常用Python库
常见库全称
- cv2 = opencv-python
- PIL = pillow
- tqdm
- argparse
1.pathlib_面向对象的文件系统路径
pathlib模块提供了表示文件系统路径的类,可适用于不同的操作系统。使用 pathlib 模块,相比于 os 模块可以写出更简洁,易读的代码。pathlib 模块中的 Path 类继承自 PurePath,对 PurePath 中的部分方法进行了重载,相比于 os.path 有更高的抽象级别。
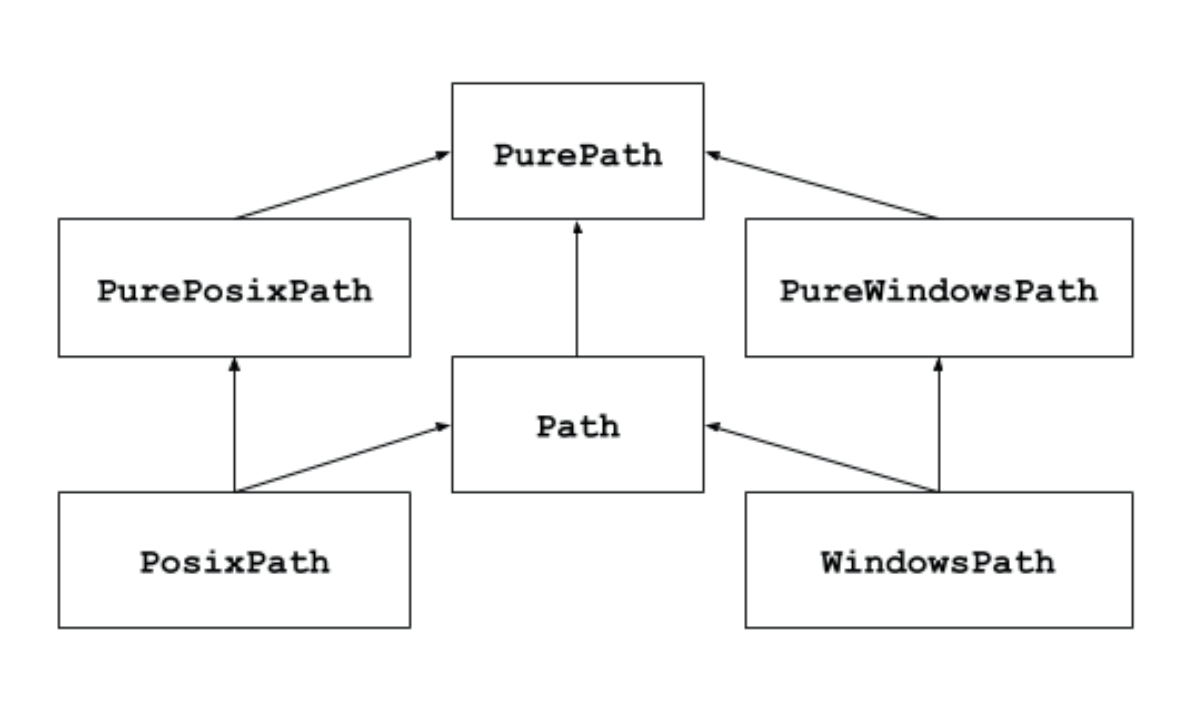
主要讲解具体路径:Path
导包:
from pathlib import Path,WindowsPath,PosixPath
实例化具体路径方式:
# 以当前系统的路径风格表示路径:
# class pathlib.Path(*pathsegments)
Path('setup.py')
# 非Windows系统路径风格:
# class pathlib.PosixPath(*pathsegments)
PosixPath('/etc')
# Windows系统路径风格:
# class pathlib.WindowsPath(*pathsegments)
WindowsPath('c:/Program Files/')
注:只能实例化与当前系统风格相同的类(允许系统调用作用于不兼容的路径风格可能在应用程序中导致缺陷或失败):
import os
os.name
# 'posix'
Path('setup.py')
# PosixPath('setup.py')
PosixPath('setup.py')
# PosixPath('setup.py')
WindowsPath('setup.py')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "pathlib.py", line 798, in __new__
% (cls.__name__,))
NotImplementedError: cannot instantiate 'WindowsPath' on your system
Path提供的方法:
-
获取目录
classmethod Path.cwd():返回一个新的表示当前目录的路径对象classmethod Path.home():返回一个表示用户家目录的新路径对象。 如果无法解析家目录,则会引发 RuntimeError。
-
创建、删除目录
Path.mkdir(),创建给定路径的目录。Path.rmdir(),删除该目录,目录文件夹必须为空。
-
路径判断
Path.exists(*, follow_symlinks=True):如果路径指向现有的文件或目录则返回 True。Path.is_dir():如果路径指向一个目录(或者一个指向目录的符号链接)则返回 True,如果指向其他类型的文件则返回 False。Path.is_file():如果路径指向一个正常的文件(或者一个指向正常文件的符号链接)则返回 True,如果指向其他类型的文件则返回 False。
-
获取文件所在目录的不同部分字段
Path.resolve(),通过传入文件名,返回文件的完整路径。Path.name,可以获取文件的名字,包含后缀名。Path.parent,返回文件所在文件夹的名字。parts:路径,每个部分的名称组成的元组。path = './labels/savedir/save.txt' save_path=path.resolve().parts # save_path=('labels','savedir','save.txt')Path.stem,获取文件名不包含后缀名。Path.suffix,获取文件的后缀名。Path.anchor,获取文件所在的盘符。
