灵感如滔滔江河,奔流不息~
多看看好文章:
利用相似(similarity)和差异(difference)去理解现实世界的高级特征
a model trained on "source dataset" and tested on the "target dataset".
from wiki:Domain adaptation is the ability to apply an algorithm trained in one or more "source domains" to a different (but related) "target domain". Domain adaptation is a subcategory of transfer learning. In domain adaptation, the source and target domains all have the same feature space (but different distributions); in contrast, transfer learning includes cases where the target domain's feature space is different from the source feature space or spaces.
Domain adaptation
Overview:
Domain adaptation is a field of computer vision, where our goal is to train a neural network on a source dataset and secure a good accuracy on the target dataset which is significantly different from the source dataset.
To get a better understanding of domain adaptation and it’s application let us first have a look at some of its use cases.:
-
We have a lot of standard datasets for different purposes, like GTSRB for German traffic sign recognition, LISA and LARA dataset for traffic light detection, COCO for object detection, and segmentation etc. However, if you want a neural network to work nicely for your task e.g. traffic sign recognition on Indian Roads, then you will have to first collect all types of images of Indian Roads, and then do the labeling for those images, which is a laborious and time taking task. Here we can use domain adaptation, as we can train the model on GTSRB (source dataset) and test it on our Indian traffic sign images (target dataset).
-
There are many cases where it is difficult to gather datasets, which have all the required variations and diversity to train a robust neural network. In this case, with the help of different computer vision algorithms, we can generate large synthetic datasets that have all the variations we require. Then train the neural network on the synthetic dataset (source dataset) and test it on real-life data(target dataset).
FCN:全卷积网络
全卷积神经网络可以使得网络模型可以输入任意大小的图片
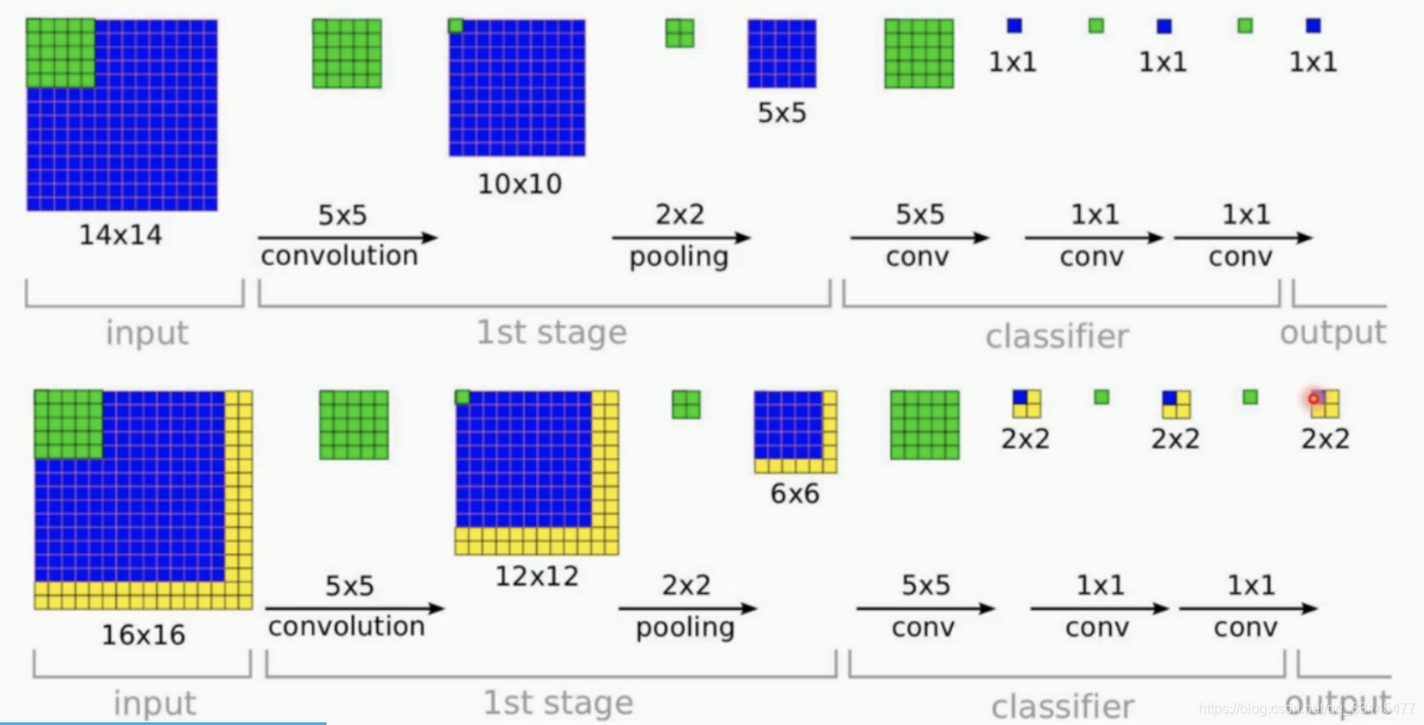
四、全卷积网络FCN详细讲解(超级详细哦
1×1卷积的作用
具体内容:
1×1卷积核的作用:
增加网络深度(增加非线性映射次数)升维/降维(维度并没有改变,改变的只是 height × width × channels 中的 channels 这一个维度的大小)跨通道的信息交互减少卷积核参数(简化模型)
具体解释:
1. 增加网络深度
通常一个卷积过程包括一个激活函数,比如sigmoid 和RELU;
通过下图的一次卷积:
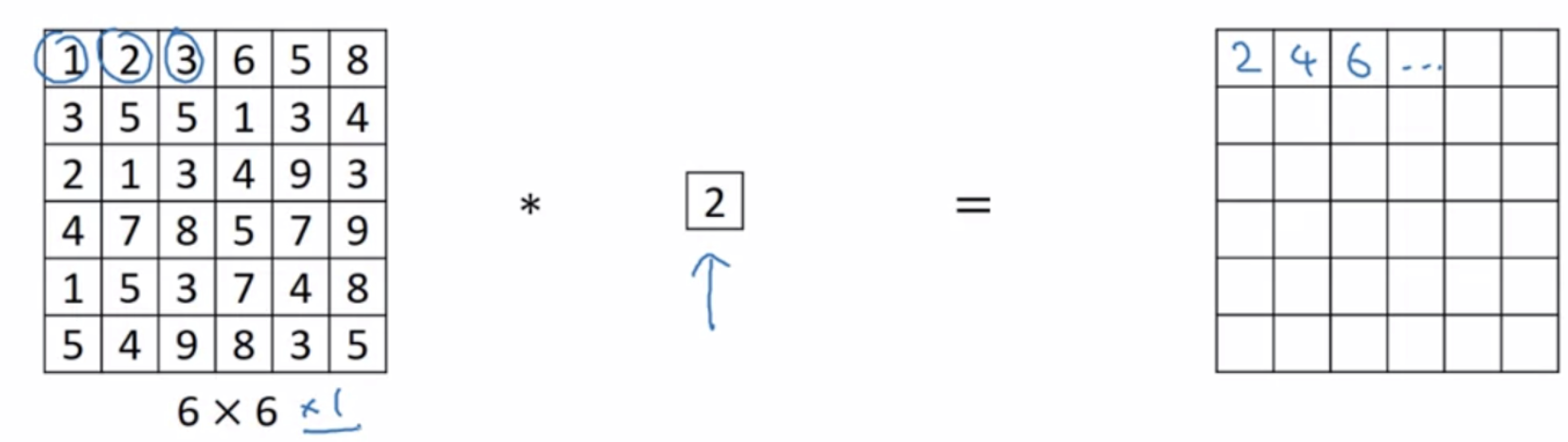
要明白:
- 1×1卷积核虽小,但增加一层卷积,网络深度会增加。
- 1×1卷积核,可以保持feature map尺度不变(即不损失分辨率)的前提下,大幅增加非线性特性(利用后接的非线性激活函数),把网络做的很深。并且1×1卷积核的卷积过程相当于全连接的计算过程,通过加入非线性激活函数,可以增加网络的非线性,使网络可以表达更复杂的特征。
问题:增加网络深度有什么好处?非要用1×1卷积吗?其他卷积不可以吗?
