Hadoop MR 执行过程和Shuffle
一、数据的本地化
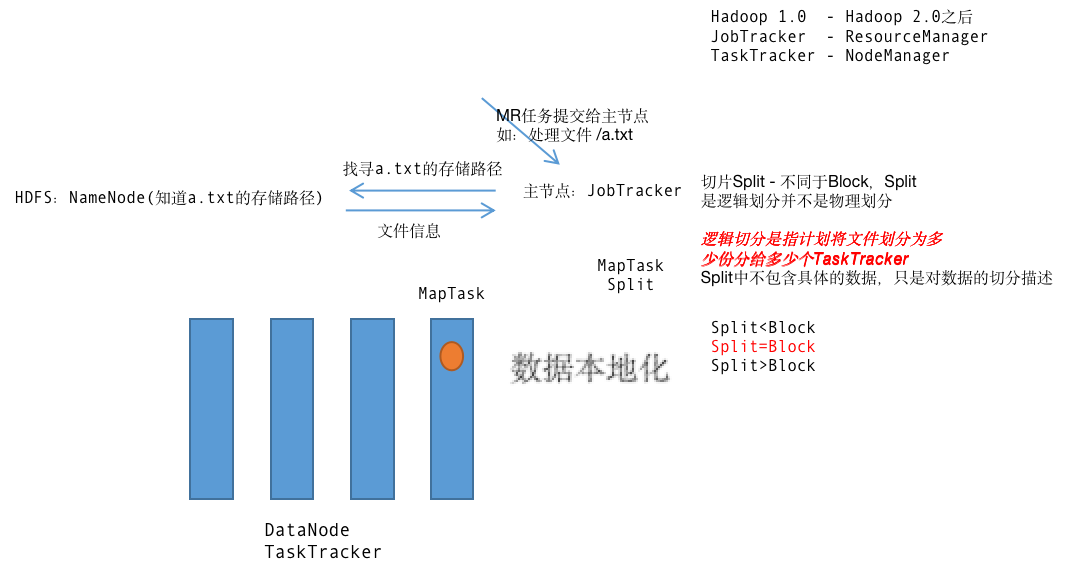
1.当JobTracker接收到应用之后,会去访问NameNode获取要处理的文件信息
2.NameNode将文件信息返回给JobTracker,这里的文件信息只是文件在DataNode上的存储路径和大小等基本属性,没有具体的文件数据内容
3.JobTracker收到文件信息之后会将文件进行逻辑划分(只包含切块信息不包含实际数据),一般将切片和HDFS中DataNode上的Block设置为一样大,每一切片会分配一个MapTask
4.JobTracker会将MapTask分发到TaskTracker来执行。在分发的时候,哪一个DataNode上有对应的Block,那么MapTask就会分发到这个节点上 - 数据本地化
5.数据本地化的目的:减少对网络资源的消耗
260M大小 ---3个Block(DataNode上) --2个Split(128M,132M:逻辑划分)
Split切分的规则,例:260/128>1.1 --128 131/128<1.1 --131
二、job的执行过程:
1.客户端提交一个job任务到JobTracker:hadoop jar xxx.jar
2.JobTracker收集环境信息:
a.检测是否匹配
b.检测输入\输出路径是否合法(输入路径的存在,输出路径的不存在)
3.JobTasker给job分配一个全局递增的jobid(实际过程中,多个客户端提交不同的job,每个job不同的id),然后将jobid返回给客户端
4.客户端收到jobid之后,将jar提交到HDFS上,存储在HDFS的tmp目录下,只是执行完成后,就会自动删除
5.准备执行job任务
6.JobTracker会将job进行划分,划分为MapTask和ReduceTask,其中MapTask的数量是由切片数据决定的,ReduceTask的数量由Partition/numRedeceTask方法决定
7.JobTracker等待TaskTracker的心跳。一般而言,TaskTracker和DataNode会设置为同一个节点。当TaskTracker发送心跳信息的时候,这个时候JobTracker就会给TaskTracker分配任务,注意:在分配任务的时候,MapTask符合数据本地化策略(即TaskTracker上有这个数据的时候才会将MapTask分配它),ReduceTask分配到相对空闲的节点上
8.TaskTracker领取到任务后,到对应的节点下载jar包 - 设计思想:逻辑移动而数据不动
9.TaskTracker会在本节点内启动JVM子进程执行MapTask或者是ReduceTask
注意:每个MapTask或者是ReduceTask 都会启动一次JVM子进程
三、shuffle过程
Map端的Shuffle
1.每一个Split分配一个MapTask(MapTask的线程)来处理
2.MapTask默认是对数据进行按行读取,每读取一行调用一次map(Hadoop中 Mapper接口)方法
