C语言程序编译过程及原理详解(简单基础篇)
可执行程序是如何诞生的?
编译链接过程(简述)
先稍微回顾一下,在生成可执行文件之前,程序会经历三步,分别是预处理、编译、汇编,预处理是将宏展开、#include、#ifendif这些条件编译,还有添加行号、删除注释信息,生成.i文件,然后是编译阶段,计算机会经过语法分析、语义分析、词义分析,并且进行代码优化,从而生成.s汇编文件,再之后是汇编阶段,将汇编指令转为机器指令,同时生成各种段和符号表,生成可重定向的二进制文件.o文件,在之后是链接阶段,链接阶段分为两种阶段,分别是静态链接和动态链接,这两者的主要区别在于链接的时机不同,静态链接主要发生在可执行文件生成之前,动态链接主要发生程序运行之前
基本概念
数据
数据是指全局变量和静态变量,还有一种数据叫做常量
存储数据有三个位置:data段、rodata段、bss段,初始化值不为0的全局变量和静态变量存放在data段,字符串常量存放在rodata段,
初始化值为0或者未初始化的全局变量和静态变量存放在bss段
指令
一个代码块除了数据外就是指令,这里举个例子
#include<stdio.h> int main() { int a = 10; int b = 20; printf("a+b=%d\n", a + b); return 0; }
上文的a和b并不是数据,因为其是局部变量,这条指令表示通过移动rsp寄存器在栈帧上开辟四个字节空间,并向其中写入数据
符号
数据段的数据都会产生符号,而代码段只有函数名会产生符号,符号的修饰符为global和local,global为没有被static修饰的全局变量和函数名,而local则是被static修饰的全局变量和函数名,global能够对所有源文件可见,local则只能对当前源文件可见
符号其实就是程序中变量名和函数名,同时还要理解符号定义和符号引用的概念
//举个例子 //main.c int buf[2]={1,2};//符号定义 void swap(); int main()//符号定义 { swap();//符号调用 return 0; } //swap.c extern int buf[];//符号定义 int* bufp0=&buf[0];//bufp0是符号定义,buf[0]是符号调用 static int*bufp1;//符号定义 void swap()//符号定义 { int temp;//这是一条指令 bufp1=&buf[1];//下面这些全部都是符号调用 temp=*bufp0; *bufp0=*bufp1; *bufp1=temp; }
链接符号的类型
global symbols:全局变量产生的符号,一般是不被static修饰的全局变量和函数名
local symbols:访问权限受限的全局变量或者函数,一般是被static修饰

符号定义的本质
符号定义的本质是分配了存储空间,符号的值就是其目标的首地址,函数名的符号指向实现它的代码区,变量的话则指向存储它的静态数据区,所以符号解析的简单过程就是在确定符号定义与符号调用的关系后,将符号调用的地址重定位为相关联的符号定义的地址
强弱符号
强符号:函数名和已初始化的全局变量
弱符号:尚未初始化的全局变量
