一个深度学习的例子
主题介绍:使用 TensorFlow,可以将深度机器学习从一个研究领域转变成一个主流的软件工程方法。在这个视频中,Martin Görner 演示了如何构建和训练一个用于识别手写数字的神经网络。在这个过程中,他将描述一些在神经网络设计中所使用的权衡技巧,最后他将使得其模型的识别准确度超过 99%。本教程的内容适用于各种水平的软件开发者。即使是经验丰富的机器学习爱好者,本视频也能通过卷积网络等已知的模型来带你了解 TensorFlow。这是一个技术密集的视频,是为想要快速上手机器学习的初学者而设计的。
第一部分
本教程将以如何进行手写数字识别为例进行讲解。

首先,Gorner 给出了一个非常简单的可以分类数字的模型:softmax 分类。对于一张 28×28 像素的数字图像,其共有 784 个像素(MNIST 的情况)。将它们进行分类的最简单的方法就是使用 784 个像素作为单层神经网络的输入。神经网络中的每个「神经元」对其所有的输入进行加权求和,并添加一个被称为「偏置(bias)」的常数,然后通过一些非线性激活函数(softmax 是其中之一)来反馈结果。
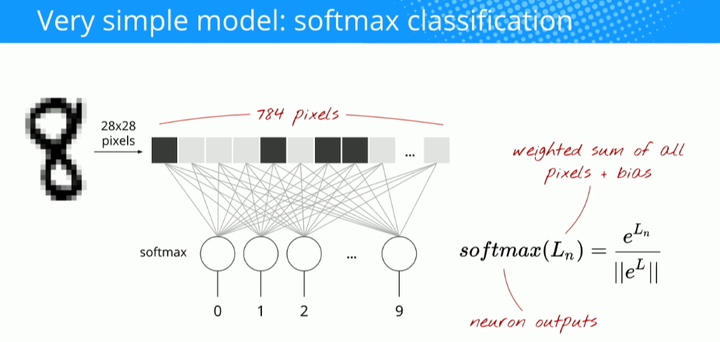
为了将数字分为 10 类(0 到 9),需要设计一个具有 10 个输出神经元的单层神经网络。对于分类问题,softmax 是一个不错的激活函数。通过取每个元素的指数,然后归一化向量(使用任意的范数(norm,L1 或 L2),比如向量的普通欧几里得距离)从而将 softmax 应用于向量。
那么为什么「softmax」会被称为 softmax 呢?指数是一种骤增的函数。这将加大向量中每个元素的差异。它也会迅速地产生一个巨大的值。然后,当进行向量的标准化时,支配范数(norm)的最大的元素将会被标准化为一个接近 1 的数字,其他的元素将会被一个较大的值分割并被标准化为一个接近 0 的数字。所得到的向量清楚地显示出了哪个是其最大的值,即「max」,但是却又保留了其值的原始的相对排列顺序,因此即为「soft」。

我们现在将使用矩阵乘法将这个单层的神经元的行为总结进一个简单的公式当中。让我们直接这样做:100 个图像的「mini-batch」作为输入,产生 100 个预测(10 元素向量)作为输出。
使用加权矩阵 W 的第一列权重,我们计算第一个图像所有像素的加权和。该和对应于第一神经元。使用第二列权重,我们对第二个神经元进行同样的操作,直到第 10 个神经元。然后,我们可以对剩余的 99 个图像重复操作。如果我们把一个包含 100 个图像的矩阵称为 X,那么我们的 10 个神经元在这 100 张图像上的加权和就是简单的 X.W(矩阵乘法)。
每一个神经元都必须添加其偏置(一个常数)。因为我们有 10 个神经元,我们同样拥有 10 个偏置常数。我们将这个 10 个值的向量称为 b。它必须被添加到先前计算的矩阵中的每一行当中。使用一个称为「broadcast」的魔法,我们将会用一个简单的加号写出它。
是 Python 和 numpy(Python 的科学计算库)的一个标准技巧。它扩展了对不兼容维度的矩阵进行正常操作的方式。「Broadcasting add」意味着「如果你因为两个矩阵维度不同的原因而不能将其相加,那么你可以根据需要尝试复制一个小的矩阵使其工作。」
我们最终应用 softmax 激活函数并且得到一个描述单层神经网络的公式,并将其应用于 100 张图像:

在 TensorFlow 中则写成这样:

接下来我们需要训练神经网络来自己找到我们所需要的权重和偏置。
接下来,Gorner 介绍了如何对神经网络进行训练。
要让神经网络从输入图像中产生预测,我们需要知道它们可以做到什么样的程度,即在我们知道的事实和网络的预测之间到底有多大的距离。请记住,我们对于这个数据集中的所有图像都有一个真实的标签。
任何一种定义的距离都可以进行这样的操作,普通欧几里得距离是可以的,但是对于分类问题,被称为「交叉熵(cross-entropy)」的距离更加有效。交叉熵是一个关于权重、偏置、训练图像的像素和其已知标签的函数。
这里用到了 one-hot 编码。「one-hot」编码意味着你使用一个 10 个值的向量,其中除了第 6 个值为 1 以外的所有值都是 0。这非常方便,因为这样的格式和我们神经网络预测输出的格式非常相似,同时它也作为一个 10 值的向量。

