PCA和Whitening
PCA:
PCA的具有2个功能,一是维数约简(可以加快算法的训练速度,减小内存消耗等),一是数据的可视化。
PCA并不是线性回归,因为线性回归是保证得到的函数是y值方面误差最小,而PCA是保证得到的函数到所降的维度上的误差最小。另外线性回归是通过x值来预测y值,而PCA中是将所有的x样本都同等对待。
在使用PCA前需要对数据进行预处理,首先是均值化,即对每个特征维,都减掉该维的平均值,然后就是将不同维的数据范围归一化到同一范围,方法一般都是除以最大值。但是比较奇怪的是,在对自然图像进行均值处理时并不是不是减去该维的平均值,而是减去这张图片本身的平均值。因为PCA的预处理是按照不同应用场合来定的。
自然图像指的是人眼经常看见的图像,其符合某些统计特征。一般实际过程中,只要是拿正常相机拍的,没有加入很多人工创作进去的图片都可以叫做是自然图片,因为很多算法对这些图片的输入类型还是比较鲁棒的。在对自然图像进行学习时,其实不需要太关注对图像做方差归一化,因为自然图像每一部分的统计特征都相似,只需做均值为0化就ok了。不过对其它的图片进行训练时,比如首先字识别等,就需要进行方差归一化了。
PCA的计算过程主要是要求2个东西,一个是降维后的各个向量的方向,另一个是原先的样本在新的方向上投影后的值。
首先需求出训练样本的协方差矩阵,如公式所示(输入数据已经均值化过):
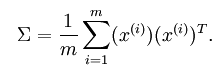
求出训练样本的协方差矩阵后,将其进行SVD分解,得出的U向量中的每一列就是这些数据样本的新的方向向量了,排在前面的向量代表的是主方向,依次类推。用U’*X得到的就是降维后的样本值z了,即:
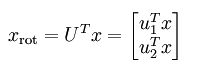
(其实这个z值的几何意义是原先点到该方向上的距离值,但是这个距离有正负之分),这样PCA的2个主要计算任务已经完成了。用U*z就可以将原先的数据样本x给还原出来。
在使用有监督学习时,如果要采用PCA降维,那么只需将训练样本的x值抽取出来,计算出主成分矩阵U以及降维后的值z,然后让z和原先样本的y值组合构成新的训练样本来训练分类器。在测试过程中,同样可以用原先的U来对新的测试样本降维,然后输入到训练好的分类器中即可。
有一个观点需要注意,那就是PCA并不能阻止过拟合现象。表明上看PCA是降维了,因为在同样多的训练样本数据下,其特征数变少了,应该是更不容易产生过拟合现象。但是在实际操作过程中,这个方法阻止过拟合现象效果很小,主要还是通过规则项来进行阻止过拟合的。
并不是所有ML算法场合都需要使用PCA来降维,因为只有当原始的训练样本不能满足我们所需要的情况下才使用,比如说模型的训练速度,内存大小,希望可视化等。如果不需要考虑那些情况,则也不一定需要使用PCA算法了。
Whitening:
Whitening的目的是去掉数据之间的相关联度,是很多算法进行预处理的步骤。比如说当训练图片数据时,由于图片中相邻像素值有一定的关联,所以很多信息是冗余的。这时候去相关的操作就可以采用白化操作。数据的whitening必须满足两个条件:一是不同特征间相关性最小,接近0;二是所有特征的方差相等(不一定为1)。常见的白化操作有PCA whitening和ZCA whitening。
PCA whitening是指将数据x经过PCA降维为z后,可以看出z中每一维是独立的,满足whitening白化的第一个条件,这是只需要将z中的每一维都除以标准差就得到了每一维的方差为1,也就是说方差相等。公式为:
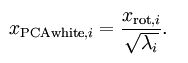
ZCA whitening是指数据x先经过PCA变换为z,但是并不降维,因为这里是把所有的成分都选进去了。这是也同样满足whtienning的第一个条件,特征间相互独立。然后同样进行方差为1的操作,最后将得到的矩阵左乘一个特征向量矩阵U即可。
ZCA whitening公式为:

posted on 2015-10-09 20:44 alexanderkun 阅读(428) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号