
cassandra学习笔记
版本3.11
cassandra:3.11
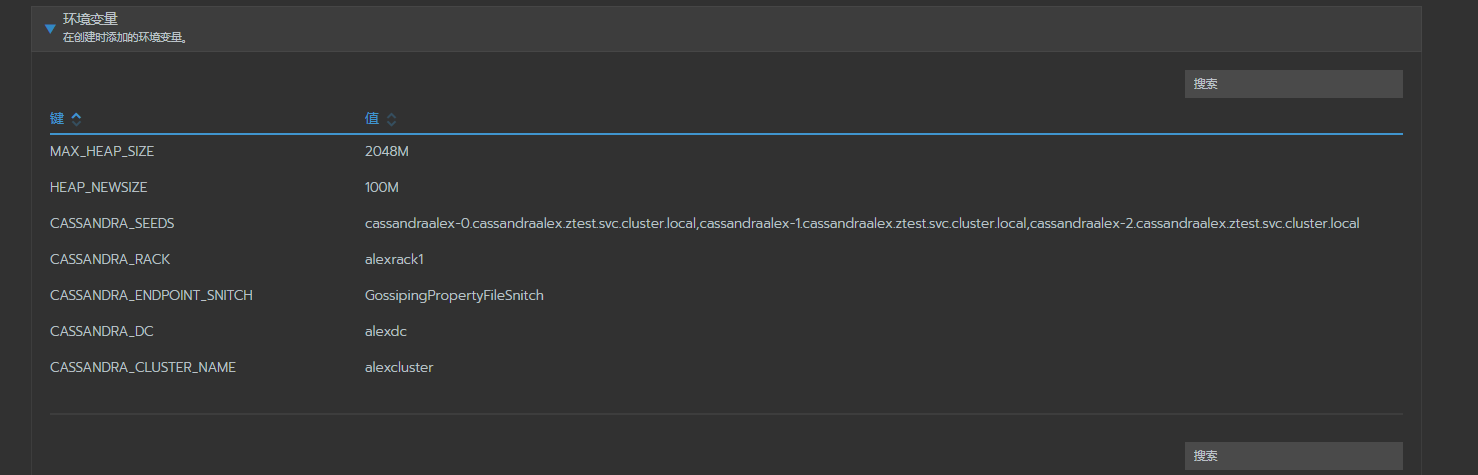
CASSANDRA_CLUSTER_NAME alexcluster
CASSANDRA_DC alexdc
CASSANDRA_ENDPOINT_SNITCH GossipingPropertyFileSnitch
CASSANDRA_RACK alexrack1
CASSANDRA_SEEDS cassandraalex-0.cassandraalex.ztest.svc.cluster.local,cassandraalex-1.cassandraalex.ztest.svc.cluster.local,cassandraalex-2.cassandraalex.ztest.svc.cluster.local
HEAP_NEWSIZE 100M
MAX_HEAP_SIZE 512M
nodetool status
Datacenter: alexdc
==================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 10.42.11.127 214.58 KiB 256 51.0% b80e1db2-63d2-4cfb-a6a1-6d9324b13799 alexrack1
UN 10.42.9.208 279.65 KiB 256 51.3% 1081fe3f-4bc9-4522-9a2c-b0acb4bcfcf3 alexrack1
UN 10.42.10.148 204.38 KiB 256 50.5% 8f0d2569-3b32-480c-8678-328d2adf9811 alexrack1
UN 10.42.6.69 215.38 KiB 256 47.2% 59a49330-00c0-454c-9fbc-698d292e6799 alexrack1
https://cassandra.apache.org/doc/latest/architecture/overview.html
keyspace: 定义一个dataset是怎么复制的。比如在哪个数据中心datacenter里有多少份copy。 keyspace包含表tables.是表table的容器
table:定义一个集合模式。table包含partitions和columns。指明哪些包含partition,哪些包含columns。这是行的容器。
partition:定义主键部份的主要部份。Cassandra必须要有。任何查询都提供partition key
row:是包含一组列的集合。必须定义一个唯一主键。(这个主键就是partition key)。还能附加集群key,clustering keys. 一个存放列的容器,由一个主键引用
column: 一个单独数据组,并且有类型和归属于哪个行row。
cluster:键空间的容器,包括一个或多个节点
cql支持:
单分区single partition支持轻量级的事务
用户自定义类型,方法,聚合。
集合类型包括set,map和list
本地二级索引
物化视图(实验阶段)
Cassandra不支持:
- Cross partition transactions 交叉分区事务
- Distributed joins 分布式的join
- Foreign keys or referential integrity. 外键
书:p71
cqlsh:
了解当前集群:
cqlsh> DESC cluster;
Cluster: alexcluster
Partitioner: Murmur3Partitioner
查看集群中有哪些键空间:
cqlsh> desc keyspaces
system_traces system_schema system_auth system system_distributed
system键空间由Cassandra内部管理,我们不能在那些键空间中存放数据。
查看cassandra版本,客户端版本和协议版本:
cqlsh> show version
[cqlsh 5.0.1 | Cassandra 3.11.9 | CQL spec 3.4.4 | Native protocol v4]
创建自己的键空间:
CREATE KEYSPACE my_keyspace WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1 };
查看刚才创建的键空间:
cqlsh> desc KEYSPACE my_keyspace
CREATE KEYSPACE my_keyspace WITH replication = {'class': 'SimpleStrategy', 'replication_factor': '1'} AND durable_writes = true;
切换键空间:
use my_keyspace ;
在键空间中创建自己的表:
CREATE table user ( first_name text, last_name text, primary key (first_name) );
类型都是text文本,text和varchar类型是同义词。first_name作为主键
也可以不切换键空间名:
create table my_keyspace.user (....来创建表
查看表的描述:
cqlsh:my_keyspace> desc table user;
CREATE TABLE my_keyspace.user (
first_name text PRIMARY KEY,
last_name text
) WITH bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
cqlsh读写数据:
insert into user (first_name , last_name ) VALUES ( 'alex', 'he') ;插入数据
SELECT count (*) from user; 统计表数据
count
-------
1
(1 rows)
Warnings :
Aggregation query used without partition key
cqlsh:my_keyspace> select * from user where first_name='alex'; 查询数据数据
first_name | last_name
------------+-----------
alex | he
(1 rows)
cqlsh:my_keyspace> delete last_name from user where first_name='alex'; 删除一行中的一列
cqlsh:my_keyspace> select * from user where first_name='alex';
first_name | last_name
------------+-----------
alex | null
(1 rows)
cqlsh:my_keyspace> delete from user where first_name='alex'; 删除一整行
cqlsh:my_keyspace> select * from user where first_name='alex';
