
postgresql笔记
查看有哪些索引和建索引的语句:
select * from pg_indexes where tablename='student_class_hour_report_view';
-- 查出所有物化视图和表,索引大小并排序:
SELECT
inet_server_addr() AS instance_address,
table_catalog AS database_name,
table_schema AS schema_name,
table_name,
pg_size_pretty(pg_table_size(table_full_name)) AS table_size,
pg_size_pretty(pg_indexes_size(table_full_name)) AS index_size,
pg_total_relation_size(table_full_name) AS total_size,
table_type
FROM (
SELECT
('"' || table_schema || '"."' || table_name || '"') AS table_full_name,
table_catalog,
table_schema,
table_name,
table_type
FROM information_schema.tables
WHERE table_schema NOT IN ('pg_catalog','information_schema','topology','tiger','tiger_data') and table_type='BASE TABLE'
UNION ALL
SELECT
('"' || schemaname || '"."' || matviewname || '"') AS table_full_name,
current_database() AS table_catalog,
schemaname AS table_schema,
matviewname AS table_name,
'MATERIALIZED VIEW' as table_type
FROM pg_matviews
) AS all_tables
ORDER BY total_size DESC;
--查物化视图的死数据:
SELECT
schemaname, relname, n_live_tup, n_dead_tup, last_autovacuum
FROM
pg_stat_all_tables
ORDER
BY
n_dead_tup
/ (n_live_tup
* current_setting(
'autovacuum_vacuum_scale_factor'
)::float8
+ current_setting(
'autovacuum_vacuum_threshold'
)::float8)
DESC
LIMIT 10;
--查出所有表(包含索引)并排序 SELECT table_schema || '.' || table_name AS table_full_name, pg_size_pretty(pg_total_relation_size('"' || table_schema || '"."' || table_name || '"')) AS size FROM information_schema.tables ORDER BY pg_total_relation_size('"' || table_schema || '"."' || table_name || '"') DESC limit 20
查正在运行的sql:
SELECT now() as now,pid,query_start,now()-query_start as running_time,query FROM pg_stat_activity WHERE datname = 'boss'
AND STATE != 'idle' AND CURRENT_TIMESTAMP :: TIMESTAMP + INTERVAL '-10 seconds' >= query_start
ORDER BY running_time desc LIMIT 10
查看表和索引大小:
SELECT
table_name,
pg_size_pretty(table_size) AS table_size,
pg_size_pretty(indexes_size) AS indexes_size,
pg_size_pretty(total_size) AS total_size
FROM (
SELECT
table_name,
pg_table_size(table_name) AS table_size,
pg_indexes_size(table_name) AS indexes_size,
pg_total_relation_size(table_name) AS total_size
FROM (
SELECT ('"' || table_schema || '"."' || table_name || '"') AS table_name
FROM information_schema.tables
) AS all_tables
ORDER BY total_size DESC
) AS pretty_sizes
创建用户
create user blex with password 'blex1234';
改hba.conf
重读配置:
pg_ctlcluster 11 main reload
给用户赋权:
1.先postgres用户连到相关数据库
2.赋权
grant all on all tables in schema public to blex;
给用户附上超级权限:
ALTER USER myuser WITH SUPERUSER;
其他权限:
createrole createdb replication;
查看系统上的角色:
SELECT rolname FROM pg_roles;
初始化角色的权限:
移除一个角色相关的默认设置,使用ALTER ROLE rolename RESET varname
转移权限给其他角色:摘自http://www.postgres.cn/docs/11/role-removal.html
此外,REASSIGN OWNED命令可以被用来把要被删除的 角色所拥有的所有对象的拥有关系转移给另一个角色。由于 REASSIGN OWNED不能访问其他数据库中的对象,有必要 在每一个包含该角色所拥有对象的数据库中运行该命令(注意第一个这样的 REASSIGN OWNED将更改任何在数据库间共享的该角色拥 有的对象的拥有关系,即数据库或者表空间)。
一旦任何有价值的对象已经被转移给新的拥有者,任何由被删除角色拥有的剩余对象 就可以用DROP OWNED命令删除。再次,由于这个命令不能 访问其他数据库中的对象, 有必要在每一个包含该角色所拥有对象的数据库中运行 该命令。还有,DROP OWNED将不会删除整个数据库或者表空间, 因此如果该角色拥有任何还没有被转移给新拥有者的数据库或者表空间,有必要手工 删除它们。
DROP OWNED也会注意移除为不属于目标角色的对象授予给目标 角色的任何特权。因为REASSIGN OWNED不会触碰这类对象,通 常有必要运行REASSIGN OWNED和 DROP OWNED(按照这个顺序!)以完全地移除要被删除对象的 从属物。
之,移除曾经拥有过对象的角色的方法是:
REASSIGN OWNED BY doomed_role TO successor_role; DROP OWNED BY doomed_role; -- 在集簇中的每一个数据库中重复上述命令 DROP ROLE doomed_role;
如果不是所有的拥有对象都被转移给了同一个后继拥有者,最好手工处理异常 然后执行上述步骤直到结束。
如果在依赖对象还存在时尝试了DROP ROLE,它将发出 消息标识哪些对象需要被重新授予或者删除。
快速复制数据库:摘自http://www.postgres.cn/docs/11/manage-ag-templatedbs.html
CREATE DATABASE dbname TEMPLATE olddbname;
当源数据库被拷贝时,不能有其他会话连接到它。如果在CREATE DATABASE开始时存在任何其它连接,那么该命令将会失败。在拷贝操作期间,到源数据库的新连接将被阻止。
-------------------------------------------------------
常用函数:
select pg_backend_pid(); #查询当前线程的pid
select pg_sleep(60); #让当前线程睡眠60秒
-------------------------------------------------------
postgresql.con中常用配置参数:
tcp_keepalives_count=3
tcp_keepalives_idle=180
tcp_keepalives_interval=10
shared_buffers=16384 # 128MB内存 16384*8kb ,建议设成50%,不要超过70%。 524288=4G。 1048576=8G。 4194304=32G 。 8388608=64G。
shared_buffers=16GB
temp_buffers=3000 #默认1000,为8mb。每个会话可以使用set命令改变此设置值,必须在绘画第一次使用临时表前设置,一旦使用临时表之后,改变该值无效。
work_mem=8MB #默认时1024,为1mb。用于内部排序操作和hash表在开始使用临时磁盘文件之前可使用的内存数目。order by,distinct和merge joins都要用到排序操作。hash表在以hash join,hash为基础的聚集,以hash为基础的in子查询中都要用到。
maintenance_work_mem=131072 #默认为16mb,131072=128mb。用于维护性操作vacuum,create index和alter table add foreign key等中使用的最大内存数。
wal_buffers=1024 #默认为8,也就是64kb,这里设置成8mb。指定放在共享内存里用于存储wal日志的缓冲区数目。改变这个参数需要重启数据库。这个设置值只需要能够保存一次失误生成的wal数据即可,这些数据在每次事务提交时都会写入磁盘。通常设为1mb-5mb就行了。
日志相关参数:
每天生成一个新日志:
logging_collector=on
log_filename='postgresql-%u.log'
log_rotation_age=1d
log_truncate_on_rotation=on
这样每天就会生成一个新的日志文件,1.log代表周一,7.log代表周日
慢日志毫秒数:
log_min_duration_statement=1000 #sql运行时间大于或等于这个毫秒数,就会被记录到日志中。如果设置成0,所有运行的sql语句及其实践都会被记录到日志文件中。
日志还可以控制是否记录ddl,dml或所有sql的功能。这个功能由log_statement来控制。
当设置为none时,表示不记录sql
设置为ddl时,记录所有ddl语句。
设置为mod时,记录insert,update,delete,truncate,copy from等语句。如果prepare,execute或explain analyze语句产生了更新,这些语句也同样会被记录下来。
设置为all,所有sql被记录,如果使用了参数log_min_duration_statement,超过一定时间的sql一再日志中被打印了,而这些sql又符合log_statement参数配置要求,可输出到日志中,那此时sql语句不会在日种中重复打印。
max_wal_senders=8 #如果要建多台hot_standby服务器,一定要设置成大于0的值。
wal_level=host_standby #主库要建hot standby服务器,wal_level一定要设置hot_standby
------------------------------------------------------
8.3访问控制配置文件
pg_hba.conf
连接类型 客户端地址 数据库名 用户名
local dbname user auth-method auth-options
host dbname user ip/mask auth-method auth-options
host dbname user ip mask auth-method auth-options
认证方法:
trust无条件的允许连接,允许任何用户以任意postgresql数据库用户身份进行连接,不需要口令或其他任何认证。
reject无条件的拒绝连接。reject行可以组织一个特定的主机连接,而允许其他的主机连接数据库。
md5要求客户端提供一个md5加密的口令进行认证。
password要求客户端提供一个未加密的口令进行认证。用的很少。
ident 允许客户端的本机操作系统上的特定用户连接到数据库。
例子:
local all all trust #允许本机的任何用户连接到数据库而不需要任何密码。
local all all md5 #在本机上开启密码验证
host all all 0.0.0.0/0 md5 #让其他主机的连接都使用md5密码验证
local all osdba(数据库中的用户) ident(使用系统上的同名用户) #数据库中有一个用户osdba,操作系统中也有一个用户osdba,在操作系统osdba用户下连接数据库不需要密码。
-------------------------------------------------------
在主库查slave的状态:
select * from pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 6061
usesysid | 10
usename | postgres
application_name | walreceiver
client_addr | 10.11.30.70
client_hostname |
client_port | 57126
backend_start | 2020-01-10 11:21:44.175029+08
backend_xmin |
state | streaming
sent_lsn | 10F4/CB679288
write_lsn | 10F4/CB679288
flush_lsn | 10F4/CB679288
replay_lsn | 10F4/CB679288
write_lag | 00:00:00.000462
flush_lag | 00:00:00.001481
replay_lag | 00:00:00.0016
sync_priority | 0
sync_state | async
-[ RECORD 2 ]----+------------------------------
pid | 10618
usesysid | 10
usename | postgres
application_name | walreceiver
client_addr | 10.11.30.51
client_hostname |
client_port | 42506
backend_start | 2020-01-03 01:26:49.381994+08
backend_xmin |
state | streaming
sent_lsn | 10F4/CB679288
write_lsn | 10F4/CB679288
flush_lsn | 10F4/CB679288
replay_lsn | 10F4/CB679288
write_lag | 00:00:00.00053
flush_lag | 00:00:00.001134
replay_lag | 00:00:00.001313
sync_priority | 0
sync_state | async
查pid慢的sql
SELECT
procpid,
START,
now() - START AS lap,
current_query
FROM
(
SELECT
backendid,
pg_stat_get_backend_pid (S.backendid) AS procpid,
pg_stat_get_backend_activity_start (S.backendid) AS START,
pg_stat_get_backend_activity (S.backendid) AS current_query
FROM
(
SELECT
pg_stat_get_backend_idset () AS backendid
) AS S
) AS S
WHERE procpid=30200
查pgsql正在执行的sql 按照运行时间排序
SELECT
procpid,
START,
now() - START AS lap,
current_query
FROM
(
SELECT
backendid,
pg_stat_get_backend_pid (S.backendid) AS procpid,
pg_stat_get_backend_activity_start (S.backendid) AS START,
pg_stat_get_backend_activity (S.backendid) AS current_query
FROM
(
SELECT
pg_stat_get_backend_idset () AS backendid
) AS S
) AS S
WHERE
current_query <> '<IDLE>'
ORDER BY
lap DESC;
查正在运行的sql:
select pid,datname,query,query_start from pg_stat_activity where state != 'idle' order by query_start asc;
psql
查看数据库:
psql -l
\l
查看数据表:
\d
创建数据库:
create database testdb;
连接到testdb
\c testdb;
psql命令连接数据库
psql -h ip -p 端口 [数据库名称] [用户名称]
psql -h x.x.x.x -p 5432 testdb postgres
\d 列出当前数据库中所有表
\d t , 后面跟一个表名,显示这个表的结构定义
\d t_key , 后面跟索引名字,可以显示索引信息
\d x? 或者 \d t* #显示x的表和索引,或者所有t*的表信息和索引信息
\d+ t #显示比\d更详细的信息,还会显示任何与表列关联的注释,以及表中出现的oid。
\dt #只显示匹配的表
\di #只显示索引
\ds #只显示序列
\dv #只显示视图
\df #只显示函数
\dn #显示所有的schema
\db #显示所有的表空间
\dg #显示所有的角色
\du #显示所有的用户
\dp t #显示 t 表的权限非匹配情况
\timing on #显示sql已执行的时间 select count(*) from t; 会显示时间。
\encoding utf8; #设置客户端的字符编码为utf8 \encoding gbk; 设置为gbk
\pset border 0; #输出内容无边框。
\pset border 1; #只有内边框
