常见字符串算法 II:自动机相关
CHANGE LOG
- 2021.12.25:新增 ACAM 部分。
- 2021.12.26:新增 SAM 部分。
- 2022.2.9:计划重构文章。
- 2022.2.20:重构完成,增加部分例题。
基本定义与约定:
- 称字符串
- 模式串:相当于题目给出的 字典,用于匹配的字符串。下文也称 单词。
- 文本串:被匹配的字符串。
- 更多约定见 常见字符串算法。
1. AC 自动机 ACAM
前置知识:字典树,KMP 算法与 动态规划 思想。
AC 自动机是一类确定有限状态自动机,这说明它有完整的 DFA 五要素,分别是起点
AC 自动机全称 Aho-Corasick Automaton,简称 ACAM。它的用途非常广泛,是重要的字符串算法(
1.1 算法详解
AC 自动机用于解决 多模式串 匹配问题:给定 字典
朴素的基于 KMP 的暴力时间复杂度为
多串问题自然首先考虑建出字典树。根据其定义,字典树上任意节点
借鉴 KMP 算法的思想,我们考虑对于每个状态
从
- 例如,当
- 再例如,当
考虑用类似 KMP 的算法求解失配指针:首先令
失配指针已经足够强大,但这并不是 AC 自动机的完全体。我们尝试将每个状态的所有字符转移
设字典树的根为节点
根据已有信息递推,这是 动态规划 的核心思想。即求解
当
有了这一性质,我们就不需要预先求出失配指针,而是在建造 AC 自动机的同时一并求出。由于我们需要保证在计算一个状态的转移时,其失配指针指向的状态的转移已经计算完毕,又因为失配指针长度小于原串长度,故使用 BFS 建立 AC 自动机。一般形式的 AC 自动机代码如下:
int node, son[N][S], fa[N];
void ins(string s) { // 建出 trie 树
int p = 0;
for(char it : s) {
if(!son[p][it - 'a']) son[p][it - 'a'] = ++node;
p = son[p][it - 'a'];
}
}
void build() { // 建出 AC 自动机
queue <int> q;
for(int i = 0; i < S; i++) if(son[0][i]) q.push(son[0][i]); // 对于第一层特判,因为 fa[0] = 0,此处即转移的第二种情况
while(!q.empty()) { // 求得的 son[t][i] 就是文章中的转移函数 delta(t, i),相当于合并了 trie 和 AC 自动机的转移函数
int t = q.front(); q.pop();
for(int i = 0; i < S; i++)
if(son[t][i]) fa[son[t][i]] = son[fa[t]][i], q.push(son[t][i]); // 转移的第一种情况:原 trie 图有 trans(t, i) 的转移
else son[t][i] = son[fa[t]][i]; // 转移的第三种情况
}
}
特别的,在 ACAM 上会有一些 终止节点
总结一下我们使用到的约定和定义:
- 节点也被称为 状态。
- 设字典树上状态
- 失配指针
- 终止节点
- 所有终止节点
- 若状态
1.2 fail 树的性质与应用
AC 自动机的核心就在于 fail 树。它有非常好的性质,能够帮我们解决很多问题。
- 性质 0:它是一棵 有根树,支持树剖,时间戳拍平,求 LCA 等各种树上路径或子树操作。
- 性质 1:对于节点
- 性质 2:若
- 性质 3:定义
- 常用结论:一个单词在匹配串
根据性质 3,有这样一类问题:单词有带修权值,多次询问对于某个给定的字符串
通常带修链求和要用到树剖,但查询具有特殊性质:一个端点是根。因此,与其单点修改链求和,不如 子树修改单点查询。实时维护每个节点的答案,这样修改一个点相当于更新子树,而查询时只需查单点。转化之前的问题需要树剖 + 数据结构
补充:对于普通的链求和,只需差分转化为三个到根链求和也可以使用上述技巧。链加,单点查询 也可以通过转化变成 单点加,子树求和。只要包含一个单点操作,一个链操作,均可以将链操作转化为子树操作,即可将时间复杂度更大的树剖 BIT 换成普通 BIT。
- 性质 4:把字符串
1.3 应用
大部分时候,我们借助 ACAM 刻画多模式串的匹配关系,求出文本串与字典的 最长匹配后缀。但 ACAM 也可以和动态规划结合:在利用动态规划思想构建的自动机上进行 DP,这是 DP 自动机 算法。
1.3.1 结合动态规划
ACAM 除了能够进行字符串匹配,还常与动态规划相结合,因为它精确刻画了文本串与 所有 模式串的匹配情况。同时,
例如非常经典的 [JSOI2007]文本生成器。题目要求至少包含一个单词,补集转化相当于求 不包含任何一个单词 的长为
1.3.2 结合矩阵快速幂
在上一部分的基础上,若
具体转移方式视题目而定。矩阵乘法也可以是广义矩阵乘法,如例 XII.
