网络流,二分图与图的匹配
CHANGE LOG
- 2021.12.5:更换模板代码。新增二分图部分。
- 2022.1.11:重构网络流部分。新增网络流的应用与模型。
- 2022.1.1.13:新增上下界网络流部分。
- 2022.5.11:重构网络流部分,更换模板代码。
- 2022.6.1:重构二分图部分,修改事实性错误。补充 dinic 算法的复杂度证明。
- 2022.7.17:新增图的匹配部分。
- 2022.8.31:新增 Hopcroft-Karp 算法。
1. 网络流
网络流的核心在于建图。建图是精髓,建图是人类智慧。
网络流的建图方法一定程度上刻画了贪心问题的内在性质,从而简便地支持了 反悔,不需要我们为每道贪心问题都寻找反悔策略。
1.1 基本定义
一个网络是一张 有向图 \(G = (V, E)\),对于每条有向边 \((u, v)\in E\) 存在 容量限制 \(c(u, v)\)。特别的,若 \((u, v)\notin E\),则 \(c(u, v) = 0\)。
网络的可行流分为有源汇(通常用 \(S\) 表示源点,\(T\) 表示汇点)和无源汇两种,但无论哪一种,其对应的 流函数 \(f\) 均具有以下三个性质:
- 首先给出定义,流函数 \(f:(u, v)\to \R\) 是从二元 有序对 \((u, v)\) 向实数集 \(\R\) 的映射,其中 \(u, v\in V\)。\(f(u, v)\) 称为边 \((u, v)\) 的 流量。
- \(f\) 满足 容量限制:\(f(u, v)\leq c(u, v)\)。每条边的流量不能超过容量。若 \(f(u, v) = c(u, v)\),则称边 \((u, v)\) 满流。
- \(f\) 具有 斜对称 性质:\(f(u, v) = -f(v, u)\)。\(u\to v\) 有 \(1\) 的流量,也可称 \(v\to u\) 有 \(-1\) 的流量。
- \(f\) 具有 流量守恒 性质:除源汇点外(无源汇网络流则不存在源汇点),从每个节点流入和流出的流量相等,即 \(\forall i \neq S, T, \sum f(u, i) = \sum f(i, v)\)。每个节点 不储存流量,流进多少就流出多少。
以下是一些网络流相关定义。
-
对于 有源汇 网络,根据斜对称和容量守恒性质,可以得到 \(\sum f(S, i) = \sum f(i, T)\),此时这个相等的和称为当前流 \(f\) 的 流量。
-
定义流 \(f\) 在网络 \(G\) 上的 残量网络 \(G_f = (V, E_f)\) 为容量函数等于 \(c_f = c - f\) 的网络。根据容量限制,我们有 \(c_f(u, v) \geq 0\)。若 \(c_f(u, v) = 0\),则视 \((u, v)\) 在残量网络上不存在,\((u, v)\notin E_f\)。换句话说,将每条边的容量减去流量后,删去满流边即可得到残量网络。
-
定义 增广路 \(P\) 是残量网络 \(G_f\) 上从 源点 \(S\) 到 汇点 \(T\) 的一条路径。无源汇网络流不讨论增广路。
-
将 \(V\) 分成 互不相交 的两个点集 \(A, B\),其中 \(S\in A\),\(T\in B\),这种点的划分方式叫做 割。定义割的 容量 为 \(\sum \limits_{u\in A} \sum \limits_{v\in B} c(u, v)\),流量 为 \(\sum\limits_{u \in A}\sum_\limits{v \in B} f(u, v)\)。若 \(u, v\) 所属点集不同,则称有向边 \((u, v)\) 为 割边。
接下来的讨论大部分与有源汇网络流相关。对于无源汇网络流,见 1.5.1 小节无源汇网络流部分。
1.2 网络最大流
网络最大流相关算法,最著名的是 Edmonds-Karp 和 dinic。对于更高级的 SAP / ISAP / HLPP,此处不做介绍。
给定网络 \(G = (V, E)\) 和源汇,求最大流量(Maximum flow,简称 MF)。
1.2.1 增广
接下来要介绍的两个算法均使用了 不断寻找增广路 和 能流满就流满 的贪心思想。
具体地,找到残量网络 \(G_f\) 上的一条增广路 \(P\),并为 \(P\) 上的每一条边增加 \(c_f(P) = \min \limits_{(u, v)\in P} c_f(u, v)\) 的流量。如果增加的流量大于该值,一些边将不满足容量限制,而根据能流满就流满的思想,增加的流量也不应小于该值。
我们在增广的过程中尽量流满一条增广路,同时每条边的流量在增广过程中不会减少。贪心的正确性如何保证?
在为当前边 \((u, v)\in P\) 增加 流量 \(c_f(P)\) 时,我们需要给其反边 \((v, u)\) 的 容量 加上 \(c_f(P)\),这样的目的是 支持反悔,收回给出的一部分流量。体现在 \(G_f\) 上,就是新的 \(G_{f'}\) 的 \(c_{f'}(u, v)\) 相较于 \(c_f(u, v)\) 减少了 \(c_f(P)\),而 \(c_{f'}(v, u)\) 相较于 \(c_f(v, u)\) 增加了 \(c_f(P)\)。
上述操作称为一次 增广。
关于增广有一个常用技巧:成对变换。网络流建图一般使用链式前向星,我们将每条边与它的反向边按编号连续存储,编号分别记为 \(k\) 和 \(k+1\),其中 \(2\mid k\),从而快速求得 \(k\) 的反向边编号为 \(k\ \mathrm{xor}\ 1\)。为此,初始边数 cnt 应设为 \(1\),这一点千万不要忘记!
1.2.2 最大流最小割定理
在介绍 EK 和 dinic 之前,我们还需要一个贯穿网络流始终的最核心,最基本的结论:最大流等于最小割。
-
任意一组流的流量 不大于 任意一组割的容量:
考虑每单位流量,设其经过 \(u\in A, v\in B\) 的割边 \(u\to v\) 的次数为 \(\mathrm{to}\),经过 \(v\to u\) 的割边次数为 \(\mathrm{back}\)。必然有 \(\mathrm{to} = \mathrm{back} + 1\),否则不可能从 \(S\) 流到 \(T\)。
根据斜对称性质与割的流量的定义,每单位流量对割边流量之和的贡献为 \(\mathrm{to} - \mathrm{back} = 1\),因此网络总流量等于割边流量之和。
对每一种流的方案均应用上述结论,并根据容量限制,推出流的流量 \(\leq\) 割的容量。
-
存在一组流的流量 等于 一组割的容量:
我们断言最大流存在,此时 残量网络不连通:若连通则可以继续增广,与最大流的最大性矛盾。这为我们自然地提供了一组割,使其容量等于流量,即当前可行流的流量。
综上,结论得证。
1.2.3 Edmonds-Karp
1.2.3.1 算法简介
Edmonds-Karp 算法的核心是使用 bfs 寻找 长度最短 的增广路。为此,我们记录流向每个点的边的编号,然后从汇点 \(T\) 不断反推到源点 \(S\)。时间复杂度 \(\mathcal{O}(n m ^ 2)\)。
注意,任意选择增广路增广,复杂度将会退化成和流量相关(朴素的 FF 算法),因为 EK 的复杂度证明需要用到增广路长度最短的性质。
模板题 P3381 网络最大流 代码如下。
#include <bits/stdc++.h>
using namespace std;
const int N = 200 + 5, M = 5e3 + 5;
struct flow {
long long fl[N], limit[M << 1];
int cnt = 1, hd[N], nxt[M << 1], to[M << 1], fr[N];
void add(int u, int v, int w) {
nxt[++cnt] = hd[u], hd[u] = cnt, to[cnt] = v, limit[cnt] = w;
nxt[++cnt] = hd[v], hd[v] = cnt, to[cnt] = u, limit[cnt] = 0;
}
long long maxflow(int s, int t) {
long long flow = 0;
while(1) {
queue<int> q;
memset(fl, -1, sizeof(fl));
fl[s] = 1e18, q.push(s);
while(!q.empty()) {
int t = q.front();
q.pop();
for(int i = hd[t]; i; i = nxt[i]) {
int it = to[i];
if(limit[i] && fl[it] == -1) { // 剩余流量为 0,在残量网络上不存在,不能走
fl[it] = min(limit[i], fl[t]); // 记录流量
fr[it] = i, q.push(it); // 记录流向每个点的边
}
}
}
if(fl[t] == -1) return flow;
flow += fl[t];
for(int u = t; u != s; u = to[fr[u] ^ 1]) limit[fr[u]] -= fl[t], limit[fr[u] ^ 1] += fl[t]; // 从 T 一路反推到 S,并更新每条边的剩余流量
}
}
} g;
int n, m, s, t;
int main() {
cin >> n >> m >> s >> t;
for(int i = 1; i <= m; i++) {
int u, v, w;
cin >> u >> v >> w, g.add(u, v, w);
}
cout << g.maxflow(s, t) << endl;
return 0;
}
1.2.3.2 复杂度证明
为证明 EK 的时间复杂度,我们需要这样一条引理:每次增广后残量网络上 \(S\) 到每个节点的最短路长度 不减。
考虑反证法,假设存在节点 \(x\) 使得 \(G_{f'}\) 上 \(S\to x\) 的最短路 \(dis'_x\) 小于 \(G_f\) 上 \(S\to x\) 的最短路 \(dis_x\),则必然存在 \(x\) 使得在 \(G_{f'}\) 上 \(S\to x\) 的最短路上除了 \(x\) 以外的节点 \(y\) 均满足 \(dis_y\leq dis'_y\)。设 \(y\) 是 \(G_{f'}\) 上 \(S\to x\) 的最短路上 \(x\) 的上一个节点,则 \(dis_x' = dis_y' + 1\)。
若 \((y, x)\in E_f\),则 \(dis_x\leq dis_y + 1\),有 \(dis_y' + 1 = dis_x' < dis_x\leq dis_y + 1\),得出 \(dis_y' < dis_y\),矛盾,因此有向边 \((y, x)\) 不在原来的残量网络 \(G_f\) 上。因为 \((y, x)\in E_{f'}\),所以 \((x, y)\) 必然被增广,即 \(dis_x + 1 = dis_y\)(增广路是最短路),所以 \(dis_y' + 1 = dis_x < dis_x = dis_y - 1\),与 \(dis_y\leq dis'_y\) 矛盾。引理证毕。
接下来证明 EK 的复杂度。
不妨设某次增广的增广路为 \(P\)。根据能流满就流满的原则,存在 \((x, y)\) 使其当前剩余流量 \(c_f(x, y)\) 等于本次增广流量 \(c_f(P)\)。这使得 \((x, y)\) 属于原来的残量网络,但不在增广后的残量网络上。我们称这种边为 关键边。
因为增广路是最短路,我们有 \(dis_x + 1 = dis_y\)。设使得 \((x, y)\) 再一次出现在增广路径上的增广对应的残量网络为 \(G_{f'}\)(增广前)。此时 \(dis_y' + 1 = dis_x'\),因为 \((y, x)\) 即将被增广。
根据引理,\(dis_y' \geq dis_y\),因此 \(dis_x' - 1 \geq dis_x + 1\),即 \((x, y)\) 每次在残量网络上消失又出现必然使得 \(dis_x\) 至少增加 \(2\)。
综上,每条边作为关键边的次数不超过 \(\mathcal{O}(n)\)。因为一次增广必然存在关键边,所以总增广次数不超过 \(\mathcal{O}(nm)\),时间复杂度 \(\mathcal{O}(nm ^ 2)\)。
1.2.4 Dinic
1.2.4.1 算法介绍
Dinic 算法的核心思想是 分层图 以及 相邻层之间增广,通过 bfs 和 dfs 实现。首先 bfs 给图分层,分层后从 \(S\) 开始 dfs 多路增广。维护当前节点和剩余流量,向下一层节点继续流。
给图分层的目的是将网络视作 DAG,规范增广路的形态,防止流成一个环。
Dinic 算法有重要的 当前弧优化。增广时,容量等于流量的边无用,可直接跳过,不需要每次搜索到同一个点时都从邻接表头开始遍历。为此,记录从每个点出发第一条没有流满的边,称为 当前弧。每次搜索到一个节点就从其当前弧开始增广。
注意,每次多路增广前每个点的当前弧应初始化为邻接表头,因为并非一旦流量等于容量,这条边就永远无用。反向边流量的增加会让它重新出现在残量网络中。
当前弧优化后的 dinic 时间复杂度 \(\mathcal{O}(n ^ 2m)\)。若不加当前弧优化,时间复杂度会退化至和 EK 一样的 \(\mathcal{O}(nm ^ 2)\)。此时由于 dfs 常数过大,实际表现并没有 EK 优秀。
- Dinic 实际上蕴含了 EK,因为 dinic 本质也是不断找最短路增广。相较于 EK,dinic 使用了多路增广和当前弧优化两个技巧。
1.2.4.2 当前弧优化的注意点
for(int i = cur[u]; res && i; i = nxt[i]) {
cur[u] = i;
// do something
}
上述代码不可以写成
for(int &i = cur[u]; res && i; i = nxt[i]) {
// do something
}
因为若 \(u\to v\) 这条边让剩余流量 res 变成 \(0\),第二种写法会使 \(u\) 的当前弧直接跳过 \((u,v)\),但 \((u,v)\) 不一定流满,所以不应跳过。这会导致当前弧跳过很多未流满的边,使增广效率降低,从而大幅降低程序运行效率。实际表现比 EK 还要差。
另一种解决方法是在循环末尾判断 if(!res) return flow;。总之,在写当前弧优化时千万注意不能跳过没有流满的边。
模板题 P3381 网络最大流 代码如下。
#include <bits/stdc++.h>
using namespace std;
const int N = 200 + 5, M = 5e3 + 5;
struct flow {
int cnt = 1, hd[N], nxt[M << 1], to[M << 1], limit[M << 1];
