常见字符串算法
关于本博客的修订版,见 字符串基础
一些基本定义:
- \(\mathrm {lcp}(s,t)\) 表示两个字符串 \(s,t\) 的最长公共前缀 longest common prefix。类似的,\(\mathrm{lcs}(s,t)\) 表示 \(s,t\) 的最长公共后缀 longest common suffix。
- \(s[l,r]\) 和 \(s_{l,r}\) 表示字符串 \(s\) 位置 \(l\sim r\) 上的字符连接而成的子串。若 \(l=1\) 或 \(r=n\) 则有时省略,即 \(s[,r]\) 表示 \(s\) 长度为 \(r\) 的前缀,\(s[l,]\) 表示长度为 \(|s|-l+1\) 的后缀,
- \(|s|\) 表示字符串 \(s\) 的长度。
- 真前缀表示非原串的前缀。真后缀同理。
Change log
- 2021.12.12. 新增 KMP 算法与 Z 算法。
- 2021.12.13. 修改部分笔误。
- 2021.12.23. 新增前言。
- 2021.12.24. 新增 SA 应用部分。
- 2022.1.10 新增几个 SA 应用与例题。
0. 前言
几乎所有字符串算法都存在一个共同特性:基于所求信息的特殊性质与已经求出的信息,使用增量法均摊复杂度求得所有信息。这是动态规划算法的又一体现。
Manacher 很好地印证了这一点:它以所求得的最右回文子串的回文中心 \(d\) 与回文半径 \(r\) 为基本,利用其回文的性质,通过均摊右端点移动距离保证在线性的时间内求得以每个位置为中心的最长回文半径。
接下来的后缀数组 SA,KMP 算法,Z 算法与后缀自动机等常见字符串结构无不遵循这一规律。读者在阅读时可以着重体会该技巧,个人认为这种思想对于提升解决问题的能力有极大帮助。
1. Manacher 算法
1.1. 算法简介
首先将字符串所有字符之间(包括头尾)插入相同分隔符,因为 Manacher 仅能找到长度为奇数的回文串。并在整个字符串最前方额外插入另一种分隔符,防止越界。
设以字符 \(s_i\) 为对称中心的回文串中最长的回文半径为 \(p_i\)。一个位置 \(i\) 的回文半径定义为以 \(i\) 为对称中心的所有长度为奇数(显然,若一个回文串以单独某个字符而非两字符之间的空隙为对称中心,其长度必然为奇数)的回文串 \(s[l,r]\) 两端与 \(i\) 的距离 \(+1\)。若 \(x\) 是 \(i\) 的回文半径,则 \(s[i - x + 1, i + x - 1]\) 是回文串。
显然,若 \(x\) 是某一位置的回文半径,则任何小于 \(x\) 的正整数都是该位置的回文半径。
Manacher 算法:记录在所有遍历过的位置 \(1\sim i-1\) 中,以任意一个点为对称中心的回文串的右端点最大值 \(r\),即 \(r=\max_{\\j=1}^{i-1}j+p_j-1\),设 \(d\) 即为取到这个最大值的对称中心。\(r\) 和 \(d\) 都需实时更新。
对于当前位置 \(i\),若 \(i>r\),则直接暴力求 \(p_i\)。否则 \(i\leq r\),先将 \(p_i\) 赋值为 \(\min(r-i+1,p_{2d-i})\),再逐位扩展。说明:因为位置 \(2d-i\) 与 \(i\) 对称(在 \(d\) 的最长回文半径范围内),所以在 \([d-p_d+1,d+p_d-1]\) 范围内,以 \(2d-i\) 为对称中心的回文串也是以 \(i\) 为对称中心的回文串。若 \(p_{2d-i}<r-i+1\),根据对称性,\(p_i\) 的最终值就等于 \(p_{2d-i}\)(否则 \(p_{2d - i}\) 还可以更大,与其满足的最大性矛盾)。否则 \(p_i\) 被初始化为 \(r-i+1\),使得每次扩展都会将 \(r\) 向右移动 \(1\),故时间复杂度均摊线性。模板题代码如下:
const int N = 2.2e7 + 5;
int n, m, ans, p[N]; char s[N >> 1], t[N];
int main(){
scanf("%s", s + 1), n = strlen(s + 1), t[0] = '#', t[m = 1] = '@';
for(int i = 1; i <= n; i++) t[++m] = s[i], t[++m] = '@'; t[++m] = '!';
for(int i = 1, r = 0, d = 0; i < m; i++) {
if(i > r) p[i] = 1; else p[i] = min(p[2 * d - i], r - i + 1);
while(t[i - p[i]] == t[i + p[i]]) p[i]++;
if(i + p[i] - 1 > r) d = i, r = i + p[i] - 1; cmax(ans, p[i] - 1);
} cout << ans << endl;
return 0;
}
1.2. 应用
利用 Manacher 算法,我们可以求出以每个字符开头或结尾的最长回文子串:考虑一个位置 \(i\) 及其最长回文半径 \(p_i\),若 \(i+p_i-1>r\) 根据算法我们用 \(i+p_i-1\) 更新 \(r\)。考虑枚举 \(j\in[r+1,i+p_i-1]\),若 \(t_j\) 对应原串字符 \(s_k\) 而非分隔符,则原串中以 \(s_k\) 结尾的最长回文子串长度为 \(j-i+1\)。实现见例题 I。
1.3. 例题
I. P4555 [国家集训队]最长双回文串
对每个位置求出以该字符开头和结尾的最长回文子串 \(l_i\) 和 \(r_i\),则 \(\max_{\\i=1}^{n=1}l_i+r_{i+1}\) 即为所求。时间复杂度线性。
const int N = 2e5 + 5;
int n, m, ans, p[N], x[N], y[N];
char s[N], t[N];
int main(){
scanf("%s", s + 1), n = strlen(s + 1), t[0] = '!', t[m = 1] = '@';
for(int i = 1; i <= n; i++) t[++m] = s[i], t[++m] = '@'; t[++m] = '#';
for(int i = 1, r = 0, d = 0; i < m; i++) {
p[i] = r < i ? 1 : min(r - i + 1, p[2 * d - i]);
while(t[i - p[i]] == t[i + p[i]]) p[i]++;
if(i + p[i] - 1 > r) {
for(int j = r + 1; j <= i + p[i] - 1; j++)
if(j % 2 == 0) x[j >> 1] = j - i + 1;
r = i + p[i] - 1, d = i;
}
