【Teradata】 TPT基础知识
来源于:https://www.cnblogs.com/badboy200800/p/10095104.html
1.TPT Description
- Teradata Parallel Transporter (TPT) is client software that performs data extractions, data transformations, and data loading functions in a scalable, parallel processing environment.
- TPT brings together the traditional Teradata Load Utilities (FastLoad, MultiLoad,FastExport and TPump) into a single product using a single script language.
- A GUI-based TPT Wizard is available for script generation.
- Teradata database is the only target for load operators.
- Any ODBC database, data files or devices may be source data.
2.Architecture
There are two types of parallelism used by TPT: pipeline parallelism and data parallelism .
(1) Pipeline parallelism (also called "functional parallelism")
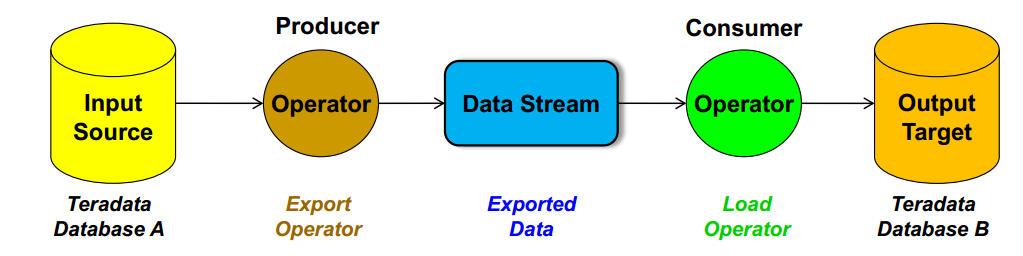
A "producer" operator extracts data from a data source and writes ("produces") it to a data stream.
A "consumer" operator reads ("consumes") the data from the data stream and writes or loads data to the target.
Both operators can operate concurrently and independently of each other. This creates a pipeline effect without the need for intermediary files.
(2) Data Parallelism
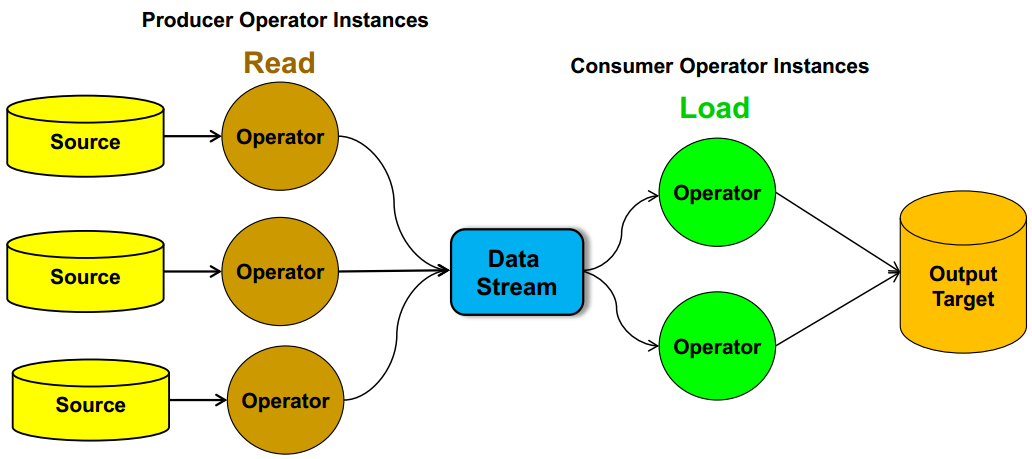
Each file can be handled by a different instance of the producer operator so that the files are read concurrently. The operator instances can then merge these files into a single data stream .
The data stream can then be input to multiple consumer operators.
3. Operator Types
(1) The two key TPT operators are:
Producer operators:[produce a Data Stream] which 'produce' a data stream, usually by reading source data.
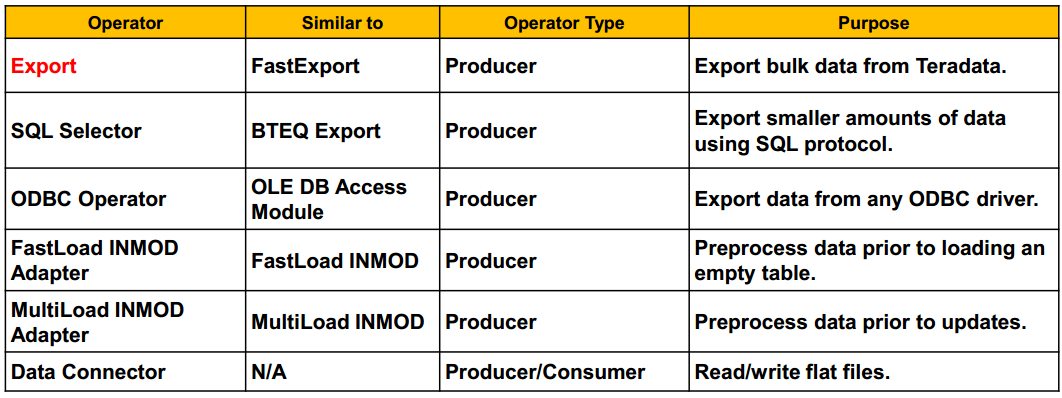
Consumer operators:[consume a Data Stream] which 'consume' data from a data stream, usually to be loaded to a target.