符号解析规则:(1)强符号不能多次定义
(2)若同时存在弱符号和强符号,则以强符号的定义为主
(3)若存在多个弱符号,则随机选一个
虚拟地址进程空间
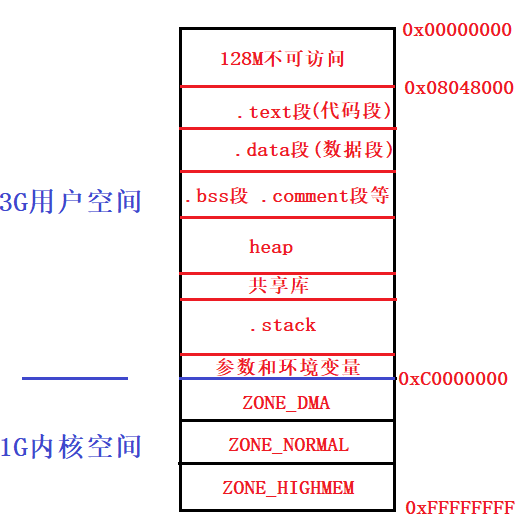
上图为32位机的虚拟进程空间,每个操作系统有2^32个字节的空间,也就是4G空间,这4G有3G是进程相互独立的用户空间,或者说是用户态,另外1G则是由全部进程共享的内核空间,即内核态
编译过程
.o文件
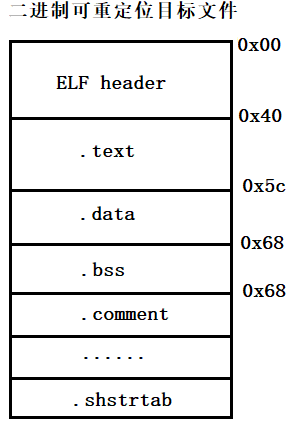
.o文件的组成
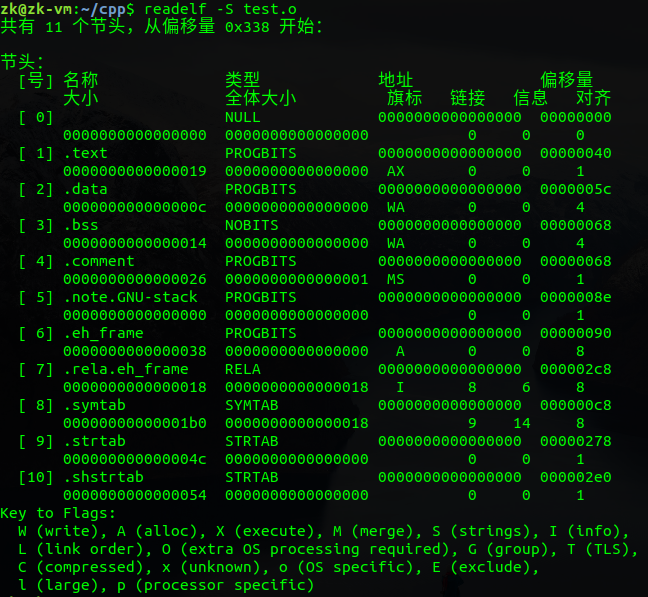
一个.o文件包含ELF header和各个段,其中ELF header占64个字节
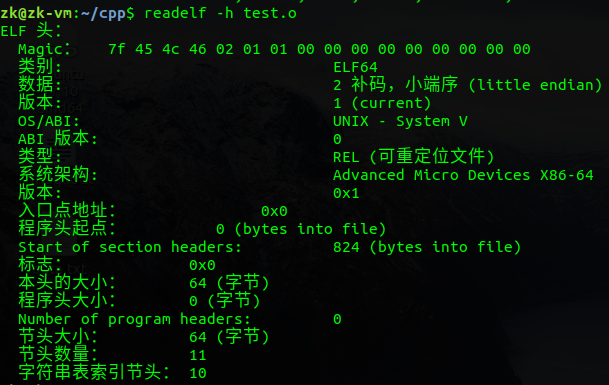
接下来是各个段:
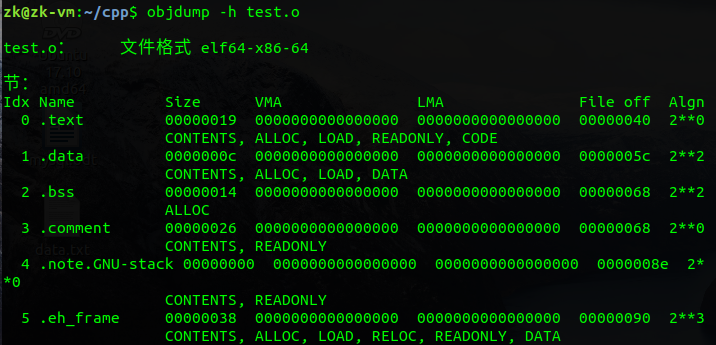
这里首先可以看出数据和代码在.o文件中是以段的形式存储,然后观察text段,发现它的file off位置在0x40,也就是64字节处,结合ELF header占64字节,可以看出text段位于ELF header后面,而ELF header位于最低地址处(0x00),然后谈论一点有难度的地方
text段大小为0x19,其file off的位置为0x40,也就是其起始偏移位置为0x59,但实际可以看到data段的file off位置为0x5c,这一现象的原因在于字节对齐,字节对齐我会在下一个标题进行讲解
之后的.bss段会出现两个问题,一个是.bss段的大小应该为4*6=24字节,但是实际上却是20字节;另一个问题就是可以看到.comment段的偏移(file off)也为0x68,这说明.bss段在目标文件中是不占大小的,即.comment和.bss段的偏移相同。对于这两个问题,这里不作详细介绍,简单说一下。第一个问题,涉及到C语言中的强符号和弱符号概念;第二个问题我们可以这样理解,因为.bss段中存的是初始化为0或者未初始化的数据,而实际未初始化的数据其默认值也为0,这样我们就没必要存它们的初始值,相当于有一个默认值0
上面的图只列出了部分段,下面查看一下目标文件中所有的段,一共有11个段,简单说明一下,.comment是注释段、.symtab是符号表段
字节对齐
字节对齐的目的在于提高CPU处理数据的效率,比如说有一个int类型的数据,那么其起始偏移地址必须要被4整除,通常来说,在 64 位机下,对于基础数据类型,它的字节对齐就是它的 sizeof。比如 bool 类型,sizeof(bool) = 1, 要求 1 字节对齐,1 字节对齐就相当于不对齐。而 int 类型,sizeof(int) = 4, 就要求 4 字节对齐。double 类型,sizeof(double) = 8,要求 8 字节对齐

上面这张图就比较形象的说明为什么要字节对齐,因为如果字节对齐,在32位机cpu每次读取4字节的信息(64位则是八字节),那么刚好可以一次读取全部的整形数据,反之如果不对齐,则需要额外次数进行读取
这里顺便介绍几个概念:
操作系统:每个时钟周期内,处理器处理二进制代码数,即“0”和“1”的个数。如64-bit,32-bit CPU位数:CPU中寄存器的位数=CPU能够一次并行处理的数据宽度(位数)=数据总线宽度;64-bit,32-bit
关系:操作系统位数 = 其所依赖的指令集位数 <= CPU位数
符号表
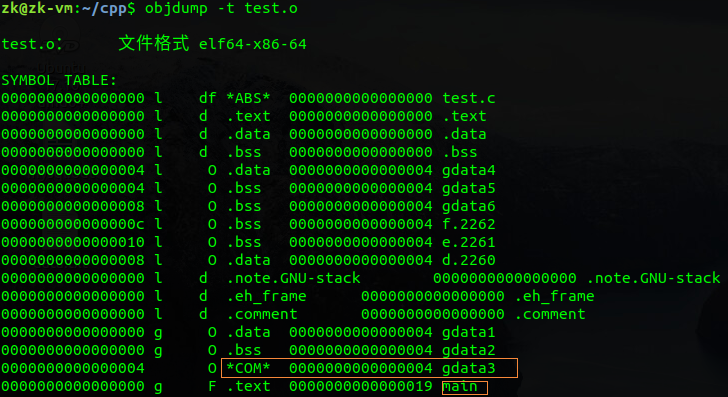
在编译时期,也就是尚未链接的时期,符号尚未被分配内存地址,因此符号地址为零或者偏移量,第一列为符号的地址(不是零就是相对于ELF header的偏移量),第二列为符号的作用域,l为local,g为global,第三列表示符号类型,第四列为在哪个段内
实际上符号表是一个结构体数组,里面存储了符号信息

name:表示了在字符串段内的偏移量,也就是变量名和函数名
type:符号类型,函数还是变量
binding:全局还是局部
section:位于哪个段
value:偏移量,在.o文件中就是距离符号定义起始位置的偏移量,但是如果在可执行文件中,就是绝对运行地址
链接过程
现在要对.o文件进行处理,也就是链接,链接的大致过程是:合并所有目标文件相同的段,并调整段偏移和段长度,合并符号表,进行内存分配,符号重定位
合并所有目标文件相同的段:将所有具有相同属性的段进行合并,例如.text段和.rodata段都具有可读与可执行权限,因此将两者合并到一个页面上,同理将.bss和.data段也合并在一个界面上,这样更省内存空间
符号解析:将符号的引用与符号的定义相关联
合并符号表:计算符号定义的绝对地址,这里要注意一点,在执行链接流程之前,符号定义与引用是没有分配地址的,其符号值为相对于符号定义的偏移量
符号重定位:将符号引用的地址修改为重新分配好的地址
静态链接
为什么要静态链接
在编写项目的时候,不可能将全部代码放入同一个源文件,要分成多个源文件,每个源文件都是.c文件,并且相互之间并不完全独立(不同源文件可能会相互调用函数),因此每个源文件经过编译产生的.o文件需要通过链接形成可执行文件,而这种链接就是静态链接
静态链接的原理
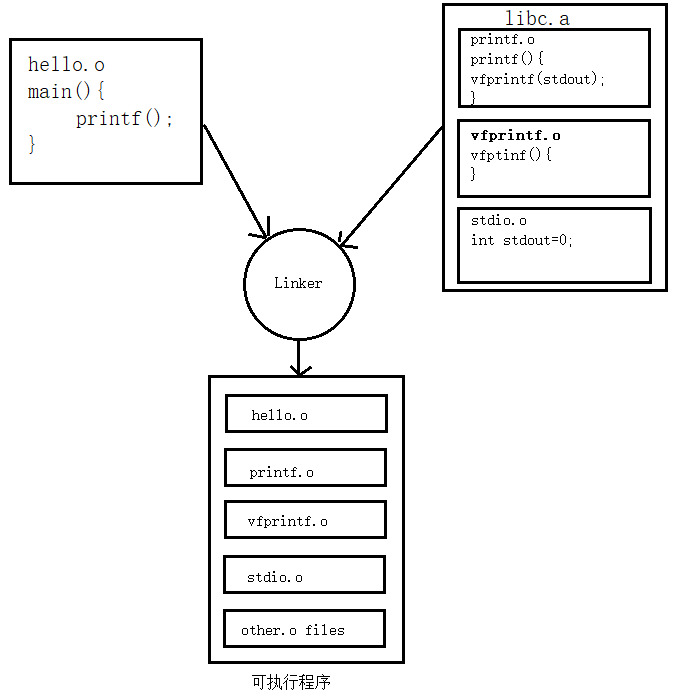
实际上静态链接是将多个.o文件链接形成静态链接库,每当可执行文件执行时,便会将所使用的函数的.o文件链接进来,下图可以发现hello.c文件中使用了printf函数,那么程序就会将静态库libc.a中的printf.o、vprintf.o、stdio.o链接进来
静态链接的优缺点
静态链接的优点就是将可执行文件所需的.o文件全部链接进来,因此可执行文件从一开始就具备所有其执行的所需的目标文件,执行速率就很快,而缺点也很明显,就是目标文件被拷贝了太多份,虽然上面这个例子只有hello.c文件调用了printf函数,但是实际应用中,如果有多个源文件调用了printf函数,那么printf.o文件将被拷贝多次,这是非常耗费内存的
动态链接
概述
为了解决静态链接的不足,而产生了动态链接,动态链接与静态链接不同,它是在执行程序时才建立链接,比如说有a和b两个文件需要c目标文件,静态链接会将c目标文件拷贝两份分给a和b链接,形成两个独立的模块,但是动态链接则是先将a和c链接,然后当b运行时将c的地址映射给b,这样就可以减少内存
举个例子吧
