第一模块:开发基础 第2章·数据类型、字符编码、文件操作
二进制转换

python可以使用bin()将十进制数字转为二进制:
>>> bin(342) '0b101010110'
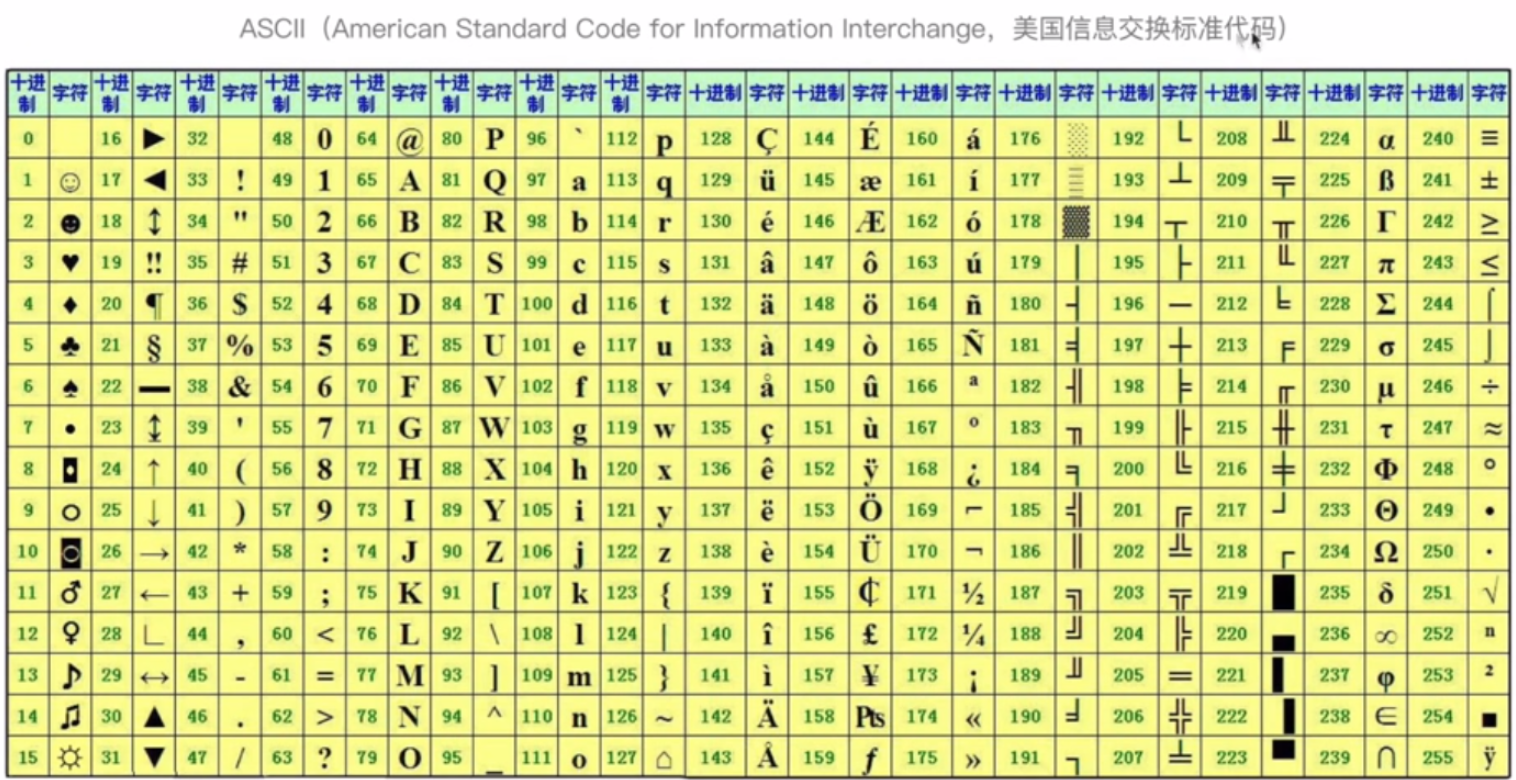
ASCII码与二进制
计算机是如何把二进制转换为文字的?
是通过一张ASCII码表:
ASCII码表可存储255个符号,没一个符号对应一个十进制的编号。
文字转二进制
需求:
请把 #Alex 按ASCII表转成二进制形式。
按照ASCII码表我们先把对应的符号分解转为二进制,如下:
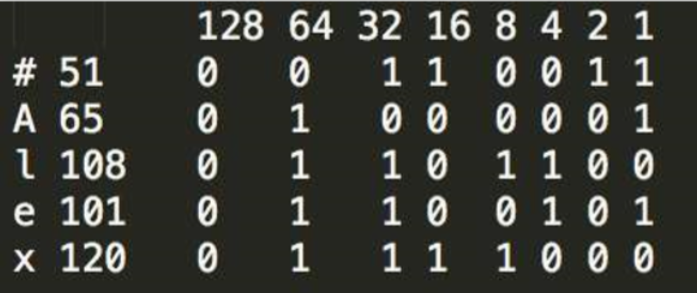
几段二进制合在一起便如下:

问题来了,以上我们通过人为的空格将每一段分开,我们可以分清哪个代表哪个,而且有的是6位,有的是7位,计算机怎么分清呢?
所以聪明的人类就想出了一个解决办法,既然一共就这255个字符,那最长的也不过是11111111八位,不如我们就把所有的二进制转换成8位的,不足的用0来替换,于是便如下,计算机就可以按照每8位来区分:

这里就引出了计算机容量单位:
每一位0或者1所占的空间单位为bit(比特),这是计算机中最小的表示单位

字符编码的演化
我们现在有个一个ASCII码表能够存储大部分的字符了,但是里面没中文啊,那我们中国怎么用,所以我国也陆续的创建的一些编码表:
1981年5月1日,GB2312,又称国标码,由国家标准总局发布,通行于大陆。新加坡等地也使用此编码。共7445个图形字符,其中汉字占6763个。
1995年,GBK1.0,GBK编码能够用来同时表示繁体字和简体字,该编码标准兼容GB2312,共收录汉字21003个,同时包含中日韩文字里所有汉字。
2000年,GB18030,是对GBK编码的扩充,覆盖中文、日文、朝鲜语和中国少数名族文字,其中收录27484个汉字,兼容GBK和GB2312字符集。
1984年,BIG5编码:台湾地区繁体中文标准字符集,采用双字节编码,共收录13053个中文字。
以上我们有了适合我们使用的字符编码,但是同时其他国家也设计了适合其他国家使用的字符编码来满足各自的使用,问题又来了,各国的软件交流怎么办,日本的软件拿到中国来,如果没有装日本的字符集必然会乱码,所以早期软件厂商都会带上自己的字符集,防止乱码,这种方式固然解决了乱码的问题,但是太麻烦了。
于是,为了解决每个国家不同编码间不互通的问题,ISO标准组织出马了,设计了Unicode.
