-
-
变量,数组,对象,集合
缺点:不能长久保存数据
-
文件,通过io读写
长久保存数据
缺点:无法控制并发,效率低
-
数据库解决上述问题
存储大量数据,长久保存,支持并发,数据安全,访问简单
-
-
数据库的分类:
-
关系型数据库:Oracle|DB2|MySql|SqlSever...
-
对象型数据库 : Object Database
-
非关系型数据库 :Redis|mongDB
-
-
数据库存储数据的结构

-
二.Oracle数据的安装
计算名配置:C:\oraclexe\app\oracle\product\10.2.0\server\NETWORK\ADMIN
OracleServiceXE:Oracle数据库的核心服务
OracleXETNSListener:Oracle数据库的对外服务
-
使用数据库
-
sqlplus--基于Dos界面
-
i-sqlplus--基于浏览器
-
PLSql--第三方工具
-
三.Oracle数据库的相关概念
-
Oracle数据库:关系型数据库管理系统---RDBMS
-
数据库:存储和管理数据(database)--DB
-
用户:hr
-
表:table,真正存储和管理数据
-
行: row,代表数据库的一条数据,对象(Object),实体(entity),记录(record)
-
列:column,代表所有数据的一个属性,单元格(一个对象的一个属性),字段(Field),键(Key)
-
主键:primary key,一行数据的唯一标识
-
外键:foreign Key,多张表之间的联系
-
简单查询
--查询表内所有信息 --单行注释 /*多行注释*/ select * from Employees; /*常见错误 表或视图不存在:表明写错了 未找到要求的 FROM 关键字,无效的Sql语句:查询结构不完整 */ /* *不建议使用 *先匹配成每一列的名字,然后再查询 *会找出无用数据,降低想查询效率 *可读性差 */ --开发使用,查询所有列名称 select Employee_id,First_name,Last_name,Email,phone_number,hire_date,job_id,salary,commission_pct, manager_id,department_id from Employees;
-
-
--查询部分列信息 --查询工号,名字,工资信息 select employee_id,first_name,salary from employees;--对列数据进行运算 + - * / --查询所有员工年薪 select employee_id,first_name,salary*12 from employees;--给列起别名 [as] 列别名 --查询所有员工年薪 select employee_id as 工号,first_name 名字,salary*12 as 年薪 from employees; 注:如果列别名使用关键字或者中间存在空格,别名需要使用"列别名
2.排序 order by
--基本语法
select ... from 表名 order by 排序条件
--按照工资降序查询员工信息
select * from employees order by salary desc;
注:asc升序排序(默认)desc降序排序
--按照工资升序查询员工信息,工资相同按照入职时间排序
select * from employees order by salary ,hire_date;
注:如果 order by 后有两个字段,表示如果按照第一个字段排序完成后,第一个字段相同的情况下,按照第二个字段排序
-
条件查询
-
select...from...where...
原理:先将基表加入缓存,然后使用基表的每一条数据与过滤做运算,满足显示,不满足删除 -
比较查询 > < >= <= != =
--查询工号105的员工信息
select * from employees where employee_id=105; -
多条件查询 and or
--查询部门编号为80且工资大于12000的员工信息
select * from employees where department_id=80 and salary>12000;
--查询部门编号为60,80,90的员工信息
