
nips 2016 吴恩达
一年一度的 NIPS 又来了。今年举办地是笔者最爱的欧洲城市巴塞罗那。阳光沙滩配学术,确实很爽。这次的会议的第一天开场的大部分时间安排给了 tutorial。其中人数爆满的依旧是吴恩达(AndrewNg)的 session。笔者在此总结一下他的 tutorial 内容。一如以往的风格,这次吴恩达博士(有趣的是,本次官方介绍他的时候 使用的是 Dr. 而不是 Prof.)在台上也是纯白板讲演。

开场的时候,他问了一下全场观众哪些是来自工业界。哗哗哗,全场接近 50% 的观众举手了。确实,这几年的 NIPS 一年比一年火,并且工业界对这类学术会议的关注度也一年比一年高。吴恩达本人打趣道,正因为如此,他今天才没在准备的讲稿中加入任何一条公式,他希望他今天的 tutorial 更多的是能给大家带来理念上的更新,而不仅仅是晦涩难懂的新公式。
吴恩达博士这次 tutorial 的主题是:「nuts and bolts of building AI」,翻译成中文就是「建造人工智能系统小细节」,也就是说,这篇 tutorial 将会更多地注重于给涉足人工智能领域的业界公司一点点人生经验。

演讲主题概述:你应该怎样将深度学习用于你的业务、产品或科研?高扩展性的深度学习技术的兴起正在改变人们解决人工智能问题的最佳方式。这包括:如何定义你的训练/开发/测试(train/dev/test)分配,如何组织你的数据,应该如何在各种有希望的模型架构中选择你研究所需的架构,以及甚至你可以怎样开发新的人工智能驱动的产品。在这个 tutorial 中,你将了解到这个新兴领域中涌现出的最佳实践。你还将了解当你的团队在开发深度学习应用时,如何更好地组织你和你的团队的工作。
规模造就了深度学习(Scale driving Deep Learning progresses)
开篇,吴恩达博士分析了一下当今深度学习这么火的原因。
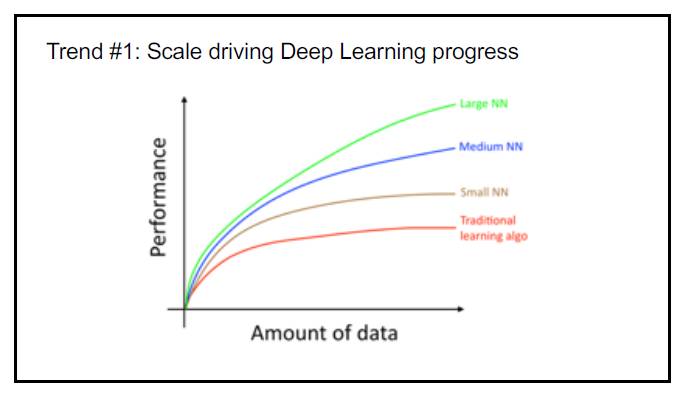
P2:趋势 1:规模正在推动深度学习的进步。随着数据量的增多,规模越大的神经网络的性能/表现(performance)就越好。
他指出,深度学习之所以这么火,主要原因是神经网络(NN)可以扩大规模(scale),甚至是可以无限地扩展。扩展之后所带来的效果是稳步提升的。并且靠扩展规模来引领深度学习,依旧会成为这个领域未来发展的大潮流。
说到这里,吴博士开始给出他的第一条人生经验:我在百度的团队构架如下:
