51cto 张岩峰 Prometheus企业级监控系统:零基础入门
启动程序介绍:
ExecStart=/usr/local/prometheus/prometheus #启动运行prometheus程序所在的路径
--config.file=/usr/local/prometheus/prometheus.yml #指定prometheus.yml配置文件路径
--storage.tsdb.path="/usr/local/prometheus/data" #指定监控指标数据存储的路径
--storage.tsdb.retention=15d #历史数据最大保留时间,默认15天
--web.console.templates="/usr/local/prometheus/consoles" #指定控制台模板目录路径
--web.console.libraries="/usr/local/prometheus/console_libraries" #指定控制台库目录路径
--web.max-connections=512 #设置最大同时连接数
--web.external-url "http://192.168.1.4:9090" #用于生产返回prometheus相对的绝对链接地址,可以在后续告警通知内容中直接点击链接地址访问prometheus Web UI。其格式为:http://{ip或者域名}:9090
--web.listen-address=0.0.0.0:9090 #prometheus默认监控端口
linux主机监控 node_exporter
scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'node_exporter' static_configs: - targets: ['10.10.10.95:9796','10.10.10.96:9796']
黑盒监控:
运维无需安装各种exporter,只要在Prometheus的服务器上安装黑盒exporter,让黑盒exporter去执行命令(类似cron),取回数据。用的最多的是ping主机,icmp监控。
blackbox_exporter下载地址:https://prometheus.io/download/ 1)安装blackbox_exporter #上传软件 [root@localhost opt]# ll blackbox_exporter-0.16.0.linux-amd64.tar.gz -rw-r--r--. 1 root root 8314959 May 18 20:40 blackbox_exporter-0.16.0.linux-amd64.tar.gz [root@localhost opt]# tar -zxvf blackbox_exporter-0.16.0.linux-amd64.tar.gz [root@localhost opt]# cp -r blackbox_exporter-0.16.0.linux-amd64 /usr/local/blackbox_exporter 2)添加blackbox_exporter为系统服务开机启动配置文件blackbox_exporter.service [root@localhost ~]# vi /usr/lib/systemd/system/blackbox_exporter.service [Unit] Description=blackbox_exporter After=network.target [Service] Type=simple User=root Group=root ExecStart=/usr/local/blackbox_exporter/blackbox_exporter \ --config.file=/usr/local/blackbox_exporter/blackbox.yml \ --web.listen-address=:9115 Restart=on-failure [Install] WantedBy=multi-user.target [root@localhost ~]# systemctl daemon-reload [root@localhost ~]# systemctl restart blackbox_exporter [root@localhost ~]# netstat -tlunp | grep blackbox_expo tcp6 0 0 :::9115 :::* LISTEN 11925/blackbox_expo icmp监控,监控主机存活状态 通过icmp 这个指标的采集,我们可以确认到对方的线路是否有问题。这个也是监控里面比较重要的一个环节。我们要了解全国各地到我们机房的线路有哪条有问题我们总结了两种方案: 全国各地各节点ping 和访问数据采集。这种类似听云运营商有提供这类服务,但是要花钱; 我现在用的方法就是:找各地测试ping 的节点,我们从机房主动ping 看是否到哪个线路有故障,下面我们开始。 prometheus 添加相关监控,Blackbox 使用默认配置启动即可 [root@localhost ~]# cat /usr/local/prometheus/prometheus.yml - job_name: "icmp_ping" metrics_path: /probe params: module: [icmp] # 使用icmp模块 file_sd_configs: - refresh_interval: 10s files: - "/qq/ping_status*.yml" #具体的配置文件 relabel_configs: - source_labels: [__address__] regex: (.*)(:80)? target_label: __param_target replacement: ${1} - source_labels: [__param_target] target_label: instance - source_labels: [__param_target] regex: (.*) target_label: ping replacement: ${1} - source_labels: [] regex: .