\pset border 2; #内网都有边框
\x 把表中每列数据都拆封为单行展示。 类似于mysql select * from xxx\G;
\i <文件名> #执行存储在外部文件中的sql语句
\i getrunsql
psql -x -f getrunsql #在psql命令行执行sql脚本文件中的命令。
\echo ==================== #输出一行信息
\? 显示更多命令
psql -E postgres #显示各种以 "\" 开头的命令执行的实际sql打印出来。
-------------------------------------------------------------------------------------
事务:
begin;
update table_t set name='xxx' where id=1;
commit;
rollback; 回滚
set autocommit on/off;
-----------------------------------------------------------------------------------
postgresql.conf
listen_addresses="localhost"
port=5432
logging_collector = on #日志的收集
log_directory = 'pg_log' #日志的目录,一般使用默认值即可
日志的切换和是否选择覆盖可以使用以下几种方案:
方案一,每天生成一个新的日志文件
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
log_truncate_on_rotation = off
log_rotation_age = 1d
log_rotation_size = 0
方案二,每当日志写满一定的大小(如10MB空间),则切换一个日志。
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
log_truncate_on_rotation = off
log_rotation_age = 0
log_rotation_size = 10M
方案三,只保留7天的日志,进行循环覆盖
log_filename = 'postgresql-%a.log'
log_truncate_on_rotation = on
log_rotation_age = 1d
log_rotation_size = 0
内存参数的设置:
shared_buffers #默认32mb,共享内存大小,主要用于共享数据块
work_mem #默认1mb,单个sql执行时,排序,hash join所使用的内存,sql运行完后,内存就释放了。设置大一些的话会让排序操作快一点。
--------------------------------------------------------------------------------------------------------------------------
数据库结构:
一个数据库服务=数据库实例
一个数据库实例可以有多个数据库。
一个数据库不能属于多个实例。
创建数据库:
create database osdbadb;
参数说明:
TEMPLATE = template 模板名,从哪个模板创建新数据库,默认为template1
create database testdb01 encoding 'latin1' template template0; #注意命令中需要指定模板数据库为template0,而不能指定为template1,因为编码和区域设置必须与模板数据库的相匹配,如果模板数据库中包含了与新建的数据库的编码不匹配的数据,或者包含了排序受LC_COLLATE和LC_CTYPE影响的索引,那么复制这些数据将会导致数据库被新设置破坏。template0公认不包含任何会受字符集编码或排序影响的数据或索引,故可以作为创建任意字符集数据库的模板。
修改数据库:
alter database name [ [ with ] option [ ... ] ]
例如:
alter database name CONNECTION LIMIT 200
alter database name rename to new_name
alter database name owner to new_owner
alter database name set tablespace new_tablespace
alter database name set configuraration_parameter { TO | = } { value | DEFAULT }
alter database name set configuration_parameter from current
alter database name RESET configuration_parameter
alter database name RESET ALL
删除数据库:
drop database [ IF EXISTS ] name
--------------------------------------------------------------------------------
模式schema
模式是数据库中的一个概念,可以将其理解为一个命名空间或目录。不同的模式下可以有相同名称的表、函数等对象且互相不冲突。提出模式的概念是为了便于管理,只要有权限,每个模式schema的对象可以互相调用
在pg中,一个数据库包含一个或多个模式,模式中又包含了表,函数及操作符等数据库对象。
在pg中,不能同时访问不同数据库中的对象,当要访问另一个数据库中的表或其他对象时,需要重新连接到这个新的数据库,而模式没有此限制。一个用户连接到一个数据库后,可以同时访问这个数据库中多个模式的对象。schema=mysql中的数据库。
创建一个模式:
create schema osdba;
\dn 查看有哪些模式
删除一个模式:
drop schema osdba;
create schema authorization osdba; #为用户osdba创建模式,名字也定为osdba
alter schema xxxx rename to newname;
alter schema xxx owner to newowner;
通常情况下,pg有一个默认模式,访问的都是public模式。
------------------------------------------------------------------
创建表
create table child(name varchar(20), age int, note text, constraint ck_child_age check(age <18)); #有个约束
create table baby (LIKE child); #复制了表,不过没把约束复制过来
create table baby2 (LIKE child INCLUDING ALL); #复制表,也把约束复制过来
其他inluding:
INCLUDING DEFAULTS
INCLUDING CONSTRAINTS
INCLUDING INDEXES
INCLUDING STORAGE
INCLUDING COMMENTS
INCLUDING ALL
也可以使用create table .... as 来创建表:
create table baby2 as select * from child WITH NO DATA;
--------------------------------------------------------------
创建索引
create index xxxx on tablename(colname); #会锁表,并作全表扫描
create index CONCURRENTLY xxxxx on tablename(colname); #不会锁表
重建索引:
由于不支持在重建索引上使用concurrently选项,所以应该这么做:
1.使用concurrently新建索引
2.删除老索引。drop index xxxxx;
-------------------------------------------------------------------
创建用户和角色
create role name [ [ with ] option [ ... ] ] #创建出来的用户没有login权限
create user name [ [ with ] option [ ... ] ] #创建出来的用户有login权限
option可以是如下内容:
SUPERUSER | NOSUPERUSER #创建出来的用户是否为超级用户。只有超级用户才能创建超级用户
CREATEDB | NOCREATEDB #指定创建出来的用户是否有执行 “create database”的权限
CREATEROLE | NOCREATEROLE #是否有创建其他用户的权限
INHERIT | NOINHERIT #如果创建的一个用户拥有某一个或某几个角色,这时若指定inherit,则表示用户自动拥有相应角色的权限,否则这个用户没有该角色的权限
LOGIN | NOLOGIN #指定创建出来的用户是否有login权限。
CONNECTION LIMMIT connlimit
[ENCTRYPTED | UNENCRYPTED ] PASSWORD 'password'
ADMIN role_name # role_name将有这个新建角色的 WITH ADMIN OPTION权限
例子:
create user readonly with password 'query';
在public这个下现有的所有表的select权限赋给用户readonly:
grant select on all table in schema public to readonly;
如果新建了表,readonly用户不能读,需要使用下面的sql把所见表的select权限也给用户readonly:
alter default privileges in schema public grant select on tables to readonly;
注意,上面的过程只是给schema下的名为public的表赋了只读权限,如果想让这个用户访问其他schema下的表,需要重复执行下面语句:
grant select on all tables in schema OTHER_SCHEMA to readonly;
alter default privileges in schema OTHER_SCHEMA grant select on tables to readonly;
---------------------------------------------------------------------
查看pgsql中的锁:
select pg_backend_pid(); #查看当前进程号。
select locktype,relation::regclass as rel,virtualxid as vxid,transactionid as xid, virtualtransaction as vxid2, pid,mode, granted from pg_locks where pid = xxx
-------------------------------------------------------------------------
postgresql的核心架构:
postmaster主进程
syslogger 系统日志进程,需要在参数logging_collect设置为on时,主进程才会启动syslogger辅助进程。
BgWriter 后台写进程。 把共享内存中的脏页写到磁盘上的进程。可以用bgwriter_开头的参数来控制配置。
WalWriter 预写式日志写 进程。wal日志保存在pg_xlog下。每个xlog文件默认是16mb。xlog目录下会产生多个wal日志,当宕机后未持久化的数据都可以通过wal日志来恢复。那些不需要的wal日志将会被自动覆盖。
PgArch 归档进程。 wal日志会被循环使用,较早时间的wal日志会被覆盖。PgArch归档进程会在覆盖前把wal日志备份出来。pgsql在8.x版本开始提供了pitr(point-in-time Recovery)技术。在数据库进行过一次全量备份后,该技术将备份时间点之后的wal日志通过归档进行备份,使用数据库的全量备份再加上后面产生的wal日志,即可把数据库向前推到全量备份后的任意一个时间点了。
AutoVacuum(自动清理)进程。在pgsql数据中,对表进行delete操作后,旧的数据不会立即被删除。更新也不会在旧的数据上更新,都是新生成一行数据。称之为多版本。旧数据被标记为删除状态,在没有并发的其他事务督导这些旧数据时,他们才会被清除掉。这个清除工作就是由AutoVacuum进程来完成的
PgStat(统计数据收集)进程
系统表pg_statistic中存储了PgStat手机的各类统计信息。信息包括在一个表和索引上进行了多少次插入,更新,删除操作,磁盘块读写的次数,以及行的读次数。
共享内存。主要用作数据块的缓冲区,提高读写性能。wal日志缓冲区和clog(commit log)缓冲区也存于共享内存中。一些全局信息也保存在共享内存中,如进程信息,锁的信息,全局统计信息等等。
本地内存。主要有以下几类。临时缓冲区:用于访问临时表的本地缓冲区。work_mem:内部排序操作和hash表在使用临时磁盘文件之前使用的内存缓冲区。maintenance_work_mem:维护性操作中使用的内存缓冲区(如vacuum,create index和alter table add foreign key等)
-------------------------------------------------------------------------
数据目录的结构:
一般使用环境变量PGDATA指向数据目录的根目录。
postgresql.conf 数据库实例的主配置文件,基本上所有的配置参数都在次文件中。
pg_hba.conf 认证配置文件,配置了允许哪些ip的主机允许访问数据库
pg_ident.conf "ident"认证方式的用户映射文件。
base目录,默认表空间的目录
global目录,一些共享系统表的目录
pg_clog目录,commit log的目录
pg_log目录,系统日志的目录
pg_stat_tmp,统计信息的存储目录
pg_tblsp,存储了指向各个用户自建表空间实际目录的链接文件。
pg_twophase,使用两阶段提交功能时分布式事务的存储目录。
pg_xlog,wal日志的目录
---------------------------------------------------------------------
表空间的目录
在创建完一个表空间后,会在表空间的目录下生成带有“Catalog version”的子目录
create tablespace tbs01 location '/home/osdba/tbs01';
同时也会生成要给子目录名 “PG_9.3_201306121”:
ls -l /home/osdba/tbs01
这个子目录名201306121就是Catalog version,它可以由pg_controldata命令查询出来:
pg_controldata
在PG_9.3_201306121子目录下,又会有一些子目录,这些子目录的名称就是数据库的oid
也可以这么查oid, select oid,datname from pg_database;
-------------------------------------------------------------------------
8.1 服务的启停
启动
postgres -D /home/osdba/pgdata &
或者:
pg_ctl -D /home/osdba/pgdata start
停止:
Smart Shutdown:智能关机模式。接受请求后,服务器不允许有新连接,并且等已有的连接全部结束后,才关闭数据库。这种模式需要用户主动断开数据库连接后,数据库才会停止,如果用户一直不断开连接,服务器就无法停止。
Fast Shutdown:快速关闭模式。不允许有新连接,想所有活跃的服务进程发送sigterm信号,让他们立刻退出,然后等待所有子进程退出并关闭数据库。如果服务处于在线备份状态,将终止备份,导致备份失败。
Immediate Shutdown:立即关闭模式。主进程postgres向所有子进程发送sigquit信号,并且立即退出,所有子进程也会立即退出。采用这种模式不会妥善的关闭数据库系统,下次启动时数据库会重放wal日志进行恢复,因此推荐旨在紧急的时候使用。
直接向数据库主进程发送的signal信号有以下三种
sigterm,发送此信号为smart shutdown关机模式
sigint=fast shutdown
sigquit=immediate shutdown
使用pg_ctl命令时,可以加不同的命令行参数:
pg_ctl stop -D DATADIR -m smart
pg_ctl stop -D DATADIR -m fast
pg_ctl stop -D DATADIR -m immediate
8.1.2 pg_ctl
初始化postgresql数据库实例的命令如下:
pg_ctl init [-s] [-D datadir] [-o options]
-s:只打印错误和警告信息,不打印提示性信息
-D datadir 指定数据库实例的数据目录
-o options 传递给initdb命令的参数。
启动pgsql数据库的命令如下:
pg_ctl start [-w] [-t seconds] [-s] [-D datadir] [-l filename] [-o options] [-p path] [-c]
start:启动数据库实例
-w 等待启动完成
-t 等待启动完成的等待描述。默认60秒
-s 只打印错误和警告信息,不打印提示性信息
-D datadir
-l 把服务器日志输出附加在filename文件上,文件不存在则创建
-o options 传递给postgres的选项
-p path 指定postgres可执行文件的位置。默认postgres可执行文件来自和pg_ctl相同的目录。
-c 提高服务器的软限制ulimit -c。尝试允许数据库实例在有异常时产生一个coredump文件。
例子:
pg_ctl start -w -D /home/osdba/pgdata
停止pgsql数据库的命令:
pg_ctl stop [-W] [-t seconds] [-s] [-D datadir] [-m s[mart] | f[ast] | i[mmediate] ]
-W 不等待数据库停下来,命令就返回
-m 指定停止的模式
例子:
pg_ctl stop -D /home/osdba/pgdata -m f
重启pgsql数据库的命令如下:
pg_ctl restart [-w] [-t seconds] [-s] [-D datadir] [-c] [-m s[mart] | f[ast] | i[mmediate] ] [-o options]
让数据库实例重新读取配置文件的命令如下:
pg_ctl reload [-s] [-D datadir]