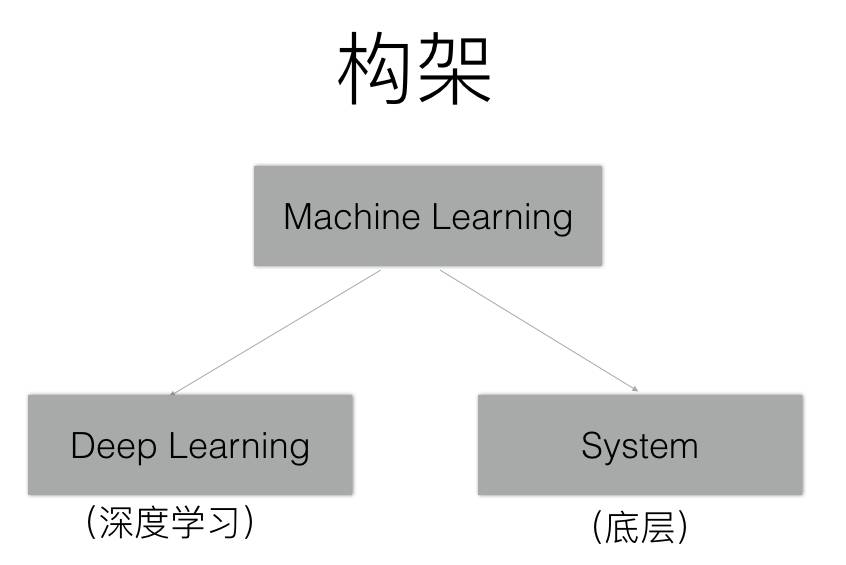
他认为在这个时代,没有人能做到在系统构架(底层)与深度学习(算法)方面都是专家,所以他的团队严格区分了两者的职责。所以,深度学习技术创业公司在技术团队建设的时候,可以做做参考。
端对端学习的崛起(the rise of end-to-end learning)
吴恩达博士还指出深度学习领域的另一个大潮将是端对端的学习(End2End learning)。
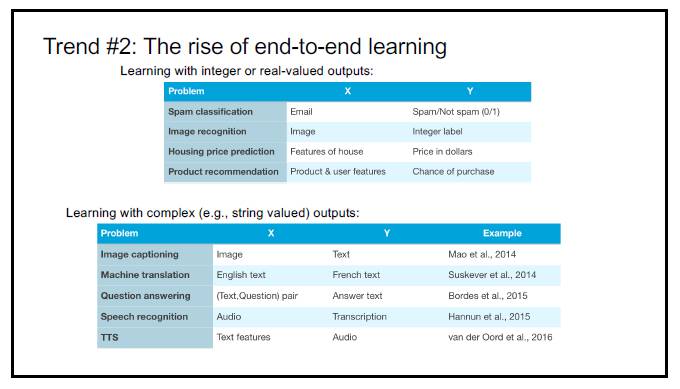
P3:趋势 2:端到端学习的兴起
传统上的端到端学习是把实体数据表达成数字数据,并通过机器学习的方法,输出数字数据作为结果。比如对电影评论数据的情感分析:输入的是文本,然后通过自然语言处理(NLP)把文本数据表达成数字向量,再通过机器学习计算,得出一个情感值,用以作为对这条评论的情感判断。这也是一种端对端的模型,但是它的结果还是一个数字值。
而现在随着深度学习的发展,更纯粹的端对端学习成为了可能。比如语音识别:输入的是语音,输出的是文本;比如机器翻译:输入的是英语,输出的是其他语言;再比如谷歌 DeepMind 的 WaveNet:输入的是文本,输出的是语音。这是比较纯粹的端对端学习。但是它也有缺点——也就是需要足够大的训练集。
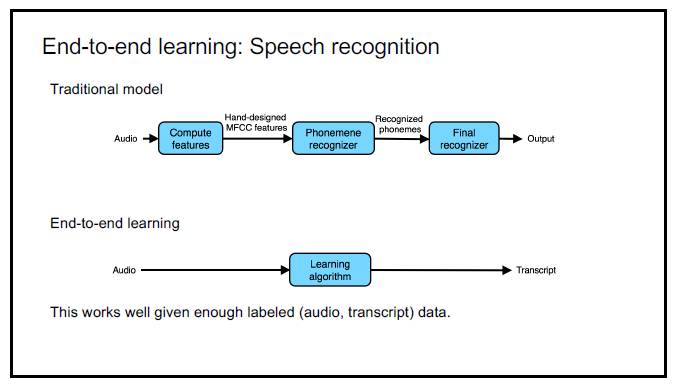
P5:端到端学习:语音识别。传统模型:音频→计算特征—(人工设计的 MFCC 特征)→音素识别器—(被识别出来的音素)→最后的识别器→输出。端到端学习:音频→学习算法→转录结果;在给定了足够的有标注数据(音频、转录)时,这种方法的效果会很好。
传统的语音识别,需要把语音转换成语音特征量(一般来说,就是一组数字化的向量),然后把这组向量通过机器学习,分类到各种音节(Phonemes)上(这是一件语言学的事儿)。然后,我们通过音节,才能还原出语音原本要表达的单词。
而现在,我们可以直接通过深度学习将语音直接对标到我们最终显示出来的文本。通过深度学习自己的特征学习功能来完成从特征提取到音节表达的整个过程。
当然,直接的端对端学习也有不太奏效的时候。比如,用计算机视觉判断进公司门的是否是自己的员工(用于公司打卡的计算机视觉)。
这种情况下,端对端(E2E)的模型假设应该是:
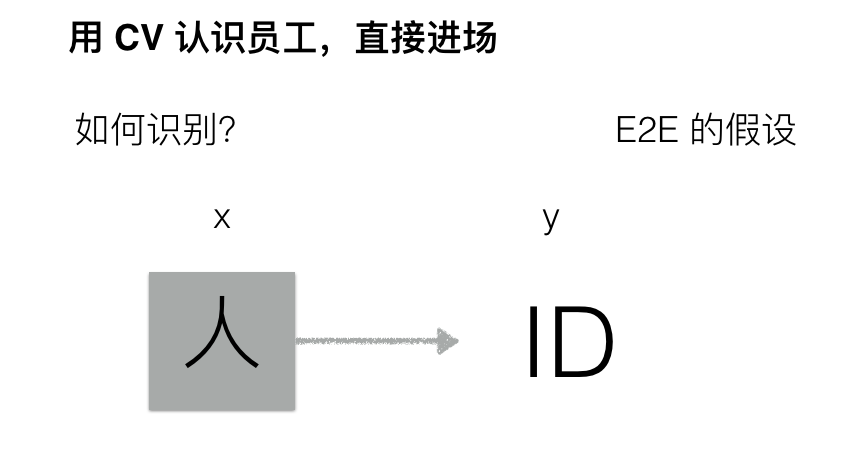
然而,这种方法行不通,因为员工进场的背景会一直变化(想象一下,公司大门对面是公路,公路上的车每分每秒都不同,背景信息噪音太大)。
