Prometheus时序数据库-数据的查询
Prometheus时序数据库-数据的查询
前言
在之前的博客里,笔者详细阐述了Prometheus数据的插入过程。但我们最常见的打交道的是数据的查询。Prometheus提供了强大的Promql来满足我们千变万化的查询需求。在这篇文章里面,笔者就以一个简单的Promql为例,讲述下Prometheus查询的过程。
Promql
一个Promql表达式可以计算为下面四种类型:
瞬时向量(Instant Vector) - 一组同样时间戳的时间序列(取自不同的时间序列,例如不同机器同一时间的CPU idle)
区间向量(Range vector) - 一组在一段时间范围内的时间序列
标量(Scalar) - 一个浮点型的数据值
字符串(String) - 一个简单的字符串
我们还可以在Promql中使用svm/avg等集合表达式,不过只能用在瞬时向量(Instant Vector)上面。为了阐述Prometheus的聚合计算以及篇幅原因,笔者在本篇文章只详细分析瞬时向量(Instant Vector)的执行过程。
瞬时向量(Instant Vector)
前面说到,瞬时向量是一组拥有同样时间戳的时间序列。但是实际过程中,我们对不同Endpoint采样的时间是不可能精确一致的。所以,Prometheus采取了距离指定时间戳之前最近的数据(Sample)。如下图所示:
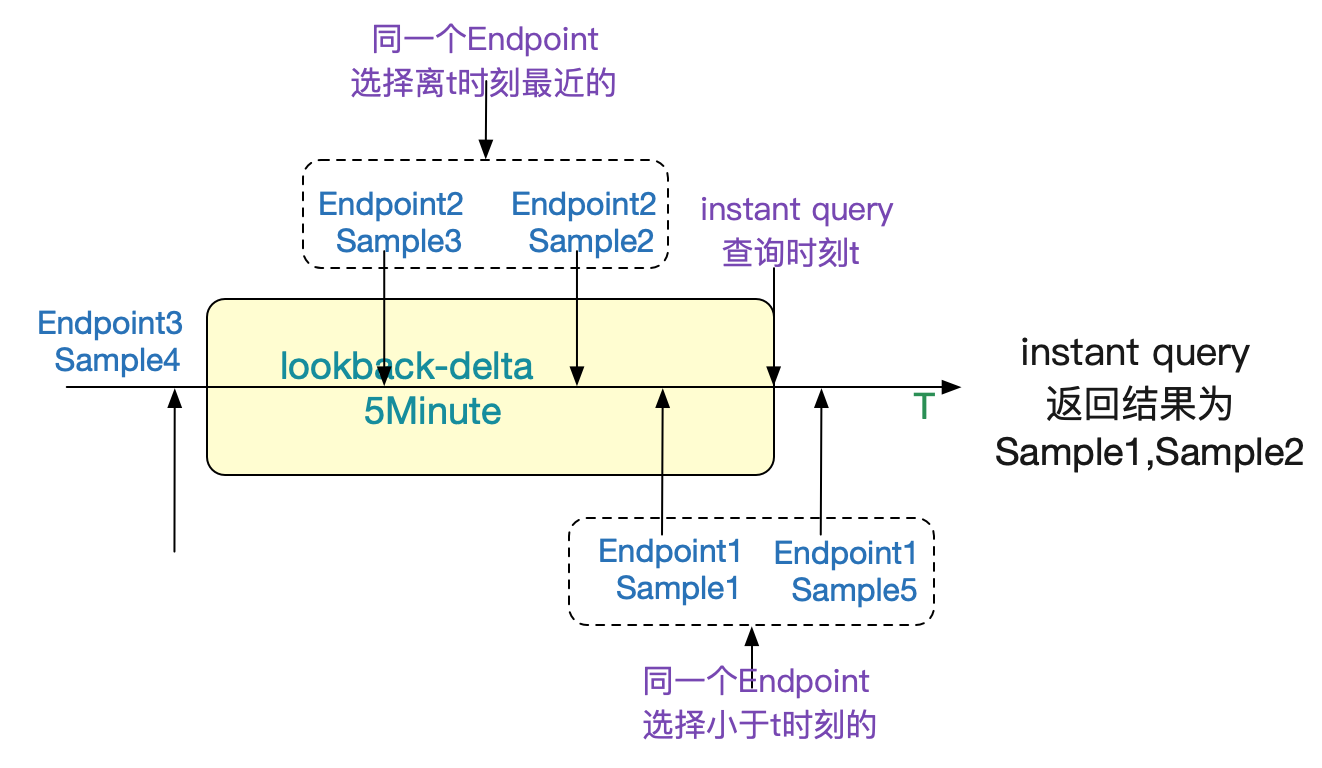
当然,如果是距离当前时间戳1个小时的数据直观看来肯定不能纳入到我们的返回结果里面。
所以Prometheus通过一个指定的时间窗口来过滤数据(通过启动参数--query.lookback-delta指定,默认5min)。
对一条简单的Promql进行分析
