
Sqoop 数据迁移
目录
Sqoop 基本概念
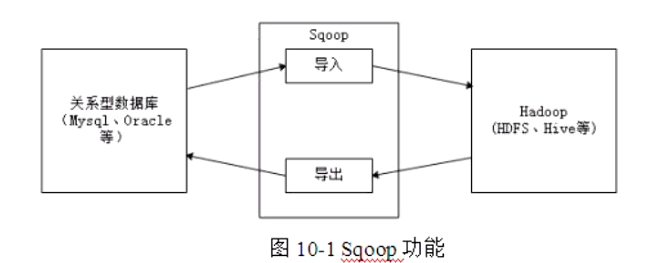
Apache Sqoop是一个性能高、易用、灵活的数据导入导出工具,在关系型数据库与Hadoop之间搭建了一个桥梁。
# 应用场景
需要将HDFS或Hive上的数据导出到传统关系型数据库中(如MySQL、Oracle等),或者将传统关系型数据库中的数据导入到HDFS或Hive上,如果通过人工手动进行数据迁移的话,就会显得非常麻烦。为此,可使用Apache提供的Sqoop工具进行数据迁移。
- 数据迁移
企业大数据平台关系型数据仓库中的数据以分析为主,综合考虑扩展性、容错性和成本开销等方面。若将数据迁移到Hadoop大数据平台上,可以方便地使用Hadoop提供的如Hive、SparkSQL分布式系统等工具进行数据分析。为了一次性将数据导入Hadoop存储系统,可使用Sqoop。
- 可视化分析结果
Hadoop处理的输入数据规模可能是非常庞大的,比如PB级别,但最终产生的分析结果可能不会太大,比如报表数据等,而这类结果通常需要进行可视化,以便更直观地展示分析结果。目前绝大部分可视化工具与关系型数据库对接得比较好,因此,比较主流的做法是,将Hadoop产生的结果导入关系型数据库进行可视化展示。
- 数据增量导入
考虑到Hadoop对事务的支持比较差,因此,凡是涉及事务的应用,比如支付平台等,后端的存储均会选择关系数据库,而事务相关的分析数据,比如用户支付行为等,可能在Hadoop分析过程中用到(比如广告系统,推荐系统等)。为了减少Hadoop分析过程中影响这类系统的性能,我们通常不会直接让Hadoop访问这些关系型数据库,而是单独导入一份到Hadoop存储系统中。
工作流程
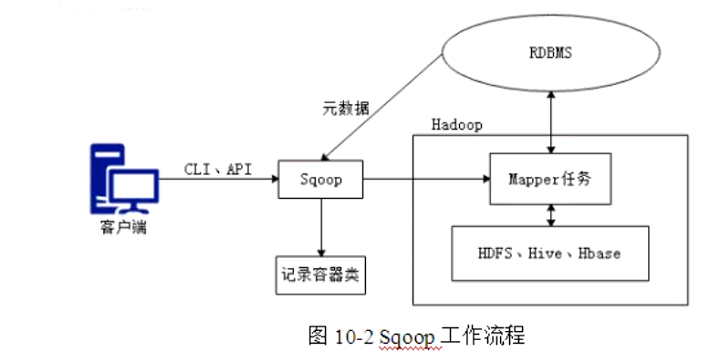
从图可以看出,通过客户端CLI(命令行界面)方式或JavaAPI方式调用Sqoop工具,Sqoop可以将指令转换为对应的MapReduce作业(通常只涉及到Map任务,每个Map任务从数据库中读取一片数据,这样多个Map任务实现并发的拷贝,可以快速的将整个数据拷贝到HDFS上),然后将关系型数据库和Hadoop中的数据进行相互转换,从而完成数据的迁移。
导入原理(HADOOP--->关系型数据库)
在导入数据之前,Sqoop 使用 JDBC 检查导入的数据表,检索出表中的所有列以及列的SQL数据类型,并将这些SQL类型映射为Java数据类型.
在转换后的 MapReduce 应用中使用这些对应的Java类型来保存字段的值,Sqoop的代码生成器使用这些信息来创建对应表的类,用于保存从表中抽取的记录。
导出原理
在导出数据之前, Sqoop 会根据数据库连接字符串来选择一个导出方法,对于大部分系统来说,Sqoop会选择JDBC。
Sqoop会根据目标表的定义生成一个Java类,这个生成的类能够从文本中解析出记录数据,并能够向表中插入类型合适的值.
