
elk7
es参数:
index.refresh_inteval 默认每隔1s统一处理一次新加入的文档。
index.refresh_interval 默认30s。如果索引在一段时间内没有收到检索数据的请求,至少要等30s后才会刷新索引数据。
创建索引
put alextest
查看索引
get alextest
{ "alextest" : { "aliases" : { }, "mappings" : { }, "settings" : { "index" : { "creation_date" : "1592978209842", "number_of_shards" : "1", 创建了一个分片 "number_of_replicas" : "1", 副本数为1 "uuid" : "iBCK1wB6T2Cg9nkwiAUnyw", "version" : { "created" : "7030099" }, "provided_name" : "alextest" } } } }
查看集群健康状态:
get _cat/health
1592978479 06:01:19 elasticsearch green 3 3 16 8 0 0 0 0 - 100.0%
或者 get_cat/health?v 会显示更加详细信息。
前两项为启动时间,第三项为集群名称。
green,所有数据正常状态
yellow,所有数据可访问,但一些副本还没有分配
red,集群部份数据不可访问。
查看所有索引
get _cat/indices
green open .kibana_task_manager g0uVudDaRJa1BvQva81Tdw 1 1 2 0 34.2kb 12.8kb green open filebeat-7.7.1-2020.06.19-000001 huhK4fKCRV6OevlYIftC0Q 1 1 0 0 566b 283b green open kibana_sample_data_logs QOhpuy3JTBWj-H_126O07g 1 1 14074 0 22.5mb 11.3mb green open filebeat-boss-2020.06.19 Jo7abqrMROC15sijk_Zxow 1 1 2 0 80.4kb 40.2kb green open alextest iBCK1wB6T2Cg9nkwiAUnyw 1 1 0 0 566b 283b green open kibana_sample_data_flights pT7UpoIeQ4-uLuj9DSPGTg 1 1 13059 0 12.9mb 6.6mb green open filebeat-ils-2020.06.19 aQAN8aqRSsuM0MzH4F2uzg 1 1 61 0 258.1kb 129kb green open .kibana_1 xAc3N1XxSIK1xbS2efIAsA 1 1 112 2 409.1kb 210.1kb
添加文档
可以用post或者put请求
put /alextest/_doc/1
{
"msg":"hello, world"
}
alextest是索引名称,_doc是索引的映射类型。1是文档编号,类似主键概念。
添加完,在es的形式为:
{
"_index": "alextest",
"_type": "_doc",
"_id": "1",
"_version": 1,
"_score": 0,
"_source": {
"msg": "hello, world"
}
}
查看文档:
get /alextest/_doc/1
{ "_index" : "alextest", "_type" : "_doc", "_id" : "1", "_version" : 1, "_seq_no" : 0, "_primary_term" : 1, "found" : true, "_source" : { "msg" : "hello, world" } }
logstash启动:
/usr/share/logstash/bin/logstash -e "input {stdin {}} output {stdout{}}" #最后会监听127.0.0.1:9600。 如果键盘输入helloworld会显示:
{ "host" => "k8s1", "message" => "helo", "@version" => "1", "@timestamp" => 2020-06-24T07:51:46.588Z }
默认stdout输出插件使用rubydebug,所以输出内容中包含了版本,时间等信息。
如果改成plain或line,则输出结果发生变化:
/usr/share/logstash/bin/logstash -e "input {stdin {}} output {stdout{codec=>plain}}"
2020-06-24T07:57:09.485Z k8s1 hello world
/usr/share/logstash/bin/logstash -e "input {stdin {}} output {stdout{codec=>line}}"
2020-06-24T07:58:01.608Z k8s1 helo
通过配置启动:
cat std_es.conf
input { stdin {} } output { elasticsearch { hosts=>{"http://xxx:9200"} index=>"alexstdin" } }
/usr/share/logstash/bin/logstash -f /etc/logstash/std_es.conf
然后输入随意内容。
进kibana查看:
get _cat/indices #alexstdin索引已经创建
get /alexstdin/_search #返回刚才随意输入的内容
-----------------------------------------------------------------------------------------------
filebeat:
cat /etc/filebeat/filebeat.yml
filebeat.inputs: - type: log enabled: true paths: - /root/elk/*.log output.logstash: hosts: ["localhost:12345"]
logstash也做相应更改:
cat /etc/logstash/beats_es.conf
input { beats { port =>12345 #logstash会监听0.0.0.0:12345 和 127.0.0.1:9600 } } output { elasticsearch { hosts => ["http://elasticsearch.efk.192.168.219.105.xip.io:80/"] index => "es_logs" } }
启动logstash:
/usr/share/logstash/bin/logstash -f /etc/logstash/beats_es.conf
启动filebeat:
systemctl start filebeat
去kibana验证:
get _cat/indices
get /es_logs/_search
p28
2.1.3索引
es参数
默认情况下es会每隔1s统一处理一次新加入的文档,可以通过index.refresh_inteval参数修改
es7中还有index.search.idle.after参数。默认值是30s。如果索引在一段时间内没有收到检索数据的请求,至少要等30s后才会刷新索引数据。
所以新添加到索引中的文档,有可能在一段时间内不能被检索到。如果要立即检索到文档,有强制刷新到索引的方式
例如_refresh接口和操作文档时使用refresh参数。但会对性能造成影响。
2.1.4 es的映射。
2.2.1字段索引
分析词项
get _analyze
{"analyzer":"standard","text":"elasticsearch is a search engine"}
analyzer standard为标准分析器
2.2.2字段存储
索引提供了一个_source字段用于存储整个文档的原始值。这个字段在默认情况下是不会被索引的。但每个查询默认都会带着_source字段返回。
2.3 字段数据类型
2.3.1核心类型
1.字符串类型,text和keyword两种类型。text会做词项分析,不能做整体检索。keyword不会词项分析,能做整体检索。
text类型适合存储全文数据,比如日志信息,文章,邮件等。
keyword适合存储结构化的文本数据,如邮编,地址,电话。
text类型不支持文档值机制(文档值机制见2.2.2字段存储),所以text类型不能文档排序,过滤,聚集等操作,除非打开它的fielddata机制。
2.数值类型。
long 64位整型
integer 32位整型
short -32768 ~ 32767
byte -128 ~ 127
double 双精度浮点 64位
float 单精度浮点32位
half_fload 半精度浮点 16位
sacled_float 基于long类型的浮点数,值取决于scaling_factor (存储采用long类型。用个换算系数放大保存)
例如3.14换算系数为100,则换算结果为3.14x100=314,最终保存值就是314.适合存储货币金额等固定小数位
例如:
put my_index { "mappings":{ "properties":{ "price":{ "type":"scaled_float", "scaling_factor": 100 } } } }
3.日期类型
date和date_nanos。他们都会转换位日期与计算机纪元1970年1月1日0点的时间差值。
date按毫秒计算差值
date_nanos按纳秒计算差值。