- 我们知道卷积核越大,感受野越大,它生成的feature map上单个节点的感受野就越大,随着网络深度的加深,越靠后的feature map 上的节点感受野也越大。此时,特征也越来越抽线。但是,有时候我我们想在不增加网络感受野的情况下,让网络加深,为了就是引入更多的非线性。此时,1×1卷积核正好可以保持感受野,同时增加网络的深度。
1×1卷积核,在输入不发生尺寸的变化下,引入更多的非线性,这将增加网络的表达能力
2. 升维/降维
这里的升维/降维是指通道数的变化。我们通过改变卷积核的数量来改变卷积后feature map 的通道的channels来实现升维/降维效果。这样原本的数据量进行增加或减少。
如图所示:
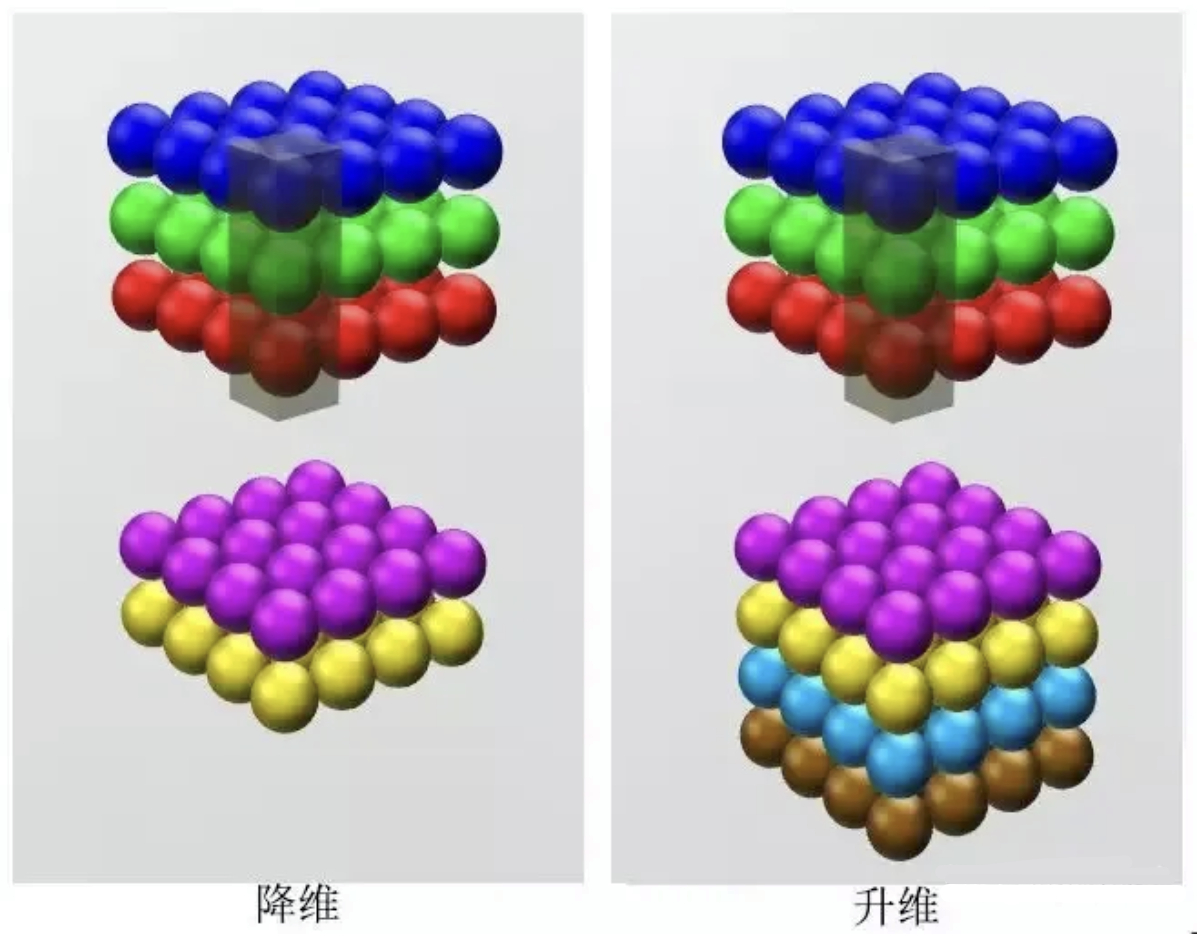
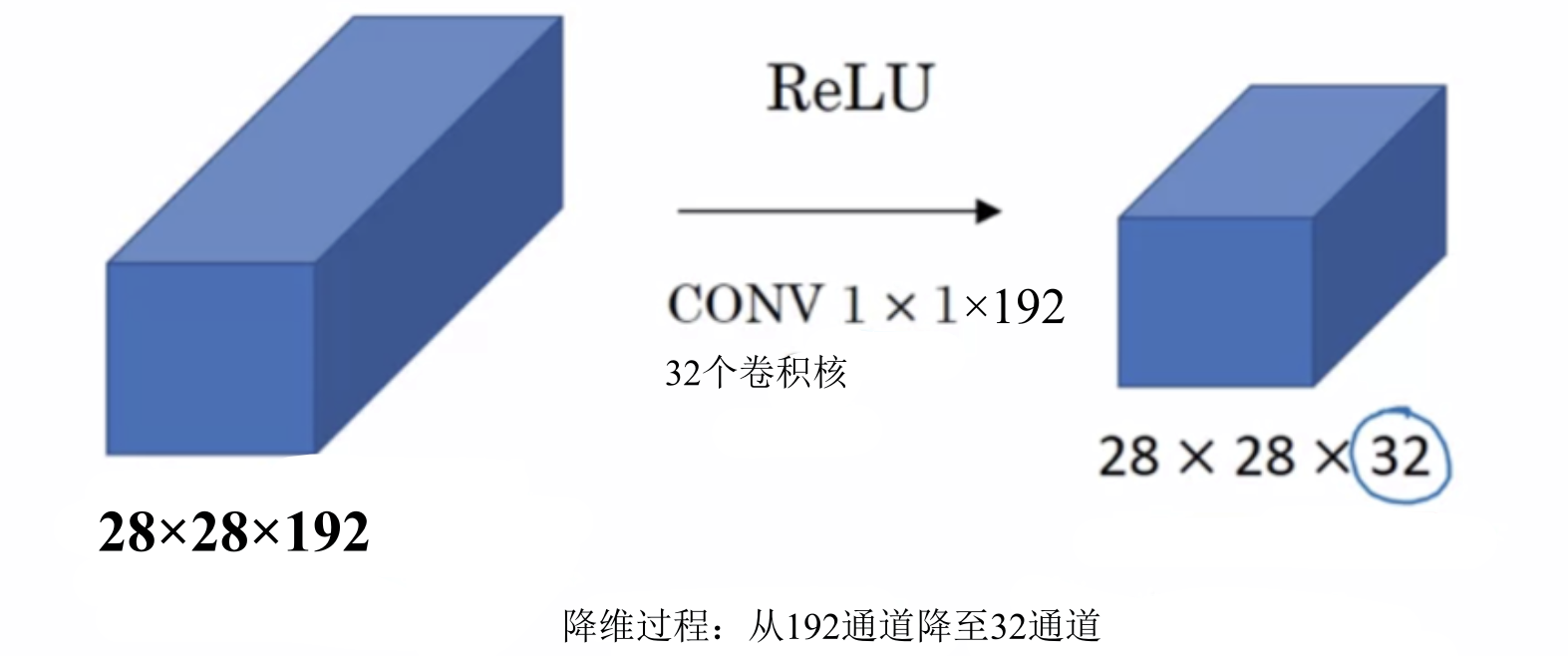
在我们只想改变通道数的情况下,大于1×1的卷积核无疑会增加计算的参数量。当只想单纯的提升或降低特征图的通道,选用1×1卷积核最合适,因为1×1卷积核会使用更少的权重参数量
3. 跨通道的信息交互
例子:使用1x1卷积核,实现降维和升维的操作其实就是channel间信息的线性组合变化,3x3,64channels的卷积核后面添加一个1x1,28channels的卷积核,就变成了3x3,28channels的卷积核,原来的64个channels就可以理解为跨通道线性组合变成了28channels,这就是通道间的信息交互。
