树状数组进阶
推荐在 cnblogs 阅读。
作为一个常数小且好写的数据结构,树状数组(Binary Indexed Tree,BIT)是求解数据结构问题的第一选择。
除了众所周知的区间加区间求和,树状数组还能代替常数巨大的线段树做很多事情,例如树状数组二分和维护高维差分。
1. 树状数组的结构
很多选手对树状数组的了解仅停留在背诵层面,却不知道这短短的两行代码背后的实际含义。深入研究树状数组的结构有助于我们更好地理解和运用树状数组。
- 树状数组可以看做线段树的简化版本,这样的简化使得它只支持前缀(或后缀)查询。因此,用树状数组维护的信息一般需要具有可减性。若信息没有可减性,则要求查询前后缀,或转化为查询前后缀。
考虑最基本的问题:单点加,单点求前缀和。设序列为 \(a\)。
树状数组的核心思想在于,将一次前缀查询 \([1, p]\) 拆成对 \(\mathcal{O}(\log n)\) 个子区间求和,使得对于所有 \(p\),不同的子区间的总数为 \(\mathcal{O}(n)\)。有的读者会指出:这不是和线段树一个道理吗?没错,但是树状数组做到了不同的子区间的总数恰好为 \(n\)。
1.1 区间拆分
对于任意正整数 \(p\),我们都可以将其拆分为 \(\mathcal{O}(\log p)\) 个 \(2\) 的幂,例如 \((1101)_2 = (1000)_2 + (0100)_2 + (0001)_2\)。
同样的,对于区间 \([1, p]\),我们可以拆成 \(\mathcal{O}(\log p)\) 个子区间,满足每个子区间的长度为 \(2\) 的幂。
考虑 \(p\) 在二进制表示下每一个为 \(1\) 的位 \(d_1 > d_2 > \cdots > d_k\),设 \(s_i = s_{i - 1} + 2 ^ {d_i}\) 且 \(s_0 = 0\),我们将 \([1, p]\) 拆分为 \(\bigcup_{i = 1} ^ k (s_{i - 1}, s_i]\)。例如,对于 \(p = 13 = (1101)_2\),将 \([1, 13]\) 拆为 \((0, 8] \cup (8, 12] \cup (12, 13]\)。
