Python 模块之 pyexcel_xls
一、适用场景
在很多数据统计或者数据分析的场景中,我们都会使用到excel;
在一些系统中我们也会使用excel作为数据导入和导出的方式,那么如何使用python加以辅助我们快速进行excel数据做更多复杂和精确的处理,下面通过pyexcel_xls模块进行。
二、模块概述
pyexcel-xls 以 OrderedDict 结构处理数据,将整个excel文件转化为一个OrderedDict (有序字典)结构:
每个key就是一个子表(Sheet);
每个子表(Sheet),转化为一个列表结构:很像二维数组,第一层列表为行(Row),行的下标为列(Column),对应的值为单元格的值;
编码为 unicode,如果有中文必须进行转换。
三、读excel数据(xls,xlsx)
3.1 先创建一个excle文件,readfile.xls,里面有如下数据:
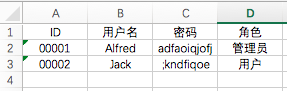
3.2 下面看如何读取这个文件:
#!/usr/bin/env python # -*- coding:utf-8 -*- ___Author___ = "Alfred Xue" ___Date_____ = "2017/11/8 上午10:08" # pyexcel_xls 以 OrderedDict 结构处理数据 from collections import OrderedDict from pyexcel_xls import save_data from pyexcel_xls import get_data def read_xls_file(): data = get_data(r"data/readfile.xls") print("数据格式:" type(data)) for sheet_n in data.keys(): print(sheet_n, ":", data[sheet_n]) if __name__ == "__main__": read_xls_file()
输出结构:
数据格式: <class 'collections.OrderedDict'> Sheet1 : [['ID', '用户名', '密码', '角色'], ['00001', 'Alfred', 'adfaoiqjofj', '管理员'], ['00002', 'Jack', ';kndfiqoe', '用户'], [], [], [], [], [], [], [], []] Process finished with exit code 0
可以看到:
整个excel文件,转化为一个OrderedDict (有序字典)结构:每个key就是一个子表(Sheet)。
每个子表(Sheet),转化为一个列表结构:很像二维数组,第一层列表为行(Row),行的下标为列(Column),对应的值为单元格的值。
编码为 unicode 简单,易用,读出数据后,非常适合做二次处理!
■ 注意,excel文件名(就是那个xls或者xlsx文件),尽量不要用中文,如果您要使用中文,请转化为unicode编码,如:
data = get_data(unicode(r"D:\试试.xlsx", "utf-8"))
四、写excel数据(xls)
#!/usr/bin/env python # -*- coding:utf-8 -*- ___Author___ = "Alfred Xue" ___Date_____ = "2017/11/9 下午3:57" # pyexcel_xls 以 OrderedDict 结构处理数据 from collections import OrderedDict from pyexcel_xls import get_data from pyexcel_xls import save_data # 写Excel数据, xls格式 def save_xls_file(): data = OrderedDict() # sheet表的数据 sheet_1 = [] row_1_data = ["ID", "序号", "等级"] # 每一行的数据 row_2_data = [4, 5, 6] # 逐条添加数据 sheet_1.append(row_1_data) sheet_1.append(row_2_data) # 添加sheet表 data.update({"Sheet1": sheet_1}) # 保存成xls文件 save_data("data/writefile.xls", data) if __name__ == '__main__': save_xls_file()
生成excel文件效果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号