--------------------------------------------------------------
8.1.3信号
SIGTERM , smart shutdown关机模式
SIGINT , fast shutdown
SIGQUIT , Immediate shutdown
SIGHUP , 让服务器重新装在配置文件,使用pg_ctl reload 命令和直接调用函数pg_reload_conf() 都是发送SIGHUP给服务主进程。
---------------------------------------------------------------
8.1.4单用户模式
postgres --single -D /home/osdba/pgdata postgres
--------------------------------------------------------------
8.2.1配置参数
所有的配置参数都在系统视图pg_settings中:
当不知道枚举类型的配置参数 client_min_messages 可以取哪些值时,可用下面的语句查询:
select enumvals from pg_settings where name = 'client_min_messages';
当不知道autovacumm_vacuum_cost_delay的时间单位是什么时,可以通过下面命令查询到:
select unit from pg_settings where name = 'autovacuum_vacuum_cost_delay';
参数改变后有些可以直接生效,有些需要重启服务器生效,有些需要超级用户才能改变。
select name,setting,unit,context,short_desc from pg_settings;
internal。参数是只读参数。
postmaster。改变这些参数需要重启postgresql实例。在postgresql.conf文件中改变后,需要重启postgresql实例才能生效。
sighup . 在postgresql.conf文件中可以改变这些参数的值,不需要重启数据库,只需要向postmaster进程发送sighup信号,让其重启装载配置新的参数值就可以了。postmaster主进程收到sighup信号后,会向他的子进程发送sighup信号,让新的参数值在所有的进程中都生效。
backend。在postgresql.conf更改后无需重新启动服务器,只需要postmaster发送一个sighup信号,让他重新读取postgresql.conf中新配置即可,但新的配置值只会出现在这之后的新连接中,在已有的连接中,这些参数的值不会改变。
superuser。这类参数可以由超级用户使用set来改变,比如检测思索超时时间的参数deadlock_timeout。而超级用户改变此参数值时,指挥影响自身session配置,不会影响其他用户。向postmaster进程发送SIGHUP信号,也只会一项项后续建的连接,不会影响现有的连接。
user。普通用户可使用set命令通过此类参数来改变本连接中的配置值。
这些tcp参数的调整即可:
tcp_keepalives_count=3
tcp_keepalives_idle=180
tcp_keepalives_interval=10
--------------------------------------------------------
8.4备份和还原
8.4.1逻辑备份
pg_dump pg_dumpall
pg_dumpall将一个postgresql数据库集群全部转储到一个脚本文件中
pg_dump可以选择一个数据库或部份表进行备份。
pg_dump [connection-option] [option] [dbname]
连接选项:
-h host 或 --host=host #如果设置了$PGGHOST环境变量,则从此环境变量中获取,否则尝试一个unix套接字连接。
-p port 或 --port=port #如果设置了$PGPORT环境变量,则从此环境变量中获取,否则从默认端口5432获取
-U username 或 --username=username
-w 或 --no-password #从不提示密码。如果服务器请求密码认证,而且密码不能通过其他方式(如.pgpass文件)来获得,则此命令会导致连接失败。
-W 或 --password #强制pg_dump在连接到一个数据库之前提示密码
dbname #连接的数据库名,也就是要备份的数据库名。如果没有使用这个参数,则使用环境变量$PGDATABASE。 如果$PGDATABASE也没生命,那么可使用发起连接的用户名。
pg_dump专有参数:
-a 或 --data-only #只输出数据,不输出数据定义的sql语句。这个选项只对纯文本格式有意义。
-c 或 --clean #只对纯文本格式有意义。指定输出的脚本中是否生成清理该数据库对象语句(比如drop table命令)
-C 或 --create #只对纯文本格式有意义。指定脚本中是否输出一条create database语句和连接到该数据库的语句。
-f file 或者 --file=file #输出到指定文件中。如果没有此参数,则输出到标准输出中。
-F format 或 --format=format #format可以时p,c或t。
p plain的意思,为纯文本sql脚本文件的格式,这是默认值。
c是custom的意思,以一个适合pg_restore使用的自定义格式输出并归档。这是最灵活的输出格式,允许手动查询并且可以在pg_restore恢复时重排归档项的顺序。该格式默认是压缩的。
t是tar的意思,以一个适合输入pg_restore的tar格式输出并桧仓。允许手动选择并且在恢复时重排归档项的顺序,但是这个重排序是有限制的,比如表数据项的相关顺序在恢复时不能更改。同时,tar格式不支持压缩,并且对独立表的大小限制为8GB。
-s 或 --schema-only 只输出对象定义(模式),不输出数据。这个选项在备份表结构或在另一个数据库上创建相同结构的表时比较有用。
-t table 或 --table=table 只转储匹配table的表,视图,序列。可以使用多个-t选项匹配多个表。也可以用通配符模式匹配多个模式如tab*。在使用通配符时,最好用单引号界定,防止shell将通配符进行扩展。使用了-t之后,-n和-N选项就失效了
-T table或 --exclude-table=table 不转储任何匹配table模式的表。可以指定多个-T以排除多种匹配的表。如果同时指定了-t和-T ,那么将只转储匹配-t但不匹配-T的表。如果出现了-T而未出现-t, 那么匹配-T的表不会被转储。
--inserts 他像insert命令一样转储数据。默认使用copy命令的格式转储数据,使用这个选项将使恢复非常缓慢。用于把数据加载到非postgresql数据库。该选项为每一行生成要给单独的insert命令,当数据库恢复时遇到一行错误时,他将仅导致丢失一行的数据而不是全部的表内容。如果目标表列的顺序与源表列的顺序不一样,恢复可能会完全失败,这时应该使用-column-inserts选项。
--column-inserts 或 --attribute-inserts #他像有显式列名的insert命令一样转储数据。这将使恢复非常缓慢。常用于加载到非postgresql数据库的转储。
pg_restore命令:
pg_restore [connection-option] [option] [filename]
连接参数与pg_dump基本相同,不同的是,pg_restore使用下面的参数来连接指定的数据库:
-d dbname 或 --dbname=dbname
而pg_dump命令连接到特定的数据库时,不以-或--开头的选项参数来指定,而是最后一个不带-的参数来指定。
pg_restore最后一个不带-或--的参数是一个转储文件名。
-a或--data-only 只恢复数据,而不恢复表模式
-c或--clean 创建数据库对象前先清理删除他们。
-C或--create 在恢复数据库之前先创建他们。和-d在一起的数据库名值时用于发出最初的create database命令,所有数据都恢复到名字出现在归档中的数据库中
-d dbname 或 --dbname=dbname 与数据库dbname连接并且直接恢复到该数据库中。
-e或--exit-on-error 如果碰到sql命令时遇到错误,则退出。默认是继续执行,并且在恢复结束时显示一个错误计数。
-f filename 或 --file=filename 指定生成的脚本的输出文件,或者出现-l选项时用于列表的文件,默认是标准输出。
-F format 或 --format=format 可以是t或c之一。t表示tar,c表示custom,备份格式来自pg_dump的自定义格式。允许数据冲i性能排序,也允许重载表模式元素,默认这个格式是压缩的。
-I index 或 --index=index 只恢复命名的索引
-j number-of-jobs 或 --jobs=number-of-jobs 运行restore最耗时部份(如加载数据,创建索引或约束)时,使用多个并发工作来完成。该选项可以显著减少恢复时间。
每个并发工作室一个进程或一个线程,并使用一个单独数据库连接。只有pg_dump的自定义格式才支持该选项。输入文件不能是一个管道,必须是一个常规文件,同时,并发作业不能与--single-transaction一起使用。
-l 或 --list 列出归档文件的内容。该操作的输出可以用作输入的-L选项。如果-n或-t,与-l一同使用,他们将限制列出的项。
-L list-file或 --use-list=list-file 仅恢复那些在list-file中列出的归档元素,并按他们在文件中出现的顺序进行恢复。如果-n或-t,与-L一同使用,他们将限制列出的项。
-n namespace 或 --schema=schema只恢复指定名字的模式里的定义或数据。这个选项可以和-t选项一起使用,只恢复一个表的数据
-O 或 --no-owner
--no-tablespaces 不选择表空间。使用该选项时,恢复数据时,所有对象被创建在默认表空间中,而不是对象原有的表空间中。
-s 或 --schema-only 只恢复表结构,不恢复数据。序列的当前值也不会得到恢复。
-t table 或 --table=table 只恢复指定的表定义或数据。可以与-n参数指定schema联合使用。
-1 或 --single-trasaction 表示作为一个单独事务来处理。这就确保了要么所有的命令成功完成,要么没有申请修改。该选项包含--exit-on-error
例子:
pg_dump osdba > osdba.sql #连接的是一个本地数据库,不需要密码,要对数据库osdba进行备份,备份文件的格式是脚本文件格式
pg_dump -h 192.168.x.x -Uosdba osdba > osdba.sql #备份一个远端数据库上面的osdba数据库
pg_dump -Fc -h 192.168.x.x -Uosdba osdba > osdba.dump #生成的备份文件格式为自定义格式。
把上述备份文件恢复到另一个数据库osdba2中:
createdb osdba2
pg_restore -d osdba2 osdba.dump
只想备份表testtab:
pg_dump -t testtab > testtab.sql
想备份schel模式中所有job开头的表,但不包括job_log表:
pg_dump -t 'schel.job*' -T schema1.job_log osdba > schema1.emp.sql
转储素有数据库对象,但是不包括名字以_log结尾的表,可以使用下面命令:
pg_dump -T '*_log' osdba > log.sql
如果先从192.168.122.1备份数据库osdba,恢复到122.2机器上:
pg_dump -h 192.168.122.1 -Uosdba osdba -Fc > osdba.dump
pg_restore -h 192.168.122.2 -Uosdba -C -d postgres osdba.dump
在pg_restore命令中,-d 中指定的数据库可以是122.2机器上实例中的任意数据库,pg_restore仅用该数据库名称连接上去,先执行create database命令建立osdba数据库,然后再重新连接到osdba数据库,最后把备份的表和其他对象建到osdba数据库中。
要将备份出来的数据 重新加载到一个不是新建的不同名称的数据库osdba2中:
createdb -T template0 osdba2
pg_restore -d osdba2 osdba.dump
上面的命令从template0而不是template1创建新数据库,确保干净。这里没有使用-C选项,而是直接连接到将要恢复的数据库上。
-------------------------------------------------------------------------
8.5常用的管理命令:
查看数据库版本:
select version(); PostgreSQL 11.6 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-39), 64-bit
查看数据库启动时间:
select pg_postmaster_start_time()
2019-12-06 17:16:55.254518+08
查看最后load配置文件的时间:
select pg_conf_load_time()
2019-12-06 17:16:55.237789+08
显示当前数据库时区:
show timezone;
Asia/Shanghai
查看当前用户名:
select user;
select current_user;
查看session用户:
select session_user;
查看当前连接的数据库名称:
select current_database();
查看当前session所在客户端的ip地址和端口:
select inet_client_addr(),inet_client_port();
查看当前数据库服务器的ip地址和端口:
select inet_server_addr(),inet_server_port();
查看当前session的后天服务进程的pid:
select pg_backend_pid();
查看当前的一些参数配置情况:
show shared_buffers;
select current_setting('shared_buffers'); #同上
修改当前session的参数配置:
set maintenance_work_mem to '128MB';
select set_config('maintenance_work_mem', '128MB', false);
查看当前正在写的wal文件:
select pg_xlogfile_name(pg_current_xlog_location()); # 11版本失效
查看当前wal的buffer中还有多少字节的数据没有写到磁盘中:
select pg_xlog_location_diff(pg_current_xlog_insert_location(), pg_current_xlog_location()); #失效
查看数据库实例是否正在做基础备份:
select pg_is_in_backup(),pg_backup_start_time();
查看当前数据库实例时hot standby状态还是正常数据库状态:
select pg_is_in_recovery(); #如果结果返回为真,说明数据库处于hot standby状态
查看数据库大小:
select pg_database_size('osdba'), pg_size_pretty(pg_database_size('osdba'));
查看表的大小:(使用pg_relation_size()仅计算表的大小,不包括索引的大小)
select pg_size_pretty(pg_relation_size('ipdb2')); ·#默认schema为public,不用写
select pg_size_pretty(pg_relation_size('hrs.job')); #hrs为schema名字
查看表的大小:包括索引:
select pg_size_pretty(pg_total_relation_size('hrs.job'));
只查看表的索引大小:
select pg_size_pretty(pg_indexes_size('hrs.job'));
查看表空间的大小:
select pg_size_pretty(pg_tablespace_size('pg_global')); #全局表空间
select pg_size_pretty(pg_tablespace_size('pg_default')); #默认表空间
查看表对应的数据文件:
select pg_relation_filepath('hrs.job');
base/16727/16808
--------------------------------------------------------------
8.5.2系统维护常用命令
修改pstgresql.conf之后,让配置生效
方法一:
操作系统中命令:
pg_ctl reload
方法二:
psql中命令:
select pg_reload_conf()
切换log日志文件到下一个:
select pg_rotate_logfile();
切换wal日志文件:
select pg_switch_xlog();
取消一个正在长时间执行的sql方法:
pg_cancel_backend(pid) #取消一个正在执行的sql
pg_terminate_backend(pid) #终止一个后台服务进程,同时释放此后台服务进程的资源
区别在于cancel函数实际上是给正在执行的sql任务配置一个取消标志,正在执行的任务在合适的时候检测到此标志后会主动退出。但如果这个任务没有主动检测到这个标志,则该任务无法退出,这时需要使用terminate命令来中止sql执行。
通常是先查询pg_stat_activity找出长时间运行的sql:
select pid,usename,query_start, query from pg_stat_activity;
-------------------------------------------------------------------
9.1执行计划
explain [ ( option [, ...])] statement
explain [analyze] [verbose] statement
命令的可选选项options为:
analyze [ boolean ]
verbose [ boolean ]
costs [ boolean ]
buffers [ boolean ]
format { text | xml | json | yaml}
analyze选项通过实际执行的sql来获得相应的执行计划。因为真正被执行,所以可以看到执行计划每一步花掉了多少时间,以及它实际返回的行数。
加上analyze选项后,会真正执行实际的sql,如果执行修改的sql语句,会修改数据库。为了不影响实际诗句,可以把explain analyze放到一个事务中,执行完后回滚:
begin;
explain analyze ....