这样拆分有一个非常好的性质:对于每个右端点 \(r\)(\(1\leq r\leq n\)),在所有不同的子区间中,与之对应的左端点 \(l\) 是唯一的。这是因为,假设存在子区间 \((l, r]\),根据我们的拆分规则,\(r\) 一定由 \(l\) 加上某个 \(2\) 的幂得到,且一定是 \(r\) 在二进制表示下最低位的 \(1\) 对应的 \(2\) 的幂 \(2 ^ {d_k}\)(这就是 \(\mathrm{lowbit}\) 的定义),记作 \(\mathrm{lowbit}(r)\),以下简记为 \(\mathrm{lb}(r)\)。因此,\(l = r - \mathrm{lb}(r)\)。
这说明不同的子区间总数 恰好为 \(n\),同时给予我们方便地维护子区间信息的方式:记录在右端点上。也就是说,用一个长度为 \(n\) 的数组 \(c\) 维护每个子区间的和,其中 \(c_r\) 表示子区间 \((r - \mathrm{lb}(r), r]\) 的和,即 \(\sum_{p = r - \mathrm{lb}(r) + 1} ^ r a_p\)。
1.2 查询与修改
对于查询 \(p\),从 \(p\) 出发不断令 \(p\) 减去 \(\mathrm{lb}(p)\) 直到 \(0\),经过的所有状态的 \(c\) 值之和即为所求。
接下来一大篇全部是关于修改的。
分析所有包含 \(p\) 的区间的形态。设区间 \((l, r]\) 包含 \(p\)(\(l < p\leq r\)),称为 \({r}\) 是 \({p}\) 的祖先。
考虑 \(p\) 和 \(r\) 在二进制下从高到低第一个不同的位置 \(d\)。除去 \(p = r\) 的情况,\(d\) 一定存在。又因为 \(p \leq r\),所以 \(p\) 的第 \(d\) 位为 \(0\),\(r\) 的第 \(d\) 位 \(1\)。如果 \(r\) 在低 \(d - 1\) 位(第 \(0\sim d - 1\) 位)还有 \(1\),那么 \(l = r - \mathrm{lb}(r)\) 的第 \(d\) 位仍为 \(1\),和 \(l < p\) 矛盾。因此,\(r\) 的低 \(d - 1\) 位全部为 \(0\),则 \(r - \mathrm{lb}(r)\) 的低 \(d\) 位为 \(0\)。此时若 \(p\) 在低 \(d - 1\) 位还有 \(1\),则符合 \(l < p\) 的条件,否则 \(l = p\),不符合条件。
