cuda 加速矩阵乘法
不优化
对于一个m * n的矩阵a和一个n * k的矩阵b
因为最后得到一个m * k的矩阵c,那么我们可以分配m * k个线程。
在线程(i,j)里矩阵a的第i行和矩阵b的第j列进行点积运算得到c[i][j]
#include<iostream>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
# define BLOCK_SIZE 2
__global__ void gpu_matrix_mult(int* a, int* b, int* c, int m, int n, int k)
{
//row和col是该线程所在行数和列数
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
int sum = 0;
if (col < k && row < m)
{
for (int i = 0; i < n; i++)
{
sum += a[row * n + i] * b[i * k + col];
}
c[row * k + col] = sum;
}
}
int main()
{
int m = 100, n = 100, k = 100;
int* h_a, * h_b, * h_c;
cudaMallocHost((void**)&h_a, sizeof(int) * m * n);
cudaMallocHost((void**)&h_b, sizeof(int) * n * k);
cudaMallocHost((void**)&h_c, sizeof(int) * m * k);
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < n; ++j)
h_a[i * n + j] = rand() % 1024;
}
for (int i = 0; i < n; ++i)
{
for (int j = 0; j < k; ++j)
h_b[i * k + j] = rand() % 1024;
}
int* d_a, * d_b, * d_c;
cudaMalloc((void**)&d_a, sizeof(int) * m * n);
cudaMalloc((void**)&d_b, sizeof(int) * n * k);
cudaMalloc((void**)&d_c, sizeof(int) * m * k);
cudaMemcpy(d_a, h_a, sizeof(int) * m * n, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, sizeof(int) * n * k, cudaMemcpyHostToDevice);
//BLOCK_SIZE是一个block边的大小
//grid_rows是一个grid有几行block
//grid_cols是一个grid有几列block
//dimGrid是一个grid一行有几个block,一列有几个block
//dimBlock是一个block一行有几个thread,一列有几个thread
unsigned int grid_rows = (m + BLOCK_SIZE - 1) / BLOCK_SIZE;