Unicode: 国际标准字符集,它将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言、跨平台的文本信息转换。Unicode(统一码、万国码)规定所有的字符和符号最少由16位来表示(2个字节),即:2 ** 16 = 65536
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ASCII码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
说明:
Windows系统中文版默认编码是GBK。这是由于我国政府的原因。
Mac OS/ Linux 系统默认编码是UTF-8
Python里使用编码
Python 2.x 默认编码是ASCII
Python 3.x 默认编码是UTF-8
Python 2.x解决中文支持的办法:
在文件首行加入:
# coding = utf-8
或者
# coding = UTF-8
或者
# -*- coding: utf-8 -*-
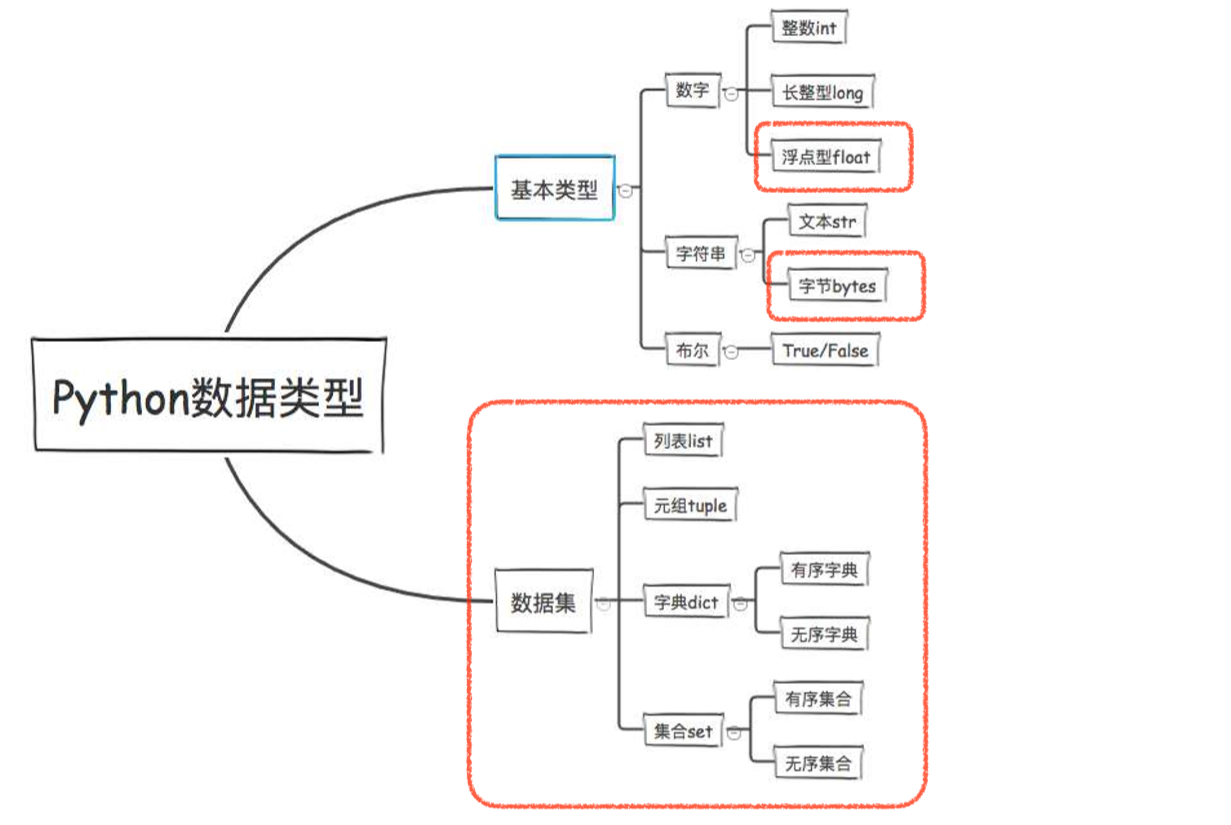
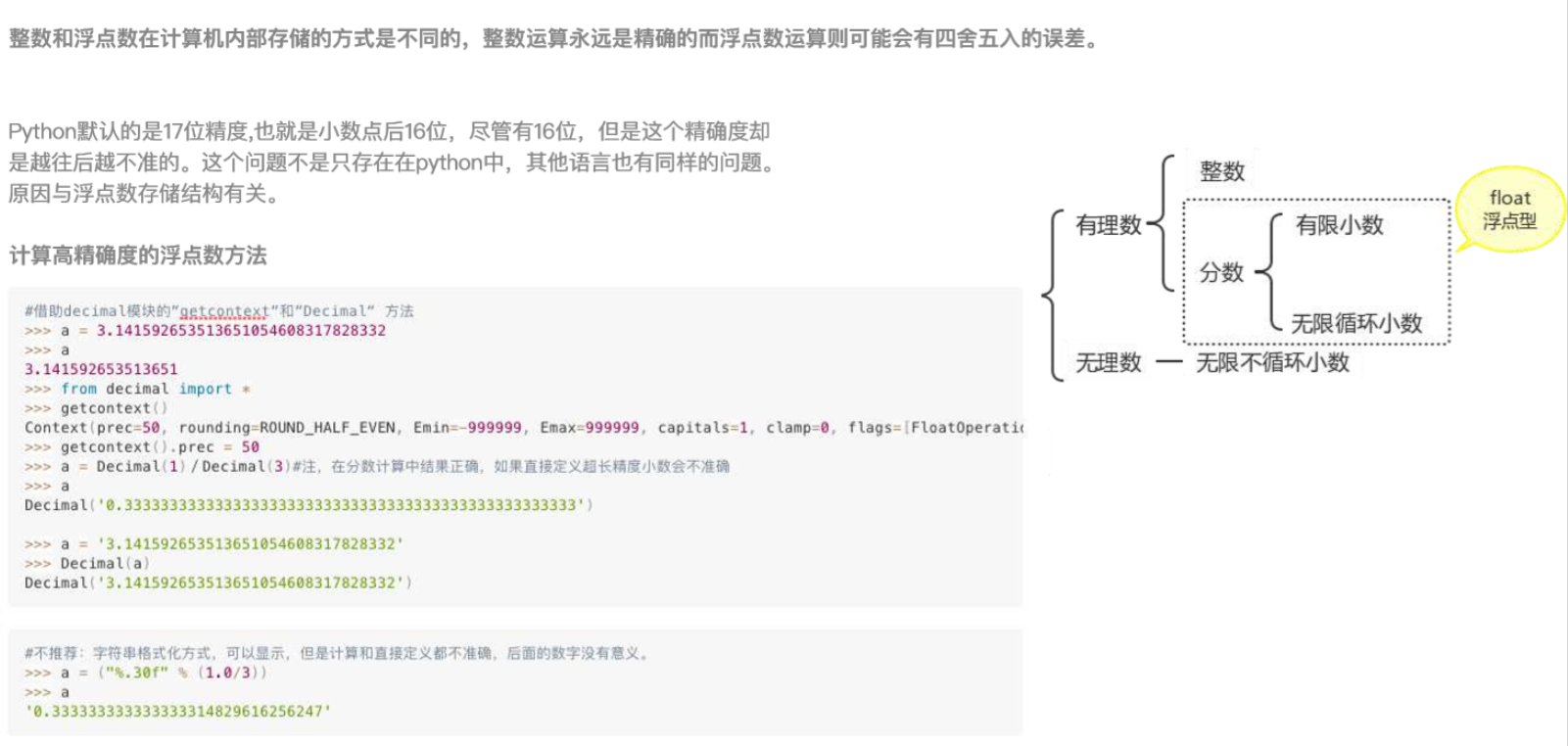
浮点数和科学计数法
之前已经学习了基本数据类型:数字类型里的整数int、长整型long、字符串类型里的文本str、布尔类型
接下来学习其他的:
浮点数
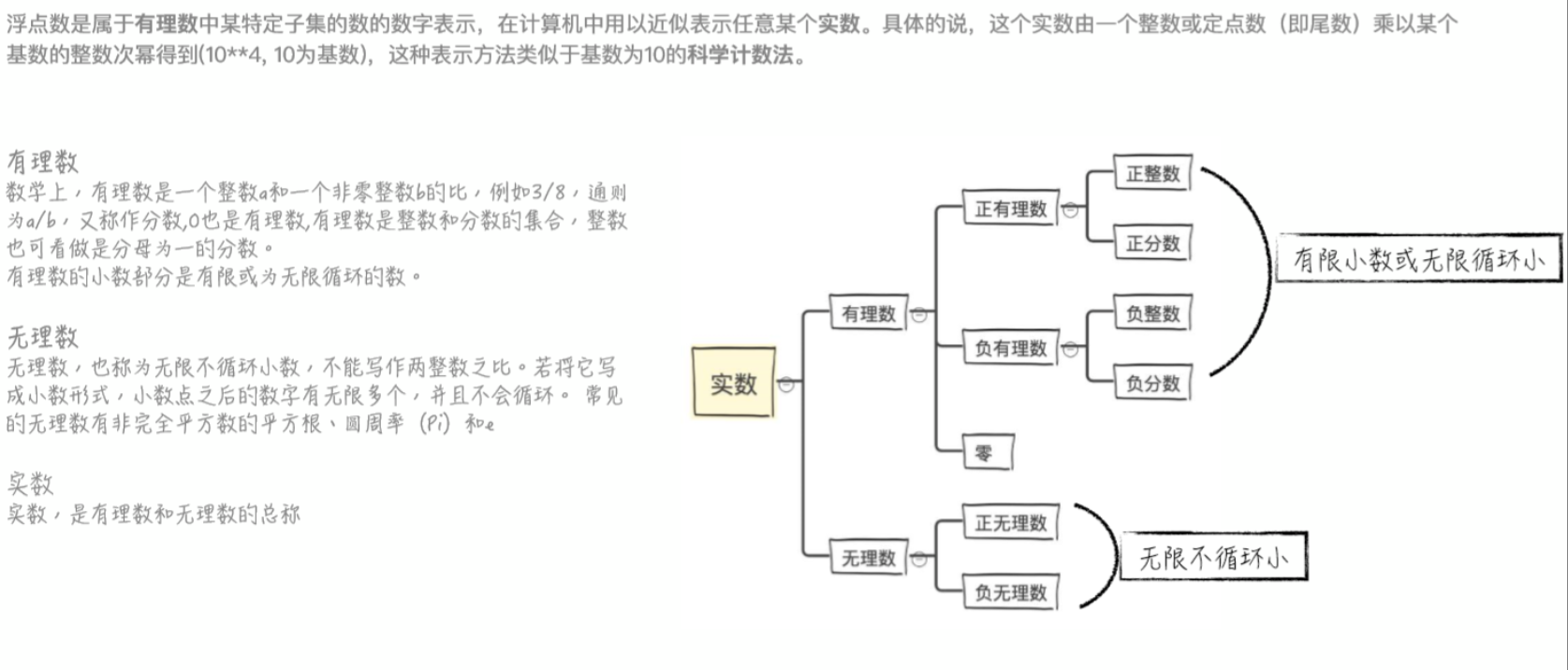
数学太烂了,理论解释说不清楚,直接来看PPT
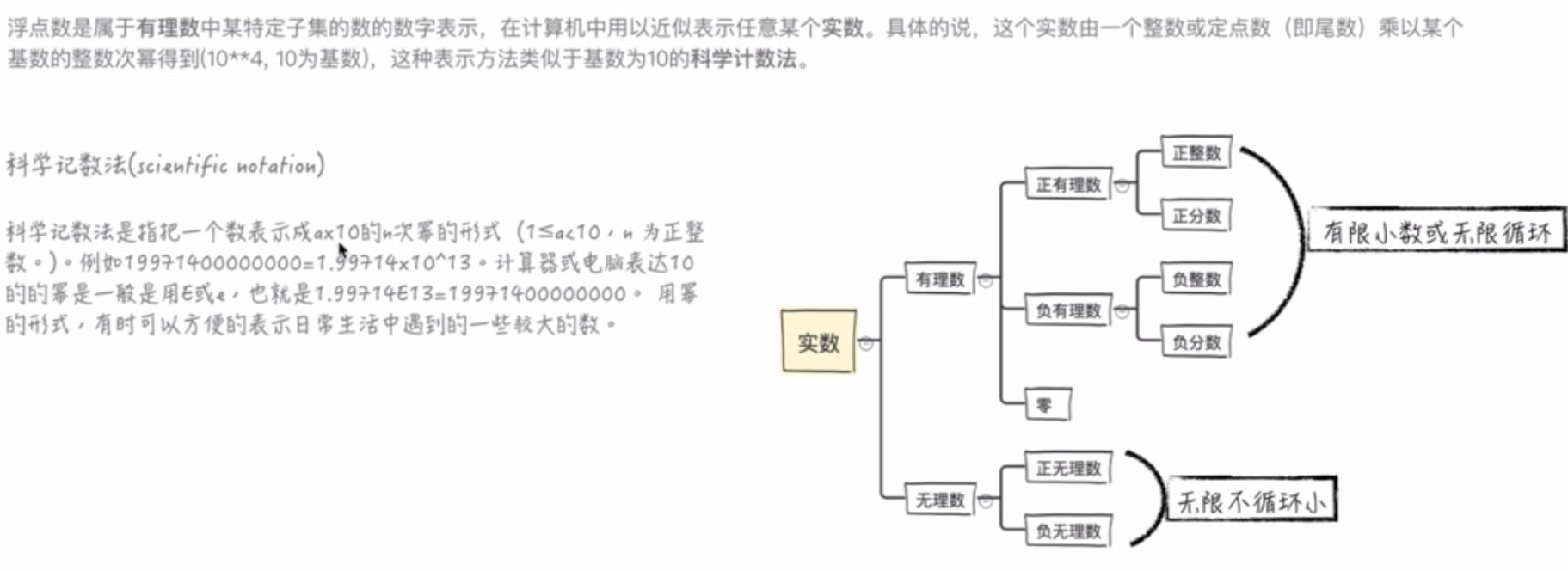

科学计数法:
>>> 1399 1399 >>> 1.399e3 1399.0
浮点数的精确度问题:
小数在python里只能精确存储17位
一个浮点数占用的存储空间要比整数大
列表
之前学习了变量来存储数据,那如何通过一个变量存储公司所有员工的名字?
这里学习列表,我们使用列表来存储。
列表是一个数据的集合,集合内可以放任何数据类型,可对集合进行方便的增删改查操作。
L1 = [] # 定义一个空列表 L2 = ['a', 'b', 'c', 'd'] # 存4个值,索引为0-3 L3 = ['abc', ['def', 'ghi']] # 嵌套列表
列表的功能:
创建
查询
切片
增加
修改
删除
循环
排序
列表-创建:
# 方法一 L1 = [] # 定义一个空列表 L2 = ['a', 'b', 'c', 'd'] # 存4个值,索引为0-3 L3 = ['abc', ['def', 'ghi']] # 嵌套列表 # 方法二 L4 = list() print(L4)
列表-查询:
>>> L2 = ['a', 'b', 'c', 'd', 'a', 'e', 1, 2] >>> L2[2] # 通过索引取值 'c' >>> L2[-1] # 通过索引从列表右边开始取值 2 >>> L2[-2] 1 >>> L2.index('a') # 返回指定元素的索引值,从左往右找,找到第一个匹配值 则返回 0 >>> L2.count('a') # 统计指定元素的个数 2 >>>
列表-切片:
切片都是顾头不顾尾。
>>> L2 = ['a', 'b', 'c', 'd', 'a', 'e', 1, 2] >>> L2 ['a', 'b', 'c', 'd', 'a', 'e', 1, 2] >>> L2[0:3] # 返回从索引0到3的元素,不包括3,顾头不顾尾 ['a', 'b', 'c'] >>> L2[0:-1] # 返回从索引0至最后一个值,不包括最后一个值 ['a', 'b', 'c', 'd', 'a', 'e', 1] >>> L2[3:6] # 返回从索引3至6的元素 ['d', 'a', 'e'] >>> L2[3:] # 返回从索引3至最后所有的值 ['d', 'a', 'e', 1, 2] >>> L2[:3] # 返回从索引0至3的值 ['a', 'b', 'c'] >>> L2[1:6:2] # 返回索引1至6的值,但是步长为2(每隔一个元素,取一个值) ['b', 'd', 'e'] >>> L2[:] # 返回所有的值 ['a', 'b', 'c', 'd', 'a', 'e', 1, 2] >>> L2[::2] # 按步长为2,返回所有的值 ['a', 'c', 'a', 1]
列表-增加/修改:
>>> L2 = ['a', 'b', 'c', 'd', 'a', 'e', 1, 2] >>> L2 ['a', 'b', 'c', 'd', 'a', 'e', 1, 2] >>> L2.append('A') # 列表最后面追加A >>> L2 ['a', 'b', 'c', 'd', 'a', 'e', 1, 2, 'A'] >>> L2.insert(3,'B') # 在列表的索引为3的位置插入一个值B >>> L2 ['a', 'b', 'c', 'B', 'd', 'a', 'e', 1, 2, 'A']>>>
>>> L2 ['a', 'b', 'c', 'B', 'd', 'a', 'e', 1, 2, 'A'] >>> L2[3] = 'Boy' # 把索引3的元素修改为Boy >>> L2 ['a', 'b', 'c', 'Boy', 'd', 'a', 'e', 1, 2, 'A'] >>> L2[4:6] = 'ALEX LI' # 把索引4-6的元素改为ALEX LI,不够的元素自动增加 >>> L2 ['a', 'b', 'c', 'Boy', 'A', 'L', 'E', 'X', ' ', 'L', 'I', 'e', 1, 2, 'A'] >>>
列表-删除:
>>> L2 ['a', 'b', 'c', 'Boy', 'A', 'L', 'E', 'X', ' ', 'L', 'I', 'e', 1, 2, 'A'] >>> >>> L2.pop() # 删除最后一个元素 'A' >>> L2 ['a', 'b', 'c', 'Boy', 'A', 'L', 'E', 'X', ' ', 'L', 'I', 'e', 1, 2] >>> L2.remove('L') # 删除从左找到的第一个指定元素 >>> L2 ['a', 'b', 'c', 'Boy', 'A', 'E', 'X', ' ', 'L', 'I', 'e', 1, 2] >>> del L2[4] # 用python全局的删除方法删除指定元素 >>> L2 ['a', 'b', 'c', 'Boy', 'E', 'X', ' ', 'L', 'I', 'e', 1, 2] >>> del L2[3:7] # 删除多个元素 >>> L2 ['a', 'b', 'c', 'L', 'I', 'e', 1, 2] >>>
del是全局删,想删什么删什么。
比如删变量:
names = ["a", "b"]
del names
列表-循环:
L2 = ['a', 'b', 'c', 'd', 'a', 'e', 1, 2] for i in L2: print(i)
输出:
a b c d a e 1 2
for循环:
for i in range(10): # range(10) 生成10个随机的数 print(i)
输出:
0 1 2 3 4 5 6 7 8 9
