SUSE Ceph RBD 基本使用 - Storage6
块存储管理系列文章
(3)使用 librbd 将虚拟机运行在 Ceph RBD
Ceph 块存储
Ceph 块设备允许共享物理资源,并且可以调整大小。它们会在 Ceph 集群中的多个 OSD 上等量存储数据。Ceph 块设备会利用 RADOS 功能,例如创建快照、复制和一致性。Ceph 的 RADOS块设备 (RBD) 使用内核模块或 librbd 库与 OSD 交互。

Ceph 的块设备为内核模块提供高性能及无限的可扩展性。它们支持虚拟化解决方案(例如QEMU)或依赖于 libvirt 的基于云的计算系统(例如 OpenStack)。您可以使用同一个集群来同时操作对象网关、CephFS 和 RADOS 块设备。
创建RBD
(1) 客户端安装rbd包
# zypper se ceph-common # zypper in ceph-common
(2)显示帮助信息
# rbd help <command> <subcommand>
# rbd help snap list
(3) 复制配置文件和key
# scp admin:/etc/ceph/ceph.conf . # scp admin:/etc/ceph/ceph.client.admin.keyring .
(4)创建块设备
# ceph osd pool create rbd 128 128 replicated # rbd create test001 --size 1024 --pool rbd # rbd ls test001
(5)映射块设备
# rbd map test001
/dev/rbd0
(6)查看已映射设备
# rbd showmapped id pool image snap device 0 rbd test001 - /dev/rbd0
(7)格式化块设备,并且挂载
# mkfs.xfs -q /dev/rbd0 # mkdir /mnt/ceph-test001 # mount /dev/rbd/rbd/test001 /mnt/ceph-test001/
注意:rbd的指令如果省略-p / --pool参数,则会默认-p rbd,而这个rbd pool是默认生成的。
- 检查挂载情况
# df -Th
Filesystem Type Size Used Avail Use% Mounted on /dev/rbd0 xfs 1014M 33M 982M 4% /mnt/ceph-test001
- 检查rbd镜像的信息
# rbd --image test001 info rbd image 'test001': size 1 GiB in 256 objects order 22 (4 MiB objects) snapshot_count: 0 id: 408ea3f9d1c3b block_name_prefix: rbd_data.408ea3f9d1c3b format: 2 features: layering op_features: flags: create_timestamp: Mon Sep 23 15:47:00 2019 access_timestamp: Mon Sep 23 15:47:00 2019 modify_timestamp: Mon Sep 23 15:47:00 2019
size: 就是这个块的大小,即1024MB=1G,1024MB/256 = 4M,共分成了256个对象(object),每个对象4M- order 22, 22是个编号,4M是22, 8M是23,也就是2^22 bytes = 4MB, 2^23 bytes = 8MB。
- block_name_prefix: 这个是块的最重要的属性了,这是每个块在ceph中的唯一前缀编号,有了这个前缀,把服务器上的OSD都拔下来带回家,就能复活所有的VM了。
- format : 格式有两种,1和2
(8) 设置自动挂载
# vim /etc/ceph/rbdmap rbd/test001 id=admin,keyring=/etc/ceph/ceph.client.admin.keyring # systemctl start rbdmap.service # systemctl enable rbdmap.service # systemctl status rbdmap.service
# vim /etc/fstab /dev/rbd/rbd/test001 /mnt/ceph-test001 xfs defaults,noatime,_netdev 0 0 # mount -a
RBD 扩容 缩容
(1)查看rbd0 原有大小为1024M
# df -Th Filesystem Type Size Used Avail Use% Mounted on /dev/rbd0 xfs 1014M 33M 982M 4% /mnt/ceph-test001
# rbd --image test001 info
rbd image 'test001':
size 1 GiB in 256 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 408ea3f9d1c3b
block_name_prefix: rbd_data.408ea3f9d1c3b
format: 2
features: layering
op_features:
flags:
(2)在线扩容
# rbd resize rbd/test001 --size 4096 Resizing image: 100% complete...done.
# rbd --image test001 info rbd image 'test001': size 4 GiB in 1024 objects order 22 (4 MiB objects) snapshot_count: 0 id: 408ea3f9d1c3b block_name_prefix: rbd_data.408ea3f9d1c3b format: 2 features: layering op_features: flags: create_timestamp: Mon Sep 23 15:47:00 2019 access_timestamp: Mon Sep 23 15:47:00 2019 modify_timestamp: Mon Sep 23 15:47:00 2019
(3)文件系统扩容
# xfs_growfs /mnt/ceph-test001/ # df -Th Filesystem Type Size Used Avail Use% Mounted on /dev/rbd0 xfs 4.0G 34M 4.0G 1% /mnt/ceph-test001
(4)在线缩小(XFS文件系统不支持缩小)
# rbd -p rbd resize test001 --size 1024 --allow-shrink
RBD 快照和回滚
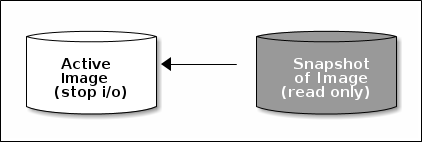
- 快照: 某块设备在一个特定时间点的一份只读副本,可以通过创建和恢复快照来保持RBD镜像的状体已经从快照恢复原始数据。
- 快照是在集群中操作,并不知道客户端是否有额外的数据,当有很重的IO时,会有dirt脏数据没有刷到磁盘上去,快照是无法保持这部分数据。
- Ceph 支持快照分层,这可让您轻松快速地克隆 VM 映像。
- Ceph 使用 rbd 命令和许多高级接口(包括QEMU、 libvirt 、OpenStack 和 CloudStack)支持块设备快照。
- 注意:做快照前,请先客户端停止IO并同步块数据。
1) 在block设备上创建文件
# echo "Ceph This is snapshot test" > /mnt/ceph-test001/snapshot_test_file # cat /mnt/ceph-test001/snapshot_test_file Ceph This is snapshot test
2) 创建快照
语法:rbd snap create <pool-name>/<image-name>@<snap-name>
# rbd snap create rbd/test001@test001_snap
3) 显示创建的快照
# rbd snap ls rbd/test001 SNAPID NAME SIZE TIMESTAMP 4 test001_snap 1GiB Mon Feb 11 11:12:40 2019
4) 删除文件
# rm -rf /mnt/ceph-test001/snapshot_test_file
5) 通过快照恢复
语法:rbd snap rollback <pool-name>/<image-name>@<snap-name>
# rbd snap rollback rbd/test001@test001_snap # umount /mnt/ceph-test001 # mount –a # ll /mnt/ceph-test001/ total 4 -rw-r--r-- 1 root root 33 Jul 16 09:19 snapshot_test_file
6) 清除快照,表示所有的快照都删除
语法:rbd --pool {pool-name} snap purge {image-name}
rbd snap purge {pool-name}/{image-name}
# rbd snap purge rbd/test001
7) 删除快照,表示只删除指定的快照
语法:rbd snap rm <pool-name>/<image-name>@<snap-name>
# rbd snap rm rbd/test001@test001_snap # rbd snap ls rbd/test001 # 再次显示快照已经没有了
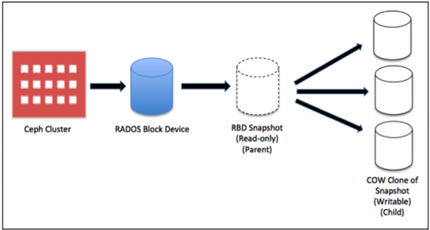
快照分层 / RBD克隆
- 分层:支持创建某一设备快照的很多写时复制( COW)克隆。分层快照使得ceph块设备客户端可以很快地创建映射,分层特性允许客户端创建多个Ceph RBD克隆实例。
- 快照是只读的,但COW克隆是完全可写的
(1)Clone必须rbd的image是类型 II
# rbd info test001 rbd image 'test001': size 4 GiB in 1024 objects order 22 (4 MiB objects) snapshot_count: 0 id: 408ea3f9d1c3b block_name_prefix: rbd_data.408ea3f9d1c3b format: 2 features: layering op_features: flags: create_tim
(2)SUSE默认是类型II,如不是,创建时添加 --image-format 2参数
# rbd create test001 --size 1024 --image-format 2 # rbd create test002 --size 1024 --image-format 1 # rbd info test002 rbd image 'test002': size 1024 MB in 256 objects order 22 (4096 kB objects) block_name_prefix: rb.0.b3dd.74b0dc51 format: 1
(3)创建COW克隆,首先要保护这个快照
克隆会访问父快照。如果用户意外删除了父快照,则所有克隆都会损坏。为了防止数据丢失,您需要先保护快照,然后才能克隆它。
# rbd snap create rbd/test001@test001_snap # 创建快照
# rbd snap protect rbd/test001@test001_snap # 保护
# rbd -p rbd ls -l NAME SIZE PARENT FMT PROT LOCK test001 4 GiB 2 test001@test001_snap 4 GiB 2 yes <=== protect test002 4 GiB 2
(4)快照克隆
语法:rbd clone {pool-name}/{parent-image}@{snap-name} {pool-name}/{child-image-name}
# rbd clone rbd/test001@test001_snap rbd/test001_snap_clone
注意:可以将快照从一个存储池克隆到另一个存储池中的映像。例如,可以在一个存储池中将只读映像和快照作为模板维护,而在另一个存储池中维护可写入克隆
# ceph osd pool create rbd_clone 128 128 replicated # rbd clone rbd/test001@test001_snap rbd_clone/test001_snap_rbd_clone
(5) 检查新镜像信息
# rbd ls
test001
test001_snap_clone
test002
# rbd ls -p rbd_clone test001_snap_rbd_clone
# rbd info rbd/test001_snap_clone rbd image 'test001_snap_clone': size 4 GiB in 1024 objects order 22 (4 MiB objects) snapshot_count: 0 id: 4153d12df2e2e block_name_prefix: rbd_data.4153d12df2e2e format: 2 features: layering op_features: flags: create_timestamp: Mon Sep 23 20:23:01 2019 access_timestamp: Mon Sep 23 20:23:01 2019 modify_timestamp: Mon Sep 23 20:23:01 2019 parent: rbd/test001@test001_snap overlap: 4 GiB
