论文:CCNet: Criss-Cross Attention for Semantic Segmentation
论文名:
CCNet: Criss-Cross Attention for Semantic Segmentation
语义分割的交叉关注
关键字
语义分割(semantic segmentation)+图注意力+交叉注意力网络+上下文模型
The source codes are available at Code.
研究问题:
目前先进的语义分割方法基于全卷积网络(FCN).
但是,由于固定的几何结构,FCN固有的受限于只提供小范围上下文信息的本地感受野,这反而对分割效率造成负面影响。
为了解决这个FCN局限,提出了一些方法:
基于膨胀卷积方法
1、Chen等人提出了一种基于多尺度膨胀卷积的空间金字塔池模型,用于上下文信息聚合;
2、Zhao等人进一步引入PSPNet与金字塔池模块捕获上下文信息;
基于膨胀卷积的方法,从周围的几个像素中收集信息,实际上不能生成密集的上下文信息。
基于池化的方法
同时,基于池化的方法以非自适应的方式聚合上下文信息,并且所有图像像素都采用同结构上下文提取过程,这不满足不同像素需要不同上下文依赖性的要求。
为了结合密集和像素级的上下文信息,出现了一些全连接图神经网络(GNN)方法
基于全连接图神经网络方法:用预估的全图上下文表示来增强传统的卷积特征
1、PSANet,通过预测的注意力地图学习聚合每个位置的上下文信息;
2、Non-local Networks,使用自注意力机制,这种机制能使任何位置的单一特征感知其他位置的特征,从而获得全图像的语境信息,也称基于自注意力的密集GAN;
基于GNN的non-local 神经网络需要产生大量的注意力图来测量各像素对的关系,造成高额的时间和空间复杂度\(O(N^{2})\)
为了解决上述问题
作者目标:
- 1、用多个连续稀疏连通图替代一般单稠密连通图,从而降低计算资源;
- 2、使用两个堆叠的交叉注意力模块的策略,大大降低时间和空间复杂度,从\(O(N^{2})\to O(N\sqrt(N))\)
之后:
1、对比Non-local方法和交叉注意力模块
2、递归交叉注意力模块流程
3、输入、输出都是卷积特征图,故可以插入到任何全卷积神经网络(FCN)
"Criss-Cross Network(CCNet)" :
Since the input and output are both convolutional feature maps, criss- cross attention module can be easily plugged into any fully convolutional neural network, named as CCNet, for learning full-image contextual information in an end-to-end manner.
研究方法:
新的交叉注意力模型用来获得它交叉路径上所有像素的语境信息;
通过进一步的递归操作,每个像素最终可以捕获整个图像的依赖关系;
类别一致性损失使交叉注意力模型产生区别性特征;
主要结论:
CCNet:具有如下特征;
- 对GPU更友好
- 高计算效率
- 最先进的性能
主要贡献:
1、在这项工作中,我们提出了一种新的纵横交错的注意力模块,可以利用它来捕捉上下文信息,从全图像的依赖关系,在一个更有效和有效的方式。
2、我们提出了类别一致性损失,它可以强制交叉注意模块产生更多的区分特征。
3、我们提出了CCNet,利用循环交叉注意力模块,在基于分割的基准测试中实现了领先的性能,包括Cityscapes,ADE20K,LIP,CamVid和COCO。
模型:
问题:
1、CCNet流程:
第一步:Criss-cross注意力模块收集其交叉路径上所有像素的上下文信息;
第二部:进一步递归操作,每个像素最终可以捕获完整图像额相关性信息;
第三步:category consistent 损失函数 使Criss-cross注意模块 生成更具有区分性的特征。
描述了CCNet,一种用于获取完整图像上下文信息的网络架构。它通过新颖的criss-cross attention模块以及递归操作,使每个像素能够理解整个图像的相关性信息,并通过一致性损失来加强特征的区分性。这种方法有助于改善图像处理任务中的性能。
行文结构梳理
Abstract:交叉注意力模型+递归操作+一致性损失|或者 递归交叉注意力模型+一致性损失函数
1、Introduction:目前语义分割结合了FCN,但受限在语境信息量太小反而降低分割精度。为了解决这个问题,提出了基于膨胀卷积+基于池化的方法,再写一写它们的缺点;
2、Related work
2.1 语义分割:
FCN-based methods:
Chen et al. and Yu et al.去除最后两个下采样层以获得密集预测,并利用扩张卷积来扩大感受野.