* target_label: __address__ replacement: 127.0.0.1:9115 [root@localhost ~]# cat /qq/ping_status.yml - targets: ['220.181.38.150','14.215.177.39','180.101.49.12','14.215.177.39','180.101.49.11','14.215.177.38','14.215.177.38'] labels: group: '一线城市-电信网络监控' - targets: ['112.80.248.75','163.177.151.109','61.135.169.125','163.177.151.110','180.101.49.11','61.135.169.121','180.101.49.11'] labels: group: '一线城市-联通网络监控' - targets: ['183.232.231.172','36.152.44.95','182.61.200.6','36.152.44.96','220.181.38.149'] labels: group: '一线城市-移动网络监控' 监控主机端口存活状态 [root@localhost ~]# cat /usr/local/prometheus/prometheus.yml - job_name: 'prometheus_port_status' metrics_path: /probe params: module: [tcp_connect] static_configs: - targets: ['172.19.155.133:8765'] labels: instance: 'port_status' group: 'tcp' relabel_configs: - source_labels: [__address__] target_label: __param_target - source_labels: [__param_target] target_label: instance - target_label: __address__ replacement: 172.19.155.133:9115 10.165.94.31是被监控端ip,172.19.155.133是Blackbox_exporter 监控网站状态 prometheus 添加相关监控,Blackbox 使用默认配置启动即可 [root@localhost ~]# cat /usr/local/prometheus/prometheus.yml - job_name: "blackbox" metrics_path: /probe params: module: [http_2xx] #使用http模块 file_sd_configs: - refresh_interval: 1m files: - "/qq/blackbox*.yml" relabel_configs: - source_labels: [__address__] target_label: __param_target - source_labels: [__param_target] target_label: instance - target_label: __address__ replacement: 127.0.0.1:9115 [root@localhost ~]# cat /qq/blackbox-dis.yml - targets: - https://www.zhibo8.cc - https://www.baidu.com
基于文件的服务发现:
JSON格式文件的服务发现: [root@localhost ~]# cd /usr/local/prometheus/ [root@localhost prometheus]# mkdir targets [root@localhost prometheus]# cat targets/dev_node.json [ { "targets": [ "192.168.1.5:9090","127.0.0.1:9090" ], "labels": { "env": "dev_webgame" } } ] [root@localhost prometheus]# cat prometheus.yml - job_name: 'node_service_discovery' file_sd_configs: - files: - targets/*.json refresh_interval: 60m [root@localhost prometheus]# systemctl restart prometheus 配置文件说明: file_sd_configs,指定prometheus基于文件的服务发现配置使用的选项 - files,自定义的和prometheus程序同级目录的targets目录,要被自动加载的所有.json格式的文件。当然也可以单独指定某一个JSON格式的文件。 refresh_interval: 60m,自定义刷新间隔时间为60秒 YAML格式文件的服务发现 [root@localhost prometheus]# cat targets/dev_node.yaml - targets: - "192.168.1.30:9100" [root@localhost prometheus]# cat prometheus.yml - job_name: 'node_service_discovery' file_sd_configs: - files: - targets/*.json refresh_interval: 60m - files: - targets/*.yaml refresh_interval: 60m [root@localhost prometheus]# systemctl restart prometheus
基于consul的服务发现:consul面向分布化的系统,提供服务注册,服务发现,服务管理的功能。
1)安装consul [root@localhost opt]# ll consul_1.7.3_linux_amd64.zip -rw-r--r--. 1 root root 39717645 May 19 03:50 consul_1.7.3_linux_amd64.zip [root@localhost opt]# mkdir /usr/local/consul [root@localhost opt]# unzip consul_1.7.3_linux_amd64.zip -d /usr/local/consul/ 2)启动consul Consul必须启动agent才可使用,它是运行在Consul集群中每个成员上的守护进程,该进程负责维护集群中成员信息、注册服务、查询响应、运行检查等功能。Agent指令是Consul的核心,可以运行为Server或Client模式,操作如下: [root@localhost ~]# cd /usr/local/consul/ [root@localhost consul]# ./consul agent -dev ==> Starting Consul agent... Version: 'v1.7.3' Node ID: '950de751-f475-f7b4-cc8e-624ef85be6e3' Node name: 'localhost.localdomain' Datacenter: 'dc1' (Segment: '<all>') Server: true (Bootstrap: false) Client Addr: [127.0.0.1] (HTTP: 8500, HTTPS: -1, gRPC: 8502, DNS: 8600) Cluster Addr: 127.0.0.1 (LAN: 8301, WAN: 8302) Encrypt: Gossip: false, TLS-Outgoing: false, TLS-Incoming: false, Auto-Encrypt-TLS: false 3)服务注册发现 Consul服务注册提供了两种注册方法:一种是定义配置文件服务注册方法,即在配置文件中定义服务来进行注册;一种是HTTP API服务注册方法,即在启动后有服务自身通过调用API进行自我注册。 