深入理解 DeepSea 和 Salt 部署工具 - Storage6
学习 SUSE Storage 系列文章
(1)SUSE Storage6 实验环境搭建详细步骤 - Win10 + VMware WorkStation
(2)SUSE Linux Enterprise 15 SP1 系统安装
(4)SUSE Ceph 增加节点、减少节点、 删除OSD磁盘等操作 - Storage6
(5)深入理解 DeepSea 和 Salt 部署工具 - Storage6
首先我们通过前几篇文章,已经搭建了一套完整的Ceph集群,对使用salt工具自动化搭建集群有所了解,下面我们就对部署方式进行详解
SUSE Enterprise Storage 部署方式
storage4 采用的方式:
- ceph-deploy 工具,标准的ceph脚本部署,适用于中小型存储集群
- crowbar工具,部署SUSE Openstack的标准工具
storage5/6 采用方式:
- DeepSea (Salt),轻量级,敏捷性,灵活性,弹性部署
过去我们的部署方式采用社区的方式ceph-deploy或 crowbar 工具搭建,这2种工具部署都有一定局限性,不适合大型存储集群部署,敏捷性、灵活性太差。因此从2018年开始,SUSE Enterprise Storage 5 弃用 ceph-deploy / crowbar 群集部署工具 ,推出DeepSea方式进行部署,该方式更加轻量级,高速互通,敏捷性,灵活性,适用于各种场景部署集群系统,也是Ceph产品部署方式的趋势。
一、DeepSea 简介
DeepSea 旨在节省管理员的时间,让他们自信地对 Ceph 群集执行复杂操作。Ceph 是一款高度可配置的软件解决方案。它提高了系统管理员的自由度和职责履行能力。最低的 Ceph 设置能够很好地满足演示目的,但无法展示 Ceph 在处理大量节点时可体现的卓越功能。DeepSea 会收集并储存有关单台服务器的相关数据,例如地址和设备名称。对于诸如 Ceph 的分布式储存系统,可能需要收集并储存数百个这样的项目。收集信息并手动将数据输入到配置管理工具的过程非常耗费精力,并且容易出错。准备服务器、收集配置信息以及配置和部署 Ceph 所需执行的步骤大致相同。但是,这种做法无法解决管理独立功能的需求。在日常操作中,必须做到不厌其烦地将硬件添加到给定的功能,以及从容地去除硬件。DeepSea 通过以下策略解决了这些需求:DeepSea 可将管理员的多项决策合并到单个文件中。这些决策包括群集指派、角色指派和配置文件指派。此外,DeepSea 会收集各组任务以组成一个简单的目标。每个目标就是一个阶段:
关于DeepSea官方资料:
GitHub 链接: https://github.com/SUSE/DeepSea/wiki
二、SaltStack 简介

SaltStack 是一个服务器基础架构集中化管理平台,具备配置管理、远程执行、监控等功能,一般可以理解为简化版的puppet和加强版的func。SaltStack 基于Python语言实现,结合轻量级消息队列(ZeroMQ)与Python第三方模块(Pyzmq、PyCrypto、Pyjinjia2、 python-msgpack和PyYAML等)构建。
通过部署SaltStack环境,我们可以在成千上万台服务器上做到批量执行命令,根据不同业务特性进行配置集中化管理、分发文件、采集服务器数据、操作系统基础及软件包管理等,SaltStack是运维人员提高工作效率、规范业务配置与操作的利器。
特性:
(1)部署简单、方便;
(2)支持大部分UNIX/Linux及Windows环境;
(3)主从集中化管理;
(4)配置简单、功能强大、扩展性强;
(5)主控端(master)和被控端(minion)基于证书认证,安全可靠;
(6)支持API及自定义模块,可通过Python轻松扩展。
SaltStack: Pillar 和 Grains 详解
