
项目落实方案选择思考(KUDU)
目录
Kudu 的应用场景是什么?
设计一个项目,分析其特点,设计方案,选取最佳处理方案
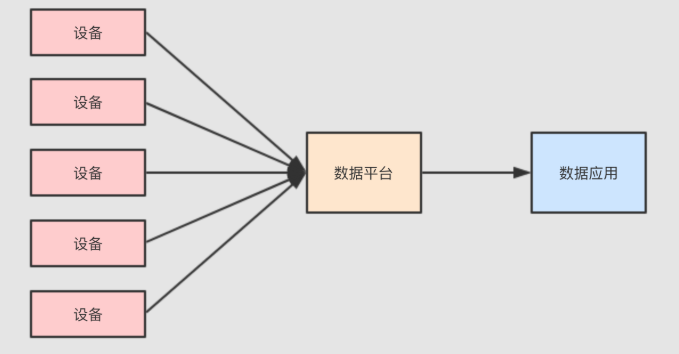
需求:做一个类似物联网的项目, 可能是对某个工厂的生产数据进行分析
项目特点
1. 数据量大
- 有一个非常重大的挑战, 就是这些设备可能很多, 其所产生的事件记录可能也很大, 所以需要对设备进行数据收集和分析的话, 需要使用一些大数据的组件和功能
2. 流式处理
- 因为数据是事件, 事件是一个一个来的, 并且如果快速查看结果的话, 必须使用流计算来处理这些数据
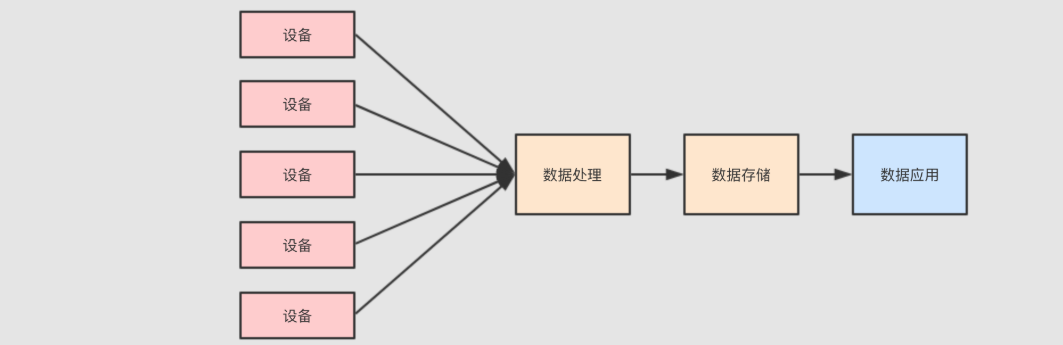
3. 数据需要存储
- 最终需要对数据进行统计和分析, 所以数据要先有一个地方存, 后再通过可视化平台去分析和处理
- 对存储层的要求
这样的一个流计算系统, 需要对数据进行什么样的处理呢?