} for(int i = m - 1, r = m, d = 0; i; i--) {
p[i] = i < r ? 1 : min(i - r + 1, p[2 * d - i]);
while(t[i - p[i]] == t[i + p[i]]) p[i]++;
if(i - p[i] + 1 < r) {
for(int j = i - p[i] + 1; j < r; j++)
if(j % 2 == 0) y[j >> 1] = i - j + 1;
r = i - p[i] + 1, d = i;
}
} for(int i = 1; i < n; i++) ans = max(ans, x[i] + y[i + 1]);
cout << ans << endl;
return 0;
}
II. P1659 [国家集训队]拉拉队排练
以 \(i\) 为对称中心所有长度 \(j\in [1,p_i]\) 的回文半径都存在,相当于进行若干次前缀加之后全局查询,差分即可。时间复杂度是快速幂的 \(\mathcal{O}(n\log n)\)。
III. P5446 [THUPC2018]绿绿和串串
转化一下题意,任何回文中心 \(i\) 使得存在以位置 \(n\) 结尾的回文串都符合题意,以及若回文中心 \(i\) 存在以位置 \(1\) 开头的回文串且位置 \(2i-1\) 符合题意也可。于是就是裸的马拉车了。时间复杂度 \(\mathcal{O}(n)\)。
IV. P6216 回文匹配
首先 KMP 求出 \(s_2\) 在 \(s_1\) 中所有出现位置(结尾)\(\{p_i\}\),考虑一个回文子串 \(s_{l,r}\) 对答案的贡献:\(|\{p_i\mid p_i\in [l+|s_2|-1,r]\}|\)。注意这对于固定的对称中心 \(i\) 随着回文半径 \(j\) 从 \(1\) 增大至 \(p_i\),\([l+|s_2|-1,r]\) 的左右端点单调向两侧不断扩展 \(1\),按照 \(i\) 割开,对于左边就是 \([j\in p_i]\times (j-(i-p_i))\)。右边同理。
使用一个被用烂掉的技巧:把形如 \(\sum_{\\i=1}^n(c+i)a_i\) 其中 \(c\) 是常数的柿子写成 \(\sum_{\\i=1}^nca_i+ia_i\) 的形式,维护 \(a_i\) 和 \(ia_i\) 的前缀和即可做到线性。
V. UVA11475 Extend to Palindrome
和例题 III 差不多。
2. Suffix Array 后缀数组
作为复习写下后缀数组相关博客。前置知识:桶排序。
2.1. 基本定义
- 设 \(su_i\) 表示字符串 \(s\) 以 \(s_i\) 为开头的后缀,称为 \(i\) 后缀,即 \(s_{i\sim n}\)。
- 定义 \(rk_i\) 表示 \(su_i\) 在所有后缀中的字典序排名。由于任意后缀长度不同,故排名唯一。
- 定义 \(sa_i\) 表示排名为 \(i\) 的后缀的开始位置,它与 \(rk\) 互逆:\(rk_{sa_i}=sa_{rk_i}=i\)。这就是我们要求的后缀数组,简称 SA。
- 简记 \(i\) 后缀与 \(j\) 后缀的最长公共前缀为 \(\mathrm{lcp}(i,j)\)。
- 定义 \(ht_i\) 表示 \(su_{sa_{i-1}}\) 与 \(su_{sa_i}\) 的最长公共前缀长度,即 \(|\mathrm{lcp}(sa_{i-1},sa_i)|\)。特殊的,\(ht_1=0\)。
2.2. 后缀排序
后缀排序算法能够通过一系列排序操作得到一个字符串的后缀数组。它主要运用倍增的思想。
假设我们知道了所有 \(2^{w-1}\) 级子串,即所有 \(s_{i,i+2^{w-1}-1}\)(如果 \(i+2^{w-1}-1>n\),则超出的部分定义为空)的排名 \(rk_i\),那么可以算出所有 \(2^w\) 级子串的排名以及对应的 \(sa_i\):对于位置 \(i\) 和 \(j\),若 \((rk_i,rk_{i+2^{w-1}})<(rk_j,rk_{j+2^{w-1}})\),则新的 \(rk'_i<rk'_j\)。也就是说 \((rk_i,rk_{i+2^{w-1}})\) 在所有这样的二元组中的排名反映了 \(2^w\) 级子串中 \(i\) 的排名。直接排序的复杂度是线性对数平方。但是由于值域仅有 \(n\),所以基数排序优化即可做到线性对数。
在实现中,为了追求更小的常数,我们可以直接优化掉首先对第二关键字的排序:若 \(i+2^{w-1}-1>n\),那么它肯定在排序中被排到最前面,然后只需将 \(sa_i\) 按照 \(i\) 从 \(1\) 到 \(n\) 的顺序,若 \(sa_i>2^{w-1}\) 则将 \(sa_i-2^{w-1}\) 依次加入排序后的数组(数组存储的是 \(i\) 而非 \(i+2^{w-1}\) 因此需要减掉 \(2^{w-1}\)),再对其进行桶排即可。
此外,由于 \(rk_i\) 的值有上界 \(m\)(开始排序会有若干个位置 \(rk\) 值相同),桶排时只需枚举到实时记录的上界。重新统计 \(rk_i\) 时需更新上界 \(m\),若 \(m=n\) 说明排序完成,直接退出而不需要继续排到 \(2^{\log_2 n+1}\) 级子串。给出一份实现较良好的后缀排序代码,附有部分注释:
char s[N];
int n, sa[N], rk[N], ork[N << 1]; // 由于统计 rk 的时候需要用到原来的 rk, 故复制一份并开两倍空间 (i + 2 ^ {w - 1} - 1 可能超出 n 的范围)
int buc[N], id[N], pid[N];
bool cmp(int a, int b, int w) {return ork[a] == ork[b] && ork[a + w] == ork[b + w];}
void build() {
int m = 1 << 7, p = 0;
for(int i = 1; i <= n; i++) buc[rk[i] = s[i]]++;
for(int i = 1; i <= m; i++) buc[i] += buc[i - 1];
for(int i = n; i; i--) sa[buc[s[i]]--] = i;
for(int w = 1; ; w <<= 1, m = p, p = 0) {
for(int i = n; i > n - w; i--) id[++p] = i; // 循环顺序无关
for(int i = 1; i <= n; i++) if(sa[i] > w) id[++p] = sa[i] - w;
mem(buc, 0, m + 1); // 注意清空数组
for(int i = 1; i <= n; i++) buc[pid[i] = rk[id[i]]]++; // pid[i] 记录 rk[id[i]] 使访问连续