Unet,DeepLabv3+,MSCI,SPGNet,RefineNet 和DFN 采用编码器解码器结构,融合低级和高级层中的信息以进行密集预测。
scale-adaptive convolutions(SAC和deformable convolutional networks(DCN)方法改进了标准卷积算子,以处理对象的变形和各种尺度。
CRF-RNN和DPN使用图模型,即,CRF,MRF,用于语义分割。
AAF使用对抗学习来捕获和匹配标签空间中相邻像素之间的语义关系。
BiSeNet被设计用于实时语义分割。
DenseDecoder在级联架构上构建了功能级的远程跳过连接。
VideoGCRF使用密集连接的时空图进行视频语义分割。
RTA提出了基于区域的时间聚合,以充分利用视频中的时间信息。此外,一些工作集中在人工解析任务。
JPPNet将姿态估计嵌入到人类解析任务中。
CE2P提出了一个简单而有效的框架,用于计算上下文嵌入,同时保留边缘。
SANet使用具有规模注意力的并行分支来处理人类解析中的大规模变化。
2.2 上下文信息聚合:
聚合上下文信息以增强特征表示是语义分割常见做法
Deeplabv 2提出了一种空间金字塔池(ASPP),使用不同的膨胀卷积来捕获上下文信息。
DenseASPP将密集连接引入到ASPP中,以生成各种规模的特征。
DPC利用架构搜索技术来构建用于语义分割的多尺度架构。
Chen等人利用几个注意力掩码来融合来自不同分支的特征图或预测图。
PSPNet利用金字塔空间池来聚合上下文信息。
最近,Zhao等人提出了逐点空间注意网络,该网络使用预测注意图来指导上下文信息收集。
Auto-Deeplab利用神经架构搜索来搜索有效的上下文建模。
He等人提出了一种自适应金字塔上下文模块用于语义分割。
Liu等人利用递归神经网络(RNN)来捕获长期依赖关系。
使用图模型来对上下文信息建模
利用条件随机场(CRF)、马尔可夫随机场(MRF)等方法获取语义分割的长距离依赖关系。
Vaswani等人将自我注意力模型应用于机器翻译。
Wang等人提出了非局部模块,通过计算特征图上每个空间点之间的相关矩阵来生成巨大的注意力图,然后由注意力图引导密集的上下文信息聚合。
OCNet和DANet利用非本地模块来获取上下文信息。
PSA学习了一个注意力地图,以自适应和具体地聚合每个单独点的上下文信息。
Chen等人提出了基于图的全局推理网络,它通过在一个小图上进行图卷积来实现关系推理。
CCNet vs. Non-Local vs. GCN.:原文照搬吧,说的很直白
在这里,我们具体讨论GCN,Non-local Network和CCNet之间的差异。在上下文信息聚合方面,只有中心点可以通过GCN中的全局卷积滤波器从所有像素中感知上下文信息。相比之下,Non-Local Network和CCNet保证任何位置的像素都能感知所有像素的上下文信息。虽然GCN交替地将方形卷积运算分解为与CCNet相关的水平和垂直线性卷积运算,但CCNet采用交叉方式来获取上下文信息,这比水平垂直分离的方式更有效。此外,CCNet被提出来模仿非局部网络,通过更有效和高效的循环交叉注意力模块来获得密集的上下文信息,其中不相似的特征得到低的注意力权重,而具有高注意力权重的特征是相似的。GCN是一种传统的卷积神经网络,而CCNet是一种图形神经网络,其中卷积特征映射中的每个像素都被视为一个节点,并且节点之间的关系/上下文可以用来生成更好的节点特征。
2.3 图神经网络
我们的工作与深度图神经网络(GNN)有关。在图神经网络之前,图形模型,如条件随机场(CRF),马尔可夫随机场(MRF),被广泛用于对图像理解的长程依赖关系进行建模。受CNN成功的启发,大量的方法将图结构适应CNN。这些方法可以分为两个主要流,基于光谱的方法和基于空间的方法。拟议的CCNet属于后者。
3、Details of CCNet for semantic segmentation
大体流程:
- 介绍CCNet框架
- 2D交叉注意力模块捕获语境信息
- 对交叉注意力模块采取递归操作捕获更多语境信息
- 介绍一个判别损失函数来驱动RCCA学习类别一致性特征。
- 提出3D交叉关注模块,用于同时利用时间和空间上下文信息。
3.1 CCNet框架
Fig. 2. Overview of the proposed CCNet for semantic segmentation.