first_name | last_name
------------+-----------
(0 rows)
清空表:
truncate user;
删除表模式:
drop table user;
修改表,新增列:
alter table user add title text;
查询并显示时间戳:注意writetime()函数不能对主键使用,这里使用的是last_name
cqlsh:my_keyspace> select first_name,last_name,writetime(last_name) from user;
first_name | last_name | writetime(last_name)
------------+-----------+----------------------
blex | he | 1614219876501842
clex | hcc | 1614219902749117
alex | he | 1614219681773120
写操作时,指定时间戳: (注意,似乎时间戳只能往后时间)
update user using timestamp 1614219800000000 set last_name='change lastname' where first_name='blex';
update user using timestamp 1714219800000000 set last_name='lastname' where first_name='blex';
cqlsh:my_keyspace> select first_name,last_name,writetime(last_name) from user;
first_name | last_name | writetime(last_name)
------------+-----------+----------------------
blex | lastname | 1714219800000000
clex | hcc | 1614219902749117
alex | he | 1614219681773120
ttl,数据过期时间:
查询数据过期时间:
select first_name, last_name, ttl(last_name) from user;
first_name | last_name | ttl(last_name)
------------+------------+----------------
blex | lastnameee | null
clex | hcc | null
alex | he | null
设置ttl过期时间:
update user using ttl 30 set last_name='kfc' where first_name='clex';
cqlsh:my_keyspace> update user using ttl 30 set last_name='kfc' where first_name='clex';
cqlsh:my_keyspace> select first_name, last_name, ttl(last_name) from user;
first_name | last_name | ttl(last_name)
------------+------------+----------------
blex | lastnameee | null
clex | kfc | 28
alex | he | null
cqlsh:my_keyspace> select first_name, last_name, ttl(last_name) from user; 30秒过后这一列last_name变为null
first_name | last_name | ttl(last_name)
------------+------------+----------------
blex | lastnameee | null
clex | null | null
alex | he | null
uuid类型:
alter table user add id uuid;
cqlsh:my_keyspace> update user set id=uuid() where first_name='alex';
cqlsh:my_keyspace> select first_name, last_name, id from user;
first_name | last_name | id
------------+------------+--------------------------------------
blex | lastnameee | null
clex | null | null
alex | he | 4460bb97-e629-4fb8-92b6-fcdfd3a0c294
集合p93:
集set,列表list,映射map
set集合无序,能够插入额外的元素而不需要先读取内容。
新增一个email地址集:
alter table user add emails set<text>;
cqlsh:my_keyspace> update user set emails={
... 'alex@alexhe.com'} where first_name='alex';
cqlsh:my_keyspace> select first_name,emails from user where first_name='alex';
first_name | emails
------------+---------------------
alex | {'alex@alexhe.com'}
使用字符串连接增加另一个email地址:
update user set emails=emails + {'alex@new.com'} where first_name='alex';
cqlsh:my_keyspace> update user set emails=emails + {'alex@new.com'} where first_name='alex';
cqlsh:my_keyspace> select first_name,emails from user where first_name='alex';
first_name | emails
------------+-------------------------------------
alex | {'alex@alexhe.com', 'alex@new.com'}
从集中删除元素
update user set emails=emails - {'alex@new.com'} where first_name='alex';
cqlsh:my_keyspace> select first_name,emails from user where first_name='alex';
first_name | emails
------------+---------------------
alex | {'alex@alexhe.com'}
list数据类型包含一个有序的元素列表:
alter table user add phone_numbers list<text>;
cqlsh:my_keyspace> update user set phone_numbers = ['111111'] where first_name='alex';
cqlsh:my_keyspace> select phone_numbers from user where first_name='alex';
phone_numbers
---------------
['111111']
list追加,追加到后面:
cqlsh:my_keyspace> update user set phone_numbers = phone_numbers+['22222'] where first_name='alex';
cqlsh:my_keyspace> select phone_numbers from user where first_name='alex';
phone_numbers
---------------------
['111111', '22222']
追加到前面:
update user set phone_numbers = ['33333'] +phone_numbers where first_name='alex';
按索引替换元素:
cqlsh:my_keyspace> update user set phone_numbers[1] = 'tihuan' where first_name='alex';
cqlsh:my_keyspace> select phone_numbers from user where first_name='alex';
phone_numbers
------------------------------
['33333', 'tihuan', '22222']
减法操作符删除一个指定值元素:
cqlsh:my_keyspace> update user set phone_numbers=phone_numbers - ['tihuan'] where first_name='alex';
cqlsh:my_keyspace> select phone_numbers from user where first_name='alex';
phone_numbers
--------------------
['33333', '22222']
使用元素索引直接删除特定的元素:
delete phone_numbers[0] from user where first_name='alex';
map类型:
创建一个列跟踪登陆会话时间秒数,并用一个timeuuid作为键:
alter tale user add login_sessions map<timeuuid,int>;
update user set login_sessions={now():13, now():18} where first_name='alex';
select login_sessions from user where first_name='alex';
用户自定义类型:
创建一个地址类型:
create type address ( street text, city text, state text, zip_code int);
alter table user add addresses map<text,frozen<address>>;
update user set addresses=addresses + {'home':{street:'yanan Road',city:'shanghai',state:'sh',zip_code:200000}} where first_name='alex';
cqlsh:my_keyspace> select first_name,addresses from user;
first_name | addresses
------------+-----------------------------------------------------------------------------------
blex | null
clex | null
alex | {'home': {street: 'yanan Road', city: 'shanghai', state: 'sh', zip_code: 200000}}
(3 rows)
二级索引:
create index on user(last_name);
cqlsh:my_keyspace> select * from user where last_name='he';
first_name | addresses | emails | id | last_name | login_sessions | phone_numbers | title
------------+-----------------------------------------------------------------------------------+---------------------+--------------------------------------+-----------+--------------------------------------------------------------------------------------+--------------------+-------
alex | {'home': {street: 'yanan Road', city: 'shanghai', state: 'sh', zip_code: 200000}} | {'alex@alexhe.com'} | 4460bb97-e629-4fb8-92b6-fcdfd3a0c294 | he | {1552ece0-772a-11eb-b47a-67f6761f951c: 18, 1552ece1-772a-11eb-b47a-67f6761f951c: 13} | ['33333', '22222'] | null
还可以根据集合中的值创建索引。
create index on user (addresses);
create index on user (emails);
create index on user (phone_numbers);
删除索引:
drop index user_last_name_idx;
不过不推荐使用二级索引,而是使用反规范化的表设计或物化视图。
sasi,一种新的二级索引实现,sstable attached secondary index
会为每个sstable文件计算sasi索引,并作为sstable文件的一部分存储。而原先的Cassandra实现会把索引存储在单独的隐藏表中。
sasi实现与传统的二级索引可以并存。可以用create custom index user_last_name_sasi_idx on user (last_name) using 'org.apache.cassandra.index.sasi.SASIIndex';
sasi索引能做大于小于搜索。还可以使用like关键字对列进行文本搜索