所以,现实情况下我们只能:
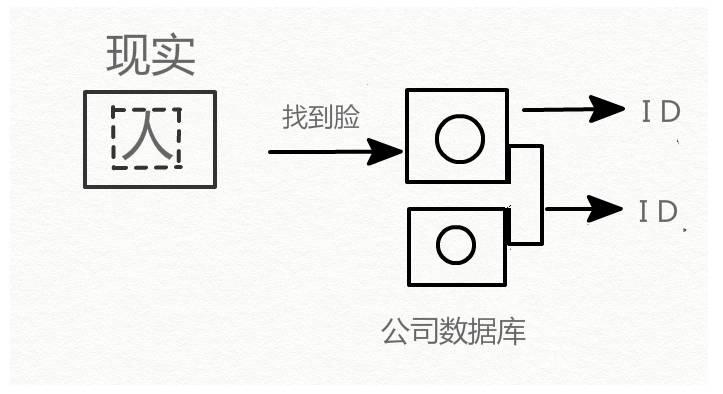
先从图片中找到脸(使用 Attentional Network),然后将这张脸和公司内部的员工数据库比较来判断这个人的 ID(是不是我司的人)。这种方面就不是我们处女座的深度学习研究者所追求的端对端了,因为它的 workflow(流程)里掺和了太多其它信息和中间步骤,不够纯粹。
如果,一个处女座的老板真的希望自己公司的门口用上非常纯粹的人工智能打卡机,那么他只能寄希望于非常非常大量的训练集。
吴博士还举了一个关于深度学习用于医学领域的例子。这也是他在斯坦福的一个朋友的研究项——通过小孩手的 X 光来检测小孩子的年龄。
同理,理想状态应该是直接从一张 X 光图中判断小孩子的年龄:
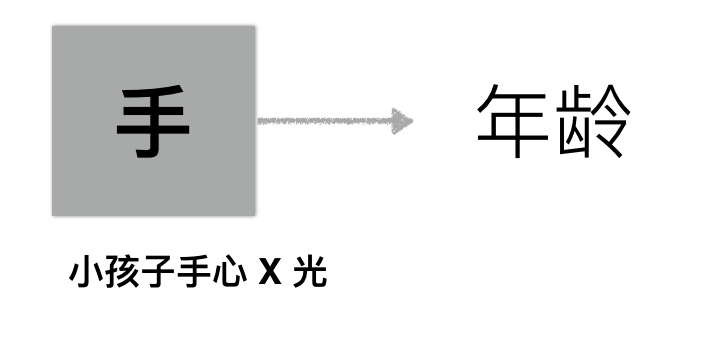
(注:左边那个是小孩的手的形象绘图)
但是实际上工业界的做法是首先通过 X 光图像判断出人骨的构架(一些代表人骨特征的数据),再依据医学上的公式来推导出被测试者的真实年龄:
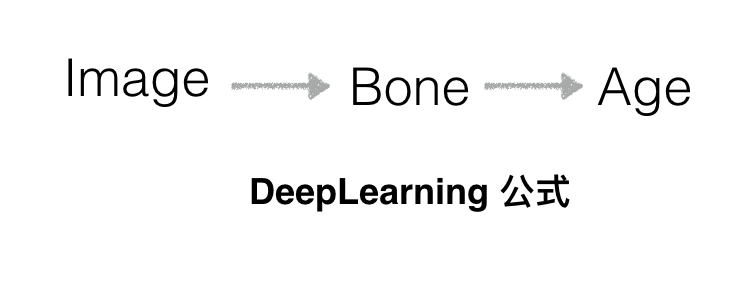
另外还有一个例子是自动驾驶:
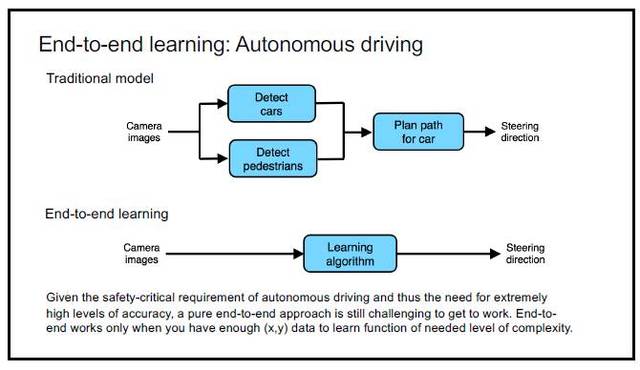
P6:端到端学习:自动驾驶。传统模型:相机图像→检测汽车+检测行人→为汽车规划路径→控制方向。端到端学习:相机图像→学习算法→控制方向。鉴于自动驾驶对安全的关键要求,所以也就需要极高的准确度,一种完全的端到端方法仍然难以应对这项工作。只有当你有足够的 (x,y) 数据时,端到端方法才会有效,才能学会所需复杂度水平的功能。
吴博士说,他敢肯定现在市面上的自动驾驶技术都是如图所示的框架:通过图片观测附近的车(cars)与行人(pedestrians),计算出该有的路径规划(plan),然后通过公式/规则判断出应该进行的下一步行动(steering)。如果想直接把图片处理成最终的操作指令,那还真的还有很长很长的一段路要走。
以上种种例子归根结底的原因是:在这些端到端表现不太好的行业内,目前的数据规模还不足以支撑起一次靠谱的端到端的深度学习过程。
机器学习策略:如何有效地处理数据集

P7:机器学习策略:在改进一个人工智能系统时,你往往会有大量的想法,你会怎么做?好的策略能帮助你节省好几个月的努力时间。
