Lucene 正排索引、倒排索引、数据库 B+树索引、Lucene原理图
正排索引、倒排索引
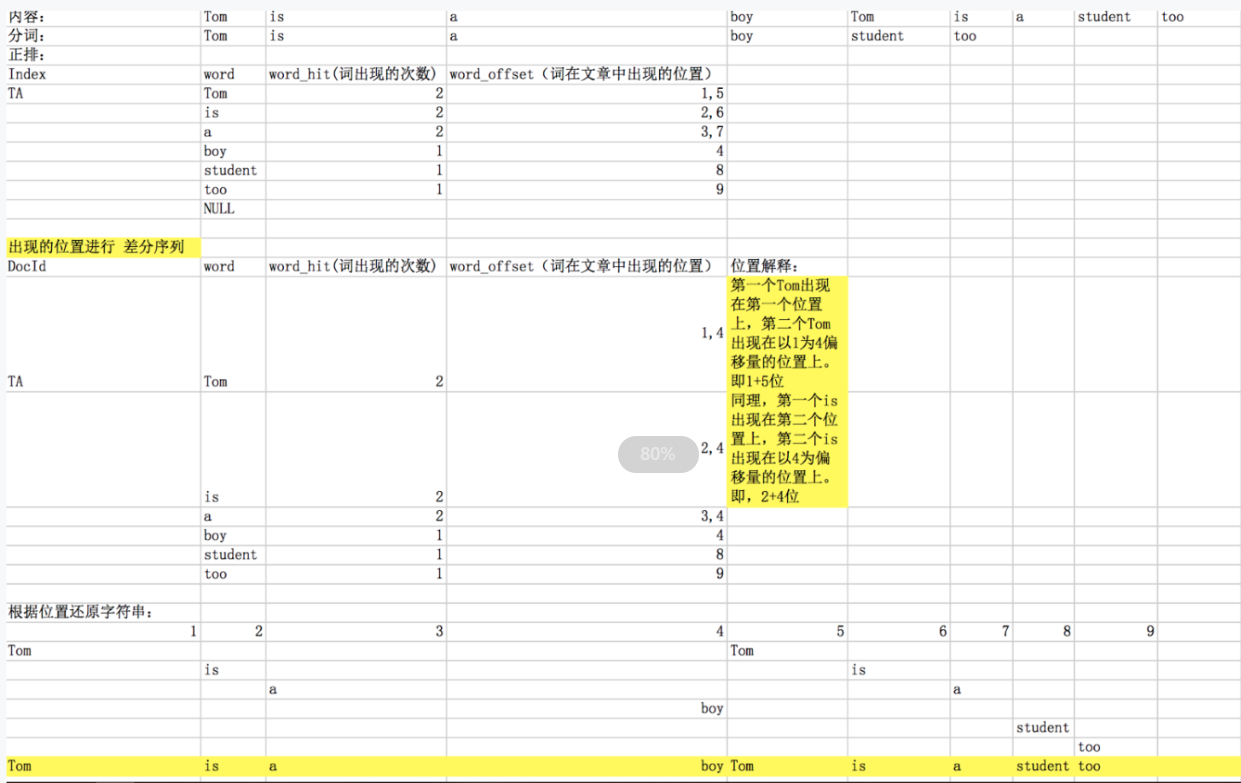
1. 正排索引:文档ID为Key,表中记录了,关键词出现的次数,出现的位置。优点:易维护。缺点:搜索的耗时太长。
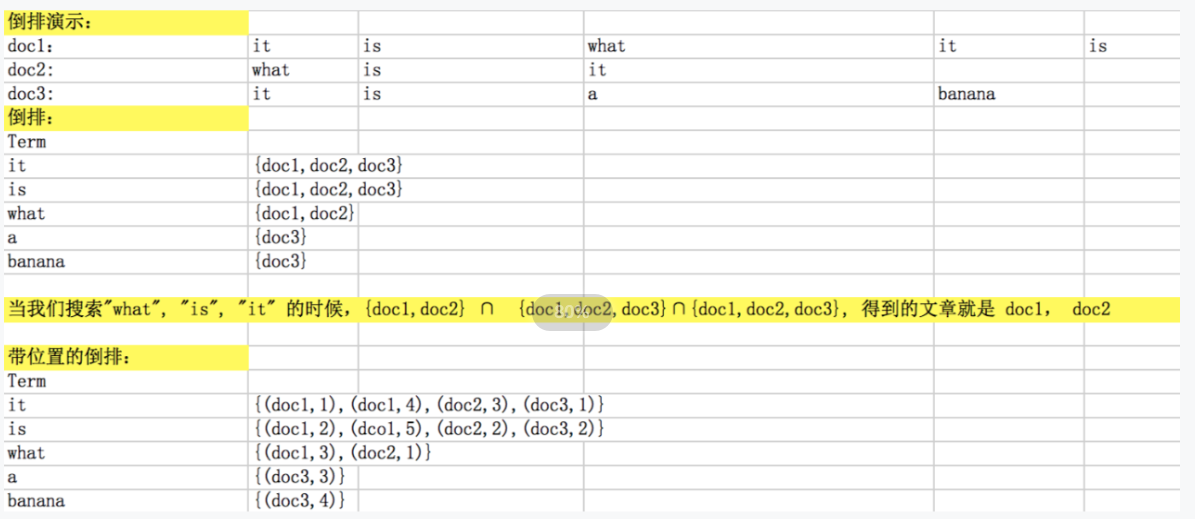
2. 倒排索引:关键词为Key,表中记录了,文档的ID,出现的频率,出现的位置。优点:搜索耗时短。缺点:不易维护。
实现:
1. Lucene中Analyzer分词器将有效的关键词分解出来。
2. 关键词:是按字符顺序排列的,可以用二元搜索算法快速定位到关键词。
3. 实现时:词典文件、频率文件、位置文件。词典文件通过指针指向了频率文件和位置文件。
4. 压缩算法:保存数字时,只保存与上一个值的差值。节省字节数。
数据库索引(B+tree)
B树:

一颗m阶的B树;
1. 每个节点最多含有m个孩子;
2. 每个节点至少有【ceil(m/2)】个孩子,ceil(x)是一个取上限的函数。
B-树的插入
满足:左小右大;节点个数;
节点未满:插入即可。节点已满:需要分裂,上移到父节点。
B-树的删除
满足:左小右大;节点个数;
若有左右孩子:需要上移,若没有,直接删除。
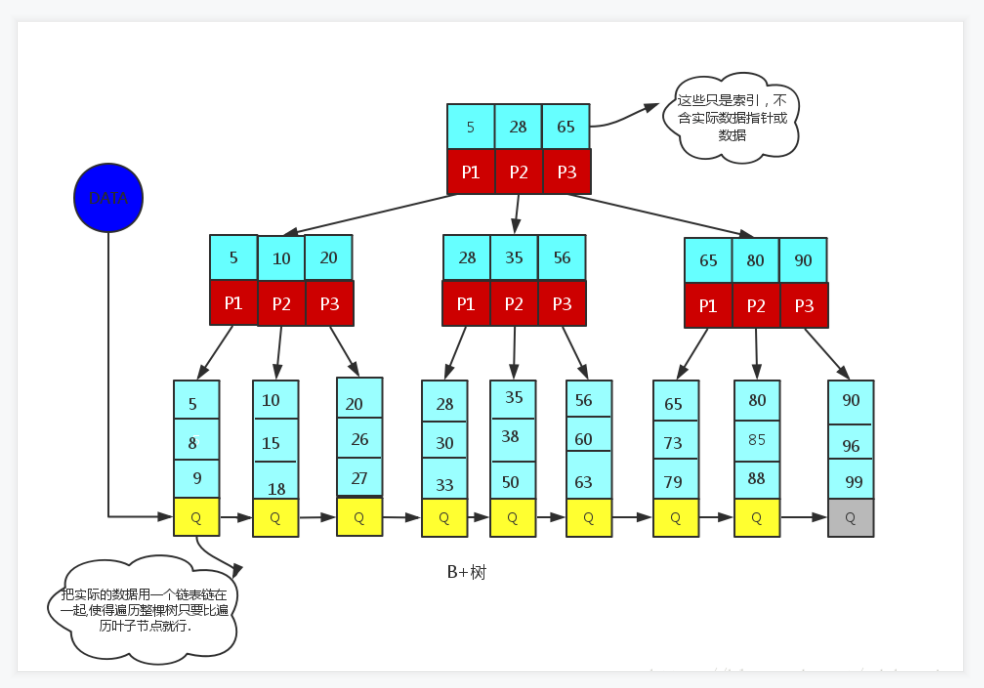