for循环与while循环的区别:
while可以是死循环,可以无边界。
for循环有边界
列表-排序:
排序规则:按照ASCII码表的顺序
>>> L2 ['a', 'b', 'c', 'L', 'I', 'e', 1, 2] >>> >>> L2.sort() Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: '<' not supported between instances of 'int' and 'str' # 不能对包含了str和int的列表进行排序 >>> >>> L2.pop() 2 >>> L2.pop() 1 >>> L2.sort() >>> L2 ['I', 'L', 'a', 'b', 'c', 'e'] >>> L2.insert(4,'#') >>> L2.insert(1,'!') >>> L2 ['I', '!', 'L', 'a', 'b', '#', 'c', 'e'] >>> L2.sort() >>> L2 ['!', '#', 'I', 'L', 'a', 'b', 'c', 'e'] >>> L2.reverse() # 反转 >>> L2 ['e', 'c', 'b', 'a', 'L', 'I', '#', '!'] >>>
列表-其它用法:
>>> L2 ['e', 'c', 'b', 'a', 'L', 'I', '#', '!'] >>> L2.extend([1,2,3,4]) # 把一个列表,扩展到L2列表 >>> L2 ['e', 'c', 'b', 'a', 'L', 'I', '#', '!', 1, 2, 3, 4] >>> >>> L2[2] = ['Alex','Jack','Rain'] >>> L2 ['e', 'c', ['Alex', 'Jack', 'Rain'], 'a', 'L', 'I', '#', '!', 1, 2, 3, 4] >>> L2[2][2] # 嵌套列表取值 'Rain' >>> L2.clear() # 清空列表 >>> L2 [] >>> L2.copy() # copy方法,后面单独讲 [] >>>
列表练习题:
1.创建一个空列表,命名为names,往里面添加old_driver,rain,jack,shanshan,peiqi,black_girl 元素
>>> names = [] >>> names.append("old_friver") >>> names.append("rain") >>> names.append("jack") >>> names.append("shanshan") >>> names.append("peiqi") >>> names.append("black_girl") >>> names ['old_friver', 'rain', 'jack', 'shanshan', 'peiqi', 'black_girl'] >>>
2.往names列表里black_girl前面插入一个alex
>>> names ['old_friver', 'rain', 'jack', 'shanshan', 'peiqi', 'black_girl'] >>> names.insert(-1, "alex") >>> names ['old_friver', 'rain', 'jack', 'shanshan', 'peiqi', 'alex', 'black_girl'] >>>
3.把shanshan的名字改为中文,姗姗
>>> names ['old_friver', 'rain', 'jack', 'shanshan', 'peiqi', 'alex', 'black_girl'] >>> >>> names[names.index("shanshan")] = "姗姗" >>> names ['old_friver', 'rain', 'jack', '姗姗', 'peiqi', 'alex', 'black_girl'] >>>
4.往names列表里rain的后面插入一个子列表,[oldboy,oldgirl]
>>> names ['old_friver', 'rain', 'jack', '姗姗', 'peiqi', 'alex', 'black_girl'] >>> names.insert(2, ["oldboy", "oldgirl"]) >>> names ['old_friver', 'rain', ['oldboy', 'oldgirl'], 'jack', '姗姗', 'peiqi', 'alex', 'black_girl'] >>>
5.返回peiqi的索引值
>>> names ['old_friver', 'rain', ['oldboy', 'oldgirl'], 'jack', '姗姗', 'peiqi', 'alex', 'black_girl'] >>> names.index("peiqi") 5 >>>
6.创建新列表[1,2,3,4,2,5,6,2],合并入names列表
>>> names ['old_friver', 'rain', ['oldboy', 'oldgirl'], 'jack', '姗姗', 'peiqi', 'alex', 'black_girl'] >>> L2 = [1, 2, 3, 4, 2, 5, 6, 2] >>> names.extend(L2) >>> names ['old_friver', 'rain', ['oldboy', 'oldgirl'], 'jack', '姗姗', 'peiqi', 'alex', 'black_girl', 1, 2, 3, 4, 2, 5, 6, 2] >>>
7.取出names列表中索引4-7的元素
>>> names ['old_friver', 'rain', ['oldboy', 'oldgirl'], 'jack', '姗姗', 'peiqi', 'alex', 'black_girl', 1, 2, 3, 4, 2, 5, 6, 2] >>> names[4:7] ['姗姗', 'peiqi', 'alex'] >>>
8.取出names列表中索引2-10的元素,步长为2
>>> names ['old_friver', 'rain', ['oldboy', 'oldgirl'], 'jack', '姗姗', 'peiqi', 'alex', 'black_girl', 1, 2, 3, 4, 2, 5, 6, 2] >>> names[2:10:2] [['oldboy', 'oldgirl'], '姗姗', 'alex', 1] >>>
9.取出names列表最后3个元素
>>> names ['old_friver', 'rain', ['oldboy', 'oldgirl'], 'jack', '姗姗', 'peiqi', 'alex', 'black_girl', 1, 2, 3, 4, 2, 5, 6, 2] >>> names[-3:] [5, 6, 2] >>>
10.循环names列表,打印每个元素的索引值,和元素
names = ['old_friver', 'rain', ['oldboy', 'oldgirl'], 'jack', '姗姗', 'peiqi', 'alex', 'black_girl', 1, 2, 3, 4, 2, 5, 6, 2] for index, i in enumerate(names): print(index, i)