比如,我们以语音识别为例。如果我们的目标是识别出语音,我们可以把我们手上的原语音数据分割成:60% 训练集、20% 开发集和 20% 测试集:

其中,训练集(training set)是我们用来训练模型的,开发集(dev set)指的是在开发过程中用于调参、验证(validation)等步骤的数据集(保证不被模型提前学习到),测试集(test set)很显然就是指测试时所使用的数据集。
有了这三个数据集,我们就可以得出三个误差值(分别为):

其中,人类水平的误差(human level error)是人类自己处理这类问题的误差值;训练集误差(training set error)是指在训练集上跑出来的误差值;开发集误差(dev set error)是指用开发集跑出来的误差值。(测试集误差后面会说)
然而我们关注的并不是这个误差值本身,而是它们互相之间的差距。人类误差与训练集误差之间的差距称为「avoidable bias」(可避免的偏差,可简称为偏差)。之所以说「可避免的(avoidable)」,是因为这部分误差可以通过进一步的学习/模型调整优化来避免。而训练集和开发集之间的差距称为「variance(方差)」,它是因为跑了不同的数据而导致的误差率变化(比如跑在见过的数据集上和没见过的数据集上的误差率之差)。这两种偏差合在一起,就是机器学习领域著名的 bias-variance trade-off(偏差-方差权衡)。
那么,同样是这三组数据,如果你遇到的情况是:

(左边是 1%, 2%, 6% ; 右边是 1%, 6%, 10%)
左边的情况是:训练集误差率与人类自己的误差率只相差 1%,然而训练集误差跟测试集误差却差了很多;这就意味着你的模型在新的(没见过)的数据上表现很不好,换句话说,你的模型过拟合(overfitting)了。
而对于右边的情况,如果你的训练集误差跟人类误差值相比就已经差了很多,而测试集误差则更加地多,那么,洗洗睡吧,这模型没戏。
吴恩达博士表示,很多企业都不遵循他上文提到的这个洞察误差值区别的配方(recipe)。如果大家都能够科学地量化并且重视起这个误差差值的话,在工业应用开发上就会省事很多。
于是,他给出了这个洞察偏差值的配方的具体操作步骤:
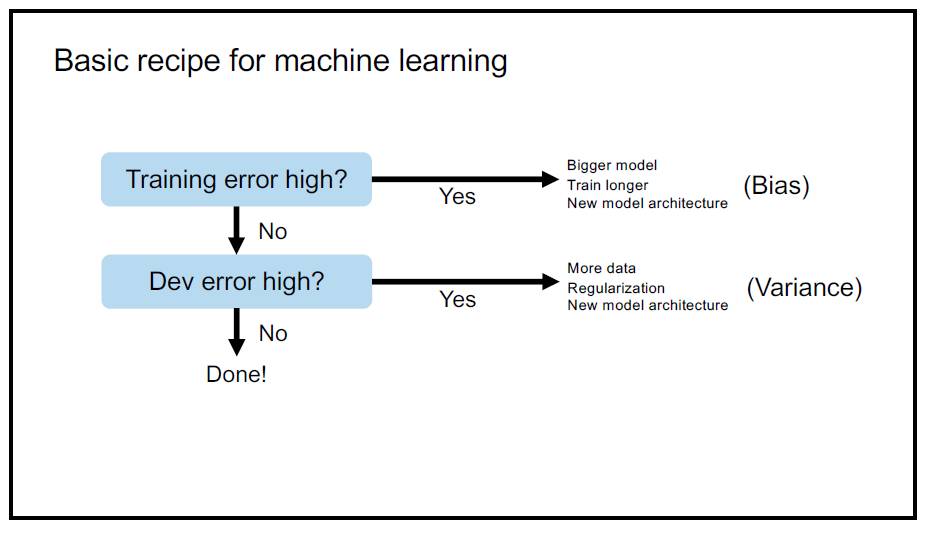
P9:机器学习的基本配方:如果训练误差高(偏差),就使用更大的模型、训练更长的时间、采用新的模型架构;如果开发误差高(方差),就使用更多数据、正则化、新的模型架构。