方法一:将本地运行的node_exporter通过服务的方式进行Consul服务注册。 [root@localhost consul]# mkdir -p /usr/local/consul/consul.d [root@localhost consul]# cd /usr/local/consul/consul.d/ [root@localhost consul.d]# cat node_exporter.json { "service": { "id": "node_exporter", "name": "node_exporter", "tags": [ "dev_games" ], "address": "127.0.0.1", "port": 9100 } } # 配置文件说明: # id:服务ID,可选提供项。若提供,则将其设置为name一致 # name:服务名称,必须提供项。要求每个节点上的所有服务都有唯一的ID。 # tags:服务的标签,自定义的可选提供项,用于区分主节点和辅助节点。 # address:地址字段,用于指定特定于服务的IP地址。默认情况下,使用agent的IP地址,因而不需要提供这个地址。可以理解为服务注册到Consul使用的IP,服务发现是发现的此IP地址。 # port:可以简单理解为服务注册到Consul使用的端口,服务发现也是发现address对应的端口。 # 编辑完配置文件后,若是首次创建使用,需要重新启动Consul服务进行加载生效。Ctrl+c停掉终端已经启动的开发者模式consul agent服务,之后再重新启动Consul服务: [root@localhost consul]# ./consul agent -dev -config-dir=/usr/local/consul/consul.d 4)服务注册成功后,我们可以通过HTTP API和DNS两种方式进行服务发现。 通过HTTP API的方式在Consul主机中获取服务列表,操作如下: [root@localhost ~]# curl http://localhost:8500/v1/catalog/service/node_exporter [ { "ID": "2d4c5e66-f00b-2ac9-0391-146993c69f0b", "Node": "localhost.localdomain", "Address": "127.0.0.1", "Datacenter": "dc1", "TaggedAddresses": { "lan": "127.0.0.1", "lan_ipv4": "127.0.0.1", "wan": "127.0.0.1", "wan_ipv4": "127.0.0.1" }, "NodeMeta": { "consul-network-segment": "" }, "ServiceKind": "", "ServiceID": "node_exporter", "ServiceName": "node_exporter", "ServiceTags": [ "dev_games" ], "ServiceAddress": "192.168.1.20", "ServiceTaggedAddresses": { "lan_ipv4": { "Address": "192.168.1.20", "Port": 9100 }, "wan_ipv4": { "Address": "192.168.1.20", "Port": 9100 } }, "ServiceWeights": { "Passing": 1, "Warning": 1 }, "ServiceMeta": {}, "ServicePort": 9100, "ServiceEnableTagOverride": false, "ServiceProxy": { "MeshGateway": {}, "Expose": {} }, "ServiceConnect": {}, "CreateIndex": 12, "ModifyIndex": 12 } ] 使用Consul提供的内置DNS服务访问当前集群中的节点信息,操作如下:(如果没有dig需要安装bind-utils) [root@localhost consul.d]# dig @127.0.0.1 -p 8600 node_exporter.service.consul ; <<>> DiG 9.11.4-P2-RedHat-9.11.4-16.P2.el7_8.3 <<>> @127.0.0.1 -p 8600 node_exporter.service.consul ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 11982 ;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;node_exporter.service.consul. IN A ;; ANSWER SECTION: node_exporter.service.consul. 0 IN A 127.0.0.1 ;; Query time: 33 msec ;; SERVER: 127.0.0.1#8600(127.0.0.1) ;; WHEN: Tue May 19 20:36:22 EDT 2020 ;; MSG SIZE rcvd: 73 5)与prometheus集成 [root@localhost prometheus]# cat prometheus.yml - job_name: 'consul_sd_node_exporter' scheme: http consul_sd_configs: - server: 127.0.0.1:8500 services: ['node_exporter'] # 配置文件说明: # consul_sd_node_exporter:指定prometheus是基于Consul的自动服务发现所使用的选项。 # - server:指定Consul服务地址,我这里是将Consul和prometheus安装在同一台主机上,所有这里使用127.0.0.1地址。 # services:服务名称列表数组,指定当前需要发现哪种服务的信息。可以指定多服务名称,例如service:['node_exporter','mysqld_exporter'],如果不填写,默认获取Consul上注册的所有服务。 6)监控机下线 当被监控服务节点故障失效或回收下线,需要删除被发现服务,否则prometheus的targets列表中仍然会显示该服务。 下面我们对以上发现的node_exporter服务进行删除操作 [root@localhost ~]# curl --request PUT http://127.0.0.1:8500/v1/agent/service/deregister/node_exporter # 这里的“node_exporter”为配置文件中service的id,若没有配置id,即为name内容。 7)监控机上线 被监控服务节点故障恢复后,可以使用命令:#./consul reload重新加载生效。 [root@localhost ~]# cd /usr/local/consul/ [root@localhost consul]# ./consul reload [root@localhost consul]# systemctl restart prometheus