select * from user where last_name like 'a%';
Cassandra中分区键,复合键和集群键之间的区别?(Difference between partition key, composite key and clustering key in Cassandra?)
There is a lot of confusion around this, I will try to make it as simple as possible. The primary key is a general concept to indicate one or more columns used to retrieve data from a Table. The primary key may be SIMPLE create table stackoverflow ( key text PRIMARY KEY, data text ); That means that it is made by a single column. But the primary key can also be COMPOSITE (aka COMPOUND), generated from more columns. create table stackoverflow ( key_part_one text, key_part_two int, data text, PRIMARY KEY(key_part_one, key_part_two) ); In a situation of COMPOSITE primary key, the "first part" of the key is called PARTITION KEY (in this example key_part_one is the partition key) and the second part of the key is the CLUSTERING KEY (key_part_two) Please note that the both partition and clustering key can be made by more columns create table stackoverflow ( k_part_one text, k_part_two int, k_clust_one text, k_clust_two int, k_clust_three uuid, data text, PRIMARY KEY((k_part_one,k_part_two), k_clust_one, k_clust_two, k_clust_three) ); Behind these names ... The Partition Key is responsible for data distribution across your nodes. The Clustering Key is responsible for data sorting within the partition. The Primary Key is equivalent to the Partition Key in a single-field-key table. The Composite/Compound Key is just a multiple-columns key Further usage information: DATASTAX DOCUMENTATION EDIT due to further requests Small usage and content examples SIMPLE KEY: insert into stackoverflow (key, data) VALUES ('han', 'solo'); select * from stackoverflow where key='han'; table content key | data ----+------ han | solo COMPOSITE/COMPOUND KEY can retrieve "wide rows" insert into stackoverflow (key_part_one, key_part_two, data) VALUES ('ronaldo', 9, 'football player'); insert into stackoverflow (key_part_one, key_part_two, data) VALUES ('ronaldo', 10, 'ex-football player'); select * from stackoverflow where key_part_one = 'ronaldo'; table content key_part_one | key_part_two | data --------------+--------------+-------------------- ronaldo | 9 | football player ronaldo | 10 | ex-football player But you can query with all key ... select * from stackoverflow where key_part_one = 'ronaldo' and key_part_two = 10; query output key_part_one | key_part_two | data --------------+--------------+-------------------- ronaldo | 10 | ex-football player Important note: the partition key is the minimum-specifier needed to perform a query using where clause. If you have a composite partition key, like the following eg: PRIMARY KEY((col1, col2), col10, col4)) You can perform query only passing at least both col1 and col2, these are the 2 columns that defines the partition key. The "general" rule to make query is you have to pass at least all partition key columns, then you can add each key in the order they're set. so the valid queries are (excluding secondary indexes) col1 and col2 col1 and col2 and col10 col1 and col2 and col10 and col 4 Invalid: col1 and col2 and col4 anything that does not contain both col1 and col2 Hope this helps.