1.4 注意点
- 建出字典树后不要忘记调用
build建出 ACAM。 - 注意模式串是否可以重复。
- 在构建 ACAM 的过程中,不要忘记递推每个节点需要的信息。如
1.5 例题
I. P3808 【模板】AC 自动机(简单版)
本题相同编号的串多次出现仅算一次,因此题目相当于求:文本串
设当前状态为
#include <bits/stdc++.h>
using namespace std;
const int N = 1e6 + 5;
const int S = 26;
int n, node, son[N][S], fa[N], ed[N];
string s;
void ins(string s) {
int p = 0;
for(char it : s) {
if(!son[p][it - 'a']) son[p][it - 'a'] = ++node;
p = son[p][it - 'a'];
} ed[p]++;
}
void build() {
queue <int> q;
for(int i = 0; i < S; i++) if(son[0][i]) q.push(son[0][i]);
while(!q.empty()) {
int t = q.front(); q.pop();
for(int i = 0; i < S; i++)
if(son[t][i]) fa[son[t][i]] = son[fa[t]][i], q.push(son[t][i]);
else son[t][i] = son[fa[t]][i];
}
}
int main() {
cin >> n;
for(int i = 1; i <= n; i++) cin >> s, ins(s);
int p = 0, ans = 0; cin >> s, build();
for(char it : s) {
int tmp = p = son[p][it - 'a'];
while(ed[tmp] != -1) ans += ed[tmp], ed[tmp] = -1, tmp = fa[tmp];
} cout << ans << endl;
return 0;
}
II. P2292 [HNOI2004] L 语言
首先我们有个显然的 DP:设
注意到
时间复杂度
*III. P2414 [NOI2011] 阿狸的打字机
由于删去一个字符和添加一个字符对字典树大小的影响均为
因此将询问离线,按
IV. P5357 【模板】AC 自动机(二次加强版)
根据 fail 树的性质 1,文本串
*V. P4052 [JSOI2007]文本生成器
ACAM 与 DP 相结合的例题。
VI. P3041 [USACO12JAN]Video Game G
非常套路的 ACAM 上 DP:设
*VII. CF1202E You Are Given Some Strings...
还算有趣的一道题目。对于同时与两个字符串相关的问题,考虑 在拼接处计算贡献,即求出
VIII. CF163E e-Government
裸题。对
*IX. P7456 [CERC2018] The ABCD Murderer
由于单词可以重叠(否则就不可做了),我们只需求出对于每个位置
最优化问题考虑 DP:设
如果不想写线段树,还有一种方法:从后往前 DP。这样,每个位置可以转移到的地方是固定的(
X. P3121 [USACO15FEB]Censoring G
非常经典的 AC 自动机题目。对
XI. P3715 [BJOI2017]魔法咒语
二合一屑题。考虑在 ACAM 上 DP,对于前
XII. CF696D Legen...
非常套路地设
显然有转移:
*XIII. P5840 [COCI2015]Divljak
由于
上述经典问题可以通过将
考虑使用 1.2 提到的技巧,将链加和单点查询转化为单点修改,子树查询,此时只需对所有
2. 后缀自动机 SAM
后缀自动机全称 Suffix Automaton,简称 SAM,是一类极其有用但难以真正理解的字符串后缀结构(
2.1 基本定义与引理
SAM 相关的定义非常多,需要牢记并充分理解它们,否则学习 SAM 会非常吃力,因为符号化的语言相较于直观的图片和实例更难以理解。
首先,我们给出 SAM 的定义:一个长为
SAM 最重要,也是最基本的一个性质:从
- 定义转移边
- 定义
- 定义 前缀 状态集合
- SAM 的有向无环转移图也是有向无环单词图(DAWG, Directed Acyclic Word Graph)。
两个字符串
读者应该有这样的直观印象:SAM 的每个状态
转移边与
在引出 SAM 的核心定义「后缀链接」前,我们需要证明关于上述概念的一些性质。下列引理的内容部分来自 OI-wiki,相关链接见 Part 2.4.