rollback;
verbose用于显示计划的附加信息,比如计划树中每个节点输出的各个列,如果触发器被处罚,还会输出触发器的名称。默认该选项为false。
costs选项显示每个计划节点的启动成本和总成本,以及估计行数和每行宽度。该选项默认值为True。
buvvers选项显示关于缓冲区使用的信息。该参数只能与analyze参数一起使用。显示缓冲区信息包括共享快、本地块和临时快读和写的块数。共享块,本地块和临时块分别包含表和索引,临时表和临时索引,以及在排序和物化计划中使用的磁盘块。上层节点显示出来的块数包括其所有子节点使用的块数。该选项默认为false。
format选项指定输出格式,可以是text,xml,json或yaml。默认为text
--------------------------------------------------------------
explain输出结果解释
explain select * from hrs.job;
Seq Scan on job (cost=0.00..289.74 rows=12874 width=68)
Seq Scan=顺序扫描=全表扫描。
cost的第一个数字0.00表示启动的成本,也就是说返回第一行需要多少cost值;第二个数字表示返回所有的数据的成本。
rows,会返回多少行
width=68,表示每行平均宽度为68个字节。
cost成本代价:
顺序扫描一个数据库,cost值为1
随机扫描一个数据库,cost值为4
处理一个数据行的cpu, cost为0.01
处理一个随银行的cpu, cost为0.005
每个操作符的cpu代价为0.0025
explain使用示例:
json格式输出:
explain (format json) select * from hrs.job;
[
{
"Plan": {
"Node Type": "Seq Scan",
"Parallel Aware": false,
"Relation Name": "job",
"Alias": "job",
"Startup Cost": 0.00,
"Total Cost": 289.74,
"Plan Rows": 12874,
"Plan Width": 68
}
}
]
xml格式:
explain (format xml) select * from hrs.job;
yaml格式:
explain (format yaml) select * from hrs.job;
加上analyze参数后,可得到更精确的执行计划:
Seq Scan on job (cost=0.00..289.74 rows=12874 width=68) (actual time=0.094..5.709 rows=12800 loops=1)
Planning Time: 0.077 ms
Execution Time: 6.639 ms
联合使用analyze选项和buffers选项,可通过实际执行来查看实际的代价和缓冲区命中的情况:
explain (analyze true,buffers true) select * from hrs.job;
Seq Scan on job (cost=0.00..289.74 rows=12874 width=68) (actual time=0.011..1.509 rows=12800 loops=1)
Buffers: shared hit=161
Planning Time: 0.048 ms
Execution Time: 2.136 ms
shared hit=161表示在共享内存中直接读到161个块。
9.1.4全表扫描也成为顺序扫描 seq scan
9.1.5索引扫描
索引扫描=Index Scan
9.1.6位图扫描=bitmap index scan
扫描索引,把满足条件的行或块在内存中建一个位图,扫描完索引后,再根据位图到表的数据文件中把相应的数据读出来。如果走了两个索引,可以把两个索引形成的位图进行and或or计算,合并成一个位图,再到表的数据文件中把数据读出来。
当执行计划的结果行数很多时会进行这种扫描,如非等值查询,in自居或有多个条件都可以走不同的索引时。
例如
explain select * from table where id > 10000;
位图扫描先在索引中找到符合条件的行,然后在内存中建立位图,之后再到表中扫描,也就是看到的bitmap heap scan
还会看到Recheck Cond: (id > 10000),这是因为多版本的原因,当从索引找出的行从表中读出后,还需要检查一下条件。
9.1.7条件过滤
条件过滤在执行计划中显示为filter:
explain select * from table where id<10000 and note like 'asdk%';
Filter: (note ~~ 'asdk%'::text)
如果挑两件的列上有索引,会走索引不走过滤
explain select * from table where id<1000;
explain select * from table where id>1000; #走的全表扫描seq scan
---------------------------------------------------------------------------------------
9.3统计信息的收集
表和索引的行数,块数等统计信息记录在系统表pg_class中,其他的统计信息主要收集在系统表pg_statistic中
---------------------------------------------------------------------------
11.2 模式匹配和正则表达式
like ‘%abc%’
~~ 等效于like
~~* 等效于ilike ,忽略大小写
!~~ 等效于not like
!~~* 等效于not ilike ,忽略大小写
11.2.3 similar to 正则表达式
similar to操作符只有在匹配整个字符串时才能成功。也是用下划线和百分号分别匹配单个字符和任意字符串。
similar to还支持:
| 表示选择两个候选项之一
* 表示重复前面的项零次或多次
+ 一次或多次
? 0次或1次
{m} 重复前面项m次
{m, } 重复前面的项m次或更多次
{m,n} 至少m次,不超过n次
括号() 可以作为项目分组到一个独立的逻辑项中
[...] 声明一个字符类,就像posix正则表达式
注意 similar to中英文的句号 . 并不是元字符
例子:
select 'osdba' similar to 'a'; # f
select 'osdba' similar to '%(b|a)%' # t
select 'osdb' similar to '%(b|a)' # t
select 'osdba' similar to '(s|d)%' # f
----------------------------------------------------
11.2.4 正则表达式
~ 匹配正则表达式,区分大小写
~* 不分大小写
!~ 不匹配正则表达式,区分大小写
!~* 不分大小写
例子:
select 'osdba' ~ 'a'; #t
select 'osdba' ~ '(b|a)*'; #t
select 'osdb' ~ '.*(b|a).*'; #t
select 'osdb' ~ '(s|d).*'; #t
在posix正则表达式中,百分号和下划线没有特殊意义
匹配开头和结尾:
select 'aosdb' ~ ‘os'; #t
select 'aosdba' ~ '^os'; #t
select 'aosdba' ~ 'db'; #t
select 'aosdba' ~ 'db$'; #f
select 'aosdba' ~ 'dba$'; #t
---------------------------------------------------------
11.2.5 模式匹配函数substring
它也可以用正则表达式,使用的是sql正则表达式,第三个参数为指定要给转义字符
substring(<字符串>,<数字>, [数字])
select substring('osdba',2); #sdba
substring(<字符串>,<字符串>)
select substring('osdba-5-osdba' , '%#"[0-9]+#"%','#'); #5 第三个参数为指定要给转义字符
-------------------------------------------------------------
11.4.1表达式上的索引:
select * from mytest where lower(note) = 'hello world'; #这样不能用到note上的索引
可以新建一个函数索引:
create index mytest_lower_note_idx on mytest (lower(note)); #可以用到索引,只是在插入数据行或更i性能数据行时会慢。
也可以加入唯一索引 unique:
create unique index mytest_lower_note_idx on mytest (lower(note)); #可以实现用户输入唯一的约束。
11.4.2部分索引:
由一个条件表达式把这部分数据行筛选出来。
示例一:
在ip地址上建索引
create table access_log ( url varchar, client_ip inet,...);
create index access_log_client_ip_ix on access_log (client_ip) where not (client_ip > inet '192.168.100.0' and client_ip < inet '192.168.100.255');
select * from accesss_log where client_ip = inet '114.113.220.27'; #能用到索引,但是192的地址就用不到索引了
示例二:设置一个部份索引以排除不感兴趣的数值
create table orders(order_nr int, amount decimal(12,2), billed boolean);
create index orders_unbilled_index on orders (order_nr) where billed is not true;
在order_nr上建索引,并且限定时没有下订单的。
造数据:
insert into orders select t.seq, t.seq*2.44, true from generate_series(1,500000) as t(seq));
insert into orders select t.seq, t.seq*2.44, false from generate_series(500001,509000) as t(seq));
select * from orders where billed is not rue and order_nr < 10000;
该索引也可以用于那些完全不涉及索引键order_nr的查询:
explain select * from orders where billed is not true and amount > 643242;
示例三:设置一个部份唯一索引
在表的子集里创建唯一索引,这样就可强制在满足谓词的行中保持唯一性,同时并不约束那些不需要唯一的行。
假设有一个记录测试项目是否成功的表,希望只有一条成功的记录,但是可以有多条不成功记录。
create table tests (
subject text,
target text,
success boolean,
);
create unique index tests_success_constraint on tests (subject,target) where success;
---------------------------------------
11.5序列sequence
create sequence seqtest01;
select nextval('seqtest01'); #1
select currval('seqtest01'); #1
如果新开一个session,不能直接调用currval('seqtest01'); #报错,因为没执行过nextval。
select lastval(); #总是返回最后一次调用nextval函数的值。不管之前有没有调用过,这和currval不同。
setval函数能改变序列的当前值,若之后再调用nextval函数,返回值将会变成改变后的当前值+1:
select setval('seqtest01', 1); #设为1
select nextval('seqtest01'); #返回2
在事务中使用序列,事务回滚后,序列不会回滚。
序列满了,会报错,除非在建序列的时候加上cycle选项
create sequence seq03 minvalue 1 maxvalue 3;
select nextval('seq03'); //1
select nextval('seq03'); //2
select nextval('seq03'); //3
再执行就报错了。
除非加上cycle选项:
create sequence seq04 start 2 minvalue 1 maxvalue 3 cycle;
select nextval('seq04'); //2 因为start从2开始
select nextval('seq04'); //3
select nextval('seq04); //2
select nextval('seq04); //3
-----------------------------------------
12.4性能监控
postgresql提供了很多性能统计视图。这些视图都以pg_stat开头。
配置参数为:
track_counts是否收集表和索引上的统计信息。默认on
track_functions 可以取none,pl,all,如果时pl则只收集pl/pgsql写的函数的统计信息。all表示收集所有类型的函数,包括c语言和sql写的函数。默认为none
track_activities 是否收集当前正在执行的sql。默认on
track_io_timing 是否收集io的时间信息。默认off。因为收集可能会导致性能瓶颈
最长用的视图为pg_stat_activity,查看正在运行的sql
\x
select * from pg_stat_activity;
还提供了各个对象级别的统计信息视图:
pg_stat_database 各个数据库相关的活跃服务器进程数。已提交的事务总数。已回滚的事务总数。已读取的磁盘块总数。缓冲区命中的总数。行插入,行读取,行删除的总数。死锁发生次数。读数据块的总时间。写数据库的总时间。
pg_stat_all_tables 顺序扫描的总数。顺序扫描抓取的活数据行的数目。索引扫描的总数。索引扫描抓取的活数据行的数目。插入的总行数,更新的总行数,删除的总行数,hot(heap only tuple)更新的总行数。上次手动vacuum该表的时间,上次由autovacuum自动清理该表的时间。上次手动analyze该表的时间,上次由autovacuum自动analyze该表的时间。vacuum的次数。autovacuum的次数。analyze的次数。由autovacuum自动analyze此表的次数。
pg_stat_sys_tables 同上
pg_stat_user_tables 同上
pg_stat_all_indexes
pg_stat_sys_indexes
pg_stat_user_indexes
postgresql还提供了对数据库内函数的调用次数及其他信息进行统计的视图:
pg_stat_user_functions
提供了如下信息:
每个函数的调用次数。
执行每个函数花费的总时间
执行函数时它自身花费的总时间,不包括它调用其他函数花费的时间。
postgresql还提供了以下对象上发生io情况的统计视图:
pg_statio_all_tables
pg_statio_sys_tables
pg_statio_user_tables
pg_statio_all_indexes
pg_statio_sys_indexes
pg_statio_user_indexes
pg_statio_all_sequences
pg_statio_sys_sequences
pg_statio_user_sequences
这些视图统计了这个对象上数据块的读取总数,缓存区命中的总数,如果是表,还提供了该表上所有索引的磁盘块读取总数,所有索引的缓冲区命中总数,辅助toast表上的磁盘块读取总数,辅助toast表上的缓冲区命中总数,toast表中索引的磁盘块读取总数,toast表中索引的缓冲区命中总数。