输出:
0 old_friver 1 rain 2 ['oldboy', 'oldgirl'] 3 jack 4 姗姗 5 peiqi 6 alex 7 black_girl 8 1 9 2 10 3 11 4 12 2 13 5 14 6 15 2
说明:在解这道题的时候我最开始是下面这样的,根据值去获取索引号,但是这样有问题,当列表里有重复值的时候就不对了。
for i in names: print(names.index(i), i) # 注意:列表中有重复的值,所以获取索引号时只会获取到第一个值的索引号,有问题,此方法在有重复值的列表里不可取
11.循环names列表,打印每个元素的索引值,和元素,当索引值为偶数时,把对应的元素改为-1
names = ['old_friver', 'rain', ['oldboy', 'oldgirl'], 'jack', '姗姗', 'peiqi', 'alex', 'black_girl', 1, 2, 3, 4, 2, 5, 6, 2] for index, i in enumerate(names): if index % 2 == 0: names[index] = -1 print(names)
输出:
[-1, 'rain', -1, 'jack', -1, 'peiqi', -1, 'black_girl', -1, 2, -1, 4, -1, 5, -1, 2]
12.names里有3个2,请返回第2个2的索引值。不要人肉数,要动态找(提示,找到第一个2的位置,在此基础上再找第2个)
names = ['old_friver', 'rain', ['oldboy', 'oldgirl'], 'jack', '姗姗', 'peiqi', 'alex', 'black_girl', 1, 2, 3, 4, 2, 5, 6, 2] first_index = names.index(2) list2 = names[first_index + 1:] second_index = list2.index(2) second_value = names[first_index + second_index + 1] print("second_value is:", second_value)
输出:
second_value is: 2
13. 现有商品列表如下:
products = [['Iphone8',6888],['MacPro',14800],['小米6',2499],['Coffee',31],['Book',80],['Nike Shoes',799]]
需打印出这样的格式:
------------商品列表------------
0.Iphone8 6888
1.MacPro 14800
2.小米6 2499
3.Coffee 31
4.Book 80
5.Nike Shoes 799
products = [['Iphone8', 6888], ['MacPro', 14800], ['小米6', 2499], ['Coffee', 31], ['Book', 80], ['Nike Shoes', 799]] print("------------商品列表------------") for i in products: print("%s.%s %s" % (products.index(i), i[0], i[1]))
14.写一个循环,不断问用户想买什么,用户选择一个商品编号,就把对应的商品添加到购物车里,最终用户输入q退出时,打印购物车里的商品列表
products = [['Iphone8', 6888], ['MacPro', 14800], ['小米6', 2499], ['Coffee', 31], ['Book', 80], ['Nike Shoes', 799]] cart = [] while True: print("------------商品列表------------") for index, i in enumerate(products): print("%s. %s %s" % (index, i[0], i[1])) choice = input("please choose product:") if choice == "q": if len(cart) > 0: print("你购买的商品如下:") for index, i in enumerate(cart): print("%s. %s %s" % (index, i[0], i[1])) break elif choice.isdigit(): choice = int(choice) if int(choice) >= len(products): print("没有你选择的商品,请重新选择.") else: cart.append(products[choice]) print("添加 %s 到购物车成功." % (products[choice][0])) else: print("无此选项。")
列表-深浅copy:
列表的深浅copy涉及到python对内存的使用。
首先看变量里的内存使用,如下:
>>> a = 1 >>> b = a>>> id(a),id(b) # 通过id查看a和b的内存地址 (1904042208, 1904042208) # 可以看到此时a和b的内存地址是一样的 >>> >>> a = 2 # 将a的值进行改变 >>> a 2 >>> b 1 >>> id(a),id(b) (1904042240, 1904042208) # 再次查看,内存地址变化了

来看列表,如果我们想变量一样进行赋值:
>>> names = ["alex","simon","kevin","bill"] >>> n1 = names # 想b=a一样将names赋给n1 >>> >>> names ['alex', 'simon', 'kevin', 'bill'] >>> n1 ['alex', 'simon', 'kevin', 'bill'] # n1的值和names一样 >>> >>> id(names),id(n1) (2670215022920, 2670215022920) # 查看两个列表的内存地址一样 >>> >>> names[0] 'alex' >>> n1[0] 'alex' >>> id(names[0]),id(n1[0]) (2670215033048, 2670215033048) # 查看两个列表里的同一个元素内存地址也一样 >>> >>> names[0] = "ALEX" # 将names的元素进行修改 >>> names ['ALEX', 'simon', 'kevin', 'bill'] # 修改成功 >>> n1 ['ALEX', 'simon', 'kevin', 'bill'] # 改的names,但是n1也跟着改变了 >>> >>> id(names[0]),id(n1[0]) (2670215033384, 2670215033384) # 查看到内存地址依然是相同的 >>>
为什么修改的names的元素,n1却跟着改变了呢?
