第三章 程序的机器级表示
注1: 这章的所有代码都是运行于x86-64位的linux系统上,也就是ATT风格的汇编代码
注2: intel 和 ATT是两种不同风格的汇编语言。
intel主要用于dos和windows,ATT主要用于Unix和linux。nasm和masm使用intel语法。
ATT的特点是与我们学的高级语言相悖:前面的数赋值给后面的数
1. 初识汇编
汇编语言是专门为某一类cpu设计的,汇编语言的类型与机器的处理器类型有关。这章中的所有都是基于x86-64位
给出这样一段c代码
long mult2(long,long);
void multstore(long x,long y,long *dest){
long t = mult2(x,y);
*dest = t;
}
这段代码的ATT汇编
我们使用指令
linux> gcc -Og -S mstore.c
可以将mstore.c 编译为ATT风格的汇编文件mstore.s
.file "mstore.c"
.text
.globl multstore
.type multstore, @function
multstore:
.LFB0:
.cfi_startproc
endbr64
1. pushq %rbx
.cfi_def_cfa_offset 16
.cfi_offset 3, -16
2. movq %rdx, %rbx
3. call mult2@PLT
4. movq %rax, (%rbx)
5. popq %rbx
.cfi_def_cfa_offset 8
6. ret
所有以'.'开头的行都是指导汇编器和链接器工作的伪指令,我们通常可以忽略这些行。
我在这段汇编代码中标注了6行。(根据寄存器的用法,函数multstore的三个参数x,y,dest分别保存在寄存器rdi,rsi,rdx中)
将寄存器rbx中的值压入栈中。
因为下面将要调用函数mult2,为了保证调用函数的时候实参不变,所以将rbx中的元素先压入栈
将寄存器rdx中的内容复制到寄存器rbx中(因为是ATT风格,所以是左边的数复制到右边)
因为寄存器rdx存放的是指针dest的内容,所以这条指令结束后rbx和rdx都指向了dest指针所指向的内容。1和2的操作都是为了避免在函数执行的过程中,形参的真实值被改变
调用mult2函数
将寄存器rax中的值复制到寄存器rbx所指向的位置上
寄存器rax保存mult2函数的返回结果
其实就是对应的*dest = t
将栈中元素弹出,并放入寄存器rbx中
multstone函数执行完毕,之前从寄存器rbx入栈的元素返回寄存器
multstone函数结束,从当前函数返回,将控制权交回给调用者
这段代码的intel汇编
我们还可以使用指令
gcc -Og -S -masm=intel mstore.c
之前的gcc -Og -S mstore.c指令可以将代码编译为ATT风格的汇编,这条指令则可以将代码编译为intel风格的汇编。详情参见注2
multstore:
.LFB0:
.cfi_startproc
endbr64
push rbx
.cfi_def_cfa_offset 16
.cfi_offset 3, -16
1. mov rbx, rdx
call mult2@PLT
2. mov QWORD PTR [rbx], rax
pop rbx
.cfi_def_cfa_offset 8
ret
这段汇编和上面ATT风格的主要有两点不同(已标记为1,2)
- 原先rdx和rbx互换了位置,但其实这行代码的意思还是将rdx的值赋值给rbx
- QWORD PTR的意思是指64位(8字节数据类型)这条指令的含义是:将 rax 寄存器的值(一个64位的数字)复制到 rbx 寄存器指向的内存地址中。
反汇编
要查看机器代码文件或者源程序文件的内容,我们可以使用反汇编器
比如对于目标代码文件mstore.o(还没有链接的二进制文件),我们想要查看它对应的汇编代码,我们可以在linux系统中打出指令
linux>objdump -d mstore.o
结果如下:
mstore.o: 文件格式 elf64-x86-64
Disassembly of section .text:
0000000000000000 <multstore>:
0: f3 0f 1e fa endbr64
4: 53 push %rbx
5: 48 89 d3 mov %rdx,%rbx
8: e8 00 00 00 00 call d <multstore+0xd>
d: 48 89 03 mov %rax,(%rbx)
10: 5b pop %rbx
11: c3 ret
2. 数据格式
由于早期的机器是16位,后来才扩展到32位,因此intel用字(word)来表示16位的数据类型
32位数为双字(double words) 64位数为四字(quad words)
下图给出c语言基本数据类型对应的x86-64表示

