浅谈日志收集
前言
各种程序输出的日志重要性不言而喻,借助日志可以分析程序的运行状态、用户的操作行为等。最早常说的日志监控系统是ELK,即ElasticSearch(负责数据检索)、Logstash(负责数据收集)、Kibana(负责数据展示)三个软件的组合,随着技术的发展,又出现了很多新的名词,比如EFK,这个F可以指Filebeat,有时也指Fluentd,其实日志收集软件的原理都是大概相同的,区别是它们的编程语言不同,功能不同,所以在选择时要根据自己的实际情况,比如在K8S及docker环境中,就可以使用更轻量级的fluent-bit, 而在云虚拟机和物理机上,则可以使用功能更强大的fluentd,目前我一直在线上使用fluentd系列的软件来收集日志,而且它们在长期的线上环境上运行良好。
实际上有时候我们并不需要ELK(或者EFK)的全部功能,比如出于成本考虑,只需要把多台机器上(或者容器)中的日志汇总到一台专用的日志机器上,并通过日期和目录区分,就已经方便技术人员登录查看,这样就节省了ES和Kibana的资源,当然这只是省钱的方法。后面的内容将写到完整的日志收集场景和配置方法。
场景1:从多台云主机收集日志到统一的Logserver
由于对fluentd比较熟悉了,我们这里的操作就使用Fluentd来实现,原理是Fluentd在AppServer上tail日志文件,并将产生的内容发送到LogServer上的fluentd,并根据规则存盘,简图如下:
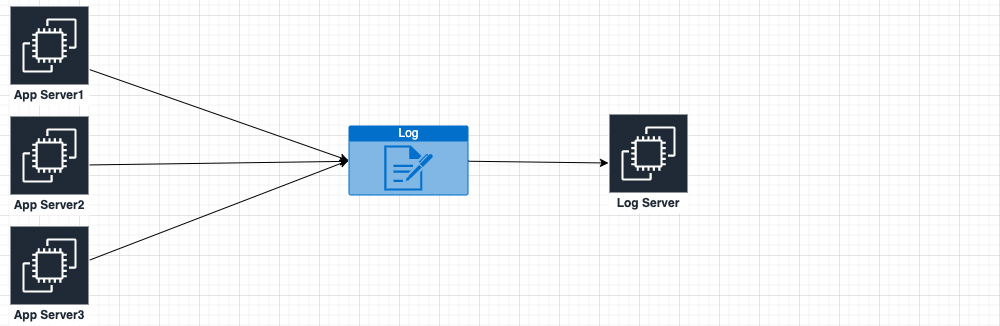
由于想把多台AppServer上的日志集中到一台机器,那么应用程序的日志输出位置应该是有规律的、固定的(和研发人员商定), 下面用我做过的一个具体需求举例分析:
日志目录结构:
├── public │ └── release-v0.2.20 │ └── sys_log.log ├── serv_arena │ └── release-v0.1.10 ├── serv_guild │ └── release-v0.1.10 │ └── sys_log.log ├── serv_name │ └── release-v0.1.10 │ └── sys_log.log
通过日志目录结构可以发现,服务器上运行了public、serv_arena等微服务,微服务目录里是程序版本,程序版本目录可能有多个,程序版本目录中是最终log。
日志原始格式:
这里输出的日志是纯文件格式,有些日志则可能是Json等其它格式,对于不同格式,可以选则不同的parser来处理
研发人员的需求是:
日志到LogServer后,目录结果不变。
下面是具体配置过程
step1:
在三台App Server上和LogServer上都安装Fluentd:
$ curl -L https://toolbelt.treasuredata.com/sh/install-redhat-td-agent3.sh | sh
我当前的版本在安装完成后,会在/etc/td-agent/目录下生成td-agent.conf文件和plugin目录,我通常会再建立一个conf.d目录,并把所有配置文件细分放进去,并在td-agent.d里include进来,这是个人习惯,感觉很清爽。所以目录结构最后为:
# tree /etc/td-agent/
/etc/td-agent/
├── conf.d
├── plugin
└── td-agent.conf
step2:
Fluentd已经安装好了,下面就要对其进行配置,三台App Server上的配置是一样的,但是 LogServer上的配置略有不同,因为Fluentd在Logserver
端的角色是接收端。
LogServer端Fluentd配置:
# cat td-agent.conf <system> log_level info </system> <source> @type forward port 24224 bind 0.0.0.0 </source> @include /etc/td-agent/conf.d/*.conf
# cat conf.d/raid.conf <match raid.**> @type file path /mnt/logs/raid/%Y%m%d/${tag[4]}/${tag[5]}.${tag[6]}.${tag[7]}/${tag[8]}_%Y%m%d%H append true <buffer time, tag> @type file path /mnt/logs/raid/buffer/ timekey 1h chunk_limit_size 5MB flush_interval 5s flush_mode interval flush_thread_count 8 flush_at_shutdown true </buffer> </match>
这里值得一说的是path选项,这里用到了tag选项来获取一些信息,而tag信息是从AppServer端的Fluentd配置中传过来的,最后path的结果如下:
# tree /mnt/logs/ /mnt/logs/ └── raid ├── 20200623 │ ├── public │ └── serv_guild │ └── release-v0.1.10 │ └── sys_log_2020062307.log └── buffer
AppServer端Fluentd配置:
# cat td-agent.conf @include /etc/td-agent/conf.d/*.conf
<source> @type tail path /mnt/logs/raid/public/*/* pos_file /var/log/td-agent/public.log.pos tag raid.* <parse> @type none time_format %Y-%m-%dT%H:%M:%S.%L </parse> refresh_interval 5s </source> <source> @type tail path /mnt/logs/raid/serv_arena/*/* pos_file /var/log/td-agent/serv_arena.log.pos tag raid.* <parse> @type none time_format %Y-%m-%dT%H:%M:%S.%L </parse> </source> <source> @type tail path /mnt/logs/raid/serv_guild/*/* pos_file /var/log/td-agent/serv_guild.log.pos tag raid.* <parse> @type none time_format %Y-%m-%dT%H:%M:%S.%L </parse> </source> <source> @type tail path /mnt/logs/raid/serv_name/*/* pos_file /var/log/td-agent/serv_name.log.pos tag raid.* <parse> @type none time_format %Y-%m-%dT%H:%M:%S.%L </parse> </source> <filter raid.**> @type record_transformer <record> host_param "#{Socket.gethostname}" </record> </filter> <match raid.**> @type forward <server> name raid-logserver host 10.83.36.106 port 24224 </server> <format> @type single_value message_key message add_newline true </format> </match>
这时值得一说的仍然是path和tag选项,我们配置的tag是raid.*,但实际tag的内容到低是什么呢?以致于tag传到LogServer后,我们能对tag进行一系列操作。
raid.*会匹配到path的路径,并把/用.代替,也就是tag raid.* 实际的内容类似:raid.mnt.logs.raid.public.release-v0.2.20.sys_log.log_2020062304.log
这样,我们后续根据tag进行目录配置才成为可能。
这里值得一说的还有format single_value参数, 如果不指定format为single_value,那你看到最终日志是如下这样,前面加了日期和tag, 这通常是我们不需要的,我们需要原样把日志打到LogServer上。message_key是fluentd自动给我们加上的,docker中的message key可能叫log, docker中的message key可能叫log, 如果我们tail的文件没有message key, 此处就不能指定,否则是无法匹配到并进行操作的,add_newline相当于是否换行。

场景2:从LogServer把日志集中导入elasticSearch
通过场景一,日志已经可以集中到LogServer上,通过LogServer就可以进一步把日志导入es或其它的系统了。
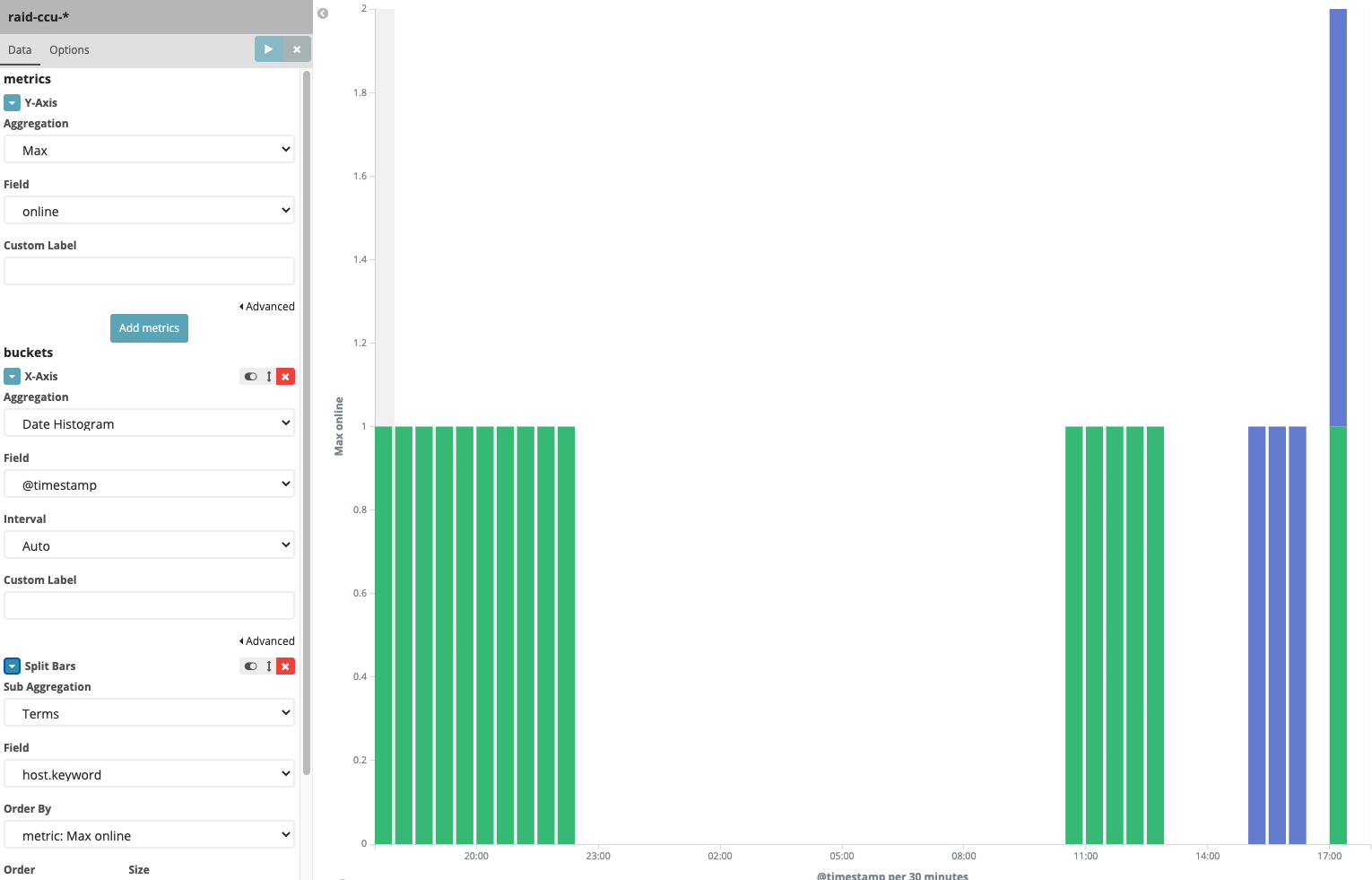
这里项目组有了新的需求,需要把在线人数在kibana中出图显示,日志格式为:
{"host":"5x.24x.6x.x","idleLoad":20000,"intVer":2000,"mode":1,"online":0,"onlineLimit":20000,"port":1000,"serverId":2,"serverName":"-game server-","serverType":21,"serviceMode":0,"sn":173221053,"status":1,"updateTime":1594278043935,"ver":"0.2.40.77","zoneId":2}
step1:
编写fluentd配置,把日志传到elasticsearch上(Logserver端配置)
<match online.**> @type elasticsearch host search-xxxxxxxxxxxxxxxx.es.amazonaws.com port 80 logstash_format true logstash_prefix game-ccu default_elasticsearch_version 5 reconnect_on_error true reload_connections false type_name doc <buffer> @type file path /mnt/logs/raid/online-buffer/ chunk_limit_size 5MB flush_interval 30s flush_mode interval flush_thread_count 4 flush_at_shutdown true </buffer> </match>
收集端配置:
<source> @type tail path /mnt/logs/raid/game/*/monitor/* pos_file /var/log/td-agent/online.log.pos tag online <parse> @type json </parse> refresh_interval 5s </source> <match online.**> @type forward <server> name raid-logserver host 10.83.3x.xx port 24224 </server> </match>
收集端需要注意的是,parse type应该指定为json而不是之前的none,否则传到es的日志带有message这个log key, 用format也无法去掉,因为elasticache插件不支持format,将带有message log key的日志传到es, 不会被es完全解析。
日志传到es后,就可以create index pattern,并创建图表了:
场景3:处理并拆分位于同一文件中的日志并打到ES
对于不同文件中的日志,我们可以使用tail分别抓取,但是如果日志混合在同一个文件中(比如docker的标准输出,就能只输出到同一个文件中)又该如何把日志拆分呢?这里就需要用到fluentd的grep retag等功能,根据关键字,对日志进行过滤,重新标记并执行相关动作。
解决此问题的思路是用fluentd监听多个日志文件,然后对其进行过滤,首先过滤掉output非es的日志,然后对于不同关键字,进行重打tag操作,最后打入es。但值得注意的是,fluentd是不支持多个match匹配相同的tag的,否则只有第一个生效。
开发人员有需求如下:
监听如下三个日志
/mnt/server/videoslotDevServer/logs/pomelo-tracking-social-server-1.log
/mnt/server/videoslotDevServer/logs/pomelo.log
/mnt/server/videoslotDevServer/pomelo-product-social-server-1.log
日志内容实例
{"LOGMSG":"MSGRouter-STC","LOGINDEX":"router","LOGOBJ":"{'type':'s2c_poll_check','token':'','qid':0,'errorCode':0,'list':{'s2c_get_server_time':{'type':'s2c_get_server_time','token':'','qid':0,'serverTime':1595246357723}}}","user_mid":3534,"OUTPUT":"ES","lft":"info","date":"2020-07-20T11:59:17.723Z","time":1595246357723}
1.日志中output值为es的才需要打入es里
2.根据不同的关键字在es建立不同的索引



step1:
Fluent配置文件
# cat slots-multi.conf <source> @type tail keep_time_key true path /mnt/server/videoslotDevServer/logs/pomelo-tracking-social-server-1.log, /mnt/server/videoslotDevServer/logs/pomelo.log, /mnt/server/videoslotDevServer/logs/pomelo-product-social-server-1.log pos_file /var/log/td-agent/slots_multi.log.pos tag multi <parse> @type json time_key @timestamp # 日志默认打到es的日志时间不正确,所以我自己给加了一个时间 </parse> refresh_interval 5s </source> <filter multi> # 先对output 是es的进行匹配 @type grep <regexp> key OUTPUT pattern "ES" </regexp> emit_invalid_record_to_error false </filter> <match multi> @type rewrite_tag_filter <rule> key LOGINDEX pattern /(.+)/ # 这里对router coin logic关键字进行匹配,如果是其它关键字,则也可以自动匹配并自动打入es生成索引 tag videoslots.$1 </rule> emit_invalid_record_to_error false </match> <match videoslots.**> @log_level debug @type elasticsearch host search-xxxxxxxxxxxxxxxxx.es.amazonaws.com port 80 logstash_format true logstash_prefix sandbox.${tag} default_elasticsearch_version 7 reconnect_on_error true reload_connections false <buffer> @type file path /sgn/logs/videoslots/buffer_multi/ chunk_limit_size 5MB flush_interval 30s flush_mode interval flush_thread_count 4 flush_at_shutdown true </buffer> </match>
Fluentd实则非常灵活,这里还有一种比较啰嗦的写法如下:
<source> @type tail keep_time_key true path /mnt/server/videoslotDevServer/logs/pomelo-tracking-social-server-1.log, /mnt/server/videoslotDevServer/logs/pomelo.log, /mnt/server/videoslotDevServer/logs/pomelo-product-social-server-1.log pos_file /var/log/td-agent/slots_multi.log.pos tag multi <parse> @type json time_key @timestamp </parse> refresh_interval 5s </source> <filter multi> @type grep <regexp> key OUTPUT pattern "ES" </regexp> </filter> <match multi> @type copy <store> @type rewrite_tag_filter <rule> key LOGINDEX pattern /^logic$/ tag logic </rule> </store> <store> @type rewrite_tag_filter <rule> key LOGINDEX pattern /^router$/ tag router </rule> </store> <store> @type rewrite_tag_filter <rule> key LOGINDEX pattern /^coin$/ tag coin </rule> </store> </match> <match logic> @type elasticsearch @log_level debug host search-xxxxxxxx.es.amazonaws.com port 80 logstash_format true logstash_prefix videoslots-logic default_elasticsearch_version 7 reconnect_on_error true reload_connections false <buffer> @type file path /sgn/logs/videoslots/buffer_logic/ chunk_limit_size 5MB flush_interval 30s flush_mode interval flush_thread_count 4 flush_at_shutdown true </buffer> </match> <match router> @log_level debug @type elasticsearch host search-videoslots-xxxxxxxxxxx.us-west-2.es.amazonaws.com port 80 logstash_format true logstash_prefix videoslots-router default_elasticsearch_version 7 reconnect_on_error true reload_connections false <buffer> @type file path /sgn/logs/videoslots/buffer_router/ chunk_limit_size 5MB flush_interval 30s flush_mode interval flush_thread_count 4 flush_at_shutdown true </buffer> </match> <match coin> @log_level debug @type elasticsearch host search-videoslots-xxxxxxxxxxx.us-west-2.es.amazonaws.com port 80 logstash_format true logstash_prefix videoslots-coin default_elasticsearch_version 7 reconnect_on_error true reload_connections false <buffer> @type file path /sgn/logs/videoslots/buffer_coin/ timekey_use_utc true chunk_limit_size 5MB flush_interval 30s flush_mode interval flush_thread_count 4 flush_at_shutdown true </buffer> </match>
step2:
到es上create index pattern
建立template,设置索引生成时的默认配置
PUT _template/sandbox_videoslots { "index_patterns": ["sandbox.videoslots*"], # 要给哪些索引生效此类配置 "settings": { "number_of_shards": 1 # shard值默认1000, 当前为测试环境,只有一个节点,所以调整shard数量为1 }, "mappings": { "properties": { "LOGOBJ": { "type": "text" # 设置LOGOBJ字段的格式为字串格式 } } } }
7版本的es中,提供了im功能(索引管理),可以控制索引数据保存的周期,比如设置router日志可保留30天
场景4:把JAVA日志按指定格式打到ES上