这是合法的例子(\(d = 3\)):
这是不合法的例子:
第一个例子因为 \(r\) 在低 \(d - 1\) 位还有 \(1\),所以 \(l\) 的第 \(d\) 位为 \(1\),\(l > p\);第二个例子因为 \(p\) 在低 \(d - 1\) 位没有 \(1\),所以 \(l = p\)。
根据条件,我们可以直接构造所有 \(p\) 的祖先 \(r\):考虑 \(p\) 的某个 \(0\) 位,且存在 \(1\) 位低于该位,将该位变成 \(1\),其低位全部变成 \(0\),就是一个合法的 \(r\)。相当于直接枚举 \(d\)。
例如,对于 \(p = (10110001)_2\),所有合法的 \(r\) 形如(\(r_0 = p\)):
可以很明显地看出,对于 \(i < j\),\(r_j\) 是 \(r_i\) 的祖先,且相邻的 \(r\) 之间存在递推关系:\(r_{i + 1} = r_i + \mathrm{lb}(r_i)\)。两个结论的证明留给读者自行思考。
我们令 \(fa_i = i + \mathrm{lb}(i)\) 表示 \(i\) 的 父节点编号,得到一个树状结构,则 \(i\) 的所有祖先就是 \(i, fa_i, fa_{fa_i}, \cdots\)。也就是说,该结构完整地描述了每个位置的所有祖先,如下图(图源):
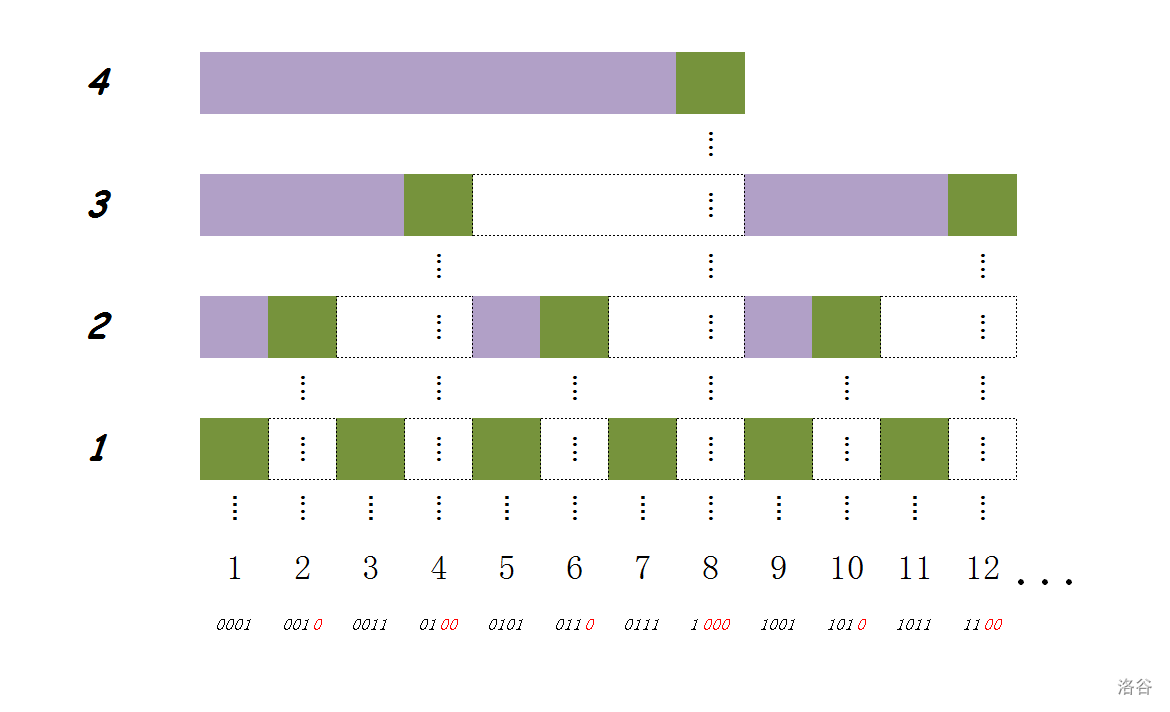
综上,对于修改 \(p\),从 \(p\) 出发不断令 \(p\) 加上 \(\mathrm{lb}(p)\),更新经过的所有状态即可。
将修改和查询放在一起看,再来一张图加深印象(图源):
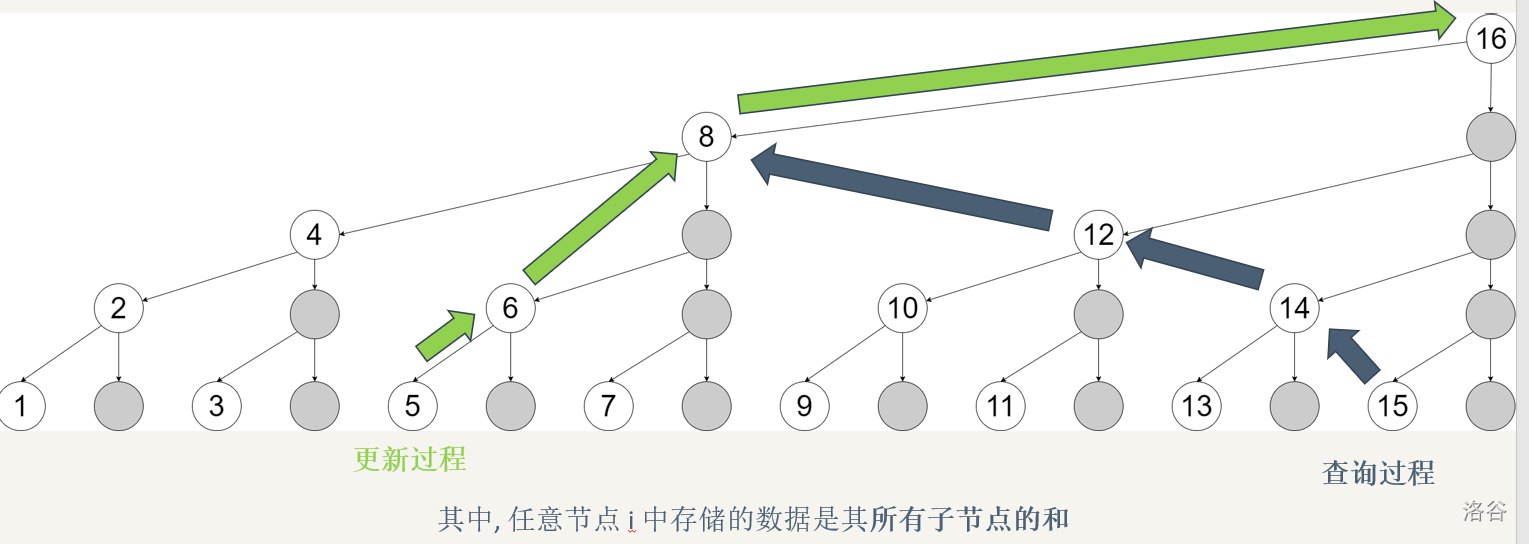
实际上,我们可以将树状数组看成 省略了所有右儿子的线段树。
从另一种角度也可以推导出上述结果:尝试证明所有区间包含或相离。满足条件的区间集合可以建树,求出每个区间的父亲,即包含该区间的长度最小的区间对应右端点编号。具体细节留给感兴趣的读者自行补充。
1.3 求 \(\mathrm{lowbit}(x)\)
\(\mathrm{lb}(x)\) 怎么算呢,总不能再 \(\mathcal{O}(\log n)\) 枚举吧!