select * from employees where department_id=60 or department_id=80 or department_id=90; -
空值判断 is [not] null
--查询部门经理为空的员工信息
select * from employees where manager_id is null;
--提成不为空的员工信息
select * from employees where commission_pct is not null; -
区间处理 [not]between and
--查询工资大于8000小于10000的员工信息
select * from employees where salary>=8000 and salary<=10000;
select * from employees where salary between 8000 and 10000;
注:小值在前,大值在后 -
枚举查询[not]in
--查询部门编号为60,80,90的员工信息
select * from employees where department_id=60 or department_id=80 or department_id=90;
select * from employees where department_id in(80,60,90);
注:判断的数据为非null值 -
模糊查询 [not]like
--查询姓氏以“K”的员工信息
select * from employees where last_name like 'K%';
--%:表示任意字符0--n
select * from employees where last_name like '____y';
--_:表示单个字符
注:字符串常量严格区分大小写 -
分支查询 case when then else end
--显示数据工资大于10000为高收入,工资>6000为中等收入,工资<=6000低收入
select employee_id,first_name,salary,
case
when salary>10000 then '高收入'
when salary>6000 then '中等水平'
else '低收入'
end as 收入水平
from employees
-
五.函数
-
单行函数
在单行函数的作用下每一个数据返回一个数据,表中有107行数据,单行函数运行完毕,返回107行数据
-
常用的单行数据 mod() length()
--显示员工工资以千单位
select employee_id,first_name,salary,mod(salary/1000,1000) from employees;
select mod(15,4) from dual;
--dual:哑表,虚表,没有意义,为了保证Sql语句的完整性
--查询所有员工名字的长度
select first_name,length(first_name) from employees;
select length('hjxdfhjsadgfhhjgsdfghjsgdhjf') from dual; -
sysdate:获取当前系统时间
select sysdate from dual -
to_char(时间,时间格式)
--作用:指定时间格式,获取时间的部分数据
时间字符串格式:
yyyy:年
mm:月
dd:日
hh24:24小时制显示时
mi:分
ss:秒
day:星期几
--展示员工入职月份
select employee_id,first_name,hire_date,to_char(hire_date,'mm') from employees 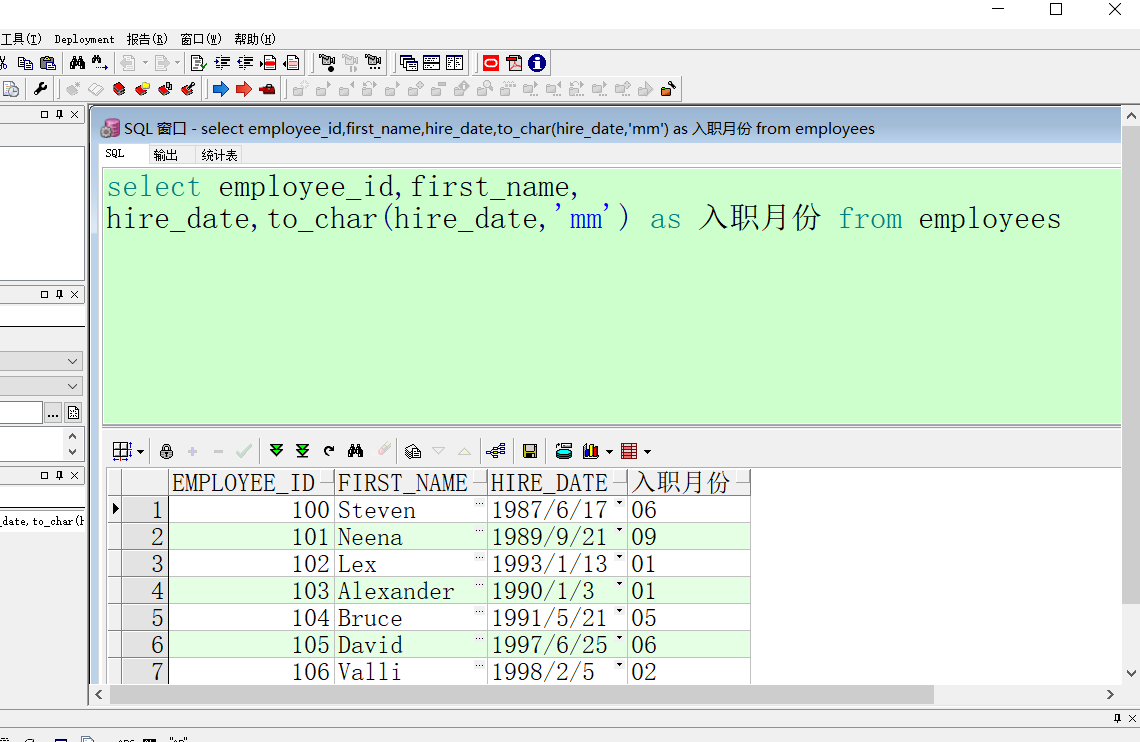
-
to_date(时间字符串,时间格式)
--作用:将给定的日期转为指定格式的日期类型,进行运算(默认以天为单位进行运算的),默认显示效果(dd-mm月-yy)
--显示2028-8-6是周几
--to_date('2028-8-6','yyyy-mm-dd'):将日期字符串转为日期类型
--to_char(to_date('2028-8-6','yyyy-mm-dd'),'day'):获取当前时间的是周几的部分