elasticsearch实际使用long类型保存这个差值,所以date_nanos类型能够保存的时间最多只能到2262年。
日期类型的格式要求,默认使用iso8601的标准时间格式,“yyyy-MM-ddTHH:mm:ss”
默认格式也支持使用毫秒数直接表示日期
4.布尔类型
布尔类型的关键字是boolean,只有两个值true和false。也接收以字符串的”true“和”false“
5.字节类型。
字节类型接收以base64编码后表示的二进制字节流。字节类型字段在默认情况下不会被存储,也不会被检索到。
6.范围类型
数值,日期或ip地址的范围。添加文档时可以使用gte,gt,lt,lte。
数值范围类型包括integer_range,float_range,long_range,double_range.
日期范围类型和ip范围类型分别为date_range和ip_range
例如
put students { "mappings":{ "properties":{ "age_range": { "type":"integer_range" } } } } post students/_doc { "age_range": {"lt":23, "gte":7 } } post students/_search { "query":{ "term": { "age_range":{"value":10} } } }
2.3.2衍生类型
包括数组和对象两种。
1.数组. 数组中的元素必须同一种类型,或者至少可以转换为同一种类型。
put person/_doc/1 { "relation":["12","2"] }
上面的数组虽然是字符串的数组,但由于可以转换为整型,所以可以赋值给整型字段。
2.对象
put colleges/_doc/1 { "address":{ "country":"cn", "city":"bj" } }
2.3.3多数据类型
文章的标题,多数情况下通过词项做检索。但有时标题很短,如果标题字段设置位text类型,那么就会提取词项而不能使用整个标题做检索,而如果设置为keyword则不能使用词项做检索。
所以针对这两个text和keyword,es专门提供了一个用于配置字段多数据类型的参数fields。能让一个字段同时具备两种数据类型的特征。
例如:
put articles { "mappings":{ "properties":{ "title":{ "type":"text", "fields":{ "raw": { "type":"keyword" }, "length":{ "type":"token_count", "analyzer":"standard" } } } } } }
title字段被设置为text。同时通过fields参数又为该字段添加了两个子字段。
其中一个子字段名称为raw。类型被设置为keyword。另一个子字段为length,类型为token_count。
使用fileds设置的子字段,添加文档时不需要单独设置值,他们与title共享相同的字段值,只是会以不同方式处理字段值。同样,在检索时,他们也不会单独显示在结果中。所以他们一般只是在检索中以查询条件的形式出现。
默认情况下,如果么有明确定义字符串类型时,添加到索引中的字符串都会以这种形式设置为多类型。
2.4分片与复制
2.4.1分片shard
get _nodes
创建了es集群后,就需要确定索引分片的数量。一般会均匀地分散到集群的不同节点上。
索引的分片数量是在创建索引时通过number_of_shards参数设置的。
put /test { "settings":{ "number_of_shards":10 } }
2.4.3容量规划
为了避免重新索引导致的性能开销。es对索引分片数量做了一个严格的限制。
索引分片数量一旦在创建索引时确定后就不能再修改。
可以看看3.1.1接介绍的_rollover接口,以滚动别名的方式给出解决这种问题。
还有一种可行的办法就是创建新的索引,再将原索引中的文档存储到新的索引中。_split _shrink _reindex接口。这三个接口通过创建新索引的方式间接改变索引容量,性能上比手工创建索引和复制文档要好一些。可以看3.3节。
2.4.4副本
默认情况下,es为每个索引设置了一个副本分片。意味着集群中应该至少两个节点。
索引的副本分片数量由number_of_replicas参数设置:
put /test { "settings":{ "number_of_shards":10, "number_of_replicas":2 } }
查看:
get _cat/shards
test索引的主分片为10个,每个主分片有2个副本分片,所以总共是30个分片。
还可以根据节点数量使用auto_expend_replicas参数动态扩展副本分片。
参数格式为from - to 1-10代表副本分片数量是1-10个。 0-all中all代表所有节点数量。
与主分片不同,副本分片的数量在索引双剑之后可以随时动态更改,见3.1.2节
12章logstash结构与配置
12.1.1 logstash插件
logstash-plugin list
logstash-plugin --installed
logstash-plugin list --verbose
logstash-plugin list '*log4j*'
logstash-plugin list --group output
安装插件:
logstash-plugin install logstash-output-jdbc
logstash-plugin instlal /xxx/xxx/logstash-output-jdbc-0.0.1.gem
更新插件:
logstash-plugin update
logstash-plugin update logstash-output-jdbc
删除插件:
logstash-plugin remove logstash-output-jdbc
生成插件:
logstash-plugin generate --type input --name first --pach c:/
插件配置:
对于deb或rpm安装的logstash,配置文件在/etc/logstash目录
使用docker镜像启动的logstash,配置位于/usr/share/logstash/config中
管道的配置文件:
1.logstash命令-e配置管道
2.使用deb或rpm装的logstash,管道配置文件在/etc/logstash/conf.d中
3.用docker启动的logstash,位于/usr/share/logstash/pipeline logstash启动时会自动扫描这个目录,并加载所有的.conf结尾的配置文件。
12.1.2事件
1.访问事件属性
[name]代表访问时间的name属性。
嵌套属性使用多层次路径 [parent][child]相当于访问parent.child属性。
除了使用方括号访问事件属性以外,还可以通过"%{ field_name }"形式访问事件属性。
例如:
output { file { path=>"/var/log/%{loglevel}.log" } }
12.1.3队列
logstash默认队列使用基于内存的事件队列。
1.持久化队列:
持久化队列将输入插件发送过来的事件存储在硬盘中,只有过滤器插件或输出插件确认已经处理了事件,持久化队列才会将事件队列从队列表中删除。
如果要开启持久化队列,logstash.yml将queue.type设置为persisted。 默认值是memory。
队列数据默认存储在logstash数据文件路径的queue目录中。存储路径可以通过参数path.queue修改。
持久化队列容量可通过事件数量和存储空间大小两种方式来控制。
默认情况下队列容量为1024mb和1GB,而事件数量则没有设置上线。
事件数量容量可通过queue.max_events修改。存储空间容量通过queue.max_bytes来修改。
12.2.1主管道配置
logstash.yml中配置的管道是主管道。
其他管道在pipline.yml中配置。pipeline.yml中的管道与主管道互斥。如果在logstash.yml文件中或是使用命令行-e,-f参数配置了主管道,那么pipeline.yml文件中配置的其他管道就会被忽略。只有主管道缺失,logstash命令才会尝试通过pipeline.yml初始化其他管道。
pipeline.id:main #用于设置管道的id,对应logstash命令参数为--pipeline.id
pipeline.workers:2 #设置并发处理事件的线程数量,默认和cpu核数相同。对应命令参数为--pipeline.works
pipeline.batch.size:125 #每个工作线程每一批处理事件的数量,每125个事件统一处理一下
pipeline.batch.delay:50 #工作线程处理事件不足时的超时事件 (50毫秒,每50ms统一处理一下时间)
pipeline.unsafe_shutdown:false #如果还有未处理完的事件,是否立即退出。默认情况logstash会将未处理完的事件全部处理完再退出。如果设置未true会因为强制退出而导致事件丢失。
config.test_and_exit:false #检查配置文件后退出 命令行-t
config.reload.automatic:false #自动加载配置文件的变化 命令行-r
config.reload.inteval:3s #扫描配置文化变化的时间间隔
logstash处理事件是先缓存125个事件或超过50ms后再统一处理。由于使用了缓存机制,所以logstash管道因意外崩溃会丢失已缓存事件。
12.2.2单管道配置:
1.语法格式
只需要运行一个管道可以使用logstash.yml配置的主管道
而在需要运行多个管道时才会使用pipeline.yml