用预处理 \(\mathrm{lb}(1\sim n)\) 确实可行,但这样不仅没有技术含量,而且会增大内存访问次数,有愧于树状数组小常数的名号。
计算机用补码存储和表示数值。考虑 \(-x\)(\(x > 0\))的补码,它等于 \(x\) 的反码 \(+1\)。设 \(\mathrm{lb}(x) = 2 ^ k\),我们发现 \(-x\) 的补码在低 \(k - 1\) 位(第 \(0\sim k - 1\) 位)都是 \(0\);在第 \(k\) 位和 \(x\) 相同,均为 \(1\);在高于 \(k\) 的位和 \(x\) 相反。
例如,对于二进制数 \((0\cdots 010100)_2\),其 \(\mathrm{lowbit}\) 值为 \(4\),其反码为 \((1\cdots 101011)_2\),相反数的补码为 \((1\cdots 101100)_2\)。又因为正数的补码就是它本身,所以一个数的 \(\mathrm{lowbit}\) 值就等于它和它的相反数的按位与,即 x & -x。
这样,我们可以顺利成章地写出支持 模板题 操作的树状数组了。
int n, c[N];
void add(int x, int v) {while(x <= n) c[x] += v, x += x & -x;}
int query(int x) {int s = 0; while(x) s += c[x], x -= x & -x; return s;}
int query(int l, int r) {return query(r) - query(l - 1);} // 区间查询转化为两次前缀查询.
1.4 树状数组二分
类似线段树二分,树状数组也可以二分。只要理解了树状数组的结构,就很容易理解树状数组二分。
它可以抽象成这样一类问题:存在分割点 \(q\),使得 \(\leq q\) 的位置满足某个限制,而 \(> q\) 的位置不满足该限制,求 \(q\)。注意,树状数组二分是 在整个序列上二分,它不支持从某个位置开始二分,必须将后者转化为前者。
考虑查询最后一个前缀和 \(\leq v\) 的位置,满足序列每个元素非负,则存在分割点 \(q\),使得 \(\leq q\) 的位置的前缀和 \(\leq v\),\(> q\) 的位置的前缀和 \(> v\),\(q\) 即为所求。
树状数组二分的本质是 倍增。设当前位置为 \(p\),对应前缀和为 \(s\)。从大到小枚举 \(1\leq 2 ^ k\leq n\),尝试将 \(p\) 加上 \(2 ^ k\),即检查 \(s + \sum_{i = p + 1} ^ {p + 2 ^ k} a_i\) 是否不大于 \(v\)。因为 \(k\) 是从大到小枚举的,所以此时 \(\mathrm{lb}(p) > 2 ^ k\),因此 \(\mathrm{lb}(p + 2 ^ k) = 2 ^ k\),这说明 \(c_{p + 2 ^ k} = \sum_{i = p + 1} ^ {p + 2 ^ k} a_i\)。因此,若 \(p + 2 ^ k\leq n\) 且 \(s + c_{p + 2 ^ k} \leq v\),则令 \(p\gets p + 2 ^ k\),再令 \(s\gets s + c_p\),否则 \(p + 2 ^ k\) 超出下标范围或 \(q < p + 2 ^ k\),不进行任何操作。
最终 \(p\) 一定等于 \(q\),否则过程中 \(p\) 一定会变得更大。
1.5 例题
P6619 [省选联考 2020 A/B 卷] 冰火战士
太经典了。
首先将温度离散化,就是求冰系战士能力关于温度的前缀和,与火系战士能力的后缀和在某个温度处较小值的最大值。由于能力都是正整数,所以前缀和单调递增,后缀和单调递减,考虑用树状数组维护冰火战士能力关于温度的前缀和(后缀和等于总和减去前缀和)。