for(int i = 1; i <= m; i++) buc[i] += buc[i - 1];
for(int i = n; i; i--) sa[buc[pid[i]]--] = id[i];
cpy(ork, rk, n + 1), p = 0;
for(int i = 1; i <= n; i++) rk[sa[i]] = cmp(sa[i - 1], sa[i], w) ? p : ++p; // 原排名相同则新排名相同,否则排名 + 1
if(p == n) break; // n 个排名互不相同则排序完成
}
}
2.3. height 数组
极大多数关于 SA 的应用都需要 \(ht\) 数组的信息,可以说 后缀排序要求出 \(sa\) 是为了求出 \(rk\),求出 \(rk\) 是为了求出 \(ht\)。height 数组的定义见上部分,这里给出线性求 height 数组的方法。核心性质:\(ht_{rk_i}\geq ht_{rk_{i-1}}-1\)。
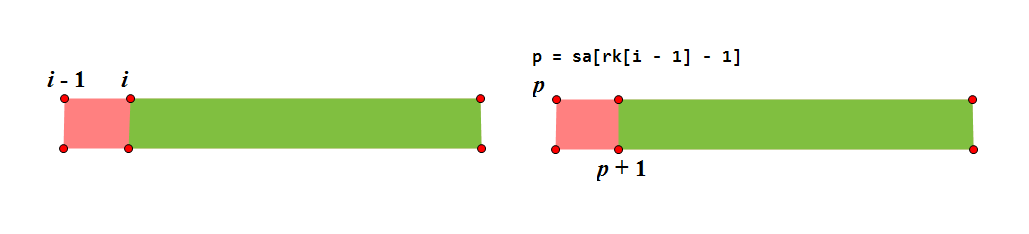
如上图,我们定义 \(p\) 为 \(i-1\) 后缀排名的前一名所对应的位置,即 \(sa_{rk_{i-1}-1}\)。因为 \(p\) 后缀的排名小于 \(i-1\) 后缀的排名,所以当 \(ht_{rk_{i-1}}>1\) 时,总有 \(s_{p+1}=s_i\),故 \(p+1\) 后缀的排名小于 \(i\) 后缀的排名。又因为 \(p+1\) 后缀与 \(i\) 后缀的 LCP 长度已经等于 \(ht_{rk_{i-1}}-1\),而排名在 \(p+1\) 后缀和 \(i\) 后缀之间的字符串与 \(i\) 后缀之间的 LCP 长度不会减少。例如按字典序排序后,两个 \(\tt abcd\) 开头的字符串之间不会出现以 \(\tt abcc\) 或 \(\tt abce\) 开头的字符串。因此 \(ht_{rk_i}\geq ht_{rk_{i-1}}-1\)。
下方求 \(ht_i\) 的代码中 \(k\) 指针的移动顺序不超过 \(2n\),故总复杂度线性。写起来很短很舒服。
for(int i = 1, k = 0; i <= n; i++) {
if(k) k--;
while(s[i + k] == s[sa[rk[i] - 1] + k]) k++;
ht[rk[i]] = k;
}
2.4. 应用
2.4.1. 求任意两个后缀的 LCP
有了 \(ht\) 数组,我们可以快速求一个字符串 \(s\) 的 \(i\) 后缀与 \(j\) 后缀的最长公共前缀 \(\mathrm{lcp}(s[i:],s[j:])\)。
接下来我们给出一个关键性质:若 \(i \neq j\),则有
\(i\) 后缀与 \(j\) 后缀的最长公共前缀长度就是夹在这两个后缀排名之间的 \(ht\) 数组的最小值。这可以由所有后缀的有序性得到。
仍然是这个例子:两个 \(\tt abcd\) 开头的后缀之间不会出现以 \(\tt abcc\) 或 \(\tt abce\) 开头的后缀。即对于任意 \(j'>j>i\),都有 \(\mathrm{lcp}(sa_i,sa_j)\geq \mathrm{lcp}(sa_i, sa_{j'})\),也即字典序排名相差越大,前缀差别越大。
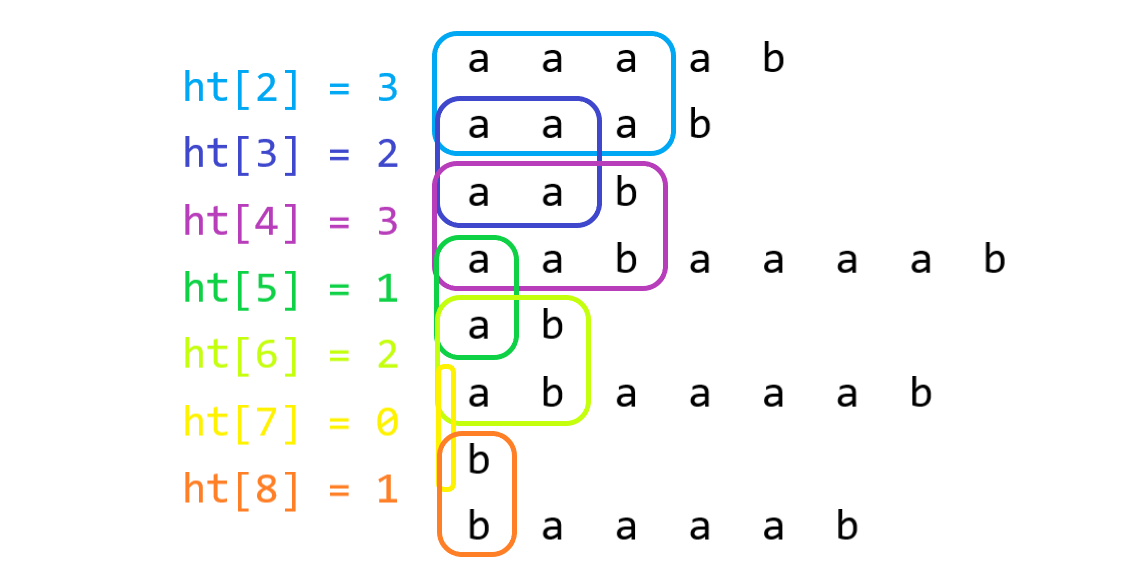
上图为对 \(\tt aabaaaab\) 后缀排序的结果及其 \(ht\) 数组,由矩形框起来的两个字符串相等。形象地,两个后缀之间的 \(\rm lcp\) 就是它们排名之间所有矩形宽度的最小值,即 \(ht\) 的最小值。
如果将整张图逆时针旋转 \(90\) 度,得到的将是一张矩形柱状图。而 \(ht\) 恰好表示了每个矩形的高度,想必这也是 height 这一名称的来源吧。也正因如此,SA 可与单调栈相结合(众所周知,单调栈可以求出柱状图中面积最大的矩形)。
由于我们需要查询区间最值,使用倍增数组维护即可做到 \(\mathcal{O}(n\log n)\) 预处理,\(\mathcal{O}(1)\) 在线回答询问。
注意点:查询时范围是 \(rk_i, rk_j\) 而非 \(i,j\),以及左边界要 \(+1\)。结合 \(sa,ht\) 数组的实际意义理解!需要特判 \(i = j\) 的情况。
2.4.2 求本质不同子串个数
考虑每次添加一个后缀,并删去这个后缀与已经添加的后缀的所有重复子串,即 \(\max_{j\in S} |\mathrm{lcp}(s_i, s_j)|\)。由于 \(\max_{j < i}|\mathrm{lcp}(sa_i, sa_j)| = |\mathrm{lcp}(sa_i, sa_{i - 1})| = ht_i\),因此考虑按照 \(sa_1,sa_2,\cdots,sa_n\) 的顺序添加后缀,答案即 \(\dbinom n 2 - \sum_{\\ i = 2} ^ n ht_i\)。
2.4.3 应用:与单调栈结合
\(ht\) 数组可以被形象地认为是一张矩形柱状图,这是我们用单调栈解决相关问题的基础。如求所有后缀两两 \(\mathrm{lcp}\) 之和,考虑按排名顺序加入所有后缀并实时维护 \(F(i) = \sum_{\\ p = 1} ^ {i - 1}|\mathrm{lcp}(sa_p,sa_i)|\),即 \(F(i) = \sum_{\\ p = 1} ^ {i - 1}\min_{q = p + 1} ^ {i} ht_q\),可以看做往单调栈内加入高为 \(ht_i\),宽为 \(1\) 的矩形后,单调栈内矩形面积之和。对所有这样的 \(F(i)\) 求和即为所求。见例题 V. & VI.
2.4.4. 应用:多个串的最长公共子串
给定 \(n\) 个字符串 \(s_1, s_2,\cdots, s_n\),求它们的最长公共子串:令 \(t = s_1c_1s_2c_2\cdots s_n\),\(L = |t|\),表示将所有字符串拼接起来,并用分隔符隔开。对 \(t\) 建出 SA 数组,问题相当于求 \(\max_{\\ 1\leq l < r\leq L} \min_{p = l + 1} ^ r|\mathrm{lcp}(p, p - 1)|\),其中 排名为 \([l, r]\) 的后缀包含了所有字符串,即对于任意 \(s_i\),它都有一个后缀的排名在 \([l, r]\) 中,这是因为我们需要同时考虑到所有 \(n\) 个字符串。
考虑用双指针维护这个过程,因为若 \([l, r]\) 满足限制,则 \([l’, r’]\ (l’ \leq l\leq r\leq r’)\) 必然满足限制。我们需要实时维护区间最小值,单调队列即可。时间复杂度是构建 SA 的线性对数,后半部分时间复杂度线性。例题见 XII.