好了,解释完Instant Vector概念之后,我们可以着手进行分析了。直接上一条带有聚合函数的Promql把。
SUM BY (group) (http_requests{job="api-server",group="production"})
首先,对于这种有语法结构的语句肯定是将其Parse一把,构造成AST树了。调用
promql.ParseExpr
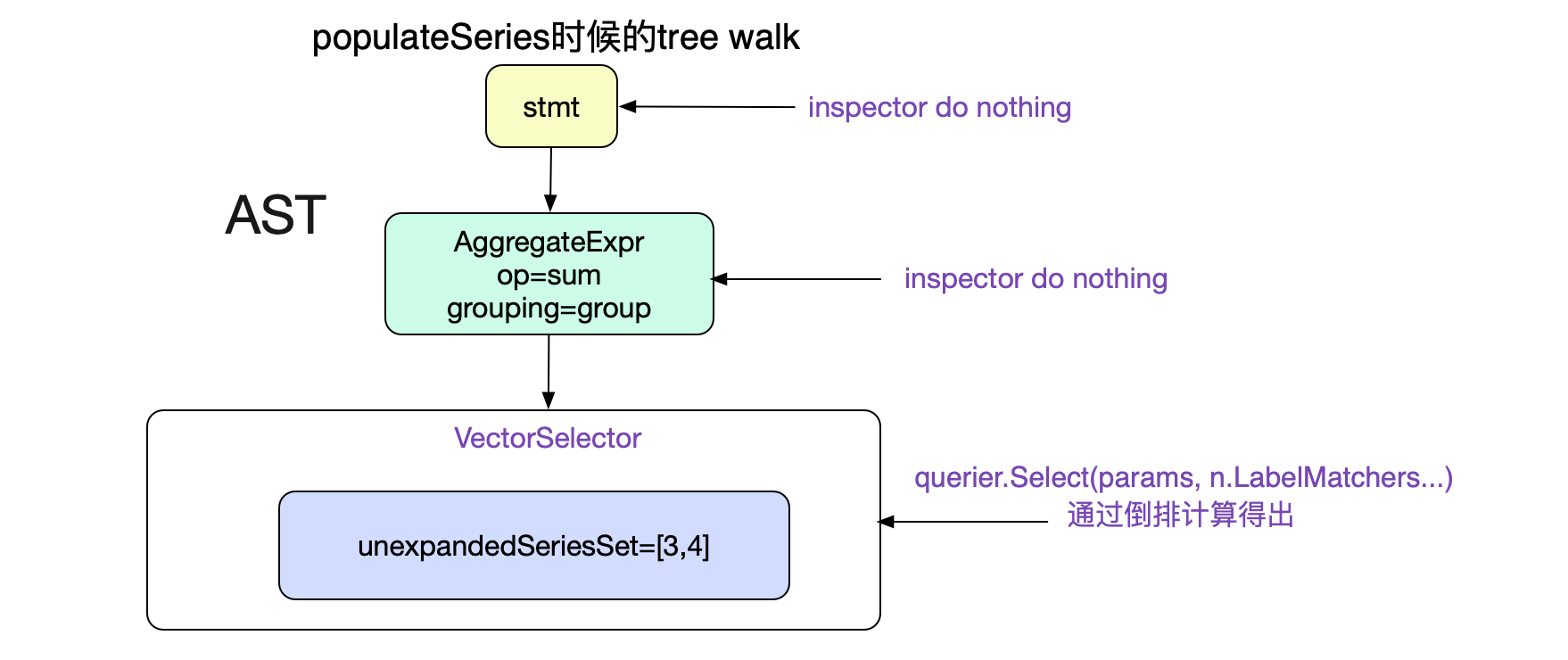
由于Promql较为简单,所以Prometheus直接采用了LL语法分析。在这里直接给出上述Promql的AST树结构。
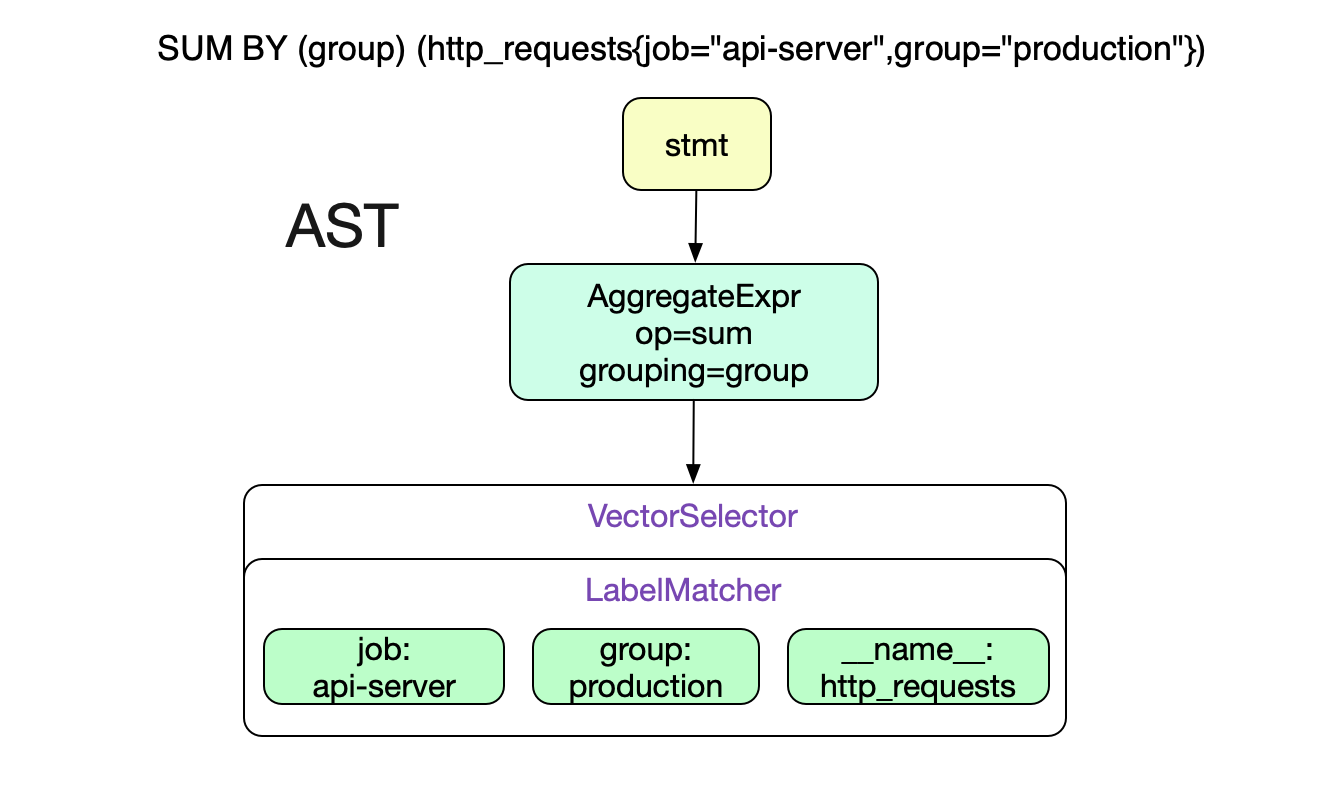
Prometheus对于语法树的遍历过程都是通过vistor模式,具体到代码为:
ast.go vistor设计模式
func Walk(v Visitor, node Node, path []Node) error {
var err error
if v, err = v.Visit(node, path); v == nil || err != nil {
return err
}
path = append(path, node)
for _, e := range Children(node) {
if err := Walk(v, e, path); err != nil {
return err
}
}
_, err = v.Visit(nil, nil)
return err
}
func (f inspector) Visit(node Node, path []Node) (Visitor, error) {
if err := f(node, path); err != nil {
return nil, err
}
return f, nil
}
通过golang里非常方便的函数式功能,直接传递求值函数inspector进行不同情况下的求值。
type inspector func(Node, []Node) error
求值过程
具体的求值过程核心函数为:
func (ng *Engine) execEvalStmt(ctx context.Context, query *query, s *EvalStmt) (Value, storage.Warnings, error) {
......
querier, warnings, err := ng.populateSeries(ctxPrepare, query.queryable, s) // 这边拿到对应序列的数据
......
val, err := evaluator.Eval(s.Expr) // here 聚合计算
......
}
populateSeries
首先通过populateSeries的计算出VectorSelector Node所对应的series(时间序列)。这里直接给出求值函数
func(node Node, path []Node) error {
......
querier, err := q.Querier(ctx, timestamp.FromTime(mint), timestamp.FromTime(s.End))
......
case *VectorSelector:
.......
set, wrn, err = querier.Select(params, n.LabelMatchers...)
......
n.unexpandedSeriesSet = set
......
case *MatrixSelector:
......