每次查询二分找到最大的 \(p\) 使得 \(\mathrm{Ice}_p \leq\mathrm{Firesum} - \mathrm{Fire}_{p - 1}\),以及最大的 \(q\) 使得 \(\mathrm{Ice}_q \geq \mathrm{Firesum} - \mathrm{Fire}_{q - 1}\) 且 \(\mathrm{Fire}_q\) 最小,两者对比取更优解即可。但是满足条件的 \(q\) 是一段后缀(树状数组二分要求满足条件的位置是一段前缀)怎么办?将 \(\mathrm{Fire}\) 平移一位变成 \(\mathrm{Ice}_p\leq\mathrm{Firesum} - \mathrm{Fire}_{p}\),求出 \(p\) 之后相当于找最大的 \(q\) 使得 \(\mathrm{Fire}_q \leq \mathrm{Fire}_{p + 1}\),这样满足条件的 \(q\) 就是一段前缀了。
时间复杂度 \(\mathcal{O}(Q\log Q)\)。代码(UOJ 最优解)和 卡常后的代码(UOJ 更优解 & 洛谷最优解 2023.4.7,看看你能不能读懂)。
P4602 [CTSC2018] 混合果汁
整体二分,则问题相当于将所有美味度不小于当前二分值的果汁拎出来,按单价从小到大排序,求买 \(L_i\) 升的价格。用 BIT 维护每个单价的果汁体积,可以二分出最大单价 \(p\) 使得单价不大于 \(p\) 的果汁体积 \(L\) 小于 \(L_i\),则买单价不大于 \(p\) 的果汁和 \(L_i - L\) 升单价为 \(p\) 的果汁即可(单价为 \(p\) 的果汁一定至少有 \(L_i - L\) 升,否则 \(p\) 还可以更大),注意需要先比较一下 \(L_i\) 和果汁总体积。
注意在每次 \(\mathrm{solve}(l, r, Q)\) 之前,需要保证所有美味度小于 \(l\) 的果汁已经加入 BIT,才能保证整体二分的时间复杂度仅与当前二分区间长度相关。
使用 BIT 倍增,时间复杂度 \(\mathcal{O}((n + m) \log ^ 2 n)\)。代码。
P3586 [POI2015] LOG
每次贪心选最大的 \(c\) 个肯定没问题,但没办法直接模拟。
每个数之间顺序无关,一般通过排序寻找性质:对于最大的元素 \(a_1\),若 \(a_1\geq s\) 说明 \(a_1\) 必定能贡献 \(s\) 次取数,令 \(c\gets c - 1\),考虑剩下来 \(n - 1\) 个数,这是子问题。递归边界是出现 \(a_i < s\),这说明 \(a_i\sim a_n\) 都小于 \(s\)。问题转化为要求选 \(s\) 次,每次选 \(c\)(这里的 \(c\) 实际上是询问的 \(c\) 减去 \(\geq s\) 的数的个数)个不同的数,每个数被选择的次数不超过 \(a_i\),其中 \(a_i<s\)。
证明:看成一个 \(s\times c\) 的表格(左上角标号 \((1, 1)\),右下角标号 \((s, c)\)),每一行的数互不相同且 \(i\) 的出现次数不超过 \(a_i\),有如下构造:对于每个 \(i\),有 \(a_i\) 次填数,每次选择最左边有空位的列的最上面那个位置填入 \(i\) 即可,即填数的轨迹是这样的:\((1, 1) \to (2, 1) \to \cdots \to (s, 1) \to (1, 2) \to (2, 2) \to \cdots \to (s, 2) \to \cdots\)。因为轨迹上任意连续 \(a_i\) 个格子横坐标互不相同,所以满足限制。
判断是否有 \(\sum_{j=i}^n a_j\geq c\times s\) 即可。具体地,求出 \(a_i\geq s\) 的 \(i\) 的个数 \(m\),以及所有小于 \(s\) 的数的和 \(v\),若 \(s\times (c-m)\leq v\) 则可行,否则不可行。离散化 + 树状数组二分即可。
时间复杂度 \(\mathcal{O}(m\log m)\)。代码(洛谷最优解 2023.4.8)。
[模拟赛] 集合
维护初始为空的序列 \(a_i\),支持插入一个数或询问 \(c\),求出最多进行多少次选出 \(c\) 个数并减去 \(1\)。