3.map方法在处理完一行数据的时候会写出,将数据写到缓冲区中
4.每一个MapTask都自带了一个缓冲区,缓冲区维系在内存中
5.缓冲区默认大小是100M
6.当缓冲区达到条件的时候,将缓冲区中的数据写到本地磁盘上,这个过程为溢写(Spill),产生的文件为溢写文件
7.溢写之后,后续产生的数据会继续写到缓冲区中
8.溢写过程可能发生不止一次
9.当map将结果放到缓冲区之后,结果在缓冲区中会进行分区和排序的过程;如果指定了Combiner(合并),那么数据在缓冲区中还会进行合并
10.如果所有的数据处理完成,但是有一部分数据在缓冲区中,一部分在溢写文件中,那么缓冲区中的数据将冲刷到最后的的溢写文件中
11.产生多次溢写,会产生多个溢写文件。在结果发送到Reduce之前,会将多个溢写文件进行合并(merge),将多个溢写文件合并成为一个结果文件
12.注意:
a.溢写过程不一定发生,如果没有发送溢写过程,则将缓冲区中的数据直接冲刷到最后的结果文件中;
如果只有一次溢写,那么这个溢写文件就是最后的结果文件
b.merge过程不一定发生
c.如果溢写文件的数量 >=3,那么merge过程中,自动进行一次combine(必须在代码中指定Combine)
d.在merge过程中,结果会进行整体的分区排序
e.初始的数据量并不能决定溢写次数
f.阈值默认0.8,即缓冲区的使用达到这个大小的80%的时候,就开始溢写
g.这个缓冲区默认是byte[]数组,而且是一个环形的
Reduce端的Shuffle
1.ReduceTask启动fetch线程去MapTask上抓取数据,只抓取当前要处理的分区的数据,将抓取的数据放到文件中,每从一个MapTask中抓取到数据就会产生一个数据文件
2.抓取数据之后,将这个数据再次进行merge
3.在merge过程中,对数据再次进行排序
4.merge完成之后,将相同键所对应的值,放入一个List集合中,然后利用List集合去产生迭代器,这个过程称之为分组
5.每一组会调用一次reduce
6.每一个ReduceTask会产生一个结果文件
7.注意:
a.默认fetch线程的数量为5,表示每一个ReduceTask会启动5个线程去抓取数据,fetch线程通过http请求去抓取数据
b.merge默认因子为10,表示每10个数据文件进行一次合并,最后合成1个数据文件
c.reduce的阈值默认为0.05,表示当有5%的MapTask结束,那么启动ReduceTask开始抓取数据
Shuffle调优:
1.调大缓冲区,实际开发中,一般将缓冲区设置250~400M左右
2.尽量添加Combine,但不是所有场景下可以添加Combiner
3.调大缓冲区的阈值 - 这种方式不推荐
4.将MapTask的结果进行压缩 - 这种方式能够有效减少网络的传输时间 - 这种方式不算优化,只是在节点资源和网络资源之间进行取舍
5.增加fetch线程的数量 - 一般可以设置为服务器承载的线程数的1/3~线程总数
6.增大merge因子 - 不推荐
7.降低Reduce的阈值 - 不推荐

 浙公网安备 33010602011771号
浙公网安备 33010602011771号