那么我们之前ATT风格的汇编代码里面的pushq,popq,movq就好理解了,因为传送的数是long long类型(4字),所以汇编代码后缀是q
3. 寄存器
最早的8086存储器包含8个16位寄存器。
扩展到IA32架构时,寄存器扩展到32位。
扩展到x86-64后,原来8个寄存器扩展到64位,除此之外,还增加了8个新寄存器:%r8到%r15
所以一个x86-64的cpu包含一组16个64位的寄存器
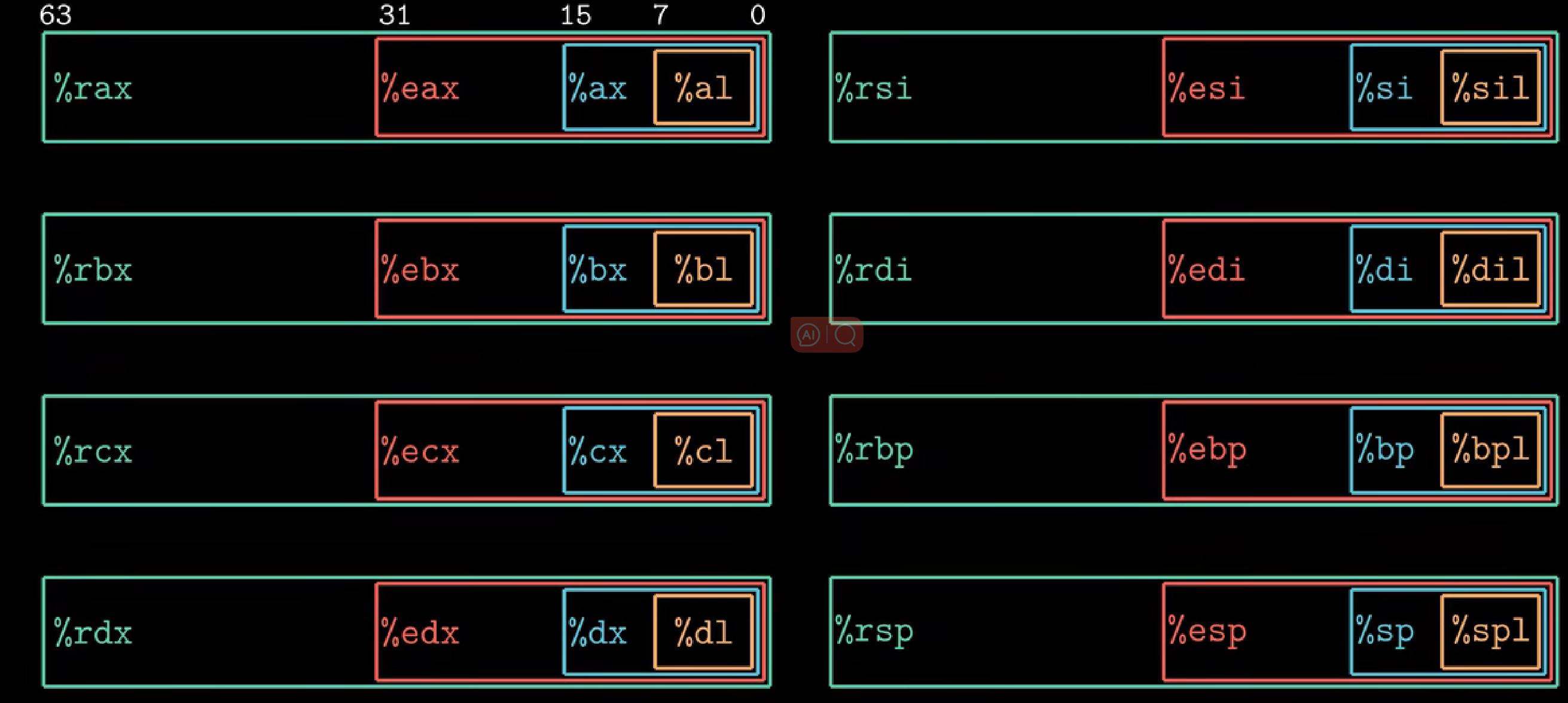
下图中 caller saved为调用者保存,callee saved为被调用者保存

每个寄存器都有特殊的用途,比如rax保存返回值,rsp保存栈顶指针
对于16位操作可以访问最低的2个字节,比如想把一个16位数存放到%rax中,那么其实可以理解为存到了%al。
32位,64位以此类推。
不过关于存储数值在寄存器有两条规则:
- 生成1字节和2字节数字的指令会保持剩下的字节不变
- 生成4字节数字的指令会把高位4个字节置为0
4. 操作数指示符
大多数指令包含两部分:操作码和操作数

大多数指令有一个或多个操作数,指示出源操作数和放置结果的目的操作数
操作数分为三种类型:
-
立即数 :常数值
比如$8 -
寄存器
下图中,用\(r_a\)表示一个寄存器,\(R[r_a]\)表示寄存器的值 -
内存引用:根据计算出来的地址(通常称为有效地址)访问某个内存位置
对于内存中的地址Addr,我们用符号\(M_b[Addr]\)表示对存储在内存中从地址Addr开始的b个字节值的引用,通常省略下标b
我们有多种寻址模式允许不同形式的内存引用。\(Imm(r_b,r_i,s)\)是最常用的形式。
\(imm\):立即数 , \(r_b\):基址寄存器 ,\(r_i\):变址寄存器 ,\(s\):比例因子
s根据数组的类型确定取值,数组类型为1字节就是1,4字节就是4。可以取1,2,3,4,8
比如12(%rsp , %rdx , 4)的有效地址为12+\(R[rsp]+R[rdx]*4\)