void add(int u, int v, int w) {
nxt[++cnt] = hd[u], hd[u] = cnt, to[cnt] = v, limit[cnt] = w;
nxt[++cnt] = hd[v], hd[v] = cnt, to[cnt] = u, limit[cnt] = 0;
}
int T, dis[N], cur[N];
long long dfs(int id, long long res) {
if(id == T) return res;
long long flow = 0;
for(int i = cur[id]; i && res; i = nxt[i]) {
cur[id] = i;
int c = min(res, (long long) limit[i]), it = to[i];
if(dis[id] + 1 == dis[it] && c) {
int k = dfs(it, c);
flow += k, res -= k, limit[i] -= k, limit[i ^ 1] += k;
}
}
if(!flow) dis[id] = -1;
return flow;
}
long long maxflow(int s, int t) {
T = t;
long long flow = 0;
while(1) {
queue<int> q;
memcpy(cur, hd, sizeof(hd));
memset(dis, -1, sizeof(dis));
q.push(s), dis[s] = 0;
while(!q.empty()) {
int t = q.front();
q.pop();
for(int i = hd[t]; i; i = nxt[i])
if(dis[to[i]] == -1 && limit[i])
dis[to[i]] = dis[t] + 1, q.push(to[i]);
}
if(dis[t] == -1) return flow;
flow += dfs(s, 1e18);
}
}
} g;
int n, m, s, t;
int main() {
cin >> n >> m >> s >> t;
for(int i = 1; i <= m; i++) {
int u, v, w;
cin >> u >> v >> w, g.add(u, v, w);
}
cout << g.maxflow(s, t) << endl;
return 0;
}
1.2.4.3 复杂度证明
Dinic 的复杂度证明也是一个技术活。
在证明 EK 的时间复杂度时,我们使用了一个引理,就是 \(S\) 到每个节点的最短路单调不减。因为 dinic 蕴含 EK,所以该引理仍然成立。
我们现在尝试证明对于 dinic 的一次增广,\(S\) 到 \(T\) 的最短路增加。
反证法,假设存在一次增广使得 \(S\) 到 \(T\) 的最短路没有增加。由引理,\(S\) 到 \(T\) 的最短路不变。称其为结论 1。
考察 增广后 的一条从 \(S\) 到 \(T\) 的最短路 \(P = \{S = p_0\to p_1 \to \cdots \to p_{k - 1} \to p_k = T\}\),此时 \(S\to p_i\) 的最短路 \(dis'(p_i)\) 等于 \(i\),\(S\to T\) 的最短路 \(dis'(T)\) 等于 \(k\)。
由引理,增广前 \(S\) 到 \(p_i\) 的最短路 \(dis(p_i) \leq i\)。由结论 1,\(dis(T) = dis'(T) = k\)。
若对于所有 \(i\) 均有 \(dis(p_i) = i\),则根据 dinic 的算法流程,\(P\) 在本轮增广中被增广。因此,\(P\) 必然存在一条边不在增广后的残量网络上,这与增广后 \(P\) 是一条从 \(S\) 到 \(T\) 的最短路矛盾,因为 \(P\) 甚至不连通。
因此,存在 \(dis(p_i) < i(0 < i < k)\)(\(k = 1\) 时可以直接导出矛盾)。又因为 \(dis(p_k) = k\),所以必然存在 \(x\) 和 \(x + 1\) 满足 \(dis(p_x) + 2 \leq dis(p_{x + 1})\),即 \((p_x, p_{x + 1})\) 不在原来的残量网络上。
又因为增广后 \((p_x, p_{x + 1})\) 在残量网络上,所以 \((p_{x + 1}, p_x)\) 被增广,即 \(dis(p_{x + 1}) + 1 = dis(p_x)\)。这与 \(dis(p_{x + 1}) - 2 \geq dis(p_x)\) 矛盾,证毕。
- 上述证明中我们没有用到 \(T\) 的任何性质,故同理可证一轮增广从 \(S\) 到每个点的最短路增加,前提是 \(S\) 在增广前可达该点。
这样,我们证明了增广轮数为 \(\mathcal{O}(n)\) 级别。接下来考虑一轮增广的复杂度,这部分比较好证。
对于本身就没有流量的边,使用当前弧优化后这些边造成的总复杂度为 \(\mathcal{O}(m)\),因为我们只用花 \(\mathcal{O}(1)\) 的代价跳过这些边。
dfs 时,每次到达 \(T\) 都代表找到一条增广路。我们将寻找这条增广路的代价放缩至增广路的长度,即 \(\mathcal{O}(n)\)。实际远达不到这一上界(但仍然是 \(\mathcal{O}(n)\)。达不到上界指常数非常小),毕竟 dfs 一棵树的复杂度不是所有叶子的深度之和,类似理解在图上 dfs 的情况。
找到增广路后,我们将回溯至增广路上第一条关键边(因为没有剩余流量了),并将所有关键边的流量置为零。这些关键边会在第二次遍历到时被直接跳过,这部分,即跳过已经作为某次增广的关键边的边的总复杂度同样为 \(\mathcal{O}(m)\)。
只剩下增广的复杂度还没有计入。每条边最多会作为一次增广的关键边,即到达 \(T\) 的次数为 \(\mathcal{O}(m)\),因此一次增广的复杂度为增广复杂度和增广路条数之积 \(\mathcal{O}(nm)\)。从分析过程即可看出这个上界非常松,这也是为什么 Dinic 在求解网络最大流时表现非常好。
1.3 无负环的费用流
费用流一般指 最小费用最大流(Minimum cost maximum flow,简称 MCMF)。
相较于一般的网络最大流,在原有网络 \(G\) 的基础上,每条边多了一个属性:权值 \(w(x,y)\)。最小费用最大流在要求我们在 保证最大流 的前提下,求出 \(\sum_\limits{(x,y)\in E} f(x, y)\times w(x, y)\) 的最小值。
简单地说,\(w\) 就是每条边流 \(1\) 单位流量的费用。我们需要最小化这一费用,因此被称为费用流。
1.3.1 SSP
1.3.1.1 算法介绍
连续最短路算法 Successive Shortest Path,简称 SSP。这一算法的核心思想是每次找到 长度最短的增广路 进行增广,且仅在网络 初始无负环 时能得到正确答案。
SSP 算法有两种实现,一种基于 EK 算法,另一种基于 dinic 算法。这两种实现均要求将 bfs 换成 SPFA(每条边的长度即 \(w\)),且 dinic 的 dfs 多路增广仅在 \(dis_x + w(x, y) = dis_y\) 之间的边进行。
\(x\to y\) 在退流流过 \(y\to x\) 时费用也要退掉,所以对于原网络的每条边 \((x, y)\),其反边的权值 \(w(y, x)\) 应设为 \(-w(x, y)\)。
时间复杂度 \(\mathcal{O}(nmf)\),其中 \(f\) 为最大流流量。实际应用中此上界非常松,因为不仅增广次数远远达不到 \(f\),同时 SPFA 的复杂度也远远达不到 \(nm\),可以放心大胆使用。
OI 界一般以 dinic 作为网络最大流的标准算法,以基于 EK 的 SSP 作为费用流的标准算法。「最大流不卡 dinic,费用流不卡 EK」是业界公约。
注意,SPFA 在队首为 \(T\) 时不能直接 break,因为第一次取出 \(T\) 时 dis[T] 不一定取到最短路。
模板题 P3381 最小费用最大流 代码。
#include <bits/stdc++.h>
using namespace std;
const int N = 5e3 + 5, M = 5e4 + 5;
struct flow {
int cnt = 1, hd[N], nxt[M << 1], to[M << 1], limit[M << 1], cst[M << 1];
void add(int u, int v, int w, int c) {
nxt[++cnt] = hd[u], hd[u] = cnt, to[cnt] = v, limit[cnt] = w, cst[cnt] = c;
nxt[++cnt] = hd[v], hd[v] = cnt, to[cnt] = u, limit[cnt] = 0, cst[cnt] = -c;
}
int fr[N], fl[N], in[N], dis[N];
pair<int, int> mincost(int s, int t) {
int flow = 0, cost = 0;
while(1) { // SPFA
queue<int> q;
memset(dis, 0x3f, sizeof(dis));
memset(in, 0, sizeof(in));
fl[s] = 1e9, dis[s] = 0, q.push(s);
while(!q.empty()) {
int t = q.front();
q.pop(), in[t] = 0;
for(int i = hd[t]; i; i = nxt[i]) {
int it = to[i], d = dis[t] + cst[i];
if(limit[i] && d < dis[it]) {
fl[it] = min(limit[i], fl[t]), fr[it] = i, dis[it] = d;
if(!in[it]) in[it] = 1, q.push(it);
}
}
}
if(dis[t] > 1e9) return make_pair(flow, cost);
flow += fl[t], cost += dis[t] * fl[t];
for(int u = t; u != s; u = to[fr[u] ^ 1]) limit[fr[u]] -= fl[t], limit[fr[u] ^ 1] += fl[t];
}
}
} g;
int n, m, s, t;
int main() {
cin >> n >> m >> s >> t;
for(int i = 1; i <= m; i++) {
int u, v, w, c;
cin >> u >> v >> w >> c, g.add(u, v, w, c);
}
pair<int, int> ans = g.mincost(s, t);
cout << ans.first << " " << ans.second << endl;
return 0;
}
1.3.1.2 正确性证明
我们尝试证明每次增广 \(S\to T\) 长度最短的增广路,一定能求出最小费用最大流。根据最大流最小割定理可证流的最大性,因此只需证明流的费用最小性。
考虑两个流量相等的流 \(f_1, f_2\),令 \(\Delta f = f_2 - f_1\),则 \(\Delta f\) 由若干个正流环组成,因其流量为零。若 \(f_1\) 的费用大于 \(f_2\),则 \(\Delta f\) 包含至少一个正流负环,因其费用为负。
若流 \(f\) 的残量网络包含负环,在负环上增广可以得到流量相等但费用更小的流。相反,若流 \(f\) 不是费用最小的流,则存在流 \(f'\) 使得 \(\Delta f = f' - f\) 包含正流负环,推出 \(f\) 的残量网络有负环。因此,\(f\) 是所有流量与之相等的流费用最小的,当且仅当 \(f\) 的残量网络上不存在负环。
考虑归纳证明。假设增广前 \(f\) 的残量网络无负环,设增广后的流为 \(f'\)。
假设存在流 \(f''\) 的流量与 \(f'\) 相等但费用更小。考察 \(\Delta f' = f' - f\),\(\Delta f'' = f'' - f\)。因为 \(\Delta f'\) 取到 \(S\to T\) 的最短路,所以 \(\Delta f''\) 的 \(S\to T\) 的费用相较于 \(\Delta f'\) 不会更小。但 \(\Delta f''\) 的费用比 \(\Delta f'\) 小,所以 \(\Delta f''\) 存在正流负环,即 \(f\) 的残量网络存在负环,与假设矛盾。
因此,不存在流量与 \(f'\) 相等但费用更小的流。这同时也说明了 \(f'\) 的残量网络上无负环,推出下一轮增广的假设成立。由于初始假设成立,所以归纳假设成立。证毕。
1.3.2 Primal-Dual
建议先学习 Johnson 全源最短路算法,详见 初级图论。
和 SSP 一样,Primal-Dual 原始对偶算法也仅适用于 无负环 的网络。其核心为尝试为每个点赋一个 势能 \(h_i\),让原图的最短路不变且 边权非负。
使用 Johnson 全源最短路算法的思想,我们先用一遍 SPFA 求出源点到每个点的最短路 \(h_i\),则 \(i\to j\) 的新边权定为 \(w'_{i, j} = w_{i, j} + h_i - h_j\)。根据三角形不等式,显然 \(w'_{i, j} \geq 0\)。因此经过上述转化,我们可以使用更稳定的 Dijkstra 而非 SPFA 求解增广路。
找到增广路后,每次增广都会改变残量网络的形态。为此,我们用每次增广时 Dijkstra 跑出来的最短路加在 \(h\) 上,即 \(h'_i\gets h_i+dis_i\)。正确性证明如下。
- 如果 \(i\to j\) 在增广路上,有 \(dis_i + w_{i, j} + (h_i - h_j) = dis_j\)。由于 \(w_{i, j} = -w_{j, i}\),所以 \(w_{j, i} + (dis_j + h_j) - (dis_i + h_i) = 0\),即 反边边权为 \(0\)。
- 对于原有的边,我们有 \(dis_i + w_{i, j} + (h_i - h_j) \geq dis_j\),即 \(w_{i, j} + (dis_i + h_i) - (dis_j + h_j)\geq 0\),原边权仍然非负。
实际表现方面,Primal-Dual 相较于 SSP 并没有很大的优势,大概是因为 SPFA 本身已经够快了,且堆优化的 dijkstra 常数较大。
代码。
1.4 对网络流的理解
1.4.1 网络流与贪心