首先,判断训练集误差率是否过高?如果是的话,说明你遇到了 bias 危机,你可以(OR 的逻辑关系):
1. 提高你的模型规模;
2. 加长你的模型训练时间;
3. 启用新的模型构架。
如果训练集误差率不很高,那么,开发集误差是否很高?如果是的话,说明你遇到了 variance 危机,你可能需要(OR 的逻辑关系):
1. 拿更多的数据;
2. 正则化;
3. 启用新模型。
数据合成(Data Synthesis)
什么是数据合成?举个例子,在语音识别领域,用清晰的声音记录来做训练集是不给力的。因为在应用场景中,不会有那么安静的背景环境。所以需要人为添加一些噪音。这些噪音在人类的眼里没什么大问题,但是对机器学习算法来说,却是个大大的考验。
类似的例子还有:

P10:自动数据合成的例子。OCR:将文本插入随机背景中;语音识别:将清晰的音频混入不同的背景噪声中;NLP:语法纠错:合成随机的语法错误。有时候,一些在人眼看来很好的合成数据实际上对机器学习算法来说是信息不足的,而且只涵盖了实际数据分布的一小部分。比如说,从视频游戏中提取出来的汽车图像。
讲到这里,吴博士突然又插播了一条人生经验:我们企业呀,不要整天想搞个大新闻,东边一个服务器,西边一个服务器,显得自己很国际化。可是这样搞得数据很不统一。他十分建议企业都使用 unified data warehouse(统一化的数据中心),让数据科学家可以安心的玩数据。
经验分享介绍后,吴博士具体举个了智能后视镜的例子:如果我们要做个智能后视镜(语音操作的车内智能助手),我们的数据该怎么搞?
首先,假设我们有 50000 小时的语音资料(随便在哪里下载来的)和 10 小时的车内对着后视镜讲话的语音资料(比如,让客户假装他的后视镜是智能的,然后录下一些语音指令……)。面对这些数据,我们该如何构造我们的训练集?

有人可能会这样说:50000 小时语料够大,可以分出一些来做开发集(dev set),其他的用来训练。而 10 小时珍贵的车内语音则做成测试集。
错!这是个非常不好的处理方式,因为你的开发集和测试集没能遵从相同的数据分布(distribution)。换句话说,开发集和测试集的内容「根本就不在同一个宇宙」。这样的结果就是,你的数据工程师在开发集上花费了很大的精力之后,结果放到测试集上却发现并没有什么用。
一个比较靠谱的处理方式应该是:

把 10 小时的车内语料分成开发集和测试集。同时,你也可以拿出训练集中的一部分内容作为训练-开发集(train-dev set)。这个数据集能帮助你的算法在训练集上做好优化,再转移到真实场景中。