-
读写文件
Path.open(mode=‘r’),以 “r” 格式打开 Path 路径下的文件,若文件不存在即创建后打开。Path.read_bytes(),打开 Path 路径下的文件,以字节流格式读取文件内容,等同 open 操作文件的 “rb” 格式。Path.read_text(),打开 Path 路径下的文件,以 str 格式读取文件内容,等同 open 操作文件的 “r” 格式。Path.write_bytes(),对 Path 路径下的文件进行写操作,等同 open 操作文件的 “wb” 格式。Path.write_text(),对 Path 路径下的文件进行写操作,等同 open 操作文件的 “w” 格式。
-
文件统计以及匹配查找
Path.iterdir(),返回 Path 目录文件夹下的所有文件,返回的是一个生成器类型。Path.glob(pattern),返回 Path 目录文件夹下所有与 pattern 匹配的文件,返回的是一个生成器类型。Path.rglob(pattern),返回 Path 路径下所有子文件夹中与 pattern 匹配的文件,返回的是一个生成器类型。
-
路径拼接
斜杠 / 操作符用于
拼接路径,比如创建子路径。
newPath=curPath / 'path1'
注意:路径拼接是针对存在的路径,无法创造路径。
2.tqdm
tqdm库的使用教程
导包
from tqdm import tqdm
参数:
iterable: 可迭代的对象, 在⼿动更新时不需要进⾏设置desc: 字符串, 左边进度条描述⽂字total: 总的项⽬数leave: bool值, 迭代完成后是否保留进度条file: 输出指向位置, 默认是终端, ⼀般不需要设置ncols: 调整进度条宽度, 默认是根据环境⾃动调节长度, 如果设置为0, 就没有进度条, 只有输出的信息unit: 描述处理项⽬的⽂字, 默认是it, 例如: 100 it/s, 处理照⽚的话设置为img ,则为 100 img/sunit_scale: ⾃动根据国际标准进⾏项⽬处理速度单位的换算, 例如 100000 it/s >> 100k it/scolour: 进度条颜色
iterable = tqdm(iterable,desc,total,leave,file,ncols,unit,unit_scale,colour)
3.argparse-命令行选项、参数和子命令解析器
[!Note]
源代码:Lib/argparse.py
argparse模块可以让人轻松编写用户友好的命令行接口。 程序定义它需要哪些参数,argparse将会知道如何从sys.argv解析它们。argparse模块还能自动生成帮助和用法消息文本。 该模块还会在用户向程序传入无效参数时发出错误消息
[!Important]
argparse模块对命令行接口的支持是围绕argparse.ArgumentParser的实例建立的。 它是一个用于参数规格说明的容器并包含多个全面应用解析器的选项;
ArgumentParser.add_argument()方法将单个参数规格说明关联到解析器;
ArgumentParser.parse_args()方法运行解析器并将提取的数据放入argparse.Namespace对象
-