ps:书232
available_rooms_by_hotel_date表的主键为primary key (hotel_id,date,room_number) 表示hotel_id是分区键,date和room_number是集群列。
insert:
insert into hotel.hotels (id,name,phone) values ('az123','super hotel','123-1111-9999') if not exists;
update:
update hotel.hotels set name='bbbb hotel' where id='az123' if name='super hotel';
copy: 把表内容保存到一个文件中
copy hotels to 'hotels.csv' with header=true;
把一个文件的内容新进表:
copy available_rooms_by_hotel_date from 'available_rooms.csv' with header=true;
select:
select * from available_rooms_by_hotel_date where hotel_id='az123' and date>'2016-01-05' and date<'2016-01-12';
select * from available_rooms_by_hotel_date where hotel_id='az123' and room_number=101; #报错!因为主键是primary key (hotel_id,date,room_number) ,必须要有date
allow filtering关键字,允许我们忽略一个分区键元素。
例如:可以利用以下查询搜索某个特定日期多个酒店的房间状态:
select * from available_rooms_by_hotel_date where date='2016-01-25' allow filtering;
不过不推荐使用allow filtering 可能带来开销很大的查询。
in子句:
用来测试一个列是否等于多个可能的值。
select * from available_rooms_by_hotel_date where hotel_id='az123' and date in ('2016-01-05','2016-01-12');
ordey by排序:
select * from available_rooms_by_hotel_date where hotel_id='az123' and date>'2016-01-05' and date<'2016-01-12' order by date desc;
nodetool监控:
root@cassandraalex-0:/etc/cassandra# nodetool describecluster
Cluster Information:
Name: alexcluster
Snitch: org.apache.cassandra.locator.GossipingPropertyFileSnitch
DynamicEndPointSnitch: enabled
Partitioner: org.apache.cassandra.dht.Murmur3Partitioner
Schema versions:
e84b6a60-24cf-30ca-9b58-452d92911703: [10.42.11.157, 10.42.6.93, 10.42.9.7, 10.42.10.229]
root@cassandraalex-0:/etc/cassandra# nodetool status
Datacenter: alexdc
==================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 10.42.11.157 70.7 KiB 256 45.5% e9ed5f4b-6533-41e4-80fb-33a9b3d7c656 alexrack1
UN 10.42.6.93 70.66 KiB 256 48.4% f7a72866-4da7-4076-92de-01ee9dc50dd5 alexrack1
UN 10.42.9.7 109.31 KiB 256 57.6% 8c4859d3-be72-4c04-849e-d82b371aa998 alexrack1
UN 10.42.10.229 75.71 KiB 256 48.5% 56057d4d-2534-4fd1-9f2d-8ebe18cbc0c2 alexrack1
info看内存占用大小,用了多少磁盘
root@cassandraalex-0:/# nodetool info
ID : f7a1b4b1-a32f-4dcd-9a38-ba4cbf0b5ecb
Gossip active : true
Thrift active : false
Native Transport active: true
Load : 75.68 KiB
Generation No : 1614848492
Uptime (seconds) : 146
Heap Memory (MB) : 68.11 / 502.00
Off Heap Memory (MB) : 0.00
Data Center : alexdc
Rack : alexrack1
Exceptions : 0
Key Cache : entries 11, size 896 bytes, capacity 25 MiB, 40 hits, 54 requests, 0.741 recent hit rate, 14400 save period in seconds
Row Cache : entries 0, size 0 bytes, capacity 0 bytes, 0 hits, 0 requests, NaN recent hit rate, 0 save period in seconds