1.要能够及时的看到最近的数据, 判断系统是否有异常
2.要能够扫描历史数据, 从而改进设备和流程
所以对数据存储层就有可能进行如下的操作
1.逐行插入, 因为数据是一行一行来的, 要想及时看到, 就需要来一行插入一行 -->随机插入,OLTP较擅长
2.低延迟随机读取, 如果想分析某台设备的信息, 就需要在数据集中随机读取某一个设备的事件记录 -->OLTP
3.快速分析和扫描, 数据分析师需要快速的得到结论, 执行一行 SQL 等上十天是不行的 -->批量读取和分析,dfs
方案一:使用 Spark Streaming 配合 HDFS 存储
总结一下需求实时处理
- Spark Streaming
- 大数据存储, HDFS
- 使用 Kafka 过渡数据(可以过渡实时流数据)

Q. 但是这样的方案有一个非常重大的问题, 就是速度机器之慢, 因为 HDFS 不擅长存储小文件, 而通过流处理直接写入 HDFS 的话, 会产生非常大量的小文件, 扫描性能十分的差
方案二:HDFS+compaction
# 上面方案的问题是大量小文件的查询是非常低效的,所以可以将这些小文件压缩合并起来
# 方案问题:
- 一个文件只有不再活跃时才能合并(外部正在使用)
- 不能将覆盖的结果放回原来的位置(外部需要使用原来的文件)
# 所以一般在流式系统中进行小文件合并的话, 需要将数据放在一个新的目录中, 让 Hive/Impala 指向新的位置, 再清理老的位置
方案三: HBase+HDFS
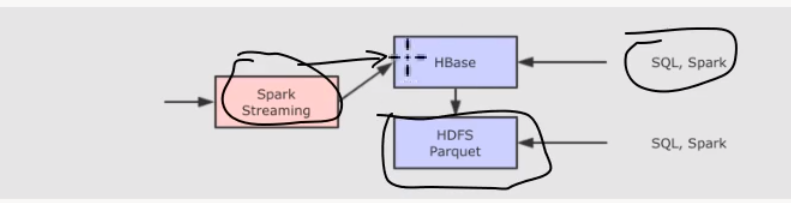
# Parquet文件格式存放 离线大规模数据分析的吞吐量最高
# 因为 HBase(随机读写插入性能好) 不擅长离线大批量数据分析, 所以在一定的条件触发下, 需要将 HBase 中的数据写入 HDFS 中的 Parquet 文件中, 以便支持离线数据分析, 但是这种方案又会产生新的问题
维护特别复杂, 因为需要在不同的存储间复制数据
难以进行统一的查询, 因为实时数据和离线数据不在同一个地方
# 这种方案, 也称之为 Lambda, 分为实时层和批处理层, 通过这些这么复杂的方案, 其实想做的就是一件事, 流式数据的存储和快速查询
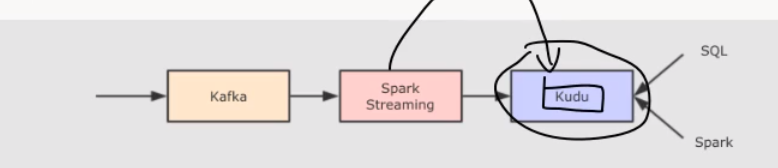
方案四:Kudu
Kudu 声称在扫描性能上, 媲美 HDFS 上的 Parquet. 在随机读写性能上, 媲美 HBase. 所以将存储层替换为 Kudu, 理论上就能解决我们的问题了。
- 项目难点总结
- 对于实时流式数据处理, Spark, Flink, Storm 等工具提供了计算上的支持, 但是它们都需要依赖外部的存储系统, 对存储系统的要求会比较高一些, 要满足如下的特点
- 支持逐行插入(机器生产的数据是逐条的)
- 支持更新(数据库不断更新)
- 低延迟随机读取(数据要能很快的读取)
- 快速分析和扫描(离线大批量数据的扫描和分析)
KUDU 和其他存储工具对比
理解 OLTP 和 OLAP
- OLTP (On-Line Transaction Processing 联机事务处理过程)
# 先举个栗子, 在电商网站中, 经常见到一个功能 - "我的订单", 这个功能再查询数据的时候, 是查询的某一个用户的数据, 并不是批量的数据
# OLTP 是传统关系型数据库的主要应用
用来执行一些基本的、日常的事务处理,比如数据库记录的增、删、改、查等等