ArgumentParser对象
ArgumentParser 类的构造函数及其参数的说明:
prog: 程序的名称,默认是通过sys.argv[0]来获取,即当前执行的 Python 脚本文件名。usage: 描述程序用途的字符串,默认是根据添加到解析器的参数自动生成的。description: 在参数帮助信息之前显示的文本,默认是没有文本。epilog: 在参数帮助信息之后显示的文本,默认是没有文本。parents: 一个 ArgumentParser 对象的列表,它们的参数也应包含在内,用于将多个 ArgumentParser 对象的参数合并到一个对象中。formatter_class: 用于自定义帮助文档输出格式的类,默认是argparse.HelpFormatter。prefix_chars: 可选参数的前缀字符集合,默认是'-',表示短参数的前缀字符。fromfile_prefix_chars: 当需要从文件中读取其他参数时,用于标识文件名的前缀字符集合,默认是None。argument_default: 参数的全局默认值,默认是None。conflict_handler: 解决冲突选项的策略,默认是'error',即遇到冲突时会报错。add_help: 为解析器添加一个-h/--help选项,默认是True,表示添加帮助选项。allow_abbrev: 如果缩写是无歧义的,则允许缩写长选项,默认是True。exit_on_error: 决定当错误发生时是否让 ArgumentParser 附带错误信息退出,默认是True。
-
add_argument() 方法:
name or flags: 一个命名或选项字符串的列表,指定参数的名称或选项。例如,可以是'foo'或'-f', '--foo'。action:(常用) 参数在命令行中出现时使用的动作基本类型。它控制参数的行为。常见的动作包括存储值、存储布尔值、计数等。nargs: 指定命令行参数应当消耗的数目。可以是具体的数字,表示参数应当消耗的固定数目,也可以是'?'、'*'、'+'等特殊值,表示参数的数目可以是零个、任意个或至少一个。const: 被一些action和nargs选择所需求的常数。default: (常用)当参数未在命令行中出现并且也不存在于命名空间对象时所产生的值。即参数的默认值。type: (常用)命令行参数应当被转换成的类型。可以是 Python 内置的数据类型(如int、float、str等),也可以是自定义的类型转换函数。choices: 由允许作为参数的值组成的序列,限制参数的取值范围。required: 此命令行选项是否可省略(仅对选项参数有效)。如果设置为True,则用户在命令行中必须提供该选项。help: (常用)对此选项作用的简单描述,将显示在帮助信息中。metavar: 在使用方法消息中使用的参数值示例,通常用于描述参数的值的类型或格式。dest: 被添加到parse_args()所返回对象上的属性名。默认情况下,这个属性的名称是参数的名字,但你可以使用dest参数来指定一个不同的名称。
-
parse_args()方法:
args- 要解析的字符串列表。 默认值是从 sys.argv 获取namespace- 用于获取属性的对象。 默认值是一个新的空 Namespace 对象
-
其他实用工具
4.importlib-提供了一个丰富的 API 用来与导入系统进行交互。
importlib 包在 Python 中的主要目标可以概括为以下三个方面
1. 实现 Python 源代码中的 import 语句
解释:
- importlib 提供了 import 语句的 Python 实现,这意味着我们可以在纯 Python 代码中模拟 import 语句的行为。
- 通过 importlib,Python 的 import() 函数可以实现和扩展,从而更灵活地管理模块的导入。
2. 允许用户创建自定义导入器
解释:
- importlib 公开了一些实现 import 的底层机制,用户可以利用这些机制创建自定义的导入器(importer)。
- 这些自定义导入器可以在模块导入过程中发挥作用,提供额外的灵活性。例如,你可以从不同的源(如数据库、网络等)导入模块。
3. 提供附加功能的模块
importlib 包含了一些附加模块,这些模块提供了与包管理和资源访问相关的额外功能:
- a. importlib.metadata
- 功能:访问来自第三方发行版的元数据。
- 解释:你可以使用它来查询已安装包的版本信息、依赖项等。比如,用它可以获取安装的包的信息而不需要直接解析 dist-info 目录。
- b. importlib.resources
- 功能:访问来自 Python 包的非代码“资源”。
- 解释:这些资源可以是数据文件、配置文件等非代码文件。importlib.resources 提供了访问这些文件的便捷方法
总结
实现 import 语句:提供了一个用 Python 实现的 import 机制,更易于理解和移植。自定义导入器:通过公开部分 import 机制,使用户可以创建自己的导入器,增加灵活性。附加功能:包括 importlib.metadata 和 importlib.resources,用于访问包的元数据和非代码资源,进一步完善了包管理功能。
函数:
importlib.__import__(name, globals=None, locals=None, fromlist=(), level=0)¶
内置 __import__() 函数的实现。
importlib.import_module(name, package=None)
导入一个模块。 参数 name 指定了以绝对或相对导入方式导入什么模块 (比如要么像这样 pkg.mod 或者这样 ..mod)。 如果参数 name 使用相对导入的方式来指定,那么 package 参数必须设置为那个包名(前面部分),这个包名作为解析这个包名的锚点 (比如 import_module('..mod', 'pkg.subpkg') 将会导入 pkg.mod)。
import_module() 函数是一个对 importlib.import() 进行简化的包装器。 这意味着该函数的所有语义都来自于 importlib.import()。 这两个函数之间最重要的不同点在于 import_module() 返回指定的包或模块 (例如 pkg.mod),而 import() 返回最高层级的包或模块 (例如 pkg)。
示例1:根据配置中的数据集名称,动态地导入对应的模型模块,并调用其中的 get_model 函数来获取模型实例。
这样做的好处是可以根据需要方便地切换和使用不同数据集对应的模型,而不需要修改代码中的硬编码路径。
def get_model(cfg):
return importlib.import_module('model.model_'+cfg.dataset.lower()).get_model(cfg)
示例2:import_module用法
import importlib
# 与 import time 效果一样
time = importlib.import_module('time')