基于dns的服务发现:
1)配置hosts解析,有dns可以配置dns [root@localhost ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.1.20 prometheus.tcp.com 2)配置prometheus [root@localhost ~]# cat /usr/local/prometheus/prometheus.yml - job_name: 'dns_node_exporter' static_configs: - targets: ['prometheus.tcp.com:9100'] [root@localhost ~]# systemctl restart prometheus
prometheus的relabeling功能:
示例一:
[root@localhost ~]# cat /usr/local/prometheus/prometheus.yml - job_name: "icmp_ping" metrics_path: /probe params: module: [icmp] # 使用icmp模块 file_sd_configs: - refresh_interval: 10s files: - "/qq/ping_status*.yml" #具体的配置文件 relabel_configs: - source_labels: [__address__] regex: (.*)(:80)? target_label: __param_target replacement: ${1} - source_labels: [__param_target] target_label: instance - source_labels: [__param_target] regex: (.*) target_label: ping replacement: ${1} - source_labels: [] regex: .* target_label: __address__ replacement: 127.0.0.1:9115
示例二:
[root@localhost ~]# cat /usr/local/prometheus/prometheus.yml - job_name: "mobile)game_nodes" static_configs:
- targets: ["10.10.10.95:9796","10.10.10.96:9796"] relabel_configs: - action: replace
source_labels: ['__address__'] regex: (.*) target_label: MobileGames replacement: $1
示例三: 使用keep和drop过滤内容 [root@localhost prometheus]# cat prometheus.yml - job_name: 'node_service_discovery' file_sd_configs: - files: - targets/*.json refresh_interval: 60m - files: - targets/*.yaml refresh_interval: 60m
relabel_configs:
- action: keep
source_labels: ['env']
regex: (dev.*) #只保留env为dev的项目
promql时序数据库:
运算符
=
!=
=~ job=~"node_.*"
!~
范围查询(区间查询):
http_request_total{}[5m]
单位smhdwy
瞬时向量表达式:
http_request_total{} #瞬时向量表达式,选择当前最新的数据
http_request_total{}[5m] #区间向量表达式,选择以当前时间为基准,5分钟内的数据
http_request_total{} offset 5m #5分钟前的一条数据
http_request_total{}[1d] offset 1d #昨天到今天的所有数据
promql聚合操作:
sum(http_request_total) sum求和
avg(node_cpu) by (mode) #按node计算主机cpu的平均使用时间
sum(sum(irate(node_cpu{mode!='idle'}[5m])) / sum(irate(node_cpu[5m]))) by (instance)
max 最大值 返回一个区间的最大值
avg 平均值 avg without(cpu,mode) (rate(node_cpu_seconds_total{mode='idle'}[1m]))
stddev 标准差
stdvar 标准放差
count 计数 计算族中的时间序列数,并将其作为组的值返回。例如,返回主机磁盘设备数量:count without(device)(node_disk_read_bytes_total)
count_value 对相同value进行计数。用于统计时间序列中每一个样本值出现的次数。
bottomk 用于对样本值进行排序,返回当前样本值后N位的时间序列。
topk 返回当前样本值前N位的时间序列。例如获取http请求的前5位的时序样本数据:top(5,http_requests_total)
quantile 用于计算当前样本数值的分布情况:quantile(0<=x<=1, express) 例如,当x等于0.5时,用来表示找到以下样本数据中的中位数: quantile(0.5 , http_requests_total)
promQL运算符:
promQL关系运算符:
==
!=
>
<
>=
<=
两个scalar运算 必须使用bool运算符: 99 >= bool 86 #返回scalar 1
18promql函数
数学函数:
abs绝对值
sqrt平方根
round 四舍五入取最近整数
clamp_max() clamn_min() 例如 clamp_max(process_open_fds, 7) #如果本来process_open_fds打开时3,那么显示3. 如果打开时是100,那么这里显示7.