# OLTP 需要做的事情是
快速插入和更新
精确查询
# 所以 OLTP 并不需要对数据进行大规模的扫描和分析, 所以它的扫描性能并不好, 它主要是用于对响应速度和数据完整性很高的在线服务应用中
- OLAP (On-Line Analytical Processing 联机分析处理)
#OLAP 则是分布式数据库的主要应用
它对实时性要求不高,但处理的数据量大,通常应用于复杂的动态报表系统上
OLAP 和 OLTP 的场景不同, OLAP 主要服务于分析型应用, 其一般是批量加载数据, 如果出错了, 重新查询即可
# 总结
OLTP 随机访问能力比较强, 批量扫描比较差
OLAP 擅长大规模批量数据加载, 对于随机访问的能力则比较差
大数据系统中, 往往从 OLTP 数据库中 ETL 放入 OLAP 数据库中, 然后做分析和处理
列式存储和行式存储
# 行式一般用做于 OLTP, 例如我的订单, 那不仅要看到订单, 还要看到收货地址, 付款信息, 派送信息等, 所以 OLTP 一般是倾向于获取整行所有列的信息
# 而分析平台就不太一样, 例如分析销售额, 那可能只对销售额这一列感兴趣, 所以按照列存储, 只获取需要的列, 这样能减少数据的读取量
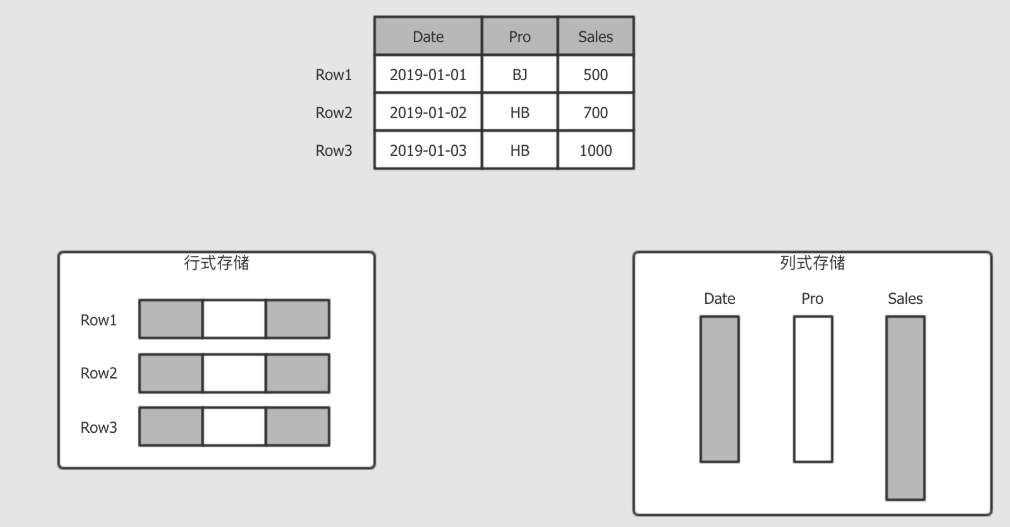
- 行式存储
传统的关系型数据库,如 Oracle、DB2、MySQL、SQL SERVER 等采用行式存储法(Row-based),在基于行式存储的数据库中,
数据是按照行数据为基础逻辑存储单元进行存储的, 一行中的数据在存储介质中以连续存储形式存在。
- 列式存储
列式存储(Column-based)是相对于行式存储来说的,新兴的 Hbase、HP Vertica、EMC Greenplum 等分布式数据库均采用列式存储。
在基于列式存储的数据库中, 数据是按照列为基础逻辑存储单元进行存储的,一列中的数据在存储介质中以连续存储形式存在。
存储模型
- 结构
Kudu 的存储模型是有结构的表
OLTP 中代表性的 MySQL, Oracle 模型是有结构的表
HBase 是看起来像是表一样的 Key-Value 型数据, Key 是 RowKey 和列簇的组合, Value 是具体的值
- 主键
Kudu 采用了 Raft 协议, 所以 Kudu 的表中有唯一主键
关系型数据库也有唯一主键
HBase 的 RowKey 并不是唯一主键
- 事务支持
Kudu 缺少跨行的 ACID 事务
关系型数据库大多在单机上是可以支持 ACID 事务的
- 性能
Kudu 的随机读写速度目标是和 HBase 相似, 但是这个目标建立在使用 SSD 基础之上
Kudu 的批量查询性能目标是比 HDFS 上的 Parquet 慢两倍以内
- 硬件需求
Hadoop 的设计理念是尽可能的减少硬件依赖, 使用更廉价的机器, 配置机械硬盘
Kudu 的时代 SSD 已经比较常见了, 能够做更多的磁盘操作和内存操作
Hadoop 不太能发挥比较好的硬件的能力, 而 Kudu 为了大内存和 SSD 而设计, 所以 Kudu 对硬件的需求会更大一些
[参考文档] (file:///E:/Big_Data_Files/DMP_Systems/Day01/Kudu.html)
谋定而后动,知止而有得

 浙公网安备 33010602011771号
浙公网安备 33010602011771号