在费用流的过程中,我们的策略是 贪心 找到长度最短的增广路并进行增广,但当前决策并不一定最优,因此需要为反边添加流量,表示 支持反悔。因此,网络流本质上是 可反悔贪心,而运用上下界网络流等技巧可以很方便地处理问题的一些限制。
更一般的,网络流是一种特殊的贪心,它们之间可以相互转化。对于具有特定增广模式(网络具有某种性质)的网络流,可以从贪心的角度思考,从而使用数据结构维护。而大部分贪心题目也可以通过网络流解释。
换句话说,网络流 将贪心用图的形式刻画,而解决网络流问题的算法与某种支持反悔的贪心策略相对应,这使得我们不需要为每道贪心都寻找反悔策略,相反,建出图后就是一遍最大流或者费用流的事儿了。
1.4.2 网络流题目的技巧
网络流相关问题,关键在于发现 题目的每一种方案与一种流或割对应。例如在 P2057 [SHOI2007]善意的投票 一题中,直接将每个小朋友拆点不可行,因为无法考虑到他与他的朋友意见不一致时的贡献。
为此,我们应用 最小割等于最大流 这一结论,考虑如何 用一组割来表示一种意见方案,最终得到解法。每割掉一条边都表示付出 \(1\) 的代价,因此,将支持和反对的小朋友分别与 \(S, T\) 连边,同时对于一对朋友,他们互相之间需要连边,得到的图的最小割即为所求:割掉 \(S, i\) 之间的边表示 \(i\) 由支持变为反对,付出 \(1\) 的代价,\(i, T\) 之间类似。而若割掉两个朋友 \(u,v\) 之间的边,表示两个人意见不一,因为在残量网络上 \(u, v\) 分别与 \(S, T\) 相连。
换句话说,对于一组割,其唯一对应了一种方案,残量网络上与 \(S\) 相连的人支持,与 \(T\) 相连的人反对。这就是经典的 集合划分模型。
1.4.3 求方案的注意点
在应用最大流最小割定理求解问题时,刚学会网络流的同学可能会陷入一个误区,就是最大流对应的最小割以所有在最大流中流满的边作为割边。
仔细想想就会发现这是错误的。反例如 \(G = S\xrightarrow 1 1 \xrightarrow 1 T\)。
回想割的定义:将 \(V\) 分成两个互不相交的点集 \(A,B\) 满足 \(S\in A\) 且 \(T\in B\),则所有两端不属于同一集合的边才是割边。
在求解最大流的过程中,我们时刻维护了残量网络上 \(S\) 到每个点的距离 \(dis(u)\)。这自然地提供了一组割的方案:若 \(dis(u)\) 存在则 \(u\in A\),否则 \(u\in B\)。结合残量网络的定义可知割边所有容量均流满,再应用最大流最小割定理,可以证明这组割一定是最小割。
因此,如果一组割对应了题目的一种方案,在求解最大流之后,一定不能将所有流满的边视作割边,而是将两端所在集合不同的边视作割边。在解决集合划分模型相关问题时需要格外注意这一点。
1.4.4 反悔的性质
因为网络流算法本身自带反悔操作,所以在解决动态加边的 最大流 问题时,我们不需要担心原来的流方案会影响到算法求解新图最大流时的正确性。
但对于费用流,因为其正确性依赖于每一步增广路均为最短路,所以一旦给网络加入新边,就必须重新跑费用流才能得到正确费用。
1.5 上下界网络流
上下界网络流相较于原始网络 \(G\),每条边多了一个属性:流量下界 \(b(u, v)\),它使可行的流函数需满足的流量限制更加严格:\(b(u, v)\leq f(u, v)\leq c(u, v)\)。
1.5.1 无源汇可行流
无源汇上下界可行流是上下界网络流的基础。我们需要为一张无源汇的网络寻找一个流函数 \(f\),使得其满足流量限制,斜对称以及流量守恒限制。
解决该问题的核心思想,是 先满足流量下界限制,再尝试调整。具体地,我们首先让每条边 \((u, v)\) 都 流满下界 \(b(u, v)\),算出每个点的净流量 \(w_i = \sum f(u,i) - \sum f(i, u)\)。当 \(w_i > 0\) 时,说明流到点 \(i\) 的流量太多了,还要再还出去 \(w_i\) 才能流量守恒。相反,若 \(w_i < 0\),说明 \(i\) 还要流进 \(-w_i\) 单位流量。根据斜对称,我们有 \(\sum w_i = 0\),因此不妨设 \(\Delta = \sum_\limits{w_i > 0} w_i = \sum_\limits{w_i < 0} -w_i\)。
这启发我们新建一个网络 \(G' \approx G\),但每条边的流量限制 \(c' = c - f = c - b\)。此外新建 独立于原有点集 的 超级源点 \(SS\) 和 超级汇点 \(TT\)(尽管当前的 \(G\) 无源无汇,但这样定义是为了接下来方便区分有源汇时不同最大流过程中的源点和汇点),若 \(w_i > 0\),则 \(SS\to i\) 连容量为 \(w_i\) 的边,否则从 \(i\to TT\) 连容量为 \(-w_i\) 的边。不难发现从 \(SS\) 连出了总容量为 \(\Delta\) 的边,且总容量为 \(\Delta\) 的边连向了 \(TT\)。
若 \(SS\to TT\) 的最大流不等于 \(\Delta\),说明我们找不到一种合法方案,使得在满足 流量限制 的前提下具有 流量守恒 性质。相反,若等于 \(\Delta\),则 \(f_\mathrm{cur}(u, v) = b(u, v) + f'(u, v)\) 显然合法,因为此时每个点的 \(w_i\) 均为 \(0\),流量守恒,且 \(f_{\rm cur} = b + f' \leq b + c' = b + (c - f) = b + (c - b) = c\),即 \(b\leq f_{\rm cur} \leq c\)。
代码。
1.5.2 有源汇可行流
从 \(T\to S\) 连容量为 \(+\infty\) 的边,转化为 无源汇 上下界可行流。注意连边是 源汇 之间而非 超源超汇。
1.5.3 有源汇最大流
有源汇上下界最大流算法基于一个非常有用的结论:给定 任意 一组 可行流,对其运行最大流算法,我们总能得到正确的最大流。这是因为最大流算法本身 支持撤销,即退流操作。所以,无论初始的流函数 \(f\) 如何,只要 \(f\) 合法,就一定能求出最大流。
因此,我们考虑先求出任意一组可行流,再进行 初步调整:首先对网络 \(G\) 跑一遍有源汇 可行流,过程中我们会新建网络 \(G'\)。然后,撤去 \(SS, TT\) 以及 \(T\to S\) 容量为 \(+\infty\) 的边。这是因为 \(SS, TT\) 存在的意义是求解无源汇可行流,\(T\to S\) 的边是将有源汇可行流转化为无源汇可行流。这说明现在我们已经得到了一组有源汇可行流,除非转化成的无源汇可行流问题无解。若要得到当前流量,\(T\to S\) 的 反边 \(S\to T\) 的流量即为所求。
接下来进行 二次调整。根据结论,我们只需要以 \(S\) 为源,\(T\) 为汇在 \(\color{red} G'\) 上再跑一遍最大流,并将可行流流量与最大流流量(新增流量)相加即为答案。注意与在此之前求解无源汇上下界可行流时,以 \(SS\) 和 \(TT\) 为源汇作区分。
- 易错点 1:调整的整个过程在 \(G'\) 上进行,千万不能在 \(G\) 上面跑最大流,因为 \(G\) 上面的退流操作会使得 \(f\) 不符合容量限制,而 \(G'\) 不会。因为 \(G\) 的实际流量 \(f\) 等于 \(b + f'\),其中 \(f'\) 是 \(G'\) 上的流函数,所以只要 \(f'\) 符合容量限制,那么 \(f\) 一定也符合。
- 易错点 2:可行流流量是 \(T\to S\) 的反边流量,而不是 \(SS\to TT\) 的流量!
代码。
1.5.4 有源汇最小流
根据 \(S\to T\) 的最小流等于 \(T\to S\) 的最大流的相反数这一结论,用可行流流量减掉 \(G'\) 上 \(T\to S\) 的最大流。
代码。
1.5.5 有源汇费用流
只需将最大流算法换成费用流即可,所有 \(SS, TT\) 相关的连边代价均为 \(0\)。
初始费用为 \(\sum b(u, v)w(u, v)\),进行初步调整时需要加上 \(SS\to TT\) 调整所产生的费用,即 \(SS\to TT\) 的最小费用最大流对应的费用,进行二次调整时也要加上产生的费用。
代码可参考 1.6.4 小节给出的有负环的费用流代码。
1.6 应用与模型
1.6.1 最小割点
通常情况下题目要求的最小割是 最小割边,但如果问题变成删去每个 点 \(i\) 有代价 \(w_i\),求使得 \(S, T\) 不连通的最小代价,应该如何求解呢?
考虑应用网络流的常用技巧:点边转化,将每个点拆成入点 \(i_{in}\) 和出点 \(i_{out}\),从 \(i_{in}\) 向 \(i_{out}\) 连一条容量为 \(w_i\) 的边,表示删去这个点,使得 \(i_{in}\) 与 \(i_{out}\) 不连通需要 \(w_i\) 的代价。对于原图的每一条边 \((u, v)\),从 \(u_{out}\to v_{in}\) 连容量为 \(+\infty\) 的边,因为我们只能删点,而不是割掉边。
不难发现 \(S_{out}\to T_{in}\) 的最小割即为所求。
1.6.2 集合划分模型
集合划分模型是网络流相关问题的常见模型,读者需要充分掌握这部分内容。
其中 \(x_i = 0 / 1\),\(\overline{x_i}\) 表示将 \(x_i\) 取反得到的结果。
给定 \(E\) 和 \(c\),我们的任务就是为 \(x_i\) 选择合适的值,使得整个和式的值最小。
我们可以为上式赋予实际意义:\(n\) 个物品,\(A, B\) 两个集合,物品 \(i\) 分到集合 \(A\) 有代价 \(a_i\),分到集合 \(B\) 有代价 \(b_i\)。此外,给定若干限制 \((u, v, c_{u, v})\),表示若 \(u, v\) 不在同一集合 还需要 \(c_{u, v}\) 的代价。
建模:将 \(i\) 与 \(S, T\) 连边,容量分别为 \(b_i, a_i\)。此外,将限制 \((u, v, c_{u, v})\) 表示为 \(u, v\) 之间容量为 \(c_{u, v}\) 的 双向边,得到网络 \(G\)。上述问题和 最小割 是等价的:
- \(i\) 与 \(S\) 相连,此时割开了 \(i\to T\),表示将 \(i\) 划分到 \(A\),有 \(a_i\) 的代价。
- \(i\) 与 \(T\) 相连,此时割开了 \(S\to i\),表示将 \(i\) 划分到 \(B\),有 \(b_i\) 的代价。
- 若 \((u, v)\) 不属于同一集合,则 \(u\to v\) 和 \(v\to u\) 之间有一条被割开(因为 \(S, T\) 分别与 \(u, v\) 相连,如果不割开一条边,\(S, T\) 就连通了),方向取决于 \(S\) 究竟与 \(u\) 还是 \(v\) 相连。
因此,对上述网络 \(G\) 求最小割即为所求。
接下来我们讨论一些扩展问题:
- 当 \(a_i, b_i\) 出现负值时,普通的最大流不能得到正确结果,因为我们无法解决容量为负的最大流问题。考虑将 \(a_i, b_i\) 同时加上 \(\delta_i\),最后再在求出的最小割中减掉 \(\sum \delta_i\)。这是因为 \(i\) 必须在选或不选 任选一种 方案,所以同时为 \(a_i, b_i\) 加上 \(\delta_i\) 对最小割的影响为 \(\delta_i\)。体现在图上即 \(S\to i\to T\),为了使 \(S,T\) 不连通,必须 至少割掉一条边。同时我们也只会 恰好割掉一条边,因为 \(x\) 不能既不与 \(S\) 连通,也不与 \(T\) 连通,这与割的定义矛盾。
- 当 \(c_{u, v}\) 出现负值时,除非所有 \(c\) 均为负值且要求代价最大化,此时所有边权取反,否则问题不可做。取反可以通过 代价和贡献的转化 理解,即若代价为 \(1\),则贡献为 \(-1\),一般我们希望最大化贡献,最小化代价。
- 如果限制形如 “当 \(x\) 在集合 \(A\) 且 \(y\) 在集合 \(B\) 中有代价 \(w\)”,此时连 \(x \to y\) 权值为 \(w\) 单向边,表示如果 \(x\) 和 \(S\) 相连且 \(y\) 和 \(T\) 相连,则需要割掉这条边产生 \(w\) 的代价,否则 \(S\to T\) 连通。在不同集合产生代价连双向边本质上就是将两种情况单独处理,连两条单向边。
- 当题目要求输出方案,见 1.4.3 小节。
1.6.3 最大权闭合子图
一张 有向图 \(G = (V, E)\) 的 闭合子图 \(G'\) 定义在点集 \(V' \subseteq V\) 上。一个点集 \(V'\) 符合要求当且仅当 \(V'\) 内部每个点的 所有出边 仍指向 \(V'\),即点集内部每个点在有向图上能够到达的点仍属于该点集。\(V'\) 的 点导出子图 即 \(G'\)。
最大权闭合子图问题,即每个点 \(u\) 有点权 \(w_u\),点集的权值为点集内每个点的权值之和。求闭合子图的最大权值。
考虑 集合划分模型,对于每个节点,我们可以将其划分到 选 或 不选 的集合当中,体现在建图上即 \(S\) 与 \(i\) 相连表示选,此时需要割开 \(i\to T\),贡献为 \(w_i\),因此 \(i\to T\) 有容量 \(w_i\),同理,\(S\to i\) 有容量 \(0\)。如果 \((u, v)\in E\),说明若 \(u\) 分到选的集合中,\(v\) 也 必须 被分到选的集合当中,即 \(u\to v\) 有容量 \(-\infty\)。对上图求 最大割 即可。
由于最大割是 NP-Hard 问题,所以考虑权值取相反数求最小割。对于 \(w_i \leq 0\) 的点,\(i\to T\) 的容量 \(-w_i\geq 0\)。但对于 \(w_i > 0\) 的点,\(i\to T\) 的容量 \(-w_i < 0\)。我们 不允许 最大流的求解过程中出现 负容量边(因为笔者不知道怎么办,大雾)。考虑应用我们上面讨论过的集合划分模型的扩展问题,将 \(S\to i\) 和 \(i\to T\) 同时加上 \(w_i\),体现在建图上即对于 \(w_i > 0\),\(S\to i\) 容量为 \(w_i\),\(T\to i\) 容量为 \(0\),最后减去所有正权点权值之和,并对所得结果 取相反数。
上述操作等价于先将所有正权点选入闭合子图,再考虑去掉不选的正权点的贡献。如果某个 \(w_i > 0\) 的 \(i\) 和 \(T\) 连通说明 \(i\) 不选,割掉 \(S\to i\) 后有 \(w_i\) 的代价,所以 \(S\to i\) 的容量为 \(w_i\)。
综上,我们得到了求解最大权闭合子图的一般算法:对于 \(w_i > 0\),\(S\to i\) 连容量为 \(w_i\) 的边。对于 \(w_i < 0\),\(i\to T\) 连容量为 \(-w_i\) 的边。对于 \((u, v)\in E\),\(u\to v\) 连容量为 \(+\infty\) 的边。设得到的网络为 \(G'\),最终答案即 \(\left(\sum_\limits{w_i > 0} w_i\right) - \mathrm{Minimum\ Cut}(G')\)。