B+树:
mysql的InnoDB引擎使用的B+树;数据库的索引机制;
B+树的插入
满足:左小右大;节点个数;
节点未满:插入即可。节点已满:需要分裂,上移到父节点。
B+树的删除
满足:左小右大;节点个数;
直接删除,或者从邻近兄弟借元素,或者合并。
B-树和B+树的区别
1. B+树的非叶子节点没有指向关键字指针或数据;它们存放在同一块盘中,一次加载进内存,有很好的空间局部性,IO次数可以降低。
2. B+树所有的数据都在叶子节点。每次访问路径长度相同,若访问的元素离根节点很近,则B树访问更迅速。
3. 数据库索引采用B+树的主要原因是B树在提高了IO性能的同时并没有解决元素遍历效率低下的问题。B+tree叶子节点中增加了一个链指针,B+树只需要取遍历叶子节点可以实现整棵树的遍历。而且数据库中基于范围的查询是非常频繁的,B树对基于范围的查询效率太低。
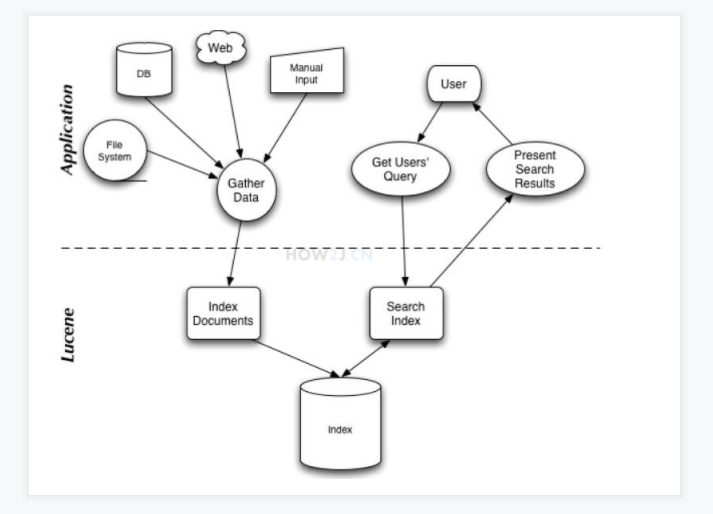
Lucene思路图
1. 首先搜集数据
数据可以是文件系统,数据库,网络上,手工输入的,或者像本例直接写在内存上的
2. 通过数据创建索引
3. 用户输入关键字
4. 通过关键字创建查询器
5. 根据查询器到索引里获取数据
6. 然后把查询结果展示在用户面前
参考:
Luncene基本概念:
倒排、分词:
B树结构:

