cuda 核函数
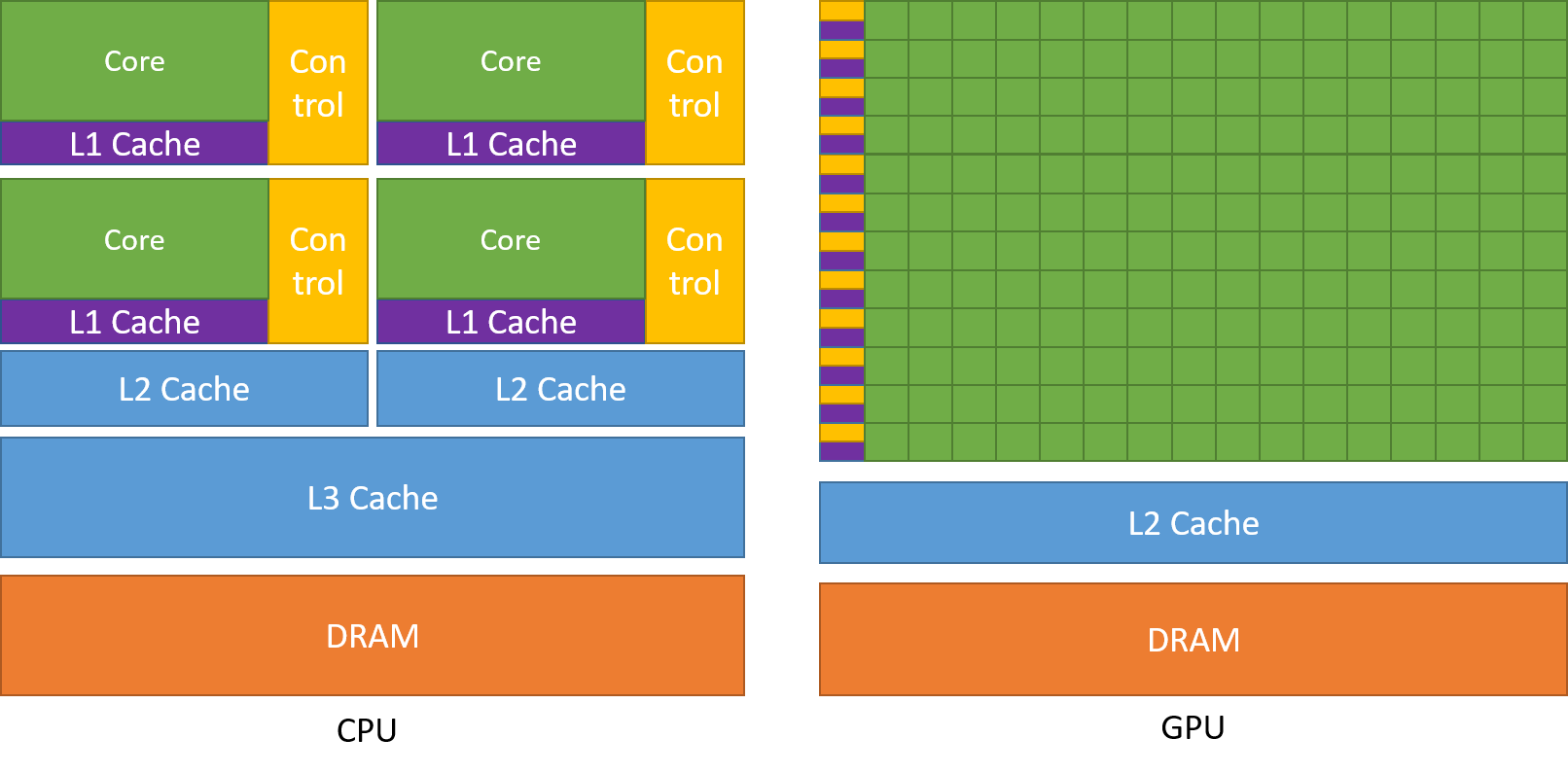
先看下为何需要cuda来实现gpu编程
如图所示,尽管现代cpu已经实现多核,但其和gpu相比还是要少得多。
所以一些重复的运算交给gpu,而一些逻辑运算交给cpu
cpu控制逻辑,gpu来辅助运算
核函数
主机(host)通过核函数来操作gpu(device)辅助计算
需要注意的是只有核函数可以操纵gpu,包括申请内存、gpu中变量的计算、gpu中变量的输出......