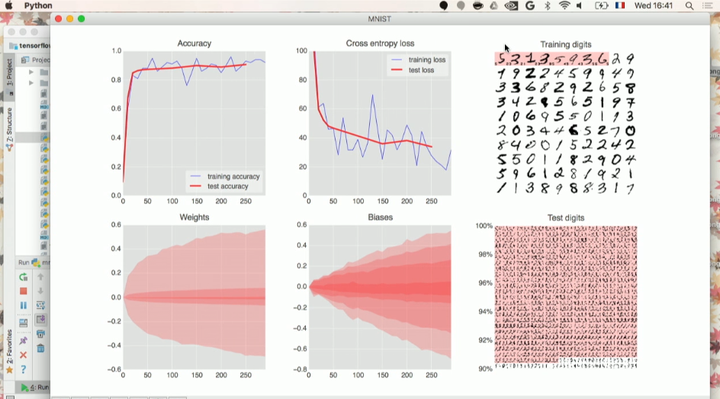
在这里可视化演示了这个动态过程(参见视频)。
-
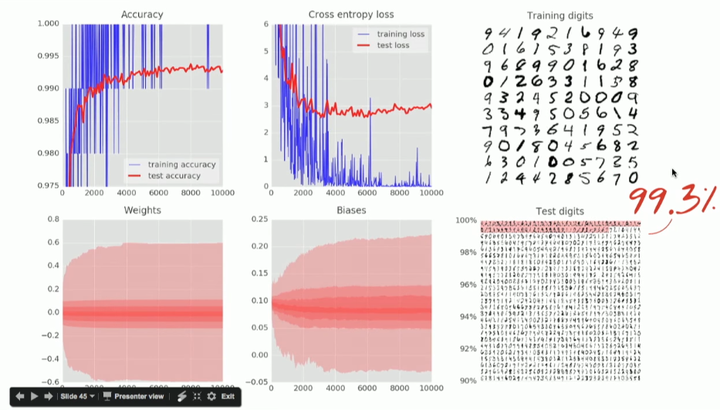
准确度(左上图):这个准确度只是正确识别的数字的百分比,是在训练和测试集上计算出的。如果训练顺利,它便会上升。
-
交叉熵损失(中上图):为了驱动训练,需要定义损失函数,即一个展示出系统数字识别能力有多糟的值,并且系统会尽力将其最小化。损失函数(loss function,此处为「交叉熵」)的选择稍后会做出解释。你会看到,随着训练的进行,训练和测试数据的损失会减少,而这个现象是好的,意味着神经网络正在学习。X 轴表示了学习过程中的迭代。
-
权重(左下图)和偏置(中下图):说明了内部变量所取的所有值的扩展,即随训练进行而变化的权重和偏置。比如偏置从 0 开始,且最终得到的值大致均匀地分布在-1.5 和 1.5 之间。如果系统不能很好地收敛,那么这些图可能有用。倘若你发现权重和偏差扩展到上百或上千,那么就可能有问题了。
-
训练数字(右上图):训练数字每次 100 个被送入训练回路;也可以看到当前训练状态下的神经网络是已将数字正确识别(白色背景)还是误分类(红色背景,左侧印有正确的标示,每个数字右侧印有计算错误的标示)。此数据集中有 50,000 个训练数字。我们在每次迭代(iteration)中将 100 个数字送入训练循环中,因此系统将在 500 次迭代之后看到所有训练数字一次。我们称之为一个「epoch」。
-
测试数字(右下图):为了测试在现实条件下的识别质量,我们必须使用系统在训练期间从未看过的数字。否则,它可能记住了所有的训练数字,却仍无法识别我刚才写的「8」。MNIST 数据集包含了 10,000 个测试数字。此处你能看到每个数字对应的大约 1000 种书写形式,其中所有错误识别的数字列在顶部(有红色背景)。左边的刻度会给你一个粗略的分辨率精确度(正确识别的百分比)。
「训练」一个神经网络实际上就是使用训练图像和标签来调整权重和偏置,以便最小化交叉熵损失函数。
那么我们在 TensorFlow 中如何实现它呢?
我们首先定义 TensorFlow 的变量和占位符(placeholder),即权重和偏置。
 占位符是在训练期间填充实际数据的参数,通常是训练图像。持有训练图像的张量的形式是 [None, 28, 28, 1],其中的参数代表:
占位符是在训练期间填充实际数据的参数,通常是训练图像。持有训练图像的张量的形式是 [None, 28, 28, 1],其中的参数代表:
-
28, 28, 1: 图像是 28x28 每像素 x 1(灰度)。最后一个数字对于彩色图像是 3 但在这里并非是必须的。
-
None: 这是代表图像在小批量(mini-batch)中的数量。在训练时可以得到。
接下来是定义模型:

第一行是我们单层神经网络的模型。公式是我们在前面的理论部分建立的。tf.reshape 命令将我们的 28×28 的图像转化成 784 个像素的单向量。在 reshape 中的「-1」意味着「计算机,计算出来,这只有一种可能」。在实际当中,这会是图像在小批次(mini-batch)中的数量。
然后,我们需要一个额外的占位符用于训练标签,这些标签与训练图像一起被提供。
现在我们有了模型预测和正确的标签,所以我们计算交叉熵。tf.reduce_sum 是对向量的所有元素求和。
最后两行计算了正确识别数字的百分比。
才是 TensorFlow 发挥它力量的地方。你选择一个适应器(optimiser,有许多可供选择)并且用它最小化交叉熵损失。在这一步中,TensorFlow 计算相对于所有权重和所有偏置(梯度)的损失函数的偏导数。这是一个形式衍生(formal derivation),并非是一个耗时的数值型衍生。