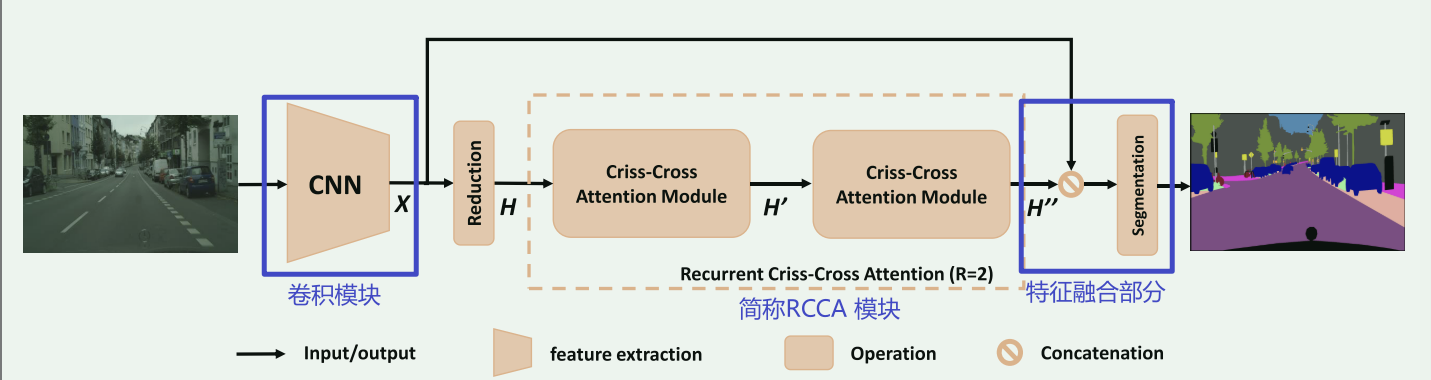
卷积模块:
1、一张输入图像通过一个深度卷积神经网络(DCNN)进行处理。这个神经网络以完全卷积的方式设计,意味着它可以处理不同尺寸的输入图像,并产生一个特征图X,其空间尺寸为 H×W。
2、为了保留更多的细节并高效地生成密集的特征图,他们在后续的卷积层中去掉了最后两次的下采样操作(通常是池化层),并使用了“膨胀卷积”(dilation convolutions)。这样做导致输出特征图X的宽度和高度变大,变为输入图像的1/8。
RCCA模块:
1、首先,对输入特征图 X 进行卷积操作,以减小维度,得到特征图 H。
2、特征图 H 被送入交叉关注模块(criss-cross attention module),以生成新的特征图 H',该特征图将上下文信息汇总在其交叉路径中的每个像素位置上。
3、特征图 H' 只包含水平和垂直方向上的上下文信息,这对于准确的语义分割来说可能不够强大。因此,为了获得更丰富和更密集的上下文信息,再次将特征图 H' 输入到交叉关注模块中,输出特征图 H''。这样,H''中的每个位置实际上收集了来自所有像素的信息。
4、两个交叉关注模块之前和之后共享相同的参数,以避免添加太多额外的参数。这种循环结构被称为“循环交叉关注”(Recurrent Criss-Cross Attention,RCCA)模块。
这个流程描述了一种在语义分割任务中使用的模块,通过多次应用交叉关注模块来获取更多的上下文信息,以提高分割的准确性。这种模块可以帮助神经网络更好地理解图像中的语义信息。
特征融合模块:
1、在获取了丰富的上下文特征地图H''之后,将其与本地表示特征地图X进行连接。这一步骤将从H''获得的丰富上下文信息与来自X的原始本地特征结合起来。
2、在连接之后,将一个或多个卷积层应用于组合后的特征地图。通常,这些层配备了批量归一化和激活函数,以增强特征融合过程。批量归一化有助于稳定和改善训练,而激活函数引入非线性到模型中。
3、这些卷积层的输出,代表了融合后的特征,然后传递到分割层。这个分割层负责进行像素级预测,可以包括将图像中的每个像素分类到不同的类别或分段中。
4、最终,分割层生成了最终的分割结果,这是模型对输入图像的预测。
这一过程涉及将丰富的上下文信息与本地特征相结合,然后使用卷积层和分割层进行图像分割任务的详细预测。
3.2 Criss-cross Attention
