captcha-trainer运行环境使用腾讯云十分钟搭建教程
GitHub项目地址:
https://github.com/kerlomz/captcha_trainer
按照readme说明,如果自行搭建环境的话,可能会踩到很多坑(教训深刻),因为这个项目相对来说已经有点老了(本文时间2022.11),很多依赖版本已经被从python仓库移除,因此直接按照readme的说明进行搭建环境几乎很难行得通。
其实仔细看主要的一些环境就是:cuda和cudnn版本搭配以及各种依赖的编译器版本匹配。
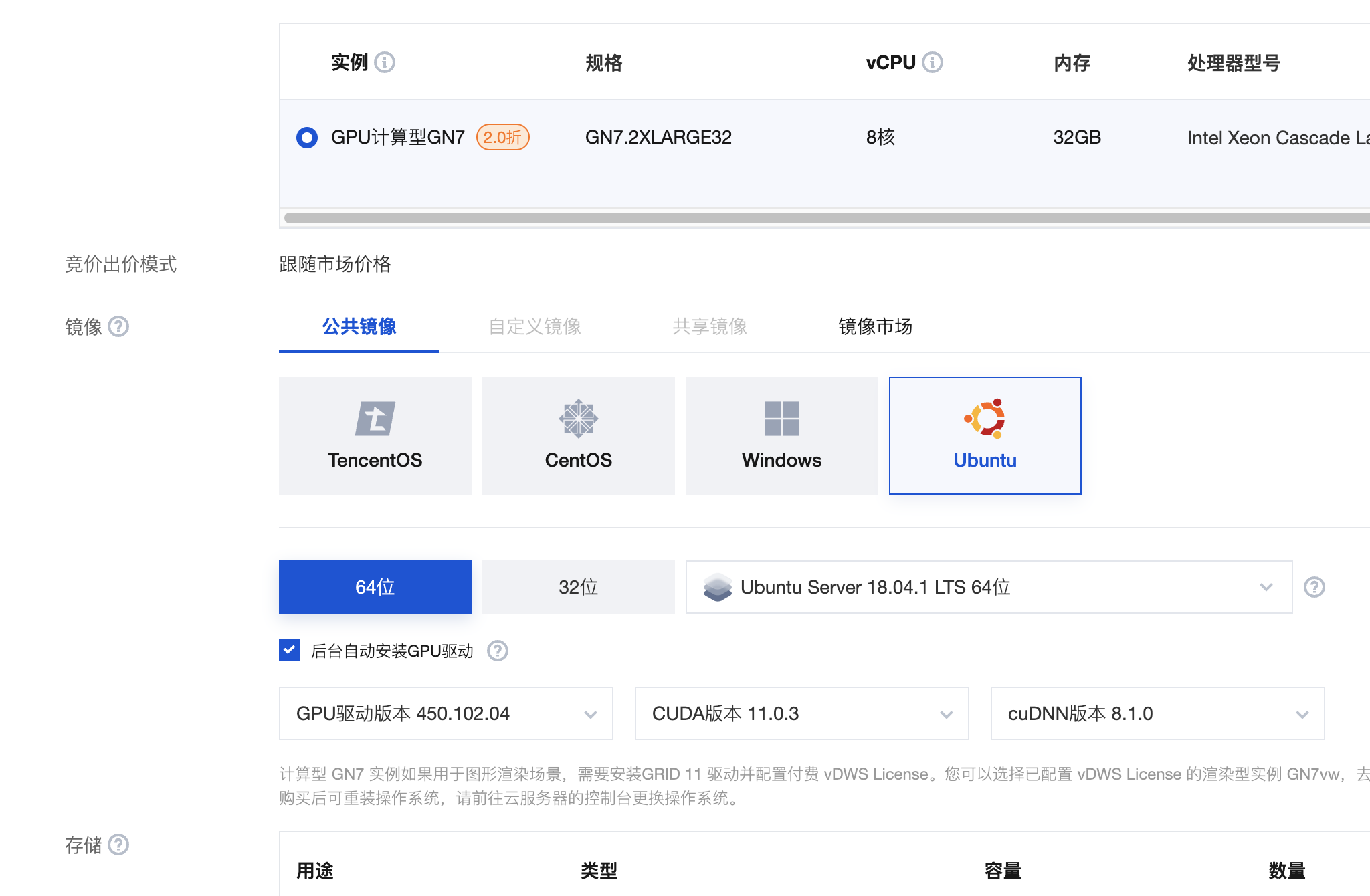
经过一番折腾,最后发现,腾讯云选择GPU服务器Ubuntu 18版本的情况下,可以出现选择 cuda 和cudnn版本的选项,而且都是搭配好的版本。 因此直接通过腾讯云的服务台创建GPU服务器,然后选择GPU机型,显卡为Nvidia T4的机器,公共镜像中的 Ubuntu,版本选择64位 18.04,下面就会出现 GPU驱动以及 cuda和cudnn的版本,选择合适的版本即可直接安装完成。根据提示,启动后预计15~25分钟即可安装完毕。
注意,这里选择的 cuda cudnn 版本不比和作者的完全一致。 版本匹配即可。
我这里选择的版本为 ubuntu x64 18.04 GPU驱动版本为 450.102.04 CUDA版本 11.0.3 cuDNN版本 8.1.0
对应的 pip依赖 requirements.txt 如下:
pillow
opencv-python-headless
numpy
pyyaml>=3.13
tqdm
colorama
pyinstaller
astor
fonttools
tensorflow==2.6.4
更多都版本匹配可以参考这篇文章:
https://www.tensorflow.org/install/source#ubuntu
这里,对于临时用来训练的小伙伴来说,可以选择竞价实例,价格便宜很多。
等服务器安装启动后,即可进行环境的搭建了。 此时可能python 版本不对,可以直接百度搜索安装python3, 然后进入虚拟环境进行依赖安装。
强烈建议使用虚拟环境,可以隔离python版本,防止不同版本因为环境变量问题被混合调用导致无法使用。以及python依赖安装pip的版本出现不同的问题等。
-
安装Python 3.8 环境(包含pip),可用conda替换。
-
安装虚拟环境 virtualenv
pip3 install virtualenv -
为该项目创建独立的虚拟环境:
virtualenv -p /usr/bin/python3 venv # venv is the name of the virtual environment. cd venv/ # venv is the name of the virtual environment. source bin/activate # to activate the current virtual environment. cd captcha_trainer # captcha_trainer is the project path. -