1.6.4 有负环的费用流
考虑运用上下界网络流将负权边强制满流,并令反边 \(b(v, u) = 0\),\(c(v, u) = c(u, v)\) 表示退流。此时,\((u, v)\) 由于 \(b(u, v) = c(u, v)\),不会出现在 \(G'\) 中,所以不可能存在负环,即任意时刻网络无负环(\(G'\) 处理完毕后删掉 \(T\to S\) 显然也不可能让网络出现负环),正确性得证。
模板题 P7173 有负圈的费用流 代码如下:
#include <bits/stdc++.h>
using namespace std;
const int N = 200 + 5, M = 2e4 + N;
struct flow {
int cnt = 1, hd[N], nxt[M << 1], to[M << 1], limit[M << 1], cst[M << 1];
void add(int u, int v, int w, int c) {
nxt[++cnt] = hd[u], hd[u] = cnt, to[cnt] = v, limit[cnt] = w, cst[cnt] = c;
nxt[++cnt] = hd[v], hd[v] = cnt, to[cnt] = u, limit[cnt] = 0, cst[cnt] = -c;
}
int fl[N], fr[N], dis[N], in[N];
pair<int, int> mincost(int s, int t) {
int flow = 0, cost = 0;
while(1) {
queue<int> q;
memset(dis, 0x3f, sizeof(dis));
q.push(s), fl[s] = 1e9, dis[s] = 0;
while(!q.empty()) {
int t = q.front();
q.pop(), in[t] = 0;
for(int i = hd[t]; i; i = nxt[i]) {
int it = to[i], d = dis[t] + cst[i];
if(limit[i] && d < dis[it]) {
dis[it] = d, fl[it] = min(fl[t], limit[i]), fr[it] = i;
if(!in[it]) in[it] = 1, q.push(it);
}
}
}
if(dis[t] > 1e9) return make_pair(flow, cost);
flow += fl[t], cost += dis[t] * fl[t];
for(int u = t; u != s; u = to[fr[u] ^ 1]) limit[fr[u]] -= fl[t], limit[fr[u] ^ 1] += fl[t];
}
}
};
struct bounded_flow {
int e, u[M], v[M], lo[M], hi[M], cst[M];
void add(int _u, int _v, int w, int c) {
if(c < 0) {
u[++e] = _u, v[e] = _v, lo[e] = w, hi[e] = w, cst[e] = c;
u[++e] = _v, v[e] = _u, lo[e] = 0, hi[e] = w, cst[e] = -c;
}
else u[++e] = _u, v[e] = _v, lo[e] = 0, hi[e] = w, cst[e] = c;
}
flow g;
pair<int, int> mincost(int n, int s, int t, int ss, int tt) {
static int w[N];
memset(w, 0, sizeof(w));
int flow = 0, cost = 0, tot = 0;
for(int i = 1; i <= e; i++) {
w[u[i]] -= lo[i], w[v[i]] += lo[i];
cost += lo[i] * cst[i];
g.add(u[i], v[i], hi[i] - lo[i], cst[i]);
}
for(int i = 1; i <= n; i++)
if(w[i] > 0) g.add(ss, i, w[i], 0), tot += w[i];
else if(w[i] < 0) g.add(i, tt, -w[i], 0);
g.add(t, s, 1e9, 0);
pair<int, int> res = g.mincost(ss, tt);
cost += res.second;
flow += g.limit[g.hd[s]];
g.hd[s] = g.nxt[g.hd[s]], g.hd[t] = g.nxt[g.hd[t]];
res = g.mincost(s, t);
return make_pair(flow + res.first, cost + res.second);
}
} f;
int n, m, s, t;
int main() {
cin >> n >> m >> s >> t;
for(int i = 1; i <= m; i++) {
int u, v, w, c;
cin >> u >> v >> w >> c, f.add(u, v, w, c);
}
pair<int, int> res = f.mincost(n, s, t, 0, n + 1);
cout << res.first << " " << res.second << endl;
return 0;
}
1.6.5 最大费用最大流
将所有权值取相反数转化为最小费用最大流,根据上一部分的技巧,求解(可能)有负环的费用流。
1.7 网络流 24 题
*I. P1251 餐巾计划问题
网络流相关问题,一个十分重要的技巧是 拆点。如果把每天仅看成一个点,我们无法区分干净的餐巾和脏餐巾,即干净的餐巾用完后还能作为脏餐巾继续流,而不是直接流到汇点去了。
因此考虑拆点,每天晚上得到 \(S\) 流入的 \(r_i\) 条脏餐巾,每天早上向 \(T\) 流出 \(r_i\) 条干净餐巾,对于延迟送洗相邻两天晚上之间连边,对于买毛巾 \(S\) 向每天早上连边,对于送洗,每天晚上向其对应的得到餐巾那天早上连边,跑最小费用最大流即可。
这题还是很巧妙的,例如通过从源点流入每天晚上所代表的节点,表示强制获得 \(r_i\) 条脏餐巾,以及从每天早上所代表的的节点流入汇点,表示强制给出 \(r_i\) 条干净的餐巾。
代码。注意 LOJ 和洛谷输入格式不一样。
II. P2754 [CTSC1999] 家园 / 星际转移问题
一艘太空船所停靠的站点随着时间的变化而变化,这启发我们使用 分层图 来刻画整个星际转移过程。
考虑从时刻 \(t\) 扩展到时刻 \(t + 1\)。
容易对每艘太空船 \(S\) 求出它在 \(t\) 时刻停靠的站点 \(S(t)\) 和在 \(t + 1\) 时刻停靠的站点 \(S(t + 1)\)。\(S(t)\) 上的至多 \(h_S\) 个人可以通过这艘太空船在时刻 \(t\) 到 \(t + 1\) 之间移动到 \(S(t + 1)\)(假定太空船每到达一个站点,就往站点处卸下所有的乘客)。故考虑从 \(t\) 时刻的 \(S(t)\) 向 \(t + 1\) 时刻的 \(S(t + 1)\) 连边,容量为 \(h_S\)。
此外,由于乘客可以在太站等待,且太空站容量无限,所以 \(t\) 时刻的 \(i\) 向 \(t + 1\) 时刻的 \(i\) 连边,容量为 \(+\infty\)。
注意地球 \(0\) 和月亮 \(-1\) 较为特殊,每个时刻不需要为它们新建节点(建完之后发现没有必要)。
从 \(1\) 到 \(+\infty\) 枚举答案 \(t\),如果 \(t\) 时刻 \(0\to -1\) 的最大流不小于需要转移的人数 \(k\),则 \(t\) 即为所求。
注意判断无解。两种方法,一是并查集判连通性,二是枚举到 \(750\),即 \((n + 2) \times k\)(虽然我也不太知道怎么证明,详见 链接)。
代码。
III. P2756 飞行员配对方案问题
二分图最大匹配模板题。对于输出方案,只需找到所有满流(即剩余流量为 \(0\))的连在两部图之间的边即可。
代码。
IV. P2761 软件补丁问题
注意到总的补丁数量很少,所以从初始态能够到达的态一定不会太多。状压 + SPFA 即可。
代码。
V. P2762 太空飞行计划问题
将所有实验和仪器抽象成点,从每个实验向它所有需要的仪器连边,就是最大权闭合子图问题。
代码。
VI. P2763 试题库问题
建模方法非常显然。
我们将每道题目抽象成左部点,每个类型抽象成右部点。源点向左部点连容量为 \(1\) 的边,每道题目向它可以属于的类型连容量为 \(1\) 的边,每个类型向汇点连容量为该类型所需题目数的边。
若最大流不等于 \(m\) 则无解,否则容易根据残量网络构造方案:若 \(u\to v\) 的边满流说明题目 \(u\) 属于类型 \(v\)。
代码。
VII. P2764 最小路径覆盖问题
DAG 不交最小路径覆盖是网络流经典问题。
题目要求每个点都被覆盖到,但我们其实并没有什么方法表示一个点被覆盖。但注意到表示一条边被覆盖是容易的,这启发我们使用点边转化的技巧。
将点 \(i\) 拆成入点 \(in_i\) 和出点 \(out_i\),如果原图上 \(u\to v\) 有边,那么 \(out_u\) 向 \(in_v\) 连边。
考虑这样建模后如何求答案。首先,因为路径不可交,所以一个点最多有 \(1\) 入度和 \(1\) 出度。因此 \(S\to out\) 和 \(in\to T\) 的流量应该均为 \(1\)。
将初始路径条数看成 \(n\),每流满一条 \(out_u\to in_v\) 的边就减少了一条路径,因为它将 \(u\) 所在路径和 \(v\) 所在路径连了起来。所以我们希望尽可能多地匹配左右两部点。
跑一遍二分图最大匹配,得到流量 \(f\),则 \(n - f\) 就是最小路径覆盖的条数。两部点之间流满的边就是所有被选进路径覆盖的边。设选中边集为 \(E\),从 \(E\) 中入度为 \(0\) 的点开始 dfs 即可求出每条路径。
代码。
VIII. P2765 魔术球问题
由于按编号从小往大放,所以一个球的上方的编号一定比它大。
从小到大考虑每个球 \(i\),如果 \(j < i\) 且 \(i + j\) 是完全平方数,那么 \(j\) 向 \(i\) 连边。这样问题就转化为了 DAG 最小路径覆盖。
直接做即可。如果加入 \(i\) 时 DAG 最小路径覆盖超过 \(n\),则答案为 \(i - 1\)。
代码。
*IX. P2766 最长不下降子序列问题
一道还不错的题目,至少笔者没有想出来。以下用 LIS 代指最长不下降子序列。
对于第一问,我们有经典的方法,就是设 \(f_i\) 表示长为 \(i\) 的 LIS 的结尾最小值。这样可以做到 \(\mathcal{O}(n\log n)\),但是并不方便扩展到第二和第三小问。
那我们尝试换一种 DP 方法,回归最原始的状态设计,设 \(f_i\) 表示以 \(a_i\) 结尾的 LIS 最长长度。暴力转移
\(f_i = \max\left(0, \max_\limits{j < i \land a_j\leq a_i} f_j\right) + 1\) 的复杂度是平方,对于本题而言已经可以接受了。
这样有什么好处呢?我们发现一个至关重要的性质,在任何最长 LIS 当中,第 \(i\) 个出现的位置的 \(f\) 值一定是 \(i\)。若非,通过反证法很容易导出矛盾。
因此,为保证选出的 LIS 是最长的,我们只需保证任意相邻两个位置 \(x, y\) 都有 \(f_x + 1 = f_y\)。
通过上述分析,我们的网络流模型就呼之欲出了。为保证一个位置只被选择一次,我们拆点后将入点向出点连容量为 \(1\) 的边。\(S\) 向所有 \(f_i = 1\) 的 \(in_i\) 连边,所有 \(f_i = ans\) 的 \(out_i\) 向 \(T\) 连边,容量均为 \(1\),对该网络求解最大流即为第二问的答案。
对于第三问,只需将 \(S\to in_1\),\(in_1 \to out_1\),\(in_n\to out_n\) 和 \(out_n\to T\) 的容量设为无穷大即可。这里有两个注意点,一是当 \(n = 1\) 的时候需要特判,否则流量无穷大。二是 \(out_n\to T\) 在 \(f_n\neq ans\) 的时候不存在。
代码。
X. P2770 航空路线问题
题目等价于找到从 \(1\) 到 \(n\) 的两条只在端点处相交的路径,使得它们的长度之和最大。
根据一个点只能被经过一次的限制,自然考虑拆点。\(1\) 和 \(n\) 的 \(in, out\) 之间连容量为 \(2\) 的边,剩下点的 \(in, out\) 之间连容量为 \(1\) 的边。若 \(i\) 与 \(j(i < j)\) 在原图有边,那么从 \(out_i\) 向 \(in_j\) 连容量为 \(1\) 的边。有解当且仅当 \(in_1 \to out_n\) 的最大流等于 \(2\)。
为最大化路径长度之和,我们使每个点被流过时产生贡献 \(1\),求最大费用最大流。因为只会从编号小的点向编号大的点连边,所以网络无环,可直接将费用取反求最小费用最大流。
\(n = 1\) 需要特判,不过数据好像没有。
本题也可以 DP 求解:设两条路径当前端点分别在 \(i, j\) 时长度之和的最大值为 \(f_{i, j}\)。枚举 \(k > \max(i, j)\),若 \(i, k\) 有边则可转移到 \(f_{k, j}\);若 \(j, k\) 有边则可转移到 \(f_{i, k}\)。若 \(i, j\) 均与 \(n\) 直接相连则可用 \(f_{i, j} + 1\) 更新答案。初始值 \(f_{1, 1} = 1\)。为输出方案,需记录每个状态的决策点。时间复杂度 \(\mathcal{O}(n ^ 3)\)。
代码。
XI. P2774 方格取数问题
相邻格有限制的网格问题,一般都是通过黑白染色转化到二分图相关问题。本题就是很明显的二分图最大权独立集。
代码。
XIII. P3254 圆桌问题
二分图多重匹配模板题。
自然想到用一滴流量代表一个人,建图方式就很显然了。\(S\) 向每个代表团连容量为 \(r_i\) 的边,每个代表团向每张餐桌连容量为 \(1\) 的边,每张餐桌向 \(T\) 连容量为 \(c_i\) 的边。
若最大流不等于 \(\sum r_i\) 说明无解,否则根据代表团与餐桌之间的连边构造方案即可。
代码。
XIV. P3355 骑士共存问题