引理 1:考虑两个非空子串
和 (假设 )。要么 ,要么 ,取决于 是否为 的一个后缀:
证明:若存在位置
引理 2:考虑一个状态
。 所表示的所有子串长度连续,且 较短者总是较长者的后缀。
证明:根据引理 1,若两个子串
对于前半部分考虑反证:假设
简单地说,对于一个子串
推论 1:对于子串
的所有后缀,其 集合大小随后缀长度减小而单调不降,且 较小的 集合包含于较大的 集合。
引理 2 是非常重要的性质。有了它,我们就可以定义后缀链接了。
- 定义状态
引理 3:所有后缀链接形成一棵以
为根的树。
证明:对于任意不等于
- 定义 后缀路径
引理 4:通过
集合构造的树(每个子节点的 都包含在父节点的 中)与通过后缀链接 构造的树相同。
根据推论 1 与后缀链接的定义容易证明。因此,后缀链接构成的树本质上是

上图图源 OI-wiki。我们给出每个状态的
2.2 关键结论
我们还需要以下定理确保构建 SAM 的算法的正确性,并使读者对上述定义形成感性的直观的认知。
结论 1.1:从任意状态
出发跳后缀链接到 的路径,所有状态 的 不交,单调递减且并集形成 连续 区间 。
证明:根据后缀链接的性质
结论 1.2:从任意状态
出发跳后缀链接到 的路径,所有状态 的 的并集为 的 所有后缀。
证明:由结论 1.1 和后缀链接的定义易证。
结论 2.1:
,若存在 的 转移边,则 。
证明:根据
结论 2.2:
,若存在 的转移边,则 使得 。
证明:结论 2.1 的逆命题。这很好理解,因为对于任意
结论 3.1:考虑状态
,不存在转移 使得 。
证明:显然。
结论 3.2:考虑状态
,**唯一 **存在状态 和转移 使得 。
证明:考虑反证法,若不存在这样的
简单地说,若数集
结论 3.3:考虑状态
,唯一 存在转移 使得 。
证明:同理。
- 定义
- 定义
结论 4.1:考虑状态
,若存在转移 ,则 在后缀链接树上是 或其祖先。
证明:由于所有
结论 4.2:考虑状态
,若存在转移 ,则 在后缀链接树上是 或其子节点。
证明:同理。
结论 4.3:考虑状态
,若存在转移 ,则所有这样的 在 树上形成了一条 深度递减的链 。
证明:结合结论 4.1 与结论 4.2 易证。
可以发现上述性质大都与后缀链接有关,因为后缀链接是 SAM 所提供的最重要的核心信息。我们甚至可以抛弃 SAM 的 DAWG,仅仅使用后缀链接就可以解决大部分字符串相关问题。
- 扩展定义:
2.3 构建 SAM
铺垫了这么多,我们终于有足够的性质来建造 SAM 了。之前的长篇大论可能让读者认为它是一个非常复杂的算法:是,但不完全是。至少在代码实现方面,它比同级的 LCT 简单到不知道到哪里去了。
SAM 的构建核心思想是 增量法。我们在
- 打开 SAM。
- 把字符插进去。
- 关上 SAM。
设
新建初始状态
接下来我们考虑如何连指向
Case 1:不存在
容易发现这种情况仅在
Case 2:存在
令
可以证明
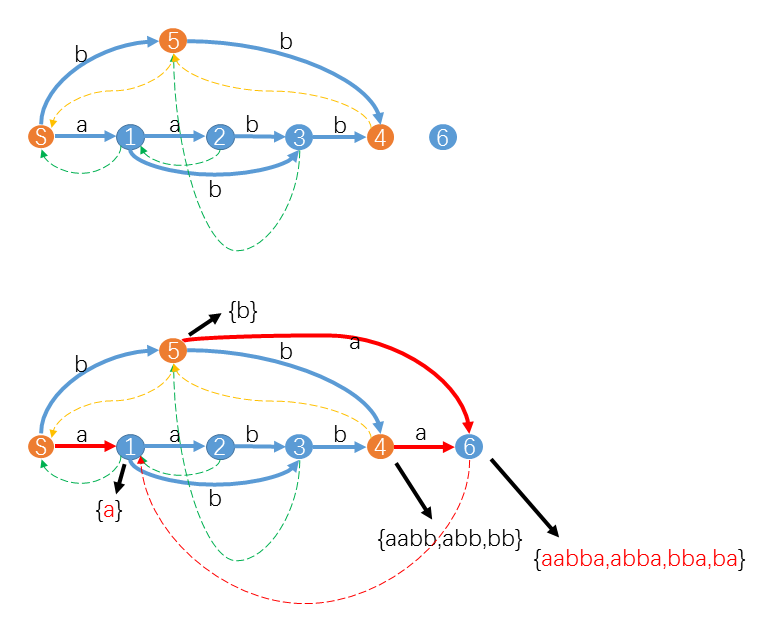
图源 hihocoder。上图中,在插入
注意状态
Case 3:存在
此时
- 新的
考虑
此外,根据结论 4.3,我们知道后缀路径
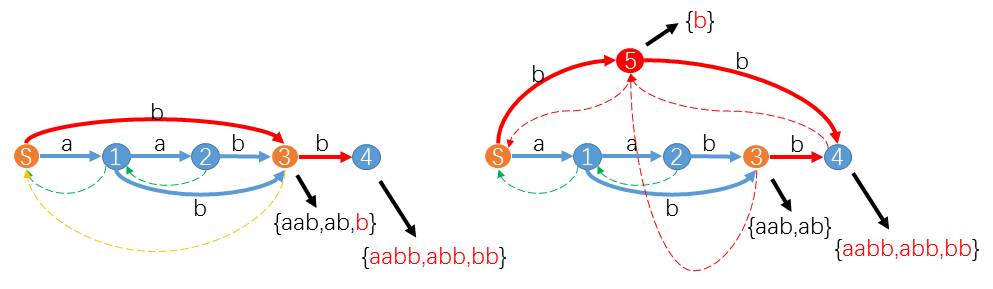
上图中,我们把
然后,从
上述分类讨论结束后,令
const int N = 1e5 + 5;
const int S = 26;
int cnt = 1, las = 1, son[N][S], fa[N], len[N];
void ins(char s) {
int it = s - 'a', p = las, cur = ++cnt;
len[cur] = len[p] + 1, las = cur; // 计算 len[cur],更新 las
while(!son[p][it]) son[p][it] = cur, p = fa[p]; // 添加转移边
if(!p) return fa[cur] = 1, void(); // case 1
