论文:Very deep convolutional networks for large-scale image recognition-VGG
论文名:
Very deep convolutional networks for large-scale image recognition
"用于大规模图像识别的深度卷积网络"
了解VGG模型
VGG在深度上的探索达到了极致,往后的精进在于改进结构
研究问题:
研究方法:
主要结论:
模型:
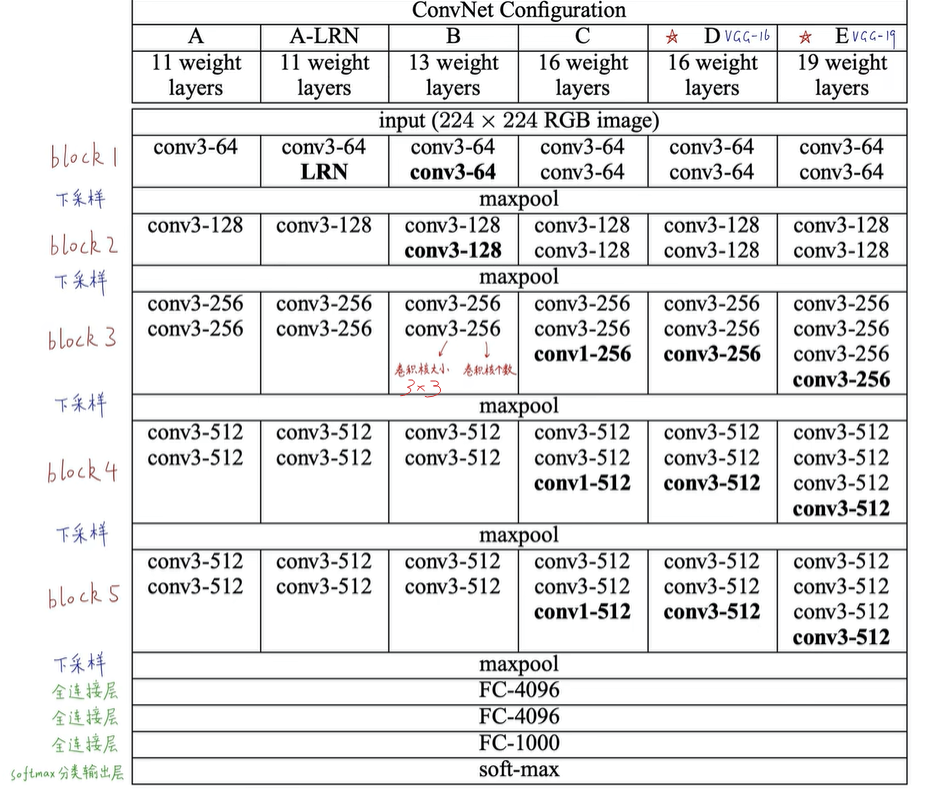
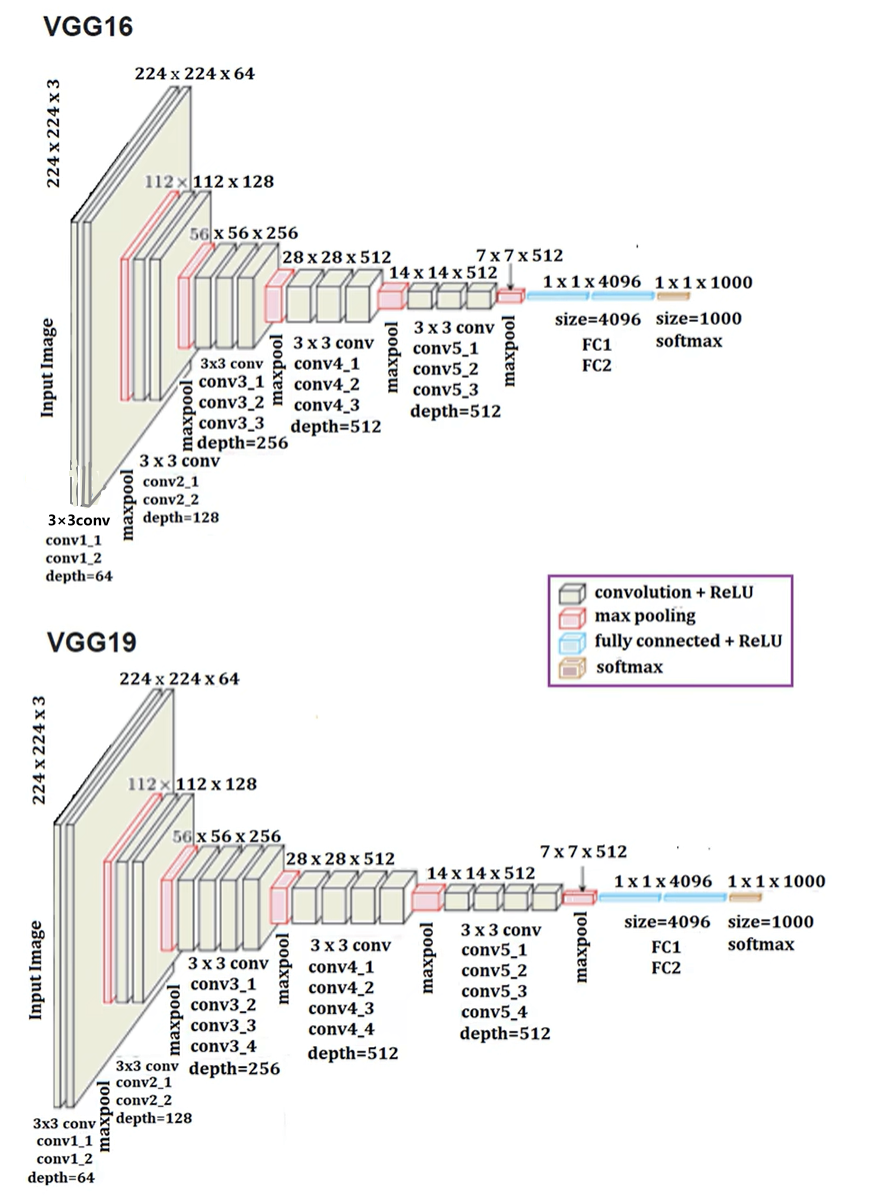
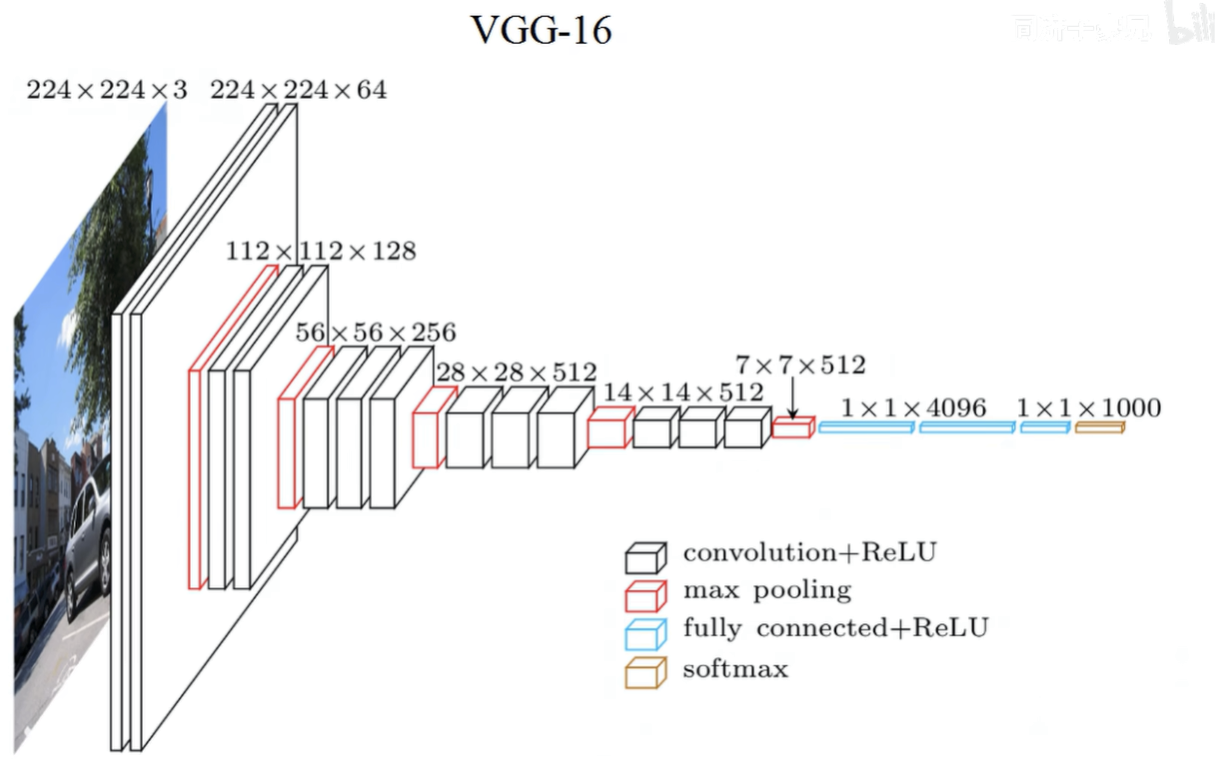
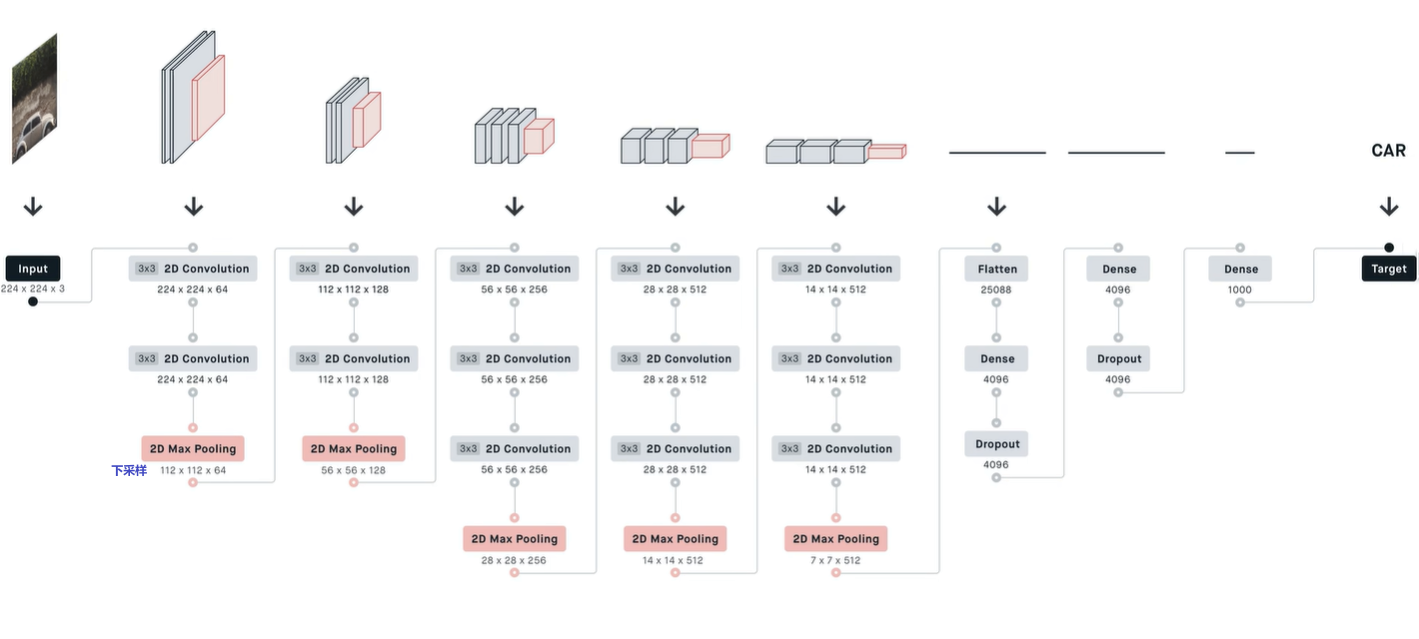
问题:
1.assuming that both the input and the output Of a three-layer 3×3 convolution stack has C channels,the stack is parametrised by \(3×(3^2× C^2)= 27×C^2\) weights;at the same time,a single 7×7conv.layer would require \(7^2×C^2=49×C^2\)parameters,i.e.