Fluentd提供了对于多行数据的parser,可以用于解析Java Stacktrace Log
当前业务中有两个类型的java log format:
# format1 2020-07-28 09:47:37,609 DEBUG [system.server] branch:release/v0.2.61 getHead name:HEAD,objectId:AnyObjectId[c9766419a4a7b691b4156fbf50] # format2 2020-07-28 00:30:59,520 ERROR [SceneHeartbeat-39] [system.error] hanlder execute error msgId:920 java.lang.IndexOutOfBoundsException: readerIndex(21) + length(1) exceeds writerIndex(21): PooledSlicedByteBuf(ridx: 21, widx: 21, cap: 21/21, unwrapped: PooledUnsafeDirectByteBuf(ridx: 3, widx: 15, cap: 64)) at io.netty.buffer.AbstractByteBuf.checkReadableBytes0(AbstractByteBuf.java:1451) at io.netty.buffer.AbstractByteBuf.readByte(AbstractByteBuf.java:738) at com.cg.raid.core.msg.net.NetMsgHelper.getU32(NetMsgHelper.java:7) at com.cg.raid.core.msg.net.NetMsgBase.getU32(NetMsgBase.java:79) at com.cg.raid.core.msg.net.INetMsg.getInts(INetMsg.java:177)
研发期望按如下格式表现日志:
"grok": { "field": "message", "patterns": ["%{TIMESTAMP_ISO8601:event_time} %{DATA:level} %{DATA:thread} %{DATA:logger} (?m)%{GREEDYDATA:msg}"], "on_failure": [ { "set": { "field": "grok_error", "value": "{{ _ingest.on_failure_message }}" } } ] },
Fluentd配置文件:
<source> @type tail path /mnt/logs/raid/%Y%m%d/publish/*/* pos_file /var/log/td-agent/publish.log.pos tag es.raid.publish <parse> @type multiline format_firstline /\d{4}-\d{1,2}-\d{1,2}/ format1 /^(?<time>\d{4}-\d{1,2}-\d{1,2} \d{1,2}:\d{1,2}:\d{1,2},\d{3}) (?<level>[^\s]+) \[(?<thread>.*)\] (?<message>.*)/ </parse> refresh_interval 5s </source> <source> @type tail path /mnt/logs/raid/%Y%m%d/game/*/* pos_file /var/log/td-agent/game.log.pos tag es.raid.game <parse> @type multiline format_firstline /\d{4}-\d{1,2}-\d{1,2}/ format1 /^(?<time>\d{4}-\d{1,2}-\d{1,2} \d{1,2}:\d{1,2}:\d{1,2},\d{3}) (?<level>[^\s]+) \[(?<thread>.*)\] \[(?<logger>.*)\] (?<message>.*)/ </parse> refresh_interval 5s </source> <source> @type tail path /mnt/logs/raid/%Y%m%d/server/*/* pos_file /var/log/td-agent/server.log.pos tag es.raid.server <parse> @type multiline format_firstline /\d{4}-\d{1,2}-\d{1,2}/ format1 /^(?<time>\d{4}-\d{1,2}-\d{1,2} \d{1,2}:\d{1,2}:\d{1,2},\d{3}) (?<level>[^\s]+) \[(?<thread>.*)\] \[(?<logger>.*)\] (?<message>.*)/ </parse> refresh_interval 5s </source> <source> @type tail path /mnt/logs/raid/%Y%m%d/inter/* pos_file /var/log/td-agent/inter.log.pos tag es.raid.inter <parse> @type multiline format_firstline /\d{4}-\d{1,2}-\d{1,2}/ format1 /^(?<time>\d{4}-\d{1,2}-\d{1,2} \d{1,2}:\d{1,2}:\d{1,2},\d{3}) (?