注意:只是在channel维度上做线性组合,W和H上是共享权值的sliding window
4. 降低计算量
参考:深度学习基础学习-1x1卷积核的作用(CNN中)
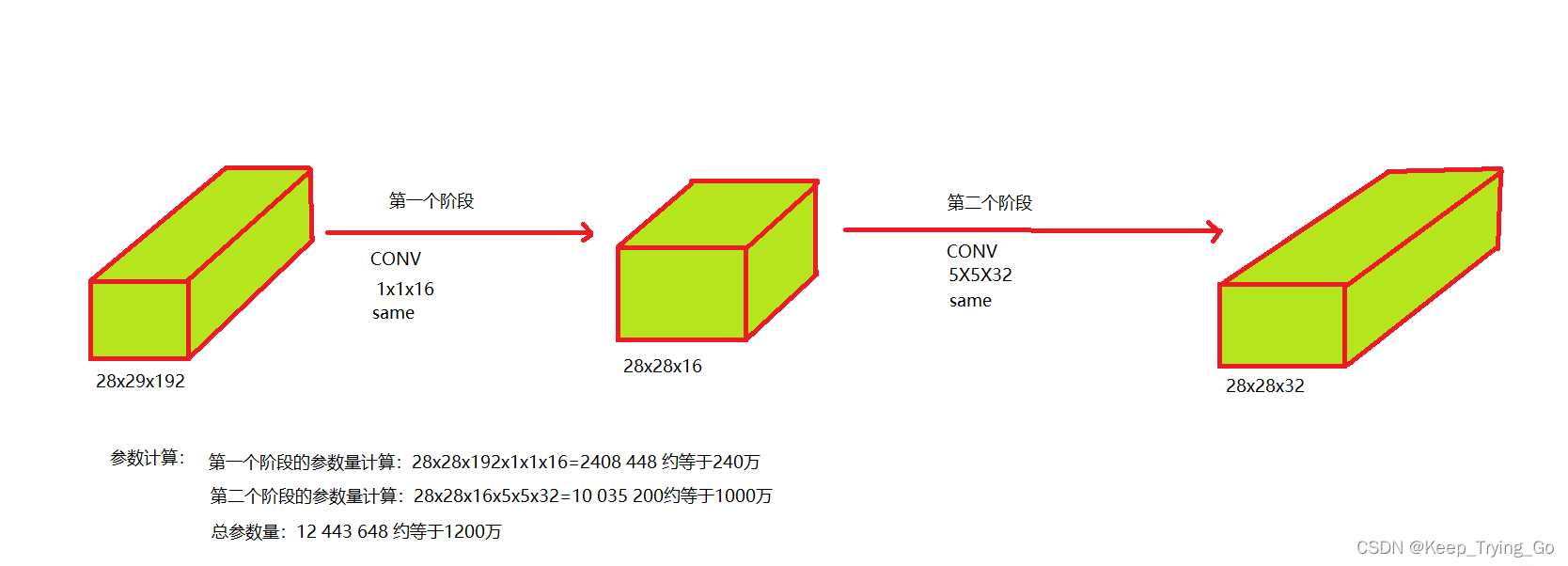
- 不使用1x1卷积核
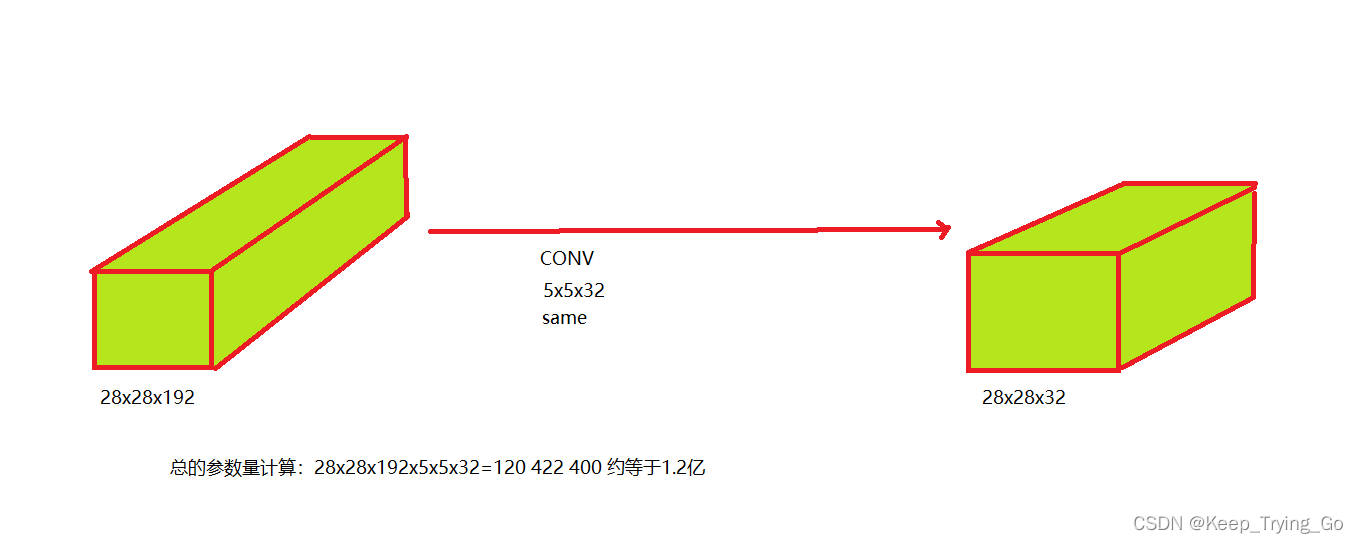
- 使用1x1卷积核
3.其他应用:
- GoogLeNet的3a模块
- Resnet
参考文章:
GAN(Generative adversarial network)
概念:
GAN:生成对抗网络是一种深度学习架构,该架构训练两个神经网络互相竞争,从而从给定的训练数据集生成更真身的新数据。比如,您可以从现有图像数据库生成新图像,也可以从歌曲数据库生成原创音乐。
GAN 之所以被称为对抗网络,是因为该架构训练两个不同的网络并使其相互对抗。一个网络通过获取输入数据样本并尽可能对其进行修改来生成新数据。另一个网络尝试预测生成的数据输出是否属于原始数据集。换句话说,预测网络决定生成的数据是假的还是真的。系统会生成更新、改进版本的假数据值,直到预测网络不再能够区分假数据值和原始数据值。
应用:
生成图像:
生成对抗网络通过基于文本的提示或修改现有图像来创建逼真的图像。它们可以协助在视频游戏和数字娱乐中创造逼真、身临其境的视觉体验。
