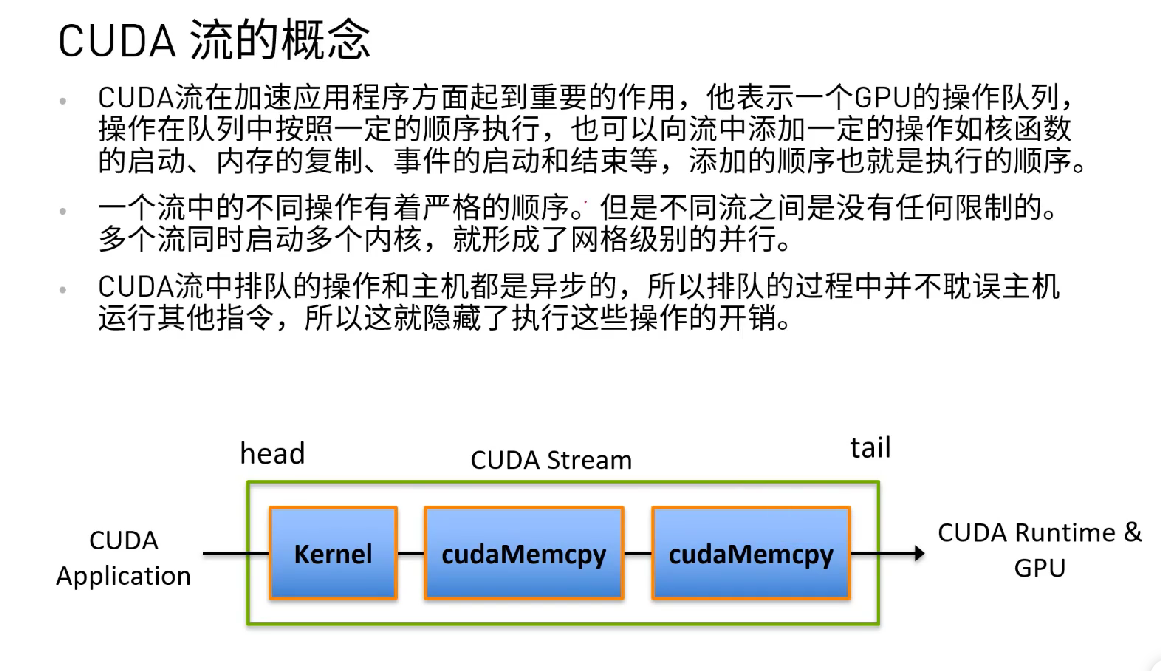
cuda 流
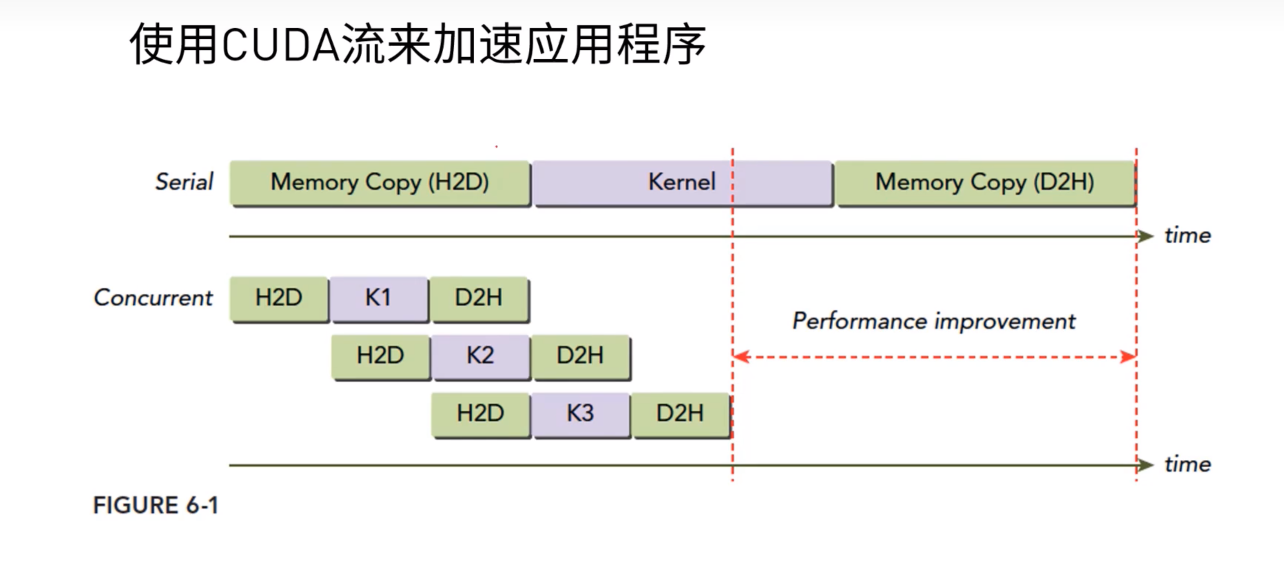
如下图,将多个执行相同核函数的进程通过cuda流来使他们并发执行,提升效率
这很像cpu的流水线
想让下面这个核函数执行两次,每次都是不同的参数
我们需要用到cuda的流来并发的执行提升效率
__global__ void kernel( int *a, int *b, int *c ) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) {
int idx1 = (idx + 1) % 256;
int idx2 = (idx + 2) % 256;
float as = (a[idx] + a[idx1] + a[idx2]) / 3.0f;
float bs = (b[idx] + b[idx1] + b[idx2]) / 3.0f;
c[idx] = (as + bs) / 2;
}
}
实现:
#include<iostream>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
# define N (1024*1024)
# define FULL_DATA_SIZE (N*20)
__global__ void kernel(int* a, int* b, int* c)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N)
{
int idx1 = (idx + 1) % 256;
int idx2 = (idx + 2) % 256;
float as = (a[idx] + a[idx1] + a[idx2]) / 3.0f;
float bs = (b[idx] + b[idx1] + b[idx2]) / 3.0f;
c[idx] = (as + bs) / 2;
}
}
int main(void)
{
cudaStream_t stream0, stream1;
int* host_a, * host_b, * host_c;
int* dev_a0, * dev_b0, * dev_c0;
int* dev_a1, * dev_b1, * dev_c1;
cudaStreamCreate(&stream0); //初始化流
cudaStreamCreate(&stream1);
cudaMalloc((void**)&dev_a0, N * sizeof(int));
cudaMalloc((void**)&dev_b0, N * sizeof(int));
cudaMalloc((void**)&dev_c0, N * sizeof(int));
cudaMalloc((void**)&dev_a1, N * sizeof(int));
cudaMalloc((void**)&dev_b1, N * sizeof(int));
cudaMalloc((void**)&dev_c1, N * sizeof(int));
//分配一个大小为FULL_DATA_SIZE * sizeof(int)字节的主机内存空间,
//cudaHostAllocDefault是分配标志,告诉CUDA运行时将主机内存分配为可被GPU直接访问的可锁定内存
//这意味着数据可以直接从主机内存传输到GPU内存,而不需要中间的数据复制操作。