select to_char(to_date('2028-8-6','yyyy-mm-dd'),'day') from dual;
-
-
组函数
组函数:作用于提前分好的组数据,有一组数据执行一次函数,有几组返回几组数据
-
sum avg max min
--(列名):统计当列的数据之和
--统计员工工资之和
select sum(salary) from employees;
--avg(列名):平均值
--统计员工平均工资
select avg(salary) from employees;
--max(列名):最大值
--统计员工最高工资
select max(salary) from employees;
--min(列名):最小值
--统计员工最低工资
select min(salary) from employees; -
count计数
--count(列名):统计列的数据条数
--对该列的非null值计数
--统计有部门的员工人数
select count(department_id) from employees;
--统计有提成的员工人数
select count(commission_pct) from employees;
-
六.分组
-
107条数据根据一定条件分为若干个组,进行组内统计(组函数)
-
基本语法
select...from...group by...--查询每个部门多少人
select department_id,count(*) from employees group by department_id;
--第一步:先进行分组
--第二步: 统计人数 -
注:
-
只有出现在group by 后面的列名,才能查询
-
没有出现在group by后面的列,查询时必须配合组函数
-
select 使用的函数必须是出现在group by后面的函数
- case when 条件bai1 then 结果1 when 条件2 then 结果du2 .......... else 结果n end
就是zhi满足条件1时,输出dao结果1,满足条件2时输出结果2,
如果条件都不满足,输出结果n
--分组统计数据工资大于10000为高收入,工资>6000为中等收入,工资<=6000低收入的人数
select
count(*),
case
when salary>10000 then '高收入'
when salary>6000 then '中等收入'
else '低收入'
end 收入水平
from employees
group by
case
when salary>10000 then '高收入'
when salary>6000 then '中等收入'
else '低收入'
end -
-
having 语句
作用:对分组后的结果进行过滤
--统计1996年每月入职员工人数大于1的月份
select to_char(hire_date,'mm'),count(*)
from employees
where to_char(hire_date,'yyyy')=1996--完成1996的筛选
group by to_char(hire_date,'mm')--完成分组
having count(*)>1--完成入职人数>1的筛选
--where count(*)>1--完成入职人数>1的筛选 error!-
having 和where区别
-
where对原始表中数据进行过滤
-
having对分组后的数据进行过滤
-
在sql语句中既可以使用where 又可以使用having,首选where ,where 效率高
-
注:组函数不能用在where字句中
-
-
七.小结
-
书写顺序:
select...
from...
where...
group by...
having...
order by... -
运行顺序
from:确定查询原始表
where:对原始数据进行过滤
group by:对留下的数据进行分组
having:对分组数据进行过滤操作
select:对留下的数据进行相关查询及运算
order by:对运算后数据进行排序
一.伪列
-
rowid
-
表中数据一行的唯一标识,根据表中数据的物理地址计算得来。应用:索引
-
-
rownum(相当于excle的计数列,第一行,第二行....)
-
自动对查询结果做一个编号,符合条件的数据计数,第一条,第二条...
