Adaptive Multi-Lane Detection Based on Robust Instance Segmentation for Intelligent Vehicles
论文名:
Adaptive Multi-Lane Detection Based on Robust Instance Segmentation for Intelligent Vehicles
基于鲁棒实例分割的智能车辆自适应多车道检测
关键字:
自适应预测+余弦度量+实例分割+车道线检测。
研究问题:
行文结构梳理:
1. Introduction
车道检测算法有两种:传统方法+深度学习方法
传统方法:对计算要求不高,但不能处理复杂场景。
深度学习方法,在复杂场景下实现了良好表现。
- 现有的无锚深度模型将实例提取任务当做多类目标检测,从而要求固定车道数和预定于车道类别。
- 车道预定义将在变道的过程中使模型困惑从而无法处理

- 之前基于实例聚类或者锚的模型不需要预定义车道数,但需要很多的计算资源在后处理过程或复杂的训练过程(NMS)
- 基于锚的方法需要在特征图的不同位置设置详尽的锚,这个工作耗时、无效并在训练或测试阶段,需要额外的非差分后处理
作者专注于无锚检测,并提出了一种新颖的基于中心的实例分割方法,用于自适应车道实例检测。该方法动态确定车道数量,并应用余弦边距损失(LCML)增强前景提取的鲁棒性。该方法可以高效、准确地提取车道实例,无需事先确定车道类别,增强了车道检测的鲁棒性和适应性。
作者工作的贡献:
- 提出了结合车道中心估计的无锚点车道实例分割方法,有效提取车道实例,增强了实例分割的效率和鲁棒性
- 将基于中心的车道检测方法与现有方法在一系列基准数据集上进行了评估和比较,证明了该方法在车道检测任务中具有鲁棒性和适应性
- 应用余弦边缘损失-LCML 来修改分割分支的目标函数,这使得网络能够为前景分割提取更多的判别性特征。
2. Related Work
将现有车道检测算法分成两类:传统方法+基于深度学习
A. 手工特征的传统方法
- 传统方法不使用深度神经网络,检测性能主要依赖手工设计的特征的稳健性。
- 一些传统方法使用基于边缘的特征提取器,比如Canny边缘检测算法,但边缘地图常常受到各种噪声的干扰。