cudaHostAlloc((void**)&host_a, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault);
cudaHostAlloc((void**)&host_b, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault);
cudaHostAlloc((void**)&host_c, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault);
//初始化
for (int i = 0; i < FULL_DATA_SIZE; i++) {
host_a[i] = rand();
host_b[i] = rand();
}
for (int i = 0; i < FULL_DATA_SIZE; i += N * 2)
{
//将指定大小的数据从主机内存异步复制到设备内存。
//由于是异步调用,函数调用将立即返回,而复制操作将在指定的CUDA流stream中异步执行。
//这允许主机和设备之间的数据传输与其他CUDA操作重叠,从而提高程序性能。
cudaMemcpyAsync(dev_a0, host_a + i, N * sizeof(int), cudaMemcpyHostToDevice, stream0);
cudaMemcpyAsync(dev_a1, host_a + i + N, N * sizeof(int), cudaMemcpyHostToDevice, stream1);
cudaMemcpyAsync(dev_b0, host_b + i, N * sizeof(int), cudaMemcpyHostToDevice, stream0);
cudaMemcpyAsync(dev_b1, host_b + i + N, N * sizeof(int), cudaMemcpyHostToDevice, stream1);
kernel << <N / 256, 256, 0, stream0 >> > (dev_a0, dev_b0, dev_c0);
kernel << <N / 256, 256, 0, stream1 >> > (dev_a1, dev_b1, dev_c1);
cudaMemcpyAsync(host_c + i, dev_c0, N * sizeof(int), cudaMemcpyDeviceToHost, stream0);
cudaMemcpyAsync(host_c + i + N, dev_c1, N * sizeof(int), cudaMemcpyDeviceToHost, stream1);
}
//流同步 , 等待与指定流相关的所有CUDA操作完成
cudaStreamSynchronize(stream0);
cudaStreamSynchronize(stream1);
//回收内存和流
cudaFreeHost(host_a);
cudaFreeHost(host_b);
cudaFreeHost(host_c);
cudaFree(dev_a0);
cudaFree(dev_b0);
cudaFree(dev_c0);
cudaFree(dev_a1);
cudaFree(dev_b1);
cudaFree(dev_c1);
cudaStreamDestroy(stream0);
cudaStreamDestroy(stream1);
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号