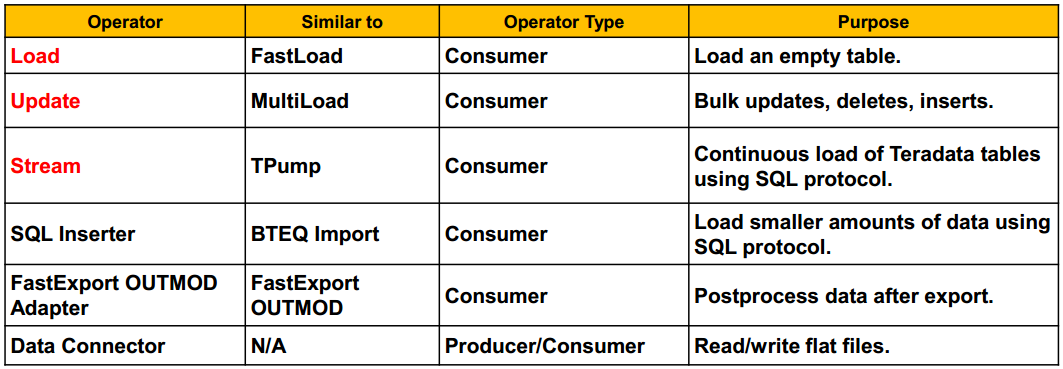
(2) Two additional operator types are:
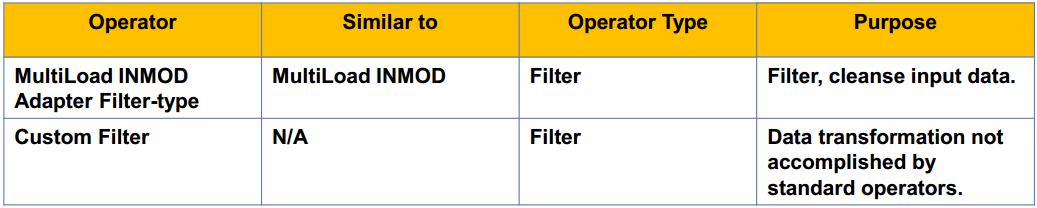
Filter operators:[Consume and Produce a Data Stream] which perform data transformation functions such as selection,validation, cleansing, and condensing. Both consumers and producers since they consume an input data stream and produce an output data stream.
There are 3 ways to perform filtering operations in the TPT environment: a) Use the MultiLoad INMOD Adapter operator as a filter. b) Use the CASE statement and the WHERE clause in the APPLY statement to limit sets. c) Create a custom filter operator using C or C++.
Standalone operators:[No Data Streams] which perform any processing that does not involve sending data to, or receiving data from the data stream
A standalone operator does not send or receive data, and thus does not use data streams. The following are standalone operators:
- Update (Delete Task) Operator: Uses Update operator to delete rows from a single table.
- DDL Operator: Permits DDL and some DML and DCL commands in a TPT script.