5. 数据传送指令
最简单形式的数据传送指令--MOV类,这些指令把数据从源位置复制到目的位置
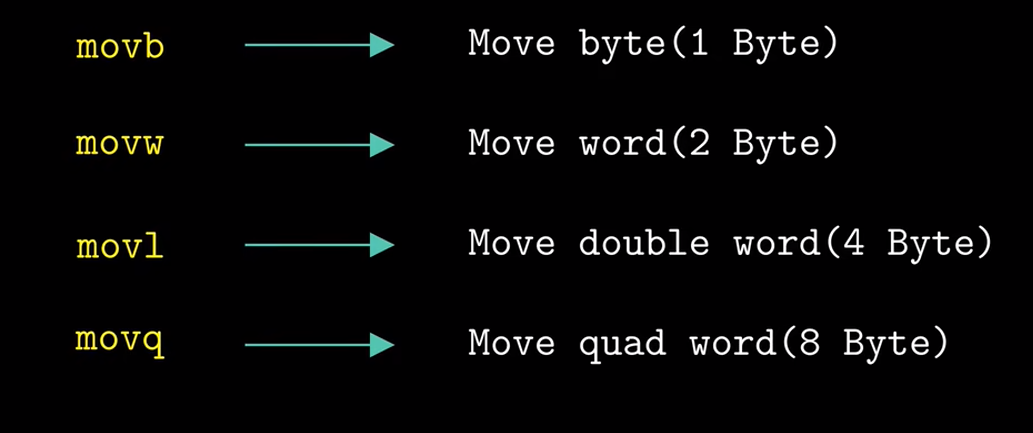
需要注意的是:x86-64加了一条限制,传送指令的两个操作数不能都指向内存位置。
所以将一个值从内存位置复制到另一个内存位置需要两条指令:
- 将源值从内存加载到寄存器
- 将寄存器值写入目的位置
mov指令还有几个特殊的情况需要了解
- 对于movq $Imm %rax 这样movq的源操作数是立即数时,该立即数只能是32位的补码表示。然后将该立即数进行符号位扩展,得到的64位数传送到目的位置
- 当立即数是64位时,我们使用指令movabsp,目的操作数只能是寄存器
我们来看一个例子:
我们依次使用不同指令,来观察寄存器的变化
movabsp $0x0011223344556677 %rax //使用movabsp改变64位

movb $-1 %al //使用movb只改变了低八位

movw $-1 ax //使用movw只改变低16位

movl $-1 eax //使用movl,不仅改变了低32位
//根据存储数值在寄存器的规则:生成4字节数字的指令会把高位4个字节置为0

以上都是源操作数与目的操作数大小一致的情况。下面我们来介绍较小的源值复制到较大的目的时使用。
当较小的源值复制到较大的目的寄存器时,有两类指令
-
MOVZ指令:0扩展
第一个字母表示源操作数的大小,第二个字母表示目的操作数的大小

-
MOVS指令:符号位扩展

我们可以发现MOVS比MOVZ多了一条movslq(从4字节到八字节)指令
这是因为对于0扩展,我们可以直接借助规则:传送4字节时自动进行0扩展使用movl指令就好了
最后还有一个指令cltq,该指令的源操作数总是寄存器eax,目的操作数总是寄存器rax
6. 栈与数据传送指令
我们看一个数据交换函数
long exchange(long* xp , long y)
{
long x = *xp;
*xp = y;
return x;
}
这个函数由三条指令实现:
exchange: //当函数开始执行时,参数xp和y分别存储在寄存器%rdi和%rsi中
movq (%rdi),%rax //从寄存器中读出xp,从xp指向内存读出x存放到寄存器%rax中
movq %rsi,(%rdi) //将y写入寄存器%rdi中xp指向的内存位置
ret //返回的值为寄存器rax中的值,也就是*xp
我们还有两个数据传送操作:将数据压入程序栈以及从程序栈中弹出数据
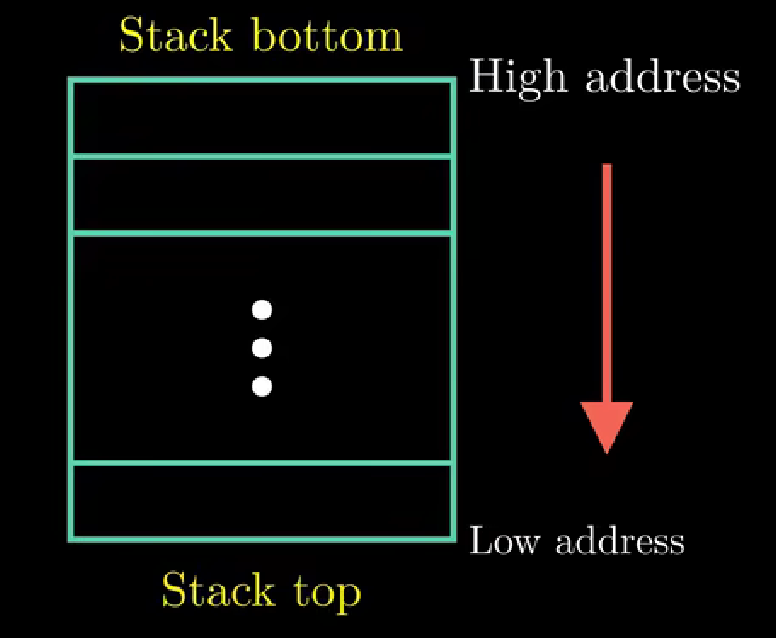
栈的增长方向是高地址到底地址,因此栈顶元素是地址最低的
- 对于pushq %rax
指向栈顶的%rsp-8,然后将s复制到新的栈顶地址
可以表示为
//伪代码:
R[%rsp] = R[%rsp]-8
M[R[%rsp]] = %rax
//汇编代码:
subq $8 , %rsp
movq %rax , (%rsp)
- 对于popq %rbx
将栈顶保存的数据复制到寄存器D,然后栈顶指针+8
可以表示为
//伪代码:
%rbx = M[R[%rsp]]
R[%rsp] = R[%rsp]+8
//汇编代码:
movq (%rsp) , %rbx
addq $8 , %rsp
7. 算术和逻辑操作
1. 加载有效地址
加载有效地址指令leaq将有效地址写入到目的操作数
指令形式和内存引用很像,只是少了最后的引用内存。
leaq 7(%rdx , %rdx , 4) , %rax
这行代码的意思是将地址\(7+ \%rdx + \%rdx*4 = 5* \%rdx+7\)赋值给%rax中
我们还可以依赖加载有效地址描述普通的算术操作
比如我们要实现算术操作\(t = x+4*y+12*z\)
c语言:
long scale(long x , long y , long z) {
long t = x+4*y+12*z;
return t;
}
汇编:
//%rdi , %rsi , %rdx分别保存x , y , z
scale :
leaq (%rdi , %rsi , 4) , %rax //把x+4*y存到%rax中
leaq (%rdx , %rdx , 2) , %rdx //把3*z存到%rdx中
leaq (%rax , %rdx , 4) , %rax
//把%rax+4*%rdx的值(其实就是x+4*y+12*z)放入%rax
ret //返回%rax中的值
大家可能会疑惑汇编的第二和第三个leaq为什么不能合成一句
leaq (%rax , %rdx , 12) , %rax
主要的原因是比例因子不能取到12
2. 一元操作
一元操作只有一个操作数,既是源又是目的