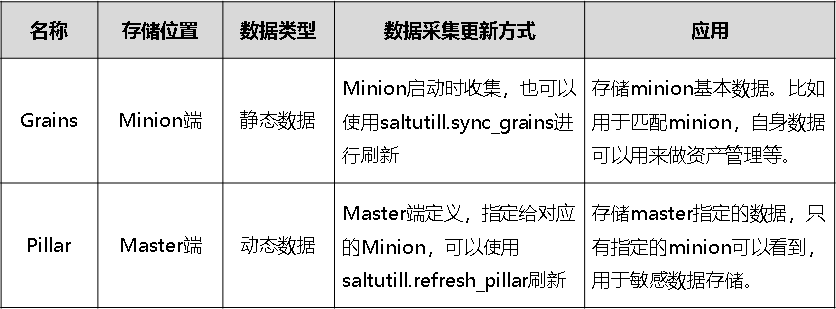
SatlStack 远程执行
1、远程执行
- 目标 (Targeting)
- 模块 (Module)
- 返回 (return)
2、目标
(1)和Minion ID 有关,需要使用Minion ID
- 通配符
- 正则表达式
- 列表
通配符方式:
# salt 'node00[1-3]'.example.com cmd.run 'w' node002.example.com: 13:06:12 up 4:05, 0 users, load average: 0.28, 0.09, 0.02 USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT node001.example.com: 13:06:12 up 4:05, 0 users, load average: 0.23, 0.13, 0.05 USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT node003.example.com: 13:06:12 up 4:05, 0 users, load average: 0.24, 0.09, 0.02 USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
正则表达式
# salt -E 'node(001|002).example.com' test.ping node002.example.com: True node001.example.com: True
(2)和Minion ID 无关,不涉及到Minion ID
- 子网 / IP 地址
- Grains
- Pillar
- Compound matchers (复合匹配)
- Node groups (节点组)
- Batching execution (批处理执行)
Grains 方式,OS是SUSE
# salt -G 'os:SUSE' test.ping node001.example.com: True node002.example.com: True node003.example.com: True node004.example.com: True admin.example.com: True
获取 Pillar ,然后指定pillar方式
# salt 'admin*' pillar.items admin.example.com: ---------- available_roles: - storage - admin - mon - mds - mgr
.....
roles:
- master
- admin
- prometheus
- grafana
time_server:
admin.example.com
# salt -I 'roles:grafana' test.ping
admin.example.com:
True
3、模块详解
1000+ 的模块,目前在不断增加中 , saltstack模块链接
admin:~ # salt 'node001*' network.arp node001.example.com: ---------- 00:0c:29:33:70:2d: 192.168.2.42 00:0c:29:33:70:37: 192.168.3.42 00:0c:29:ae:44:51: 172.200.50.39 00:0c:29:ae:44:5b: 192.168.2.39 00:0c:29:d3:ba:15: 192.168.2.41 00:0c:29:d3:ba:1f: 192.168.3.41 00:0c:29:e0:5c:8c: 192.168.2.43 00:0c:29:e0:5c:96: 192.168.3.43