梯度然后被用来更新权重和偏置。学习率为 0.003。
那么梯度和学习率是什么呢?
-
梯度:如果我们相对于所有的权重和所有的偏置计算交叉熵的偏导数,我们就得到一个对于给定图像、标签和当前权重和偏置的「梯度」。请记住,我们有 7850 个权重和偏置,所以计算梯度需要大量的工作。幸运的是,TensorFlow 可以来帮我们做这项工作。梯度的数学意义在于它指向「上(up)」。因为我们想要到达一个交叉熵低的地方,那么我们就去向相反的方向。我们用一小部分的梯度更新权重和偏置并且使用下一批训练图像再次做同样的事情。我们希望的是,这可以使我们到达交叉熵最小的凹点的低部。梯度下降算法遵循着一个最陡的坡度下降到局部最小值的路径。训练图像在每一次迭代中同样会被改变,这使得我们向着一个适用于所有图像的局部最小值收敛。
-
学习率(learning rate): 在整个梯度的长度上,你不能在每一次迭代的时候都对权重和偏置进行更新。这就会像是你穿着七里靴却试图到达一个山谷的底部。你会直接从山谷的一边到达另一边。为了到达底部,你需要一些更小的步伐,即只使用梯度的一部分,通常在 1/1000 区域中。我们称这个部分为「学习率」。
接下来该运行训练循环了。到目前为止,所有的 TensorFlow 指令都在内存中准备了一个计算图,但是还未进行计算。
TensorFlow 的「延迟执行(deferred execution)」模型:TensorFlow 是为分布式计算构建的。它必须知道你要计算的是什么、你的执行图(execution graph),然后才开始发送计算任务到各种计算机。这就是为什么它有一个延迟执行模型,你首先使用 TensorFlow 函数在内存中创造一个计算图,然后启动一个执行 Session 并且使用 Session.run 执行实际计算任务。在此时,图无法被更改。
由于这个模型,TensorFlow 接管了分布式运算的大量运筹。例如,假如你指示它在计算机 1 上运行计算的一部分,而在计算机 2 上运行另一部分,它可以自动进行必要的数据传输。
计算需要将实际数据反馈进你在 TensorFlow 代码中定义的占位符。这是以 Python 的 dictionary 的形式给出的,其中的键是占位符的名称。

在这里执行的 train_step 是当我们要求 TensorFlow 最小化交叉熵时获得的。这是计算梯度和更新权重和偏置的步骤。
最终,我们还需要一些值来显示,以便我们可以追踪我们模型的性能。
通过在馈送 dictionary 中提供测试而不是训练数据,可以对测试数据进行同样的计算(例如每 100 次迭代计算一次。有 10,000 个测试数字,所以会耗费 CPU 一些时间)。
最后一行代码用于在训练回路中计算准确度和交叉熵(例如每 10 次迭代)。
下面是所有代码:

这个简单的模型已经能识别 92% 的数字了。但这个准确度还不够好,但是你现在要显著地改善它。怎么做呢?深度学习就是要深,要更多的层!

让我们来试试 5 个全连接层。
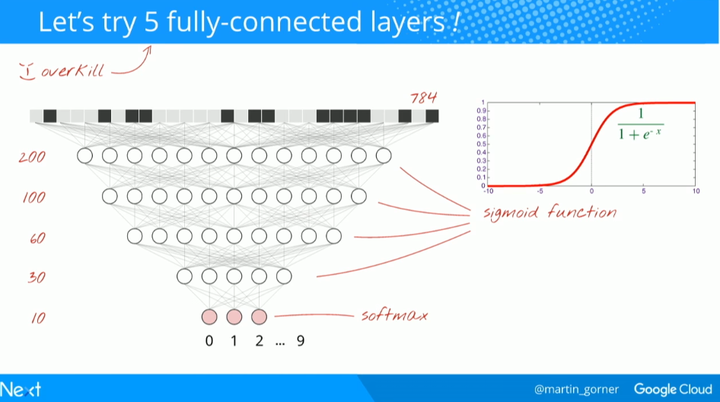
我们继续用 softmax 来作为最后一层的激活函数,这也是为什么在分类这个问题上它性能优异的原因。但在中间层,我们要使用最经典的激活函数:sigmoid 函数。
下面开始写代码。为了增加一个层,你需要为中间层增加一个额外的权重矩阵和一个额外的偏置向量:

这样增加多个层:

但 sigmoid 不是全能的。在深度网络里,sigmoid 激活函数也能带来很多问题。它把所有的值都挤到了 0 到 1 之间,而且当你重复做的时候,神经元的输出和它们的梯度都归零了。修正线性单元(ReLU)也是一种很常使用的激活函数:
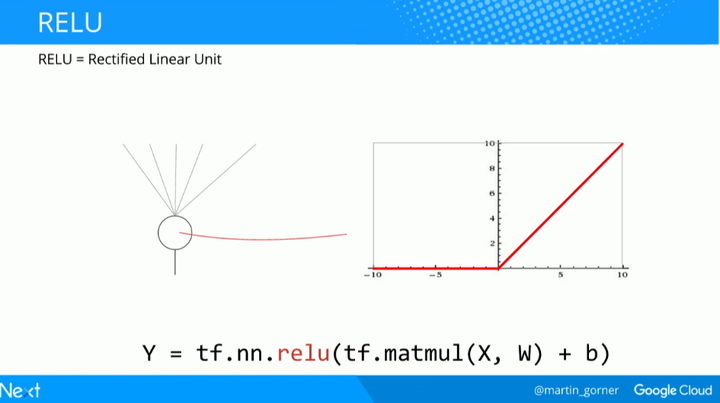
对比一下在 300 次迭代时 sigmoid 函数(浅色线)和 ReLU(深色线)的效果,可以看到 ReLU 在准确度和交叉熵损失上的表现都显著更好。
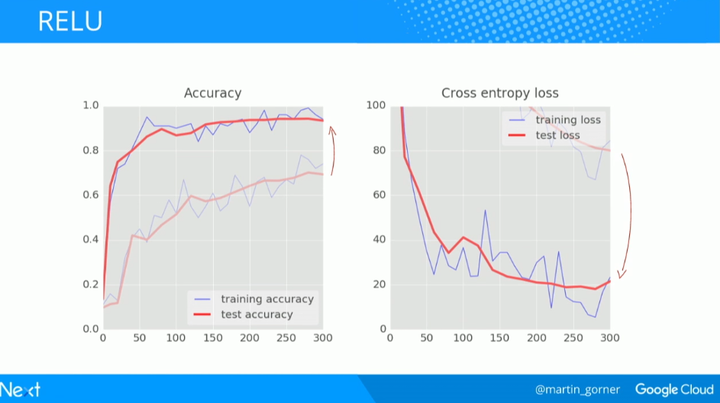
用 ReLU 替换你所有的 sigmoid,然后你会得到一个更快的初始收敛并且当我们继续增加层的时候也避免了一些后续问题的产生。仅仅在代码中简单地用 tf.nn.relu 来替换 tf.nn.sigmoid 就可以了。
但收敛过快也有问题:

这些曲线很嘈杂,看看测试精确度吧:它在全百分比范围内跳上跳下。这意味着即使 0.003 的学习率我们还是太快了。但我们不能仅仅将学习率除以十或者永远不停地做训练。一个好的解决方案是开始很快随后将学习速率指数级衰减至比如说 0.0001。
这个小改变的影响是惊人的。你会看到大部分的噪声消失了并且测试精确度持续稳定在 98% 以上。
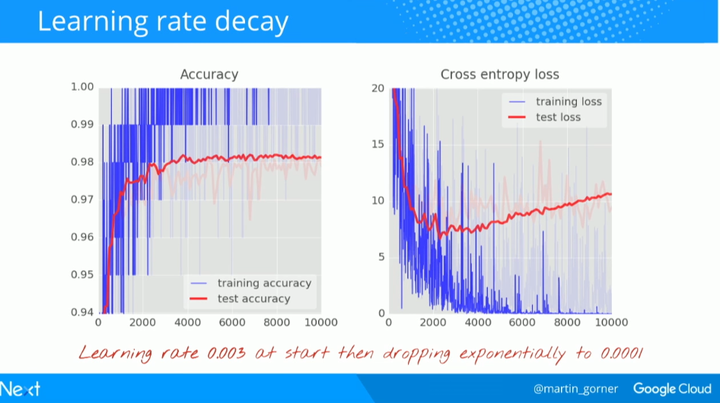
再看看训练精确度曲线。在好多个 epoch 里都达到了 100%(一个 epoch=500 次迭代=全部训练图片训练一次)。第一次我们能很好地识别训练图片了。
但右边的图是什么情况?
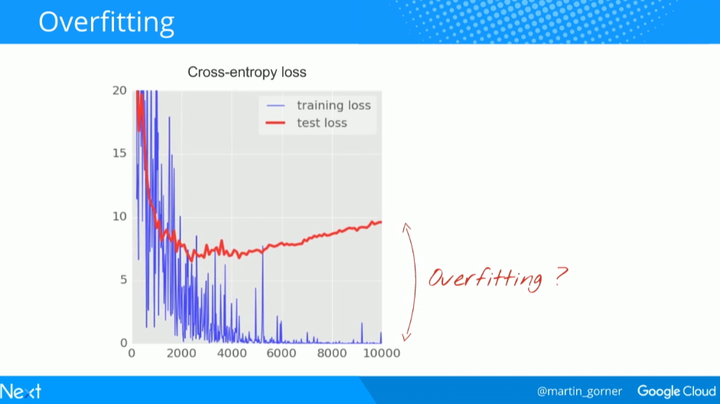
在数千次迭代之后,测试和训练数据的交叉熵曲线开始不相连。学习算法只是在训练数据上做工作并相应地优化训练的交叉熵。它再也看不到测试数据了,所以这一点也不奇怪:过了一会儿它的工作不再对测试交叉熵产生任何影响,交叉熵停止了下降,有时甚至反弹回来。它不会立刻影响你模型对于真实世界的识别能力,但是它会使你运行的众多迭代毫无用处,而且这基本上是一个信号——告诉我们训练已经不能再为模型提供进一步改进了。这种情况通常会被称为「过拟合(overfitting)」。
为了解决这个问题,你可以尝试采用一种规范化(regularization)技术,称之为「dropout」。
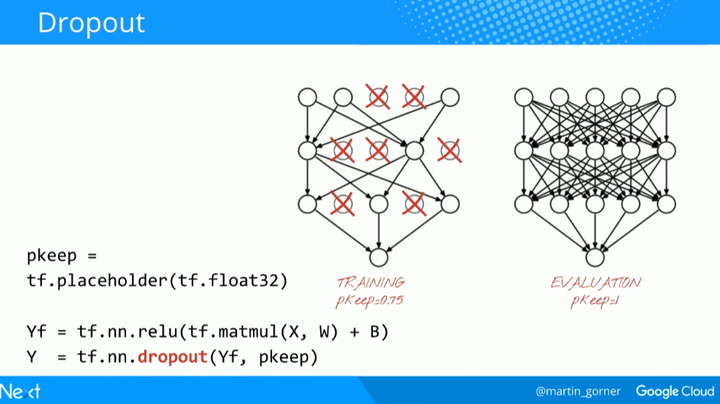
在 dropout 里,在每一次训练迭代的时候,你可以从网络中随机地放弃一些神经元。你可以选择一个使神经元继续保留的概率 pkeep,通常是 50% 到 75% 之间,然后在每一次训练的迭代时,随机地把一些神经元连同它们的权重和偏置一起去掉。在一次迭代里,不同的神经元可以被一起去掉(而且你也同样需要等比例地促进剩余神经元的输出,以确保下一层的激活不会移动)。当测试你神经网络性能的时候,你再把所有的神经元都装回来 (pkeep=1)。
TensorFlow 提供一个 dropout 函数可以用在一层神经网络的输出上。它随机地清零一些输出并且把剩下的提升 1/pkeep。你可以在网络中每个中间层以后插入 dropout。
下面我们集中看一下改进的情况。
当使用 sigmoid 函数,学习率为 0.003 时:
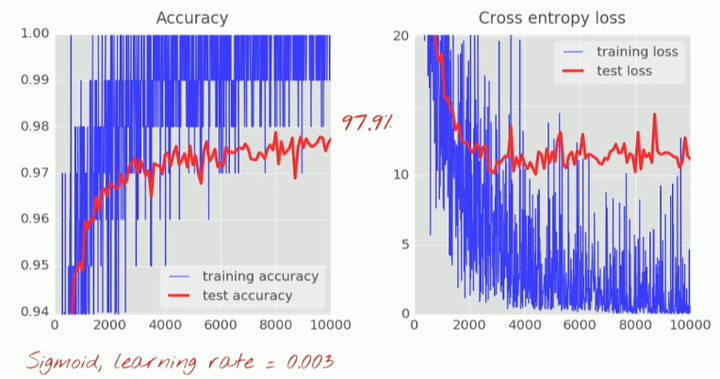
然后使用 ReLU 替代 sigmoid:
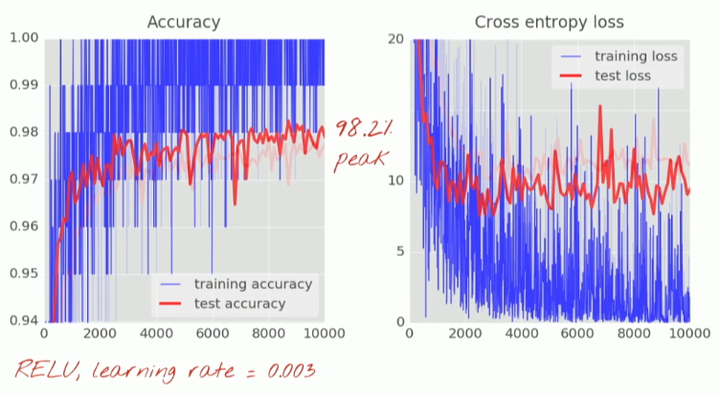
然后再将学习率衰减到 0.0001:
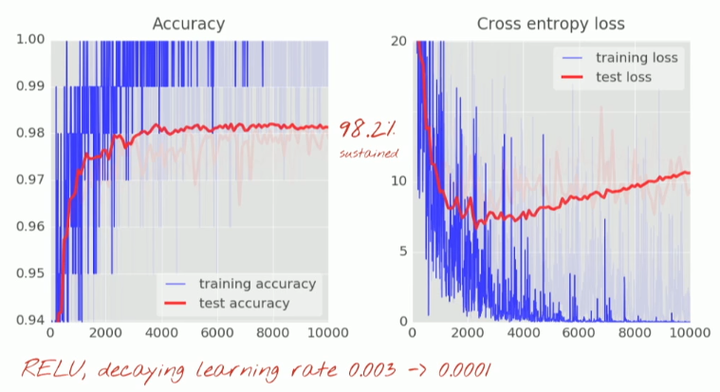
增加 dropout:
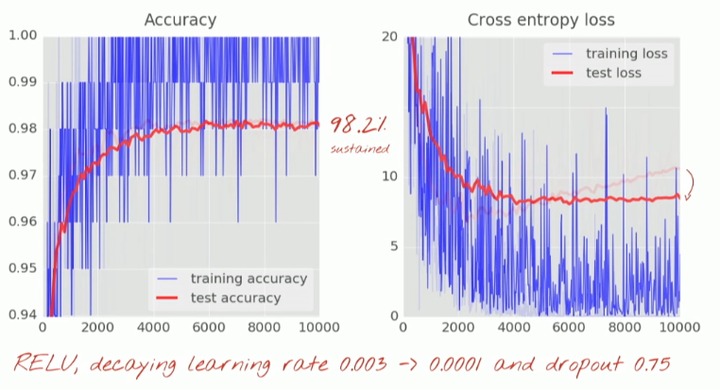
解决了过拟合,准确度达到了 98%,但是噪声又回来了。看起来无论我们做什么,我们看上去都不可能很显著地解决 98% 的障碍,而且我们的损失曲线依然显示「过拟合」无法连接。什么是真正的「过拟合」?过拟合发生在该神经网络学得「不好」的时候,在这种情况下该神经网络对于训练样本做得很好,对真实场景却并不是很好。有一些像 dropout 一样的规范化技术能够迫使它学习得更好,不过过拟合还有更深层的原因。