- 许多方法提出了增强车道标记特征的方案,例如使用线性判别分析、设计分段线性拉伸函数以增强ROI的对比度等方法。
- 先验几何信息有助于消除噪声,如利用平滑性原则提出的两阶段特征提取方法。
- 引入高级先验信息,比如消失点约束和顺序信息,以提高检测的鲁棒性。
- 最终采用Hough变换、RANSAC或CRF等算法来拟合提取的特征与各种车道模型。
B. 基于深度学习的方法
- 分类深度学习方法:
锚点无关结构(anchor-free structure): 诸如VPG-Net、SCNN、EL-GAN、ERFnet等模型,这些模型不需要预先定义车道类别或数量,但大多需要事先确定车道数量,这使得在车道和车辆相对位置不明确的情况下表现不稳定,如车道变换的场景。
锚点基础结构(anchor-based structure): 包括3D-LaneNet、LineCNN、PointLaneNet等模型,这些模型利用预定义的锚点作为先验信息来提取车道实例。然而,锚点设计在不同特征图位置上是低效且需要额外的非微分后处理。 - 问题与解决方案:
锚点无关模型的局限性: 这些模型对车道实例的预定义要求使其在车道与车辆相对位置不明确的情况下表现不稳定,特别是在车道变换场景下。
锚点基础方法的问题: 设计在特征图不同位置的锚点是低效的,这需要额外的后处理,并且降低了训练和测试的速度。 - 提出的解决方案:
提出了一种高效的无锚点实例分割方法: 该方法专注于适应性车道实例检测。相较于使用锚点的方法,此提出的方法旨在提高效率和稳健性。
3. Methodology
整体框架:
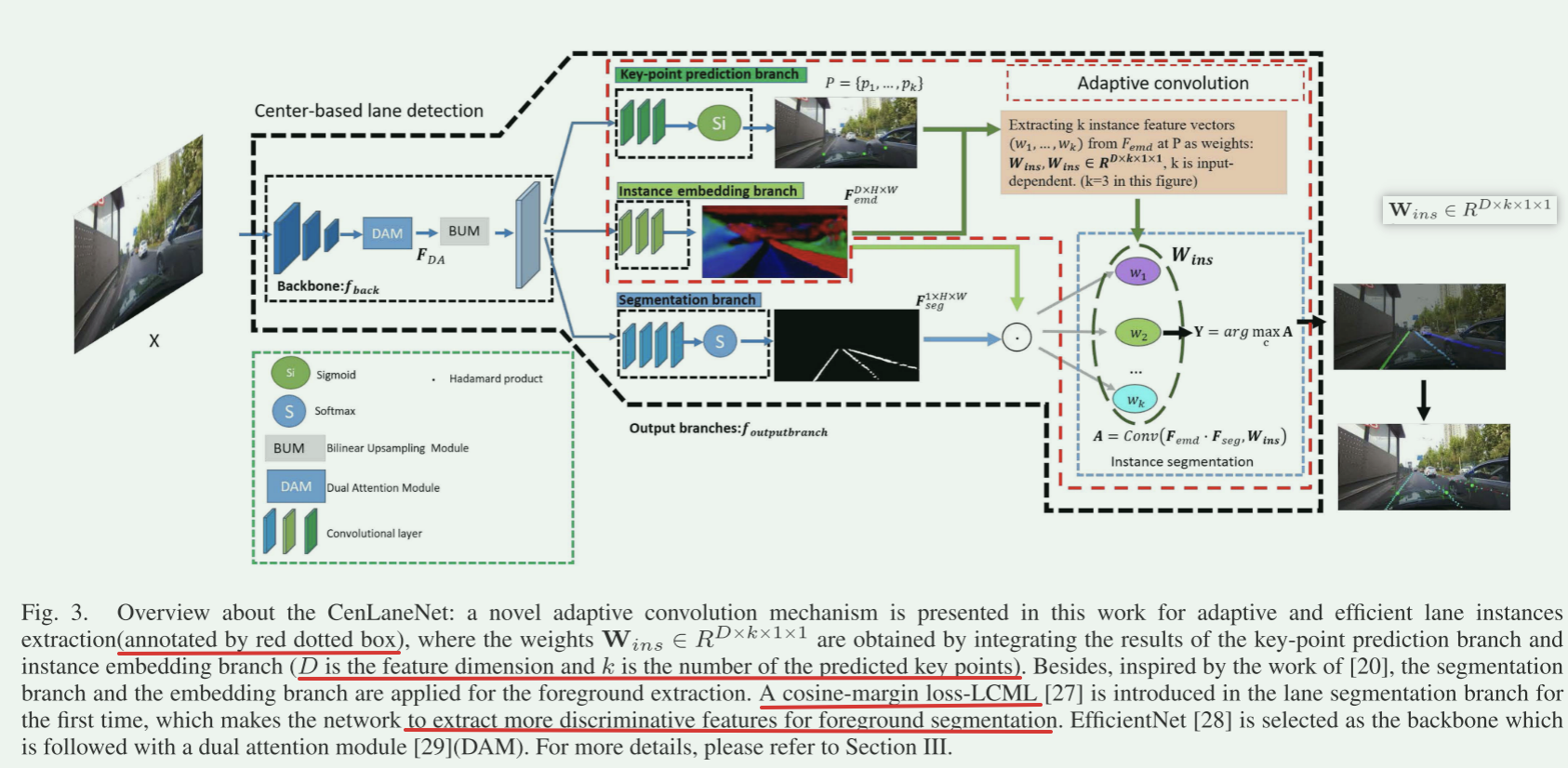
包括关键点预测分支、分割分支和实例嵌入分支。
算法一:展示了主要步骤:

A. 特征提取
- 输入图像:\(X\in R^{C_{1}×H_{1}×W_{1}}\)
- X通过骨干网络选取:EfficientNetb6(\(f_{back}表示\))
- 特征图输出:\(Fb\in R^{C_{2}×H_{2}×W_{2}}\)
- 通过DAM :dual attention module
- DAM输出:\(F_{DA}\)
- 通过BUM:Bilinear Upsampling module 双线性上采样模块