2.5. 例题
*I. CF822E Liar
使用贪心的思想可知在一轮匹配中,我们能匹配尽量匹配,即若从 \(s_i\) 和 \(t_j\) 开启新的一段,那么我们一定会匹配直到第一个 \(k\) 使得 \(s_{i + k} \neq t_{j + k}\)。这是因为若匹配到一半就断掉,必然没有匹配到不能继续为止更优,即若前者存在符合题意的分配方案,则后者必然存在,调整法易证。
考虑到 \(x\leq 30\) 的限制很像动态规划,我们尝试设计 DP:设 \(f_{i, j}\) 表示 \(s[1,i]\) 选出最多 \(j\) 个两两不交的子串,最多能匹配到 \(j\) 的哪个位置。对于每个 \(f_{i, j}\),首先可以转移到 \(f_{i + 1, j}\) 表示不开启一段匹配。若开启一段匹配,则需要找到 \(s[i +1,n]\) 和 \(t[f_{i, j} + 1, m]\) 的最长公共前缀长度 \(L\),并令 \(f_{i +L, j}\gets \max(f_{i + L, j}, f_{i, j} + L)\)。
求一个字符串某两个后缀的 \(\rm lcp\) 是后缀数组的拿手好戏,时间复杂度 \(\mathcal{O}(n(x+\log n))\)。本题同时用到了贪心,DP 和 SA 这三个跨领域的算法,是好题。
*II. P1117 [NOI2016] 优秀的拆分
本题巧妙的地方有两点,一是通过乘法原理将 \(AABB\) 转化为以每个位置开头和结尾的 \(AA\) 数量 \(g_i / f_i\),二是枚举 \(A\) 的长度 \(L\),设置关键点并通过差分求 \(f\) 和 \(g\)。对于固定的 \(L\),若每间隔 \(L\) 放置一个关键点,则 \(AA\) 必然恰好经过两个关键点。不妨设为 \(p, q\ (p+L = q)\)。我们会在 \(q\) 处统计 \(f_i\) 即可能的结尾位置,在 \(p\) 处统计 \(g_i\) 即可能的开始位置,且 \(q\) 管辖的右端点范围为 \([q,\min(n,q+L-1)]\),\(p\) 管辖的左端点范围为 \([\max(1, p-L+1)]\)。
求出 \(s[p+1,n]\) 和 \(s[q+1,n]\) 的最长公共前缀长度 \(r\),以及 \(s[1,p]\) 和 \(s[1,q]\) 的最长公共后缀长度 \(l\)。这说明从 \([q+\max(0,L-l),q+\min(r,L-1)]\) 都可能成为 \(AA\) 的结尾位置:\(l\) 限制了右端点的最小值,即 \(AA\) 的左端点不能小于 \(p-l+1\),因为 \(s[1,p]\) 和 \(s[1,q]\) 的 LCS 只有 \(l\),这说明对于任意 \(i\in [p-l+1,p]\) 都有 \(s_i=s_{i+L}\),且 \(s_{p-l}\neq s_{q-l}\)。同理,\(r\) 限制了右端点的最大值。
求任意两个前缀的 LCS 或任意两个后缀的 LCP 用 SA 实现,时间复杂度线性对数,包括建出 SA,建出 \(ht\) 的 ST 表以及枚举 \(L\) 的调和级数。
*III. P7361 「JZOI-1」拜神
还算不错的题目。考虑建出 \(s\) 的后缀数组,考虑一次询问的本质是什么:对于长度 \(L\),它合法当且仅当存在两个位置 \(p,q\in [l,r-L+1]\ (p\neq q)\),使得 \(\mathrm{lcp}(s[p,n],s[q,n])\geq L\),这说明若将所有 \(\geq L\) 的 \(ht_i\) 值对应的两个位置 \(sa_{i-1}\) 与 \(sa_i\) 之间连边,则 \(p,q\) 在同一连通块。
显然答案满足可二分性,因此着眼于判断一个长度 \(L\) 是否合法。借鉴品酒大会的技巧,我们求出 \(ht\) 数组后从大到小加入并查集,相当于每次合并两个位置 \((sa_{i-1},sa_i)\)。对于每个长度 \(L\),在线段树上记录每个位置 \(p\) 的前驱 \(v_p\),表示 \(v_p\) 是小于 \(p\) 且和 \(p\) 在相同连通块的最靠右的位置。判断合法只需查询 \([l+1,r-L+1]\) 的区间最大值是否 \(\geq l\) 即可。
考虑如何更新 \(v_p\):启发式合并。对于每个并查集维护一个 set \(S_i\),每往 \(S_i\) 中插入一个数 \(y\),lower_bound 查询 \(y\) 的后继 \(su_y\) 与前驱 \(pr_y\),在线段树上更新 \(v_y\gets pr_y\) 且 \(v_{su_y}\gets y\)。由于要储存每个长度的线段树,所以需要可持久化。不难发现时空复杂度均为线性对数平方。
*IV. P2178 [NOI2015] 品酒大会
由于 \(r\) 相似也是 \(r'\ (0\leq r<r)\) 相似,如果仅考虑 \(\geq L\) 的 \(ht_i\),将 \(sa_{i-1}\) 和 \(sa_i\) 之间连边,若 \(p,q\) 在同一连通块,说明 \(\mathrm{lcp}(su_p,su_q)\geq L\),也即 \(p,q\) 是 “\(L\) 相似” 的。
这启发我们求出 \(ht\) 后从大到小排序离线处理,并用启发式合并实时维护每个连通块的大小以及所有权值。只需要用最大值乘以次大值,以及最小值乘以次小值(因为有负数)更新 \(L\) 的答案即可,时间复杂度线性对数平方。
进一步地,如果只记录四个极值并使用线性方法求 SA,可以做到 \(\mathcal{O}(n\alpha(n))\)。
V. P4248 [AHOI2013]差异
SA 与单调栈结合应用例题,时间复杂度线性对数。这里给出代码。
ll solve() {
static ll stc[N], w[N], top = 0, area = 0, ans = 0;
for(int i = 2; i <= n; i++) {
ll width = 1;
while(top && stc[top] >= ht[i])
width += w[top], area -= w[top] * stc[top], top--;
area += ht[i] * width, stc[++top] = ht[i], w[top] = width, ans += area;
} return ans << 1;
}
int main() {
cin >> s + 1, n = strlen(s + 1), build();
cout << 1ll * (n - 1) * n * (n + 1) / 2 - solve() << endl;
return 0;
}
VI. P7409 SvT
双倍经验。
VII. CF1073G Yet Another LCP Problem
三倍经验。注意区分 \(a_i\) 和 \(b_i\)。
VIII. P3763 [TJOI2017]DNA
枚举开始位置,使用 SA 加速匹配即可。时间复杂度线性对数。
IX. P7769 丑国传说 · 大师选徒(Selecting Apprentices)
考虑 \(a_{l+k} + a_{b + k} = s\) 的充要条件是什么:设 \(d\) 为 \(a\) 的差分数组,即 \(d_i = a_{i + 1} - a_i\),显然需要满足 \(a_l + a_b = s\) 且 \(d_{l\sim r - 1}\) 与 \(d_{b\sim b + (r - l) - 1}\) 按序互为相反数。
这启发我们把 \(d\) 以及 \(d\) 的相反数 \(d'\) 拼接在一起,得到序列 \(D\)。然后求出其后缀数组,问题转化为:求是否存在 \(D\) 的后缀 \(D[i,2n]\),满足 \(i > n\) 且 \(a_{i - n} = s - a_l\) 且 \(|\mathrm{lcp}(D[i, 2n],D[l, 2n])| \geq r - l\)。对于第三条限制我们容易处理:定位 \(l\) 后缀的排名,那么符合要求的后缀的排名一定是一段区间 \([x, y]\ (x\leq rk_l\leq y)\)。可以首先预处理 \(ht\) 的倍增 RMQ 数组,然后二分 + RMQ 求出。
对于限制 1 和 2,开个桶 \(buc_c\) 记录 \(i > n\) 且 \(a_{i - n} = c\) 的所有 \(i\) 后缀的 \(rk\),询问即查询 \(buc_{s - a_l}\) 中是否存在 \([x, y]\) 之间的数。首先对每个桶排序,回答询问时直接二分查找即可。时空复杂度均为线性对数,强烈谴责出题人 std 使用 \(\rm 100M\) 空间限制开 \(\rm128M\) 的行为。
X. P5028 Annihilate
考虑枚举每个字符串 \(s_i\),然后从小到大枚举每个排名 \(j\),单调队列维护区间最小值即可。时间复杂度 \(\mathcal{O}(n\sum s_i)\)。
XI. P2852 [USACO06DEC]Milk Patterns G
考虑从大到小添加每个 \(rk_i\),等价于在 \(sa_i\) 和 \(sa_{i - 1}\) 连边,使得出现大小为 \(k\) 的连通块的 \(rk_i\) 即为所求。
XII. P2463 [SDOI2008] Sandy 的卡片
将 \(M_i\) 数组差分后即求所有 \(n\) 个数组的最长公共子串,用双指针加单调队列实现。时间复杂度线性对数。
const int N = 1.1e5 + 5;
int n, L, ans, a[N], bel[N], s[N];
int sa[N], ht[N], rk[N], ork[N << 1];
int buc[N], id[N], pid[N];
bool cmp(int a, int b, int w) {return ork[a] == ork[b] && ork[a + w] == ork[b + w];}
void build() {
int m = N - 5, p = 0;
for(int i = 1; i <= L; i++) buc[rk[i] = s[i]]++;
for(int i = 1; i <= m; i++) buc[i] += buc[i - 1];
for(int i = L; i; i--) sa[buc[rk[i]]--] = i;
for(int w = 1; ; w <<= 1, m = p, p = 0) {
for(int i = L; i > L - w; i--) id[++p] = i;
for(int i = 1; i <= L; i++) if(sa[i] > w) id[++p] = sa[i] - w;
cpy(ork, rk, L + 1), mem(buc, 0, m + 1);
for(int i = 1; i <= L; i++) buc[pid[i] = rk[id[i]]]++;