基本的过拟合发生在一个神经网络针对手头的问题有太多的自由度的时候。想象一下我们有如此多的神经元以至于所组成的网络可以存储我们所有的训练图像并依靠特征匹配来识别它们。它会在真实世界的数据里迷失。一个神经网络必须有某种程度上的约束以使它能够归纳推理它在学习中所学到的东西。
如果你只有很少的训练数据,甚至一个很小的网络都能够用心学习它。一般来说,你总是需要很多数据来训练神经网络。
最后,如果你已经做完了所有的步骤,包括实验了不同大小的网络以确保它的自由度已经约束好了、采用了 dropout、并且训练了大量的数据,你可能会发现你还是被卡在了当前的性能层次上再也上不去了。这说明你的神经网络在它当前的形态下已经无法从你提供的数据中抽取到更多的信息了,就像我们这个例子这样。
还记得我们如何使用我们的图像吗?是所有的像素都展平到一个向量里么?这是一个很糟糕的想法。手写的数字是由一个个形状组成的,当我们把像素展平后我们会丢掉这些形状信息。不过,有一种神经网络可以利用这些形状信息:卷积网络(convolutional network)。让我们来试试。
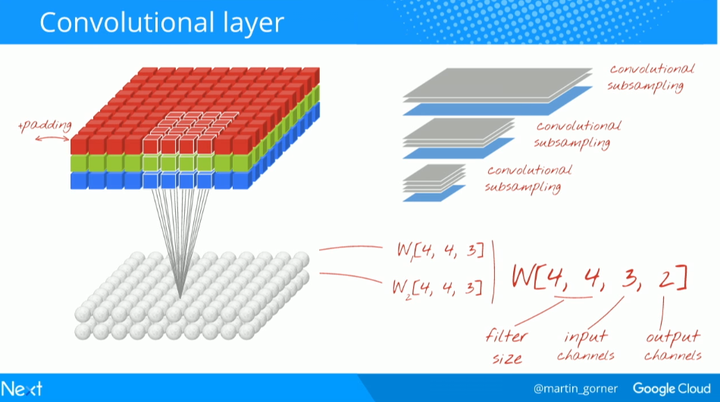
在卷积网络层中,一个「神经元」仅对该图像上的一个小部分的像素求加权和。然后,它通常会添加一个偏置单元,并且将得到的加权和传递给激活函数。与全连接网络相比,其最大的区别在于卷积网络的每个神经元重复使用相同的权重,而不是每个神经元都有自己的权重。
在上图中,你可以看到通过连续修改图片上两个方向的权重(卷积),能够获得与图片上的像素点数量相同的输出值(尽管在边缘处需要填充(padding))。
要产生一个输出值平面,我们使用了一张 4x4 大小的彩色图片作为出输入。在上图当中,我们需要 4x4x3=48 个权重,这还不够,为了增加更多自由度,我们还需要选取不同组的权重值重复实验。
通过向权重张量添加一个维度,能够将两组或更多组的权重重写为一组权重,这样就给出了一个卷积层的权重张量的通用实现。由于输入、输出通道的数量都是参数,我们可以开始堆叠式(stacking)和链式(chaining)的卷积层。
最后,我们需要提取信息。在最后一层中,我们仅仅想使用 10 个神经元来分类 0-9 十个不同的数字。传统上,这是通过「最大池化(max-pooling)」层来完成的。即使今天有许多更简单的方法能够实现这分类任务,但是,「最大池化」能够帮助我们直觉地理解卷积神经网络是怎么工作的。如果你认为在训练的过程中,我们的小块权重会发展成能够过滤基本形状(水平线、垂直线或曲线等)的过滤器(filter),那么,提取有用信息的方式就是识别输出层中哪种形状具有最大的强度。实际上,在最大池化层中,神经元的输出是在 2x2 的分组中被处理,最后仅仅保留输出最大强度的神经元。
这里有一种更简单的方法:如果你是以一步两个像素移动图片上的滑块而不是以每步一个像素地移动图片上的滑块。这种方法就是有效的,今天的卷积网络仅仅使用了卷积层。
让我们建立一个用于手写数字识别的卷积网络。在顶部,我们将使用 3 个卷积层;在底部,我们使用传统的 softmax 读出层,并将它们用完全连接层连接。
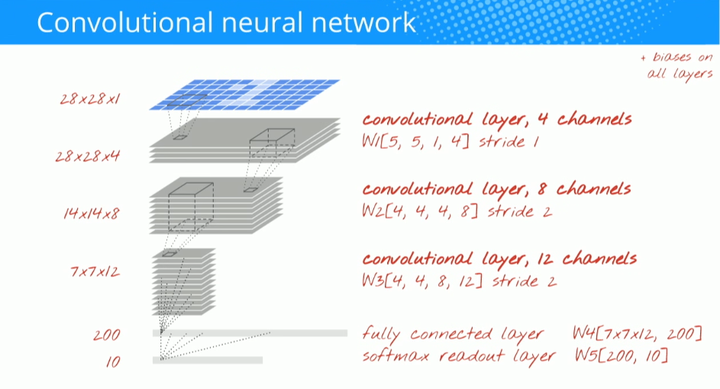
注意,第二与第三卷积层神经元数量以 2x2 为倍数减少,这就解释了为什么它们的输出值从 28x28 减少为 14x14,然后再到 7x7。卷积层的大小变化使神经元的数量在每层下降约为:28x28x14≈3000->14x14x8≈1500 → 7x7x12≈500 → 200。下一节中,我们将给出该网络的具体实现。
那我们如何在 TensorFlow 中实现它呢?为了将我们的代码转化为卷积模型,我们需要为卷积层定义适当的权重张量,然后将该卷积层添加到模型中。我们已经理解到卷积层需要以下形式的权重张量。下面代码是用 TensorFlow 语法来对其初始化:

然后实现其模型:

在 TensorFlow 中,使用 tf.nn.conv2d 函数实现卷积层,该函数使用提供的权重在两个方向上扫描输入图片。这仅仅是神经元的加权和部分,你需要添加偏置单元并将加权和提供给激活函数。不要过分在意 stride 的复杂语法,查阅文档就能获取完整的详细信息。这里的填充(padding)策略是为了复制图片的边缘的像素。所有的数字都在一个统一的背景下,所以这仅仅是扩展了背景,并且不应该添加不需要的任何样式。
完成这一步之后,我们应该能达到 99% 的准确度了吧?
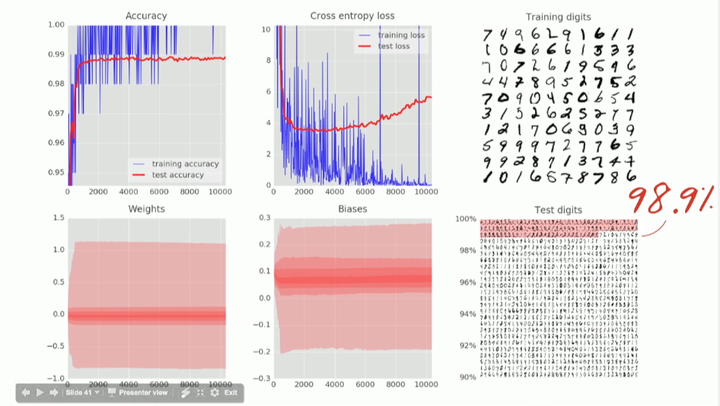
然而并没有!什么情况?
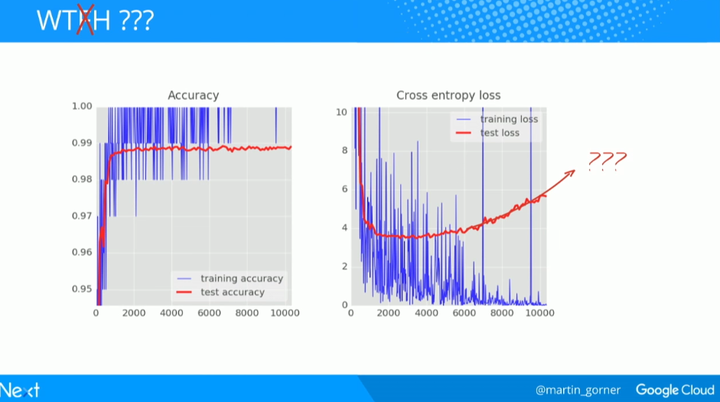
还记得前面我们怎么解决这个「过拟合」问题的吗?使用 dropout。
我们该怎么对其进行优化呢?调整你的神经网络的一个好方法是先去实现一个限制较多的神经网络,然后给它更多的自由度并且增加 dropout,使神经网络避免过拟合。最终你将得到一个相当不错的神经网络。