admin:~ # salt 'node001*' network.interface eth1 node001.example.com: |_ ---------- address: 192.168.2.40 broadcast: 192.168.2.255 label: eth1 netmask: 255.255.255.0
三、配置和自定义
policy.cfg 文件
/srv/pillar/ceph/proposals/policy.cfg 配置文件用于确定单个群集节点的角色。例如,哪个节点充当 OSD,或哪个节点充当监视器节点。请编辑 policy.cfg ,以反映所需的群集设置。段落采用任意顺序,但所包含行的内容将重写前面行的内容中匹配的密钥。
1、policy.cfg 的模板
- 可以在 /usr/share/doc/packages/deepsea/examples/ 目录中找到完整策略文件的多个示例。
- 一般我们选择基于角色定义的模板
# ll /usr/share/doc/packages/deepsea/examples/ total 12 -rw-r--r-- 1 root root 329 Aug 9 16:00 policy.cfg-generic -rw-r--r-- 1 root root 489 Aug 9 16:00 policy.cfg-regex -rw-r--r-- 1 root root 577 Aug 9 16:00 policy.cfg-rolebased
2、群集指派
要包含所有受控端,请添加以下几行:
cluster-ceph/cluster/*.sls
要将特定的受控端加入白名单,请运行以下命令:
cluster-ceph/cluster/abc.domain.sls
要将一组受控端加入白名单,可以使用通配符:
cluster-ceph/cluster/mon*.sls
要将受控端加入黑名单,可将其设置为 unassigned :
cluster-unassigned/cluster/client*.sls
3、policy.cfg 示例
下面是一个基本 policy.cfg 文件的示例:
1 vim /srv/pillar/ceph/proposals/policy.cfg 2 3 ## Cluster Assignment 4 cluster-ceph/cluster/*.sls 5 6 ## Roles 7 # ADMIN 8 role-master/cluster/admin*.sls 9 role-admin/cluster/admin*.sls 10 11 # Monitoring 12 role-prometheus/cluster/admin*.sls 13 role-grafana/cluster/admin*.sls 14 15 # MON 16 role-mon/cluster/node00[1-3]*.sls 17 18 # MGR (mgrs are usually colocated with mons) 19 role-mgr/cluster/node00[1-3]*.sls 20 21 # COMMON 22 config/stack/default/global.yml 23 config/stack/default/ceph/cluster.yml 24 25 # Storage 26 role-storage/cluster/node00*.sls 27 28 # MDS 29 role-mds/cluster/node001*.sls 30 31 # IGW 32 role-igw/stack/default/ceph/minions/node002*.yml 33 role-igw/cluster/node002*.sls 34 35 # RGW 36 role-rgw/cluster/node00[3-4]*.sls
(1)第3-4行:
- 指示在 Ceph 群集中包含所有受控端。如果您不想在 Ceph 群集中包含某些受控端,请使用:
cluster-unassigned/cluster/*.sls cluster-ceph/cluster/node00*.sls
- 将所有受控端标记为未指派。
- 覆盖与“node00*.sls”匹配的受控端,并将其指派到 Ceph 群集。
(2)第7-9行
- 指定主机名为admin的主机节点具有"master" 和 “admin” 角色
(3)第11-13行
- 指定要部署 Dashboard 可视化界面的节点
(4)第15-16行
- 将受控节点 node001 node002 node003 设置为MON 节点
(5)第18-19
- 将受控节点 node001 node002 node003 设置为 MGR 节点 ,该设置必须跟随 MON 设置一样
(6)第21-23行
- 表示接受 fsid 和 public_network 等通用配置参数的默认值
(7)第25-36行
- 受控端 “node00*” 将具有 storage IGW RGW MDS 角色
四、DeepSea 部署方式
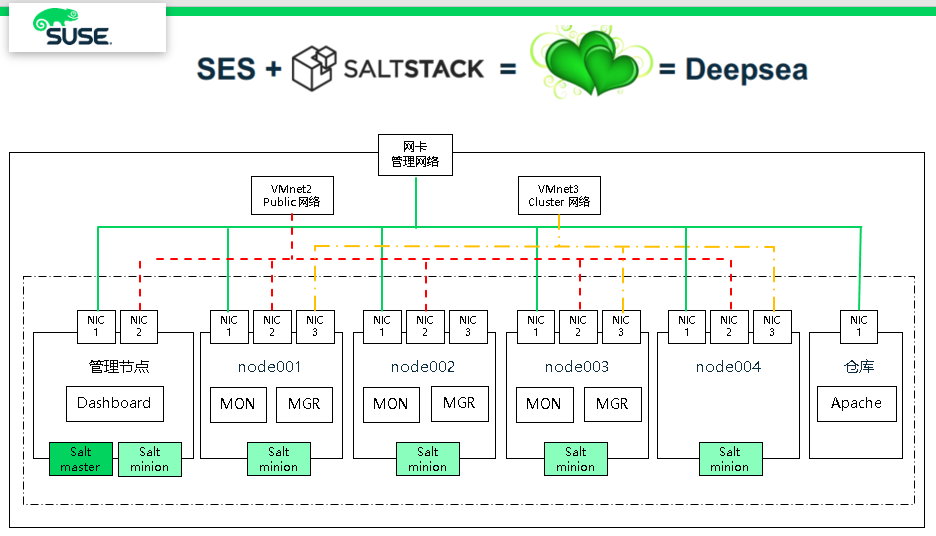
通过架构图,我们可以清楚的了解到,安装 Storage6 时只要管理节点安装 satl-master 和 salt-minion,其他OSD节点安装 salt-minion,并且所有的 minion 都指向salt-master IP地址或主机名(推荐使用public网段地址),然后执行deepsea 的4个阶段命令 “salt-run state.orch ceph.stage.X” 就可以轻松的搭建完成。
DeepSea阶段说明
阶段 0 — 准备:在此阶段,将应用全部所需的更新,并且可能会重引导您的系统。
阶段 1 — 发现:在此阶段,通过Salt在客户端安装的salt minion, 将检测群集中的所有硬件, 并收集 Ceph 配置所需的信息。
阶段 2 — 配置:您需要以特定的格式准备配置数据。(定义 salt 的pillar)
阶段 3 — 部署:创建包含必要 Ceph 服务的基本 Ceph 群集。有关必要服务的列表
阶段 4 — 服务:可在此阶段安装 Ceph 的其他功能,例如 iSCSI、RADOS 网关和CephFS。其中每个功能都是可选的。
阶段 5 — 去除阶段:此阶段不是必需的,在初始设置期间,通常不需要此阶段。在此阶段,将会去除受控端的角色以及群集配置。如果您需要从群集中去除某个储存节点,则需要运行此阶段.
DeepSea CLI
DeepSea 还提供了一个 CLI 工具,供用户监视或运行阶段,同时实时将执行进度可视化。支持使用以下两种模式来可视化阶段的执行进度:
- 监视模式:可视化另一个终端会话中发出的 salt-run 命令所触发 DeepSea 阶段的执行进度。
- 独立模式:运行 DeepSea 阶段,并在该阶段的构成步骤执行时提供相应的实时可视化效果。
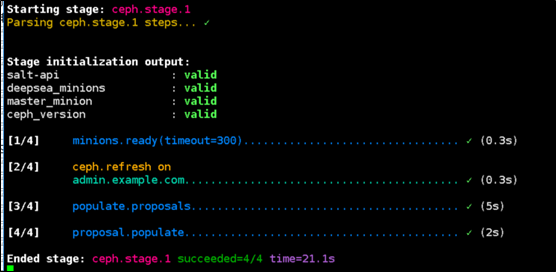
监控模式 Monitor Mode
该程序监控提供一个详细的,实时的可视化操作行为,当在执行运行salt-run state.orch时,监控执行期间运行了什么
# deepsea monitor
独立模式 Stand-alone Mode
# deepsea stage run stage-name # salt-run state.orch ceph.stage.0 # deepsea stage run ceph.stage.0
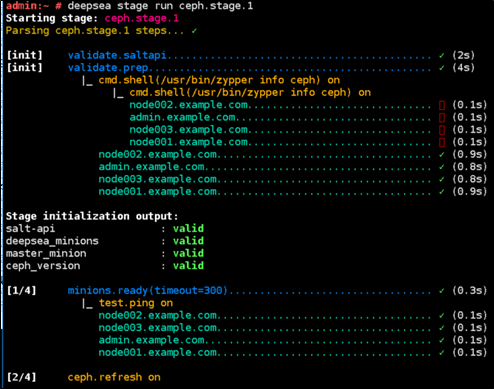
Deepsea帮助信息
# man deepsea-monitor NAME deepsea-monitor - Starts the DeepSea stage execution progress monitor. # man deepsea-stage run


 浙公网安备 33010602011771号
浙公网安备 33010602011771号