//a.c #include "Lib.h" int main() { foobar(1); return 0; } //b.c #include "Lib.h" int main() { foobar(2); return 0; } //c.h #ifndef LIB_H //条件编译,主要应用于不同源文件声明同一头文件,避免声明冲突 #define LIB_H //定义标识,标识名可以随意 void foobar(int i); #endif //c.c #include <stdio.h> void foobar(int i) { printf("Printing from Lib.so %d\n", i); }
可以看到a和b都用到了c的foobar函数,动态链接中可以将c文件共享,但是要注意这里共享并不是完全共享,实际上只有代码段是共享的,而数据段仍然是拷贝的,这是因为不同文件对数据的修改不同,需要将数据拷贝多份,但是代码段之所以能够被共享,是因为代码段只有可读权限,不可修改,实际上这也说明了动态链接的核心问题:如何重定位,实际上,在静态链接中,我们提到过在静态链接中,会先进行符号解析,建立定义与引用的关联后,合并符号表并且重定位,但是重定位就意味着要修改代码段,这是违背动态链接的,因此就有了got
got和plt
got表和plt表分别针对了变量和函数的引用,先来说说GOT表,之前说过代码是共享的,数据是私人的,也就是说代码不可被修改,但是数据是通过拷贝人手一份的,因此GOT表正是通过修改数据段来实现代码段的重定位的,这就是地址无关代码(PIC),GOT表的本质是一个指针数组,它的表项是一个4字节的指针,在编译阶段GOT表的内容为空,当动态链接时,GOT表的内容就会变成引用的符号的真实地址,从而实现指令的重定位
然后再谈谈plt表,可以设想一下,当程序运行时,需要将所有引用符号和函数名重定位,这毫无疑问是时间花费巨大,因此产生plt表,其作用是只有当函数被调用时才会进行重定位,plt表的工作流程分为四步:
-
指令跳转到 plt 表
-
plt 表判断其对应的 got 表项是否已经被重定位
-
如果重定位完成,plt 代码跳转到目标地址执行
-
如果未重定位,调用动态链接器为当前的引用进行重定位,重定位完成之后再跳转
参考博客
https://zhuanlan.zhihu.com/p/317478523 #静态链接 https://zhuanlan.zhihu.com/p/319784776 #动态链接 https://zhuanlan.zhihu.com/p/363489654 #got和plt https://www.cnblogs.com/cyyljw/p/10949660.html #静态链接与动态链接的区别与优缺点 https://blog.csdn.net/kang___xi/article/details/79571137 #编译链接过程的基本概念 https://www.jianshu.com/p/bda60193808d #符号和符号表 https://zhuanlan.zhihu.com/p/166219554 #编译原理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号