2.数据类型
数值型包括整型和浮点型。
布尔型包括true和false
字符串需要双引号。
数组和列表使用[ ]
散列类型使用 { }将一组键值对组成的对应关系配置给参数

默认情况,参数值不支持转义字符。参数值中包含"\r"会被转译成"\\r"而不是回车符。
如果需要再参数中使用转义符,需要logstash.yml文件中config.support_escapes参数设置为true
3.分支语句
用户希望根据事件自身的一些特征将它们发送给不同的目标数据源。
提供了if , else if 和 else语句来实现分支控制
if expression {
} else if expression {
} else {
}
分支语句表达式的操作符:
关系运算==,!=, <, >, <=, >=
正则表达式=~, !~ #左值为字符串,右值为正则表达式
包含运算in, not in #运算左值是否包含在右值中
逻辑运算 and, or, nand, nor, !
可以使用小括号( ) 提升优先级或分组。
例子:根据事件的tag属性设置了不同的aggregate过滤器插件:

12.2.3多管道配置
配置单进程多管道的logstash是通过pipeline.yml文件实现的
pipeline.yml通过config.string或path.config参数以配置字符串或配置文件的形式为每个管道设置独立的配置信息。
在启动logstash时,如果没有设置主管道信息,logstash读取pipeline.yml文件以加载管道配置信息。
示例:

配置了2组管道,唯一标识分别是test和another_test。
test管道使用config.string直接设置了管道的插件信息。
another_test则通过path.config指定了管道配置文件的路径。
pipeline.yml还可以使用配置队列和死信队列的参数,只是这些参数都只对当前管道有效。
12.3编解码器插件
12.3.1plain编解码器
plain编解码器在编码和解码的过程中没有定义明确的分隔符用于区分事件。
而line编解码器则定义了以换行符作为区分事件的分隔符,每读入一行文本就会产生一个独立的事件。而每输出一个事件也会在输出文本的结尾添加换行符。
除了plain和line编解码器以外,json编解码器也是另一种常用的编解码器。

plain编解码器使用起来非常简单,只有charset和format两个参数。
charset用于设置文本内容采用的字符集,默认为utf-8
format用于定义输出格式,只能用于输出插件中。format参数定义输出格式时,采用%{ }形式,例如:

12.3.2line编解码器
解码时,每一行都有可能成为一个独立事件
编码时,每个事件输出结尾都会添加换行符。
以行为单位的编解码器有line和multiline两种。
linue编解码器默认以换行符"\n"作为行结束符。但windows系统中行结束符是\r\n,而不是\n
所以在win系统中使用line编解码器时,输入事件的消息中都会以\r结尾。如果想从消息中去除\r,就需要将换行符修改为\r\n。这可以通过line编解码器的delimiter参数来修改。需要在logstash.yml中之恩加一个配置参数config.support_escapes作为是否支持转义字符的开关,需要设置为true才可以生效。
同时修改管道配置中文件输入插件的delimiter参数为\r\n ,例如:
input {
stdin {codec => line {delimiter=>"\r\n"}}
}
multiline编解码器适合处理java异常:
codec => multiline {
pattern => "^\["
negate => true
what => "previous"
}
pattern和negate两参数共同决定什么文本需要被合并,negate参数用于设置对patter定义的正则表达式取反。
上面的两个参数的含义就是所有不满足”^\[“正则表达式的行都需要被合并,而合并到哪里则由桉树what来决定。
what参数有previous和next两个可选值,前置将需要合并行与前一个事件合并,后者则会将需要合并行与下一个事件合并。multiline可用配置参数见下表:
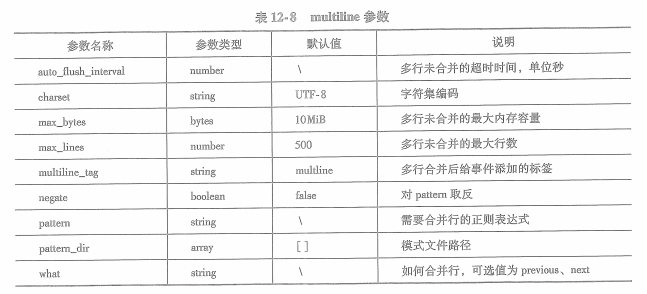
12.3.3json编解码器
在输入时从json格式的数据中将消息解析出来生成事件,输出时将事件编码为json格式。
如果json编解码器在解析json时出错,logstash会使用plain编解码器将json视为纯文件编入事件,同时会在事件中添加_jsonparsefailure标签。
json编解码器只有一个参数charset,用于设置json数据字符集,默认utf8
13章 输入输出插件
最简单的两个插件stdin插件和stdout插件
分别代表标准输入和标准输出,也就是命令行控制台。不需要任何配置就可以直接使用。
stdin只有一组通用参数,这些参数不仅对stdin有效,对其他输入插件也有效。
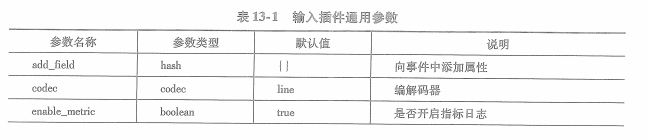

stdout也是通用参数。对所有输出插件有效:

13.1 beats与elasticsearch插件
13.1.1beats插件
logstash只要通过port参数指定logstash监听beats组件的端口即可。例如logstash监听beats组件的端口被设置为5044:
input {
beats {
port => 5044
}
}
同时,beats组件也需要在他的配置中输出类型为logstash,并配置连接端口为5044.
beats组件想logstash输入事件时,默认会在@metadata属性中添加三个子属性即为 beat,version和type。分别代表了beats组件的名称,版本和类型。他们可以在输出组件为es时设置索引名称。
一般设置为”%{[@metadata][beat]}-%{[@metadata][version]-%{+YYYY.MM.dd}}“
beats输入插件其他参数大部分都与安全连接相关:
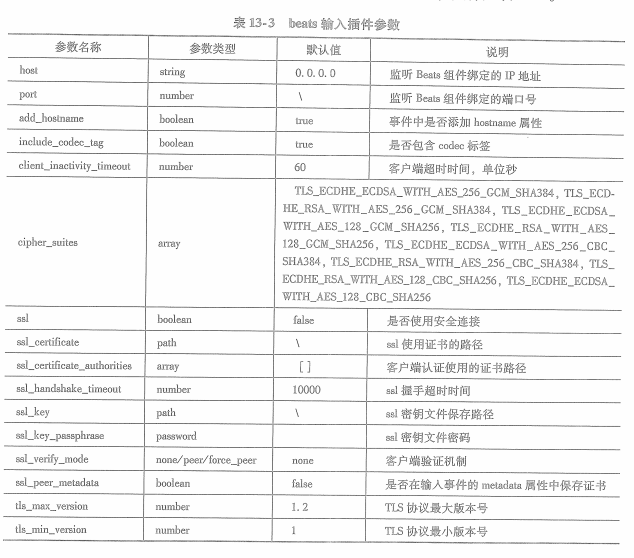
13.1.2 es插件
es既可以作为logstash的输入也可以作为输出。多数情况下时作为输出使用。
es输出插件使用hosts参数设置连接es实例的地址,hosts参数可以接收多个es实例地址,logstash在发送事件时会在这些实例上做负载均衡。
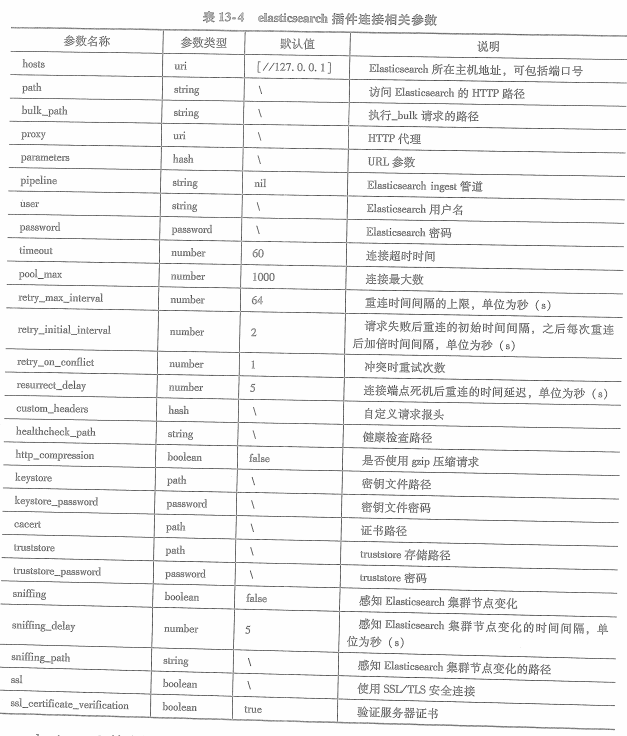
elasticsearh输出插件对logstash事件转换为对es索引的操作,默认情况下插件会将事件写入名称为”logstash-%{+YYYY.MM.dd}“索引中,可使用index参数修改索引名称格式。
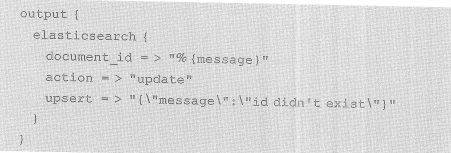
es输出插件还支持根据id删除文档,更新文档等操作,具体可以通过action参数设置。
action可选参数包括index,delete,create和update几种,其中index和create都用于向索引中编入文档,区别在于create在文档存在时会报错,而index则会使用新文档替换原文档。delete和update用于删除和更新文档,所以使用delete,update,create时需要通过document_id参数指定文档id。
如果update在更新时文档id不存在,可以使用upsert参数设置添加新文档的内容,例如:
13.2面向文件的插件
从文件读取数据并转换为事件转入logstash管道
从logstash管道事件转换为文本写入到文件中。
面向文件的输入输出插件名称都是file,都需要通过path参数设置文件路径。
输入插件的path参数类型是数组,可以指定一组文件作为输入源头。
输出插件的path参数为字符串,只能设置一个文件名称。
输入插件path参数只能用绝对路径不能使用相对路径,可以使用*或者**这样的通配符。
输出插件可以使用相对路径,并且可以在路径中使用 ”%{ }“的形式动态设置文件路径或名称。
例如:
path => "/logs/log-%{+YYYY-MM-dd}.log" 每日生成一个文件。
13.2.1事件属性
文件输入插件产生的输入事件中包含一个path的属性,记录来自哪个文件。
默认情况下,文件输入插件以一行结束标识一个输入事件,message属性中会包含换行符前面的所有内容。
也可以通过插件的编解码器设置为multiline
13.2.2读取模式
文件输入插件默认从文件结尾处读取文件的新航。称为尾部读取模式 tail mode
如果要配置从文件开头读取,称为全部读取模式Read mode.如果使用全部读取模式读到eof就意味着文件已经结束,文件输入插件会关闭文件并将其设置为”未监视“状态以释放文件。参数file_completed_action可以设置文件读取结束后的释放行为,可选值为delete,log和log_and_delete。默认行为是删除文件即delete。如果选择log或log_and_delete,还需要使用file_complted_log_path参数指定一个日志文件及路径,文件输入插件会将已经读取完的文件及其路径写入到这个日志文件中。对于log_and_delete来说,则会先写日志再将文件删除。