然后启动一个 MapReduce 作业,从HDFS中读取源数据文件,使用生成的类解析出记录,并且执行选定的导出方法。
掌握Sqoop的安装配置和导入导出操作
SQOOP 安装配置
- 下载
sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz - 上传
cd /export/softwares - 解压至 /export/servers
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C ../servers/ - 重命名为 sqoop-1.4.6
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha sqoop-1.4.6 - 配置Sqoop
# 赋值模板文件
cp sqoop-env-template.sh sqoop-env.sh
# 参数设置
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/export/servers/hadoop-2.7.5
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/export/servers/hadoop-2.7.5
#set the path to where bin/hbase is available
#export HBASE_HOME=
#Set the path to where bin/hive is available
export HIVE_HOME=/export/servers/apache-hive-2.1.1-bin
#Set the path for where zookeper config dir is
export ZOOCFGDIR=/export/servers/zookeeper-3.4.9
# 系统环境变量配置
vim /etc/profile
export SQOOP_HOME=/export/servers/sqoop-1.4.6
export PATH=:$SQOOP_HOME/bin:$PATH
source /etc/profile
# 上传mysql驱动包至 sqoop的lib目录下
cd /export/servers/sqoop-1.4.6/lib
Sqoop测试及常用指令
连接测试
[root@node03 sqoop-1.4.6]# bin/sqoop help

- 连接mysql
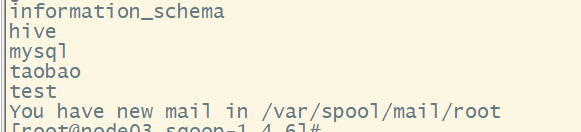
- 列出数据库
sqoop list-databases --username root --password 123456 --connect jdbc:mysql://node03:3306/
![]()
- 列出表格
sqoop list-tables --username root --password 123456 --connect jdbc:mysql://node03:3306/taobao
常用指令

# 查看导出到关系型数据库操作的参数
sqoop help export
sqoop 数据导入导出案例
数据
是将关系型数据库中的单个表数据导入到HDFS,HIVE等具有HADOOP分布式存储结构的文件系统中
# 创建userdb数据库,里面添加三张表 emp, emp_add和emp_contact
# emp
create table emp(
id int,
name varchar(20),
deg varchar(20),
salary int,
dept varchar(20)
);
# 插入数据
insert into emp values(1201,'gopal','manager',50000,'TP');
insert into emp values(1202,' manisha ',' Proof reader',50000,'TP');
insert into emp values(1203,' khalil','php dev',30000,'AC');
insert into emp values(1204,' prasanth',' php dev',30000,'AC');
insert into emp values(1205,' kranthi',' admin',20000,'TP');
# emp_add
create table emp_add(
id int,
hno varchar(20),
street varchar(20),
city varchar(20)
);
# 插入数据
insert into emp_add values(1201,'288A','vgiri','jublee');
insert into emp_add values(1202,'1801','aoc','sec-bad');
insert into emp_add values(1203,'144Z','pguttai','hyd');
insert into emp_add values(1204,'78B','old city','sec-bad');
insert into emp_add values(1205,'720X','hitec','sec-bad');
# emp_conn
create table emp_conn(
id int,
phno int,
email varchar(20)
);
# 插入数据
insert into emp_conn values(1201,'2356742','gopal@tp.com');
insert into emp_conn values(1202,'1661663','manisha@tp.com');
insert into emp_conn values(1203,'8887776','khalil@ac.com');
insert into emp_conn values(1204,'9988774','prasanth@ac.com');
insert into emp_conn values(1205,'1231231','kranthi@tp.com');
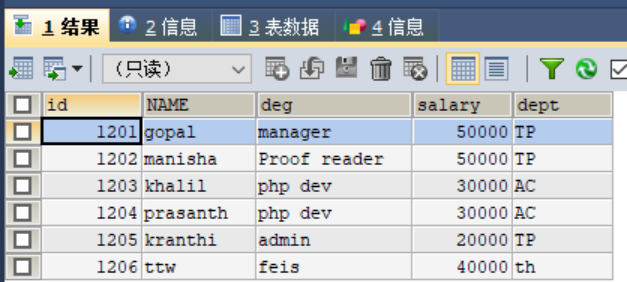
从MySQL数据库服务器中的emp表导入HDFS
# 启动 hadoop 集群
# 执行
sqoop import --connect jdbc:mysql://node03:3306/userdb --username root --password 123456 --table emp --m 1