例如,我们在第一层卷积层中仅仅使用了 4 个 patch,如果这些权重的 patch 在训练的过程中发展成不同的识别器,你可以直观地看到这对于解决我们的问题是不够的。手写数字模式远多于 4 种基本样式。
因此,让我们稍微增加 patch 的数量,将我们卷积层中 patch 的数量从 4,8,12 增加到 6,12,24,并且在全连接层上添加 dropout。它们的神经元重复使用相同的权重,在一次训练迭代中,通过冻结(限制)一些不会对它们起作用的权重,dropout 能够有效地工作。
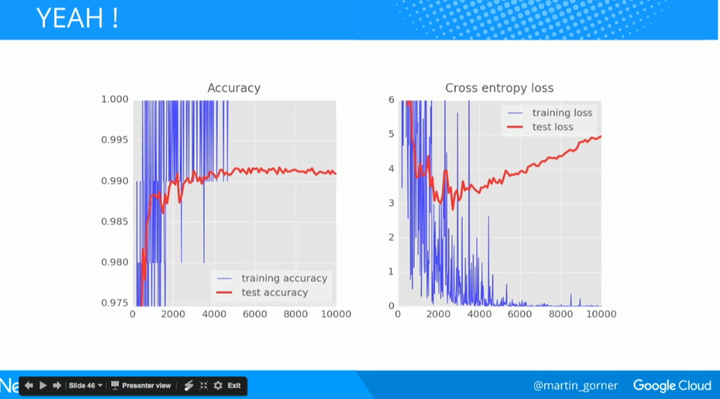
然后模型的准确度就突破 99% 了!
对比之前的结果可以看到明显的进步:
相关资源:

第二部:建立循环神经网络
在这一部分 Gorner 讲解了如何使用 TensorFlow 建立循环神经网络。
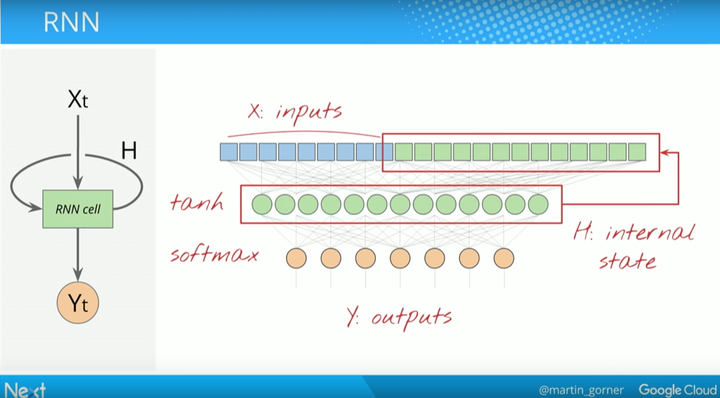
RNN 的结构与训练
首先,RNN 的结构如下,其中第二层为 softmax 层(读取出东西)。但特殊的是,中间绿色层的输出在下一步骤中会返回到输入中。
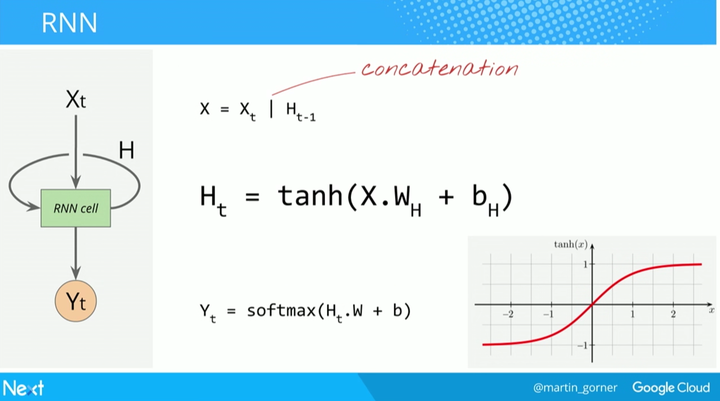
下面是循环神经网络里面的等式。
那么接下来如何训练 RNN?以自然语言处理为例:输入通常为字符(character)。如下图中所示,我们输入字符,反向传播通过该神经网络、反向传播通过 softmax 层,我们会得到字符的输出。如果得到的字符不是我们想要的,对比一下得到的与我们想要的,我们就对网络中的权重进行调整,从而得到更好的结果。

但如果结果是错的怎么办?而且不是因为网络中的权重偏见,而是因为状态输入 H-1 是错的。在此问题中,输入是连续的,有些无能为力的感觉。在这个问题上卡住了,那么解决方案是什么?
解决方案就是复制该 cell,再次使用同样的权重。下图演示了你该如何训练循环神经网络,在多次迭代中共享同样的权重和偏差。

另外,值得一提的是如果你想往深处做,可以堆叠 cells(如下图)。

而后,Gorner 以句子为例讲解了如何使用 TensorFlow 建立循环神经网络。在以下示例中,我们是用单词而非字符作为输入,建立这样的模型中就有一个典型的问题:长期依存关系。而要把下面的长句输入,需要非常深的循环神经网络,而如果网络太深,训练时候又不太好收敛。在数学细节上要提到的就是梯度消失的问题,梯度成 0 了。