- 然后送到关键点预测分支、分割分支和实例嵌入分支
以上就是Section A的步骤
DAM:Dual attention module双注意力模块
作用:对特征的空间和通道相互依赖性进行建模。
组成:位置注意力模块(PAM)+通道注意力模块(CAM)
图例: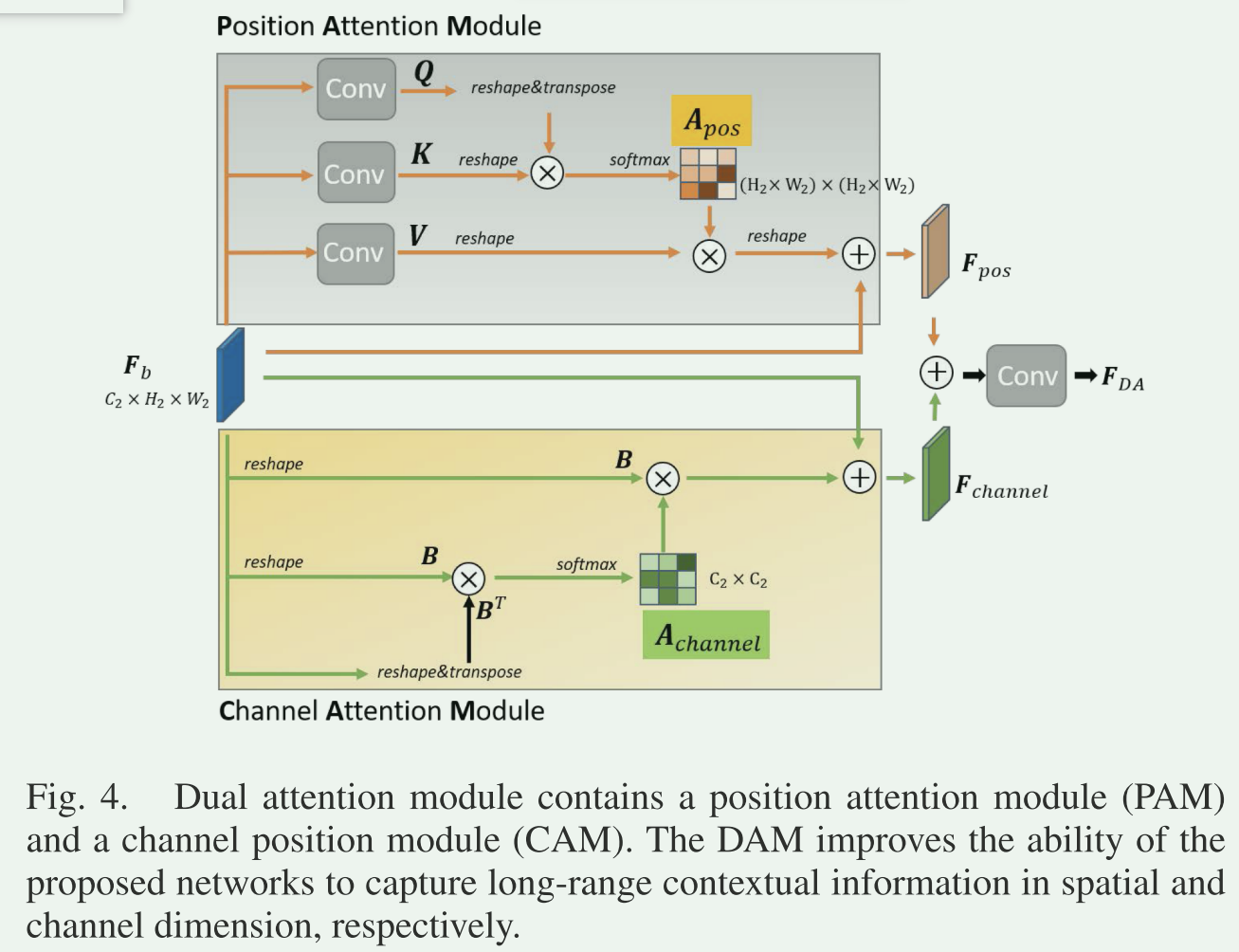
具体形式:
- 特征图输出作为DAM的输入
- 在PAM模块:
\(F_b\)分别经过三个卷积层,生成三个特征图Q,K,V
Q,K,V reshape成\(R^{C_{2}×(H_{2}W_{2})}\)的矩阵
注意力图\(A_{pos}\)可表示成:\(A_{pos}=softmax(Q^{T}K),A_{pos}\in R^{(H_{2}W_{2})×(H_{2}W_{2})}\)
PAM的输出\(F_{pos}\)可表示成:\(F_{pos}=Re(VA_{pos})+F_{b},F_{pos}\in R^{C_{2}×H_{2}×W_{2}}\) - 在CAM模块:
\(F_b\)经过reshape成B,B是\(R^{C_{2}×(H_{2}W_{2})}\)的矩阵
注意力图\(A_{channel}\)可表示成:\(A_{channel}=softmax(BB^{T}),A_{channel}\in R^{C_{2}×C_{2}}\)
CAM的输出\(F_{channel}\)可表示成:\(F_channel = Re(A_{channel}B)+ Fb,F_{channel}\in R^{C_{2}×H_2×W_2}\) - DAM输出
DAM的输出\(F_{DA}\)表示成:\(F_{DA}=conv(F_{pos}+F_{channel})\).
关键点预测分支(key-point prediction branch):定位车道中心位置
实例嵌入分支(Instance embedding branch):编码实力特征以便通过余弦相似度区分不同车道实例
分割分支(segmentation branch):提取前景像素
诠释:
嵌入实例分支:
作用:这个分支负责对图像中的实例进行编码,以便能够区分不同的实例。它生成实例特征嵌入(例如,每条车道线、每个车辆等)。
