
客户要求要使用Python,调用mysql,调用kafka ,没办法,硬着头皮上
首先确定开发环境,我自己的是windows
(1)到网上下载了最新的Python版本,3.8.2,安装到我本地;
(2)若干年前,自己闲着无事下载的开发工具 pycharm-professional-5.0.4.exe ,安装起来;
(3)配置一下,要让开发工具能够使用本地Python编译器;启动的时候一般会提示,如果按照顺序安装,一般不需要配置;
(4)因为要连接MYSQL数据库,随便找了段代码,我的文章中记录了。
要拉最新的驱动,所以按照网上的说法 pip install mysqlclient ,

1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 import MySQLdb as mdb 4 5 # 连接数据库 6 conn = mdb.connect('localhost', 'root', '123456') 7 8 # 也可以使用关键字参数 9 conn = mdb.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='ry', charset='utf8') 10 11 # 也可以使用字典进行连接参数的管理 12 config = { 13 'host': '127.0.0.1', 14 'port': 3306, 15 'user': 'root', 16 'passwd': '123456', 17 'db': 'aa', 18 'charset': 'utf8' 19 } 20 conn = mdb.connect(**config) 21 22 # 如果使用事务引擎,可以设置自动提交事务,或者在每次操作完成后手动提交事务conn.commit() 23 conn.autocommit(1) # conn.autocommit(True) 24 25 # 使用cursor()方法获取操作游标 26 cursor = conn.cursor() 27 # 因该模块底层其实是调用CAPI的,所以,需要先得到当前指向数据库的指针。 28 29 try: 30 # 创建数据库 31 DB_NAME = 'aa' 32 33 conn.select_db(DB_NAME) 34 35 #创建表 36 TABLE_NAME = 'stock' 38 41 # 查询数据条目 42 count = cursor.execute('SELECT * FROM %s' %TABLE_NAME) 43 44 print (count) 45 print('total records:', cursor.rowcount) 46 47 # 获取表名信息 48 # desc = cursor.description 49 # print 50 # var1 = "%s %3s" % (desc[0][0], desc[1][0]) 51 # print(var1) 52 53 # 查询一条记录 54 55 result = cursor.fetchone() 56 print (result) 57 print('id: %s,name: %s' % (result[0], result[1])) 58 59 60 # 查询所有记录 61 # 重置游标位置,偏移量:大于0向后移动;小于0向前移动,mode默认是relative 62 # relative:表示从当前所在的行开始移动; absolute:表示从第一行开始移动 63 cursor.scroll(0,mode='absolute') 64 results = cursor.fetchall() 65 for r in results: 66 print(r[0],r[1]) 67 68 69 70 71 72 73 74 # 如果没有设置自动提交事务,则这里需要手动提交一次 75 conn.commit() 76 except: 77 import traceback 78 traceback.print_exc() 79 # 发生错误时会滚 80 conn.rollback() 81 finally: 82 # 关闭游标连接 83 cursor.close() 84 # 关闭数据库连接 85 conn.close()
调试成功;
(5)尝试 连接Phoenix 参考 https://www.cnblogs.com/weiyiming007/p/12212743.html
(6)编写kafka代码,测试通过
1 import json 2 from kafka import KafkaProducer 3 4 producer = KafkaProducer(bootstrap_servers='127.0.0.1:9092') 5 6 msg_dict = { 7 "sleep_time": 10, 8 "db_config": { 9 "database":"test_1", 10 "host":"xxxx", 11 "user":"root", 12 "password":"root" 13 }, 14 "table": "msg", 15 "msg": "Hello World" 16 } 17 msg = json.dumps(msg_dict) 18 msg2="aabbccddeeffaagg" 19 #producer.send('test',msg,partition=0) 20 21 producer.send(topic='userTest',value=msg.encode('utf-8'),headers=None,partition=0,timestamp_ms=None) 22 23 producer.close()
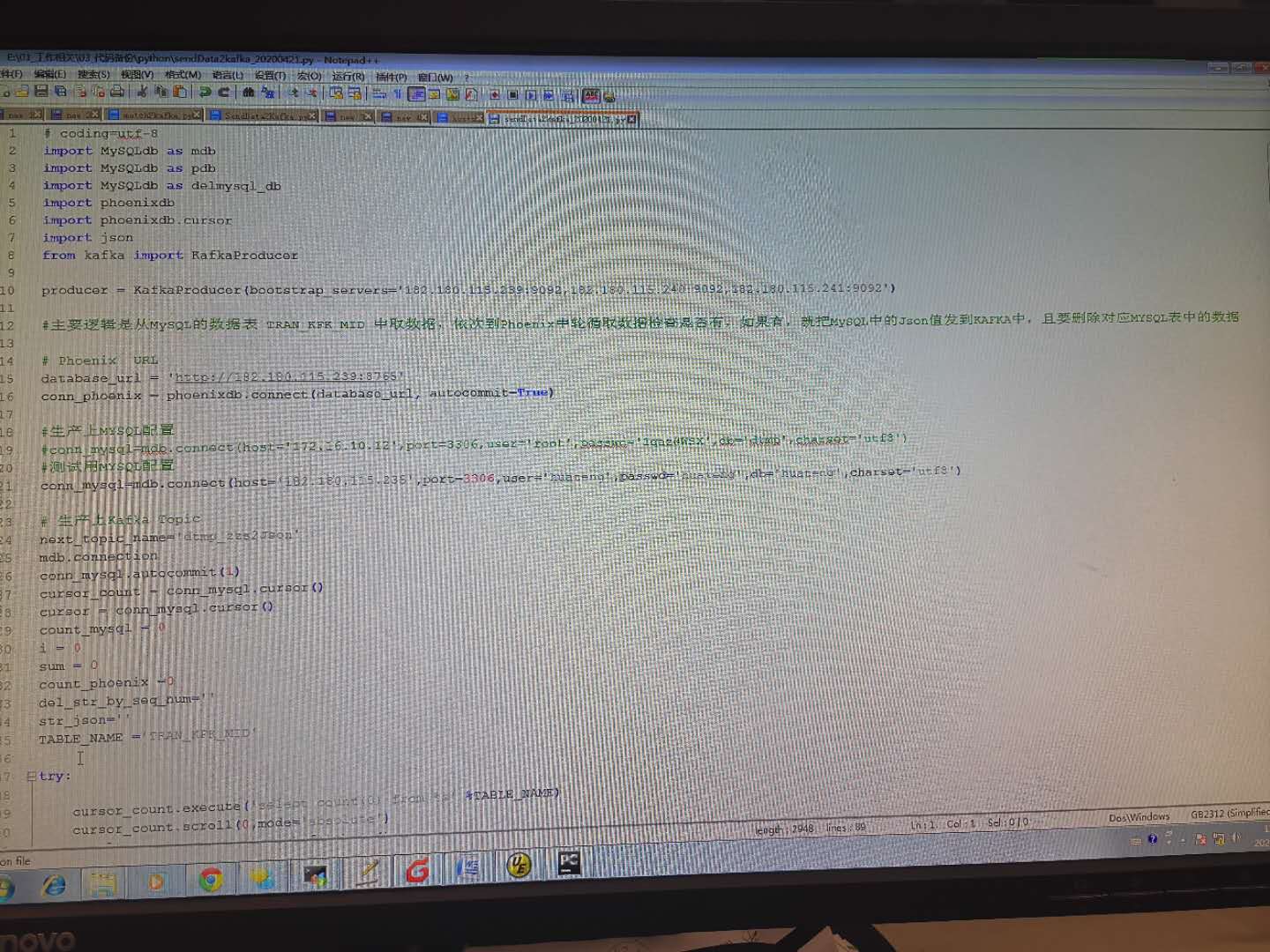
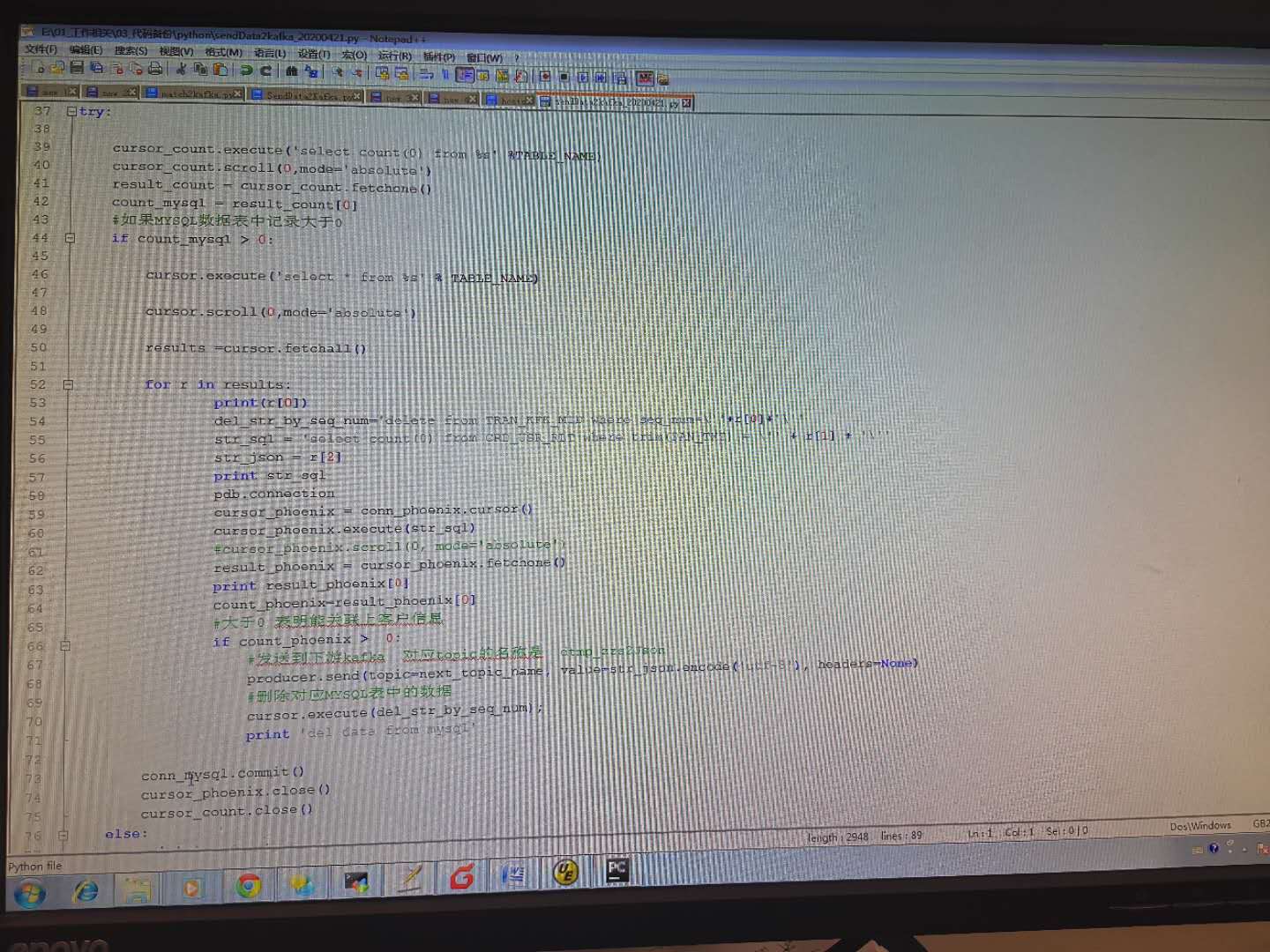
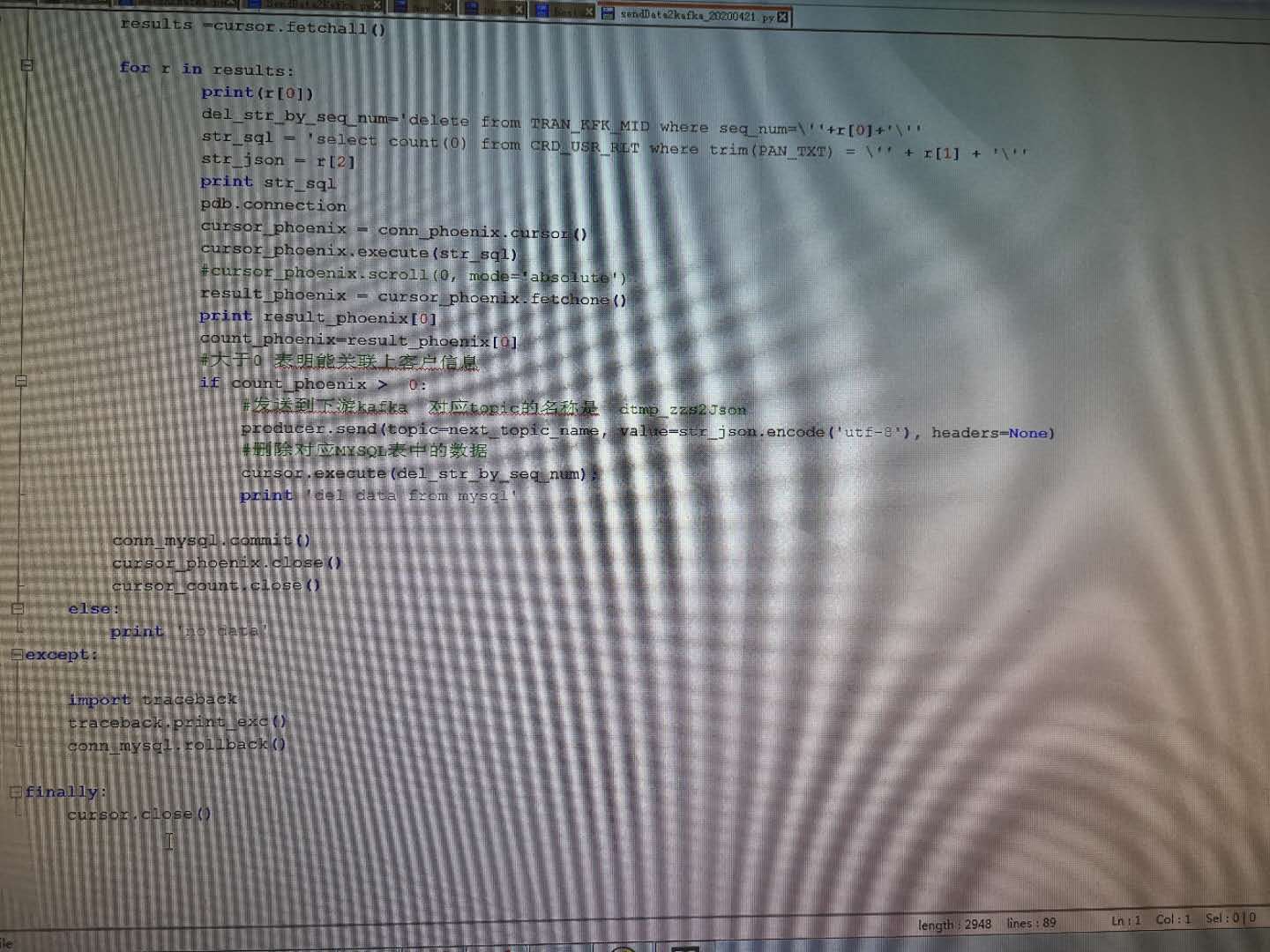
最后成功的代码
客户要求的逻辑是 从MYSQL中获取表,然后检查PHOENIX中是否能够对应到数据,如果能对应,就调用KAFKA,删除MYSQL对应数据,否则就啥也不做;
用空常来坐坐
https://www.cnblogs.com/alexgl2008/


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理