for(int i = 1; i <= m; i++) buc[i] += buc[i - 1];
for(int i = L; i; i--) sa[buc[pid[i]]--] = id[i]; p = 0;
for(int i = 1; i <= L; i++) rk[sa[i]] = cmp(sa[i - 1], sa[i], w) ? p : ++p;
if(p == L) break;
}
for(int i = 1, k = 1; i <= L; i++) {
if(k) k--;
while(s[i + k] == s[sa[rk[i] - 1] + k]) k++;
ht[rk[i]] = k;
}
}
int main() {
cin >> n;
if(n == 1) cout << read() << endl, exit(0);
for(int i = 1, m; i <= n; i++) {
cin >> m;
for(int j = 1; j <= m; j++) a[j] = read();
for(int j = 2; j <= m; j++) s[++L] = a[j] - a[j - 1] + 2e3, bel[L] = i;
s[++L] = 1e5 + i;
} build(), mem(buc, 0, N);
static int d[N], hd = 1, tl = 0;
for(int i = 1, l = 1, cnt = 0; i <= L && s[sa[i]] <= 1e5; i++) {
cnt += !buc[bel[sa[i]]], buc[bel[sa[i]]]++;
while(cnt == n && buc[bel[sa[l]]] > 1) buc[bel[sa[l]]]--, l++;
while(hd <= tl && d[hd] <= l) hd++;
if(i > 1) {
while(hd <= tl && ht[d[tl]] >= ht[i]) tl--;
d[++tl] = i;
} if(cnt == n) cmax(ans, ht[d[hd]]);
} cout << ans + 1 << endl;
return flush(), 0;
}
XIII. P6095 [JSOI2015]串分割
显然的贪心是让最大位数最小,即答案串长度 \(len = \left \lceil \dfrac n k \right\rceil\)。
同时答案 在后缀数组中的排名 满足可二分性。我们破环成链,枚举 \(len\) 个起始点并判断是否可行。具体来说,假设当前匹配到 \(i\),若 \(s_{i, i + len-1}\) 的排名不大于二分的答案,那么就匹配 \(len\) 位,否则匹配 \(len-1\) 位。若总匹配位数不小于 \(n\) 则可行。
正确性证明:若可匹配 \(len\) 位时匹配 \(len-1\) 位,则下一次最多匹配 \(len\) 位,这与首先匹配 \(len\) 位的下一次匹配的 最坏 情况,即匹配 \(len-1\) 位,是相同的。
3. KMP 算法
重新复习基础算法 ing……
3.1. 算法简介
KMP 算法可以在 \(|s|+|t|\) 的时间内解决两个字符串的匹配问题。所谓匹配问题,就是求一个字符串 \(t\ (m=|t|)\) 在另一个字符串 \(s\ (n=|s|)\) 中所有出现位置。当然,也可以通过字符串哈希做到同样复杂度,但 KMP 算法为我们提供了更多的信息。
维护两个指针 \(i,j\) 表示当前 \(s_i\) 与 \(t_j\) 匹配。尝试移动指针,若 \(s_{i+1}\neq t_{j+1}\),说明我们需要重新开始一轮匹配。暴力的做法是令 \(i\) 变成 \(i-j+2\),然后 \(j\) 变成 \(1\),相当于将匹配的开始位置向右移动 \(1\),但复杂度变成了更劣的 \(nm\)。
此时,三位大神横空出世(大雾),提出了这样一个解决方法:因为我们知道 \(s[i-j+1,i]\) 与 \(t[1,j]\) 是匹配的,所以接下来一个有可能匹配成功开始位置 \(p\),一定满足 \(s[p,i]\) 与 \(s[i-j+1,i-j+(i-p+1)]\) 相等。
例如 \(s=\tt abababc\),\(t=\tt ababc\),我们首先会匹配到 \(i=4\),\(j=4\)。但是 \(s_5\neq t_5\) 失配了。根据暴力算法,我们会令 \(i\gets 2\),\(j\gets 1\) 重新进行匹配。但是 \(s_2\) 和 \(t_1\) 根本没有匹配的可能:\(s[1,4]=t[1,4]\),而 \(s[2,4]=t[2,4]\neq t[1,3]\)。那么,究竟应该如何找到这样的 \(p\) 呢?
给出结论:记 \(nxt_p\) 表示 \(t[1,p]\) 最长的相等真前缀与真后缀,即 \(t[1,nxt_p]=t[p-nxt_p+1,p]\) 且 \(nxt_p<p\) 且 \(nxt_p\) 最大,第一个可能的匹配位置为 \(i-nxt_j+1\)。原因如下:如果某个小于 \(i-nxt_j+1\) 的位置 \(p\) 可能匹配,那么说明 \(s[p,i]=t[1,i-p+1]\),又因为 \(s[p,i]=t[j-(i-p+1)+1,j]\),所以 \(t[1,i-p+1]=t[j-(i-p+1)+1,j]\)。这说明 \(nxt_j\) 可以等于 \(i-p+1\)。但 \(p<i-nxt_j+1\) 即 \(nxt_j<i-p+1\),这与 \(nxt_j\) 最大的定义矛盾。得证。
对于 \(t=\tt ababc\),其 \(nxt\) 数组即 \(\{0,0,1,2,0\}\)。我们在 \(s_5\neq t_5\) 处失配了,因此令 \(j\gets nxt_j=2\) 继续尝试匹配。\(j\gets nxt_j\) 一句跳过了很多东西:它首先忽略了根本没有匹配可能的开始位置,又跳过了从第一个可能匹配的开始位置 \(i-nxt_j+1\) 匹配 \(nxt_j\) 个字符到 \(i\) 的过程:因为我们已经知道了 \(s[i-nxt_j+1,i]=t[j-nxt_j+1,j]=t[1,nxt_j]\),所以没有必要再花 \(nxt_j\) 步模拟到达一个已知一定会出现的状态(即 \(i\) 还是原来的 \(i\),\(j\) 变成了 \(nxt_j\)),而是直接一步得到。
求出 \(nxt_p\) 的过程也很有技巧性:我们让 \(t\) 对自己做匹配,这其实是一种增量法,也是动态规划思想的体现。假设 \(nxt_1\sim nxt_p\) 已知,我们要求 \(nxt_{p+1}\):
- 首先令 \(i\gets nxt_p\),这表示 \(t[1,p+1]\) 的最长相等前缀后缀一定由 \(t[1,p]\) 的相等前缀后缀(不一定最长,因为可能不匹配)扩展而来,我们先尝试最长的那个相等前缀后缀。
- 尝试匹配 \(s_{i+1}\) 和 \(s_{p+1}\),若匹配,则得到 \(nxt_{p+1}=i+1\)。
- 否则我们要找到最大的 \(i'\) 使得 \(i'<i\) 且 \(t[1,p]\) 存在长度为 \(i'\) 的相等前缀后缀。注意到因为 \(t[1,p]\) 存在长度为 \(i\) 的相等前缀后缀,故 \(t[1,p]\) 长度不大于 \(i\) 的后缀也一定是 \(t[1,i]\) 的后缀。这表明我们要求的 \(i’\) 和 \(nxt_i\) 的定义本质相同。因此令 \(i\gets nxt_i\)。
- 不断重复上述过程直到找到一个 \(i\) 使得 \(s_{i+1}\) 与 \(s_{p+1}\) 成功匹配(\(nxt_{p+1}=i+1\))或者 \(i=0\),此时直接判断是否有 \(t_1=t_{p+1}\) 即可,若是,则 \(nxt_{p+1}=1\) 否则 \(nxt_{p+1}=0\)。
KMP 非常好写,模板题 P3375 【模板】KMP 字符串匹配 代码:
const int N = 1e6 + 5;
int n, m, nxt[N]; char s1[N], s2[N];
int main(){
scanf("%s %s", s1 + 1, s2 + 1), n = strlen(s1 + 1), m = strlen(s2 + 1);
for(int i = 2, p = 0; i <= m; i++) {
while(p && s2[p + 1] != s2[i]) p = nxt[p];
p = nxt[i] = p + (s2[p + 1] == s2[i]);
} for(int i = 1, p = 0; i <= n; i++) {
while(p && s1[i] != s2[p + 1]) p = nxt[p];
if((p += s1[i] == s2[p + 1]) == m) printf("%d\n", i - m + 1), p = nxt[p];
} for(int i = 1; i <= m; i++) printf("%d ", nxt[i]);
return 0;
}
相较于字符串哈希,KMP 算法为我们提供了非常有用的 \(nxt\) 数组,牢记它的定义:\(nxt_i\) 表示 \(s[1,i]\) 最长相等真前缀后缀。很多时候我们使用 KMP 算法不是为了求解字符串匹配,而是为了用 \(nxt\) 数组解题。
注意点:很多时候题目会给 \(nxt\) 数组一些奇奇怪怪的限制(如例题 II. 中,相同公共前缀后缀不能超过串长一半),但我们不能在一开始求 \(nxt\) 时就将这些限制条件加入,而是先完整地求完一遍 \(nxt\) 后再利用其提供的信息解题。因为 KMP 算法的正确性基于求 \(nxt_i\) 时已知的 \(nxt_1\sim nxt_{i-1}\) 的最大性。这好比我们不能给高速行驶的汽车(求 KMP 的过程)换轮胎(加限制),只有当车停下来之后(求得 \(nxt\) 数组)才可以(加限制)。
3.2. 扩展:KMP 自动机
KMP 自动机是一种确定有限状态自动机。
对一个长度为 \(n\) 的字符串 \(s\) 建立 KMP 自动机,它的状态集合 \(Q\) 为 \(0\sim n\)。每个结点 \(i\) 表示已经输入的所有字符 \(t[1,p]\) 与 \(s\) 的前缀匹配长度为 \(i\),即 \(t[p-i+1,p]=s[1,i]\)。它的转移函数 \(\delta(i,c)\) 为:
很好理解:若当前字符匹配,则匹配长度 \(+1\)。否则若 \(i=0\) 显然匹配长度仍为 \(0\),否则找到 \(s[1,i]\) 的最长相等前缀后缀长度 \(nxt_i\),\(i\) 接受字符 \(c\) 转移到的状态就是 \(nxt_i\) 接受字符 \(c\) 转移到的状态,而 \(nxt_i<i\) 所以 \(\delta(nxt_i,c)\) 已知。例题见 I.