因为names列表是有独立的内存空间的,列表里面的元素也是有独立空间的,将n1=names,实际上只是将n1指向了和names同样的内存空间,里面的元素地址是不会变的,所以修改names,n1也会跟着变,因为修改的是同一个地方。
浅copy:
那如何做到修改names,n1不会跟着变化呢,这里我们就来学习学习浅copy:
>>> names ['ALEX', 'simon', 'kevin', 'bill'] >>> >>> n2 = names.copy() # 使用copy()方法赋给n2 >>> >>> names ['ALEX', 'simon', 'kevin', 'bill'] >>> n2 ['ALEX', 'simon', 'kevin', 'bill'] # n2的元素和names一样,没毛病 >>> >>> id(names),id(n2) (2670215022920, 2670215023432) # 查看到names和n2的内存空间已经不一样的,说明n2是新开的一块空间 >>> >>> id(names[0]),id(n2[0]) (2670215033384, 2670215033384) # 看看names和n2的第0个元素内存地址,竟然是一样的,先不急继续看下面 >>>
>>> names[0]="Alex Chen" # 修改names[0] 的值 >>> names ['Alex Chen', 'simon', 'kevin', 'bill'] # 修改成功 >>> n2 ['ALEX', 'simon', 'kevin', 'bill'] # n2的第0个元素没有跟着变化,说明两个列表独立了 >>> >>> id(names[0]),id(n2[0]) (2670215030640, 2670215033384) # 看看内存地址是不一致的,确实是独立了 >>>
没有修改之前,两个元素的内存地址是一样的,修改之后两个元素的内存地址就不一样了,这里就和变量那个例子同样的道理了,没有修改之前元素指的是同一个空间,这样可以节省内存使用,修改之后再重新开辟空间给各自使用。
上面的例子应该就满足我们的需要了,既使内存得到合理的利用,2个列表之间又互不影响,简直完美,真的解决了吗?那你就too young too naive.
继续往下看:
>>> names ['Alex Chen', 'simon', 'kevin', 'bill'] >>> names.append(["pen","pencil"]) # 给names插入一个小列表 >>> names ['Alex Chen', 'simon', 'kevin', 'bill', ['pen', 'pencil']] >>> >>> n3 = names.copy() # 进行copy操作给n3 >>> >>> names ['Alex Chen', 'simon', 'kevin', 'bill', ['pen', 'pencil']] >>> n3 ['Alex Chen', 'simon', 'kevin', 'bill', ['pen', 'pencil']] # 元素和names一样 >>> >>> id(names),id(n3) (2670215022920, 2670215030344) # 大列表内存地址不一样,说明两个列表是独立的 >>> >>> id(names[-1]),id(n3[-1]) (2670215023112, 2670215023112) # 看最后一个小元素,内存地址一样的,根据上一个例子,没有对元素进行过修改,使用的同一内存地址不奇怪 >>> >>> id(names[-1][0]),id(n3[-1][0]) (2670215033440, 2670215033440) # 看看小列表里面的元素,地址也是一样的 >>> >>> names[-1][0] = "PEN" # 将names里的小列表元素进行修改 >>> names ['Alex Chen', 'simon', 'kevin', 'bill', ['PEN', 'pencil']] # 修改成功 >>> n3 ['Alex Chen', 'simon', 'kevin', 'bill', ['PEN', 'pencil']] # 擦,怎么n3跟着变了? >>> id(names[-1][0]),id(n3[-1][0]) (2670215033496, 2670215033496) # 再看看小列表元素的内存地址,是一样的。 >>>
为什么修改了names小列表的元素,n3跟着变了,按照之前的例子,不是copy后进行修改就会开辟一块新空间来存值吗?才不是呢。copy()只对第一层生效,对里面的子列表就瞎了。
深copy:
>>> names ['Alex Chen', 'simon', 'kevin', 'bill', ['PEN', 'pencil']] >>> import copy #使用深copy需要引入copy模块 >>> n4 = copy.deepcopy(names) # 使用deepcopy()方法进行深copy给n4 >>> names ['Alex Chen', 'simon', 'kevin', 'bill', ['PEN', 'pencil']] >>> n4 ['Alex Chen', 'simon', 'kevin', 'bill', ['PEN', 'pencil']] # 元素一样,没毛病 >>> id(names),id(n4) (2670215022920, 2670216486152) # 2个列表内存地址不一样,是独立的 >>> id(names[0]),id(n4[0]) (2670215030640, 2670215030640) # 2个列表里的普通元素内存地址一样的,修改后会变的 >>> id(names[-1]),id(n4[-1]) (2670215023112, 2670216486216) # 2个列表里的子列表内存地址不一样,说明子列表是独立的
>>> id(names[-1][0]),id(n4[-1][0])
>>> (2670215033496, 2670215033496) # 2个列表里的子列表的元素内存地址也一样
>>> names[0] = "China" # 修改names的第0个元素 >>> names ['China', 'simon', 'kevin', 'bill', ['PEN', 'pencil']] # 修改成功 >>> n4 ['Alex Chen', 'simon', 'kevin', 'bill', ['PEN', 'pencil']] # n4没有跟着改变,没问题 >>> >>> names[-1][0] = "Box" # 修改子列表的第0个元素 >>> names ['China', 'simon', 'kevin', 'bill', ['Box', 'pencil']] # 修改成功 >>> n4 ['Alex Chen', 'simon', 'kevin', 'bill', ['PEN', 'pencil']] # n4没有跟着改变,没问题 >>>
以上使用深copy就实现了列表copy的完全独立。
数据类型-字符串
字符串是一个有序的字符的集合,用于存储和表示基本的文本信息,一对单双、或三引号中间包含的内容称之为字符串。
创建:
s = "Hello, beauty! How are you?"