\(1\leq a_i\leq 10 ^ 9\),\(1\leq q\leq 10^6\)。2s,512MB。
和上一题(P3586)思想差不多,但是稍微难一点。
考虑哪些元素每次必然被选,自然从最大值开始考虑。设最大值为 \(v\),总和为 \(s\),则最多选择 \(\frac s c\)(所有分数下取整)次。若 \(v \geq \frac s c\),说明 \(v\) 每次必然被选,令 \(c\gets c - 1\) 并丢掉 \(v\);若 \(v < \frac s c\),就是上一题的结论,可以选满 \(\frac s c\) 次。
将所有数从大到小排序,相当于找到最后一个位置使得 \(a_i > \frac {suf_i} {c - i + 1}\),\(suf\) 表示后缀和。感性理解,满足条件的位置一定是一段前缀(不存在 \(a_i > a_j\) 使得 \(a_j\) 每次都被选择了且存在一次没选择 \(a_i\),否则可以调整)。
证明:变形得 \(a_ic - a_ii + a_i > suf_i\),即 \(a_i(c - i) > suf_{i + 1}\),即 \(c > \frac {suf_i} {a_i} + i\)。注意到 \(\frac {suf_i} {a_i}\) 在 \(i\) 增加 \(1\) 时,值最多减小 \(1\)(\(\frac {suf_i} {a_i} = 1 + \frac {suf_{i + 1}} {a_i} \leq 1 + \frac {suf_{i + 1}} {a_{i + 1}}\)),所以不等号右侧非严格递增。\(\square\)
离散化 + BIT 二分找到最后一个满足条件的位置,则 \(\frac {suf_{p + 1}} {c - p} = \frac {S - pre_p} {c - p}\) 即为所求。
时间复杂度 \(\mathcal{O}(q\log q)\)。
2. 对树状数组的理解
上面讨论的都是前缀 BIT,前缀表示查询一段前缀。它本质上是 一阶前缀和:在 \(x\) 处的修改对所有 \(y\geq x\) 处的查询产生贡献。
对于单点加区间求和,转化为 “单点修改原序列” 对 “某个位置的前缀和” 的贡献:给 \(a_x\) 加上 \(v\) 相当于给 \(s_y\)(\(y\geq x\))加上 \(v\),即位置 \(x\) 的加 \(v\) 的修改会让所有位置 \(y\geq x\) 处的查询加上 \(v\)。
对于区间加单点查询,转化为 “单点修改差分序列” 对 “原序列的某个位置” 的贡献:给 \(d_x\) 加上 \(v\) 相当于给 \(s_y\)(\(y\geq x\))加上 \(v\),原理是类似的。
2.1 高阶前缀和
当问题来到高阶前缀和,应当如何去思考?简单,只需要梳理清楚某处修改对某处查询的贡献即可。
对于区间加区间求和,转化为 “单点修改差分序列” 对 “某个位置的前缀和” 的贡献。这是二阶前缀和。
考虑给 \(d_x\) 加上 \(v\),在 \(y\) 处查询前缀和 \(s_y\)。\(d_x\) 加了 \(v\) 使得 \(a_{x\sim y}\) 全部加了 \(v\),所以 \(s_y\) 加了 \((y - x + 1) v\)。将贡献拆成 \((y + 1)v\) 和 \(-xv\)。我们用两个树状数组 \(c_1, c_2\),分别维护修改值 \(v\) 的一阶前缀和,和修改值 \(v\) 乘以修改位置 \(x\) 的一阶前缀和,那么 \(y\) 处的二阶前缀和就等于修改值在 \(y\) 处的一阶前缀和乘以 \(y + 1\),减去修改值乘以修改位置在 \(y\) 处的一阶前缀和。
换言之,我们考虑 单次修改对单次查询的贡献。对于某种维护方式,只要单次修改对单次查询的答案是对的,那么无论多少次修改,多少次查询,它依然正确。
支持线段树 模板题 操作(区间加,区间求和)的树状数组如下:
using ll = long long;
ll n, c[N], c2[N];
void add(int x, ll v) {
ll v2 = 1ll * x * v;
