cuda c 矢量相加
若线程够用
# include<iostream>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
# define n 10
//定义成宏而不是定义成全局变量
//是因为随便定义全局变量可能会导致在调用核函数的时候发生"应输入表达式"的错误
__global__ void add(int *a , int *b , int *c)
{
int i = blockIdx.x;
c[i] = a[i] + b[i];
}
int main()
{
int a[n], b[n], c[n];
int* dev_a, int* dev_b, int* dev_c;
cudaMalloc((void**)&dev_a, n * sizeof(int));
cudaMalloc((void**)&dev_b,n * sizeof(int));
cudaMalloc((void**)&dev_c, n * sizeof(int));
//向gpu申请内存
//此时dev_这三个变量已经指向gpu的内存而不是cpu的
for (int i = 0; i < n; i++)
{
a[i] = i, b[i] = i + 1; //给cpu的两个数组赋值
}
cudaMemcpy(dev_a, a, n * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, n * sizeof(int), cudaMemcpyHostToDevice);
//将cpu的数组传到gpu上
add << <n, 1 >> > (dev_a, dev_b, dev_c);
//n个block,每个block有1个thread
cudaMemcpy(c, dev_c, n * sizeof(int), cudaMemcpyDeviceToHost);
//将答案复制到cpu上
for (int i = 0; i < n; i++) printf("%d ", c[i]);
cudaFree(dev_a); //释放gpu上申请的内存
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}
若线程不够用
假设我们要32个数相加,但只给gpu分配了2block*4thread = 8个线程
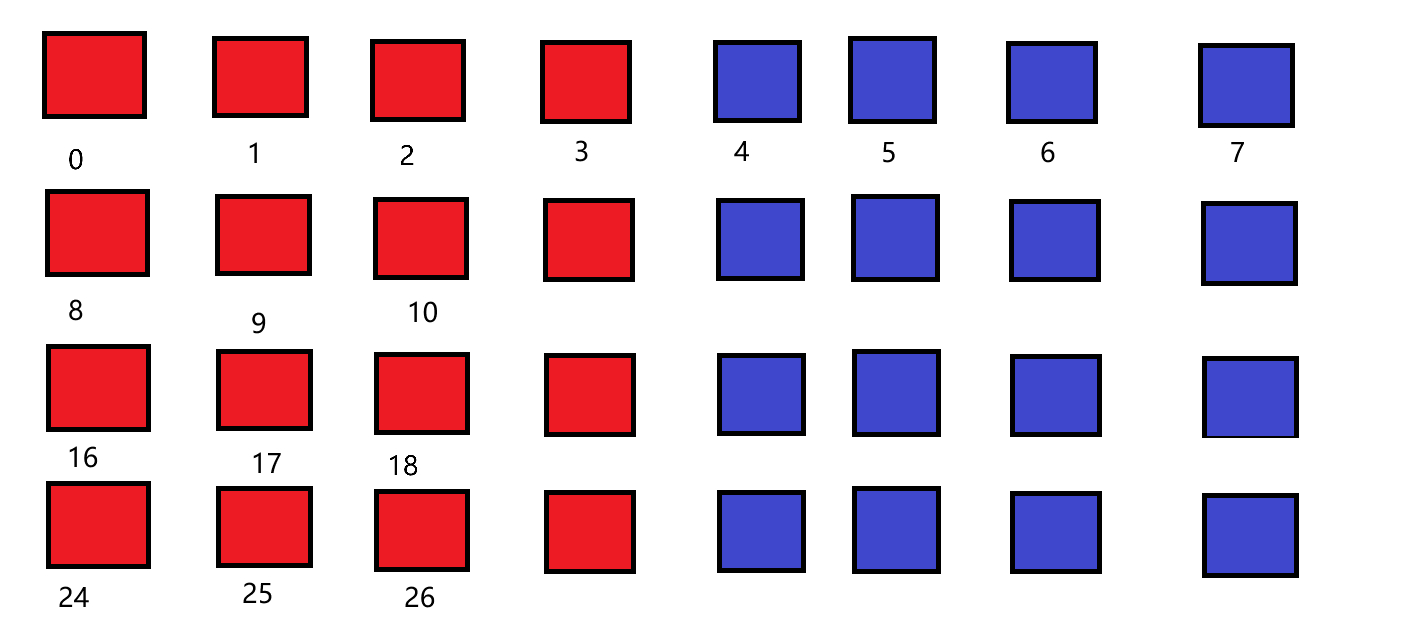
逐步分析一下上图
每一行的八个块代表分配的8个线程,红色为block1,蓝色为block2
我们可以让这八个线程轮流负责这32个数
0号线程负责它所在的那一列(0,8,16,24)
1号线程负责它所在的那一列(1,9,17,25)
...
7号线程负责它所在的那一列(7,15,23,31)
每个线程负责的都是一个差为8(块数*每个块的线程数 = gridDim * blockDim)的等差数列
#include<iostream>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
# define N 32
__global__ void add(int *d_a , int *d_b , int *d_c)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int str = gridDim.x * blockDim.x;
for (; i < N; i += str) d_c[i] = d_a[i] + d_b[i];
}
int main(int argc, char** argv)
{
int a[N], b[N], c[N];
int* d_a, int* d_b, int* d_c;
cudaMalloc((void**)&d_a, N * sizeof(int));
cudaMalloc((void**)&d_b, N * sizeof(int));
cudaMalloc((void**)&d_c, N * sizeof(int));
for (int i = 0; i < N; i++) a[i] = i;
for (int i = 0; i < N; i++) b[i] = i;
cudaMemcpy(d_a, a, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, N * sizeof(int), cudaMemcpyHostToDevice);
add << <2, 4 >> > (d_a, d_b, d_c);
cudaMemcpy(c, d_c, N * sizeof(int), cudaMemcpyDeviceToHost);
for (int i = 0; i < N; i++) std::cout << c[i] << " ";
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号