Counter Cache : entries 0, size 0 bytes, capacity 12 MiB, 0 hits, 0 requests, NaN recent hit rate, 7200 save period in seconds
Chunk Cache : entries 12, size 768 KiB, capacity 93 MiB, 25 misses, 115 requests, 0.783 recent hit rate, 98.579 microseconds miss latency
Percent Repaired : 100.0%
Token : (invoke with -T/--tokens to see all 256 tokens)
root@cassandraalex-0:/#
tpstats提供线程池的统计信息:
root@cassandraalex-0:/# nodetool tpstats
Pool Name Active Pending Completed Blocked All time blocked
ReadStage 0 0 178 0 0
MiscStage 0 0 0 0 0
CompactionExecutor 0 0 395 0 0
MutationStage 0 0 26 0 0
MemtableReclaimMemory 0 0 21 0 0
PendingRangeCalculator 0 0 5 0 0
GossipStage 0 0 3241 0 0
SecondaryIndexManagement 0 0 0 0 0
HintsDispatcher 0 0 0 0 0
RequestResponseStage 0 0 346 0 0
ReadRepairStage 0 0 0 0 0
CounterMutationStage 0 0 0 0 0
MigrationStage 0 0 5 0 0
MemtablePostFlush 0 0 29 0 0
PerDiskMemtableFlushWriter_0 0 0 21 0 0
ValidationExecutor 0 0 0 0 0
Sampler 0 0 0 0 0
MemtableFlushWriter 0 0 21 0 0
InternalResponseStage 0 0 0 0 0
ViewMutationStage 0 0 0 0 0
AntiEntropyStage 0 0 0 0 0
CacheCleanupExecutor 0 0 0 0 0
Message type Dropped
READ 0
RANGE_SLICE 0
_TRACE 0
HINT 0
MUTATION 0
COUNTER_MUTATION 0
BATCH_STORE 0
BATCH_REMOVE 0
REQUEST_RESPONSE 0
PAGED_RANGE 0
READ_REPAIR 0
tablesstats,查看键空间和表的统计信息。
nodetool tablestats 为每个表生成相同的统计信息。可以看到读写延迟,以及键空间和表级的总读写数。
还可以看到对应各个表的cassandra内部结构详细信息,包括memtable,布隆过滤器和sstable。
维护p277
nodetool flush 强制Cassandra将数据从memtable写入文件系统中的sstable,所有表
nodetool flush hotel选择性的刷新指定键空间
nodetool flush hotel reservations_by_hotel_date hotels_by_poi
nodetool drain与flush类似。完成一个刷新输出,然后让cassandra停止监听来自客户端和其他节点的命令。drain命令通常作为依序关闭一个Cassandra节点过程的一部分,可以帮助这个节点更快的启动运行,因为没有提交日志需要重放。
清理
cleanup命令会扫描一个节点上所有数据,并删除这个节点不再拥有的数据。用cleanup可以更快回收这些额外数据占用的磁盘空间,以减少集群的压力
cleanup也可以选择清理特定的键空间和表。
修复
nodetool repair
这个命令会迭代处理集群中的所有键空间和表,分别进行修复。也一样可以选择修复特定的键空间和表。
还可以限制修复范围 -local选项限制repair命令旨在本地数据中心运行。--in-local-dc也可以用过长选项选择。
或者可以通过-dc<name>下面下哦昂或者--in-dc <name>限制只在指定的数据中心运行这个命令
重建索引:
二级索引不能修复,Cassandra运行使用nodetool的rebuild_index命令从头创建索引。
性能监控:
p309
nodetool proxyhistograms 显示读请求,写请求,区间请求的延迟,在这里所请求的节点作为协调器。如果在多个节点上运行这个命令,可以帮助找出集群中速度慢的节点。
root@cassandraalex-0:/# nodetool proxyhistograms
proxy histograms
Percentile Read Latency Write Latency Range Latency CAS Read Latency CAS Write Latency View Write Latency
(micros) (micros) (micros) (micros) (micros) (micros)
50% 0.00 0.00 0.00 0.00 0.00 0.00
75% 0.00 0.00 0.00 0.00 0.00 0.00
95% 0.00 0.00 0.00 0.00 0.00 0.00
98% 0.00 0.00 0.00 0.00 0.00 0.00
99% 0.00 0.00 0.00 0.00 0.00 0.00
Min 0.00 0.00 0.00 0.00 0.00 0.00
Max 0.00 0.00 0.00 0.00 0.00 0.00
nodetool tablehistograms 后跟表名,关注特定表的性能。提供了每个查询的sstable读操作个数。还给出了分区大小和单元数量,这提供了一种发现大分区的方法。