时间函数:
time() 返回目前unixtime值。 例子:time()-process_start_time_seconds 返回程序运行了多少秒
略
标签操作函数:
label_replace()
label_join()
counter指标增长率函数:
increase() 获取区间向量的第一个和最后一个样本,并返回增长率。 increase(process_cpu_seconds_total[3m])/180 process_cpu_seconds_total是counter类型。取出【3m】的所有样本,用increse计算出最近3分钟的增长率,最后除以180秒得到样本在最近3分钟的平均增长率。
rate() 同样和counter计数器一起使用,用于计算区间向量中时间序列每秒的平均增长率。 rate(process_cpu_seconds_total[3m])
irate() 计算区间向量中时间序列的每秒即时增长率,是一个灵敏度更高的函数。irate函数时通过区间向量中最后两个数据点来计算区间向量的增长速率,反映的是即时增长率,反映样本数据的即时变化状态。
Gauge指标趋势变化预测:
predict_linear()
二进制方式安装alertmanager:
1)安装Alertmanager [root@localhost opt]# ll alertmanager-0.20.0.linux-amd64.tar.gz -rw-r--r--. 1 root root 23928771 May 21 20:02 alertmanager-0.20.0.linux-amd64.tar.gz [root@localhost opt]# tar -zxvf alertmanager-0.20.0.linux-amd64.tar.gz [root@localhost opt]# cp -r alertmanager-0.20.0.linux-amd64 /usr/local/alertmanager 2)添加alertmanager为系统服务开机启动 [root@localhost ~]# vi /usr/lib/systemd/system/alertmanager.service [Unit] Description=Prometheus Alertmanager Service daemon After=network.target [Service] User=root Group=root Type=simple ExecStart=/usr/local/alertmanager/alertmanager \ --config.file=/usr/local/alertmanager/alertmanager.yml \ --storage.path=/usr/local/alertmanager/data/ \ --data.retention=120h \ --web.external-url=http://192.168.1.10:9093 --web.listen-address=:9093 Restart=on-failure [Install] WantedBy=multi-user.target # alertmanager选项说明 # ExecStart=/usr/local/alertmanager/alertmanager 启动运行alertmanager程序所在的路径 # --config.file=/usr/local/alertmanager/alertmanager.yml 指定alertmanager配置文件路径 # --storage.path=/usr/local/alertmanager/data/ 数据存储路径 # --data.retention=120h 历史数据最大保留时间,默认120小时 # --web.external-url 生成返回alertmanager的相对和绝对链接地址,可以在后续告警通知信息中直接点击链接地址访问alertmanager web ui。其格式为http://{ip或者域名}:9093 # --web.listen-address 监听web接口和API的地址端口 [root@localhost ~]# systemctl daemon-reload [root@localhost ~]# systemctl restart alertmanager.service [root@localhost ~]# systemctl status alertmanager.service 3)web访问测试 浏览器访问示例地址:http://192.168.1.10:9093/#/status
docker安装alertmanager:
1)下载alertmanager镜像 [root@localhost ~]# docker pull prom/alertmanager 2)检查是否下载成功 [root@localhost ~]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE docker.io/prom/alertmanager latest 0881eb8f169f 5 months ago 52.1 MB 3)运行alertmanager镜像 [root@localhost ~]# docker run -d -p 9093:9093 -v /usr/local/alertmanager/simple.yml:/etc/alertmanager/config.yml --name alertmanager prom/alertmanager [root@localhost ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 121610a9f7ee prom/alertmanager "/bin/alertmanager..." 17 seconds ago Up 16 seconds 0.0.0.0:9093->9093/tcp alertmanager
alertmanager主配置文件介绍:
[root@localhost alertmanager]# cat alertmanager.yml global: resolve_timeout: 5m smtp_smarthost: 'smtp.qq.com:465' # 邮箱SMTP服务器代理地址 smtp_from: '1754815191@qq.com' # 发送邮件的名称 smtp_auth_username: '1754815191@qq.com' # 邮箱用户名称 smtp_auth_password: 'rkmdpoviehcvddde' # 邮箱授权密码 smtp_require_tls: false route: #告警路由 group_by: ['alertname'] #告警分组的标签 group_wait: 10s #从接收告警到发送的等待时间。若在等待时间内当前group接收到了新告警。这些告警会被合并未一个通知进行发送。默认30秒 group_interval: 10s #设置相同的group之间发送告警通知的时间间隔。默认为5分钟 repeat_interval: 1h #设置告警成功发送后能够再次发送完全相同告警的时间间隔。默认是4小时 receiver: 'email' #指定发哪里 receivers: #接收器 - name: 'email' email_configs: - to: '1754815191@qq.com' headers: { Subject: " WARNING- -告警邮件" } send_resolved: true inhibit_rules: #抑制规则 - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance']
templates: #告警模板在哪
- '/usr/local/alertmanager/templates/*.tmpl'
Prometheus的告警规则 和email告警:
3)配置prometheus配置文件 [root@localhost prometheus]# cat prometheus.yml global: scrape_interval: 15s evaluation_interval: 15s alerting: alertmanagers: - static_configs: - targets: - 192.168.1.10:9093 rule_files: - "/usr/local/prometheus/rules/*.yml" scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'node' static_configs: - targets: ['192.168.1.6:9100'] - job_name: 'Alertmanager' static_configs: - targets: ['192.168.1.10:9093']
4)配置告警规则文件
[root@localhost prometheus]# cat rules/up_rules.yml groups: - name: UP rules: - alert: node expr: up{job="node"} == 0 #监控状态是不是up for: 1m labels: severity: crirical annotations: description: " {{ $labels.instance }} of job of {{ $labels.job }} has been down for more than 5 minutes." summary: "{{ $labels.instance }} down,up=={{ $value }}" 5)重启prometheus服务 [root@localhost prometheus]# systemctl restart prometheus 6)测试 停止node_exporter [root@localhost ~]# systemctl stop node_exporter
企业微信告警:
import requests import sys import os import json import logging # python3 weixin.py hejinlin "test3" "test4" logging.basicConfig(level = logging.DEBUG, format = '%(asctime)s, %(filename)s, %(levelname)s, %(message)s', datefmt = '%a, %d %b %Y %H:%M:%S', filename = os.path.join('/tmp','weixin.log'), filemode = 'a') corpid='wwf1ac1cee' appsecret="9Gs05RZDEE38im3pYYP7VW" agentid="1000002" token_url='https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid=' + corpid + '&corpsecret=' + appsecret req=requests.get(token_url) accesstoken=req.json()['access_token'] msgsend_url='https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token=' + accesstoken touser=sys.argv[1] subject=sys.argv[2] #toparty='3|4|5|6' message=sys.argv[2] + "\n\n" +sys.argv[3] params={ "touser": touser, # "toparty": toparty, "msgtype": "text", "agentid": agentid, "text": { "content": message }, "safe":0 } req=requests.post(msgsend_url, data=json.dumps(params)) logging.info('sendto:' + touser + ';;subject:' + subject + ';;message:' + message)
