1. 确定由于NotReady节点
kubectl get nodes -owide | grep NotReady
2. 确定有无异常Pod
kubectl get po --all-namespaces | egrep -v '(Running|Complete|ark-diagnose|NAME)'
3. 确认集群组件状态(deprecated in v1.19+)
kubectl get cs
# STATUS为Healthy为正常
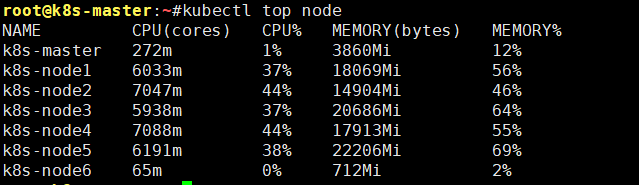
4.确认节点资源水位情况
kubectl top node
# 节点资源水位有无超限(CPU使用率大于80%,内存使用率超过80%)
5. 查看集群异常事件信息
kubectl get events --all-namespaces | egrep -v '(Normal|NAMESPACE)' | awk '{print $1,$5,$4}' | grep -v BackendInvalid | sort | uniq | sort -k 3
6. 查看pod重启次数
kubectl get pod -A -owide
# 正常应为个位数或为0
7. 确定具体问题与处理
kubectl -n <NAMESPACE> describe <TYPE> <RESOURCE_ID>
# 关注Events事件,Condition条件,Limit/Requests是否超限等
kubectl -n<NAMESPACE> logs <POD_ID> [-c <CONTAINER_NAME>]