题图提示我们对网格图黑白染色,有限制的两个格子之间颜色不同。二分图最大独立集直接做。
代码。
XV. P3356 火星探险问题
挺无聊的一道题。
首先拆点 \(in, out\) 点权转边权,然后一个石块只能被采集一次,那么若某个位置上有石块,则 \(in \to out\) 连一条容量为 \(1\),代价为 \(1\) 的边,再连一条容量为 \(car - 1\),代价为 \(0\) 的边。
跑一遍最大费用最大流,无环所以直接费用取反 MCMF。输出方案就记录每个位置有多少向右和向下的流量,从 \((1, 1)\) 开始进行 \(car\) 遍 dfs 即可。
代码。
XVI. P3357 最长 k 可重线段集问题
由于会出现平行于 \(y\) 轴的线段,相当于闭区间 \([x, x]\),所以直接套用最长 k 可重区间集的做法不太可行。
稍作修补,拆点 \(in_x\) 和 \(out_x\),所有 \((l, r)\) 连 \(out_l \to in_r\),\([x, x]\) 则是 \(in_x\to out_x\)。此外 \(in_x\to out_x\) 还要连容量为 \(k\),代价为 \(0\) 的边。
发现拆点还是有些麻烦,直接令 \(in_x = 2x\),\(out_x = 2x + 1\) 即可转化为最长 k 可重区间集。
\(m = \mathcal{O}(n)\),代码。
*XVII. P3358 最长 k 可重区间集问题
如果一组方案符合条件,那么一定能用不超过 \(k\) 条链把所有区间串起来,满足每条链上的区间两两不交。相反,显然任何能用 \(k\) 条链串起来的区间集合均符合要求。
因此考虑用 \(k\) 条链将区间串起来。为限制每个区间只能贡献一次,将区间拆点 \(L_i\) 和 \(R_i\),\(L_i\) 向 \(R_i\) 连容量为 \(1\),代价为 \(r_i - l_i\) 的边。此外,若 \(r_i \leq l_j\),则从 \(R_i\) 向 \(L_j\) 连一条容量为 \(1\),代价为 \(0\) 的边。
\(S\) 向 \(L\),\(R\) 向 \(T\) 连容量为 \(1\),代价为 \(0\) 的边。注意为限制流量 \(\leq k\) 需要新建 \(T'\) 然后 \(T\to T'\) 连容量为 \(k\),代价为 \(0\) 的边。最大费用最大流即为所求,因为连边不成环所以直接权值取反求最小费用最大流。
\(m = \mathcal{O}(n ^ 2)\),不是很优秀。
但实际上我们发现,我们建出的大部分边都用于连接两个不相交的区间。转换一下思路,将每个坐标而不是区间看成点,这样只需在相邻两个点之间连边即可描述所有连接两个不相交的区间的边。
具体地,将区间所有端点离散化,从小到大依次为 \(x_1, x_2, \cdots, x_k\)。令 \(x_0 = 0\)。对于所有 \(0\leq i < k\),\(i\) 向 \(i + 1\) 连容量为 \(k\),代价为 \(0\) 的边,\(0\to 1\) 的边限制了最大流 \(\leq k\)。此外,对于所有区间 \([l, r]\),令其端点分别为 \(x_i = l\) 和 \(x_j = r\),则 \(i\to j\) 连容量为 \(1\),代价为 \(r - l\) 的边。
此时我们做到了 \(m = \mathcal{O}(n)\)。代码。
XVIII. P4009 汽车加油行驶问题
设 \(f_{i, j, k}\) 表示走到 \((i, j)\) 且油箱剩余 \(k\) 单位的最小代价,dijkstra 即可。放在网络流 24 题里显得很奇怪。
令 \(m = n ^ 2k\),时间复杂度 \(\mathcal{O}(m\log m)\)。代码。
XIX. P4011 孤岛营救问题
注意到钥匙种类很少,所以将每个钥匙种类是否拥有压成一个 mask,bfs 即可。
时间复杂度 \(\mathcal{O}(nm2 ^ P)\)。代码。
XX. P4012 深海机器人问题
和 XV 火星探险一样,用建平行边的方式限制一条边的权值只贡献一次。建图方式显然,从所有源点向所有汇点跑最大费用最大流即可。代码。
XXI. P4013 数字梯形问题
通过拆点连容量为 \(1\) 的边限制每个点只能被选一次,边的容量设置为 \(1\) 限制每条边只能被选一次。代码。
XXII. P4014 分配问题
二分图最小 / 大权完美匹配模板题,代码。
XXIII. P4015 运输问题
除了边的容量改变,剩余部分和上道题一模一样,代码。
XXIV. P4016 负载平衡问题
类似上下界费用流,需要的货物从源点送,多出的货物送到汇点。
求出平均值 \(avg\),若 \(a_i < avg\) 则 \(S\to i\) 连容量 \(avg - a_i\),边权为 \(0\) 的边。否则 \(i\to T\) 连容量 \(a_i - avg\),边权为 \(0\) 的边。相邻点连容量 \(+\infty\),边权为 \(1\) 的边,最小费用最大流。代码。
1.8 例题
现在你已经对网络流的基本原理有了一定了解,就让我们来看一看下面这些简单的例子,把我们刚刚学到的知识运用到实践中吧。
I. P2936 [USACO09JAN] Total Flow S
最大流模板题。
II. P1345 [USACO5.4] 奶牛的电信 Telecowmunication
有向图点边转化基础练习题。
*III. P2057 [SHOI2007] 善意的投票 / [JLOI2010] 冠军调查
集合划分模型,分析见 1.4.2 小节。代码。
IV. P2045 方格取数加强版
有向图点边转化,将每个点 \(i\) 拆成 \(i_{in}\) 和 \(i_{out}\),\(i_{in}\to i_{out}\) 分别连容量为 \(1\),边权为 \(c_i\) 和容量为 \(k - 1\),边权为 \(0\) 的边,表示每个点的贡献只会算一次。每个点的出点向右侧和下侧点的入点连边。\((1, 1)_{in}\to (n, n)_{out}\) 的最小费用最大流即为所求。代码。
V. P3410 拍照
最大权闭合子图板子题。
VI. P2805 [NOI2009] 植物大战僵尸
对于每个植物,从它的攻击位置向它连边,表示若选择攻击位置则必须选择该植物。
因为环以及能到达环的点都不可以选择,所以对反图拓扑排序。对遍历到的节点求解最大权闭合子图问题。代码。
VII. P2604 [ZJOI2010] 网络扩容
第一问建容量 \(w\) 费用 \(0\) 的边跑最大流,第二问新建容量 \(+\infty\) 费用 \(c\) 的边跑限制流量 \(k\) 的费用流。代码。
VIII. CF1082G Petya and Graph
如果一条边被选,则其两个端点必须选。最大权闭合子图模型。
IX. P5192【模板】有源汇上下界最大流
对于每一天 \(i\),从 \(S\) 向 \(i\) 连流量限制为 \([0, D_i]\) 的边,从 \(i\) 向每个少女 \(k_i\) 连流量限制为 \([L_{k_i}, R_{k_i}]\) 的边。对于每个少女 \(i\),向 \(T\) 连流量限制为 \([G_i, \infty]\) 的边,跑有源汇上下界最大流。
注意在编号上区分 \(S, T, SS, TT\) 以及少女 \(i\) 和第 \(i\) 天。代码。
X. P4843 清理雪道
有源汇上下界最小流模板题。从 \(S\to i\to T\) 连容量范围为 \([0, +\infty]\) 的边,原图的边容量范围为 \([1, +\infty]\) 表示必须被流。代码。
如果点边转化为 DAG 最小可交路径覆盖,则时间复杂度 \(\mathcal{O}(m ^ 3 + \mathrm{maxflow}(m , m ^ 2))\)。因为 \(m = \mathcal{O}(n ^ 2)\) 所以无法接受。
XI. P4553 80 人环游世界
有源汇上下界费用流模板题。代码。
XII. P8215 [THUPC2022 初赛] 分组作业
裸的集合划分模型。
与 \(S\) 相连表示同意,否则与 \(T\) 相连表示不同意。因此 \(S\to i\) 连权值为 \(d_i\) 的边,\(i\to T\) 连权值为 \(c_i\) 的边。
根据集合划分模型,我们可以用 \(i\to j\) 权值为 \(w\) 的边表示若 \(i\) 同意且 \(j\) 不同意,则代价加上 \(w\)。因此 \(i\) 向与其同组的人连权为 \(e_i\) 的边。
合作是本题的一大难点,但只要想到独立每个人的状态和每个组的合作状态,问题就迎刃而解了。设组 \(j\) 在最终的残量网络上与 \(S\) 相连表示合作,与 \(T\) 相连表示不合作。
首先,如果任何人 \(i\) 不同意,其对应的组 \(j\) 均不可以合作。\(j\to i\) 连权值为 \(+\infty\) 的边,表示如果合作且 \(i\) 不同意,则代价为 \(+\infty\)。
剩下来就好办了。对于每个关系 \(A, B\),\(B\) 向 \(A\) 对应的组连边 \(a_i\),表示若 \(B\) 同意且 \(A\) 没有合作则有 \(a_i\) 的代价。同理,\(B\) 对应的组向 \(A\) 连边 \(b_i\),表示若 \(B\) 合作且 \(A\) 不同意则有 \(b_i\) 的代价。
对上述网络跑最大流即可。代码。
*XIII. P2053 [SCOI2007] 修车
如果技术人员 \(i\) 倒数第 \(j\) 个维修的车子是 \(k\),将对答案产生 \(\dfrac{jT_{k, i}} n\) 的贡献。\(\dfrac 1 n\) 是定值,可以忽略。
考虑将每个技术人员拆成 \(N\) 个点 \((i, j)(1\leq j\leq N)\),表示技术人员 \(i\) 的倒数第 \(j\) 次维修。因为一次只能维修一辆车子,且每辆车子只会被维修一次,所以建出二分图,左部点表示一次维修,右部点表示一辆车子,\((i, j) \to k\) 连容量为 \(1\),费用为 \(jT_{k, i}\) 的边。最小费用最大流即为所求。
XIV. P2153 [SDOI2009] 晨跑
将 \(2\sim n\) 拆点后跑最小费用最大流即可。
*XV. CF103E Buying Sets
没有 \(|N(S)| = |S|\) 的限制就是裸闭合子图模型。由于任意 \(k\) 个子集的并 \(\geq k\),所以只需保证 \(|N(S)|\leq |S|\)。考虑为元素的权值减去 \(+\infty\),子集的权值加上 \(+\infty\)。这样,当 \(|N(S)| > |S|\) 时,\(+\infty\) 贡献了至少一次,劣于不选任何一个子集,这种情况必然不会发生。
对上述模型跑最大权闭合子图即可。代码。
XVI. P1231 教辅的组成
模型显然,将中间点拆点连容量为 \(1\) 的边限制每个中间点的度数,跑最大流即可。代码。
XVII. P1361 小 M 的作物
考虑集合划分模型。
令作物与 \(S\) 相连表示种在 \(A\) 地,与 \(T\) 相连表示种在 \(B\) 地。因集合划分模型只能处理最小化代价,故先将所有贡献加入,尝试最小化扣除贡献。据此,\(S\to i\) 容量 \(a_i\),\(i\to T\) 容量 \(b_i\)。
对于联合贡献,同样先将贡献 \(c_1 + c_2\) 加入并最小化扣除贡献。易知 \(S\to c_A\) 容量 \(c_1\),\(c_A \to I\) 容量 \(+\infty\),\(I\to c_B\) 容量 \(+\infty\),\(c_B \to T\) 容量 \(c_2\),其中 \(I\) 为涉及到的作物集合。代码。
XVIII. P4313 文理分科
考虑集合划分模型。
令学生与 \(S\) 相连表示选理科,与 \(T\) 相连表示选文科。对所有贡献求和,尝试最小化减去的代价。据此,\(S\to (i, j)\) 容量为 \(science_{i, j}\),\((i, j)\to T\) 容量为 \(art_{i, j}\)。
对于联合贡献,新建点 \(e_1 \to (x, y)\) 容量为 \(+\infty\),其中 \((x, y)\) 为 \((i, j)\) 及与其四连通的总共五个格子,\(S\to e_1\) 容量为 \(same\_science_{i, j}\);新建点 \((x, y)\to e_2\) 容量为 \(+\infty\),\(e_2\to T\) 容量为 \(same\_art{i, j}\)。代码。
2. 二分图
二分图是 OI 界常见的一类图,其延伸出的相关算法和模型非常广泛。我们将看到网络流在二分图上的广泛应用。
2.1 定义,性质与判定
定义:设无向图 \(G = (V, E)\),若能够将 \(V\) 分成两个点集 \(V_1\) 和 \(V_2\) 满足 \(V_1 \cap V_2 = \varnothing\),\(V_1 \cup V_2 = V\) 且 \(\forall (u, v) \in E\) 均有 \(u\in V_1 \land v\in V_2\)(\(\land\) 是逻辑与)或者 \(u\in V_2 \land v\in V_1\),则称 \(G\) 是一张二分图,\(V_1, V_2\) 分别为其左部点和右部点。
简单地说,二分图就是可以将原图点集分成两部分,满足两个点集内部没有边的图。这也是它的名字的由来。
有了定义,我们自然希望对其进行判定。考虑满足条件的图有什么性质。
我们发现,从一个点开始,每走一条边就会切换一次所在集合。这说明从任意一个点出发,必须经过偶数条边才能回到这个点,即图上不存在奇环。反过来,若一张图不存在奇环,对其进行黑白染色就可以得到一组划分 \(V_1, V_2\) 的方案。
综上,我们得到判定二分图的充要条件:不存在奇环。
-
什么是黑白染色?我们希望给每个点染上白色或黑色,使得任意一条边两端的颜色不同。
从某个点开始深搜,初始点的颜色任意。遍历当前点 \(u\) 的所有邻居 \(v\)。如果 \(v\) 未被访问,则将 \(v\) 的颜色设为与 \(u\) 相反的颜色并向 \(v\) 深搜。否则检查 \(u\) 的颜色是否与 \(v\) 的颜色不同 —— 若是,说明满足限制;否则说明图上存在奇环,黑白染色无解。
黑白染色给予我们在 \(\mathcal{O}(|V| + |E|)\) 的时间内判定二分图的方法。注意图可能不连通,此时需要从每个未被染色的节点开始对连通分量进行染色。
注意,接下来讨论的二分图均指点集划分方案 \(V_1, V_2\) 已经确定的二分图,而非满足条件的 \(V_1, V_2\) 未定的二分图。事实上,给定连通二分图,若 \(V_1, V_2\) 之间无序,则将其划分成两部点的方案是唯一的。但对于非连通二分图,方案数不唯一,因为每个连通分量安排 \(V_1', V_2'\) 的方案有两种。本质不同的划分方案有 \(2 ^ {c - 1}\) 种,其中 \(c\) 是连通分量个数。