GAN 还可以编辑图像,例如将低分辨率图像转换为高分辨率图像,或将黑白图像转换为彩色图像。该工具还可以为动画和视频打造逼真的面部、角色和动物。
为其他模型生成训练数据
在机器学习(ML)中,数据增强通过使用现有数据创建数据集的已修改副本来人为地增加训练集规模。
可以使用生成模型进行数据增强,以创建具有现实世界数据所有属性的合成数据。例如,机器学习可以生成欺诈性交易数据,然后使用这些数据训练另一个欺诈检测机器学习系统。这些数据可以教导系统准确区分可疑交易和真实交易。
补全缺失的信息
有时,您可能希望生成模型能够准确地猜测并补全数据集中的一些缺失信息。
例如,您可以通过了解地表数据与地下结构之间的相关性来训练 GAN 生成地下表面(次表面)的图像。通过研究已知的次表面图像,GAN 可以使用地形图创建用于能源应用的新图像,例如地热测绘或碳捕集和储存。
根据 2D 数据生成 3D 模型
GAN 可以根据 2D 照片或扫描的图像生成 3D 模型。例如,在医疗保健领域,GAN 将 X 射线和其他身体扫描相结合以创建逼真的器官图像,将其用于手术计划和模拟。

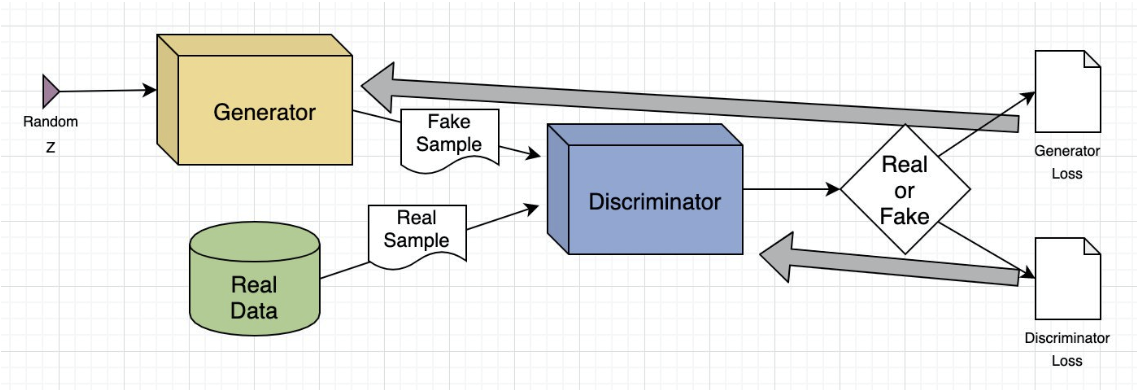
运作原理:
生成对抗网络系统包括两个深度神经网络 — 生成者网络和辨别者网络。这两个网络在对抗性游戏中训练模型,其中一个网络尝试生成新数据,另一个网络尝试预测输出是虚假数据还是真实数据。