按照这个构架,我们于是可以得到五种不同的误差值:

人类误差、训练集误差,训练-开发集误差、开发集误差、测试集误差
其中,人类误差与训练集误差之间的差值还是称为 bias(偏差);训练集误差与训练-开发误差之间的差值称为「训练集的过拟合」(也就是说,它代表了模型单纯在训练集上表现能力);训练-开发误差与开发集误差之间的差值称为「data mismatch」(数据不匹配,就是刚才说的两组数据不在同一个「宇宙」带来的偏差);开发集误差与测试集误差之间的差值称为「开发集过拟合」(同理)。
这个时候,拥有的差值就更多了,我们就需要一个新的处理策略:
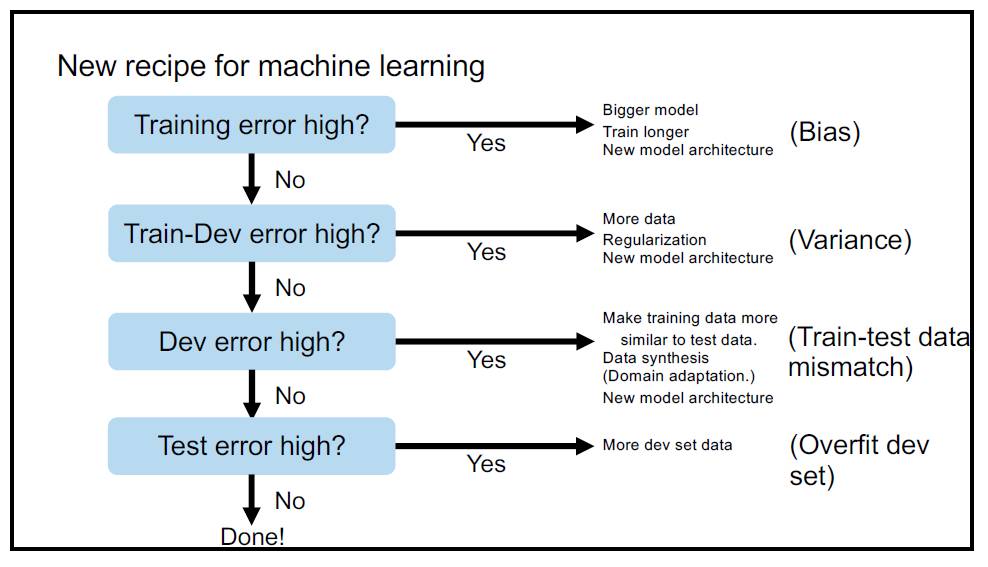
P13:用于机器学习的新配方:如果训练误差高(偏置),就使用更大的模型、训练更长时间、使用新的模型架构;如果训练-开发误差高(方差),就使用更多数据、正则化、新的模型架构;如果开发误差高(训练-测试数据不匹配),就使训练数据更近似于测试数据、进行数据合成(域适应)、使用新的模型架构。
当你遇到数据不匹配(data mismatch)时,你可以:
1. 让你的训练集跟测试集更加相似;
2. 数据合成;
3. 尝试新模型。
而这时候,如果你又遇到了测试集误差太高的情况,那么你就只能寻求更多的测试集了。
总结一下以上内容,我们可以得出下面这张表:
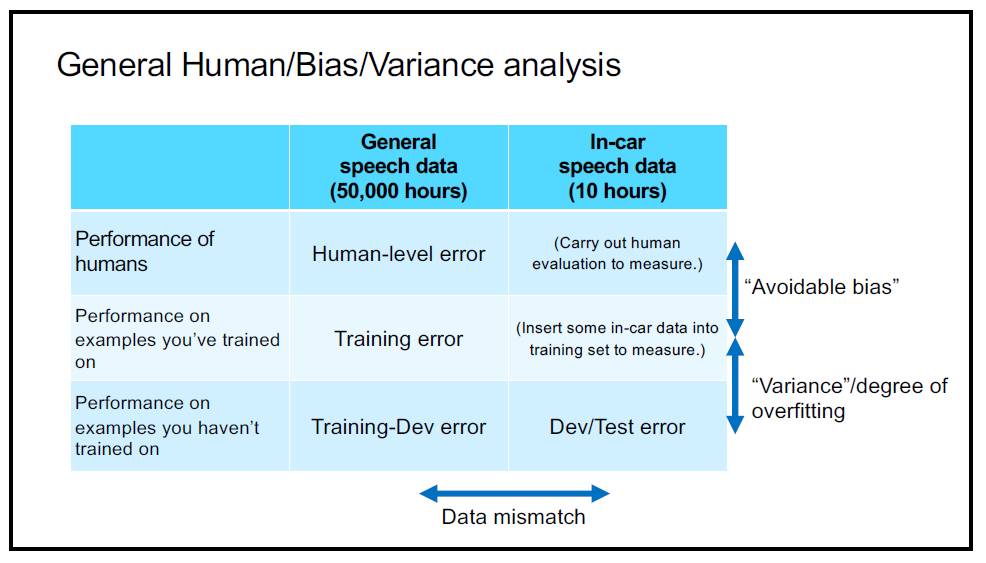
P14:一般的人类/偏差/方差分析
人类水平的表现(Humen-Level performance)
对于人类误差和机器学习误差,你会发现一个规律:
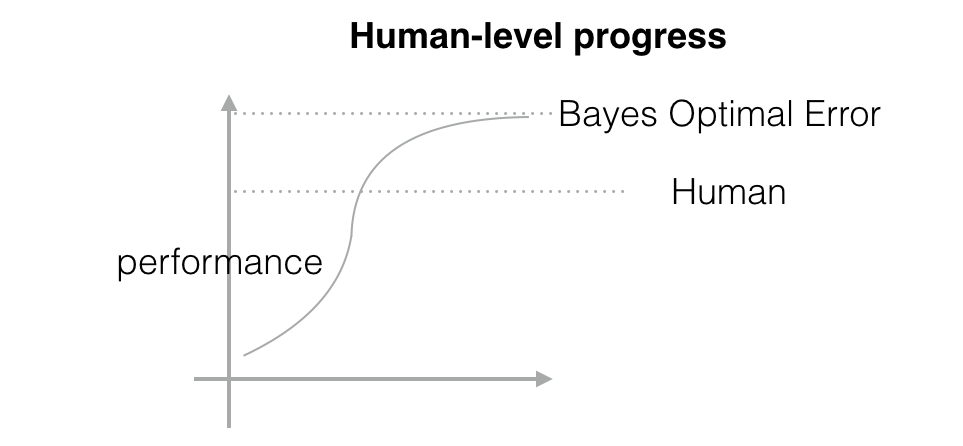
当机器学习比人类水平低时,它的准确率的提升是很快的。但是当它超越人类以后,往往准确率提升效率就逐步降低了。并且,在人类水平线的上方,有一个叫 Bayes Optimal Error(贝叶斯最优误差)的线,这是我们人和机器学习都永远无法逾越的。

这一切的原因有二:
1. 机器学习超越人类以后,很快就会靠近贝叶斯最优误差线,这是一条理论上无法逾越的线。
2. 数据带有人类自己做的标签(label),所以本身就含有人类自己的见解(insight)。

P16:小测试:医学成像
在医学领域,如果我们想用深度学习来观察医学图像并作出判断,那么,以下哪一种应该被我们选作人类的误差值(human-level error)?