功能:通过该分支,模型学习将像素级别的信息映射到实例特征空间中,使得同一实例内的像素具有相似的嵌入特征,不同实例之间的特征有较大的差异。
分割分支:
作用:用于图像语义分割,将图像中的不同区域进行像素级别的分类,例如将道路、车辆、行人等区域分割开来。
功能:生成图像中每个像素的类别预测,例如预测哪些像素属于车道线、哪些属于车辆等。
关键点预测分?支:
作用:用于预测关键点或中心点,这些点可能对于实例的编码和分割非常重要。
功能:提供了实例分割和分类所需的中心点或关键点位置,作为实例特征提取和最终像素级别分类的依据。
这三个分支在整个系统中协同工作。嵌入实例分支提供了对实例的编码特征,分割分支进行像素级别的分类,而关键点预测分支则提供了关于实例位置和特征的信息。整合这些分支的结果,模型能够进行像素级别的实例分类和分割。这种设计使得模型可以学习到实例级别的特征,并能够准确地将图像中的不同实例进行分类和分割。
B. 中心提取
关键点预测分支
特征图\(F_{cen}=Sigmoid(conv_{cen}^2(conv_{cen}^1(fc_{cen}^1(BUM(F_{DA})))))\)
其中“fc”表示全连接层(或1 × 1卷积层)
“conv”表示(卷积+relu+批量归一化)操作
“BUM”是双线性上采样模块
The loss function lcen for training key point prediction branch is as follows
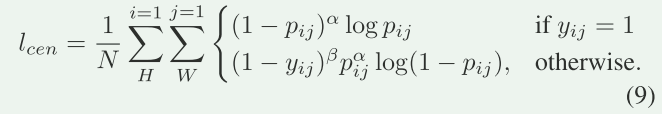
\(p_{ij}\)是\(F_{cen}\in R^{1×H×W}\)在(i,j)处的输出概率
α和β是焦点损失的超参数,分别设置为4和2
N(N =H×W)是\(F_{cen}\)的像素总数。
高斯模糊后,由关键点映射图 \(P\in {0,1}^{H×W}\)给出真实值y
关键点数量问题:
首先,使用高斯模糊对输入的二值化热图(heatmap)F进行处理。关键点检测分支会从热图F中输出具有更强响应的前K个位置,这些位置被假定是实际道路上车道的数量之上(K通常设置为20)。然而,在实际道路上可能会出现多个候选中心点位于同一车道的情况,因此算法提供了一种高效的非极大值抑制(NMS)算法,用于抑制重复的中心点。