print(time.time())
# 与 import os.path as path 效果一样
path = importlib.import_module('os.path')
path.join('a', 'b') # results: 'a/b'
# 相对引入, 一级目录,与 import os.path as path 效果一样
path = importlib.import_module('.path', package='os')
path.join('a', 'b') # results: 'a/b'
# 相对引入,二级目录,与 import os.path as path 效果一样
path = importlib.import_module('..path', package='os.time')
path.join('a', 'b') # results: 'a/b'
注意最后的例子中,相对引入时需要在前面增加
.或者..来表示相对目录(一级目录则一个.,二级目录则..),如果直接使用importlib.import_module('path', package='os') 会报错。
示例3:假设我们在设计一个深度学习工具库,里面包含了N个网络模型(ResNet50, HRNet, MobileNet等等),每个模型的实现都有一个load_model 的函数。由于计算设备的性能不同,需要调用的网络结构也会变化,我们需要根据外部传入的参数来判断实际load哪一个模型。
def run(model_name, input):
if model_name == 'resnet_50':
from resnet_50.model import load_model
elif model_name == 'hrnet':
from hrnet.model import load_model
elif model_name == 'moblienet':
from mobilenet.model import load_model
model = load_model()
output = model(input)
return output
这种写法存在下面的两个问题:
- 写法很冗余, N个模型的话需要添加2N条语句
- 新增模型时需要修改调用处的代码,添加对应的import语句,不符合模块化的要求。
import importlib
def run(model_name, input):
load_model = importlib.import_module('load_model', package='{}.model'.format(model_name))
model = load_model()
output = model(input)
return output
注意:importlib.import_module('load_model', package='{}.model'.format(model_name)),
为什么'load_model'没有相对路径的.,解释如果是package里面的函数就不需要加点,如果是package下面的文件就需要加点
5.matplotlib
Matplotlib 通常与 NumPy 和 SciPy(Scientific Python)一起使用
-
pyplot 是 Matplotlib 的子库,提供了和 MATLAB 类似的绘图 API。
-
pyplot 是常用的绘图模块,能很方便让用户绘制 2D 图表。
-