指令
incq (%rsp)
会使栈顶的8字节元素+1
3. 二元操作
二元操作有两个操作数,第二个操作数既是源又是目的

我们来看一组例子
一开始寄存器与内存中的值如图所示
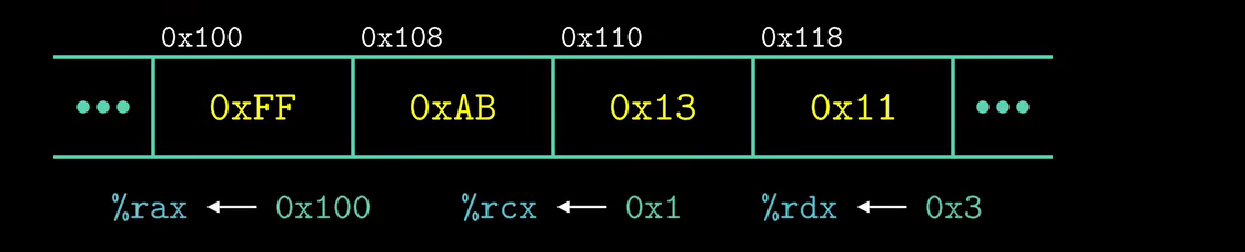
接下来我们将会给出若干指令并给出执行完毕后的结果图
addq %rcx , (%rax)
//将内存0x100中的值与%rcx中的值0x1相加
//结果保存到rax中的值指向的内存位置(0x100)
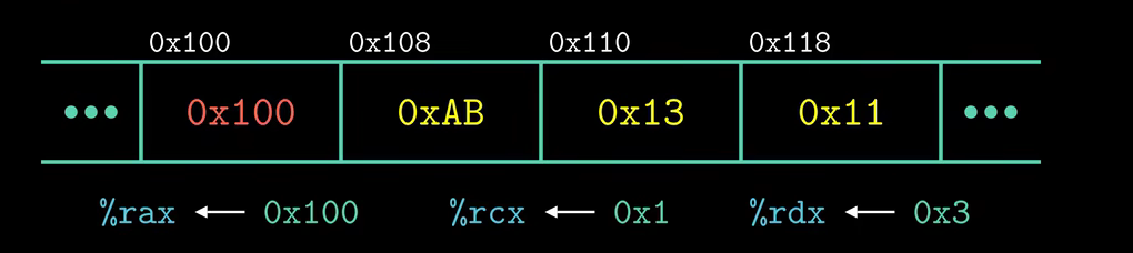
subq %rdx , 8(%rax)
//将rax里的值+8(0x108)指向的内存位置上的值(0xAB)- 0x3
//结果保存到0x108

incq 16(%rax)
//0x100+16 = 0x100+F+1 = 0x110
//M[0x110] = M[0x110]+1

subq %rdx , %rax
//寄存器rax的值-rdx = 0xFD

4. 移位操作

对于移位量k可以是一个立即数,也可以是放在寄存器%cl中的数(只允许以这个寄存器作为操作数)
对于指令salb,移位量由寄存器的低3位来决定,salw:低4位,salq:低5位。
我们来看这行代码
long t = z*48
所对应的汇编指令
//%rdx保存数值z
leaq (%rdx , %rdx , 2) , %rax
//rax保存数值3*z
salq $4 , %rax
//将rax里面的数值右移4位,也就是*2^4 = 48*z
这样得到的乘法运算的结果比直接使用乘法指令效率更高
还有一些特殊的算术指令 ,放一个图在这里,就不再深究了