这一系列pg_statio_视图在判断缓冲区效果时特别有用,可以统计出各个数据库缓冲区的命中率。
---------------------------------------------------------
13.2pg_baseackup工具
pg_basebackup完成数据库的基础备份。这个工具会把整个数据库实例拷贝出来。
该工具使用replication协议连接到数据库实例上,所以主数据库中的pg_hba.conf必须允许relication连接。
local replication osdba trust
local replication osdba ident
host replication osdba 0.0.0.0/0 md5
这里第二列的数据库名填写的是replication,并不是代表连接到名称为replication数据库上,而是表示允许replication连接。
理论上一个数据库可以被几个pg_basebacup同时链接上去,但为了不影响主库的性能,建议最好还是一个数据库同时只有一个pg_basebackup在做备份。
在9.2之后postgresql之后支持级联复制,pg_basebackup也可以从一个standby库上做基础备份,但从standby备份有以下一些注意事项:
1.备份中没有备份历史文件
2。不确保所有需要的wal文件都备份了,如果想确保,需要加命令行参数-x
3.如果在备份过程中standby被提升为主库,则备份会失败。
4.要求主库打开了full_page_writes参数,wal文件不能被类似pg_compresslog的工具去掉full-page writes信息。
13.2.2 pg_basebackup命令行参数
-D directory 或 --pgdata=directory: 指定把备份写到哪个目录。如果这个目录或这个目录路径中的各级父目录不存在,则pg_basebackup就会自动创建这个目录。如果这个目录存在,但目录不为空,会导致pg_basebackup执行失败。如果备份的出书是tar结果(-F tar),而-D参数后的目录名写成了 "-" ,则备份会输出到标准输出中,以便管道与其他工具配合使用。
-F format 或 --format=format 指定输出格式,仅支持两种格式,一种是原样输出,即把主数据库中的各个数据文件,配置文件,目录接口都完全一样的写到备份目录,这种情况下format指定为p或plain;另一种是tar格式,相当于把输出的备份文件打包到一个tar文件中,这种情况下format为t或tar
-x 或 --xlog 备份时会把悲愤中产生的xlog文件也自动备份出来,这样才嗯那个在恢复数据库时,应用这些xlog文件把数据库推到一个一致点,然后真正打开这个备份的数据库。这个选项与“-X fetch”是完全一样的。使用这个选项,需要设置wal_keep_segments参数,以保证在备份过程中,需要的wal日志文件不会被覆盖。
-X method或--xlog-method=method method可以取值为f fetch s stream,这四种。f=fetch,意义和-x参数一样。s=stream,表示备份开始后,启动另一个流复制连接从主库接收wal日志,这种方式避免了使用-X f时,主库上的wal日志有可能被覆盖而导致失败的问题。但这种方式需要与主库建两个连接,因此使用这种方式时,主库的max_wal_senders参数至少需要设置为2或大于2的值。
-z或--gzip 仅能与tar输出模式配合使用,表明输出的tar备份包时经过gzip压缩的,相当于生成了要给*.tar.gz的备份包。
-c fast | spread 或 --checkpoint=fast | spread。设置checkpoint模式时fast还是spread
-P或 --pregress 允许在备份过程中实时地打印备份的进度。
-v --verbose 享系模式,使用了-P参数后,还会打印出正在备份的具体文件的信息。
命令例子1:
pg_basebackup -D backup -Ft -z -P
其中命令没有指定任何连接参数,所以会连到本地数据库上。想让后续命令成功运行,一般要在pg_hba.conf上允许本地连接,如在pg_hba.conf上做类似下面配置:
local replication osdba ident
上面配置中,osdba是数据库中的一个超级用户,或者是本地的一个有replication权限的用户,走的认证是ident,表示需要与数据库用户osdba存在一个对应的操作系统用户
命令执行后,会生成一个backup_label文件,内容中,如果不指定备份label,pg_basebacup工具生成的label为pg_basebackup base backup
命令例子2:
pg_basebackup -h 192.168.1.108 -U osdba -F p -P -x -R -D /home/osdba/pgdata -l osdbabackup20200122
上面命令把192.168.1.108上的数据库备份到本地,使用的连接用户名为osdba,输出格式为普通原样输出(-F p),在执行过程中会输出备份的进度(-P),且自动把在备份过程中产生的xlog也备份出来-x,同时在备份中会生成一个ierecovery.conf,当用词备份启动备库时,只需要简单修改recovery.conf,就可以把数据库启动起来。备份文件都生成到/home/osdba/pgdata目录下,备份的标志串为osdbabackup20200122
13.3异步流复制hot standby的示例:
db1 10.0.0.1 主库 /home/osdba/pgdata
db2 10.0.0.2 Standby /home/osdba/pgdata
13.3.2主数据的配置:
需要允许主库接受流复制的连接,需要在/home/osdba/pgdata/pg_hba.conf中做如下配置:
host replication osdba 10.0.0.0/24 md5
允许用户osdba从10.0.0.0/24的网络上发起到本数据库的流复制连接,使用md5密码认证。
因为建的是使用流复制的Hot Standby,所以需要在主库db01上的/home/osdba/pgdata/postgresql.conf中设置如下几个参数:
listen_address='*'
max_wal_senders=8 #如果要建多台hot_standby服务器,一定要设置成大于0的值。
wal_level=host_standby #主库要建hot standby服务器,wal_level一定要设置hot_standby
13.3.3在Standby上生成基础备份
完成上述准备工作后,就可以使用pg_basebackup命令行工具在db02机器上生成基础备份了:
pg_basebackup -h 10.0.0.1 -U osdba -F p -P -x -R -D /home/osdba/pgdata -l osdbabackup20200122
执行完上面命令后,就可在db02机器上的/home/osdba/pgdata目录下看到拷贝过来的各种数据文件及配置文件:
ls -l /home/osdba/pgdata
因为使用了-R参数,所以生成了recovery.conf
13.3.4启动standby
在db2机器启动standby数据库之前,还需要修改/home/osdba/pgdata/postgresql.conf
hot_standby=on
然后启动standby,就可自动进入hot standby状态,这时可以连接到hot standby上
pgstart #server starting
psql postgres
测试:
在主库上建测试表,插入数据,备库马上就同步了。
因为hotstandby是只读的,所以在standby上修改,操作会失败
13.4同步流复制的standby数据库
同步流复制要求在数据写入standby数据库后,事务的commit才返回,所以standby库出现问题时,会导致主库被hang住。解决这个问题的方法是启动两个standby数据库,这两个standby数据库只要有一个是正常的,就不会让主库hang住。
13.4.2同步复制的配置
主库上配置:
synchronous_standby_names,这个参数指定多个standby名称,各个名称通过逗号分隔,而standby名称是在standby连接到主库时,由连接参数application_name指定的。要使用同步复制,在standby数据库中,recovery.conf里的primary_conninfo一定要指定连接参数application_name。 recovery.conf示例如下:
standby_mode='on'
primary_conninfo='application_name=standby01 user=osdba password=xxxxx ....'
配置示例:
db1 10.0.0.1 主库 /home/osdba/pgdata
db2 10.0.0.2 standby /home/osdba/pgdata
db2 10.0.0.3 standby /home/osdba/pgdata
第一步:在主库db1上配置:
pg_hba.conf
host replication osdba 10.0.0.0/24 md5
postgresql.conf配置:
max_wal_senders=8
wal_level=hot_standby
synchronous_standby_names='standby01,standby02' #这个standby01,standby02就是在standby数据库中配置连接参数application_name时指定的。
第二步,在备库db2上进行配置
recovery.conf增加:
primary_conninfo='application_name=standby01 user=osdba ...'
完成配置后,启动数据库:
pgstart
第三步在备库db2上进行配置
recovery.conf增加:
primary_conninfo='application_name=standby02 user=osdba ...'
完成配置后,启动数据库:
pgstart
第四步:在主库上启动同步复制
在主库上改变参数synchronous_standby_names并不需要重启数据库,只需要重新装载配置即可:
pg_ctl reload -D /home/osdba/pgdata
测试:
先关掉standby db2,看主库能否正常工作:
db2 : pgstop
然后主库建表,插入数据
在关掉standby db3,
db3: pgstop
主库select,没问题。
主库insert update delete,都hang住了。
这时再启动一台standby db2:
db2:pgstart
发现主库hang主的操作可以继续下去。
13.5检查备库及流复制情况
如果流复制时异步的,查询视图pg_stat_replication:
select pid,state,client_addr, sync_priority,sync_state from pg_stat_replication;
可以看到,sync_state字段显示的信息为async
另外,再pg_stat_replication视图中有如下几个字段记录发送wal的位置及备库接收到wal的位置,备库写wal日志到磁盘的位置,备库应用日志的位置:
sent_location
write_location
flush_location
replay_location
查看备库落后主库多少字节的wal日志,可以用下面的sql
select pg_xlog_location_diff(pg_current_xlog_location(), replay_location) from pg_stat_replication;
检查同步流复制的情况:
select pid,state,client_addr, sync_priority,sync_state from pg_stat_replication;
可以看到db2的优先级为1,db3的优先级为2.这个优先级是由synchronous_standby_names参数配置的顺序决定的。目前主库与db2处于同步sync,而db3的状态为potential,表示db3是一个潜在的同步standby,当db2损坏时,db3会切换到同步状态,这时关掉db2:
db2:pgstop
主库:select pid,state,client_addr, sync_priority,sync_state from pg_stat_replication;
可以看到db3 state变成sync
再启动db2
db2: pgstart
select pid,state,client_addr, sync_priority,sync_state from pg_stat_replication;
db3再次变为potential,db2变为sync同步状态
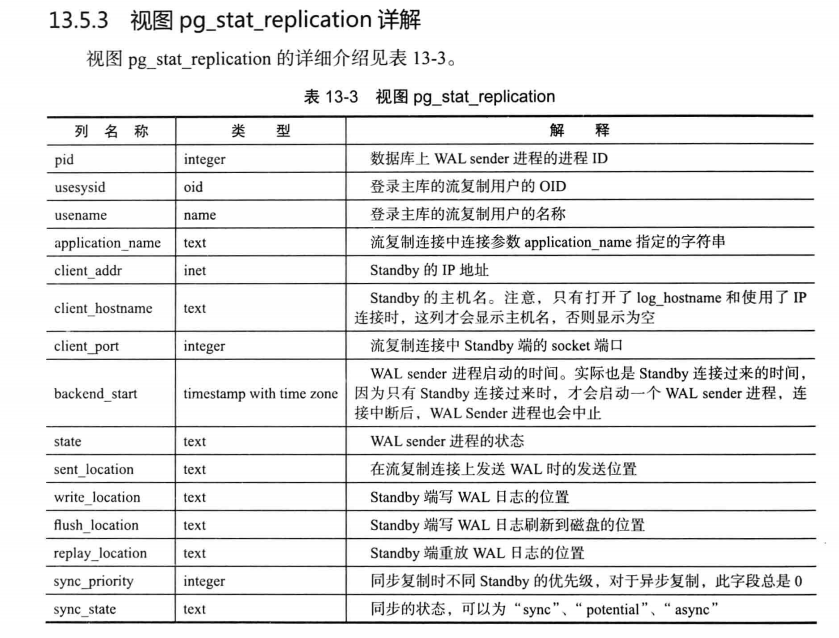
13.5.4查看备库状态
如果数据库处于host standby状态,可以连接到数据库中执行pg_is_in_recovery()函数。
如果是在主库上,此函数返回是false。如果是备库上,返回的是true
如果备库不是host standby,不能直接连接上去,这时可以使用命令行工具pg_controldata来判断,可以在主库上看到database cluster 为 ”in production“ :
db1主库: pg_controldata
db2 db3 备库: pg_controldata #这里显示in archive recovery
在hot standby上还可以执行如下一些函数,查看备库接收的wal日志和应用wal日志的状态:
pg_last_xlog_receive_location()
pg_last_xlog_replay_location()
pg_last_xact_replay_timestamp()

13.6 Hot standby的限制:
dml:insert,update,delete,copy from,truncate
ddl:create,drop,alter,comment不能再hot standby执行。
select ... for share | update语句也不能执行。因为在postgresql中,行锁是要更新数据行的。
select * from test01 for update; #备库执行会报错
虽然行锁不能使用,但部份类型的表锁是可以使用的,只要注意这部分表锁需要在begin启动的事务块中使用。

如果使用begin启动事务块,则不会报错:
begin;
lock table test01 in access share mode;
end;
begin;
lock table test01 in row share mode;
end;
begin;
lock table test01 in row exclusive mode;
end;
begin;
lock table test01 in share update exclusive mode; 报错
end;
begin;
lock table test01 in share mode; 报错
end;
begin;
lock table test01 in share row exclusive mode; 报错
end;
begin;
lock table test01 in exclusive mode; 报错
end;
begin;
lock table test01 in access exclusive mode; 报错
end;
也就是说,比row exclusive mode级别高的表锁都是不能执行的,或者说,自己和自己互斥的锁和”share“类型的表锁都不能执行。
两阶段提交的命令也不能执行:
prepare transaction
commit prepared
rollback prepared
序列中会导致更新的函数同样不能执行:
nextval()
setval()
此外消息通知的语句也不能执行:
listen
unlisten
notify
13.7恢复配置详解
13.7.1归档恢复配置的配置项(archive方式,而上面的时流复制streaming方式)
recovery.conf主要有以下三项:
1.restore_command 指定standby如何获得wal日志文件,通常是配置一个拷贝命令,从一个备份目录把一个wal日志文件拷贝过来。
2.archive_cleanup_command 清理standby数据库机器上不需要的wal日志文件