--查询表内前5名员工
select * from Employees where rownum<=5;
--查询表内6--10的员工信息
select * from employees where rownum>5 and rownum<11;-- error rownum>5
select * from employees where rownum>=1;--true
select * from employees where rownum>=10;-- error rownum>=10
注:romnum只能进行< <= >=1,不能进行>n,>=n
--查询表内所有数据和伪劣
select *,rownum from employees;--error ,*号只允许存在一列
select rownum,employees.* from employees;--使用表名.*是所有数据和其他数据共存
select rownum,e.* from employees e;--简化表名的写法,给表起别名
注:给表起别名不能使用 as -
二.子查询
-
子查询:在一个完整select语句中嵌套其他的完成的select语句,称内部select语句为子查询,外部select语句为主查询。
-
子查询的结果为单个值(1行1列):把子查询结果当成一个值,带入主查询参与运算
--查询最高工资的员工信息
--步骤一:找出最高工资--24000
select max(salary) from employees;
--步骤二:找出员工信息--where
select * from employees where salary=24000;
--合并Sql
select * from employees where salary=(select max(salary) from employees); -
子查询的结果多个值(N行1列):把子查询的结果当成一个范围,带入主查询参与运算
--查询姓‘King’的部门的同部门员工
--步骤一:查出姓‘King’所在的部门
select department_id from employees where last_name='King';
--步骤二:查询80 90 部门的所有员工
select * from employees where department_id in(80,90);
-- 步骤三:合并SQL
select * from employees where department_id in(select department_id from employees where last_name='King');
-
子查询的结果为一个表(N行N列):把子查询的结果当成一张表,继续进行筛选
--查询工资前5名
select * from employees where rownum<=5 order by salary desc;--error
--步骤一:按照工资排序降序--tb1
select * from employees order by salary desc;
--步骤二:从表1找出前五条数据
select * from tb1 where rownum<=5
--步骤三:合并sql
select * from(select * from employees order by salary desc)where rownum<=5; -
分页查询:【重点】
--查询工资前6-10名 --步骤一:对工资排序查所有人信息 select * from Employees order by salary desc;--tb1 --步骤二:查询前十条数据+伪劣 select rownum,tb1.* from tb1 where rownum<=10;--tb2 --步骤三:查询rownum>=6 select * from tb2 where rownum>=6 --合并前两个 select rownum ,tb1.* from (select * from Employees order by salary desc) tb1 where rownum<=10; --合并所有 select * from (select rownum r,tb1.* from (select * from Employees order by salary desc) tb1 where rownum<=10) where r>=6;
分页SQL(第n-m)步骤总结: --步骤0:对原始数据进行筛选 --步骤1:查询符合条件的<=m的所有数据作为新表,表中需要展示rownum,起别名 rn --步骤2:查询得到表的rn>=n的数据 --步骤3:合称SQL
三.连接查询
-
连接查询:要查询的数据来自于多张表,可以做表连接
-
基本语法:
select ...
from 表1
[...]join 表2
on 连接条件
--多张表做连接查询:
列数:表1列数+表2列数+...
行数:取决表连接方式 -
内连接【重点】
--关键字:[inner] join
--查询刘克的信息+老师的信息
特点:
结果:符合连接条件的数据
必须连接条件
2张表没有顺序要求
select s.*,t.* from student s
inner join teacher t
on s.teacherid=t.teacherid
where stuname='刘克';
--查询king 工号,名,工资,部门编号,部门名称 -
外链接
-
左向外连接:左连接
--关键字:left [outer] join
--查询所有学生信息和所在教室的信息
select s.*,c.*
from Student s
left join Clazz c
on s.clazzid=c.clazzid -
右向外连接:右连接
-
-
-
-
--关键字:right [outer] join
--查询所有班级及班级内学生的信息
select s.*,c.*
from student s
right join clazz c
on s.clazzid=c.clazzid -
完全外连接
--full [outer] join
--查询所有班级及学生的信息
select s.* ,c.*
from student s
full join clazz c
on s.clazzid=c.clazzid;

-
-
交叉连接
关键字:cross join
无条件连接(表1rownum*表2rownum),笛卡儿积,毫无意义 -
自连接(特殊的表连接)
关键字:join
--查询哈哈的信息和哈哈组长的信息
select s1.*,s2.*
from student s1
join student s2
on s1.leader=s2.studentid
where s1.stuname='哈哈'; -
多表连接
关键字:join
--查询刘克的信息+班级信息+老师信息
select s.*,c.*,t.*
from student s
join clazz c
on s.clazzid=c.clazzid
join teacher t
on s.teacherid=t.teacherid
where s.stuname='哈哈';
SQL语句体系
-
SQL:(Structured Query Language)结构化查询语言,Oracle/mySQL/SqlServer...可以用在RDBMS中管理数据;PL/SQl:Oracle数据库的工具;PL/SQl:Oracle公司在SQL语言上的扩展
-
DQL:(Data Query Language)数据查询语言
例:select[重点]
-
DDL:(Data Define Language)数据定义语言
例:create/drop/alter--表
-
创建表

-
表名--望文生义
create table 表名(
列1,
...