int tr[N][26];
for(int i = 0; i <= n; i++) {
for(int j = 'a'; j <= 'z'; j++)
if(i < n && s[i + 1] == j) tr[i][j] = i + 1;
else if(!i) tr[i][j] = 0;
else tr[i][j] = tr[nxt[i]][j];
}
3.3. 应用:失配树与 Border 理论
见 Part 5. border 理论部分。
3.4. 应用:AC 自动机
3.5. 例题
I. P3193 [HNOI2008]GT考试
KMP 自动机。设 \(g_{i,j}\) 表示当匹配长度为 \(i\) 时有多少种加字符的方式能使得匹配长度变为 \(j\),形式化地:
设 \(f_{i,j}\) 表示长度为 \(i\) 的准考证,和 \(A\) 匹配到了第 \(j\) 位的方案数(有点 DP 自动机的味道),那么 \(f_{i+1,k}=\sum_{\\j=0}^{m-1}f_{i,j}g_{j,k}\)。注意到这是矩阵乘法的形式,因此矩阵快速幂解决即可。时间复杂度 \(\mathcal{O}(m^3\log n)\)。
*II. P2375 [NOI2014] 动物园
相当于对每个前缀求其最长的长度不超过串长一半的 border 在失配树上的深度。为此,我们首先求一遍 \(nxt\) 数组,然后用 \(s\) 匹配自己,特别地,若任意 \(i\) 前缀与 \(s\) 的匹配长度 \(j\) 大于 \(\dfrac i 2\) 则需要不断跳 \(nxt_j\) 直到 \(j\leq \dfrac i 2\)。
为什么不能在一开始就限制 \(nxt_i\leq \dfrac i 2\) 呢?因为这样会导致求得的 \(nxt_i\) 错误。具体原因见 Part 3.1. 结尾部分注意事项。
III. UVA11022 String Factoring
经 典 老 题。设 \(f_{l,r}\) 表示 \(s[l,r]\) 能够被压缩成的最短长度,分两种情况讨论:枚举分割点 \(p\),\(f_{l,r}=\min_{\\l\leq p<r} f_{l,p}+f_{p+1,r}\) 或者压缩整个串,枚举压缩成的长度 \(p\),若 \(s[l,r]\) 具有整周期 \(p\) 则 \(\mathrm{checkmin}(f_{l,r},f_{l,l+p-1})\),周期和 border 的定义见 Part 5. Border 理论。
预处理 \(nxt_{i,j}\) 表示对 \(s[i+1,n]\) 建 \(nxt\) 数组后 \(j\) 的 \(nxt\) 值,不断跳 \(nxt\) 找 border,因为一个 border 对应一个周期。这样我们可以在 \(\mathcal{O}{(r-l)}\) 时间内找到所有周期。因此总复杂度 \(\mathcal{O}(n^3)\),比暴力判断周期的 \(\mathcal{O}(n^4)\) 更快一点。
*IV. P3449 [POI2006]PAL-Palindromes
神仙题!看到题目,我的想法是如果 \(s_j\) 能接到 \(s_i\) 后面,说明 \(s_j\) 是 \(s_i\) 的前缀。因此,对枚举每个 \(s_i\) 的每一位 \(p\),求出 \(s_{i}[1,p]\) 在 \(s\) 中的出现次数,以及 \(s_i[p+1,|s_i|]\) 是否是回文串。这可以通过简单的字符串哈希在线性对数时间内做到。
注意到我们根本没有用到 \(s\) 是回文串的性质。这好吗?这不好。我们有一个更强的性质:在 \(s_i,s_j\) 是回文串的前提下,\(s_i+s_j\) 是回文串(命题 \(P\))当且仅当它们的最短回文整周期串相同(命题 \(Q\))。
充分性(\(Q\Rightarrow P\)):显然。
在证明必要性之前,我们给出一个引理:若长度为 \(n\) 的回文串 \(s\) 存在回文周期 \(p\),则存在长为 \(\gcd(n,p)\) 的回文整周期。利用数学归纳法证明如下:
-
当 \(p\mid n\) 时,显然成立。
-
设串 \(A=s[1,p]\),\(B=s[n-n\bmod p+1,n]\),即 \(s=AA\cdots AB\)。设 \(q=|B|\),显然 \(q=n\bmod p>0\)。设 \(B_R\) 表示 \(B\) 翻转后得到的串。
由于 \(s,A\) 都是回文串,故 \(s=B_RA\cdots AA\)。因为 \(B\) 是 \(A\) 的前缀,\(B_R\) 也是 \(A\) 的前缀,所以 \(B=B_R\) 即 \(B\) 回文。故 \(s=BA\cdots AA\)。
因为 \(A\) 是 \(BA\) 的前缀,所以 \(A[1,q]=A[q+1,2q]\)。同理,\(A[q+1,2q]=A[2q+1,3q]=\cdots\)。这说明 \(|B|\) 是 \(A\) 的回文周期。
-
这是一个递归式的子命题:若长度为 \(p\) 的回文串 \(A\) 存在回文周期 \(q\),则存在长为 \(\gcd(p,q)\) 的回文整周期。若子命题成立,则原命题成立。
-
由于 \(\gcd(n,p)=\gcd(p,n\bmod p)=\gcd(p,q)\),类似辗转相除法,因此必然出现 \(p'\mid n\) 的情况,此时 \(p'=\gcd(n,p)\)。故原命题成立。
数学归纳法真好用。
必要性(\(P\Rightarrow Q\)):考虑反证法,设 \(s_i\) 最短回文周期对应的回文串为 \(x\)(下文省略 “对应的” 字样),\(s_j\) 的为 \(y\)。不妨设 \(|x| < |y|\)(\(|x|=|y|\) 时显然若 \(s_i+s_j\) 回文则 \(x=y\) )。
-
首先,\(x\) 不可能是 \(y\) 某个整周期回文串,否则 \(s_j\) 最短回文周期不大于 \(|x|\),显然矛盾。
-
当 \(|s_i|<|y|\) 时,因为 \(s_i+s_j=s_iyy\cdots y\),而 \(s_i\) 和 \(s_i+s_j\) 是回文串,所以 \(s_i+s_j=yy\cdots ys_i\)。故 \(y[1,|s_i|]=y[|s_i|+1,2|s_i|]=\cdots\),即 \(|s_i|\) 是 \(y\) 的回文周期。
根据引理,这说明 \(y\) 存在回文整周期 \(d=\gcd(|y|,|s_i|)<|y|\),从而有 \(s_j\) 的最短回文周期不大于 \(d\) 即小于 \(|y|\),与 \(y\) 的定义矛盾。
-
当 \(|s_i|\geq |y|\) 时,因为 \(y\) 和 \(s_i+s_j\) 是回文串,所以 \(s_i[1,|y|]=y\)。这说明 \(|x|\) 是 \(y\) 的回文周期。
根据引理,\(y\) 存在回文整周期 \(d=\gcd(|x|,|y|)<|y|\),从而有 \(s_j\) 的最短回文周期不大于 \(d\) 即小于 \(|y|\),与 \(y\) 的定义矛盾。\(\square\)
本文用了多少遍反证法(大雾)?