<level>[^\s]+) \[(?<thread>.*)\] (?<message>.*)/ </parse> refresh_interval 5s </source> <source> @type tail path /mnt/logs/raid/%Y%m%d/public/*/* pos_file /var/log/td-agent/public.log.pos tag es.raid.public <parse> @type multiline format_firstline /\d{4}-\d{1,2}-\d{1,2}/ format1 /^(?<time>\d{4}-\d{1,2}-\d{1,2} \d{1,2}:\d{1,2}:\d{1,2},\d{3}) (?<level>[^\s]+) \[(?<thread>.*)\] \[(?<logger>.*)\] (?<message>.*)/ </parse> refresh_interval 5s </source> <source> @type tail path /mnt/logs/raid/%Y%m%d/arena/*/* pos_file /var/log/td-agent/arena.log.pos tag es.raid.arena <parse> @type multiline format_firstline /\d{4}-\d{1,2}-\d{1,2}/ format1 /^(?<time>\d{4}-\d{1,2}-\d{1,2} \d{1,2}:\d{1,2}:\d{1,2},\d{3}) (?<level>[^\s]+) \[(?<thread>.*)\] \[(?<logger>.*)\] (?<message>.*)/ </parse> refresh_interval 5s </source> <source> @type tail path /mnt/logs/raid/%Y%m%d/guild/*/* pos_file /var/log/td-agent/guild.log.pos tag es.raid.guild <parse> @type multiline format_firstline /\d{4}-\d{1,2}-\d{1,2}/ format1 /^(?<time>\d{4}-\d{1,2}-\d{1,2} \d{1,2}:\d{1,2}:\d{1,2},\d{3}) (?<level>[^\s]+) \[(?<thread>.*)\] \[(?<logger>.*)\] (?<message>.*)/ </parse> refresh_interval 5s </source> <source> @type tail path /mnt/logs/raid/%Y%m%d/name/*/* pos_file /var/log/td-agent/name.log.pos tag es.raid.name <parse> @type multiline format_firstline /\d{4}-\d{1,2}-\d{1,2}/ format1 /^(?<time>\d{4}-\d{1,2}-\d{1,2} \d{1,2}:\d{1,2}:\d{1,2},\d{3}) (?<level>[^\s]+) \[(?<thread>.*)\] \[(?<logger>.*)\] (?<message>.*)/ </parse> refresh_interval 5s </source> <filter es.raid.**> @log_level debug @type grep <regexp> key level pattern "ERROR" </regexp> </filter> <match es.raid.**> @log_level debug @type elasticsearch host search-xxxxxx.es.amazonaws.com port 80 logstash_format true logstash_prefix raid-log-${tag[2]} default_elasticsearch_version 5 reconnect_on_error true reload_connections false type_name doc <buffer tag> @type file path /mnt/logs/raid/raid_es_buffer/ chunk_limit_size 5MB flush_interval 5s flush_mode interval flush_thread_count 4 flush_at_shutdown true </buffer> </match>
ES索引设置:
PUT _template/raid-log { "index_patterns": ["raid-log-*"], "settings": { "number_of_shards": 1 }, "mappings": { "properties": { "level": { "type": "keyword", "doc_values": true }, "logger": { "type": "keyword", "doc_values": true }, "thread": { "type": "keyword", "doc_values": true }, "message": { "type": "text" } } } } # 测试环境number_of_shards指定1即可 # text类型比keyword消耗更多cpu资源,但查询更灵活
最后建立index pattern即可。