列n
); -
列
-
语法
列名 数据类型 约束,
注:列名--望文生义,多个单词组成列名,由_隔开 -
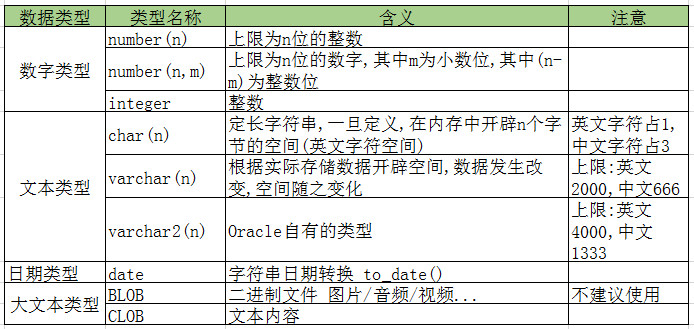
数据类型
-
约束:对列的内容要求

-
-
-
删除表
drop table 表名;
注:如果当前表有列被其他表引用作为外键,先删除引用表,再删除当前表
暴力操作: drop table 表名 cascade constraints;--删除当前表和引用表的外键约束 -
修改表
-
修改列类型
alter table 表名 modify 列名 类型;
注:表内没有数据可以修改 -
修改列名
alter table 表名 rename column 旧列名 to 新列名; -
追加新列
alter table 表名 add 列名 类型 约束;
-
-
-
DML:(Data Modify Language)数据修改语言
例:insert/delete/update--记录
-
增加数据
insert into 表名(列名1,列名2,...) values(值1,值2...);
注:列名和值依次匹配
--执行完insert,必须执行commit,数据才能添加至数据库,否则数据仅仅被验证可以添加,放在缓存区而已(回滚段) -
删除数据
delete from 表名;--删除表中全部数据
delete from 表名 where 条件删除;--删除表中指定数据 -
修改数据
update 表名 set 列名=值;--修改一列所有数据
update 表名 set 列名=值 where 修改条件;--修改指定字段
-
-
TCL:(transaction Control Language)事务控制语言
例:commit/rollback--提交/回滚
-
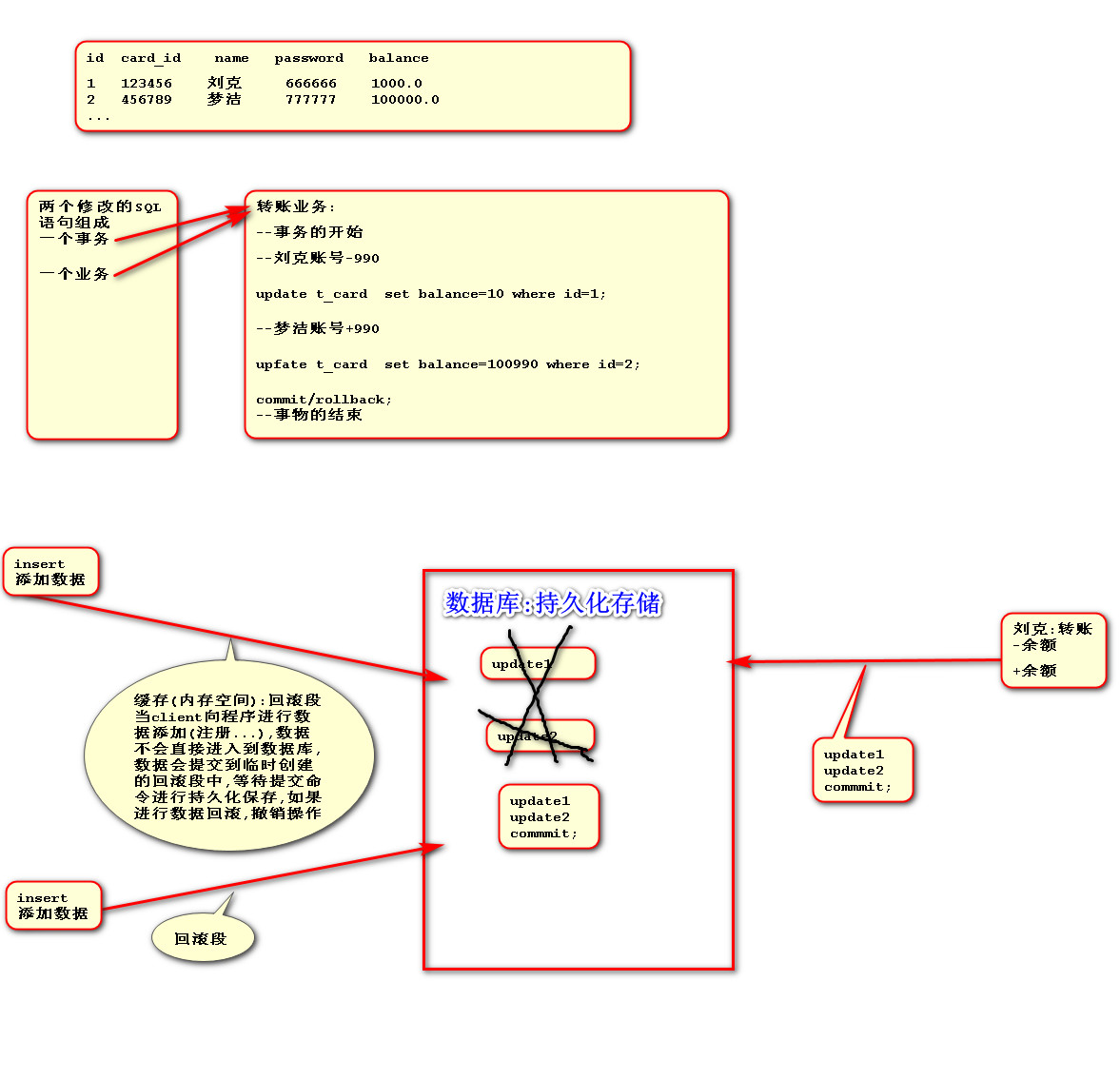
事务
保证业务操作完整性的一种数据库机制
(事务时数据库执行的最小单元,通常由一个或者多个Sql组成,并且在一个事务中SQl,要成功需要一起commint;如果有一条失败,都失败rollback)
-
命令
commit;提交事务--把回滚段数据持久化到数据库
rollback;撤销事务--把回滚段中的数据删除
-
事务的边界
-
事务的开始:一个业务(事务)的第一条SQL语句开始
-
事务的结束:提交或者回滚事务
-
提交或者回滚事务方式:
-
DDL内含事务控制,只要执行,那么直接commit;
-
DML事务提交必须手动执行commit,不成功手动执行rollback;