安装本项目的依赖列表:
pip install -r requirements.txt -
建议开发者们使用 PyCharm 作为Python IDE(我用的是VSCode)
至此,环境基本都已经安装完毕了。按照readme文档的解释,我们需要新建一个项目文件夹,并放置好标记样本,以及配置文件。 标记样本的格式其实很简单就是: 正确标记答案_md5或随机字符.扩展名 的方式
例如
一张验证码为mn3的图片,标记样本为:mn3_89adf98a8df89asdf8.gif
配置文件,作者并没有给出默认的配置值,虽然在windows下可以默认生成,但是此处使用linux,还是需要手动配置一下默认值,下面的配置文件,仅供参考,可以根据作者文档中的标注进行修改和测试。
# - requirement.txt - GPU: tensorflow-gpu, CPU: tensorflow
# - If you use the GPU version, you need to install some additional applications.
System:
MemoryUsage: 0.8
Version: 2
# CNNNetwork: [CNN5, ResNet, DenseNet]
# RecurrentNetwork: [CuDNNBiLSTM, CuDNNLSTM, CuDNNGRU, BiLSTM, LSTM, GRU, BiGRU, NoRecurrent]
# - The recommended configuration is CNN5+GRU
# UnitsNum: [16, 64, 128, 256, 512]
# - This parameter indicates the number of nodes used to remember and store past states.
# Optimizer: Loss function algorithm for calculating gradient.
# - [AdaBound, Adam, Momentum]
# OutputLayer: [LossFunction, Decoder]
# - LossFunction: [CTC, CrossEntropy]
# - Decoder: [CTC, CrossEntropy]
NeuralNet:
CNNNetwork: CNNX
RecurrentNetwork: GRU
UnitsNum: 64
Optimizer: Adam
OutputLayer:
LossFunction: CTC
Decoder: CTC
# ModelName: Corresponding to the model file in the model directory
# ModelField: [Image, Text]
# ModelScene: [Classification]
# - Currently only Image-Classification is supported.
Model:
ModelName: fo
ModelField: Image
ModelScene: Classification
# FieldParam contains the Image, Text.
# When you filed to Image:
# - Category: Provides a default optional built-in solution:
# -- [ALPHANUMERIC, ALPHANUMERIC_LOWER, ALPHANUMERIC_UPPER,
# -- NUMERIC, ALPHABET_LOWER, ALPHABET_UPPER, ALPHABET, ALPHANUMERIC_CHS_3500_LOWER]
# - or can be customized by:
# -- ['Cat', 'Lion', 'Tiger', 'Fish', 'BigCat']
# - Resize: [ImageWidth, ImageHeight/-1, ImageChannel]
# - ImageChannel: [1, 3]
# - In order to automatically select models using image size, when multiple models are deployed at the same time:
# -- ImageWidth: The width of the image.
# -- ImageHeight: The height of the image.
# - MaxLabelNum: You can fill in -1, or any integer, where -1 means not defining the value.
# -- Used when the number of label is fixed
# When you filed to Text:
# This type is temporarily not supported.
FieldParam:
Category: ALPHANUMERIC_UPPER
Resize: [96, 48]
ImageChannel: 1
ImageWidth: 96
ImageHeight: 48
MaxLabelNum: 4
OutputSplit: null
AutoPadding: True
# The configuration is applied to the label of the data source.
# LabelFrom: [FileName, XML, LMDB]
# ExtractRegex: Only for methods extracted from FileName:
# - Default matching apple_20181010121212.jpg file.
# - The Default is .*?(?=_.*\.)
# LabelSplit: Only for methods extracted from FileName:
# - The split symbol in the file name is like: cat&big cat&lion_20181010121212.png
# - The Default is null.
Label:
LabelFrom: FileName
ExtractRegex: .*?(?=_)
LabelSplit: null
# DatasetPath: [Training/Validation], The local absolute path of a packed training or validation set.
# SourcePath: [Training/Validation], The local absolute path to the source folder of the training or validation set.
# ValidationSetNum: This is an optional parameter that is used when you want to extract some of the validation set
# - from the training set when you are not preparing the validation set separately.
# SavedSteps: A Session.run() execution is called a Step,
# - Used to save training progress, Default value is 100.
# ValidationSteps: Used to calculate accuracy, Default value is 500.
# EndAcc: Finish the training when the accuracy reaches [EndAcc*100]% and other conditions.
# EndCost: Finish the training when the cost reaches EndCost and other conditions.
# EndEpochs: Finish the training when the epoch is greater than the defined epoch and other conditions.
# BatchSize: Number of samples selected for one training step.
# ValidationBatchSize: Number of samples selected for one validation step.
# LearningRate: [0.1, 0.01, 0.001, 0.0001]
# - Use a smaller learning rate for fine-tuning.
Trains:
DatasetPath:
Training:
- /home/captcha-trainer-master/projects/fo/trains.0.tfrecords
Validation:
- /home/captcha-trainer-master/projects/fo/valids.0.tfrecords
SourcePath:
Training:
- /home/captcha-trainer-master/projects/fo/source
Validation:
ValidationSetNum: 500
SavedSteps: 100
ValidationSteps: 500
EndAcc: 0.90
EndCost: 0.5
EndEpochs: 2
BatchSize: 64
ValidationBatchSize: 300
LearningRate: 0.001
# Binaryzation: The argument is of type list and contains the range of int values, -1 is not enabled.
# MedianBlur: The parameter is an int value, -1 is not enabled.
# GaussianBlur: The parameter is an int value, -1 is not enabled.
# EqualizeHist: The parameter is an bool value.
# Laplace: The parameter is an bool value.
# WarpPerspective: The parameter is an bool value.
# Rotate: The parameter is a positive integer int type greater than 0, -1 is not enabled.
# PepperNoise: This parameter is a float type less than 1, -1 is not enabled.
# Brightness: The parameter is an bool value.
# Saturation: The parameter is an bool value.
# Hue: The parameter is an bool value.
# Gamma: The parameter is an bool value.
# ChannelSwap: The parameter is an bool value.
# RandomBlank: The parameter is a positive integer int type greater than 0, -1 is not enabled.
# RandomTransition: The parameter is a positive integer int type greater than 0, -1 is not enabled.
DataAugmentation:
Binaryzation: -1
MedianBlur: -1
GaussianBlur: -1
EqualizeHist: False
Laplace: False
WarpPerspective: False
Rotate: -1
PepperNoise: -1.0
Brightness: False
Saturation: False
Hue: False
Gamma: False
ChannelSwap: False
RandomBlank: -1
RandomTransition: -1
# Binaryzation: The parameter is an integer number between 0 and 255, -1 is not enabled.
# ReplaceTransparent: Transparent background replacement, bool type.
# HorizontalStitching: Horizontal stitching, bool type.
# ConcatFrames: Horizontally merge two frames according to the provided frame index list, -1 is not enabled.
# BlendFrames: Fusion corresponding frames according to the provided frame index list, -1 is not enabled.
# - [-1] means all frames
Pretreatment:
Binaryzation: -1
ReplaceTransparent: True
HorizontalStitching: False
ConcatFrames: -1
BlendFrames: -1
以上配置文件,准备就绪以后,即可正式开始训练了,训练需要先打包样本 tfrecords格式,打包很简单,很快就可以完成。
经过尝试, 3800张图片,训练了一个相对复杂的三位数字大小写字母混合的验证码,结果一直无法收敛。失败告终,等后续继续收集一些样本再试吧,预计需要2w个左右的样本,才有可能收敛。
附件:
tensorflow GPU版本搭配:
| Version | Python version | Compiler | Build tools | cuDNN | CUDA |
|---|---|---|---|---|---|
| tensorflow-2.10.0 | 3.7-3.10 | GCC 9.3.1 | Bazel 5.1.1 | 8.1 | 11.2 |
| tensorflow-2.9.0 | 3.7-3.10 | GCC 9.3.1 | Bazel 5.0.0 | 8.1 | 11.2 |
| tensorflow-2.8.0 | 3.7-3.10 | GCC 7.3.1 | Bazel 4.2.1 | 8.1 | 11.2 |
| tensorflow-2.7.0 | 3.7-3.9 | GCC 7.3.1 | Bazel 3.7.2 | 8.1 | 11.2 |
| tensorflow-2.6.0 | 3.6-3.9 | GCC 7.3.1 | Bazel 3.7.2 | 8.1 | 11.2 |
| tensorflow-2.5.0 | 3.6-3.9 | GCC 7.3.1 | Bazel 3.7.2 | 8.1 | 11.2 |
| tensorflow-2.4.0 | 3.6-3.8 | GCC 7.3.1 | Bazel 3.1.0 | 8.0 | 11.0 |
| tensorflow-2.3.0 | 3.5-3.8 | GCC 7.3.1 | Bazel 3.1.0 | 7.6 | 10.1 |
| tensorflow-2.2.0 | 3.5-3.8 | GCC 7.3.1 | Bazel 2.0.0 | 7.6 | 10.1 |
| tensorflow-2.1.0 | 2.7, 3.5-3.7 | GCC 7.3.1 | Bazel 0.27.1 | 7.6 | 10.1 |
| tensorflow-2.0.0 | 2.7, 3.3-3.7 | GCC 7.3.1 | Bazel 0.26.1 | 7.4 | 10.0 |
| tensorflow_gpu-1.15.0 | 2.7, 3.3-3.7 | GCC 7.3.1 | Bazel 0.26.1 | 7.4 | 10.0 |
| tensorflow_gpu-1.14.0 | 2.7, 3.3-3.7 | GCC 4.8 | Bazel 0.24.1 | 7.4 | 10.0 |
| tensorflow_gpu-1.13.1 | 2.7, 3.3-3.7 | GCC 4.8 | Bazel 0.19.2 | 7.4 | 10.0 |
| tensorflow_gpu-1.12.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.15.0 | 7 | 9 |
| tensorflow_gpu-1.11.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.15.0 | 7 | 9 |
| tensorflow_gpu-1.10.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.15.0 | 7 | 9 |
| tensorflow_gpu-1.9.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.11.0 | 7 | 9 |
| tensorflow_gpu-1.8.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.10.0 | 7 | 9 |
| tensorflow_gpu-1.7.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.9.0 | 7 | 9 |
| tensorflow_gpu-1.6.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.9.0 | 7 | 9 |
| tensorflow_gpu-1.5.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.8.0 | 7 | 9 |
| tensorflow_gpu-1.4.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.5.4 | 6 | 8 |
| tensorflow_gpu-1.3.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.4.5 | 6 | 8 |
| tensorflow_gpu-1.2.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.4.5 | 5.1 | 8 |
| tensorflow_gpu-1.1.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.4.2 | 5.1 | 8 |
| tensorflow_gpu-1.0.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.4.2 | 5.1 | 8 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号