综上,我们只需 KMP 求出每个字符串的 \(nxt\) 数组,若 \(|s|-nxt_{|s|}\) 整除 \(|s|\) 则 \(s[1,|s|-nxt_{|s|}]\) 是最短回文周期字符串,否则最短回文周期字符串就是 \(s\) 本身。
每个最短回文周期字符串对答案的贡献为 \(c^2\),其中 \(c\) 表示它作为 \(c\) 个串的最短回文周期字符串出现。为此,我们需要排序并检查相邻两个最短回文周期字符串是否相等。时间复杂度线性对数。
*V. P3546 [POI2012]PRE-Prefixuffix
好题!不难发现若 \(S,T\) 循环相同则它们可以分别被写成 \(AB\) 和 \(BA\) 的形式。因此题目相当于:对于 \(S\) 的每个 border 长 \(p\ (2p\leq S)\),求 \(S\) 去掉 \(p\) 前缀和 \(p\) 后缀后最长的不重叠 border 长 \(q\),则 \(\max p+q\) 即答案。
\(p\) 是好求的,但每个 \(S[p+1,n-p]\) 的 border 就不好求了。考虑 \(S\) 所有这样的子串串 \(S_i=S[i+1,n-i]\),\(S_i\) 的 border 掐头去尾后变成了 \(S_{i+1}\) 的 border,因此 \(|B_{\max}(S_i)|\leq |B_{\max}(S_{i+1})|+2\)。
根据这一性质,我们从大到小枚举所有 \(i\ (1\leq i\leq n/2)\),维护长度 \(p\) 表示 \(S_i\) 的最长不重叠 border 长。当 \(i\to i-1\) 时,令 \(p\gets p+2\),然后不断减小 \(p\) 直到 \(p\) 是 \(S_i\) 的一个不重叠 border 长。势能分析,\(p\) 的移动距离不超过 \(2n\)。
判断字符串是否相等使用哈希,自然溢出哈希会被卡。求 \(S\) 的所有 border 直接 KMP 就行。时间复杂度线性。双 倍 经 验。
4. Z Algorithrm
别称 Z 算法,扩展 KMP 算法。
4.1. 算法简介
我们定义一个长度为 \(n\) 的字符串 \(s\) 的 z 函数 \(z_i\) 表示 \(s\) 的 \(i\) 后缀与 \(s\) 本身的最长公共前缀长度,即 \(z_i=|\mathrm{lcp}(s[i:n],s)|\)。一般令 \(z_1=0\)。Z 算法利用已经求得的信息的性质,通过增量法求出 z 函数。OI-wiki。
称 \([i,i+z_i-1]\) 为 \(i\) 的匹配段,也称 z-box。根据定义,\(s[i,i+z_i-1]=s[1,z_i]\)。算法中,我们实时记录最靠右侧的匹配段 \([l,r]\),初始化 \(l=r=0\)。匹配到位置 \(i\) 时,分两种情况讨论:
- 若 \(i>r\),直接暴力匹配。
- 若 \(i\leq r\),因为 \(s[1,r-l+1]=s[l,r]\),所以 \(s[i,r]=s[i-l+1,r-l+1]\)。故首先令 \(z_i=\min(r-i+1,z_{i-l+1})\),然后暴力匹配。
看完我直呼:这也太像 Manacher 了!
时间复杂度分析:当 \(z_{i-l+1}<r-i+1\) 时,\(z_i\) 不可能继续向下匹配,否则与 \(z_{i-l+1}\) 的最大性矛盾。因此,每次成功的匹配都会让 \(r\) 增加 \(1\)。因此时间复杂度是优秀的线性,代码如下:
for(int i = 2, l = 0, r = 0; i <= n; i++) {
z[i] = i > r ? 0 : min(r - i + 1, z[i - l + 1]);
while(t[1 + z[i]] == t[i + z[i]]) z[i]++;
if(i + z[i] - 1 > r) l = i, r = i + z[i] - 1;
}
4.2. 应用:字符串匹配
求字符串 \(t\) 的每个后缀 \(i\) 与 \(s\) 的最长公共前缀长度 \(p_i\)。
- 解法 1:令 \(s’=s+c+t\),其中 \(c\) 是任意分隔符,对 \(s'\) 求 z 函数。
- 解法 2:类似求 z 函数的方法,我们维护最右匹配段 \([l,r]\) 表示 \(t[l,r]=s[1,r-l+1]\),若 \(i>r\) 则暴力匹配,否则令 \(p_i=\min(z_{i-l+1},r-i+1)\)。
两种解法本质相同,因为 Z Algorithm 就相当于用 \(s\) 匹配 \(s\),类比 KMP 算法中自己匹配自己的方式求出 \(nxt\) 数组。解法 2 代码见例题 I.
4.3. 例题
I. P5410 【模板】扩展 KMP(Z 函数)
const int N = 2e7 + 5;
int n, m, z[N], p[N]; ll ans;
char s[N], t[N];
int main(){
scanf("%s %s", s + 1, t + 1), n = strlen(s + 1), z[1] = m = strlen(t + 1);
for(int i = 2, l = 0, r = 0; i <= m; i++) {
z[i] = i > r ? 0 : min(r - i + 1, z[i - l + 1]);
while(t[1 + z[i]] == t[i + z[i]]) z[i]++;
if(i + z[i] - 1 > r) l = i, r = i + z[i] - 1;
} for(int i = 1; i <= m; i++) ans ^= 1ll * i * (z[i] + 1);
cout << ans << endl, ans = 0;
for(int i = 1, l = 0, r = 0; i <= n; i++) {
p[i] = i > r ? 0 : min(r - i + 1, z[i - l + 1]);
while(p[i] < m && t[1 + p[i]] == s[i + p[i]]) p[i]++; // 注意这里应该判断 p[i] 小于模式串长度而非匹配串长度
if(i + p[i] - 1 > r) l = i, r = i + p[i] - 1;
} for(int i = 1; i <= n; i++) ans ^= 1ll * i * (p[i] + 1);
cout << ans << endl, ans = 0;
return 0;
}
*II. CF526D Om Nom and Necklace
重新表述题意:若 \(S\) 能被表示成 \(AAA\cdots AB\),其中 \(A\) 出现了 \(k\) 次且 \(B\) 是 \(A\) 的前缀,则 \(S\) 符合要求。考虑在 \(k\times A\) 处统计答案。根据 border 的性质 2:若 \(S\) 有长为 \(|S|-p\) 的 border 说明 \(S\) 有周期 \(p\),我们 KMP 求出 \(S\) 的 \(nxt\) 数组。若 \(i - nxt_i \left | \dfrac i k \right.\) 说明 \(S[1,i]\) 由 \(k\) 个相同字符串拼接而成,即 \(|A|=\dfrac i k\)。
此时仅需考虑可能的 \(B\) 的最长长度 \(r\),即 \(\min(|A|,|\mathrm{lcp}(S[i+1, n],S)|)\),后者可以用 Z 算法求得。这说明 \(S[1,i\sim i + r]\) 都可以成为答案,用差分维护即可,时间复杂度线性。
III. CF432D Prefixes and Suffixes
找到前缀后缀可用 KMP 求得 \(nxt\) 数组,求出现次数使用 \(z\) 函数 + 差分即可。时间复杂度线性。
5. Border 理论
5.1. 基础定义