2.2 二分图的匹配
给定二分图 \(G = (V, E)\),若边集 \(M \subseteq E\) 满足 \(M\) 中任意两条边不交于同一端点,则称 \(M\) 是 \(G\) 的一组 匹配,匹配的大小为 \(|M|\)。
特别的,若 \(|V_1| = |V_2|\) 且匹配 \(M\) 包含 \(|V_1|\) 条边,则称 \(M\) 为 完美匹配。
下文称节点 \(u\) 被匹配当且仅当 \(M\) 存在一条边以 \(u\) 为端点。
2.2.1 最大匹配
2.2.1.1 Dinic
对于给定二分图 \(G\),我们希望求出边集 \(M\) 的大小的最大值。求解该问题的经典方法是匈牙利算法,详见 3.2 小节。
尝试用网络流解决问题。一个节点最多与一条边相连,即节点度数 \(\leq 1\)。这启发我们从源点 \(S\) 向 \(V_1\) 每个节点连容量为 \(1\) 的边,从 \(V_2\) 每个节点向汇点 \(T\) 连容量为 \(1\) 的边,再加上给 \(E\) 中所有边定向后由 \(V_1\) 指向 \(V_2\) 的容量为 \(1\) 的边。\(S\to T\) 的最大流即最大匹配。
容易证明这样做的正确性:我们发现每个点最多与一个点相邻,因为限制了它到源点或汇点的流量为 \(1\)。因此,一组可行流与一组匹配一一对应,且流量等于匹配大小。
使用 dinic 求解二分图最大匹配,时间复杂度是优秀的 \(\mathcal{O}(m\sqrt n)\)。
2.2.1.2 增广路和交错路
在证明 dinic 求解二分图最大匹配的时间复杂度之前,我们需要补充二分图匹配的增广路和交错路的定义。
考虑匹配 \(M\),若原图存在一条长度为奇数的路径 \(P = p_0 \xrightarrow{e_1} p_1 \xrightarrow{e_2} \cdots \xrightarrow{e_k} p_k(2\nmid k)\) 使得 \(e_1, e_3, \cdots, e_k \notin M\),而 \(e_2, e_4, \cdots, e_{k - 1}\in M\),同时 \(p_0, p_k\) 均不是 \(M\) 的任何一条边的某个端点,则称 \(P\) 为匹配 \(M\) 的 增广路。
用自然语言描述,增广路是从一个没有被匹配的点出发,依次走非匹配边,匹配边,非匹配边 …… 最后通过一条非匹配边到达 另外一部点 当中某个没有被匹配的点的路径。因此,不妨钦定增广路的方向为从左部端点走向右部端点。
如下图,红色边是匹配边 \(M = \{(p_1, p_2), (p_3, p_4)\}\)。我们从非匹配左部点 \(p_0\) 开始,依次走非匹配边 \((p_0, p_1)\),匹配边 \((p_1, p_2)\),非匹配边 \((p_2, p_3)\),匹配边 \((p_3, p_4)\) 和非匹配边 \((p_4, p_5)\),到达非匹配右部点 \(p_5\)。这些边连接而成的路径就是一条增广路。
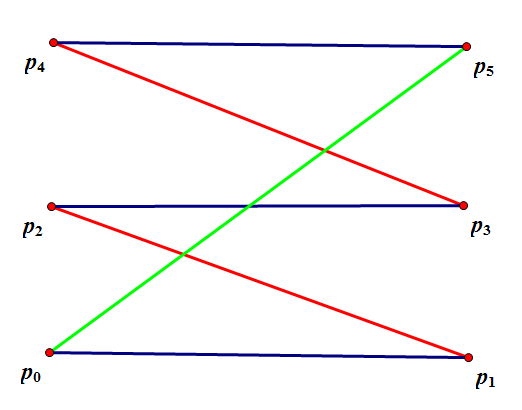
考察使用网络流求解二分图最大匹配时的增广路和二分图匹配本身的增广路形态,它们本质上一致:因为左部点向右部点连边,所以对于非匹配边,它在从左往右的方向上有流量;反之,对于匹配边,它在从右往左的方向上有流量。
网络上增广路的形态为从 \(S\) 开始,到某个未被匹配的左部点,然后在左右部点之间反复横跳,最后到达某个未被匹配的右部点,并走到 \(T\)。如果一个点被匹配,那么在残量网络上它和 \(S\) 或 \(T\) 不连通,因此路径上和 \(S\),\(T\) 相连的都是非匹配点,对应增广路的开头和结尾都是非匹配点。忽略掉 \(S\) 和 \(T\),路径的第一条和最后一条边都是从左部点走到右部点,对应增广路的第一条最后一条边都是非匹配边。
容易发现,每次将一条增广路上所有边的状态取反,可得比原来匹配大 \(1\) 的匹配。
交错路 的限制则更弱一些,它只需满足路径上任意相邻两条边一条不在匹配内,另一条在匹配内。显然,增广路一定是交错路。
2.2.1.3 复杂度证明
根据 dinic 复杂度证明的结论,每次增广使得 \(S\to T\) 的最短路增加。因此,进行 \(\sqrt n\) 次增广后,任意增广路长度大于 \(\sqrt n\)。
设当前匹配为 \(P\),最大匹配为 \(Q\)。考虑 \(P\) 和 \(Q\) 的对称差 \(R = P\oplus Q\),即 \(R = \{e \in E\mid [e\in P] \neq [e\in Q]\}\)。\(R\) 由若干不交的路径和环组成,因为每个点的度数 \(\leq 2\)(\(P\) 和 \(Q\) 中每个点的度数 \(\leq 1\))。
忽略环,因为它是由 \(P\) 和 \(Q\) 当中的边依次交替组成的长度为偶数的环,若非则 \(P\) 或 \(Q\) 存在点度数 \(\geq 2\),不合法。因此,将环上 \(P\) 的边替换为 \(Q\) 的边不会使匹配大小增加。
同理可证长度为偶数的路径不会使匹配大小增加。
每条长度为奇数的路径对应一条 \(P\) 上的增广路,因为这样的交错路径必然由 \(Q\) 作为第一条和最后一条边。若以 \(P\) 作为开头和结尾,那么对于 \(Q\),将该路径上的所有边状态取反可以得到更大的匹配,与 \(Q\) 的最大性矛盾。因此,对 \(P\) 进行该条增广路的增广可以使其大小增加 \(1\)。
由于路径不交且增广路长度至少为 \(\sqrt n\),所以增广路条数不超过 \(\sqrt n\),这说明 \(|Q| - |P| \leq \sqrt n\)。因此再增广至多 \(\sqrt n\) 轮即可得到最大匹配。
根据每条边的容量为 \(1\) 容易证明一轮增广的复杂度为 \(\mathcal{O}(m)\),因此 dinic 的复杂度即 \(\mathcal{O}(m\sqrt n)\)。
上述证明结合了 “dinic 每轮增广使得增广路长度增加” 和 “长度 \(\geq k\) 的不交增广路至多有 \(\dfrac n k\) 条” 两条结论以及根号分治的思想。
2.2.2 最大多重匹配
多重匹配指节点 \(u\) 不能与超过 \(L_u\) 条边相连。一般匹配即 \(L_u = 1\) 的特殊情况。
求解最大多重匹配,只需将 \(S\to V_1\) 的每条边 \(S\to u\) 的容量设为 \(L_u\),对于 \(V_2 \to T\) 同理。二分图内部每条边的容量不变,仍为 \(1\)。对上述网络求最大流即最大多重匹配。
Dinic 二分图匹配算法的时间复杂度证明中并没有用到与 \(S, T\) 相连的边容量为 \(1\) 的性质,因此使用 dinic 求解二分图最大多重匹配的时间复杂度仍为 \(\mathcal{O}(m\sqrt n)\)。
2.2.3 带权最大匹配
对于最小权最大匹配,将最大流算法换成最小费用最大流。
对于最大权最大匹配,将最大流算法换成最大费用最大流。图中无正环,只需权值取反求最小费用最大流。
对于最大权 完美 匹配,有专门的 KM 算法 解决该问题。详见 3.3 小节。
2.3 二分图相关问题
2.3.1 最小点覆盖集
给定二分图 \(G = (V, E)\),若点集 \(C\subseteq V\) 满足对于任意 \((u, v)\in E\) 都有 \(u\in C\) 或 \(v\in C\),则称 \(C\) 是 \(G\) 的 点覆盖集。即一个点可以覆盖以该点为端点的边,覆盖所有边的点集就是点覆盖集。点覆盖集的大小为 \(|C|\)。
考虑一组点覆盖集,不存在边 \((u, v) \in E\) 使得 \(u, v\) 同时不属于 \(C\)。因为一个点只有属于 \(C\) 和不属于 \(C\) 两种状态,这启发我们将其套入集合划分模型。
但是这样会产生问题:一般集合划分模型只能处理 \(x, y\) 在不同集合时产生代价的限制,不能强制某两个点不同时在相同集合。
不过注意到我们还没有使用 \(G\) 是二分图的性质。因为任意一条边连接两部点,所以尝试将一部点的状态取反,即左部点与 \(S\) 连通表示它不属于 \(C\),但右部点与 \(S\) 连通表示它属于 \(C\)。这样限制变为 “如果左部点 \(u\) 与 \(S\) 连通,\(u, v\) 之间有连边,但右部点 \(v\) 与 \(T\) 连通,则 \(u, v\) 同时不属于 \(C\),不合法”。
相比求解最大匹配时建出的网络,上述操作进行的修改仅是将两部点之间连边的容量设为 \(+\infty\)。对该网络求解最大流,可得最小点覆盖集大小。同样,可以根据集合划分模型的结果求出具体最小点覆盖集方案。
进一步地,因为一个点最多流入或流出一单位流量,所以将两部点之间连边的容量设为 \(1\) 不影响最终结果。这个观察证明了最大匹配等于最小点覆盖集。
最小点覆盖集的应用:对于每条限制 \(lim\) 恰有两种方案 \(u, v\) 能满足。一种方案可满足多条限制。求最少需要选择多少种方案以满足所有限制。问题可以转化为二分图最小点覆盖集进行求解。
2.3.2 König 定理
如果从匹配的角度理解点覆盖集,“不存在增广路” 这一性质使得我们可以根据最大匹配构造出最小点覆盖集。
以下讨论基于不存在增广路的最大匹配 \(M\)。
从任意一个未被匹配的 右部点 出发走交错路,并依次标记所有经过的点。换言之,我们按遍历顺序依次标记从没有匹配的右部点开始的所有交错路上的所有点。注意,交错路可能退化成单点。
首先确定这些交错路的形态。交错路必然是从右部点出发,通过非匹配边走到左部点,再通过匹配边走到右部点,以此类推。这说明 从左到右走匹配边,从右到左走非匹配边。
取出所有被标记的左部点和未被标记的右部点,我们断言它是最小点覆盖集。证明如下:
考虑一条匹配边。它不可能是右端点先被标记:交错路从右部非匹配点开始,所以右端点的标记由另外一个被标记的左部点走到它而产生。又因为从左到右走匹配边,所以右端点和两条匹配边相连,矛盾。因此,它必然左端点先被标记,接下来走到右端点使得它被标记;或者两个端点同时未被标记。一条匹配边恰有一个端点属于点覆盖集。
考虑一条非匹配边。不可能出现它的左端点未被标记且右端点被标记的情况,因为此时可以从右到左走该非匹配边使得左端点被标记。因此一条非匹配边至少有一个端点属于生成的点覆盖集。
综上,我们证明了点覆盖集的合法性,每一条边被至少一个点覆盖。点覆盖集的最小性只需证明 \(|C|\) 取到了下界。
首先证明 \(|C| = |M|\):
- 对于左部被标记的点,若它是非匹配点,考虑使得它被标记的交错路,发现这是一条增广路,矛盾。因此,被标记的左部点是匹配点。
- 对于右部点,若它是非匹配点,我们必然标记它,因为它可以作为交错路的开头:要么它是孤立点,此时交错路退化成单点;要么存在至少一条从它出发的非匹配边,考虑非匹配点的定义可得。因此,未被标记的右部点是匹配点。
结合上述两点以及一条匹配边恰有一个端点属于点覆盖集,匹配边与点覆盖集内的点一一对应。命题 \(|C| = |M|\) 得证。
而 \(|C| \geq |M|\) 非常容易证明:任何一条匹配边都需要一个单独的点以覆盖它,所以任何点覆盖集大于任何匹配。这样,我们证明了点覆盖集的最小性。
综上,通过上述方法构造出的 \(C\) 是最小点覆盖集。这是匈牙利数学家柯尼希(D.König)在 1913 年给出的构造。
König 定理:二分图的最大匹配大小等于最小点覆盖集大小。
2.3.3 最大独立集
给定二分图 \(G = (V, E)\),若点集 \(I \subseteq V\) 满足任意两点不直接相连,则称 \(I\) 是 \(G\) 的 独立集,独立集大小为 \(|I|\)。
考虑集合划分模型,限制形如不存在边 \((u, v)\in E\) 使得 \(u, v\) 同时属于 \(I\),和最小点覆盖集的限制「不存在边 \((u, v) \in E\) 使得 \(u, v\) 同时不属于 \(C\)」恰好相反。
这启发我们考虑 \(G\) 的点覆盖集 \(C\) 并取反。因为每条边至少被一个 \(u \in C\) 所覆盖,所以 \(I = V \backslash C\) 的所有点之间互不相连。这说明独立集与点覆盖集 一一对应,且它们的交为空,并为 \(V\),即点覆盖集与独立集互补。
综上,二分图最大独立集等于 \(V\) 减去最小点覆盖集。
2.3.4 最大团
给定二分图 \(G = (V, E)\),若其 点导出子图 \(G' = (V', E')\) 满足对于任意 \(u, v\in V'\),其中 \(u\in V_1\),\(v\in V_2\),均有 \((u, v)\in E'\),则称 \(G'\) 是 \(G\) 的 团。
- 作为补充,一般图的团定义为其完全子图。
同样,二分图最大团问题可以通过集合划分模型解决。方法类似,细节不再赘述。
整个过程本质等价于求补图最大独立集:考虑 \(G\) 的补图 \(G_c = (V, E_c)\),若 \((u, v) \in E_c\) 则 \(u, v\) 不能同时出现在最大团中。故二分图最大团等于补图最大独立集。
2.3.5 某部点的极值
存在一些题目让我们求使得某部点的数量尽可能多的最小点覆盖集,最大独立集或最大团。
套入集合划分模型,总可以将问题转化为:对于二分图 \(G\),我们希望在维持被割掉的总边数等于最大匹配数不变的前提下,尽可能多地割掉 \(S\) 与左部点之间的连边,或者右部点与 \(T\) 之间的连边。两种情况对称,接下来只讨论前者。
- 例如,若希望使最大团左部点尽量多,根据最大团 \(\sim\) 补图最大独立集 \(\sim\) 补图最小点覆盖集的补集,我们希望使补图最小点覆盖集左部点尽量少。因为最小点覆盖集的集合划分模型形如被割掉的左部点加入覆盖集(已经讨论过这一点),所以我们希望被割掉的左部点尽量多。
如果仅在原图上跑最大流,我们无法控制某部点被割掉的数量。此时,集合划分模型就要发挥它的威力了。
考虑改变每个点划分入各个集合的代价,以给予每个点被割掉的优先级:将 \(S\) 与左部点之间的边的容量修改为 \(c\),右部点与 \(T\) 之间的边容量修改为 \(c + 1\),两部点之间的容量设为 \(+\infty\),这样可以优先割掉 \((S, u\in V_1)\)。
为了保证割掉总边数的正确性,\(c\) 应当不小于 \(n = \min(|V_1|, |V_2|)\):不能出现割掉 \(x\) 个左部点不劣于割掉 \(y < x\) 个右部点的情况,即 \(n\times c\) 必须要大于 \((n - 1)(c + 1)\),化简得到 \(c > n - 1\)。这保证了我们在该网络上求得的最小割满足割边条数最小,而最小割边条数就是最大匹配数。
2.4 应用与模型
2.4.1 DAG 最小路径覆盖
给定 DAG \(G = (V, E)\),定义其 路径覆盖 为路径集合 \(P\),满足每个节点至少被一条路径覆盖。根据路径是否可交,即一个节点是否只能恰好被一条路径覆盖,可以分为不交路径覆盖与可交路径覆盖。
最小 不交 路径覆盖:见网络流 24 题 VII.