1. 一个普通人 3%
2. 一个普通医生 1%
3. 一个专家医生 0.7%
4. 一个医生专家组 0.5%
答案:选 4.
因为 4 是人类能达到的最大限度,也是最靠近 Bayes Error 线的地方。我们做机器学习的目的就是要让我们的误差率无限接近于 Bayes Error 线。
关于人工智能的未来
讲到这里,吴恩达教授又顺便展望了一下人工智能的未来:
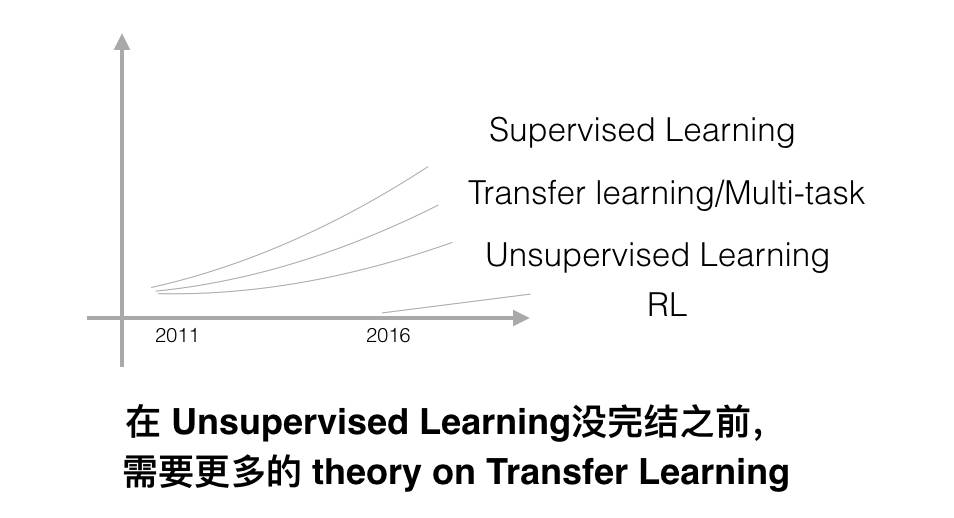
他说,从 2011 年以来,supervised learning(监督学习)是发展得最快的。也将继续快速发展下去,因为现有的有标签数据还远远没有被发掘完毕。
当然,他也不否认,真正的人工智能未来还是会落在 unsupervised learning(无监督学习)和 reinforcement learning(强化学习)上。但是,很明显,如我们所知,这两个领域目前的水平跟有监督的深度学习是完全没法比的。他预测这两个领域会在 2016 年以后逐步起飞。其中强化学习飞得慢点,因为目前大多数强化学习都还仅仅被运用在电子游戏模拟上,而无监督学习似乎是起点高一点,因为我们熟知的很多算法就已经是无监督学习了(比如:word2vec)。
然而,在这一切还没有成熟之前,他认为还有一个折中的处理方法:迁移学习(transfer learning)。简单来说,就是把有标签或者数据量大的集合用于预训练(pre-train),然后在此基础上对真正的目标数据集进行无监督优化。相比于完全的无监督,这条路似乎更有希望。说到这里,吴恩达博士又振臂一呼:希望学界能在迁移学习上产出更多高质量的理论与论文。
人工智能产品管理(AI product management)