特征:
有序
不可变
方法:
1. capitalize()
>>> s = "Hello World" >>> s.capitalize() # 只将整个字符串首字母大写 'Hello world'
2. casefold()
>>> s = "Hello World" >>> s.casefold() # 全部变小写 'hello world'
3. center()
>>> s = "Hello World" >>> s.center(20) # 将字符串设定为指定长度,字符串居中,不够默认以空格填充 ' Hello World ' >>> s.center(20,"-") #将字符串设定为指定长度,字符串居中,以“-”进行填充 '----Hello World-----' >>>
4. count()
>>> s = "Hello World" >>> s.count("o") #统计有字符串中有多少个指定字符 2 >>> >>> s.count("o",1,5) # 给指定字符指定开始和结束范围,从索引1到5有多少个指定字符 1 >>>
5. encode()
暂时不讲
6. endswith()
>>> s = "Hello World" >>> s.endswith("orld") # 判断是否已指定字符结尾,是返回True True >>> s.endswith("aaa") # 不是返回False False >>>
7. expandtabs()
暂时不讲
8. find()
>>> s = "Hello World" >>> s.find("o") # 查询指定字符在字符串中的索引,只返回找到的第一个字符索引 4 >>> s.find("ddo") # 如果没有找到返回-1 -1 >>> s.find("o",5,9) # 指定查找范围,索引5到9 7 >>>
9. format()
>>> info = "My name is {0}, I'm {1} years old." >>> info.format("Alex",22) "My name is Alex, I'm 22 years old." >>> >>> info2 = "My name is {name}, I'm {age} years old." >>> info2.format(name="Alex",age=22) "My name is Alex, I'm 22 years old." >>>
10. format_map()
暂时不讲
11. index()
>>> s = "Hello World" >>> s.index("o") # 返回指定字符的索引值,只返回第一个找到的值 4 >>> s.index("o",5,9) # 指定查找范围 7 >>>
12. isalnum()
如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False
>>> s = "" >>> s.isalnum() False >>> s = "aaa" >>> s.isalnum() True >>> s = "123" >>> s.isalnum() True >>> s = "aaa123" >>> s.isalnum() True >>> >>> s = "aaa123$$" >>> s.isalnum() False >>>
13. isalpha()
如果 string 至少有一个字符并且所有字符都是字母则返回 True,否则返回 False
>>> s = "" >>> s.isalpha() False >>> s = "aaa" >>> s.isalpha() True >>> s = "123" >>> s.isalpha() False >>> s = "aaa$$" >>> s.isalpha() False >>>
14. isdecimal()
如果 string 只包含十进制数字则返回 True 否则返回 False.
>>> s = "123" >>> s.isdecimal() True >>> s = "abc123" >>> s.isdecimal() False
15. 如果 string 只包含数字则返回 True 否则返回 False.
>>> s = "123" >>> s.isdigit() True >>> s = "123ab" >>> s.isdigit() False
16. isidentifier
暂时不讲
17. islower()
判断字符串是否都是小写,是返回True,不是返回False
>>> s = "Hello" >>> s.islower() False >>> >>> s = "hello" >>> s.islower() True
18. isnumeric()
如果 string 中只包含数字字符,则返回 True,否则返回 False
>>> s = "123" >>> s.isnumeric() True >>> s= "壹" >>> s.isnumeric() True >>> s="一" >>> s.isnumeric() True
19. isprintable()
暂时不讲
20. isspace()
如果 string 中只包含空格,则返回 True,否则返回 False.
>>> s="" >>> s.isspace() False >>> s=" " >>> s.isspace() True
21.istitle()
如果 string 是标题化的(见 title())则返回 True,否则返回 False
>>> s = "Hello World" >>> s.istitle() True >>> s = "Hello world" >>> s.istitle() False >>> s = "hello world" >>> s.istitle() False >>>
22. isupper()
判断是否都是大写。
>>> s = "Hello World" >>> s.isupper() False >>> s = "HELLO" >>> s.isupper() True >>>
23. join()
以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串
>>> s1 = "-" >>> s2 = ["a","b","c"] >>> s1.join(s2) 'a-b-c' >>>
24. ljust()
>>> s = "Hello World" >>> s.ljust(50) # 居左,填充至指定个数字符 'Hello World ' >>> s.ljust(50,"-") # 居左,已“-”填充 'Hello World---------------------------------------' >>>
25. lower()
>>> s = "Hello World" >>> s.lower() # 大写变小写 'hello world'
26. lstrip()
>>> s = "\n\t Hello World " >>> s.lstrip() # 截掉左边的空格 'Hello World '
27. maketrans()
暂时不讲
28. partition()
暂时不讲
29. replace()
替换
>>> s = "Hello World" >>> s.replace("o","O") # 默认替换所有指定字符,将小o替换为大O 'HellO WOrld' >>> s.replace("o","O",1) # 指定只替换1次 'HellO World' >>>
30. rfind()
>>> s = "Hello World" >>> s.rfind("o") # 从右往左查找,返回索引值 7
>>> s.rfind("ooo") # 没有返回-1
-1
31. rindex()
>>> s = "Hello World" >>> s.rindex("o") # 从右往左查找,返回索引值 7 >>> s.rindex("oooo") # 没有返回错误 Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: substring not found >>>
32. rjust()
>>> s = "Hello World" >>> s.rjust(50) ' Hello World' >>> s.rjust(50,"-") '---------------------------------------Hello World' >>>
33. rpartition()
暂时不讲
34. rsplit()
>>> s = "Hello World" >>> s.rsplit() ['Hello', 'World'] >>> s="a,b,c,d,e" >>> s.rsplit() ['a,b,c,d,e']
35. rstrip()
>>> s = "\n\t Hello World \t\n " >>> s.rstrip() '\n\t Hello World' >>>
36. split()
>>> s = "Hello World" >>> s.split() ['Hello', 'World'] >>> s="a,b,c,d,e" >>> s.split() ['a,b,c,d,e'] >>>
37. splitlines()
>>> s='a\nb\nc' >>> s.splitlines() ['a', 'b', 'c'] >>>
38. startswith()
>>> s='Hello World' >>> s.startswith("He") True >>> s.startswith("he") False >>>
39. strip()
>>> s = "\n\t Hello World \t\n " >>> s.strip() 'Hello World'
40. swapcase()
>>> s='Hello World' >>> s.swapcase() # 大写变小写,小写变大写 'hELLO wORLD'
41. title()
>>> s = "hello world" >>> s.title() # 设置为标题格式,即每个单词首字母大写 'Hello World' >>>
42. translate()
暂时不讲
43. upper()
>>> s = "hello world" >>> s.upper() # 小写变大写 'HELLO WORLD' >>>
44. zfill()
返回长度为指定宽度的字符串,原字符串 string 右对齐,前面填充0
>>> s = "hello world" >>> s.zfill(20) # 宽度20 '000000000hello world' >>> s.zfill(40) # 宽度40 '00000000000000000000000000000hello world' >>>
数据类型-元组
元组和列表差不多,也是存一组数,只不过它一旦创建,便不能再修改,所以又叫只读列表
names = ("alex","jack","eric")
特征:
不可变
元组本身不可变,如果元组中还包含其他可变元素,这些可变元素可以改变
功能:
index
count
切片
使用场景:
显示的告知别人,此处数据不可修改
数据库连接配置信息等
插入知识-hash函数
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
特征:
hash值的计算过程是依据这个值的一些特征计算的,这就是要求被hash的值必须固定,因此被hash的值必须是不可变的。
用途:
文件签名
md5加密
密码验证
>>> hash("abc") -5247515932151086839 >>> hash("alex") 8653465431056711621 >>> hash("abc") -5247515932151086839 >>>
被hash的只能是不可变类型。
可变类型:列表
不可变类型:数字、字符串、元组
数据类型-字典
引子:如何在一个变量里存储公司每个员工的个人信息?