最小 可交 路径覆盖:
一个点的出度和入度可能大于 \(1\),直接沿用不交路径覆盖的方法不可行。但我们发现,如果一条路径覆盖了某个点,那么可以选择占用这个点的入度或出度,也可以选择不占用。这给予我们初步想法:若一条路径真实地覆盖了某个点,可以选择视为没有覆盖。此时可能出现一条路径两个相邻的被覆盖的点在原图上不相邻的情况。
接下来具体描述上述思考。
考虑一组可交路径覆盖方案,依次考虑其中的每个路径 \(P_i\)。称 \(P_i\) 覆盖点 \(u\) 当且仅当 \(u\in P_i\) 且 \(u\notin P_j(1\leq j < i)\),即 \(u\) 第一次被覆盖是被 \(P_i\) 覆盖。
设 \(P_i\) 覆盖的点集为 \(V_i\)。若 \(V_i\) 为空,则删去 \(P_i\) 后不影响合法性,因此 \(V_i\) 非空。考虑按拓扑序将 \(V_i\) 内所有点排序,得到 \(p_1, p_2, \cdots, p_k(k = |V_i|)\),显然 \(p_i\) 可达 \(p_{i + 1}\),设对应路径为 \(P'_i\)。
一个点在路径集合 \(\{P'_i\}\) 当中至多有 \(1\) 出度和 \(1\) 入度,再根据 \(p_i\) 可达 \(p_{i + 1}\),考虑求出原 DAG 传递闭包,再对传递闭包求最小不交路径覆盖。简单地说,若 \(i \rightsquigarrow j\),则 \(i\) 向 \(j\) 连边。
容易证明传递闭包的一组不交路径覆盖对应若干原图的可交路径覆盖。尽管方案不唯一,因为传递闭包上相邻两点在原 DAG 上之间可能有多条路径,但路径条数是不变的。
综上,DAG 最小可交路径覆盖是它传递闭包的最小不交路径覆盖。
2.5 例题
I. P2055 [ZJOI2009] 假期的宿舍
将所有需要住下的人视为左部点,所有空的床视为右部点。
对于左部点,源点向所有要在学校住下的人连边。对于右部点,所有回家的人向汇点连边。两部点之间认识的人连边,检查最大匹配是否与左部点个数相等。代码。
II. P3701 主主树
对于左边能打败右边的,连容量为 \(1\) 的边。左部点从 \(S\) 连容量为生命值的边,右部点向 \(T\) 连容量为生命值的边。注意每个 J 的生命值还要加上所属阵营中 YYY 的数量。求出带权最大匹配对 \(m\) 取 \(\min\)。代码。
III. P6268 [SHOI2002] 舞会
二分图最大独立集模板题,需要先对可能不连通的图进行黑白染色。答案为 \(n\) 减去最小点覆盖,即 \(n\) 减去最大匹配。代码。
IV. P7368 [USACO05NOV] Asteroids G
一个小行星被消除当且仅当它所在的行或列被选中,建出二分图,则题目转化为二分图最小点覆盖集,跑最大匹配即可。代码。
V. CF1684G Euclid Guess
为使得余数为 \(t\),除数 \(b\) 必然 \(> t\),不妨令 \(b = t + 1\)。因为 \(a > b\),所以 \(a\) 最小为 \(2t + 1\)。因此若存在 \(2t + 1 > m\) 则无解。
考虑接下来的过程。若 \(1\leq k < t\),则 \((2t + k, t + k) \to (t + k, t) \to (t, k)\),这意味着如果要搞出一个 \(t\),我们还需要一些比较小的数作为垫背。
当 \(k = t\) 时,整个过程 \((3t, 2t)\) 只会形成一个数 \(t\),很棒,唯一的问题是需要满足 \(3t \leq m\)。
这样一来就有了大致思路。找到所有 \(3t > m\) 的 大 \(t\),我们需要一个 \((2t + k, t + k)\) 消灭掉这个 \(t\),并且还需要 \(k\) 以及 \((t, k)\) 后续形成的数作为垫背。如果存在方案使得每个数够用,那么剩下来所有 \(3t\leq m\) 的 小 \(t\) 可以每次用 \((3t, 2t)\) 消灭掉。
问题转化为怎么消灭掉较大的 \(t\)。如果直接尝试枚举其对应的 \(k\) 等于某个小 \(t\),由于一次操作会涉及多个小 \(t\),我们没有办法解决这种情况。
考察欧几里得算法本身,我们发现对于一开始的 \((a, b)\) 而言,\(\gcd(a, b)\) 一定会出现在序列当中。这就好办了啊!如果 \(k\) 不是 \(t\) 的约数,那么令 \(k\gets \gcd(k, t)\) 显然一定更优,因为后者涉及到的数完全包含于前者。更劲爆的是,后者仅涉及到 \(k\) 本身一个数。
综上,枚举大 \(t_i\) 和小 \(t_j\),若 \(t_j \mid t_i\) 且 \(2t_i + t_j \leq m\),则 \(i\to j\) 连边。大 \(t\) 之间由于 \(3t > m\) 所以内部不会连边,跑二分图最大匹配。如果所有左部点均被匹配则有解,将匹配对应的方案输出,并将剩下来的小 \(t\) 通过 \((3t, 2t)\) 消灭掉,否则无解。
时间复杂度 \(\mathcal{O}(n ^ {2.5})\),代码。
VI. CF1139E Maximize Mex
因每个学生恰属于一个社团,所以一个学生可以看成其对应社团与能力值之间的连边。对于单组询问,只需从小到大枚举 \(i\),若仅考虑 \(\leq i\) 的能力值时,最大匹配等于 \(i + 1\),说明 \(\mathrm{mex}\) 可以等于 \(i + 1\),继续枚举 \(i + 1\),否则说明无法使得答案大于 \(i\),且可以使得答案等于 \(i\),故 \(i\) 即为所求。
删去学生不好考虑,倒过来变成加边,根据单调性用指针维护答案即可。代码。
3. 图的匹配
匹配 是一组没有公共点的边集,每个点要么有唯一匹配的点,要么是非匹配点。
乍一看,一般图最大匹配似乎和一般图最大独立集同样棘手,以至于笔者很长一段时间都以为一般图最大匹配是 NPC 问题,但事实并非如此。
3.1 相关定义
上一章我们介绍了二分图匹配,将相关概念迁移至一般图上,可得如下定义:给定图 \(G\),
- 称边集 \(M\) 为 \(G\) 的一组 匹配,当且仅当 \(M\) 中任意两条边没有公共点。
- 匹配的 大小 为边数 \(|M|\)。
- 若 \(|M|\) 最大,则称 \(M\) 为 最大匹配。最大匹配不一定唯一。
- 边带权时,若边权和最大,则称 \(M\) 为 最大权匹配。最大权匹配不一定是最大匹配。
- 若一条边在 \(M\) 中,则称该边为 匹配边,反之称为 非匹配边。
- 若一个点是 \(M\) 中某条边的端点,则称该点为 匹配点,反之称为 非匹配点。
- 若基于 \(M\) 无法再增加匹配边,则称 \(M\) 为 极大匹配。极大匹配不一定最大。
- 若 \(G\) 的每个点均为匹配点,则称 \(M\) 为 完美匹配。
信息竞赛常见匹配问题由两个因素划分为四类。根据图是否是二分图以及边是否带权,分为二分图 / 一般图最大(权)匹配。接下来将依次介绍解决它们的常用算法。
3.2 二分图最大匹配
3.2.1 匈牙利算法
使用 Hopcroft-Karp 求解二分图最大匹配,时间复杂度 \(\mathcal{O}(m\sqrt n)\)。
另一种常见方法是匈牙利算法,时间复杂度 \(\mathcal{O}(nm)\),比 HK 劣,但它是学习 KM 算法的基础。
由 2.2.1.2 小节可知将增广路上边的状态取反可得比原来大 \(1\) 的匹配。
考虑反转的过程,令增广路为 \(p_1 \to p_2 \to \cdots \to p_{2k}\),原 \((p_{2i}, p_{2i + 1})(1 \leq i < k)\) 是匹配边,现 \((p_{2i - 1}, p_{2i})(1 \leq i \leq k)\) 是匹配边。反转后相比反转前多出两个匹配点,而原匹配点不会因此变为非匹配点。只要一个点被匹配,那么它一直被匹配下去。
因此,考虑依次添加每一个左部点 \(u\in V_1\),使用 dfs 求出是否存在从 \(u\) 开始的增广路。若存在,则反转增广路上所有边的状态,并令匹配数 \(+1\)。设当前搜索到的左部点为 \(x\),具体流程如下:
- 若 \(x\) 已被访问,返回增广失败的信息。
- 标记 \(x\) 已被访问。
- 遍历 \(x\) 所有出边对应的右部点 \(y\in N(x)\):
- 若 \(y\) 已被访问,则跳过。
- 否则,若 \(y\) 为非匹配点,令 \(y\) 匹配 \(x\),并返回增广成功的信息。
- 否则,搜索 \(y\) 匹配的左部点 \(x'\)。若成功增广,据分析,\(y\) 匹配点左部点应变为 \(x\),并返回增广成功的信息。
- 若此时仍未返回,说明 \(x\) 的所有出边均无法增广,返回增广失败的信息。
进一步地,因每个左部点 \(x\) 最多只会被其匹配的右部点 \(y\) 访问到,故无需记录每个左部点是否被访问。
增广成功次数之和即为最大匹配。注意,每次尝试从 \(u\) 开始找增广路前需清空访问标记。
因为每次尝试增广最坏情况下需遍历所有 \(m\) 条边,故总复杂度为 \(\mathcal{O}(nm)\)。
#include <bits/stdc++.h>
using namespace std;
constexpr int N = 500 + 5;
int n, m, E, mch[N], vis[N];
vector<int> e[N];
bool dfs(int id) {
for(int it : e[id]) {
if(vis[it]) continue;
vis[it] = 1;
if(!mch[it] || dfs(mch[it])) return mch[it] = id, 1;
}
return 0;
}
int main() {
cin >> n >> m >> E;
for(int i = 1; i <= E; i++) {
int u, v;
cin >> u >> v;
e[u].push_back(v);
}
int ans = 0;
for(int i = 1; i <= n; i++) {
memset(vis, 0, sizeof(vis));
ans += dfs(i);
}
cout << ans << endl;
return 0;
}
3.2.2 Hopcroft-Karp
Hopcroft-Karp 和 dinic 求解二分图最大匹配的方法本质相同,但前者常数更小。HK 相当于将 dinic 特殊化,借用了 dinic 的流程,但专门用于求二分图最大匹配。
HK 首先从左部非匹配点开始 bfs 将图分层:考虑 dinic 从 \(S\) 开始 bfs 的过程,第一步宽搜到的即左部非匹配点。HK 将 \(S\) 去掉了,直接从左部非匹配点开始。
和匈牙利一样,我们只 bfs 左部点,右部点仅作为中转点。因此,bfs 到左部点 \(x\) 时,枚举其所有邻点 \(y\):
- 若 \(y\) 已经访问过,则忽略。
- 否则令 \(d_y = d_x + 1\)。若 \(y\) 为匹配点,则与之匹配的左部点 \(x'\) 入队,且 \(d_{x'} = d_y + 1\)。因为一开始仅左部非匹配点入队,所以若 \(y\) 未访问,则 \(x'\) 未访问。
注意,任意时刻若 \(d_x\) 大于某个右部非匹配点 \(y\) 的 \(d_y\),因为 \(d_T\) 为 \(\min\limits_{y\in V_R \land y\notin M} d_y + 1\),所以 \(d_x\) 不小于 \(d_T\),其中 \(T\) 是 dinic 对应汇点,但在 HK 中不存在,此时可直接退出 bfs 减小常数。
接下来多路增广,且仅在 \(d_x + 1 = d_y\) 的 \((x, y)\) 和 \(d_y + 1 = d_{x'}\) 的 \((y, x')\) 之间寻找增广路。从每个左部非匹配点开始类似匈牙利 dfs 增广,但每次出发前不要清空作用于右部点的 visit 数组,因为如果从某个右部点开始找不到增广路,那么接下来一定也找不到从它开始的增广路:整个过程中找到的增广路会在多路增广结束后同时作用于原匹配,而不是每找到一条增广路就扩大匹配。为了方便写代码,我们每找到一条增广路就改变匹配关系,但读者需注意这些增广路实质上应在多路增广结束后才被处理。
#include <bits/stdc++.h>
using namespace std;
constexpr int N = 500 + 5;
constexpr int inf = 1e9 + 7;
int n, m, E, dx[N], dy[N], mx[N], my[N], vis[N]; // mx[x] 表示 x 是否被匹配,my[y] 表示与 y 匹配的左部点
vector<int> e[N];
bool bfs() {
queue<int> q;
memset(dx, -1, sizeof(dx));
memset(dy, -1, sizeof(dy));
for(int i = 1; i <= n; i++) if(!mx[i]) dx[i] = 0, q.push(i);
int dT = inf;
while(!q.empty()) {
int t = q.front();
q.pop();
if(dx[t] >= dT) break; // 如果 dis[t] >= dis[T],直接退出
for(int it : e[t]) {
if(dy[it] != -1) continue;
dy[it] = dx[t] + 1;
if(!my[it]) dT = dy[it] + 1;
else dx[my[it]] = dy[it] + 1, q.push(my[it]);
}
}
return dT != inf;
}
bool dfs(int id) {
for(int it : e[id]) {
if(vis[it] || dx[id] + 1 != dy[it]) continue;
vis[it] = 1;
if(!my[it] || dfs(my[it])) return mx[id] = 1, my[it] = id, 1; // 类似匈牙利增广
}
return 0;
}
int main() {
cin >> n >> m >> E;
for(int i = 1; i <= E; i++) {
int u, v;
cin >> u >> v;
e[u].push_back(v);
}
int ans = 0;
while(bfs()) {
memset(vis, 0, sizeof(vis));
for(int i = 1; i <= n; i++) if(!mx[i]) ans += dfs(i);
}
cout << ans << "\n";
return 0;
}
3.3 二分图最大权完美匹配
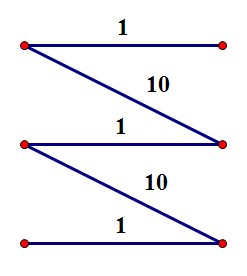
给定二分图 \(G = (V, E)\),若边集 \(M \subseteq E\) 满足 \(M\) 中任意两条边不交于同一端点,\(|M| = |V_1| = |V_2|\) 且 \(M\) 的边权和最大,则称 \(M\) 是 \(G\) 的一组 最大权完美匹配。将 \(|M| = |V_1| = |V_2|\) 的限制去掉,则称 \(M\) 是 \(G\) 的一组 最大权匹配。
最大权匹配不一定是完美匹配,如下图,最大权匹配为 \(20\),最大权完美匹配为 \(3\)。
3.3.1 理论分析
著名的 KM 算法用于求解二分图最大权 完美 匹配。若不存在完美匹配,则 KM 算法会死循环,故初始需对二分图进行特殊处理:
- 若求最大权匹配,则补点使得两部点大小相等,并将不存在的边补 \(0\)。
- 若边权可以为负,则将不存在的边视为 \(-\infty\)。
KM 算法的核心步骤由线性规划引出,但笔者不了解线性规划,故直接给出结论,将显得不自然。待笔者学习线性规划后再做补充。