int q = son[p][it];
if(len[p] + 1 == len[q]) return fa[cur] = q, void(); // case 2
int cl = ++cnt; cpy(son[cl], son[q], S); // 新建节点,cl 继承 q 的所有转移
len[cl] = len[p] + 1, fa[cl] = fa[q], fa[q] = fa[cur] = cl; // 计算 len[cl] 以及 cl, q, cur 的后缀链接,注意 fa[cl] = fa[q] 要在 fa[q] = cl 之前
while(son[p][it] == q) son[p][it] = cl, p = fa[p]; // 修改后缀路径 p -> T 的一段前缀
}
当字符集 map 代替。
2.4 时间复杂度证明
下设字符串
2.4.1 状态数上界
构建后缀自动机的算法本身就已经证明了其 SAM 状态数不超过
2.4.2 转移数上界
称
由于最大的状态数量仅在形如
2.4.3 操作次数上界
该部分 OI Wiki 上讲得较为简略,因此笔者自行证明了这一结论。在构建 SAM 的过程中,有且仅有将
定义
- 考虑后缀路径
- 若
- 可结合下图以更好理解,其中
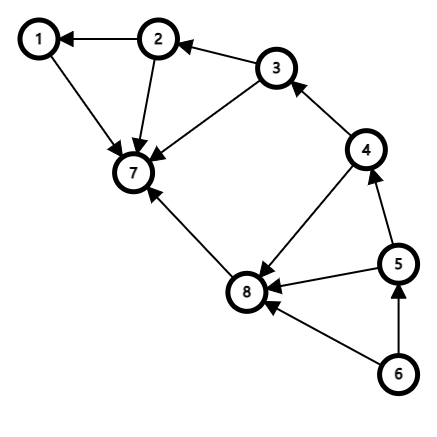
假设我们从
同时,根据
2.5 应用
2.5.1 求本质不同子串个数
根据 SAM 的性质,每个子串唯一对应一个状态,因此答案即
2.5.2 字符串匹配
用文本串
for(int i = 1, p = 1, L = 0; i <= n; i++) {
while(p > 1 && !son[p][t[i] - 'a']) L = len[p = fa[p]];
if(son[p][t[i] - 'a']) L = min(L + 1, len[p = son[p][t[i] - 'a']]);
}
2.6 广义 SAM
广义 SAM,GSAM,全称 General Suffix Automaton,相对于普通 SAM 它支持对多个字符串进行处理。它可以看做对 trie 建后缀自动机。
一般的写法是每插入一个字符串前将
- 当
- 当
int ins(int p, int it) {
if(son[p][it] && len[son[p][it]] == len[p] + 1) return son[p][it]; // 如果节点已经存在,且 len 值相对应,即 (p, son[p][it]) 是连续转移,则直接转移。
int cur = ++cnt, chk = son[p][it]; len[cur] = len[p] + 1;
while(!son[p][it]) son[p][it] = cur, p = fa[p];
if(!p) return fa[cur] = 1, cur;
int q = son[p][it];
if(len[p] + 1 == len[q]) return fa[cur] = q, cur;
int cl = ++cnt; cpy(son[cl], son[q], S);
len[cl] = len[p] + 1, fa[cl] = fa[q], fa[q] = fa[cur] = cl;
while(son[p][it] == q) son[p][it] = cl, p = fa[p];
return chk ? cl : cur; // 如果 len[las][it] 存在,则 cur 是空壳,返回 cl 即可
}
上述方法本质相当于对匹配串建出 trie 后进行 dfs 构建 SAM。部分特殊题目会直接给出 trie 而非模板串,此时模板串长度之和的级别为
#include <bits/stdc++.h>
using namespace std;
#define ll long long
#define cpy(x, y, s) memcpy(x, y, sizeof(x[0]) * (s))