Fig. 3. The details of criss-cross attention module.
用于建模全图像依赖关系
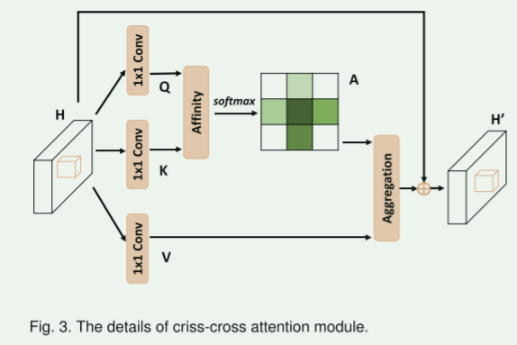
- 给定一个本地特征图H,其中H的尺寸为C×W×H,模块首先应用两个1×1卷积层在H上,生成两个特征图Q和K,分别记为{Q,K},尺寸为C'×W×H。这里C'表示通道数,通常会小于C以降低维度。
- 得到Q和K后,模块进一步生成一个注意力图A,A的尺寸为\(R^{(H+W-1))×(W×H)}\),通过Affinity操作。在Q的空间维度中的每个位置u,可以获得一个向量Qu。同时,也可以从K中提取与位置u在同一行或同一列的特征向量,形成一个集合Ωu,Ω(i,u)表示Ωu中的第i个元素.Affinity操作定义了特征Qu和Ω(i,u)之间的相关度,这被表示为d(i,u),D是d(i,u)的集合,大小为(H×W-1)×(W×H)
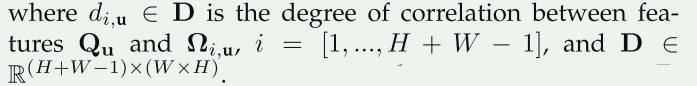
- 接着,应用softmax层在D上,通过通道维度计算注意力图A。
- 再应用一个1×1卷积层在H上生成特征V,V的尺寸为C×W×H,用于特征适应。在V的空间维度中的每个位置u,可以获得一个向量Vu,以及一个集合Φu,Φu是与位置u在同一行或同一列的特征向量的集合。上下文信息通过Aggregation聚合操作添加到本地特征H中,以增强像素级表示。

总之,这个模块用于捕获图像中像素级别的上下文信息,以提高特征表示的能力。它在水平和垂直方向上收集上下文信息,从而拥有广泛的上下文视野并有选择地汇聚上下文信息。这有助于更准确的图像语义分割。
3.3 Recurrent Criss-Cross Attention (RCCA)
- 尽管 criss-cross 注意力模块可以捕获水平和垂直方向上的上下文信息,但仍然缺少一个像素与其周围不在 criss-cross 路径上的像素之间的连接。为了解决这个问题,我们引入了一种基于 criss-cross 注意力的 RCCA(recurrent criss-cross attention)操作。
Fig. 4. An example of information propagation when the loop number is
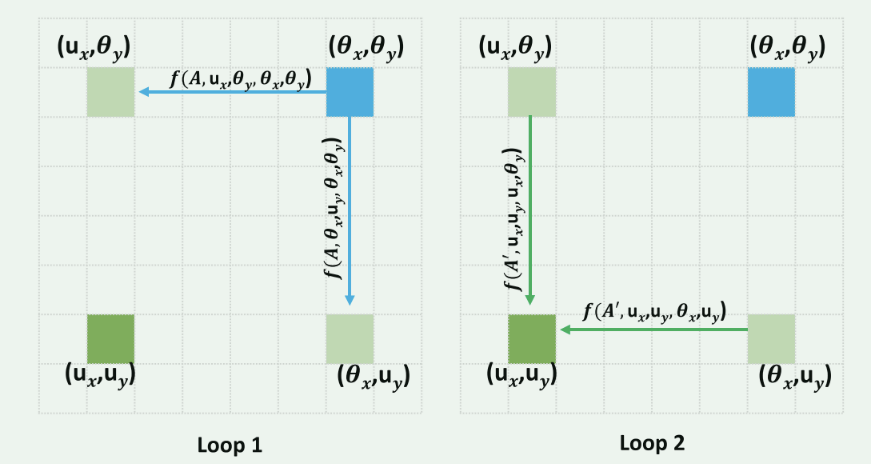