- 显示children of snapshot
# rbd children rbd/test001@test001_snap rbd/test001_snap_clone rbd_clone/test001_snap_rbd_clone
(6)平展克隆的映像
不在使用父镜像快照,所谓的完整克隆而不是之前的链接克隆,提高性能。
语法:# rbd --pool pool-name flatten --image image-name
# rbd flatten rbd/test001_snap_clone Image flatten: 100% complete...done.
# rbd flatten rbd_clone/test001_snap_rbd_clone
- 会发现父镜像/快照的名字不存在了,并且克隆是独立的
# rbd info rbd/test001_snap_clone rbd image 'test001_snap_clone': size 4 GiB in 1024 objects order 22 (4 MiB objects) snapshot_count: 0 id: 4153d12df2e2e block_name_prefix: rbd_data.4153d12df2e2e format: 2 features: layering op_features: flags: create_timestamp: Mon Sep 23 20:23:01 2019 access_timestamp: Mon Sep 23 20:23:01 2019 modify_timestamp: Mon Sep 23 20:23:01 2019
(7)取消保护快照
# rbd info rbd/test001@test001_snap
rbd image 'test001': size 4 GiB in 1024 objects order 22 (4 MiB objects) snapshot_count: 1 ....... protected: True
# rbd snap unprotect rbd/test001@test001_snap # 取消保护的
# rbd info rbd/test001@test001_snap
rbd image 'test001':
size 4 GiB in 1024 objects
order 22 (4 MiB objects)
......
protected: False
迁移RBD
(1)导出 RBD 镜像
语法:rbd export [image-name] [dest-path]
# rbd export test001 /tmp/test001_rbd_image
Exporting image: 100% complete...done
(2)导入 RBD 镜像
语法:# rbd import [path] [dest-image]
# rbd import /tmp/test001_rbd_image test002
Importing image: 100% complete...done.
# rbd ls
test001
test002
# rbd info test002
rbd image 'test002':
size 4 GiB in 1024 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 40b02f91b3a9d
block_name_prefix: rbd_data.40b02f91b3a9d
format: 2
features: layering
op_features:
flags:
如何确认 RBD 镜像被那个客户端使用?
(1)通过 rbd status 命令确认镜像被那个客户端所使用
# rbd -p rbd ls test001 test002
# rbd status rbd/test001 Watchers: watcher=192.168.2.39:0/3075193743 client.264380 cookie=18446462598732840961
可以看到该镜像或者instance属于192.168.2.39 IP地址
- 查看镜像信息
# rbd info test001 rbd image 'test001': size 4 GiB in 1024 objects order 22 (4 MiB objects) snapshot_count: 0 id: 408ea3f9d1c3b block_name_prefix: rbd_data.408ea3f9d1c3b format: 2 features: layering
- 通过头部信息查找
# rados -p rbd listwatchers rbd_header.408ea3f9d1c3b watcher=192.168.2.39:0/3075193743 client.264380 cookie=18446462598732840961
- 脚本通过遍历池信息查找
# for each in `rados -p rbd ls | grep rbd_header`; do echo $each: && rados -p \
rbd listwatchers $each && echo -e '\n';done
rbd_header.408ea3f9d1c3b: watcher=192.168.2.39:0/3075193743 client.264380 cookie=18446462598732840961
删除 RBD
1) 注释映射信息
# vim /etc/ceph/rbdmap rbd/test001 id=admin,keyring=/etc/ceph/ceph.client.admin.keyring
2) 注释下面挂载信息
# vim /etc/fstab /dev/rbd/rbd/test001 /mnt/ceph-test001 xfs defaults,noatime,_netdev 0 0
3) 显示映射关系
# rbd showmapped id pool image snap device 0 rbd test001 - /dev/rbd0
4) 卸载映射关系,删除test001块设备
# rbd unmap /dev/rbd0 # rbd rm rbd/test001