const int N = 2e6 + 5;
const int S = 26;
ll n, ans, cnt = 1;
string s;
int len[N], fa[N], son[N][S];
int ins(int p, int it) {
int cur = ++cnt; len[cur] = len[p] + 1;
while(!son[p][it]) son[p][it] = cur, p = fa[p];
if(!p) return fa[cur] = 1, cur;
int q = son[p][it];
if(len[p] + 1 == len[q]) return fa[cur] = q, cur;
int cl = ++cnt; cpy(son[cl], son[q], S);
len[cl] = len[p] + 1, fa[cl] = fa[q], fa[q] = fa[cur] = cl;
while(son[p][it] == q) son[p][it] = cl, p = fa[p];
return cur;
}
int node = 1, pos[N], tr[N][S];
void ins(string s) {
int p = 1;
for(char it : s) {
if(!tr[p][it - 'a']) tr[p][it - 'a'] = ++node;
p = tr[p][it - 'a'];
}
}
void build() {
queue <int> q; q.push(pos[1] = 1);
while(!q.empty()) {
int t = q.front(); q.pop();
for(int i = 0, p; i < S; i++) if(p = tr[t][i])
pos[p] = ins(pos[t], i), q.push(p);
}
}
int main() {
cin >> n;
for(int i = 1; i <= n; i++) cin >> s, ins(s);
build();
for(int i = 2; i <= cnt; i++) ans += len[i] - len[fa[i]];
cout << ans << endl;
return 0;
}
2.7 常用技巧与结论
2.7.1 线段树合并维护
对于部分题目,我们需要维护每个状态的
为此,我们在
注意,线段树合并时会破坏原有线段树的结构,因此若需要在线段树合并后保留每个状态的
特别的,如果仅为了得到
2.7.2 桶排确定 dfs 顺序
显然后缀链接树上父亲的
2.7.3 快速定位子串
给定区间
2.7.4 其它结论
- 在
2.8 注意点总结
- 做题时不要忘记初始化
- 第二个
while不要写成son[p][it] = cur,应为son[p][it] = cl。 - SAM 开两倍空间。
- 对于多串 SAM,如果每插入一个新字符串时令
2.9 例题
I. P3804 【模板】后缀自动机 (SAM)
对
#include <bits/stdc++.h>
using namespace std;
#define ll long long
#define cpy(x, y, s) memcpy(x, y, sizeof(x[0]) * (s))
const int N = 2e6 + 5; // 不要忘记开两倍空间
const int S = 26;
char s[N];
int cnt = 1, las = 1;
int son[N][S], len[N], fa[N];
int ed[N], buc[N], id[N];
ll n, ans;
void ins(char s) {
int it = s - 'a', cur = ++cnt, p = las;
las = cur, len[cur] = len[p] + 1, ed[cur] = 1;
while(!son[p][it]) son[p][it] = cur, p = fa[p];