3.recovery_end_command 恢复完成后,可以执行一个命令
使用这几个配置项就可以搭建起一个从归档日志文件中恢复的standby数据库。
例如在主库上配置archive_command参数,把wal文件复制到standby库的一个目录下:
archive_command='scp %p 192.168.1.1:/data/archivedir/%f.mid && ssh 192.168.1.2 "mv /data/archivedir/%f.mid /data/archivedir/%f"'
然后再standby数据库的recovery.conf中配置restore_command参数:
restore_command='cp /data/archivedir /%f "%p"'
archive_cleanup_command参数可以用来清理上面实例中/data/archivedir目录下的wal日志文件。
从上面例子可以知道,当主库不断把wal日志文件复制到standby的"/data/archivedir"中时,一定要有清理机制,否则就会把空间占满。
清理的原则通常是清除standby已使用完的wal日志文件。
contrib目录中提供了一个命令行的工具pg_archivecleanup可以很方便地实现这个清理工作。
archive_cleanup_command的参数配置内容如下:
archive_cleanup_command='pg_archivecleanup /data /archivedir %r'
13.7.2 Recovery Target配置
recovery_target 此参数只能配置为空或immediate。当设置为immediate时,则standby恢复到一个一致点时,就立即停止恢复。这通常使用在热备份中。完成一个热备份后,如果想使用它,希望应用wal日志再把热备份恢复到一个可以打开的点时,就立即打开此数据库,则需要配置此参数。
recovery_target_name 再主库上可以创建要给回复点,然后让standby恢复到这个点,此参数就是用来指定这个恢复点的名称的。创建恢复点时通过调用函数pg_create_restore_point()来完成的
recovery_target_time 用于指定恢复到哪个时间点。恢复到这个时间点之前最近的一致点还是这个时间点之后最近的一致点是由参数recovery_target_inclusive来指定的。
recovery_target_xid。 用于恢复到哪个事务。
recovery_target_inclusive 指定恢复到回复目标recovery target之后还是之前。默认为之后,也就是true。
13.7.3 Standby Server配置
还有如下一些参数用于配置Standby Server
standby_mode 默认on。是否运行在standby模式下。
primary_conninfo 在流复制中,如何连接主库。是一个标准的libpg连接串
primary_slog_name 指定复制槽replication slot。
把备库激活为主库: pg_ctl promote 来激活standby数据库
recovery_min_apply_delay 此参数可以让standby数据库落后主库一段时间。可以防止误删除。可以为这个参数指定要给时间值,如5min。设置此参数后hot_standby_feedback也会相应被延迟。
13.8 流复制的注意事项
13.8.1 wal_keep_segments参数
主库上都要保留多少个wal日志文件。默认参数为0,表示并不专门为standby保留wal日志文件。通常需要把此参数配置成一个安全的值,如64.如果每个wal日志大小通常是16mb,那么会占用64x16=1GB空间。磁盘允许的话,可以设置的大一些。
13.8.2 vacuum_defer_cleanup_age参数
在主库上,vacuum进程知道那些旧版本的数据会被当前数据中的查询使用,从而不清理这些数据。但对hot standby上的查询,主库时不知道的,所以主库上的vacuum可能会把hot standby上的查询还需要的旧版本数据清理掉,导致standby上的查询失败。可以在主库设置vacuum_defer_cleanup_age参数,让主库延迟清理。这个参数的意思时延迟清理多少个事务。
系统信息函数:摘自http://www.postgres.cn/docs/11/functions-info.html#FUNCTIONS-INFO-SESSION-TABLE
表 9.60. 会话信息函数
| 名称 | 返回类型 | 描述 |
|---|---|---|
current_catalog |
name |
当前数据库名(SQL 标准中称作“目录”) |
current_database() |
name |
当前数据库名 |
current_query() |
text |
当前正在执行的查询的文本,和客户端提交的一样(可能包含多于一个语句) |
current_role |
name |
等效于current_user |
|
name |
当前模式名 |
current_schemas( |
name[] |
搜索路径中的模式名,可以选择是否包含隐式模式 |
current_user |
name |
当前执行上下文的用户名 |
inet_client_addr() |
inet |
远程连接的地址 |
inet_client_port() |
int |
远程连接的端口 |
inet_server_addr() |
inet |
本地连接的地址 |
inet_server_port() |
int |
本地连接的端口 |
pg_backend_pid() |
int |
与当前会话关联的服务器进程的进程 ID |
pg_blocking_pids( |
int[] |
阻塞指定服务器进程ID获得锁的进程 ID |
pg_conf_load_time() |
timestamp with time zone |
配置载入时间 |
pg_current_logfile([ |
text |
当前日志收集器在使用的主日志文件名或者所要求格式的日志的文件名 |
pg_my_temp_schema() |
oid |
会话的临时模式的 OID,如果没有则为 0 |
pg_is_other_temp_schema( |
boolean |
模式是另一个会话的临时模式吗? |
pg_jit_available() |
boolean |
这个会话中JIT编译是否可用(见第 32 章)?如果jit被设置为假,则返回false。 |
pg_listening_channels() |
setof text |
会话当前正在监听的频道名称 |
pg_notification_queue_usage() |
double |
异步通知队列当前被占用的分数(0-1) |
pg_postmaster_start_time() |
timestamp with time zone |
服务器启动时间 |
pg_safe_snapshot_blocking_pids( |
int[] |
阻止指定服务器进程ID获取安全快照的进程ID |
pg_trigger_depth() |
int |
PostgreSQL触发器的当前嵌套层次(如果没有调用则为 0,直接或间接,从一个触发器内部开始) |
session_user |
name |
会话用户名 |
user |
name |
等价于current_user |
version() |
text |
PostgreSQL版本信息。机器可读的版本还可见server_version_num。 |
访问权限查询函数:
| 名称 | 返回类型 | 描述 |
|---|---|---|
|
boolean |
用户有没有表中任意列上的权限 |
|
boolean |
当前用户有没有表中任意列上的权限 |
|
boolean |
用户有没有列的权限 |
|
boolean |
当前用户有没有列的权限 |
|
boolean |
用户有没有数据库的权限 |
|
boolean |
当前用户有没有数据库的权限 |
|
boolean |
用户有没有外部数据包装器上的权限 |
|
boolean |
当前用户有没有外部数据包装器上的权限 |
|
boolean |
用户有没有函数上的权限 |
|
boolean |
当前用户有没有函数上的权限 |
|
boolean |
用户有没有语言上的权限 |
|
boolean |
当前用户有没有语言上的权限 |
|
boolean |
用户有没有模式上的权限 |
|
boolean |
当前用户有没有模式上的权限 |
|
boolean |
用户有没有序列上的权限 |
|
boolean |
当前用户有没有序列上的权限 |
|
boolean |
用户有没有外部服务器上的权限 |
|
boolean |
当前用户有没有外部服务器上的权限 |
|
boolean |
用户有没有表上的权限 |
|
boolean |
当前用户有没有表上的权限 |
|
boolean |
用户有没有表空间上的权限 |
|
boolean |
当前用户有没有表空间上的权限 |
|
boolean |
用户有没有类型的特权 |
|
boolean |
当前用户有没有类型的特权 |
|
boolean |
用户有没有角色上的权限 |
|
boolean |
当前用户有没有角色上的权限 |
|
boolean |
当前用户是否在表上开启了行级安全性 |
一些例子:
SELECT has_table_privilege('myschema.mytable', 'select');
SELECT has_table_privilege('joe', 'mytable', 'INSERT, SELECT WITH GRANT OPTION');
系统管理函数:摘自http://www.postgres.cn/docs/11/functions-admin.html
配置设定函数:查询以及修改运行时配置参数的函数。
表 9.77. 配置设定函数
| 名称 | 返回类型 | 描述 |
|---|---|---|
current_setting( |
text |
获得设置的当前值 |
set_config( |
text |
设置一个参数并返回新值 |
SELECT current_setting('datestyle');
set_config将参数setting_name设置为new_value。如果 is_local设置为true,那么新值将只应用于当前事务。 如果你希望新值应用于当前会话,那么应该使用false。 它等效于 SQL 命令 SET。例如:
SELECT set_config('log_statement_stats', 'off', false);
set_config
------------
off
(1 row)
9.26.2. 服务器信号函数
在表 9.78中展示的函数向其它服务器进程发送控制信号。默认情况下这些函数只能被超级用户使用,但是如果需要,可以利用GRANT把访问特权授予给其他用户。
表 9.78. 服务器信号函数
| 名称 | 返回类型 | 描述 |
|---|---|---|
pg_cancel_backend( |
boolean |
取消一个后端的当前查询。如果调用角色是被取消后端的拥有者角色的成员或者调用角色已经被授予pg_signal_backend,这也是允许的,不过只有超级用户才能取消超级用户的后端。 |
pg_reload_conf() |
boolean |
导致服务器进程重载它们的配置文件 |
pg_rotate_logfile() |
boolean |
切换服务器的日志文件 |
pg_terminate_backend( |
boolean |
中止一个后端。如果调用角色是被取消后端的拥有者角色的成员或者调用角色已经被授予pg_signal_backend,这也是允许的,不过只有超级用户才能取消超级用户的后端。 |
这些函数中的每一个都在成功时返回true,并且在失败时返回false。
pg_cancel_backend和pg_terminate_backend向由进程 ID 标识的后端进程发送信号(分别是SIGINT或SIGTERM)。一个活动后端的进程 ID可以从pg_stat_activity视图的pid列中找到,或者通过在服务器上列出postgres进程(在 Unix 上使用ps或者在Windows上使用任务管理器)得到。一个活动后端的角色可以在pg_stat_activity视图的usename列中找到。
pg_reload_conf给服务器发送一个SIGHUP信号, 导致所有服务器进程重载配置文件。
pg_rotate_logfile给日志文件管理器发送信号,告诉它立即切换到一个新的输出文件。这个函数只有在内建日志收集器运行时才能工作,因为否则就不存在日志文件管理器子进程。 subprocess.
9.26.3. 备份控制函数
表 9.79中展示的函数可以辅助制作在线备份。这些函数不能在恢复期间执行(pg_is_in_backup、pg_backup_start_time和pg_wal_lsn_diff除外)。
表 9.79. 备份控制函数
| 名称 | 返回类型 | 描述 |
|---|---|---|
pg_create_restore_point( |
pg_lsn |
为执行恢复创建一个命名点(默认只限于超级用户,但是可以授予其他用户 EXECUTE 特权来执行该函数) |
pg_current_wal_flush_lsn() |
pg_lsn |
得到当前的预写式日志刷写位置 |
pg_current_wal_insert_lsn() |
pg_lsn |
获得当前预写式日志插入位置 |
pg_current_wal_lsn() |
pg_lsn |
获得当前预写式日志写入位置 |
pg_start_backup( |
pg_lsn |
准备执行在线备份(默认只限于超级用户或者复制角色,但是可以授予其他用户 EXECUTE 特权来执行该函数) |
pg_stop_backup() |
pg_lsn |
完成执行排他的在线备份(默认只限于超级用户或者复制角色,但是可以授予其他用户 EXECUTE 特权来执行该函数) |
pg_stop_backup( |
setof record |
结束执行排他或者非排他的在线备份 (默认只限于超级用户,但是可以授予其他用户 EXECUTE 特权来执行该函数) |
pg_is_in_backup() |
bool |
如果一个在线排他备份仍在进行中则为真。 |
pg_backup_start_time() |
timestamp with time zone |
获得一个进行中的在线排他备份的开始时间。 |
pg_switch_wal() |
pg_lsn |
强制切换到一个新的预写式日志文件(默认只限于超级用户,但是可以授予其他用户 EXECUTE 特权来执行该函数) |
pg_walfile_name( |
pg_lsn |
转换预写式日志位置字符串为文件名 |
pg_walfile_name_offset( |
pg_lsn, integer |
转换预写式日志位置字符串为文件名以及文件内的十进制字节偏移 |
pg_wal_lsn_diff( |
numeric |
计算两个预写式日志位置间的差别 |
pg_start_backup接受一个参数,这个参数可以是备份的任意用户定义的标签(通常这是备份转储文件将被存储的名字)。当被用在排他模式中时,该函数向数据库集簇的数据目录写入一个备份标签文件(backup_label)和一个表空间映射文件(tablespace_map,如果在pg_tblspc/目录中有任何链接),执行一个检查点,然后以文本方式返回备份的起始预写式日志位置。用户可以忽略这个结果值,但是为了可能需要的场合我们还是提供该值。 当在非排他模式中使用时,这些文件的内容会转而由pg_stop_backup函数返回,并且应该由调用者写入到备份中去。
postgres=# select pg_start_backup('label_goes_here');
pg_start_backup
-----------------
0/D4445B8
(1 row)
第二个参数是可选的,其类型为boolean。如果为true,它指定尽快执行pg_start_backup。这会强制一个立即执行的检查点,它会导致 I/O 操作的峰值,拖慢任何并发执行的查询。
在一次排他备份中,pg_stop_backup会移除标签文件以及pg_start_backup创建的tablespace_map文件(如果存在)。在一次非排他备份中,backup_label和tablespace_map的内容会包含在该函数返回的结果中,并且应该被写入到该备份的文件中(这些内容不在数据目录中)。有一个可选的boolean类型的第二参数。如果为假,pg_stop_backup将在备份完成后立即返回而不等待WAL被归档。这种行为仅对独立监控WAL归档的备份软件有用。否则,让备份一致所要求的WAL可能会丢失,进而让备份变得毫无用处。当这个参数被设置为真时,在启用归档的前提下pg_stop_backup将等待WAL被归档,在后备服务器上,这意味只有archive_mode = always时才会等待。如果主服务器上的写活动很低,在主服务器上运行pg_switch_wal以触发一次即刻的段切换会很有用。