从技术上讲,GAN 的工作原理如下。复杂的数学方程式构成整个计算过程的基础,以下是其简单的概述:
- 生成者神经网络分析训练集并识别数据属性
- 辨别者神经网络分析初始训练数据并独立区分属性
- 生成者通过向某些属性添加噪点(或随机变化)来修改某些数据属性
- 生成者将修改后的数据传递给辨别者
- 辨别者计算生成的输出属于原始数据集的概率
- 辨别者为生成者提供了一些指导,以减少下一个周期中的噪点向量随机化
生成者尝试最大限度地提高辨别者出错的可能性,而辨别者会尝试最大限度地降低出错的可能性。在训练迭代中,生成者和辨别者会不断演变并相互对抗,直到它们达到平衡状态。在平衡状态下,辨别者无法再识别合成数据。至此,培训过程结束。
For example:
GAN 训练示例
接下来用图像间转换中的 GAN 模型示例来情境化上述步骤。
假设输入图像是 GAN 尝试修改的人脸。例如,属性可以是眼睛或耳朵的形状。假设生成者通过在其上添加太阳镜来更改真实图像。辨别者会收到一组图像,其中一些是戴着太阳镜的真实人物,其他一些生成的图像则经过修改以包含太阳镜。
如果辨别者可以区分虚假图像和真实图像,则生成者会更新其参数以生成更不易辨别的虚拟图像。如果生成者生成的图像成功欺骗辨别者,则辨别者会更新其参数。在达到平衡之前,这种竞争会不断改善两个网络。
GAN类型
Vanilla GAN