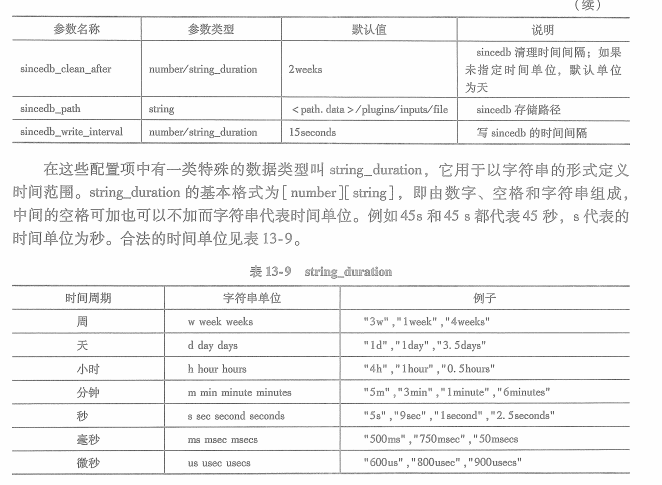
13.2.3 sinceDB文件
已经读取过的文件内容都不应该再次读取。
默认情况下,sinceDB文件放置在logstash安装路径的data目录下,具体是plugins/inputs/file
sinceDB文件与文件输入插件的path参数相关,一个path值对应要给SinceDB文件,机使path参数使用数组定义了一组路径也只对应一个SinceDB文件。更改path参数会导致新的sinceDB文件生成,所以这将导致文件更名之前所有的文件读取位置信息全部丢失。如果因业务需求path参数必须要做修改,可以使用sincedb_path参数锁定sinceDB文件。对于path参数必须使用不同的sincedb_path,并且必须要指定到具体文件名而不能只是路径。

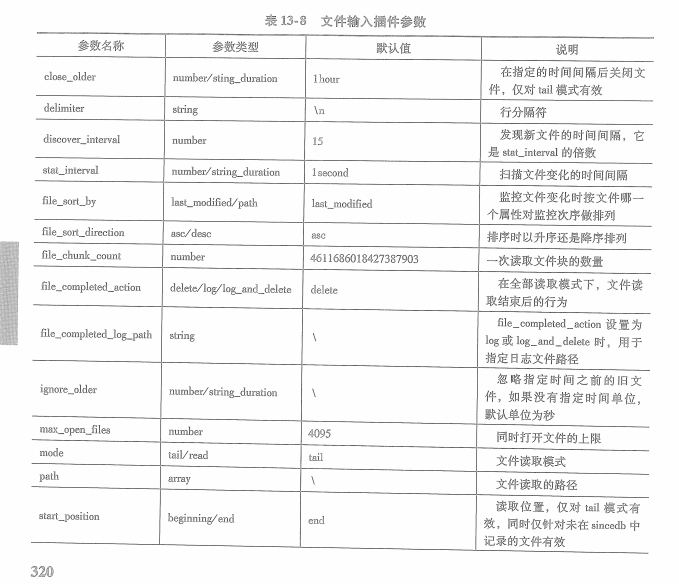
13.2.5文件输入插件的配置参数:
13.2.6文件输出插件

第14章 过滤器

14.1.1 grok过滤器
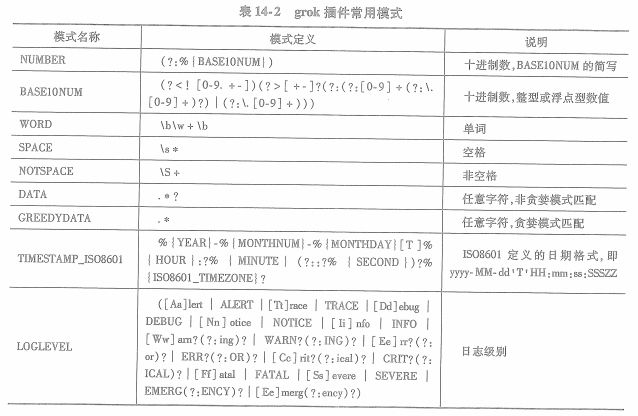
1.预定义模式:
使用grok过滤器需要遵从语法规则:
%{ syntax:semantic } syntzx为模式名称,semantic为存储匹配内容的事件属性名称
把想匹配的一段数字存储到事件的age属性上,则为 %{NUMBER:age}
2.自定义模式
语法为(?<属性名>模式定义)
例如定义邮编模式为6位数字,并提取后存到postcode属性上
(?<postcode>\d{6})
3.match参数
match参数接收一个由事件属性名称及其文本提取规则为键值对的哈希结构。
grok过滤器会根据match中的键读取相应的事件属性,然后再根据键对应的提取规则从事件属性中提取数据。
例子:
原材料如下:

现在将时间,日志级别,logger名称和日志内容提取出来:
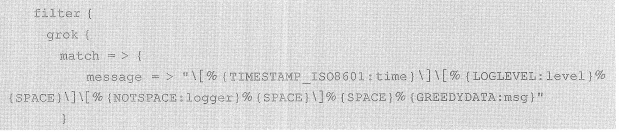
上面的例子,match参数的类型为散列,只包含一个条目。这个条目以message属性为键,对该属性的提取规则为值。其中%{ LOGLEVEL:level }使用了LOGLEVEL预定义模式匹配文本,并将匹配结果添加到事件的level属性。
在匹配失败时会给事件打上_grokparsefailure标签。
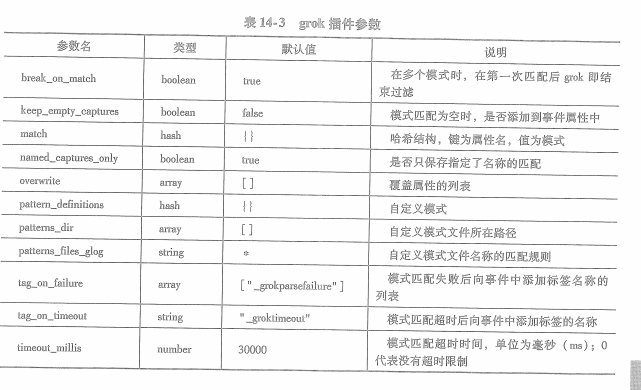
grok其他参数:
14.1.2dissect过滤器
它使用用户自定义的分隔符切分文本,然后再将切分后的文本存储到事件属性上。
定义一个切分单元的格式为 %{field}。field在一般情况下是事件的属性名称
%{field1}/%{field2} 一共定义了两个切分单元。符号/ 位于两个切分单元之间,所以被认为是切分文本的分隔符。
1.mapping参数
mapping参数也是哈希类型。与match参数类似。mapping参数的键为需要切分的属性名称,而值为切分规则。

dissect过滤器会按分隔符的顺序一次切分文本。切分后的文本会存储到事件属性上,在后续过滤器中,这些属性就可以参与其他处理了。
2.特殊符号
在上面的例子中,年月日分别保存到year,month,date三个属性中。如果希望它们合并到一个属性time中,就必须要用到一些特殊字符。
在dissect过滤器的切分单元中,可以使用? + & / "->"等特殊号,这些符号都是在%{field}中与field一起使用。
例如%{?field} 代表切片单元提取出来后不会出现在事件属性上。
&符号代表切片单元保存提取内容的属性名称为另一个属性的值。
例如 response: 200 - ok,定义如下dissect过滤器:

%{?code}切分单元会将文本中的200提取出来并保存在code属性上,虽然使用?号使得这个属性不会出现在最终的事件上,但在dissect过滤器内部这个属性还是可以使用的。所以后面的%{%code}切分单元会将ok提取出来,而保存提取内容的属性名称则是code属性保存的值200. 所以在最终的事件中将出现一个名为200的属性,它的值为ok
+的用法,主要作用是将切分单元提取出来的内容合并到其他属性上。而 / 也经常与 + 一起使用,用于指定切分单元合并的次序。使用这两个符号就可以将前面提到的logstash日志存储文件名称中的年月日合并到一个属性中了。
例如:

年月日被合并到time属性上,他们的合并次序由属性名称后的数值表示。如果不指定次序,则他们按照在配种中次序依次合并。
->的用法,不需要指定空格数量而会将所有连续空格剔除。需要注意的是,如果使用了->则需要切分的文本就必须实际存在补齐的空格,否则在切分文本时会报错。
例如:

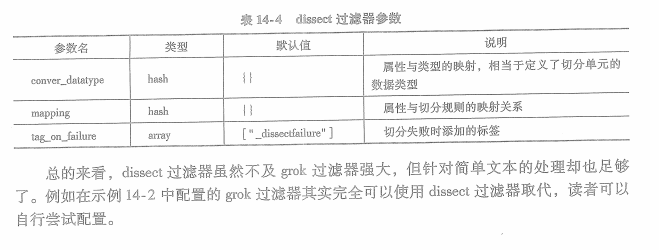
dissect过滤器有三个参数:
14.2处理半结构化文本
比如json,xml,csv等
14.2.1json过滤器
json过滤器从属性中读取json字符串,然后按json语法解析后将json属性添加到事件属性上。所以json插件有一个必须要设置的参数source,指定插件从哪一个事件属性中读取json字符串。
例如:
filter {
json {source => "message"}
}
默认情况下,json过滤器解析后的json属性会添加到事件的根元素上,可通过配置过滤器target参数将他们添加到其他事件属性中。解析失败时,事件被打赏_jsonparsefailure标签。如果json中摆好@timestamp属性,json过滤器将使用json中的@timestamp属性覆盖事件的@timestamp属性。如果@timestamp解析失败,事件会将@timestamp重命名为_@timestamp,并将事件打赏_timestampparsefailure标签。
json过滤器有四个参数:

14.2.2 xml过滤器
14.2.3 csv过滤器
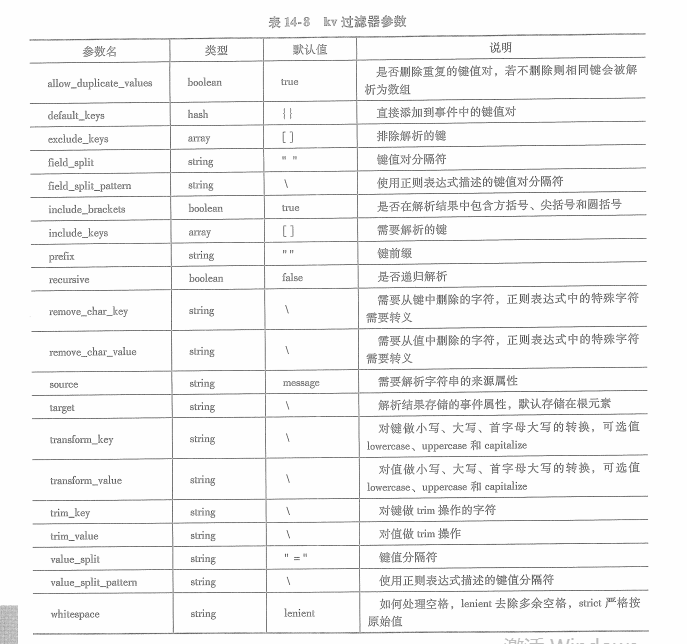
14.2.4 kv过滤器
用于解析格式为 key=value键值对。多个键值对可以使用空格连接起来,使用field_split或field_split_pattern可以定制连接对的分隔符。kv过滤器默认会从message属性中取值并解析,解析后的结果会存储在事件的根元素中。
例如: username=root&password=root

14.3 事件聚集
aggregate过滤器可以将多个输入事件整合到一起,形成一个新的,带有总结性质的输入事件。
14.5 数据转换
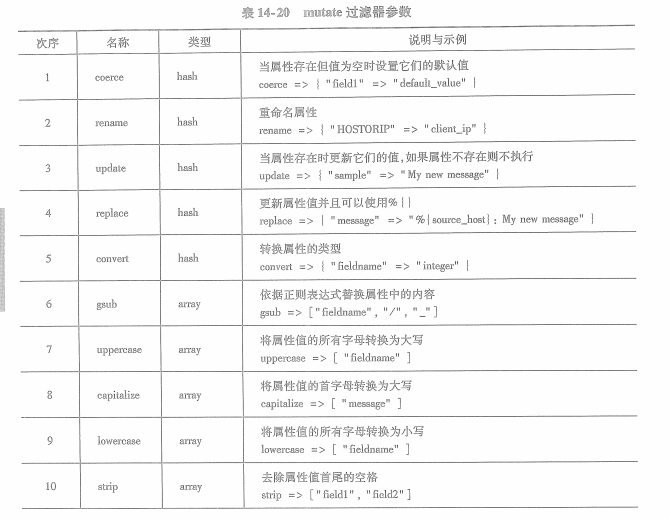
14.5.1 mutate过滤器
mutate过滤器定义了一组对事件属性做变换的行为。比如设置属性初始值,删除属性,修改属性,重命名等。
这些行为定义在mutate过滤器中,按照预定义的顺序执行;如果希望他们按自定义的顺序执行则需要将他们定义在不同的mutate过滤器中。

14.5.4 date过滤器
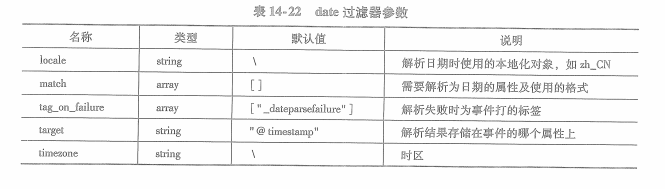
date过滤器取事件某一属性解析为日期或事件,解析结果将作为事件的时间戳(@timestamp)保存起来。
date过滤器核心配置项为match,它接收字符串列表类型,列表的第一个元素为需要解析为时间的事件属性名称,
其余元素均可以是时间的格式。