- OS Command: Permits commands to the client OS in a TPT script
Data Connector Operator:Producer or Consumer TYPE DATACONNECTOR PRODUCER – if the file is being read TYPE DATACONNECTOR CONSUMER – if the file is being written to
4.Export
(1) Export Job ExampleDEFINE JOB Export_to_FileDESCRIPTION 'Export 1000 rows from AP.Accounts table'

( DEFINE SCHEMA Accounts_Schema (Account_Number INTEGER, Street_Number INTEGER, Street CHARACTER(25), City CHARACTER(20), State CHARACTER(2), Zip_Code INTEGER, Balance_Forward DECIMAL(10,2), Balance_Current DECIMAL(10,2) ); /* DEFINE SCHEMA Accounts_Schema FROM TABLE 'AP.Accounts'; This is an alternate technique to define your schema */
DEFINE OPERATOR File_Writer TYPE DATACONNECTOR CONSUMER SCHEMA Accounts_Schema ATTRIBUTES (VARCHAR FileName = 'Export_1000', VARCHAR Format = 'FORMATTED', VARCHAR OpenMode = 'Write', VARCHAR IndicatorMode = 'Y' ); DEFINE OPERATOR Export_Accounts TYPE EXPORT SCHEMA Accounts_Schema ATTRIBUTES ( VARCHAR UserName = 'user1', VARCHAR UserPassword = 'passwd1', VARCHAR Tdpid = 'tdp1', INTEGER MaxSessions = 4, INTEGER TenacitySleep = 1, VARCHAR SelectStmt = 'SELECT Account_Number, Street_Number,Street, City, State, Zip_Code,Balance_Forward, Balance_Current FROM AP.Accounts SAMPLE 1000;' );
APPLY TO OPERATOR (File_Writer[1]) SELECT Account_Number, Street_Number, Street, City, State, Zip_Code, Balance_Forward, Balance_Current FROM OPERATOR (Export_Accounts[1]); );
(2) SQL Selector Job Example
DEFINE JOB Select_Accounts DESCRIPTION 'Select 1000 rows from AP.Accounts table' ( DEFINE SCHEMA Accounts_Schema FROM TABLE 'AP.Accounts'; /* If your schema is identical (names, sequence, and data type) to an existing table definition in Teradata, you can specify the tablename in the DEFINE SCHEMA statement. The column names are then used in your operators. */
DEFINE OPERATOR File_Writer TYPE DATACONNECTOR CONSUMER SCHEMA Accounts_Schema ATTRIBUTES (VARCHAR FileName = 'Select_1000', VARCHAR Format = 'FORMATTED', VARCHAR OpenMode = 'Write', VARCHAR IndicatorMode = 'Y' ); /**
The DataConnector operator has the following OpenMode options:
– 'Read' = Read-only access.
– 'Write' = Write-only access.
– 'WriteAppend' = Write-only access appending to existing file.
**/
DEFINE OPERATOR Select_Accounts TYPE SELECTOR SCHEMA Accounts_Schema ATTRIBUTES (VARCHAR UserName = 'user1', VARCHAR UserPassword = 'passwd1', VARCHAR Tdpid = 'tdp1', VARCHAR SelectStmt = 'SELECT Account_Number, Street_Number,Street, City, State, Zip_Code,Balance_Forward, Balance_Current FROM AP.Accounts SAMPLE 100;' ); APPLY TO OPERATOR (File_Writer[1]) SELECT Account_Number, Street_Number, Street, City, State, Zip_Code, Balance_Forward, Balance_Current FROM OPERATOR (Select_Accounts[1]); );
(3) Exporting a CSV Data File Example
DEFINE JOB Export_CSV DESCRIPTION 'Export Accounts data to CSV file' ( DEFINE SCHEMA Accounts_Schema FROM TABLE DELIMITED 'AP.Accounts'; /* Place above statement on 1 line. If DELIMITED option is not used, define each field AS VARCHAR */ /*( Account_Number VARCHAR(11), : Balance_Current VARCHAR(12) ); */
DEFINE OPERATOR File_Writer DESCRIPTION 'Writes file to disk' TYPE DATACONNECTOR CONSUMER SCHEMA Accounts_Schema ATTRIBUTES ( VARCHAR FileName = 'accounts_csv', VARCHAR OpenMode = 'Write', VARCHAR Format = 'DELIMITED', VARCHAR TextDelimiter = ',', VARCHAR IndicatorMode = 'N' ); DEFINE OPERATOR Exp_Accounts TYPE SELECTOR SCHEMA Accounts_Schema ATTRIBUTES (VARCHAR UserName = 'user1', VARCHAR UserPassword = 'password1', VARCHAR Tdpid = 'tdp1', INTEGER MaxSessions = 1, VARCHAR SelectStmt = 'SELECT CAST(Account_Number AS VARCHAR(11)), CAST(Street_Number AS VARCHAR(11)),
cast( Street as varchar(25)),
cast( City as varchar(20)),
cast( State as varchar(2)),
cast( Zip_Code as varchar(11)),
cast( Balance_Forward as varchar(12)),
CAST(Balance_Current AS VARCHAR(12))
FROM AP.Accounts;'
);
APPLY TO OPERATOR (File_Writer[1]) SELECT * FROM OPERATOR (Exp_Accounts[1]); );
5.LOAD
(1) LOAD Job Example