8. 指令与条件码
除了整数寄存器,cpu还维护着一组单个位的条件码寄存器,它们描述了最近的算数或逻辑操作的属性。
在执行算数和逻辑运算指令时候,需要用到算数逻辑单元(ALU),ALU从寄存器中读取数据然后执行相应的运算并将结果保存到目的寄存器中。
同时,ALU还会根据计算结果设置条件码寄存器(condition code)
整个过程如图所示:

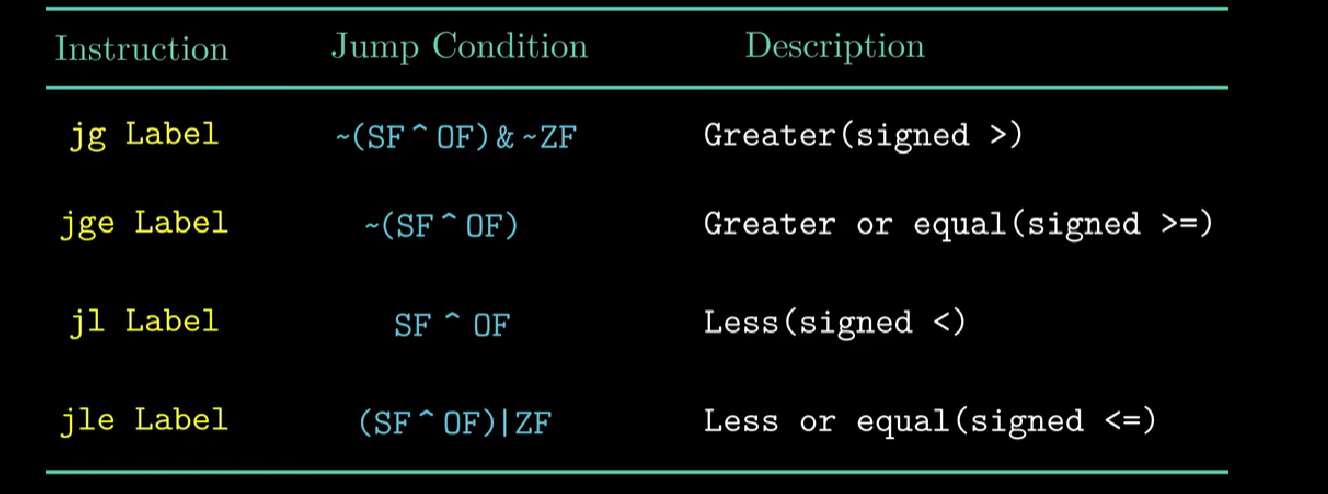
最常用的条件码有四种:
- CF : 进位标志。最近的操作使最高位进位时,CF置1。可以检查无符号数操作的溢出
unsigned char a = 255;
unsigned char b = 1;
unsigned char t = a+b;
//由于a+b发生溢出,CF置1
- ZF : 零标志。最近的操作得出的结果为0时ZF置1
unsigned char a = 1;
unsigned char b = -1;
unsigned char t = a+b;
//a+b == 0 , ZF置1
- SF :符号标志。最近的操作得到的结果为负数时SF置1
- OF :溢出标志(针对有符号数)。最近的操作导致一个补码正溢出或负溢出时OF置1
下图中这些指令都会设置条件码(leaq不会改变任何条件码)
例如XOR:进位标志和溢出标志会置0
移位操作:进位标志设置为最后一个被移出的位,溢出标志设置为0

除此之外,还有两条指令可设置条件码寄存器
- cmp指令
和sub行为一样,然后根据两个操作数之差设置条件码 - test指令
和add行为一样,然后根据两个操作数之和设置条件码
SET指令:每条指令根据条件码的某种组合,将一个字节设置为0或者1