81%more.为什么这样计算参数呢?
卷积层的参数数量是由以下几个因素决定的:
-
卷积核大小(Kernel Size):这是卷积核的尺寸,通常表示为HxW,其中H表示高度,W表示宽度。
-
输入通道数(Input Channels):这是输入数据的通道数,例如,对于彩色图像,通常有3个通道(红、绿、蓝)。
-
输出通道数(Output Channels):这是卷积层生成的特征图的通道数,也可以称为卷积核的数量。
参数的计算公式如下:
在你提到的情况下,针对一个卷积核,卷积核大小是3x3,输入通道数和输出通道数都是C。因此,参数数量为:
对于三层3x3卷积堆栈,参数数量是27× C^2。
对于单层7x7卷积层,参数数量为49*C^2,正如之前解释的一样。再次对比两者,三层3x3卷积堆栈需要更少的参数。
2、This can be seen as imposing a regularisation on the 7 × 7 conv. filters, forcing them to
have a decomposition through the 3 × 3 filters (with non-linearity injected in between)
这句话指的是在深度学习中使用较小的3x3卷积核来构建7x7卷积核的过程,通过在这些小卷积核之间引入非线性操作,从而实现正则化的效果。
正则化:将大卷积核分解成多个小卷积核的组合,有助于减少模型的复杂度,降低过拟合,限制参数的数量
小卷积核的组合:比如将多个3×3卷积核组合起来,通过非线性激活函数连接它们。这种组合可以捕获更复杂的特征,同时减少参数数量。
例如,将三个3x3卷积核串联在一起,然后再通过ReLU激活函数,将其作为一个整体来看,这相当于一个7x7的感受野,但只需要学习27个参数(3个3x3卷积核,每个有9个参数),远少于单个7x7卷积核的参数数量。
The training was regularised by weight decay (the L2 penalty multiplier set to \(5*10^{−4}\)) and dropout regularisation for the first two fully-connected layers (dropout ratio set to 0.5).
The learning rate was initially set to \(10^{−2}\), and then decreased by a factor of 10 when the validation set accuracy stopped improving.
权重衰减(L2 正则化):权重衰减是一种正则化技巧,用于控制神经网络的复杂性,以防止过拟合。在这里,它的强度(L2 惩罚系数)被设置为 5 x 10^(-4)。这意味着在损失函数中会添加一个与所有权重的平方和成正比的项,以鼓励模型的权重保持较小。这有助于提高模型的泛化性能。
Dropout 正则化:Dropout 是一种用于防止神经网络过拟合的正则化技巧。在这里,它被应用于模型的前两个全连接层(或密集层)。"Dropout 比例" 被设置为 0.5,这表示在每次训练迭代中,平均来说,这两个层的一半神经元单元会被随机关闭(设置输出为零),从而减少神经元之间的协作,使网络更健壮。
学习率(Learning Rate):初始学习率被设置为 10^(-2),这是在训练神经网络时控制权重更新的重要超参数。学习率控制了每一次权重调整的幅度。初始学习率设置较高,可以加快模型的训练过程。不过,这个高学习率随着时间逐渐减小。
学习率衰减(Learning Rate Decay):学习率被设置为在训练过程中逐渐减小的。当验证集(或开发集)的准确度不再提高时,学习率会按一个因子(通常是10)减小。这是一种常见的策略,目的是在训练后期更加精细地调整权重,以使模型更好地收敛并获得更好的性能。
综上所述,这些设置和策略有助于在神经网络训练过程中防止过拟合,调整权重,加快收敛速度,并提高模型的泛化性能。这些都是训练深度学习模型时常用的技巧和策略。
行文结构梳理:
Sect.2:Convet 配置
Sect.3:图像分类训练的细节与评估
Sect.4:配置跟在ILSVRC分类任务的配置作对比
Sect.5:总结全文
附录A:描述和评估ILSVRC-2014目标定位系统
附录B:讨论了深度特征在其他数据集中的泛化能力
附录C:包含文章修订列表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号