素,然后用这个像素代替插值处理时用到的那些像素。与前面提到的技术一样,这种方法也会损失一定的信息,并且图像失真也是存在的。
如果图像质量是最关键的因素,那么也有些其他的方法可以完成缩放,而不会降低图像质量。这些方法将会根据水平和垂直缩放比例相应的保留图像中的高频成分,同时减弱了锯齿效应。例如,假定一副图像的缩放因子是Y:X,为了完成这个缩放,图像将被上采样(插值)Y倍,并过滤以便消除锯齿,然后再下采样(抽取)X倍,在实际应用中,这两个采样过程可以合并为一个多速率滤波器。
增加或减少每帧中的行数
增加或减少每行中的像素数量用到的方法一般也可以扩展到修改图像中每帧的行数上。例如,丢弃相隔的行(或者说丢弃一个隔行扫描场)就是一种快速的降低垂直分辨率的方法。但是,正如在上面提到的,不管是移除还是复制行,可能需要某些形式的垂直滤波操作,因为这些处理过程在图像中引入了人为的干扰。这里需要用到同样的滤波器策略:简单的垂直平均滤波、高阶FIR滤波,或者用于垂直缩放到一个精确比例的多速率滤波器。
显示处理
阿尔法混合
在显示之前,常常需要将两幅图像或者两个视频缓存叠加在一起。这种情况的一个实际的例子是图标的叠加,例如移动电话中显示的信号强度、电池电量指示等。另外,还有一个涉及两个视频流的例子就是画中画功能。
当叠加两个视频流的时候,需要知道哪个流的内容要在上面显示。这就是阿尔法混合的用武之地。阿尔法混合定义可一个alpha,用来表示叠加流和背景流之间的“透明度因子”,公式如下:
输出值=alpha*(前景像素值) + (1-alpha)*(背景像素值)
从上面的公式中可以看出,alpha为0表示完全透明的叠加,alpha为1表示完全部透明的叠加,即忽略背景图像。
有时候,alpha以单独的通道随着亮度和色度信息按像素顺序一起发送。这就产生了一个新的表示法“4:2:2:4”,其中最后一个数字表示伴随每一个4:2:2像素整体的alpha值。Alpha的编码方式和亮度分量完全相同,但是对于绝大多数应用来说,一般只需要少量的离散透明度等级。有时候,视频叠加缓存会预先与alpha相乘,或者通过查找表预先映射好,这种情况下,该视频缓存称为“成型”(shaded)视频缓存。
混合
混合操作是将叠加缓存放置在更大的图像缓存中。常见的例子是视频显示中的“画中画”模式,以及背景图或者背景视频中的图标。一般来讲,在输出图像完成之前,混合功能可以执行多次循环。换句话说,可能有许多“层”图像和视频结合在一起产生了一个混合的图像。
二维DMA的传输能力对于混合操作而言是非常有用的,因为二维DMA可以将任意大小的矩形区域缓存放置到一个更大的缓存中。需要牢记的一点是,任何图像剪切应该在混合操作之后进行,因为叠加的位置可能违反了新的剪切边界。当然,一种替换方案是保证叠加一开始就不违反边界,但是有时候这很难做到。
色度键控
术语“色度键控”(chroma keying)是这样的一个过程,当两幅图像混合在一起的时候,叠加图像中的内容代替了背景图像中特定的颜色(通常为蓝色或绿色)。这就提供了一种便利的方法,可以有目的地用第二幅图像中适当的部分代替第一幅图像中特定的部分。色度键控可以用媒体处理器中的软件或硬件实现。作为一个相关的概念,当没有独立的alpha通道可用时,在叠加图像中也可以用“透明色”(transparent color)来产生一个alpha=0的条件。
旋转
许多情况下,在显示之前还需要将输出缓存中的内容进行旋转。最常见的情况是,旋转90度的整数倍。这是体现二维DMA非常有用的另外一个例子。
输出格式
针对消费类应用的大多数彩色LCD显示屏(TFT-LCD)具有数字RGB接口。显示中的每一个像素实际上有3个子像素——红绿蓝,但人眼看到的是单个的彩色像素。例如,一个320*240像素的显示屏实际具有960*240个像素分量,分别是R、G、和B子像素。每个子像素的位宽为8比特,这样就构成了常用的24比特彩色LCD显示屏的基础。
3种最常用的配置分别是:每通道8比特的RGB888格式,每通道6比特的RGB666格式,R和B通道5比特、G通道6比特的RGB565格式。
RGB888在这3种格式中具有最高的色彩表现力。由于总共24比特的分辨率,这种格式可以提供1600万种速度。在高性能的应用中,例如LCD电视,这种格式提供了高分辨率和精度。
RGB666格式在便携式电子设备中应用比较普遍。这种格式可以提供262000种色度,总共有18比特分辨率。但是,由于18个引脚(6+6+6)的数据线不符合16比特处理器的数据路径,因此,一种流行的行业折中方案是分别使用5比特表示R和B分量,而用6比特表示G(5+6+5=16比特数据总线),然后连接到RGB666显示面板上。这种方式工作的很好,因为绿色是3种颜色中对视觉影响最重要的一种颜色。显示面板中红色和蓝色的最低有效位连接到了各自的最高有效位。这就保证了每一个颜色通道都具有完全的动态范围(从全亮到全黑)。
版权所有权归卿萃科技,转载请注明出处
作者:卿萃科技ALIFPGA
原文地址:卿萃科技FPGA极客空间 微信公众号

扫描二维码关注卿萃科技FPGA极客空间

 浙公网安备 33010602011771号
浙公网安备 33010602011771号