算法二:非极大抑制

算法内容:根据实验数据构建特征矩阵\(F\in R^{K×D}\),这个矩阵F由K个D维的归一化特征向量\(\{w_{i},i=1,..,K \}\)组成,这些向量是从\(F_{emd}\)中提取的。然后通过计算特征矩阵F的转置与自身的乘积得到一个亲和矩阵A = \(FF^T\)。在这个亲和矩阵A中,相似度大于δ的元素被认为属于同一个实例。对于每个实例,从\(F_{cen}\)中选择具有最高响应值的点作为关键点P = {p1,...,pk},其中k是实例的数量。
C.基于中心实例分割

解释:它结合了三个输出分支的结果,通过在 \((F_{seg}⋅F_{emd})\)上应用自适应卷积操作来将前景像素分成不同的实例。这个卷积操作使用的权重可以根据预测的关键点位置 \(P\) 动态提取自 \(F_{emd}\)
方案核心思想:通过测量每个像素与每个实例的提取特征之间的特征距离,来确定每个像素属于哪个实例。像素特征通过实例嵌入分支进行编码,预测的中心\(P\)被应用于从\(F_{emd}\)中对应位置提取每个实例的特征。
文章中使用余弦相似性损失来训练实例嵌入分支。给定k个中心点,将\(\{w_{1},...,w_{k} \}\)表示为k个实例特征,x是一个像素的特征,y表示该像素属于哪个实例。
实例分类可以用以下公式表示:
公式(10)可以通过一个1×1卷积操作重塑,适用于图像计算。从\(F_{emd}\)中在预测的中心位置P处提取k个归一化特征向量\(\{w_{1},...,w_{k} \}\).然后将提取的特征\(\{w_{1},...,w_{k} \}\)连接起来生成\(W_{ins}\in R^{D×k×1×1}\):\(W_{ins}=concatenate(\{w_{1},...,w_{k}\})\)
接下来对\(W_{ins}\)和\((F_{seg}·F_{emd})\)进行卷积操作,并通过argmax决定每个像素属于哪个实例:

公式 (12) 中的 c 表示按通道进行比较。
为什么$W_{ins}$和$(F_{seg}·F_{emd})$进行卷积操作,能决定像素的实例归属?