- 例子1:
c代码:
//当a == b时,函数返回1,否则返回0
int comp(long a , long b)
{
return (a == b);
}
汇编代码:
//a放在%rdi , b放在%rsi
comp:
cmpq %rsi , %rdi //设置条件码
sete %al //将ZF复制到%al。后缀e是equal
movzbl %al , %eax //进行0扩展
- 例子2:
c代码:
int comp(char a , char b)
{
return (a<b)
}
汇编代码:
comp:
cmpb %rsi , %rdi
setl %al
//将setl对应的条件码组合复制给%al。
//效果相当于如果%rsi<%rdi,将%al置1。后缀l是less
movzbl %al ,%eax
9. 跳转指令
跳转(jmp)指令会让程序跳转到新的位置
-
直接跳转:
jmp .L1直接跳转到.L1处 -
间接跳转:
jmp *%rax : 用%rax保存的值作为跳转目标
jmp *(%rax):以%rax的值为读地址,在内存中读出跳转目标
跳转指令还会根据条件寄存器的某种组合决定是否进行跳转
例子:
long absdiff_se(long x , long y)
{
long result;
if(x<y) result = y-x;
else result = x-y;
return result
}
absdiff_se:
.LFB0:
.cfi_startproc
endbr64
cmpq %rsi, %rdi
jge .L2 //如果x大于等于y跳转到L2
movq %rsi, %rax
subq %rdi, %rax //y-x
ret
.L2:
movq %rdi, %rax
subq %rsi, %rax //x-y
ret
在64位ubuntu中编译器进行了一个诡异的优化,将if(x<y)在汇编中改写成了if(x>=y)。但是这不是我们关注的重点
我们观察跳转指令,当x>=y则跳转到.L2否则顺序执行。
jge就代表着>=
跳转指令的编码
理解跳转指令的目标如何编码对之后研究链接非常重要,也能帮助理解反汇编器的输出
跳转指令最常用的编码都是PC相对的(PC-relative),也就是
movq %rid,%rax
jmp .L2
.L3:
sarq %rax
.L2:
testq %rax,%rax
jg .L3
rep;ret
将上面的代码汇编后再反汇编后如下:
1 0: 48 89 f8 mov %rdi,%rax
2 3: eb 03 jmp 8 <loop+0x8>
3 5: 48 d1 f8 sar %rax
4 8: 48 85 c0 test %rax,%rax
5 b: 7f f8 jg 5 <loop+0x5>
6 d: f3 c3 repz retq
根据
我们来看第二行的跳转指令。跳转指令的编码为0x03(第二个字节),下一条指令也就是第三行的指令的地址是0x5(第一个数字),0x03+0x5=0x8(跳转目标地址)
我们再来看第五行的跳转指令。跳转指令的编码为0xf8(第二个字节),下一条指令也就是第六行的指令的地址是0xd,0xf8+0xd = 0x5(跳转目标地址)
用条件传送来实现条件分支
控制的条件转移就是当条件满足时,程序沿着一条路径执行,不满足时走另一条路径。但是在现代处理器上,它可能会非常低效
我们可以用数据的条件转移代替控制的转移。计算一个条件操作的两种结果,再根据条件是否满足从中选取一个。只有在一些受限制的情况这种策略才可行。但如果可行,就可以用一条简单的条件传送指令来实现它,更符合现代处理器的性能特性
我们将计算两个数差的绝对值这样实现:
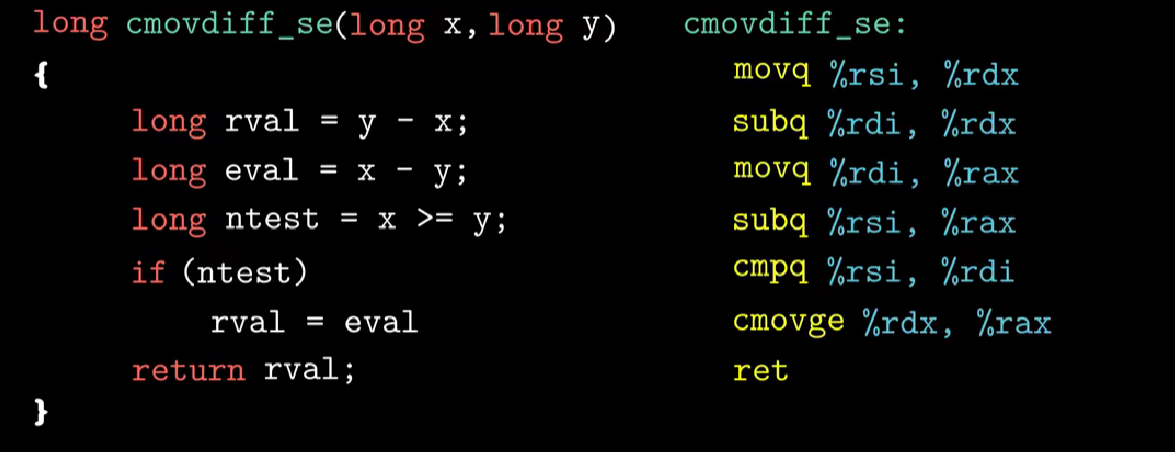
comvge表明一个值大于等于另一个值时才会把数据寄存器传送到目的
更多条件传送指令如图所示

为什么条件传送的代码比基于跳转指令的代码效率高:
现代处理器通过使用流水线来获得高性能,当遇到跳转时,处理器会根据分支预测器来猜测每条指令是否执行。当发生错误预测时,会浪费大量的时间,导致程序性能严重下降
2023/11/20:
这章还剩大概2/5的东西
但因为要复习期末了(这学期的很多学科都和以后的计算机科学内功相关所以我不想只是通过期末考试)所以先停止更新,未完待续
2024/1/3:
因为感觉期末复习就是在浪费生命,所以又回来了
10. 循环
循环的实现其实就可以简单理解为用比较指令进行比较后再用跳转指令跳转
do-while可改写为
loop:
body
t = test-expr;
if(t)
goto loop;
for 和 while都可改写成
goto test
loop :
body;
test:
t = test-expr;
if(t)
goto loop;
我们用do while循环 , while循环和for循环分别实现求n的阶乘
1. do-while循环:

2. while 和 for循环
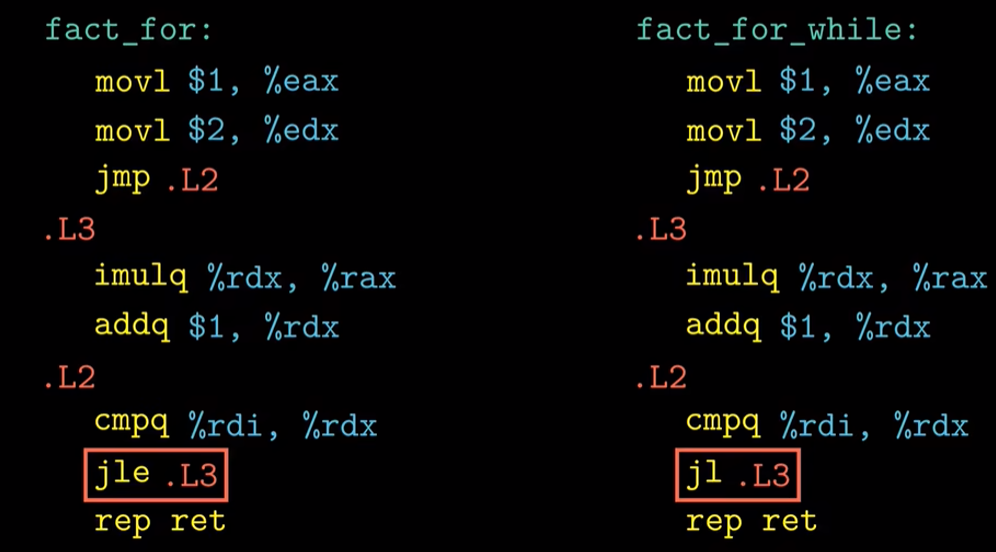
我们发现除了红圈部分,while和for的汇编是一致的。
11. switch