定义长度为 \(n\) 的字符串 \(s\) 的 \(\mathrm{Border}(s)\) 表示 \(s\) 的所有相等真前缀后缀集合,下文简记为 \(B(s)\)。简记 \(i\) border 表示长度 \(i\) 的 border。
定义 \(s\) 的 border 中最长的一个为 \(\mathrm{Border}_{\max}(s)\),简记为 \(B_{\max}(s)\)。不难发现若对 \(s\) 建出 \(nxt\) 数组,\(nxt_n=|B_\max(s)|\)。
定义 \(p\) 为 \(s\) 的周期当且仅当 \(\forall i\in [1,n-p],s_i=s_{i+p}\)。
5.2. Border 的性质
-
性质 1:若 \(p\) 为 \(s\) 的周期,则 \(s[1,n-p]\) 为 \(s\) 的 border。
证明:因为 \(s_i=s_{i+p}\),所以 \(s[1,n-p]=s[p+1,n]\)。\(\square\)
-
性质 2:若 \(s\) 存在 border,则其最短 border 长度不超过字符串长度的一半。
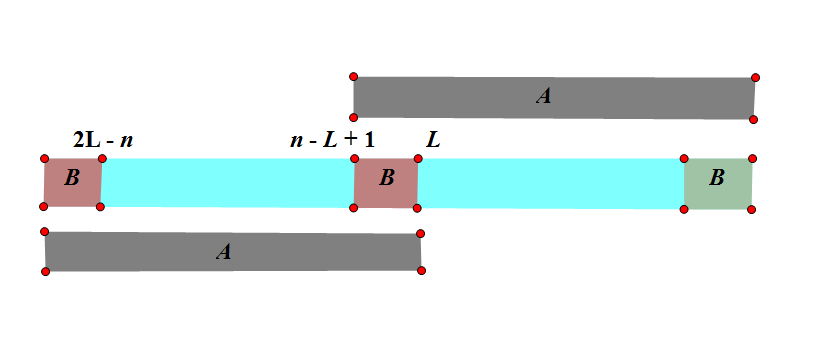
证明:设 \(s\) 的最短 border 长度为 \(L\ (2L>n)\),那么 \(s[1,L]=s[n-L+1,n]\)。因为 \(n-L+1\leq L\),所以 \(s[n-L+1,L]=s[1,2L-n]\) 且 \(s[n-L+1,L]=s[2n-2L+1,n]\)。因此 \(s[1,2L-n]\) 也是 \(s\) 的 border,这与 \(L\) 的定义矛盾,如下图。\(\square\)
-
性质 3:
5.3. 失配树
在 KMP 算法中注意到 \(nxt_i<i\),因此若从 \(nxt_i\) 向 \(i\) 连边,我们最终会得到一棵有根树。这就是失配树。
失配树有很好的性质:对于树上任意两个具有祖先 - 后代关系的节点 \(u, v\ (u\in \mathrm{ancestor}(v))\),\(s[1,u]\) 是 \(s[1,v]\) 的 Border。这一点由 \(nxt\) 的性质可以得到。因此,若需要查询 \(u\) 前缀和 \(v\) 前缀的最长公共 border,只需要查询 \(u,v\) 在失配树上的 LCA 即可。模板题 P5829 【模板】失配树 代码:
const int N = 1e6 + 5;
const int K = 20;
int n, m, lg, dep[N], fa[K][N]; char s[N];
int main(){
scanf("%s %d", s + 1, &m), n = strlen(s + 1), lg = log2(n), dep[0] = 1, dep[1] = 2;
for(int i = 2, p = 0; i <= n; i++) {
while(p && s[p + 1] != s[i]) p = fa[0][p];
dep[i] = dep[p = fa[0][i] = p + (s[p + 1] == s[i])] + 1;
} for(int i = 1; i <= lg; i++) for(int j = 2; j <= n; j++) fa[i][j] = fa[i - 1][fa[i - 1][j]];
while(m--) {
int u, v; scanf("%d %d", &u, &v), u = fa[0][u], v = fa[0][v];
if(dep[u] < dep[v]) swap(u, v);
for(int i = lg; ~i; i--) if(dep[fa[i][u]] >= dep[v]) u = fa[i][u];
for(int i = lg; ~i; i--) if(fa[i][u] != fa[i][v]) u = fa[i][u], v = fa[i][v];
cout << (u == v ? u : fa[0][u]) << "\n";
} return 0;
}
暂时没见到失配树有什么应用。
I. P4391 [BOI2009]Radio Transmission 无线传输
来一道基础题:根据性质 1,要求 \(s_1\) 的最短周期,只需要用 \(n-nxt_n\) 即可。
*II. P3435 [POI2006]OKR-Periods of Words
若 \(s\) 存在 border,令其最短 border 长度为 \(L\),根据 border 的性质 1 和性质 2,\(s[1,n-L]\) 就是一个合法的周期。因此只需求出每个点在失配树上的最浅非 \(0\) 祖先。
*III. P3426 [POI2005]SZA-Template
POI 的题目质量总是这么高,很有启发性,好评!
转化题意,相当于求长度最小的 border \(s[1,p]\) 使得其在 \(s\) 中的出现位置间隔不超过 \(p\)。如果一个长为 \(p\) 的 border 在位置 \(i\) 出现了,说明 \(nxt_i\geq p\)(除了特例 \(i=p\))。这启发我们从小到大枚举所有可能的 border 长度 \(L\ (L\in \{|t|\mid t\in B(s)\})\),每次不断删去 \(nxt\) 值小于 \(L\) 的位置 \(i\)(特判 \(i=L\)),实时维护任意两个相邻的未被删去的位置之间的距离最大值 \(mx\),可以用双向链表实现。长为 \(L\) 的 border 可行当且仅当 \(mx\leq L\)。时间复杂度线性。
翻看了一遍题解区,发现一个惊为天人的 DP 做法。它用到了这样一个性质:设 \(f_i\) 表示 \(s[1,i]\) 的答案,那么 \(f_i\) 要么等于 \(i\),要么等于 \(f_{nxt_i}\)。
定义 \(i\) 覆盖 \(j\) 表示 \(s[1,j]\) 能由 \(s[1,i]\) 覆盖得到,证明如下:若 \(i<k\) 且 \(i\) 覆盖 \(k\),则 \(i\) 能覆盖所有 \(j\),其中 \(i<j<k\) 且 \(j\) 是 \(k\) 的 border,这一点显然。因此,若 \(f_{nxt_i}<f_i\leq nxt_i\),说明 \(f_i\) 覆盖 \(nxt_i\)。因为 \(f_{nxt_i}\) 也能覆盖 \(nxt_i\),所以 \(f_{nxt_i}\) 覆盖 \(f_i\)。再结合 \(f_i\) 能覆盖 \(i\),说明 \(f_{nxt_i}\) 能覆盖 \(i\),这与 \(f_i\) 的定义矛盾。又因为 \(f_i\) 显然不小于 \(f_{nxt_i}\) 且 \(f_i\) 若不等于 \(i\) 则必须是 \(s[1,i]\) 的 border 长,结合 \(nxt_i\) 的定义可知 \(f_i\) 只能等于 \(i\)。
\(f_i=f_{nxt_i}\) 的充要条件是存在 \(j\in [i-nxt_i,i-1]\) 使得 \(f_j=f_{nxt_i}\),开桶记录即可,时间复杂度是常数更小的线性,实在是太巧妙了。
IV. P3538 [POI2012]OKR-A Horrible Poem
\(s\) 有长为 \(p\) 的周期 \(\Leftrightarrow\) \(s\) 有 \(|s|-p\) 的 border。因此,枚举区间长 \(r-l+1\) 的所有因数 \(d\) 判断是否有 \(|s|-d\) 的 border 即可。时间复杂度 \(\mathcal{O}(nd(n))\)。
由于若 \(p\) 是周期,那么 \(kp\ (kp\mid |s|)\) 也是周期,因此可以不断除以 \(|s|\) 的质因数判断,即从小到大枚举所有 \(|s|\) 的质因数 \(d\),不断将 \(p\) 除以 \(d\) 直到不是周期或不能整除为止。时间复杂度 \(\mathcal{O}(n\omega(n))\),拿到了最优解(2021.12.19)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号