实例特征向量的归一化,并且连成一个张量即Wins;通过Wins与\((F_{seg}·F_{emd})\)进行卷积,为每个像素生成与实例数k相关的置信度(表示像素与每个实例之间的相似性)。
D. 分割和实例嵌入
- 前景分割
目标是识别图像中的前景区域,将其与背景区域分开
- 通过卷积结构获得前景分割图:
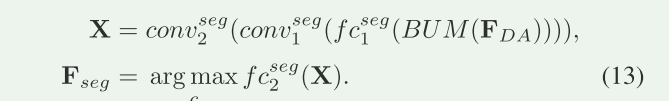
\(fc_{2}^{seg}的权重W=concat{w_n,w_p}\),wn为背景类别,wp为前景类别;
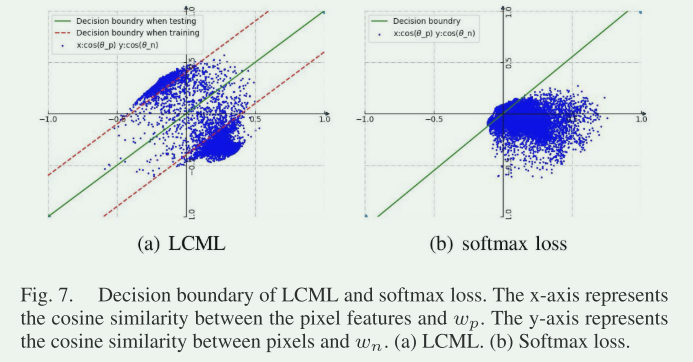
传统上,分割网络常使用 softmax 损失。但是在这里提到,softmax 损失的决策边界可能不够具有辨别性。
所以为了更好地训练分割网络,选择了 LCML(Large Margin Cosine Loss)作为替代。LCML 用于训练分割网络,这个损失函数能够帮助网络学习更具区分性的特征。
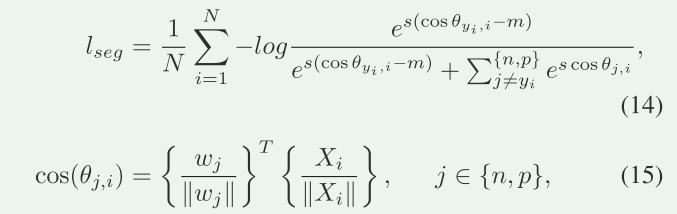
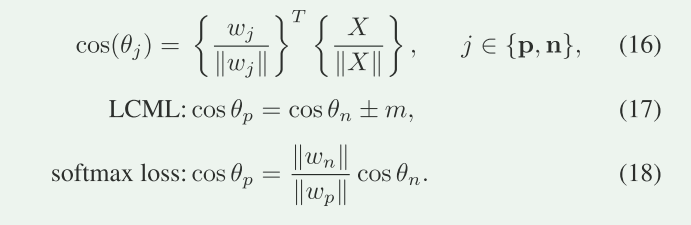
cos(θ j,i) 表示特征向量之间的余弦相似度,m是余弦相似度用于最大化决策边界的余弦边缘。
cos(θj) 表示根据不同的损失函数(LCML 或 softmax loss)计算出的决策边界。
损失结果对比
2.使用余弦相似性的实例嵌入
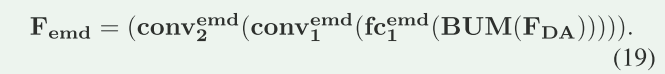
余弦相似度损失函数:
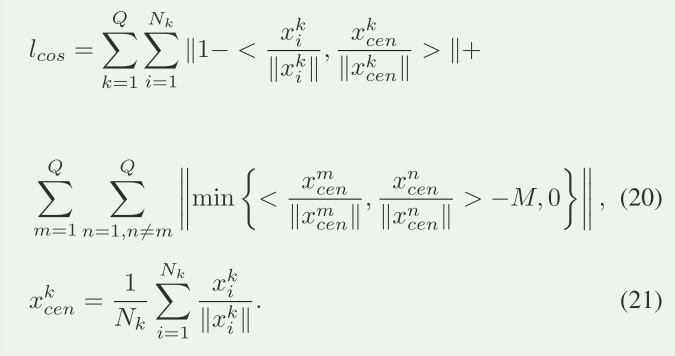
最后,针对整个 CenLaneNet 提出了一个组合损失函数 L,由分割损失 \(l_{seg}\)、余弦相似性损失 \(l_{cos}\)和其他特定损失 \(l_{cen}\)组成。这些损失函数以不同的权重系数 \(α_0、α_1\)和\(α_2\)组合在一起。在这里,这些系数已经被设定为特定的值,用于平衡各种损失函数对整体模型的训练所起的作用。
CenLaneNet结构:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号