给每个点赋顶标。设左部点顶标为 \(A_i\),右部点顶标为 \(B_j\),需满足对于任意边 \((i, j)\) 均有 \(w_{i, j} \leq A_i + B_j\)。
结论:令满足 \(w_{i, j} = A_i + B_j\) 的边 \((i, j)\) 构成 相等子图,若相等子图存在完美匹配,则其为原二分图最大权完美匹配。
证明:求得最大权完美匹配的权值为当前顶标和。对于其它完美匹配,因 \(w_{i, j} \leq A_i + B_j\),故其权值不大于当前顶标和。证毕。
考虑在一组合法顶标基础上调整顶标,不断扩大相等子图直到其存在完美匹配。类似匈牙利,枚举每个左部点 \(u\),尝试将其加入匹配。
从 \(u\) 出发找相等子图的增广路。若发现增广路,则将路径上边的状态取反,宣告成功匹配 \(u\);否则需要对部分节点的顶标进行调整。因无增广路,故相等子图上所有从 \(u\) 出发的路径均为两端为左部点的交错路,这些交错路形成 交错树(尽管它并不是树)。
考虑边 \((x, y)\),设 \(x\) 的顶标变化量为 \(\Delta_x\),\(y\) 的顶标变化量为 \(\Delta_y\)。若 \((x, y)\) 在交错树上,则 \(\Delta_x + \Delta_y = 0\),因为不应使已经进入相等子图的边离开相等子图。据此可知大致调整思路:令交错树上左部点顶标变化量和右部点顶标变化量互为相反数。
根据 \(\Delta_x + \Delta_y \geq w_{x, y} - A_x - B_y\) 可知,
- 若增加交错树上左部点顶标,减少右部点顶标,令变化量为 \(d\),\(d\geq 0\),则
- 对于左部点属于交错树,右部点不属于交错树的边 \((x, y)\),因 \(\Delta_x = d\) 且 \(\Delta_y = 0\),故 \(\Delta_x + \Delta_y \geq 0\),必然合法。
- 对于左部点不属于交错树,右部点属于交错树的边 \((x, y)\),因 \(\Delta_x = 0\) 且 \(\Delta_y = -d\),故 \(d\) 不大于所有 \((x, y)\) 的 \(A_x + B_y - w_{x, y}\) 的最小值。令 \(d\) 取最大值 \(d_{\max} = \min\limits_{(x, y)} (A_x + B_y - w_{x, y})\),容易发现可将至少一条 \((x, y)\) 加入相等子图。
- 对于左右部点均属于或均不属于交错树的边,无影响。
- 同理,若减少交错树上左部点顶标,增加右部点顶标,令变化量为 \(d\),则 \(d\) 不大于所有左部点属于交错树,右部点不属于交错树的边 \((x, y)\) 的 \(A_x + B_y - w_{x, y}\) 的最小值,且可以将至少一条这样的 \((x, y)\) 加入相等子图。
哪种方法更优秀呢?感性理解,加入左部点属于交错树,右部点不属于交错树的边更优。增广路以右部点结尾,所以加入这样的边可扩展以 \(x\) 结尾的交错路径(尽管不一定能找到增广路,如当 \(y\) 为匹配点时)。但加入左部点不属于交错树,右部点属于交错树的边时,无法扩大交错树:\(y\) 为右部点且其匹配左部点非 \(x\),故 \((x, y)\) 是否在相等子图中对交错树无影响。
综上,不断将交错树上左部点顶标增加 \(d\),右部点顶标减少 \(d\),可不断往交错树中加入左部点属于交错树,右部点不属于交错树的边 \((x, y)\)。接下来证明它一定能求出相等子图完备匹配:
不妨设按编号从小到大依次尝试加入每个左部点。考虑归纳法,假设前 \(i - 1\) 个左部点均可通过调整顶标加入相等子图匹配。
考虑尝试加入第 \(i\) 个点时不断加边的过程终态,所有与原交错树上前 \(i\) 个左部点相邻的右部点 \(y\) 及它们之间的所有边 \((x, y)(1\leq x \leq i)\) 均被加入交错树。对原二分图执行匈牙利算法,发现尝试加入第 \(i\) 个点时形成的交错树 \(T\) 等于当前相等子图形成的交错树 \(T'\)。因原二分图存在完美匹配,故 \(T\) 存在增广路,故 \(T'\) 存在增广路,故必然存在某次加边使得出现从 \(i\) 出发的增广路。
当 \(i = 1\) 时,命题显然成立,故原命题成立,KM 算法正确性得证。
3.3.2 实现方法
根据理论分析,容易得到一个朴素实现 KM 的算法。
设当前希望加入节点 \(i\),则不断从 \(i\) 开始搜索。每次开始搜索前清空右部点的访问标记,以及右部点的 \(slack_y\) 表示 \(\min A_x + B_y - w_{x, y}\) 初始化为 \(+\infty\),其中 \(x\) 为交错树上的左部点。
类似匈牙利算法,设当前搜索到左部点 \(x\),
- 遍历 \(x\) 所有出边对应的右部点 \(y\in N(x)\):
- 若 \(y\) 已被访问,则跳过。
- 否则,若 \(A_x + B_y = w_{x, y}\),则 \((x, y)\) 在相等子图上。回忆匈牙利算法,当 \(y\) 为非匹配点或搜索 \(y\) 匹配的左部点 \(x'\) 成功增广时,令 \(y\) 匹配 \(x\),并返回增广成功的信息。否则跳过这条边。
- 否则 \((x, y)\) 不在相等子图上,用 \(A_x + B_y - w_{x, y}\) 更新 \(slack_y\)。
- 若此时仍未返回,说明 \(x\) 的所有出边均无法增广或不在相等子图上,返回增广失败的信息。
无需记录 \(x\) 是否被访问的原因在匈牙利部分已经提到:每个左部点 \(x\) 最多只会被其匹配的右部点 \(y\) 访问到。
搜索完毕后,若未能成功增广,则令 \(d\) 为所有 未被访问 的右部点 \(y\) 的 \(\min\limits_{y} slack_y\)。令所有 被访问 的左部点的顶标减少 \(d\),被访问 的右部点的顶标增加 \(d\)。否则成功增广,退出从 \(i\) 开始搜索的过程。据分析,必然存在某一次搜索使得可以增广。
- 所有被访问的左部点即 \(i\) 与所有被访问的右部点的左部匹配点。
因每次搜索的时间复杂度均为 \(\mathcal{O}(m)\),而每次搜索必然往相等子图中加入至少一条边,故总复杂度 \(\mathcal{O}(m ^ 2)\),通常视复杂度为 \(\mathcal{O}(n ^ 4)\),足以应付大部分题目。
模板题 P6577 代码如下。
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
constexpr int N = 500 + 5;
ll e[N][N], A[N], B[N], slack[N];
int n, m, mch[N], vis[N];
bool dfs(int id) {
for(int it = 1; it <= n; it++) {
if(vis[it]) continue;
if(A[id] + B[it] == e[id][it]) {
vis[it] = 1;
if(!mch[it] || dfs(mch[it])) return mch[it] = id, 1;
}
else slack[it] = min(slack[it], A[id] + B[it] - e[id][it]);
}
return 0;
}
int main() {
cin >> n >> m;
memset(e, 0xcf, sizeof(e));
for(int i = 1; i <= m; i++) {
int y, c, h;
cin >> y >> c >> h;
e[y][c] = h;
}
memset(A, 0xcf, sizeof(A));
for(int i = 1; i <= n; i++)
for(int j = 1; j <= n; j++)
A[i] = max(A[i], e[i][j]);
for(int i = 1; i <= n; i++) {
while(1) {
memset(vis, 0, sizeof(vis));
memset(slack, 0x3f, sizeof(slack));
if(dfs(i)) break;
ll d = 1e18;
for(int j = 1; j <= n; j++) if(!vis[j]) d = min(d, slack[j]);
for(int j = 1; j <= n; j++) if(vis[j]) B[j] += d, A[mch[j]] -= d;
A[i] -= d;
}
}
ll ans = 0;
for(int i = 1; i <= n; i++) ans += A[i] + B[i];
cout << ans << "\n";
for(int i = 1; i <= n; i++) cout << mch[i] << " ";
cout << "\n";
return 0;
}
我们发现调整顶标后重新搜索浪费时间,因为原交错树仍然存在,同时往相等子图中新加入一些边,这些边由于其左部点属于交错树,右部点不属于交错树的性质,也会加入交错树。为了不浪费已有信息,考虑 bfs。
设当前希望加入节点 \(i\),当前 bfs 到的节点为 \(x\),\(x\) 的初始值为 \(i\)。在开始 bfs 前,清空右部点的访问标记,初始化 \(slack_y\) 为 \(+\infty\)。
- 枚举 \(x\) 的所有出边 \(y\in N(x)\):
- 若 \(y\) 已被访问,则跳过。
- 否则,用 \(A_x + B_y - w_{x, y}\) 更新 \(slack_y\)。
- 令 \(d\) 为所有未被访问的右部点 \(y\) 的 \(\min slack_y\),\(y'\) 为取到该最小值的 \(y\)。
- 将所有被访问的左部点的顶标减少 \(d\),被访问的右部点的顶标增加 \(d\),未被访问的右部点的 \(slack\) 减少 \(d\):对于不与任何被访问左部点相连的右部点 \(y\),其 \(slack\) 为初始值 \(+\infty\),即使减去 \(d\) 也不会影响到 \(\min slack_y\)。
- 此时 \(slack_{y'} = 0\),说明 \(y'\) 在相等子图的交错树上。
- 若 \(y'\) 未被匹配,则找到增广路,退出 bfs。
- 否则,令 \(x\) 为 \(y'\) 匹配的左部点,继续 bfs。
考虑记录额外信息从而更新增广路上所有节点的状态。仔细思考后发现可以记录每个右部点 \(y'\) 由哪个右部点 \(y\) 匹配的左部点 \(x\) 扩展而来,设为 \(pre_{y'} = y\),不妨设初始时 \(i\) 匹配右部点 \(0\)。
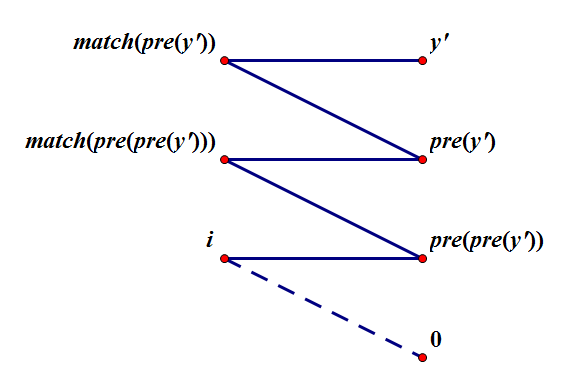
由上图可知,从退出 bfs 对应的 \(y'\) 开始,此时 \(match(y') = 0\),不断令 \(match(y') \gets match(pre(y'))\),\(y'\gets pre(y')\) 直到 \(y' = 0\) 即可。
如何维护 \(pre\):根据 dfs 过程,欲知 \(pre(y)\),只需知道使得 \(slack_y\) 变为 "bfs \(x\) 时对应的 \(d\)" 时对应的左部点 \(x'\)。注意 \(x'\) 不一定等于 \(x\),因为 \(slack_y\) 可能在 bfs 到 \(x\) 之前就已变为 bfs \(x\) 时对应的 \(d\),而 \((x, y)\) 不一定满足 \(A_x + B_y - w_{x, y} = slack_y\),只是 bfs \(x'\) 时存在比 \(slack_y\) 更小的 \(slack_{y'}\) 使得 \(y\) 在 bfs \(x'\) 时没有作为取到 \(slack_y\) 最小值的 \(y'\) 而被遍历到。
因使得 \(slack_y\) 变为某次 bfs 对应的 \(d\) 对应的更新 \((x, y)\) 必然最后一次使 \(slack_y\) 减小,故只需在 bfs \(x\) 时,若 \(A_x + B_y - w_{x, y} < slack_y\),则用 \(x\) 匹配的右部点 \(y'\),即使得 bfs 到 \(x\) 的交错树右部点,更新 \(pre(y)\)。
若 \(d > 0\),则 \(\mathcal{O}(n)\) 更新顶标和 \(slack_y\) 后必然加入一条边,但单次 bfs 的复杂度为 \(\mathcal{O}(n ^ 2)\)(遍历到的总点数乘以 bfs 单点的复杂度 \(\mathcal{O}(n)\),后者是卡满的,因为需要求 \(d\)),故基于 bfs 实现的 KM 算法时间复杂度为 \(\mathcal{O}(n ^ 3)\),可以通过模板题。
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
constexpr int N = 500 + 5;
ll e[N][N], A[N], B[N], slack[N];
int n, m, mch[N], pre[N], vis[N];
void bfs(int id) {
memset(vis, 0, sizeof(vis));
memset(slack, 0x3f, sizeof(slack));
int x = mch[0] = id, y = 0;
while(1) {
vis[y] = 1;
ll d = 1e18;
int _y = 0;
for(int i = 1; i <= n; i++) {
if(vis[i]) continue;
ll D = A[x] + B[i] - e[x][i];
if(D < slack[i]) slack[i] = D, pre[i] = y;
if(slack[i] < d) d = slack[i], _y = i;
}
A[id] -= d;
for(int i = 1; i <= n; i++) {
if(vis[i]) B[i] += d, A[mch[i]] -= d;
else slack[i] -= d;
}
if(!mch[y = _y]) break;
x = mch[y];
}
while(y) mch[y] = mch[pre[y]], y = pre[y];
}
int main() {
cin >> n >> m;
memset(e, 0xcf, sizeof(e));
for(int i = 1; i <= m; i++) {
int y, c, h;
cin >> y >> c >> h;
e[y][c] = h;
}
memset(A, 0xcf, sizeof(A));
for(int i = 1; i <= n; i++)
for(int j = 1; j <= n; j++)
A[i] = max(A[i], e[i][j]);
for(int i = 1; i <= n; i++) bfs(i);
ll ans = 0;
for(int i = 1; i <= n; i++) ans += A[i] + B[i];
cout << ans << "\n";
for(int i = 1; i <= n; i++) cout << mch[i] << " ";
cout << "\n";
return 0;
}
3.4 一般图最大匹配
NOI 后再更。
3.5 一般图最大权匹配
NOI 后再更。
参考文章
第一章:
第二章:
- Dinic 二分图匹配 / Hopcroft-Karp 算法 复杂度简单证明 - Itst。
- 二部图最大匹配 —— 新数据结构 Augmenting graph 与 Hopcroft-Karp 算法的复杂度证明 - JHack。
- Konig 定理及证明 - Bennettz。
第三章:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号