当在主服务器上执行时,该函数还在预写式日志归档区里创建一个备份历史文件。这个历史文件包含给予pg_start_backup的标签、备份的起始与终止预写式日志位置以及备份的起始和终止时间。返回值是备份的终止预写式日志位置(同样也可以被忽略)。在记录结束位置之后,当前预写式日志插入点被自动地推进到下一个预写式日志文件,这样结束的预写式日志文件可以立即被归档来结束备份。
pg_switch_wal移动到下一个预写式日志文件,允许当前文件被归档(假定你正在使用连续归档)。返回值是在甘冈完成的预写式日志文件中结束预写式日志位置 + 1。如果从上一次预写式日志切换依赖没有预写式日志活动,pg_switch_wal不会做任何事情并且返回当前正在使用的预写式日志文件的开始位置。
pg_create_restore_point创建一个命名预写式日志记录,它可以被用作恢复目标,并且返回相应的预写式日志位置。这个给定的名字可以用于recovery_target_name来指定恢复要进行到的点。避免使用同一个名称创建多个恢复点,因为恢复会停止在第一个匹配名称的恢复目标。
pg_current_wal_lsn以上述函数所使用的相同格式显示当前预写式日志的写位置。类似地,pg_current_wal_insert_lsn显示当前预写式日志插入点,而pg_current_wal_flush_lsn显示当前预写式日志的刷写点。在任何情况下,插入点是预写式日志的“逻辑”终止点,而写入位置是已经实际从服务器内部缓冲区写出的日志的终止点,刷写位置则是被确保写入到持久存储中的日志的终止点。写入位置是可以从服务器外部检查的终止点,对那些关注归档部分完成预写式日志文件的人来说,这就是他们需要的位置。插入和刷写点主要是为了服务器调试目的而存在的。这些都是只读操作并且不需要超级用户权限。
你可以使用pg_walfile_name_offset从任何上述函数的结果中抽取相应的预写式日志文件名称以及字节偏移。例如:
postgres=# SELECT * FROM pg_walfile_name_offset(pg_stop_backup());
file_name | file_offset
--------------------------+-------------
00000001000000000000000D | 4039624
(1 row)
相似地,pg_walfile_name只抽取预写式日志文件名。当给定的预写式日志位置正好在一个预写式日志文件的边界,这些函数都返回之前的预写式日志文件的名称。这对管理预写式日志归档行为通常是所希望的行为,因为前一个文件是当前需要被归档的最后一个文件。
pg_wal_lsn_diff以字节数计算两个预写式日志位置之间的差别。它可以和pg_stat_replication或表 9.79中其他的函数一起使用来获得复制延迟。
关于正确使用这些函数的细节,请见第 25.3 节。
9.26.4. 恢复控制函数
表 9.80中展示的函数提供有关后备机当前状态的信息。这些函数可以在恢复或普通运行过程中被执行。
表 9.80. 恢复信息函数
| 名称 | 返回类型 | 描述 |
|---|---|---|
pg_is_in_recovery() |
bool |
如果恢复仍在进行中,为真。 |
pg_last_wal_receive_lsn() |
pg_lsn |
获得最后一个收到并由流复制同步到磁盘的预写式日志位置。当流复制在进行中时,这将单调增加。如果恢复已经完成,这将保持静止在恢复过程中收到并同步到磁盘的最后一个 WAL 记录。如果流复制被禁用,或者还没有被启动,该函数返回 NULL。 |
pg_last_wal_replay_lsn() |
pg_lsn |
获得恢复过程中被重放的最后一个预写式日志位置。当流复制在进行中时,这将单调增加。如果恢复已经完成,这将保持静止在恢复过程中被应用的最后一个 WAL 记录。如果服务器被正常启动而没有恢复,该函数返回 NULL。 |
pg_last_xact_replay_timestamp() |
timestamp with time zone |
获得恢复过程中被重放的最后一个事务的时间戳。这是在主机上产生的事务的提交或中止 WAL 记录的时间。如果在恢复过程中没有事务被重放,这个函数返回 NULL。否则,如果恢复仍在进行这将单调增加。如果恢复已经完成,则这个值会保持静止在恢复过程中最后一个被应用的事务。如果服务器被正常启动而没有恢复,该函数返回 NULL。 |
表 9.81中展示的函数空值恢复的进程。这些函数只能在恢复过程中被执行。
表 9.81. 恢复控制函数
| 名称 | 返回类型 | 描述 |
|---|---|---|
pg_is_wal_replay_paused() |
bool |
如果恢复被暂停,为真。 |
pg_wal_replay_pause() |
void |
立即暂停恢复(默认仅限于超级用户, 但是可以授予其他用户 EXECUTE 特权来执行该函数)。 |
pg_wal_replay_resume() |
void |
如果恢复被暂停,重启之(默认仅限于超级用户,但是可以授予其他用户 EXECUTE 特权来执行该函数)。 |
在恢复被暂停时,不会有进一步的数据库改变被应用。如果在热备模式,所有新的查询将看到数据库的同一个一致快照,并且在恢复被继续之前不会有更多查询冲突会产生。
如果流复制被禁用,暂停状态可以无限制地继续而不出问题。在流复制进行时,WAL 记录将继续被接收,最后将会填满可用的磁盘空间,取决于暂停的持续时间、WAL 的产生率和可用的磁盘空间。
9.26.5. 快照同步函数
PostgreSQL允许数据库会话同步它们的快照。一个快照决定对于正在使用该快照的事务哪些数据是可见的。当两个或者更多个会话需要看到数据库中的相同内容时,就需要同步快照。如果两个会话独立开始其事务,就总是有可能有某个第三事务在两个START TRANSACTION命令的执行之间提交,这样其中一个会话就可以看到该事务的效果而另一个则看不到。
为了解决这个问题,PostgreSQL允许一个事务导出它正在使用的快照。只要导出的事务仍然保持打开,其他事务可以导入它的快照,并且因此可以保证它们可以看到和第一个事务看到的完全一样的数据库视图。但是注意这些事务中的任何一个对数据库所作的更改对其他事务仍然保持不可见,和未提交事务所作的修改一样。因此这些事务是针对以前存在的数据同步,而对由它们自己所作的更改则采取正常的动作。
如表 9.82中所示,快照通过pg_export_snapshot函数导出,并且通过SET TRANSACTION命令导入。
表 9.82. 快照同步函数
| 名称 | 返回类型 | 描述 |
|---|---|---|
pg_export_snapshot() |
text |
保存当前快照并返回它的标识符 |
函数pg_export_snapshot保存当前的快照并且返回一个text串标识该快照。该字符串必须被传递(到数据库外)给希望导入快照的客户端。直到导出快照的事务的末尾,快照都可以被导入。如果需要,一个事务可以导出多于一个快照。注意这样做只在 READ COMMITTED事务中有用,因为在REPEATABLE READ和更高隔离级别中,事务在它们的生命期中都使用同一个快照。一旦一个事务已经导出了任何快照,它不能使用PREPARE TRANSACTION。
关于如何使用一个已导出快照的细节请见SET TRANSACTION.
9.26.6. 复制函数
表 9.83中展示的函数 用于控制以及与复制特性交互。有关底层特性的信息请见 第 26.2.5 节、 第 26.2.6 节以及 第 50 章。这些函数只限于超级 用户使用。
很多这些函数在复制协议中都有等价的命令,见 第 53.4 节。
第 9.26.3 节、 第 9.26.4 节和 第 9.26.5 节 中描述的函数也与复制相关。
表 9.83. 复制 SQL 函数
| 函数 | 返回类型 | 描述 |
|---|---|---|
pg_create_physical_replication_slot( |
(slot_name name, xlog_position pg_lsn) |
创建一个新的名为slot_name的物理复制槽。第二个参数是可选的,当它为true时,立即为这个物理槽指定要被保留的LSN。否则该LSN会被保留在来自一个流复制客户端的第一个连接上。来自一个物理槽的流改变只可能出现在使用流复制协议时 — 见第 53.4 节。当可选的第三参数temporary被设置为真时,指定那个槽不会被持久地存储在磁盘上并且仅对当前会话的使用有意义。临时槽也会在发生任何错误时被释放。这个函数对应于复制协议命令CREATE_REPLICATION_SLOT ... PHYSICAL。 |
pg_drop_replication_slot( |
void |
丢弃名为slot_name的物理或逻辑复制槽。 和复制协议命令DROP_REPLICATION_SLOT相同。对于逻辑槽,在连接到在其中创建该槽的同一个数据库时,必须调用这个函数。 |
pg_create_logical_replication_slot( |
(slot_name name, lsn pg_lsn) |
使用输出插件plugin创建一个名为 slot_name的新逻辑(解码)复制槽。当可选的第三参数temporary被设置为真时,指定那个槽不会被持久地存储在磁盘上并且仅对当前会话的使用有意义。临时槽也会在发生任何错误时被释放。对这个函数的调用与复制协议命令 CREATE_REPLICATION_SLOT ... LOGICAL具有相同的效果。 |
pg_logical_slot_get_changes( |
(lsn pg_lsn, xid xid, data text) |
返回槽slot_name中的改变,从上一次已经被消费的点开始返回。 如果upto_lsn和upto_nchanges为 NULL,逻辑解码将一 直继续到 WAL 的末尾。如果upto_lsn为非 NULL,解码将只包括那些在指 定 LSN 之前提交的事务。如果upto_nchanges为非 NULL, 解码将在其产生的行数超过指定值后停止。不过要注意, 被返回的实际行数可能更大,因为对这个限制的检查只会在增加了解码每个新的提交事务产生 的行之后进行。 |
pg_logical_slot_peek_changes( |
(lsn text, xid xid, data text) |
行为就像pg_logical_slot_get_changes()函数, 不过改变不会被消费, 即在未来的调用中还会返回这些改变。 |
pg_logical_slot_get_binary_changes( |
(lsn pg_lsn, xid xid, data bytea) |
行为就像pg_logical_slot_get_changes()函数, 不过改变会以bytea返回。 |
pg_logical_slot_peek_binary_changes( |
(lsn pg_lsn, xid xid, data bytea) |
行为就像pg_logical_slot_get_changes()函数, 不过改变会以bytea返回并且这些改变不会被消费, 即在未来的调用中还会返回这些改变。 |
pg_replication_slot_advance( |
(slot_name name, end_lsn pg_lsn) bool |
名为slot_name的复制槽的当前确认位置的增长。该槽将不会被反向移动,且它将不会被移动到超过当前插入位置的地方。返回该槽的名称以及它被推进到的真实位置。 |
pg_replication_origin_create( |
oid |
用给定的外部名称创建一个复制源,并且返回分配给它的内部 id。 |
pg_replication_origin_drop( |
void |
删除一个之前创建的复制源,包括任何相关的重放进度。 |
pg_replication_origin_oid( |
oid |
用名称查找复制源并且返回内部 id。如果没有找到则抛出错误。 |
pg_replication_origin_session_setup( |
void |
把当前会话标记为正在从给定的源进行重放,允许重放进度被跟踪。使用 pg_replication_origin_session_reset可以取消 标记。只有之前没有源被配置时才能使用。 |
pg_replication_origin_session_reset() |
void |
取消pg_replication_origin_session_setup()的效果。 |
pg_replication_origin_session_is_setup() |
bool |
当前会话中是否已经配置了一个复制源? |
pg_replication_origin_session_progress( |
pg_lsn |
返回当前会话中配置的复制源的重放位置。参数 flush决定对应的本地事务是否被确保 已经刷入磁盘。 |
pg_replication_origin_xact_setup( |
void |
标记当前事务为正在重放一个已经在给定的LSN 和时间戳提交的事务。只有当之前已经用 pg_replication_origin_session_setup()配置过 一个复制源时才能被调用。 |
pg_replication_origin_xact_reset() |
void |
取消pg_replication_origin_xact_setup()的效果。 |
pg_replication_origin_advance |
void |
把给定节点的复制进度设置为给定的位置。这主要用于配置更改或者类似 操作之后设置初始位置或者新位置。注意这个函数的不当使用可能会导致 不一致的复制数据。 |
pg_replication_origin_progress( |
pg_lsn |
返回给定复制元的重放位置。参数 flush决定对应的本地事务是否被确保 已经刷入磁盘。 |
pg_logical_emit_message( |
pg_lsn |
发出文本形式的逻辑解码消息。这可以被用来通过 WAL 向逻辑解码插件传递一般消息。参数transactional指定该消息是否应该是当前事务的一部分或者当逻辑解码读到该记录时该消息是否应该被立刻写入并且解码。prefix是逻辑解码插件用来识别它们感兴趣的消息的文本前缀。content是消息的文本。 |
pg_logical_emit_message( |
pg_lsn |
发出二进制逻辑解码消息。这可以被用来通过WAL向逻辑解码插件传递一般性消息。参数transactional指定该消息是否应该成为当前事务的一部分或者是否应该在逻辑解码过程读到该记录时立刻进行写入和解码。参数prefix是一个逻辑解码插件使用的文本前缀,逻辑解码插件用它来识别感兴趣的消息。参数content是消息的二进制内容。 |
9.26.7. 数据库对象管理函数
表 9.84中展示的函数计算数据库对象使用的磁盘空间。
表 9.84. 数据库对象尺寸函数
| 名称 | 返回类型 | 描述 |
|---|---|---|
pg_column_size( |
int |
存储一个特定值(可能压缩过)所需的字节数 |
pg_database_size( |
bigint |
指定 OID 的数据库使用的磁盘空间 |
pg_database_size( |
bigint |
指定名称的数据库使用的磁盘空间 |
pg_indexes_size( |
bigint |
附加到指定表的索引所占的总磁盘空间 |
pg_relation_size( |
bigint |
指定表或索引的指定分叉('main'、'fsm'、'vm'或'init')使用的磁盘空间 |
pg_relation_size( |
bigint |
pg_relation_size(..., 'main')的简写 |
pg_size_bytes( |
bigint |
把人类可读格式的带有单位的尺寸转换成字节数 |
pg_size_pretty( |
text |
将表示成一个 64位整数的字节尺寸转换为带尺寸单位的人类可读格式 |
pg_size_pretty( |
text |
将表示成一个数字值的字节尺寸转换为带尺寸单位的人类可读格式 |
pg_table_size( |
bigint |
被指定表使用的磁盘空间,排除索引(但包括 TOAST、空闲空间映射和可见性映射) |
pg_tablespace_size( |
bigint |
指定 OID 的表空间使用的磁盘空间 |