如果不想将解析后的时间存储为事件的时间戳,则可以通过target参数将解析结果保存到其他属性上。
14.6数据添加与删除
14.6.5删除
drop用于删除整个事件,prune用于删除事件中的单个属性。


在上面的例子中,blacklist_names设置了需要删除属性的名称,所以在最终输出的事件中将不包含message和host属性。
15章 beats的原理和结构
15.1.1处理器
处理器种类:
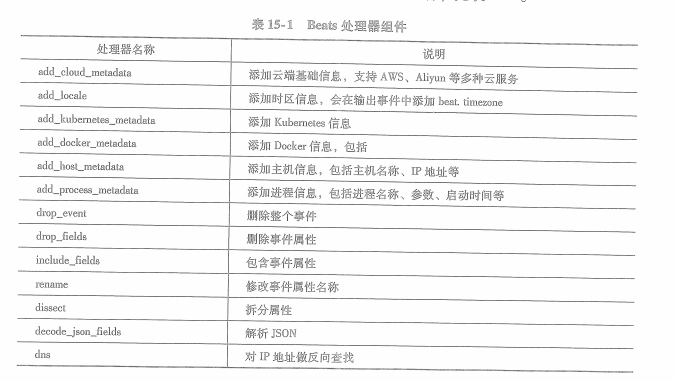
15.2 beats处理器
处理器配置格式:

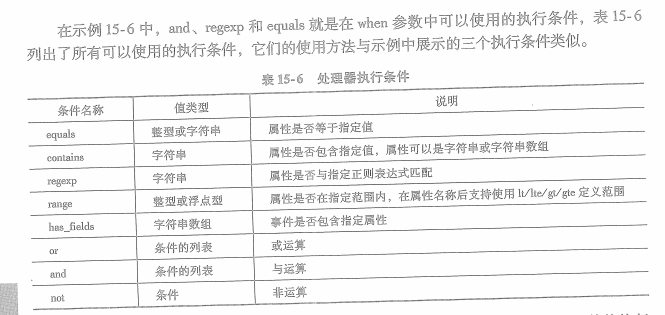
所有处理器都包含一个when参数,用于定义处理器的执行条件。
如果没有定义执行条件,则处理器总会执行。
例子: 处理器的执行条件使用了逻辑与运算,而参与逻辑与运算的两个条件分别是正则表达式和等于。
当message属性以 【 开头并以 】 结尾,并且input.type属性为stdin时,向事件添加formattedMsg属性

15.2.1添加逻辑信息
1.add_fields
可以向事件添加额外的属性。默认会被添加到fields属性下,也可以通过target参数来配置添加位置。
如果要将属性添加到根元素下,则将target参数设置为空,即target: ''
向事件中添加额外属性可通过add_fields.fields参数来配置,可按键值对形式配置多个:

上面添加了两个add_fields处理器,第一个处理器添加了一个log属性到事件根元素上。
第二个处理器同样也添加了log属性 ,但这个属性会被添加到fields属性下。
第二个处理器添加的另一个属性是service,这个属性最终会以json对象的形式添加到fields属性中。
如果新添加的属性在实践中已经存在,那么add_fields将覆盖原来的属性值。
上例中,由于第一个处理器的log在事件中已经存在,那么原事件中的log属性就会被覆盖。
beats组件还有另外两个更为通用的配置项
fields和fields_under_root。也用于向事件中添加属性。例如:


2.add_tags
用于向事件添加标签,标签是一组字符串。默认情况下标签会被添加到事件的tags属性中,tags属性是一个包含了多个字符串的数组。标签添加的属性可通过target参数来设置,而需要添加的标签则通过tags参数设置:

标签只能添加到某一属性中,不能添加到根元素上。所以不能用target: ''
另外与add_fields类似,beats组件也有一个tags参数用于添加通用标签。
tags参数设置的标签内容只能添加到tags属性中,add_tags设置标签最终会与tags参数设置的标签合并起来。
3.add_labels
用于向事件添加标注label。标注与标签(label vs tag)区别在于标注label是一组键值对,而标签tag是一组字符串。
标注只能被添加到事件的labels属性中,而不能添加到别处。
add_labels只有一个参数labels,用于设置希望向事件中添加的标注,例如:

上面添加了两个标注,log和service
但service属性在配置时虽然使用对象形式,但他们在添加到labels属性后会被平铺为service.name和service.author两个属性。
15.2.2添加基础信息
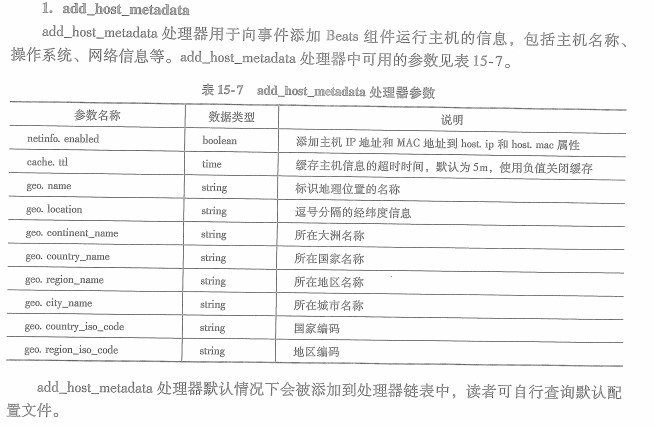
1.add_host_metadata
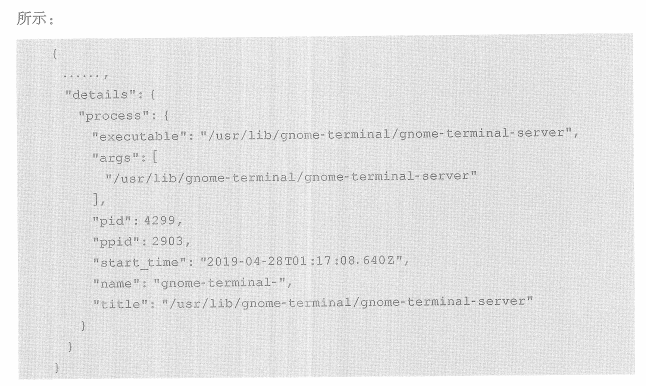
2.add_process_metadata