这是基本的 GAN 模型,它在辨别者网络的反馈很少或根本没有反馈的情况下生成数据变化。对于大多数现实世界的使用案例,Vanilla GAN 通常需要增强。
有条件 GAN
有条件 GAN(cGAN)引入了条件性概念,可有针对性地生成数据。生成者和辨别者接收额外信息,通常是类标签或其他形式的调整数据。
例如,如果生成图像,则条件可能是描述图像内容的标签。调整可让生成者生成满足特定条件的数据。
深度卷积 GAN
深度卷积 GAN(DCGAN)认识到卷积神经网络(CNN)在图像处理中的强大功能,因此将 CNN 架构集成到 GAN 中。
在 DCGAN 中,生成者使用转置卷积来扩展数据分布,而辨别者使用卷积层对数据进行分类。DCGAN 还引入架构指南,以提高训练的稳定性。
超分辨率 GAN
超分辨率 GAN (SRGAN) 专注于将低分辨率图像放大到高分辨率。目标是将图像增强到更高的分辨率,同时保持图像质量和细节。
Laplacian Pyramid GAN(LAPGAN)通过将问题分为几个阶段来解决生成高分辨率图像的挑战。它们使用分层方法,其中多个生成者和辨别者在图像的不同比例或分辨率下工作。该过程从生成低分辨率图像开始,该图像的质量在渐进式 GAN 阶段中逐步提高。
此外还有,StyleGAN、CycleGAN 和 DiscoGAN,它们可以解决不同类型的问题。
算法过程:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号