while(x <= n) c[x] += v, c2[x] += v2, x += x & -x;
}
void add(int l, int r, ll v) {add(l, v), add(r + 1, -v);}
ll query(int x) {
ll y = x + 1, s = 0, s2 = 0;
while(x) s += c[x], s2 += c2[x], x -= x & -x;
return s * y - s2;
}
ll query(int l, int r) {return query(r) - query(l - 1);}
对于更高阶前缀和,思路是一致的。
假设 \(y - x = 6\),用矩阵(行列均从 \(0\) 开始标号)的第 \(i\) 行表示 \(i + 1\) 阶前缀和从 \(x\) 到 \(y\) 的贡献系数序列,则
对组合数较熟悉的同学已经发现,矩阵第 \(i\) 行第 \(j\) 列就是 \(\binom {i + j} {i}\)。推导过程不难,归纳即可。
综上,对于 \(k\) 阶前缀和,\(x\) 处加 \(1\) 对 \(y\) 处的查询产生的贡献为 \(\binom {y - x + k - 1} {k - 1}\)。理解方式:考虑贡献路径 \(p_0 = x\leq p_1 \leq \cdots \leq p_k = y\),每一个这样的 \(\{p\}\) 都对应 \(1\) 的贡献。换言之,建出这样一张图:对于任意 \(x\leq i\leq y\),\(i\) 向 \([i, y]\) 连边,从 \(x\) 恰好走 \(k\) 步到 \(y\) 的方案数就是贡献系数。这是经典问题,相当于在 \(y - x\) 个空隙放入 \(k - 1\) 个插板,两个插板可以放在不同的空隙;也相当于将 \(y - x +1\) 个球装入 \(k - 1\) 个不同的盒子,可以有盒子为空。有方案数 \(\binom {y - x + k - 1} {k - 1}\)。
\(k\) 为定值,\(\binom {y - x + k - 1} {k - 1}\) 是关于 \(x\) 和 \(y\) 的多项式。对于所有含 \(x ^ u\) 的项,将 \(x ^ u\) 提出得到关于 \(y\) 的多项式,设为 \(f_u\)。维护所有 \(vx ^ u\)(\(0\leq u < k\))的 一阶 前缀和,查询时算出 \(vx ^ u\) 在 \(y\) 处的前缀和 \(s_u(y)\),则 \(\sum_{u = 0} ^ {k - 1} f_u(y) s_u(y)\) 即为所求。
例如,当 \(k = 3\) 时,\(\binom {y - x + 2} {2} = \frac 1 2 (y - x + 2) (y - x + 1)\)。提出 \(\frac 1 2\),展开得到 \(y ^ 2 + x ^ 2 - 2xy + 3y - 3x + 2\),即 \(x ^ 2 + (-2y - 3)x ^ 1 + (y ^ 2 + 3y + 2)x ^ 0\)。因此:
- 求出 \(vx ^ 0\) 即 \(v\) 在 \(y\) 处的前缀和,乘以 \(y ^ 2 + 3y + 2\)。
- 求出 \(vx ^ 1\) 在 \(y\) 处的前缀和,乘以 \(-2y - 3\)。
- 求出 \(vx ^ 2\) 在 \(y\) 处的前缀和,乘以 \(1\)。
将上述三个结果相加即为所求。
时间复杂度 \(\mathcal{O}(kq\log n)\),其中 \(k\) 表示前缀和阶数,\(q\) 表示操作次数, \(n\) 表示序列长度。
2.2 二维 BIT
本质上是树状数组套树状数组,用二维数组维护。它可以直接做单点加矩形查询,且矩形两维的左边界都是 \(1\)。差分一下就可以对任意矩形求和。