pyplot 包含一系列绘图函数的相关函数,每个函数会对当前的图像进行一些修改,例如:给图像加上标记,生新的图像,在图像中产生新的绘图区域等等。
-
使用的时候,我们可以使用 import 导入 pyplot 库,并设置一个别名
plt:
import matplotlib.pyplot as plt
以下是一些常用的 pyplot 函数:
-
plot():用于绘制线图和散点图# 画单条线 plot([x], y, [fmt], *, data=None, **kwargs) # 画多条线 plot([x], y, [fmt], [x2], y2, [fmt2], ..., **kwargs)参数说明:
- x, y:点或线的节点,x 为 x 轴数据,y 为 y 轴数据,数据可以列表或数组。
- fmt:可选,定义基本格式(如颜色、标记和线条样式)。
'[marker][line][color]' - **kwargs:可选,用在二维平面图上,设置指定属性,如标签,线的宽度等。如标记关键字参数marker
颜色字符:'b' 蓝色,'m' 洋红色,'g' 绿色,'y' 黄色,'r' 红色,'k' 黑色,'w' 白色,'c' 青绿色,'#008000' RGB 颜色符串。多条曲线不指定颜色时,会自动选择不同颜色。
线型参数:'‐' 实线,'‐‐' 破折线,'‐.' 点划线,':' 虚线
标记字符:'.' 点标记,',' 像素标记(极小点),'o' 实心圈标记,'v' 倒三角标记,'^' 上三角标记,'>' 右三角标记,'<' 左三角标记...等等。
配合的函数:
- 设置标题:
plt.title() - 设置x轴和y轴的标签:
plt.xlabel(),plt.ylabel() - 显示图片:
plt.show()
绘制多图:subplot()
subplot(nrows, ncols, index, **kwargs)
函数将整个绘图区域分成 nrows 行和 ncols 列,然后从左到右,从上到下的顺序对每个子区域进行编号 1...N ,左上的子区域的编号为 1、右下的区域编号为 N,编号可以通过参数 index 来设置。
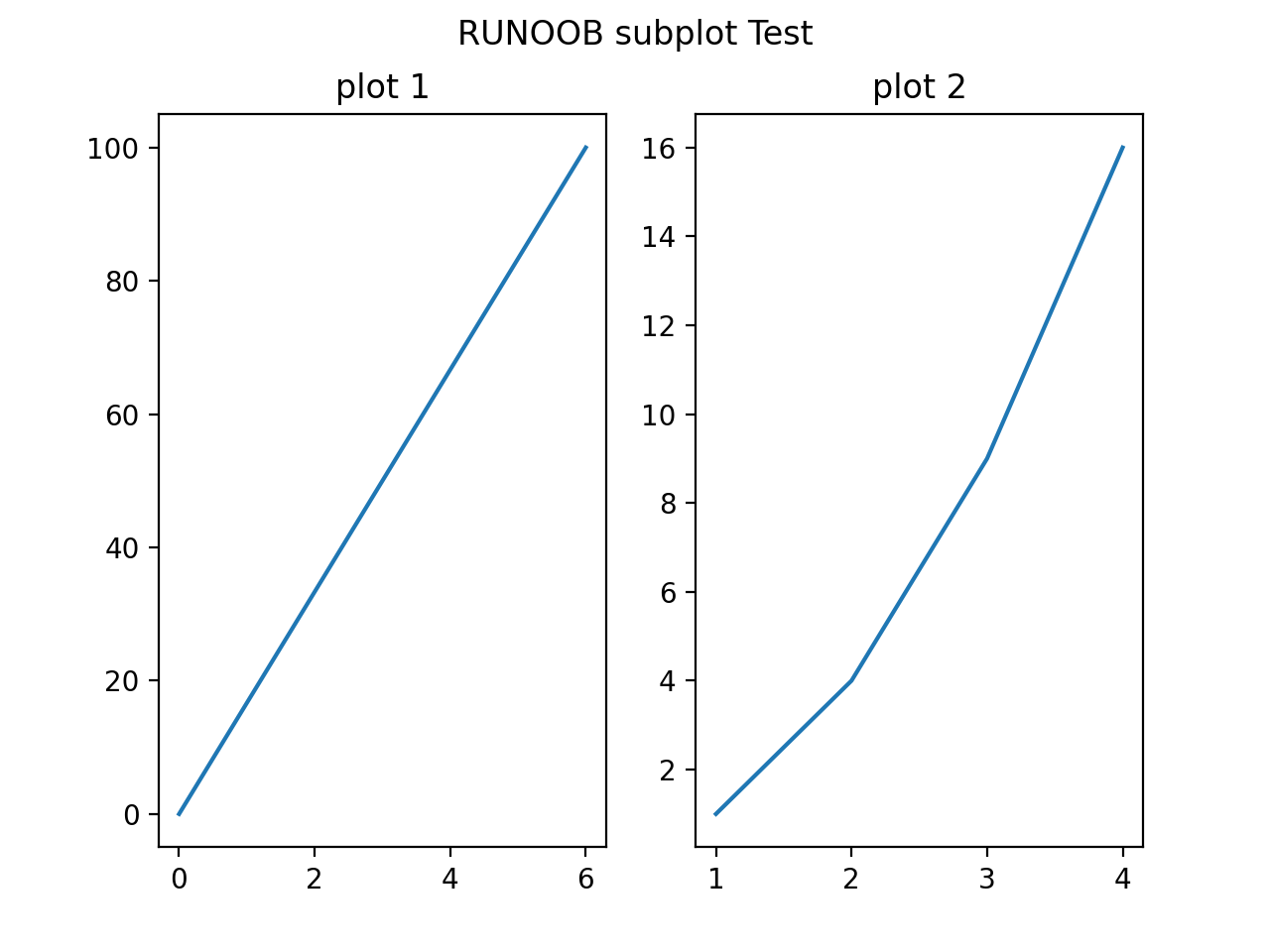
示例:
import matplotlib.pyplot as plt
import numpy as np
#plot 1:
xpoints = np.array([0, 6])
ypoints = np.array([0, 100])
plt.subplot(1, 2, 1)
plt.plot(xpoints,ypoints)
plt.title("plot 1")
#plot 2:
x = np.array([1, 2, 3, 4])
y = np.array([1, 4, 9, 16])
plt.subplot(1, 2, 2)
plt.plot(x,y)
plt.title("plot 2")
plt.suptitle("RUNOOB subplot Test")
plt.show()
- plotNum = 1, 表示的坐标为(1, 1), 即第一行第一列的子图。
- plotNum = 2, 表示的坐标为(1, 2), 即第一行第二列的子图。
scatter():用于绘制散点图bar():用于绘制垂直条形图和水平条形图hist():用于绘制直方图pie():用于绘制饼图imshow():用于绘制图像subplots():用于创建子图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号