unsigned int grid_cols = (k + BLOCK_SIZE - 1) / BLOCK_SIZE;
dim3 dimGrid(grid_cols, grid_rows);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
gpu_matrix_mult<<<dimGrid , dimBlock>>>(d_a, d_b, d_c, m, n, k);
cudaMemcpy(h_c, d_c, sizeof(int) * m * k, cudaMemcpyDeviceToHost);
for (int i = 0; i < m*k; i++)
{
std::cout << h_c[i] << std::endl;
}
return 0;
}
shared memory优化
理解的还不是很清楚,以后详细讲一下
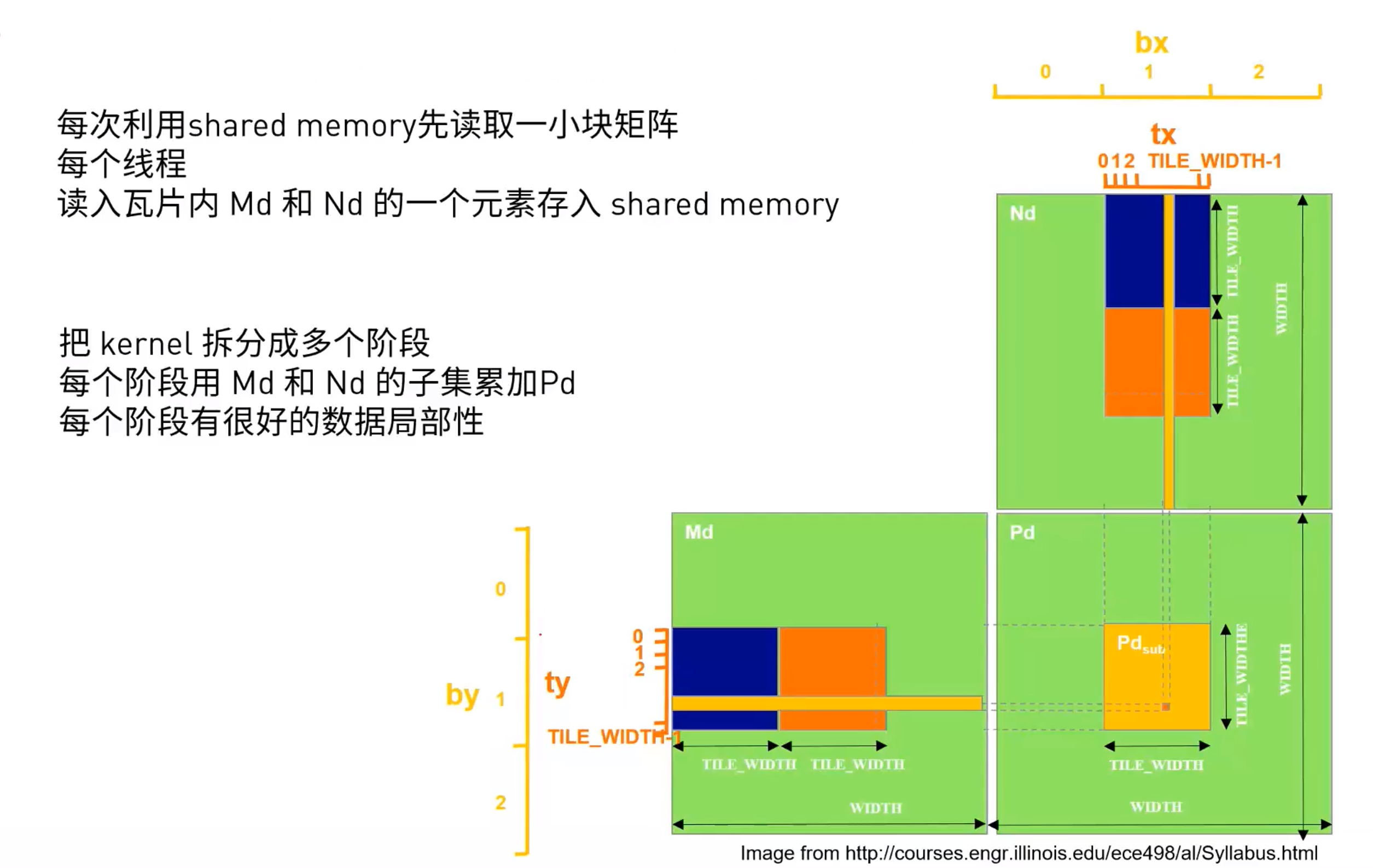
__global__ void gpu_matrix_mult_shared(int *d_a , int *d_b , int *d_result, int M , int N , int K)
{
int col = blockIdx.x * blockDim.x + threadIdx.x;
int row = blockIdx.y * blockDim.y + threadIdx.y;
__shared__ int tile_a[BLOCK_SIZE][BLOCK_SIZE];
__shared__ int tile_b[BLOCK_SIZE][BLOCK_SIZE];
int tmp = 0, idx;
for (int sub = 0 ; sub <= N / BLOCK_SIZE; ++sub)
{
int r = row;
int c = sub * BLOCK_SIZE + threadIdx.x;
idx = r * N + c;
if (r >= M || c >= N)
{
tile_a[threadIdx.y][threadIdx.x] = 0;
}
else
{
tile_a[threadIdx.y][threadIdx.x] = d_a[idx];
}
r = sub * BLOCK_SIZE + threadIdx.y;
c = col;
idx = r * K + c;
if (c >= K || r >= N)
{
tile_b[threadIdx.y][threadIdx.x] = 0;
}
else
{
tile_b[threadIdx.y][threadIdx.x] = d_b[idx];
}
__syncthreads();
for (int k = 0; k < BLOCK_SIZE; ++k)
{
tmp += tile_a[threadIdx.y][k] * tile_b[k][threadIdx.x];
}
__syncthreads();
}
if (row < M && col < K)
{
d_result[row * K + col] = tmp;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号