pg_tablespace_size( |
bigint |
指定名称的表空间使用的磁盘空间 |
pg_total_relation_size( |
bigint |
指定表所用的总磁盘空间,包括所有的索引和TOAST数据 |
pg_column_size显示用于存储任意独立数据值的空间。
pg_total_relation_size接受一个表或 TOAST 表的 OID 或名称,并返回该表所使用的总磁盘空间,包括所有相关的索引。这个函数等价于pg_table_size + pg_indexes_size。
pg_table_size接受一个表的 OID 或名称,并返回该表所需的磁盘空间,但是排除索引(TOAST 空间、空闲空间映射和可见性映射包含在内)
pg_indexes_size接受一个表的 OID 或名称,并返回附加到该表的所有索引所使用的全部磁盘空间。
pg_database_size以及pg_tablespace_size接受数据库或者表空间的OID或者名称,并且返回它们使用的磁盘空间。要使用pg_database_size,用户必须具有指定数据库上的CONNECT权限(默认情况下已经被授予)或者是pg_read_all_stats角色的一个成员。要使用pg_tablespace_size,用户必须具有指定表空间上的CREATE权限或者是pg_read_all_stats角色的一个成员,除非该表空间是当前数据库的默认表空间。
pg_relation_size接受一个表、索引或 TOAST 表的 OID 或者名称,并且返回那个关系的一个分叉所占的磁盘空间的字节尺寸(注意 对于大部分目的,使用更高层的函数pg_total_relation_size 或者pg_table_size会更方便,它们会合计所有分叉的尺寸)。 如果只得到一个参数,它会返回该关系的主数据分叉的尺寸。提供第二个参数 可以指定要检查哪个分叉:
pg_size_pretty可以用于把其它函数之一的结果格式化成一种人类易读的格式,可以根据情况使用字节、kB、MB、GB 或者 TB。
pg_size_bytes可以被用来从人类可读格式的字符串得到其中所表示的字节数。其输入可能带有的单位包括字节、kB、MB、GB 或者 TB,并且对输入进行解析时是区分大小写的。如果没有指定单位,会假定单位为字节。
注意
函数pg_size_pretty和pg_size_bytes所使用的单位 kB、MB、GB 和 TB 是用 2 的幂而不是 10 的幂来定义,因此 1kB 是 1024 字节,1MB 是 10242 = 1048576 字节,以此类推。
上述操作表和索引的函数接受一个regclass参数,它是该表或索引在pg_class系统目录中的 OID。你不必手工去查找该 OID,因为regclass数据类型的输入转换器会为你代劳。只写包围在单引号内的表名,这样它看起来像一个文字常量。为了与普通SQL名称的处理相兼容,该字符串将被转换为小写形式,除非其中在表名周围包含双引号。
如果一个 OID 不表示一个已有的对象并且被作为参数传递给了上述函数,将会返回 NULL。
表 9.85中展示的函数帮助标识数据库对象相关的磁盘文件。
表 9.85. 数据库对象定位函数
| 名称 | 返回类型 | 描述 |
|---|---|---|
pg_relation_filenode( |
oid |
指定关系的文件结点号 |
pg_relation_filepath( |
text |
指定关系的文件路径名 |
pg_filenode_relation( |
regclass |
查找与给定的表空间和文件节点相关的关系 |
pg_relation_filenode接受一个表、索引、序列或 TOAST 表的 OID 或名称,返回当前分配给它的“filenode”号。文件结点是关系的文件名的基本组件(详见第 68.1 节)。对于大多数表结果和pg_class.relfilenode相同,但是对于某些系统目录relfilenode为零,并且必须使用此函数获取正确的值。 如果传递一个没有存储的关系(如视图),此函数将返回 NULL。
pg_relation_filepath与pg_relation_filenode类似,但是它返回关系的整个文件路径名(相对于数据库集簇的数据目录PGDATA)。
pg_filenode_relation是pg_relation_filenode的反向函数。给定一个“tablespace” OID 以及一个 “filenode”,它会返回相关关系的 OID。对于一个在数据库的默认表空间中的表,该表空间可以指定为 0。
表 9.86列出了用来管理排序规则的函数。
表 9.86. 排序规则管理函数
pg_collation_actual_version返回当前安装在操作系统中的该排序规则对象的实际版本。如果这个版本与pg_collation.collversion中的值不同,则依赖于该排序规则的对象可能需要被重建。还可以参考ALTER COLLATION。
pg_import_system_collations基于在操作系统中找到的所有locale在系统目录pg_collation中加入排序规则。这是initdb会使用的函数,更多细节请参考第 23.2.2 节。如果后来在操作系统上安装了额外的locale,可以再次运行这个函数加入新locale的排序规则。匹配pg_collation中现有项的locale将被跳过(但是这个函数不会移除以在操作系统中不再存在的locale为基础的排序规则对象)。schema参数通常是pg_catalog,但这不是一种要求,排序规则也可以被安装到其他的方案中。该函数返回其创建的新排序规则对象的数量。
9.26.8. 索引维护函数
表 9.87展示了可用于 索引维护任务的函数。这些函数不能在恢复期间执行。只有超级用户以及给定索引的拥有者才能是用这些函数。
表 9.87. 索引维护函数
| 名称 | 返回类型 | 描述 |
|---|---|---|
brin_summarize_new_values( |
integer |
对还没有建立概要的页面范围建立概要 |
brin_summarize_range( |
integer |
如果还没有对覆盖给定块的页面范围建立概要,则对其建立概要 |
brin_desummarize_range( |
integer |
如果覆盖给定块的页面范围已经建立有概要,则去掉概要 |
gin_clean_pending_list( |
bigint |
把 GIN 待处理列表项移动到主索引结构中 |
brin_summarize_new_values接收一个 BRIN 索引的 OID 或者名称作为参数并且检查该索引以找到基表中当前还没有被该索引汇总的页面范围。对任意一个这样的范围,它将通过扫描那些表页面创建一个新的摘要索引元组。它会返回被插入到该索引的新页面范围摘要的数量。brin_summarize_range做同样的事情,不过它只对覆盖给定块号的范围建立概要。
gin_clean_pending_list接受一个 GIN 索引的 OID 或者名字,并且通过把指定索引的待处理列表中的项批量移动到主 GIN 数据结构来清理该索引的待处理列表。它会返回从待处理列表中移除的页数。注意如果其参数是一个禁用fastupdate选项构建的 GIN 索引,那么不会做清理并且返回值为 0,因为该索引根本没有待处理列表。有关待处理列表和fastupdate选项的细节请见第 66.4.1 节和第 66.5 节。
9.26.9. 通用文件访问函数
表 9.88中展示的函数提供了对数据库服务器所在机器上的文件的本地访问。只能访问数据库集簇目录以及log_directory中的文件,除非用户被授予了角色pg_read_server_files。 使用相对路径访问集簇目录里面的文件,以及匹配 log_directory配置设置的路径访问日志文件。
注意向用户授予pg_read_file()或者相关函数上的EXECUTE特权,函数会允许他们读取服务器上该数据库能读取的任何文件并且这些读取动作会绕过所有的数据库内特权检查。这意味着,除了别的之外,具有这种访问的用户能够读取pg_authid表中包含着认证信息的内容,也能读取数据库中的任意文件。因此,授予对这些函数的访问应该要很仔细地考虑。
表 9.88. 通用文件访问函数
| 名称 | 返回类型 | 描述 |
|---|---|---|
pg_ls_dir( |
setof text |
列出目录中的内容。默认仅限于超级用户使用,但是可以给其他用户授予EXECUTE让他们运行这个函数。 |
pg_ls_logdir() |
setof record |
列出日志目录中文件的名称、尺寸以及最后修改时间。访问被授予给pg_monitor角色的成员,并且可以被授予给其他非超级用户角色。 |
pg_ls_waldir() |
setof record |
列出WAL目录中文件的名称、尺寸以及最后修改时间。访问被授予给pg_monitor角色的成员,并且可以被授予给其他非超级用户角色。 |
pg_read_file( |
text |
返回一个文本文件的内容。默认仅限于超级用户使用,但是可以给其他用户授予EXECUTE让他们运行这个函数。 |
pg_read_binary_file( |
bytea |
返回一个文件的内容。默认仅限于超级用户使用,但是可以给其他用户授予EXECUTE让他们运行这个函数。 |
pg_stat_file( |
record |
返回关于一个文件的信息。默认仅限于超级用户使用,但是可以给其他用户授予EXECUTE让他们运行这个函数。 |
这些函数中的某些有一个可选的missing_ok参数, 它指定文件或者目录不存在时的行为。如果为true, 函数会返回 NULL (pg_ls_dir除外,它返回一个空 结果集)。如果为false,则发生一个错误。默认是 false。
pg_ls_dir返回指定目录中所有文件(以及目录和其他特殊文件) 的名称。include_dot_dirs指示结果集中是否包括 “.”和“..”。默认是排除它们(false),但是 当missing_ok为true时把它们包括在内是 有用的,因为可以把一个空目录与一个不存在的目录区分开。
pg_ls_logdir返回日志目录中每个文件的名称、尺寸以及最后的修改时间(mtime)。默认情况下,只有超级用户以及pg_monitor角色的成员能够使用这个函数。可以使用GRANT把访问授予给其他人。
pg_ls_waldir返回预写式日志(WAL)目录中每个文件的名称、尺寸以及最后的修改时间(mtime)。默认情况下,只有超级用户以及pg_monitor角色的成员能够使用这个函数。可以使用GRANT把访问授予给其他人。
pg_read_file返回一个文本文件的一部分,从给定的offset开始,返回最多length字节(如果先到达文件末尾则会稍短)。如果offset为负,它相对于文件的末尾。如果offset和length被忽略,整个文件都被返回。从文件中读的字节被使用服务器编码解释成一个字符串;如果它们在编码中不合法则抛出一个错误。
pg_read_binary_file与pg_read_file相似,除了前者的结果是一个bytea值;相应地,不会执行编码检查。通过与convert_from函数结合,这个函数可以用来读取一个指定编码的文件:
SELECT convert_from(pg_read_binary_file('file_in_utf8.txt'), 'UTF8');
pg_stat_file返回一个记录,其中包含文件尺寸、最后访问时间戳、最后修改时间戳、最后文件状态改变时间戳(只支持 Unix 平台)、文件创建时间戳(只支持 Windows)和一个boolean指示它是否为目录。通常的用法包括:
SELECT * FROM pg_stat_file('filename');
SELECT (pg_stat_file('filename')).modification;
9.26.10. 咨询锁函数
表 9.89中展示的函数管理咨询锁。有关正确使用这些函数的细节请参考第 13.3.5 节。
表 9.89. 咨询锁函数
| 名称 | 返回类型 | 描述 |
|---|---|---|
pg_advisory_lock( |
void |
获得排他会话级别咨询锁 |
pg_advisory_lock( |
void |
获得排他会话级别咨询锁 |
pg_advisory_lock_shared( |
void |
获得共享会话级别咨询锁 |
pg_advisory_lock_shared( |
void |
获得共享会话级别咨询锁 |
pg_advisory_unlock( |
boolean |
释放一个排他会话级别咨询锁 |
pg_advisory_unlock( |
boolean |
释放一个排他会话级别咨询锁 |
pg_advisory_unlock_all() |
void |
释放当前会话持有的所有会话级别咨询锁 |
pg_advisory_unlock_shared( |
boolean |
释放一个共享会话级别咨询锁 |
pg_advisory_unlock_shared( |
boolean |
释放一个共享会话级别咨询锁 |
pg_advisory_xact_lock( |
void |
获得排他事务级别咨询锁 |
pg_advisory_xact_lock( |
void |
获得排他事务级别咨询锁 |
pg_advisory_xact_lock_shared( |
void |
获得共享事务级别咨询锁 |
pg_advisory_xact_lock_shared( |
void |
获得共享事务级别咨询锁 |
pg_try_advisory_lock( |
boolean |
如果可能,获得排他会话级别咨询锁 |
pg_try_advisory_lock( |
boolean |
如果可能,获得排他会话级别咨询锁 |
pg_try_advisory_lock_shared( |
boolean |
如果可能,获得共享会话级别咨询锁 |
pg_try_advisory_lock_shared( |
boolean |
如果可能,获得共享会话级别咨询锁 |
pg_try_advisory_xact_lock( |
boolean |
如果可能,获得排他事务级别咨询锁 |
pg_try_advisory_xact_lock( |
boolean |
如果可能,获得排他事务级别咨询锁 |
pg_try_advisory_xact_lock_shared( |
boolean |
如果可能,获得共享事务级别咨询锁 |
pg_try_advisory_xact_lock_shared( |
boolean |
如果可能,获得共享事务级别咨询锁 |
pg_advisory_lock锁住一个应用定义的资源,可以使用一个单一64位键值或两个32位键值标识(注意这些两个键空间不重叠)。如果另一个会话已经在同一个资源标识符上持有了一个锁,这个函数将等待直到该资源变成可用。该锁是排他的。多个锁请求会入栈,因此如果同一个资源被锁住三次,则它必须被解锁三次来被释放给其他会话使用。
pg_advisory_lock_shared的工作和pg_advisory_lock相同,不过该锁可以与其他请求共享锁的会话共享。只有想要排他的锁请求会被排除。
pg_try_advisory_lock与pg_advisory_lock相似,不过该函数将不会等待锁变为可用。它要么立刻获得锁并返回true,要么不能立即获得锁并返回false。
pg_try_advisory_lock_shared的工作和pg_try_advisory_lock相同,不过它尝试获得一个共享锁而不是一个排他锁。
pg_advisory_unlock将会释放之前获得的排他会话级别咨询锁。如果锁被成功释放,它返回true。如果锁没有被持有,它将返回false并且额外由服务器报告一个 SQL 警告。
pg_advisory_unlock_shared的工作和pg_advisory_unlock相同,除了它释放一个共享的会话级别咨询锁。
pg_advisory_unlock_all将释放当前会话所持有的所有会话级别咨询锁(这个函数隐式地在会话末尾被调用,即使客户端已经不雅地断开)。
pg_advisory_xact_lock的工作和pg_advisory_lock相同,不过锁是在当前事务的末尾被自动释放的并且不能被显式释放。
pg_advisory_xact_lock_shared的工作和pg_advisory_lock_shared相同,除了锁是在当前事务的末尾自动被释放的并且不能被显式释放。
pg_try_advisory_xact_lock的工作和pg_try_advisory_lock相同,不过锁(若果获得)是在当前事务的末尾被自动释放的并且不能被显式释放。
pg_try_advisory_xact_lock_shared的工作和pg_try_advisory_lock_shared相同,不过锁(若果获得)是在当前事务的末尾被自动释放的并且不能被显式释放。