最后,吴博士讲了人工智能领域的产品经理应该做些什么。他们被赋予了更多的职责,需要做更多的思考。
一个人工智能产品经理的工作流:
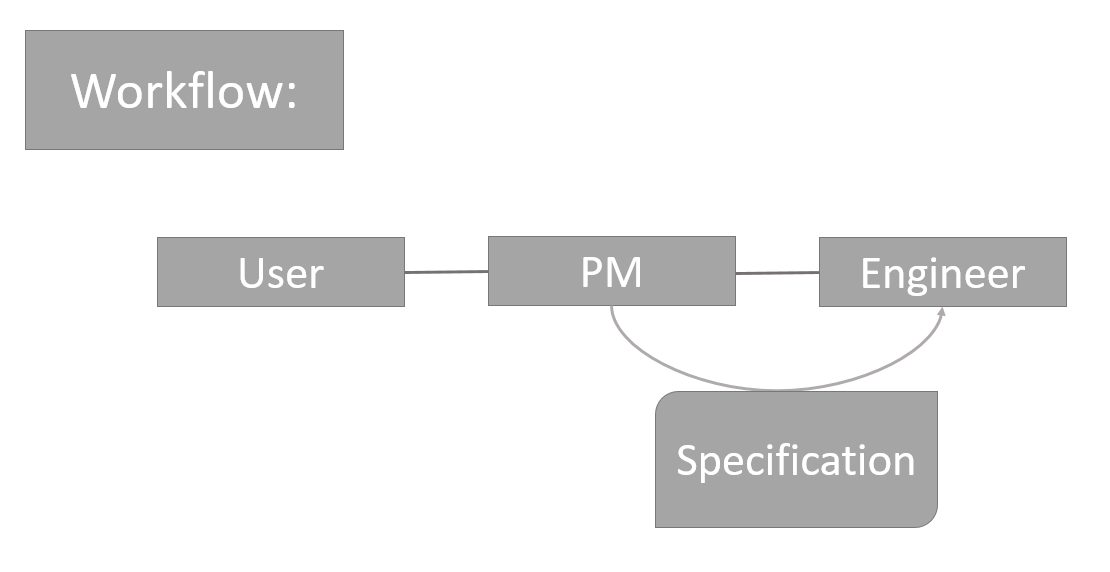
跟一般的产品经理类似,PM 对用户负责,并将需求反馈给工程师。
举个例子,在做语音识别的时候,我们可以选择:
-
不同的噪音背景
-
重点关注的口音
-
语音文件的大小
-
等等
人工智能产品经理需要选择工程师应该关注的重点,从而让数据集能更准确地模拟出应用场景。简单来说就是寻找用户需求与当今机器学习技术的能力的交集:
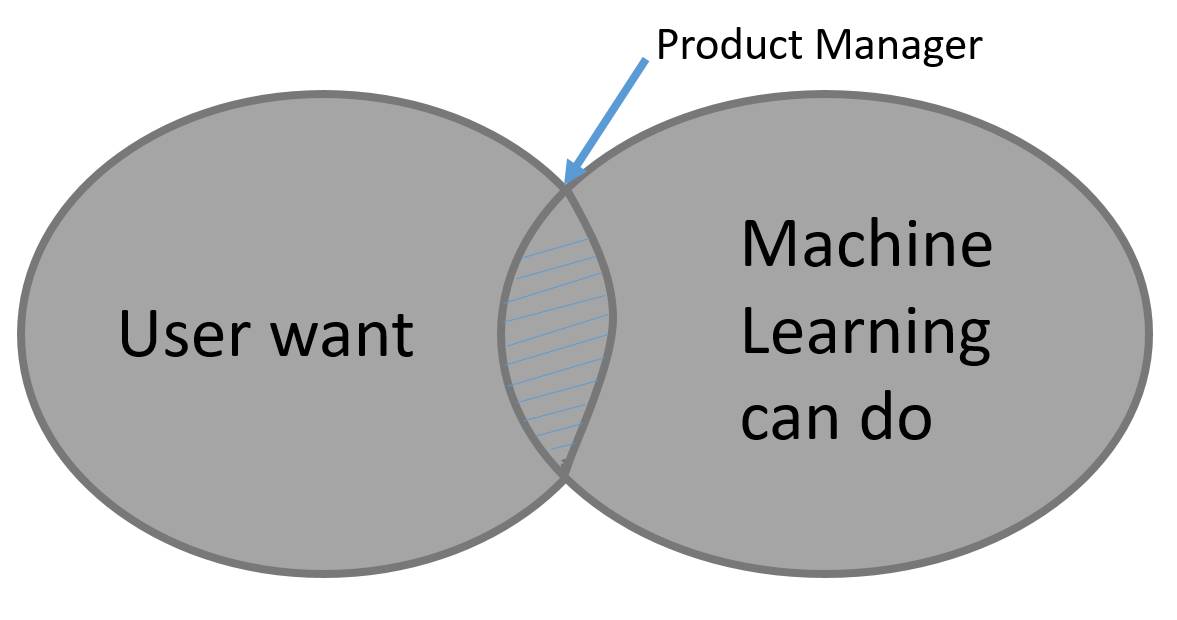
具体来讲,一个人工智能产品经理的任务如下:

产品经理需要提供出靠谱的测试和开发集,并提出靠谱的验证方法(metrics)。相应地,工程师就会依照这个需求,来获取他们需要的训练集,并开发靠谱的人工智能系统。
最后,吴恩达博士在演讲幻灯片最后一页推荐了他的新书《Machine Learning Yearning》,对于人工智能产品设计理念及策略有兴趣的读者,可以在 http://www.mlyearning.org/ 免费订阅一部分。

总结
总体来说,吴恩达博士的这场 tutorial 非常客气地照顾到了人数庞大的工业界听众。具体的点都放在了人工智能产品开发的策略与技巧上,并还时不时地插入了几句人生经验。可见,他在谷歌和百度的这些年正在将他一步步从一位顶尖的学界大拿跨界成一位顶尖的产品人。
posted on 2016-12-06 22:09 alexanderkun 阅读(1208) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号