2)Alertmanager配置 [root@localhost /usr/local/alertmanager]# cat alertmanager.yml global: resolve_timeout: 5m wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/' wechat_api_corp_id: 'ww73c38218513ba1e3' wechat_api_secret: 'hQevGrxnifRSsWPnKFVHnNVlAygVnTP_u1p6JbfIFIU' route: group_by: ['alertname'] group_wait: 10s group_interval: 10s repeat_interval: 1h receiver: 'wecat' receivers: - name: 'wecat' wechat_configs: - send_resolved: true to_party: '1' agent_id: '1000005' corp_id: 'ww73c38218513ba1e3' #to_uesr: 'ZhangYanFeng' api_url: 'https://qyapi.weixin.qq.com/cgi-bin/' api_secret: 'hQevGrxnifRSsWPnKFVHnNVlAygVnTP_u1p6JbfIFIU' inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance'] 3)配置prometheus主配置文件 [root@localhost /usr/local/prometheus]# cat prometheus.yml global: scrape_interval: 15s evaluation_interval: 15s alerting: alertmanagers: - static_configs: - targets: - 192.168.1.10:9093 rule_files: - "/usr/local/prometheus/rules/*.yml" scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'node' static_configs: - targets: ['192.168.1.6:9100'] - job_name: 'Alertmanager' static_configs: - targets: ['192.168.1.10:9093'] 4)配置告警规则 [root@localhost /usr/local/prometheus]# cat rules/up_rules.yml groups: - name: UP rules: - alert: node expr: up{job="node"} == 0 for: 1m labels: severity: crirical annotations: description: " {{ $labels.instance }} of job of {{ $labels.job }} has been down for more than 5 minutes." summary: "{{ $labels.instance }} down,up=={{ $value }}" 5)重启服务 [root@localhost ~]# systemctl restart prometheus [root@localhost ~]# systemctl restart alertmanager 6)测试
grafana:
mtail安装与使用:
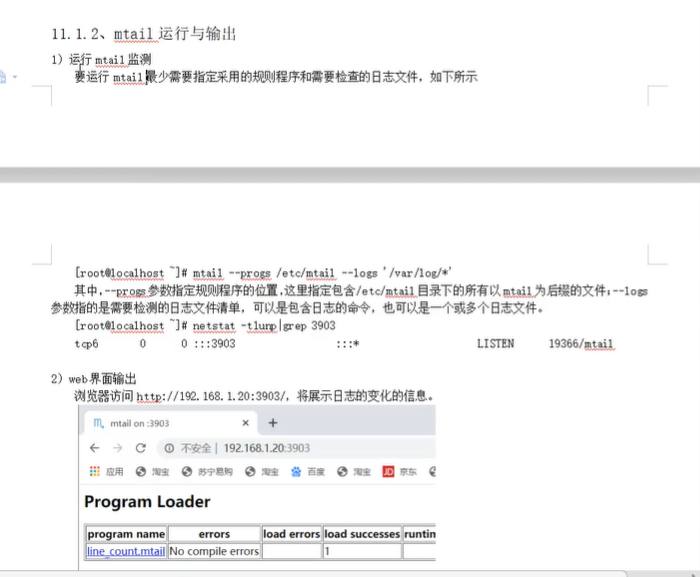
1)配置go环境 # 安装go运行环境,上传软件包 [root@localhost ~]# cd /opt/ [root@localhost opt]# ll go1.14.3.linux-amd64.tar.gz -rw-r--r--. 1 root root 123703837 May 30 03:41 go1.14.3.linux-amd64.tar.gz # 解压 [root@localhost opt]# tar zxvf go1.14.3.linux-amd64.tar.gz -C /usr/local/ #新建go项目根目录 [root@localhost opt]# mkdir -p /var/opt/wwwroot/goblog # 配置环境变量 [root@localhost ~]# vi /etc/profile export GOROOT=/usr/local/go export GOBIN=$GOROOT/bin export PATH=$PATH:$GOBIN export GOPATH=/var/opt/wwwroot/goblog [root@localhost ~]# source /etc/profile # 用go version验证安装结果,看输出版本 [root@localhost ~]# go version go version go1.14.3 linux/amd64 2)安装mtail [root@localhost ~]# cd /opt/ [root@localhost opt]# ll mtail_v3.0.0-rc35_linux_amd64 -rw-r--r--. 1 root root 15084336 May 30 03:48 mtail_v3.0.0-rc35_linux_amd64 [root@localhost opt]# mv mtail_v3.0.0-rc35_linux_amd64 /usr/bin/mtail [root@localhost opt]# chmod 0755 /usr/bin/mtail #用mtail --help验证是否正确 [root@localhost opt]# mtail --help 3)使用规则 二进制的mtail是通过命令行配置的,需要指定解析的日志文件清单和作用于这些日志的规则程序。 首先创建一个目录来存放mtail规则程序,一般通过配置管理模块来实现。创建存放目录/etc/mail,然后在该目录中增加以.mtail为后缀的规则程序文件line_count.mtail,这是一个简单的规则程序文件,当日志增加1行时line_count计数加1,示例代码如下: [root@localhost ~]# mkdir /etc/mtail [root@localhost ~]# cat /etc/mtail/line_count.mtail counter line_count /$/ { line_count++ } 文件中定义了一个line_count计数器,line_count前面是计数器名称的类型声明counter,如果是度量器就是guage。这些定义的计数器和度量器通过mtail作为终端展示给prometheus来抓取数据。因此在使用之前需要先定义计数器或度量器。