RCCA 模块可以展开成 R 个循环。在第一个循环中,criss-cross 注意力以从 CNN 模型中提取的特征图 H 作为输入,并输出具有相同形状的特征图 H',其中 H 和 H' 具有相同的形状。在第二个循环中,criss-cross 注意力以特征图 H' 作为输入,并输出特征图 H''。
在 R = 2 的情况下,RCCA 模块构建的特征图中任意两个空间位置之间的连接可以通过引入以下定义的函数 f 进行清晰和定量的描述。

参数解释:其中 \(u(ux, uy) \in R^{H×W}\)是 H 中的任意空间位置,\(u^{CC} (u_{x}^{CC},u_{y}^{CC})\in R^{H+W−1}\) 是位于u中心的criss-cross 结构中的位置。函数f实际上是从特征图中的位置对\((u^{CC},u)\in R^{(H+W-1)×(H×W)}\) 到注意力图 \(A⊂R^{(H+W-1)×(H×W)}\) 中的特定元素 Ai,u 的一对一映射,其中 \(u^{CC}\) 映射到 A 中的特定行 i,u 映射到 A 中的特定列。
图片解释:具体来说,蓝色的位置 (θx, θy) 首先将信息传递到循环 1 中的 (ux, θy)和(θx, uy)(浅绿色).传播可以通过函数f进行量化。这两个点 (ux, θy) 和 (θx, uy) 都在 u(ux, uy) 的 criss-cross 路径中。然后,位置 (ux, θy) 和 (θx, uy) 将信息传递到循环 2 中的 (ux, uy)(深绿色)。因此,即使 θ(θx, θy) 不在 u(ux, uy) 的 criss-cross 路径中,θ(θx, θy) 中的信息最终可以流向 u(ux, uy)。总之,RCCA 模块弥补了 criss-cross 注意力无法从所有像素中获取密集上下文信息的不足之处。与 criss-cross 注意力相比,RCCA 模块(R = 2)不会增加额外的参数,并且可以在计算成本略微增加的情况下实现更好的.
3.4 Learning Category Consistent Features
3.5 3D Criss-Cross Attention
4、ablation and results
5、conclusion and future work

 浙公网安备 33010602011771号
浙公网安备 33010602011771号