DEFINE JOB Load_from_File DESCRIPTION 'Load 1000 rows to empty AP.Accounts' ( DEFINE SCHEMA Accounts_Schema ( Account_Number INTEGER, Street_Number INTEGER, Street CHARACTER(25), City CHARACTER(20), State CHARACTER(2), Zip_Code INTEGER, Balance_Forward DECIMAL(10,2), Balance_Current DECIMAL(10,2) );
DEFINE OPERATOR File_Reader TYPE DATACONNECTOR PRODUCER SCHEMA Accounts_Schema ATTRIBUTES ( VARCHAR FileName = 'Export_1000', VARCHAR Format = 'FORMATTED', VARCHAR OpenMode = 'Read', VARCHAR IndicatorMode = 'Y' ); DEFINE OPERATOR Load_Accounts TYPE LOAD SCHEMA Accounts_Schema ATTRIBUTES ( VARCHAR UserName = 'user1', VARCHAR UserPassword = 'password1', VARCHAR Tdpid = 'tdp1', VARCHAR LogTable = 'Accounts_Load_Log', VARCHAR TargetTable = 'Accounts', INTEGER MaxSessions = 8, INTEGER TenacitySleep = 1, VARCHAR WildCardInsert = 'N' /*Default */ /*'Y[es]' = builds an INSERT statement 'N[o]' = (default); you must specify a INSERT ... VALUES statement */ );
APPLY ('INSERT INTO Accounts (Account_Number, Street_Number, Street, City, State, Zip_Code, Balance_Forward, Balance_Current) VALUES (:account_number, :street_number, :street, :city, :state, :zip_code, :balance_forward, :balance_current);') TO OPERATOR (Load_Accounts[1]) SELECT Account_Number, Street_Number, Street,City, State, Zip_Code, Balance_Forward, Balance_Current FROM OPERATOR (File_Reader[1]); );
(2)LOAD Job Example (WildCardInsert)
The WildCardInsert option ONLY is available to the LOAD operator and does NOT work with the other operators
DEFINE OPERATOR Load_Accounts
TYPE LOAD
SCHEMA Accounts_Schema
ATTRIBUTES
( VARCHAR UserName = 'user1',
VARCHAR UserPassword = 'password1',
VARCHAR Tdpid = 'tdp1',
VARCHAR LogTable = 'Accounts_Load_Log',
VARCHAR TargetTable = 'Accounts',
INTEGER MaxSessions = 8,
INTEGER TenacitySleep = 1,
VARCHAR WildCardInsert = 'Y' /*Not default*/
);
APPLY ('INSERT INTO Accounts;')
TO OPERATOR (Load_Accounts[1])
SELECT * FROM OPERATOR (File_Reader[1]);
);
(3) Data Conversions
TPT permits conversion in the APPLY statement. Data can be converted to an alternate data type, or be changed to/from a null
APPLY ( 'INSERT INTO Customer VALUES (:Customer_Number, :Last_Name, :First_Name, :Social_Security);') TO OPERATOR (Load_Customer [1]) SELECT Customer_Number ,Last_Name ,First_Name ,CASE WHEN (Social_Security = 0) THEN NULL ELSE Social_Security END AS Social_Security /* A derived column name is needed that matches the schema name */ FROM OPERATOR (File_Reader [1]); );
(4) Checkpoint Option
Checkpoints slow down Load processing
使用方式一: tbuild -f scriptfilename -z 60 f - This indicates the script file which is input to tbuild. z - This indicates that a checkpoint will be taken every 60 seconds. 使用方式二: DEFINE JOB test_job SET CHECKPOINT INTERVAL 60 SECONDS ...
(5) Techniques to Load Multiple Data Files
- UNION ALL – can be used with APPLY to combine multiple data files (and optionally from different data sources) into a single source data stream.
- File List – this is filename which contains a list of the data files to process.
- Directory Scan – can be used to scan a directory for files to be processed.
- Staged Loading – if you want to process data files serially or if they arrive at different times, the first data file can be loaded and additional files are loaded as needed.
APPLY
('INSERT INTO Customer VALUES (:CustNum, … );')
TO OPERATOR (MyUpdateOperator [1])
SELECT * FROM OPERATOR (FileReader[1]
ATTRIBUTES (FileName = 'custdata1'))
UNION ALL
SELECT * FROM OPERATOR (FileReader[1]
ATTRIBUTES (FileName = 'custdata2'));
APPLY ( 'INSERT INTO Customer VALUES (:CustNum, … ) ;') TO OPERATOR (MyUpdateOperator [1] ) SELECT * FROM OPERATOR (MyExportOperator [1] ATTRIBUTES (SelectStmt = 'SELECT * FROM Customer WHERE CustNum <= 100000;') ) UNION ALL SELECT * FROM OPERATOR (MyExportOperator [1] ATTRIBUTES (SelectStmt = 'SELECT * FROM Customer WHERE CustNum > 100000;') );
执行TPT脚本
tbuild -f scriptname.tpt

 浙公网安备 33010602011771号
浙公网安备 33010602011771号