15.2.3添加云信息
1.add_cloud_metadata
用于向事件中添加云服务的元数据,这些有关云的元数据将会存储在事件的cloud属性上。
目前支持aws,aliyun,google,tencent,azure,openstack,digital ocean
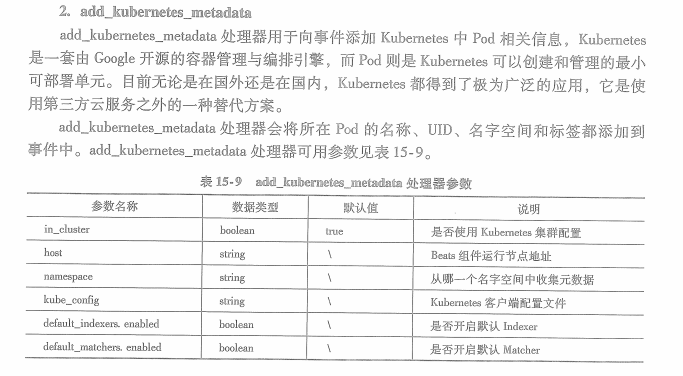
2.add_kubernetes_metadata
3.add_docker_metadata

15.2.4删除数据
1.drop_fields
用于从事件中删除一个或多个属性,需要删除的属性通过该处理器的fields参数定义。有两个属性不能删除,是@timestamp和type

2.include_fields
通过定义需要输出的属性来排除其他属性。比如只包含message属性:

3.drop_event
在满足一定条件下删除整个事件。

15.2.5转换数据
1.rename
用于修改属性名称

2.dissect
用于根据定义的文本内容做拆解,拆解出来的字符串会根据模式定义的名称存储到相应的属性上。
dissect拆解字符串使用的模式由tokenizer参数定义,在模式中可以使用 &{ fields } 格式定义拆解字符串的单元。
例子:message属性以空格为分隔符拆解,提取出来的字符串最终会存在事件根元素下的command, action, argument三个属性上

3.decode_json_fields
用于解析json字符串,并将json字符串转换为事件的JSON对象。这个处理器从fields参数指定的属性中读取json字符串,然后将他们解析成json对象后存储在target参数指定的属性上。
例子:处理器会将message属性解析为json对象,并将json对象存储在事件的user元素上

15.3beats输出组件

输出到elasticsearch:

16章beats采集数据
16.2文件数据
16.2.1输入类型
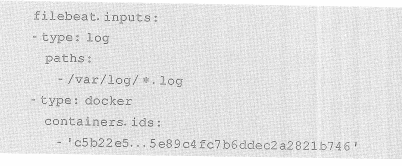
输入类型通过filebeat.inputs参数开启,他是一个list类型的参数,可以接收多个相同或不同类型的输入组件。
每个输入组件有一个type参数用于设置输入组件的类型。
下例开启了log和docker两种类型的输入:
1.log输入类型
用于收集文件中的日志数据。
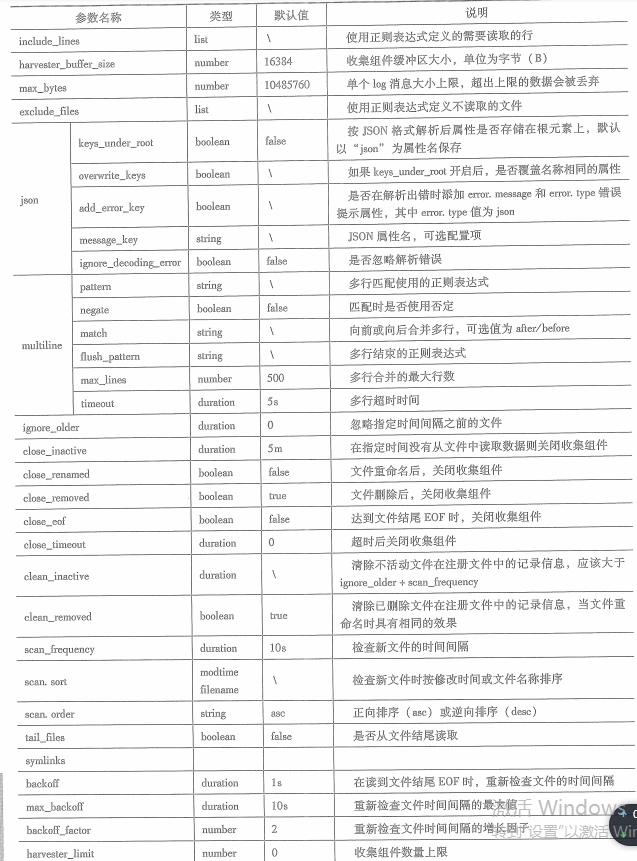
必选参数paths,用于设置日志文件所在路径。参数类型为list。

2.docker输入类型
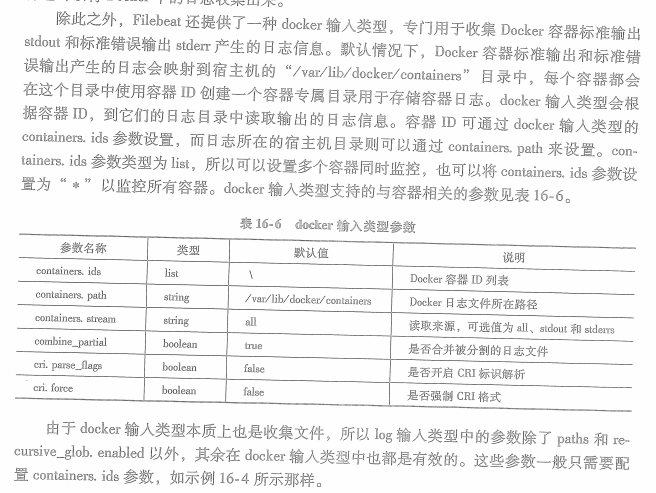
使用sql:
https://www.elastic.co/guide/en/elasticsearch/reference/7.3/sql-rest-format.html
POST /_sql?format=json
{
"query": """select onlyerror,count(onlyerror) as cnt from "filebeat-7.3.0-*" group by onlyerror"""
}
format可选csv,json,tsv,txt,yaml
POST /_sql?format=json
{
"query": """select onlyerror,message from "filebeat-7.3.0-*" where onlyerror='true' limit 1 """
}
POST /_sql?format=txt { "query": "SELECT * FROM library ORDER BY page_count DESC", "filter": { "range": { "page_count": { "gte" : 100, "lte" : 200 } } }, "fetch_size": 5 }
把sql解析为dsl:
POST /_sql/translate { "query": """select onlyerror,message from "filebeat-7.3.0-*" where onlyerror='true' limit 1 """ }
select语法:
https://www.elastic.co/guide/en/elasticsearch/reference/7.3/sql-syntax-select.html
支持的sql功能大全:
https://www.elastic.co/guide/en/elasticsearch/reference/7.3/sql-functions.html
结尾