if(!p) return fa[cur] = 1, void();
int q = son[p][it];
if(len[p] + 1 == len[q]) return fa[cur] = q, void();
int cl = ++cnt; cpy(son[cl], son[q], S);
len[cl] = len[p] + 1, fa[cl] = fa[q], fa[q] = fa[cur] = cl;
while(son[p][it] == q) son[p][it] = cur, p = fa[p];
}
int main() {
scanf("%s", s + 1), n = strlen(s + 1);
for(int i = 1; i <= n; i++) ins(s[i]);
for(int i = 1; i <= cnt; i++) buc[len[i]]++;
for(int i = 1; i <= n; i++) buc[i] += buc[i - 1];
for(int i = cnt; i; i--) id[buc[len[i]]--] = i;
for(int i = cnt; i; i--) ed[fa[id[i]]] += ed[id[i]];
for(int i = 1; i <= cnt; i++) if(ed[i] > 1) ans = max(ans, 1ll * ed[i] * len[i]);
cout << ans << endl;
return 0;
}
II. P4070 [SDOI2016]生成魔咒
非常裸的 SAM,插入每个字符后新增的子串个数为
*III. P4022 [CTSC2012]熟悉的文章
首先二分答案
IV. P5546 [POI2000]公共串
建出 GSAM 后,设
V. P3346 [ZJOI2015]诸神眷顾的幻想乡
由于叶子节点仅有
VI. P3181 [HAOI2016]找相同字符
建出两个串的 GSAM,设
VII. P5341 [TJOI2019]甲苯先生和大中锋的字符串
建出
VIII. P4341 [BJWC2010]外星联络
SAM 的转移函数刻画了一个字符串
*IX. P3975 [TJOI2015]弦论
根据一条路径表示一个子串的性质,考虑求出从每个节点开始的路径条数
*X. H1079 退群杯 3rd E.
给定字符串
,多次询问求 有多少个子串包含 。 。
设
转化贡献形式,考虑每个落在
XI. CF316G3 Good Substrings
对所有串建出 GSAM,求出每个状态所表示的串在
如果用先建出字典树再建 GSAM 的方法,空间开销会比较大,需要用 unsigned short 卡空间。
XII. SP8222 NSUBSTR - Substrings
这就属于 SAM 超级无敌大水题了吧。
XIII. 某模拟赛 一切的开始
给定字符串
,求其两个 不相交 子串的长度乘积最大值,满足其中一个子串为另一个子串的子串。 。
对
综上,答案即
*XIV. CF1037H Security
考虑直接在后缀自动机的 DAWG 上贪心。使用线段树合并判断当前字符串是否作为
*XV. CF700E Cool Slogans
容易发现
再根据 2.7.4 的结论一(实际上这个结论是笔者做本题时才遇到的),我们可以设
*XVI. CF666E Forensic Examination
SAM 各种常用技巧结合版。首先对
使用线段树合并,预处理
2.10 相关链接与资料
- OI wiki:后缀自动机(SAM)。
- hihoCoder:后缀自动机一。
- hihoCoder:后缀自动机二。
- Linshey:对 SAM 和 PAM 的一点理解。
- 洛谷题单:SA & SAM。
- 辰星凌:题解 P6139 【模板】广义后缀自动机(广义SAM)。
3. 回文自动机 PAM
省选前两周填坑。之所以不是省选之后是因为担心省选考这玩意。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!