#include<stdio.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
__global__ void hello_world(void) //像这样修饰的就是核函数
{
printf("GPU: Hello world!\n");
}
int main(int argc, char** argv)
{
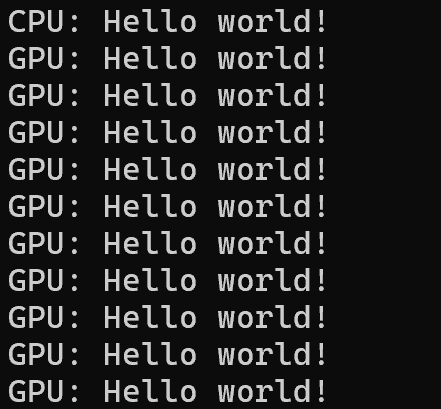
printf("CPU: Hello world!\n");
hello_world <<<1, 10 >>> ();
//核函数的调用时三个尖括号引用的变量为<<<grid.size,block.size>>>
cudaDeviceReset();//if no this line ,it can not output hello world from gpu
return 0;
}
输出结果:
我们来解释一下尖括号里的grid.size和block.size
一个核函数只有一个grid,grid里有block,block里有thread
所以<<<grid.size,block.size>>>其实等价于<<<block,thread>>>
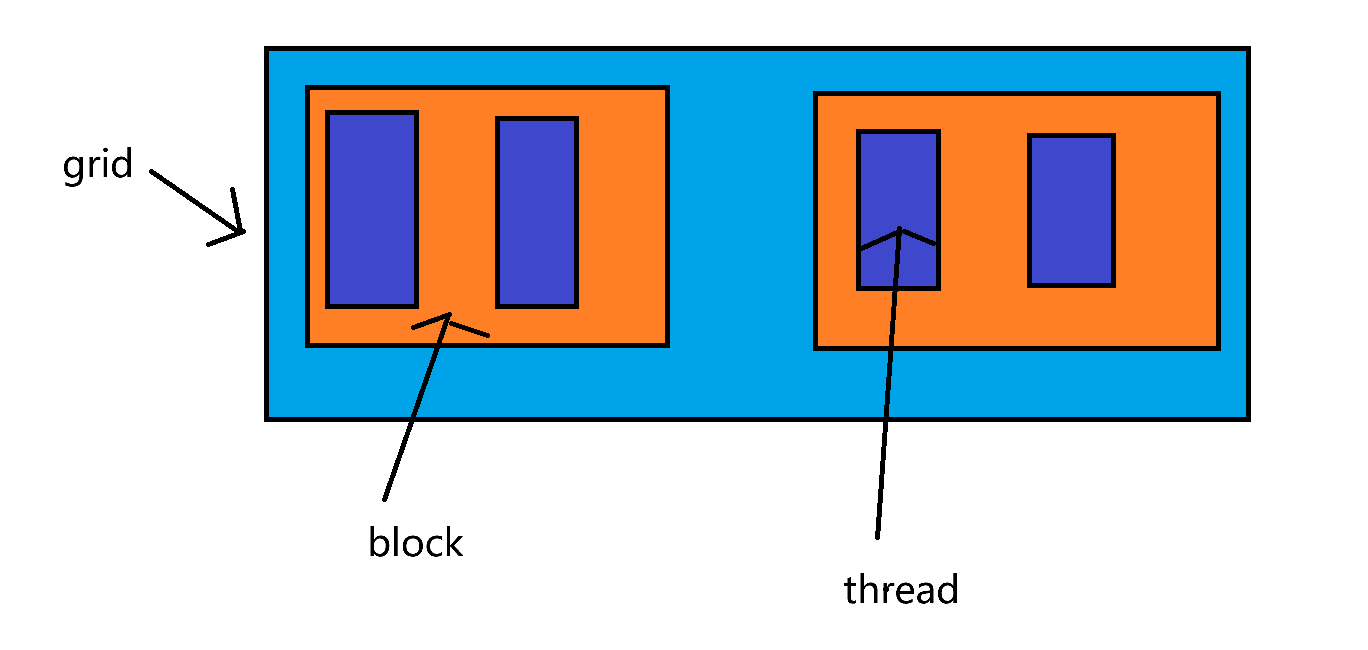
调用核函数时自己指定将grid分为n个block,每个block有m个thread
那么block的编号为0-n,thread的编号为0-m
blockIdx则为block的编号,二维情况下则用blockIdx.x
threadIdx则为thread的编号,二维情况下用threadIdx.x
gridDim为一个grid的block数量
blockDim为一个block的线程数量
cuda线程分配
在分配线程时,block.size最好设置为32的倍数
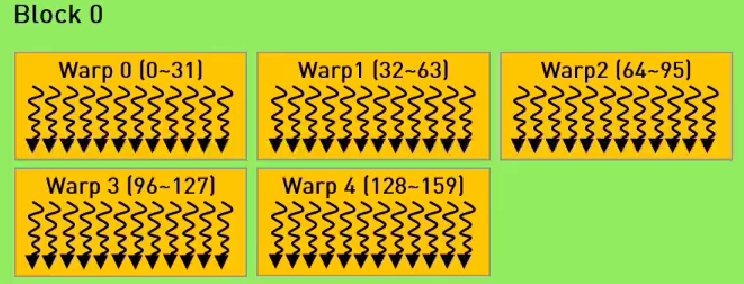
如图,一个block有若干个warp
每个warp有32个thread,所以在分配thread最好设置为32的倍数。
不然可能会导致有warp里的线程不会参与工作造成资源的浪费

 浙公网安备 33010602011771号
浙公网安备 33010602011771号