-
DML事务使用SQLPlUS时,如果使用exit;正常退出,存在于回滚段中的数据自动commit;如果非正常退出命令窗口,存在于回滚段的数据执行rollback;
-
-
图例:
-
-
原理:
-
事务的特性ACID[了解 面试]
A:原子性--一组Sql语句,一起成功,一起失败,完整整体
C:一致性--保证用户数据操作前操作后的一致
I:隔离性--保证多线程并发的数据安全
D:持久性--事务操作的数据持久化到数据库
-
二.数据库中的其他对象
-
序列
-
作用:自动的生成一段有顺序的数字
-
语法:
create sequence 序列名 --生成序列,序列名:表名_列名_seq/seq_表名_列名
[start with n]--数字n开始
[increment by m];--递增m -
使用:通常用在主键上,添加数据时使用序列名.nextval获取序列的下一个值
--创建序列
create sequence seq_card_id start with 1 increment by 1;
--插入数据
insert into t_card values(1,123456,'666666',1000.0);--没有添加序列前
insert into t_card values(seq_card_id.nextval,456789,'777777',999.9);--添加序列后 -
注:
序列生成后可以使用在所有表,所有列,数据一旦使用无法再次生成
-
删除序列
drop sequence 序列名;
-
-
视图
-
作用:起了名字的select语句
-
语法:
create view 视图名 as select...;生成一个视图 -
使用:
select * from 视图名; -
删除视图:
drop view 视图名; -
注意:
-
通过视图查询不能提高查询效率(简化SQL)
-
只是保存 查询列,没有生成新的库表结构
-
不建议使用通过视图的insert/delete/update
-
-
-
索引
-
作用:提高查询效率
-
语法:
create index 索引名 on 表名(字段名); -
自动使用
-
删除索引
drop index 索引名; -
注意:
-
主键列和唯一列(unique)自动增加索引
-
通常在 大量数据 中查询 小量数据,经常查询的列上增加索引
-
索引不是越多越好,原因:索引占用内存 DML:维护索引
-
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号