- --m 1表示设置一个mapper任务
# 执行成功,数据在 http://node01:50070/explorer.html#/user/root/emp 打开
# 也可以设置输出路径 --target-dir /sqoopresult
sqoop import --connect jdbc:mysql://node03:3306/userdb --username root --password 123456 --target-dir /sqoopresult --table emp --num-mappers 1
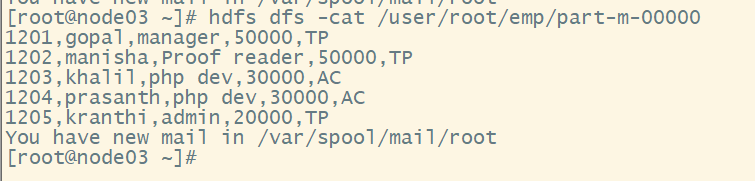
# 查看方式 2
hdfs dfs -cat /user/root/emp/part-m-00000
增量导入
当MySQL表中的数据发生了新增或修改变化,需要更新HDFS上对应的数据时,就可以使用Sqoop的增量导入功能。
Sqoop目前支持两种增量导入模式:append模式和lastmodified模式。
- append模式主要针对INSERT新增数据的增量导入;
- lastmodified模式主要针对UPDATE修改数据的增量导入。
- 在进行增量导入操作时,首先必须指定“-check-column”参数,用来检查数据表列字段,从而确定哪些数据需要执行增量导入。
- 例如,在执行append模式增量导入时,通常会将“check-column”参数指定为具有连续自增功能的列(如主键id);
- 执行lastmodified模式增量导入时,通常会将“--check-column”参数必须指定为日期时间类型的列(如date 或timestamp类型的列)。
# 在mysql中插入数据
INSERT INTO emp VALUES(1206,'ttw','feis',40000,'th');
# 执行增量导入
sqoop import --connect jdbc:mysql://node03:3306/userdb --username root --password 123456 --table emp --incremental append --check-column id --last-value 1205 --num-mappers 1
# 查看
hdfs dfs -cat /user/root/emp/part-m-00001
mysql表数据导入HIVE
# 打开hive
cd /export/servers/apache-hive-2.1.1-bin/
bin/hive
show databases;
- 包含test数据库,下面将emp_add 上传至 HIVE上的目标地址为 test 数据仓库的 emp_add_sp表中、
sqoop import --connect jdbc:mysql://node03:3306/userdb --u root --p 123456 --table emp_add --hive-table mytest.emp_add_sp --create-hive-table --hive-import --m 1
# 查看
- 在 hive 中进入数据库-表,select *
- 在 hdfs中打开: /user/hive/warehouse/mytest.db/emp_add_sp/part-m-00000
hdfs dfs -cat /user/hive/warehouse/mytest.db/emp_add_sp/part-m-00000
MySQL 表数据的子集导入
实际业务中,开发人员可能需要只针对部分数据进行导入操作
-使用sqoop提供的 where 和 query 参数,先进行数据过滤,例如,将表emp_add中 city=sec-bad 的数据导入HDFS 中
# where 进行数据过滤
sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root --password '123456' \
--where "city ='sec-bad'" \
--target-dir /wherequery \
--table emp_add --m 1
# query 进行数据过滤
sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root --password '123456' \
--target-dir /wherequery \
--query 'select id,name,deg FROM emp WHERE id>1203 AND $CONDITIONS' \
--m 1
上述代码示例中,使用了Sqoop的“-query”参数进行数据过滤,它的主要作用就是先通过该参数指定的查询语句查询出子集数据,然后再将子集数据进行导入。上述示例中,$CONDITIONS相当于一个动态占位符,动态的接收传过滤后的子集数据,然后让每个Map任务执行查询的结果并进行数据导入。
(1)如果没有指定“-num-mappers 1”(或-m 1,即map任务个数为1),那么在指令中必须还要添加“-split-by”参数。“-split-by”参数的作用就是针对多副本map任务并行执行查询结果并进行数据导入,该参数的值要指定为表中唯一的字段(例如主键id);
(2)“-query”参数后的查询语句中(例如示例中单引号中的SELECT语句),如果已经使用了WHERE关键字,那么在连接SCONDITIONS占位符前必须使用AND关键字;否则,就必须使用WHERE关键字连接;
(3)“-query”参数后的查询语句中的$CONDITIONS占位符不可省略,并且如果查询语句使用双引号(")进行包装,那么就必须使用\$CONDITIONS,这样可以避免Shell将其视为Shell变量。
sqoop数据导出
# 数据库中新建一张表 emp_export
DROP TABLE IF EXISTS emp_export;
CREATE TABLE emp_export(
id INT,
NAME VARCHAR(20),
deg VARCHAR(20),
salary INT,
dept VARCHAR(20),
PRIMARY KEY (id)
);
# 数据导出(将HDFS上的文件导入到mysql中)
sqoop export \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table emp_export \
--export-dir /user/root/emp
# 导出结果
谋定而后动,知止而有得

 浙公网安备 33010602011771号
浙公网安备 33010602011771号