对此问题的一种解决方案是 LSTM。下图从数学角度解释了该解决方案为何有效。
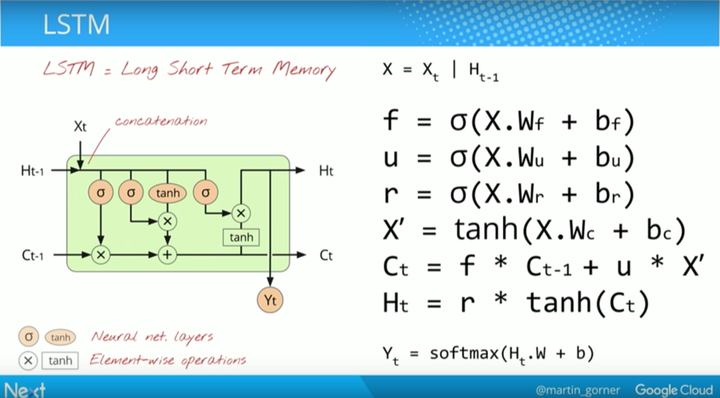
在实践中,LSTM 有效是因为它基于了门(gates) 的概念:
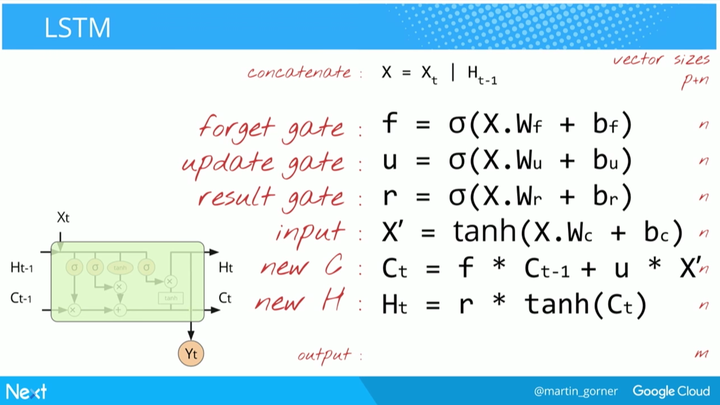
GRU 的等式:

在 TensorFlow 中实现 RNN 语言模型
接下来就是如何用 TensorFlow 实现语言模型的循环神经网络了。在教授语言模型预测单词的下一个字符是什么的例子中,Gorner 使用了 TensorFlow 中更高等级的 API。图中的 GRUCell 有着多层的循环神经网络层、两个门。然后把网络做的更深,3 个 GRU 堆叠在一起。接下来,展开整个网络,在 TensorFlow 中,这被称为动态 RNN 功能。最终得到如下结果。
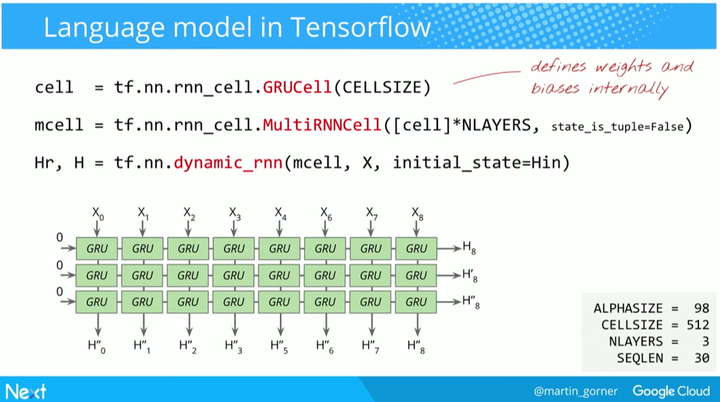
下图演示了如何在 TensorFlow 中实现 Softmax 层。

就行正确理解 RNN 的工作原理很难一样,向它们正确的输入数据也很难,你会发现里面里面有很多误差。接下来 Gorner 尝试了如何做出正确的输入、得到正确的输出。依此为例,他讲解了所选择的 batchsize、cellsize 和层(如下)。
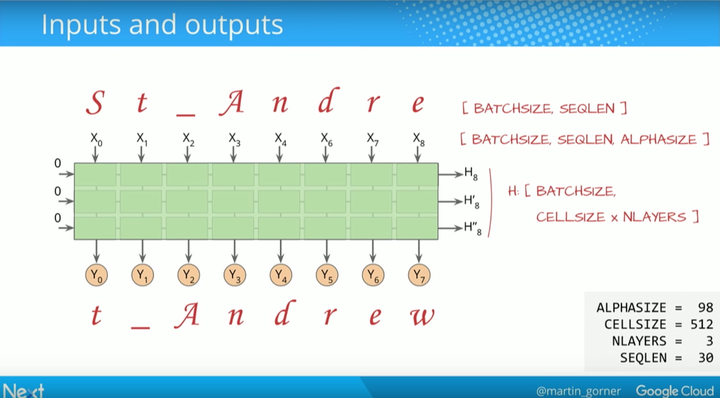
各个步骤实现的代码如下:

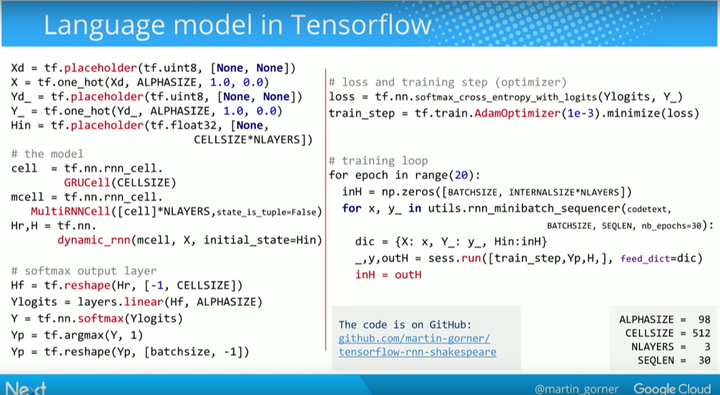
在 TensorFlow 中实现语言模型的完整代码如下:
最后,Gorne 打开 TensorFlow 演示了如何实际建模语言模型,并且演示了 RNN 在文本翻译、图像描述等领域的应用。看完之后我决定先下个 TensorFlow。
posted on 2017-12-24 22:43 alexanderkun 阅读(14680) 评论(1) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号