对于矩形加矩形求和,即维护二维差分数组的二阶二维前缀和。类似地,考虑 \((i, j)\) 处对二维差分数组的修改对 \((x, y)\) 处查询二维前缀和的贡献。给 \(d_{i, j}\) 加 \(v\) 使得 \(a_{i\sim x, j\sim y}\) 全部加了 \(v\),所以 \(s_{x, y}\) 加了 \((x -i + 1) (y - j + 1) v\)。拆开变成 \((x + 1)(y + 1)v - (y + 1)iv - (x + 1)jv + ijv\)。用四个树状数组分别维护 \(v\),\(iv\),\(jv\) 和 \(ijv\) 的一阶二维前缀和即可。
时间复杂度 \(\mathcal{O}(q\log n\log m)\)。
模板题 代码:
#include <bits/stdc++.h>
using namespace std;
constexpr int N = 2050;
char s;
int n, m, c1[N][N], c2[N][N], c3[N][N], c4[N][N];
void add(int x, int y, int v) {
int v2 = x * v, v3 = y * v, v4 = x * y * v;
for(int i = x; i <= n; i += i & -i)
for(int j = y; j <= m; j += j & -j)
c1[i][j] += v, c2[i][j] += v2, c3[i][j] += v3, c4[i][j] += v4;
}
int query(int x, int y) {
int s1 = 0, s2 = 0, s3 = 0, s4 = 0;
for(int i = x; i; i -= i & -i)
for(int j = y; j; j -= j & -j)
s1 += c1[i][j], s2 += c2[i][j], s3 += c3[i][j], s4 += c4[i][j];
return (x + 1) * (y + 1) * s1 - (y + 1) * s2 - (x + 1) * s3 + s4;
}
int main() {
cin >> s >> n >> m;
while(cin >> s) {
if(s == 'L') {
int a, b, c, d, v;
cin >> a >> b >> c >> d >> v;
add(a, b, v), add(c + 1, b, -v), add(a, d + 1, -v), add(c + 1, d + 1, v);
}
else {
int a, b, c, d;
cin >> a >> b >> c >> d;
cout << query(c, d) + query(a - 1, b - 1) - query(a - 1, d) - query(c, b - 1) << "\n";
}
}
return 0;
}
2.3 后缀 BIT
交换查询和修改的跳转方式就是后缀 BIT 了。
int n, c[N];
void add(int x, int v) {while(x) c[x] += v, x -= x & -x;}
int query(int x) {int s = 0; while(x <= n) s += c[x], x += x & -x; return s;}
int query(int l, int r) {return query(l) - query(r + 1);}
可以这样思考:在前缀 BIT 中,对于 \(x \leq y\),一个 \(x\) 处的更新对 \(y\) 处的查询产生了贡献。类似地,在后缀 BIT 中,一个 \(y\) 处的更新对 \(x\) 处的查询产生了贡献。
\(x\) 不断增大的操作只会影响所有位置不小于 \(x\) 的信息(或和这样的信息有关),\(x\) 不断减小的操作只会影响所有位置不大于 \(x\) 的信息(或和这样的信息有关)。
对于可减信息,用前缀后缀 BIT 维护是一样的。后缀 BIT 的用途在于,当信息不可减且询问具有良好性质(询问后缀,或可以转化为询问后缀)时,能够不翻转序列地维护修改和查询,避免因翻转序列产生的大量下标变换使得代码写挂。
参考资料
第一章

 浙公网安备 33010602011771号
浙公网安备 33010602011771号