在之前我们可以通过下面这种方式:
names = [ ["alex", 26, "技术部", "卖苦力的", 13012341234], ["jack", 26, "人事部", "HR", 13012341234], ["simon", 26, "设计部", "UI", 13012341234] ]
上面我们使用列表嵌套的方式将信息存入了,虽然是存入了,但是取就是个大问题。以上只有3条记录,如果有上万条记录,你就抓瞎了。
那么如果来存呢?我们可以使用字典。
字典是一种key-value的数据类型,使用就像我们上学用的字典,通过笔画、字母查对应也的详细内容。
特征:
key-value结构
key必须可hash、且必须为不可变数据类型、必须唯一
可存放任意多个值、可修改、可以不唯一
无序(因为没有索引)
查找速度快
语法:
info = { "alex": [26, "技术部", "卖苦力的", 13012341234], "jack": [26, "人事部", "HR", 13012341234], "simon": [26, "设计部", "UI", 13012341234] }
增加:
info["zhangsan"] = [32, "酒店部", "清洁工", 13122332233] print(info)
输出:
{'alex': [26, '技术部', '卖苦力的', 13012341234], 'jack': [26, '人事部', 'HR', 13012341234], 'simon': [26, '设计部', 'UI', 13012341234], 'zhangsan': [32, '酒店部', '清洁工', 13122332233]}
修改:
info["alex"] = "此人已离职,信息清除." print(info)
输出:
{'alex': '此人已离职,信息清除.', 'jack': [26, '人事部', 'HR', 13012341234], 'simon': [26, '设计部', 'UI', 13012341234], 'zhangsan': [32, '酒店部', '清洁工', 13122332233]}
为什么key必须可hash?以及为什么查找速度快的原因?
字典的key hash之后会变成数字,在查找的时候,数字经过排序,然后利用二分法的原理进行查找,很快就可以找到要找的值。
二分法查询次数的说明:
>>> 2**10 1024 # 1024个记录,最多分10次找到数据 >>> >>> 2**16 65536 # 65536个路基,最多分16次找到数据
字典的方法:
print(info.get("alex")) # 返回key为 alex 的value ,没有找到返回 None
输出:
[26, '技术部', '卖苦力的', 13012341234]
print(info.values()) # 返回字典所有的value 输出: dict_values([[26, '技术部', '卖苦力的', 13012341234], [26, '人事部', 'HR', 13012341234], [26, '设计部', 'UI', 13012341234]])
print(info.keys()) # 返回字典所有的key 输出: dict_keys(['alex', 'jack', 'simon'])
print(info.pop("alex")) # 删除指定的key,并返回其对应的value
输出:
[26, '技术部', '卖苦力的', 13012341234]
info = {
"alex": [26, "技术部", "卖苦力的", 13012341234],
"jack": [26, "人事部", "HR", 13012341234],
"simon": [26, "设计部", "UI", 13012341234]
}
dict2 = {"a": "a_value", "b": "b_value", "simon": "测试用户"}
info.update(dict2) # 将字典dict2合并到字典info里,如果info里不存在的就创建,如果存在就覆盖
print(info)
输出:
{'alex': [26, '技术部', '卖苦力的', 13012341234], 'jack': [26, '人事部', 'HR', 13012341234], 'simon': '测试用户', 'a': 'a_value', 'b': 'b_value'}
info = {
"alex": [26, "技术部", "卖苦力的", 13012341234],
"jack": [26, "人事部", "HR", 13012341234],
"simon": [26, "设计部", "UI", 13012341234]
}
info2 = info.copy() # 将字典info copy到info2
print(info)
print(info2)
输出:
{'alex': [26, '技术部', '卖苦力的', 13012341234], 'jack': [26, '人事部', 'HR', 13012341234], 'simon': [26, '设计部', 'UI', 13012341234]}
{'alex': [26, '技术部', '卖苦力的', 13012341234], 'jack': [26, '人事部', 'HR', 13012341234], 'simon': [26, '设计部', 'UI', 13012341234]}
info = {
"alex": [26, "技术部", "卖苦力的", 13012341234],
"jack": [26, "人事部", "HR", 13012341234],
"simon": [26, "设计部", "UI", 13012341234]
}
print(info.items()) # 字典里的key和value变成小元组,放到一个大列表里
输出:
dict_items([('alex', [26, '技术部', '卖苦力的', 13012341234]), ('jack', [26, '人事部', 'HR', 13012341234]), ('simon', [26, '设计部', 'UI', 13012341234])])
print(info.popitem()) # 随机删除,并返回被删除key的value
输出:
('simon', [26, '设计部', 'UI', 13012341234])
info.clear() # 清空字典
dict1 = {}
mylist = ["a", "b", "c"]
dict3 = dict1.fromkeys(mylist)
print(dict3)
输出:
{'a': None, 'b': None, 'c': None}
dict3 = dict1.fromkeys(mylist,"新用户")
print(dict3)
输出:
{'a': '新用户', 'b': '新用户', 'c': '新用户'}
info = {
"alex": [26, "技术部", "卖苦力的", 13012341234],
"jack": [26, "人事部", "HR", 13012341234],
"simon": [26, "设计部", "UI", 13012341234]
}
print(info.setdefault("alex", "如果字典里没有key alex,我就填入,否则就返回alex的value"))
输出:
[26, '技术部', '卖苦力的', 13012341234]
print(info.setdefault("alex2", "如果字典里没有key alex,我就填入,否则就返回alex的value"))
print(info)
输出:
如果字典里没有key alex,我就填入,否则就返回alex的value
{'alex': [26, '技术部', '卖苦力的', 13012341234], 'jack': [26, '人事部', 'HR', 13012341234], 'simon': [26, '设计部', 'UI', 13012341234], 'alex2': '如果字典里没有key alex,我就填入,否则就返回alex的value'}
多级字典嵌套:
info = {
"alex": {
"age": 26,
"department": "技术部",
"position": "工程师",
"phone": 13111111111
},
"jack": [26, "人事部", "HR", 13012341234],
"simon": [26, "设计部", "UI", 13012341234]
}
print(info["alex"]["position"]) # 输出 工程师
print(info.get("alex").get("position")) # 输出 工程师
字典 循环:
info = { "alex": { "age": 26, "department": "技术部", "position": "工程师", "phone": 13111111111 }, "jack": [26, "人事部", "HR", 13012341234], "simon": [26, "设计部", "UI", 13012341234] } # 方法1: for key in info: print(key, info[key]) # 方法2: for k, v in info.items(): # info.items()会先把dict转成list,数据大时慎用 print(k, v)
输出都是:
alex {'age': 26, 'department': '技术部', 'position': '工程师', 'phone': 13111111111}
jack [26, '人事部', 'HR', 13012341234]
simon [26, '设计部', 'UI', 13012341234]
字典练习题:
写代码,有如下字典,按照要求实现每一个功能 dic = {"k1": "v1", "k2": "v2", "k3": "v3"}
1. 请循环遍历出所有的 key
for key in dic: print(key)
输出:
k1 k2 k3
2. 请循环遍历出所有的value
for key in dic: print(dic[key])
输出:
v1 v2 v3
3. 请循环遍历出所有的key和value
for key in dic: print(key, dic[key])
输出:
k1 v1 k2 v2 k3 v3
4. 请在字典中添加一个键值对,‘k4' : 'v4' ,输出添加后的字典
dic["k4"] = "v4" print(dic)
输出:
{'k1': 'v1', 'k2': 'v2', 'k3': 'v3', 'k4': 'v4'}
5. 请删除字典中键值对 'k1':'v1' ,并输出删除后的字典
dic.pop("k1") print(dic)
输出:
{'k2': 'v2', 'k3': 'v3', 'k4': 'v4'}
6. 请删除字典中的键 'k5' 对应的键值对,如果字典中不存在键 'k5' 则不报错,并且让其返回 None
dic = {"k1": "v1", "k2": "v2", "k3": "v3"}
dic["k4"] = "v4"
if "k5" in dic:
dic.pop("k5")
else:
print(dic.get("k5"))
输出:
None
7. 请获取字典中 'k2' 对应的值
dic = {"k1": "v1", "k2": "v2", "k3": "v3"}
dic["k4"] = "v4"
print(dic["k2"]) # 输出 v2
print(dic.get("k2")) # 输出 v2
8. 请获取字典中 'k6' 对应的值,如果'k6'不存在,则不报错,并且让其返回 None.