switch是通过跳转表来访问代码位置的
对于上述例子,跳转表如下

因为case 一直到6,所以该跳转表有七个标号
对于重复的情况,case3和case6使用相同标号
对于缺失的情况,case1和case5使用默认情况标号
我们发现,使用跳转表,即使情况很复杂也只需要一次跳转就能到达想要执行的操作。
与使用一组很长的if-else相比,使用switch更高效
12. 过程(函数调用)
过程是一种抽象,提供一种封装代码的方式同时提供清晰简洁的接口定义,如c语言中的函数,java中的方法
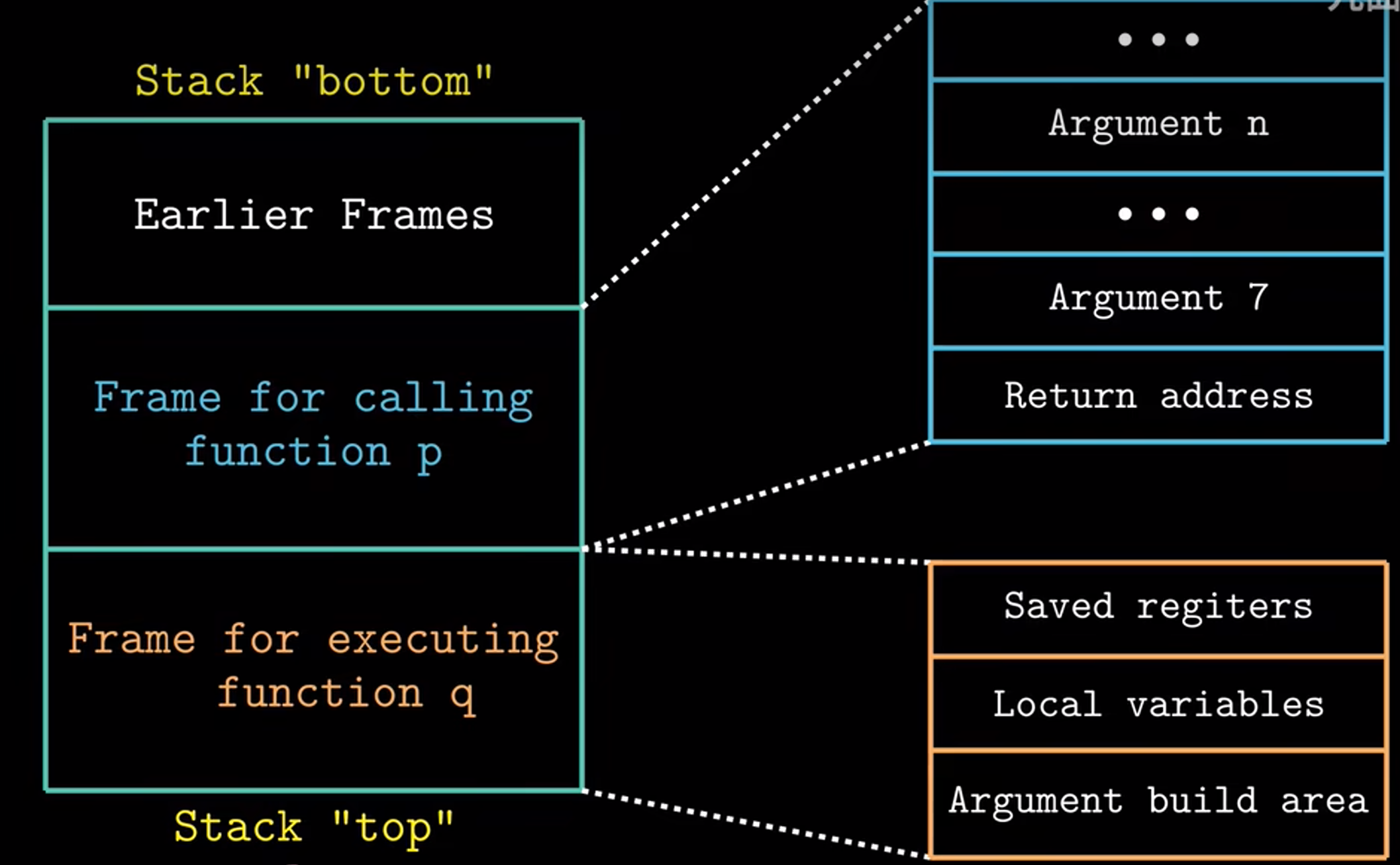
1. 栈帧
在过程p调用过程q的时候,q在执行时p是暂时被挂起的。
q运行时,需要为局部变量分配新的存储空间,当需要的存储空间超过寄存器能够存放的大小的时候,就会在栈上分配空间,这个部分就是栈帧
其实简单说就是当函数的参数超过寄存器个数时,就会分配栈帧存储多余参数。
2. 转移控制
将控制从函数p转移到函数q时的操作:
- 把程序计数器(PC)设置为Q的代码起始位置
- 从q返回时处理器必须记录好它需要继续p的执行代码的位置
例
比如在main函数中调用multstore函数
下图是main函数和multstore部分反汇编的节选
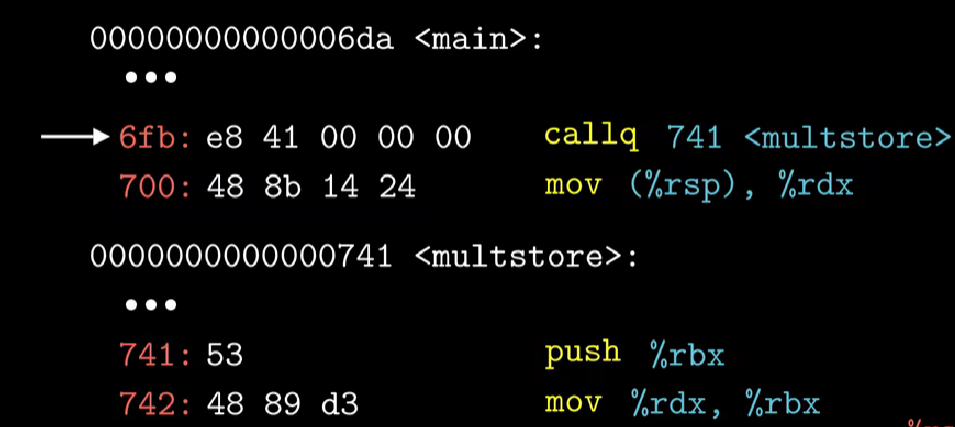
-
地址为0x6fb的call指令调用multstor函数时

-
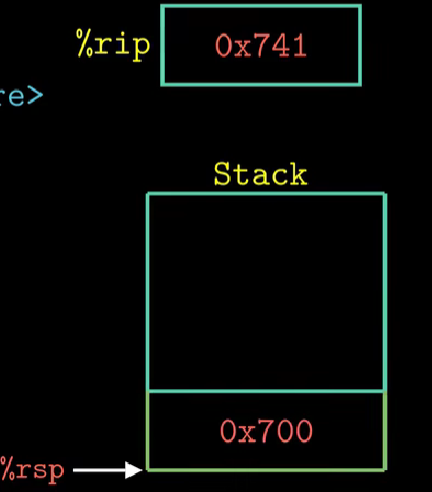
将multstore函数第一条指令的地址写入到程序指令寄存器%rip中,并将multstore函数返回地址(调用完该函数后main函数继续执行的位置)压入栈中
-
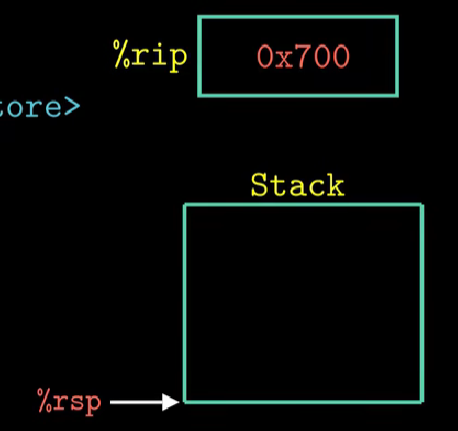
multstore函数执行完毕后,将栈中地址弹出,放入%rip中,继续执行main函数中相关操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号