dic = {"k1": "v1", "k2": "v2", "k3": "v3"}
dic["k4"] = "v4"
print(dic.get("k6")) # 返回 None
9. 现有 dic2 = {'k1':'v111','a':'b'} 通过一行操作使 dic2 = {'k1': 'v1', 'a': 'b', 'k2': 'v2', 'k3': 'v3'}
dic = {"k1": "v1", "k2": "v2", "k3": "v3"}
dic2 = {'k1': 'v111', 'a': 'b'}
dic2.update(dic)
print(dic2)
10. 组合嵌套题。写代码,有如下列表,按照要求实现每一个功能
lis = [['k', ['qwe', 20, {'k1': ['tt', 3, "1"]}, 89], "ab"]]
1. 将列表lis 中的'tt'变成大写(用两种方式)。
lis[0][1][2]["k1"][0] = lis[0][1][2]["k1"][0].upper() lis[0][1][2]["k1"][0] = "TT"
2. 将列表中的数字3变成字符串'100'(用两种方式)。
lis[0][1][2]["k1"][1] = "100"
3. 将列表中的字符串'1'变成数字101(用两种方式)
lis[0][1][2]["k1"][2] = 101
11. 按照要求实现以下功能:
现有一个列表 li =[1,2,3,'a','b',4,'c'],有一个字典(此字典是动态生成的,你并不知道他里面 有多少键值对,所以用 dic = {} 模拟字典);
现在需要完成这样的操作:
如果该字典没有 'k1' 这个键,那就创建 'k1' 键和其对应的值(该键对应的值设置为空列表),并将列表 li 中的索引位为基数对应的元素,添加到 'k1' 这个键对应的空列表中。
如果该字典中有 'k1'这个键,且k1对应的value是列表类型,那就将列表li中的索引位为基数对应的元素,添加到'k1' 这个键对应的值中。
li = [1, 2, 3, 'a', 'b', 4, 'c'] dict = {} li2 = [] for index, i in enumerate(li): if index % 2 == 1: li2.append(i) if "k1" not in dict: dict["k1"] = li2 elif "k1" in dict and type(dict["k1"]) == list: dict["k1"] = li2 print(dict)
输出:
{'k1': [2, 'a', 4]}
数据类型-集合
集合是一个无序的,不重复的数据组合,它的主要作用如下:
去重,把一个列表变成集合,就自动去重了
关系测试,测试两组数据之前的交集、差集、并集等关系
来看一个例子:
如何找出同时买了iPhone7和iPhone8的人?
iphone7 = ["alex", "rain", "jack", "old_driver"]
iphone8 = ["alex", "shanshan", "jack", "old_boy"]
在这之前我们肯定会像下面这样做:
both_list = [] for i in iphone7: if i in iphone8: both_list.append(i) print(both_list)
结果输出:
['alex', 'jack']
我们通过上面的方法得到了同时购买iPhone7和iPhone8的人了。
如果逻辑在复杂点呢,比如找出买了iPhone7没买iPhone8的人,找出买了iPhone8没买iPhone7的人,找出没有同时买iPhone7和iPhone8的人,这时候如果要实现,就需要更多的判断来得到,就会很复杂。
这时候集合就可以帮助我们很容易的解决这个问题。
集合的定义:
my_set = {1, 2, 3,4 } # 使用大括号括起来并且有元素才叫集合, 如果 my_set = { } 没有元素就是一个普通的空字典
集合的自动去重:
>>> li = [1,1,2,3,4,23,6,4] >>> set(li) {1, 2, 3, 4, 6, 23}
列表转集合:
上面的去重例子就已经转为集合了。
集合的方法:
s = {1, 2, 3, 4, 5, 6}
s.add(7) # 增加一个值,如果增加的值是集合里已经存在的,无法加入,因为自动去重
print(s)
li = [11, 12]
s.update(li) # 扩展
print(s)
s.pop() # 随机删
print(s)
s.discard(12) # discard存在则直接删,不存在不报错,remove不存在会报错
print(s)
s.remove(4) # 删除指定
print(s)
s.clear() # 清空
print(s)
关系测试:
关系测试有:
交集:即2个集合里都有的
差集:即a集合里存在,在b集合里不存在 或 b集合里存在,在a集合里不存在
并集:即2个集合合起来,去重
对称差集:排除2个集合里都存在的
再回到之前的例子,我们可以用新方法来获取:
iphone7 = {"alex", "rain", "jack", "old_driver"}
iphone8 = {"alex", "shanshan", "jack", "old_boy"}
# 交集(iPhone7和iPhone8都买了的)
print(iphone7.intersection(iphone8)) # 输出:{'jack', 'alex'}
print(iphone7 & iphone8)
# 差集(只买了iPhone7的):
print(iphone7.difference(iphone8)) # 输出:{'rain', 'old_driver'}
print(iphone7 - iphone8)
# 差集(只买了iPhone8的):
print(iphone8.difference(iphone7)) # 输出:{'shanshan', 'old_boy'}
print(iphone8 - iphone7)
# 并集(只要是买了的,不管是买的iPhone7还是iPhone8)
print(iphone7.union(iphone8)) # 输出:{'jack', 'alex', 'old_boy', 'shanshan', 'rain', 'old_driver'}
print(iphone7 | iphone8)
# 对称差集(只买了iPhone7或者iPhone8的人,排除都买了的)
print(iphone7.symmetric_difference(iphone8)) # 输出:{'shanshan', 'old_boy', 'rain', 'old_driver'}
print(iphone7 ^ iphone8)
包含关系:
in 和 not in :判断某元素是否在集合内
== 和 != :判断两个集合是否相等
两个集合之间一般有三种关系:相交、包含、不相交。
在Python中分别用下面的方法判断:
set.isdisjoint(s): 判断两个集合是不是不相交
set.issuperset(s):判断集合是不是包含其他集合,等同于 a>=b
set.issubset(s):判断集合是不是被其他集合包含,等同于 a<=b
>>> s = {1, 2, 3, 4, 5, 6}
>>> s1 = {1 , 2}
>>> s.issuperset(s1) # s是s1的超集(s包含s1)
True
>>> s1.issubset(s) # s1是s的子集(s1被s包含)
True
>>>
>>> s.isdisjoint(s1) # 返回False说明s与s1是相交的
False
字符编码
特别重要,直接看大王的博客好文:http://www.cnblogs.com/alex3714/articles/7550940.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号