}
return nil
可以看到这个求值函数,只对VectorSelector/MatrixSelector进行操作,针对我们的Promql也就是只对叶子节点VectorSelector有效。
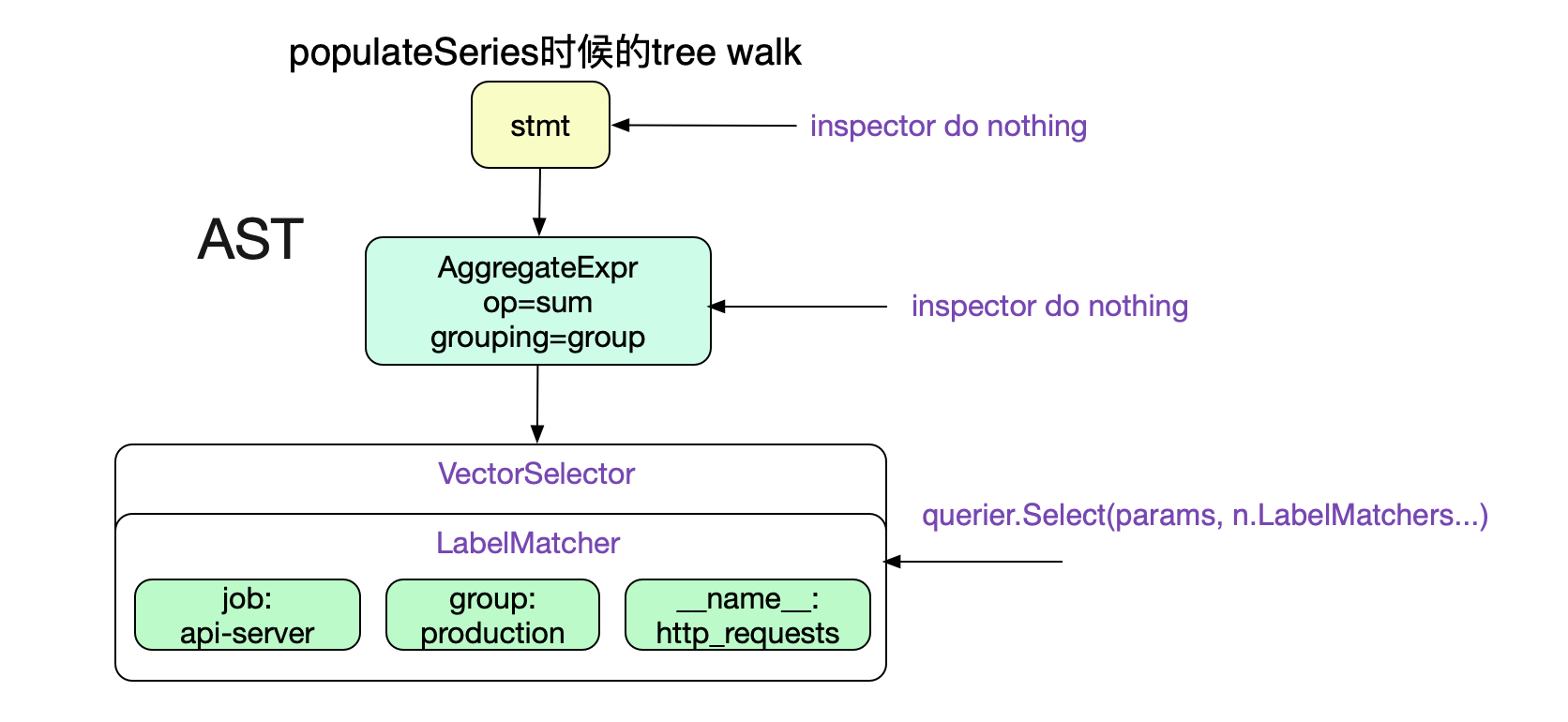
select
获取对应数据的核心函数就在querier.Select。我们先来看下qurier是如何得到的.
querier, err := q.Querier(ctx, timestamp.FromTime(mint), timestamp.FromTime(s.End))
根据时间戳范围去生成querier,里面最重要的就是计算出哪些block在这个时间范围内,并将他们附着到querier里面。具体见函数
func (db *DB) Querier(mint, maxt int64) (Querier, error) {
for _, b := range db.blocks {
......
// 遍历blocks挑选block
}
// 如果maxt>head.mint(即内存中的block),那么也加入到里面querier里面。
if maxt >= db.head.MinTime() {
blocks = append(blocks, &rangeHead{
head: db.head,
mint: mint,
maxt: maxt,
})
}
......
}

知道数据在哪些block里面,我们就可以着手进行计算VectorSelector的数据了。
// labelMatchers {job:api-server} {__name__:http_requests} {group:production}
querier.Select(params, n.LabelMatchers...)
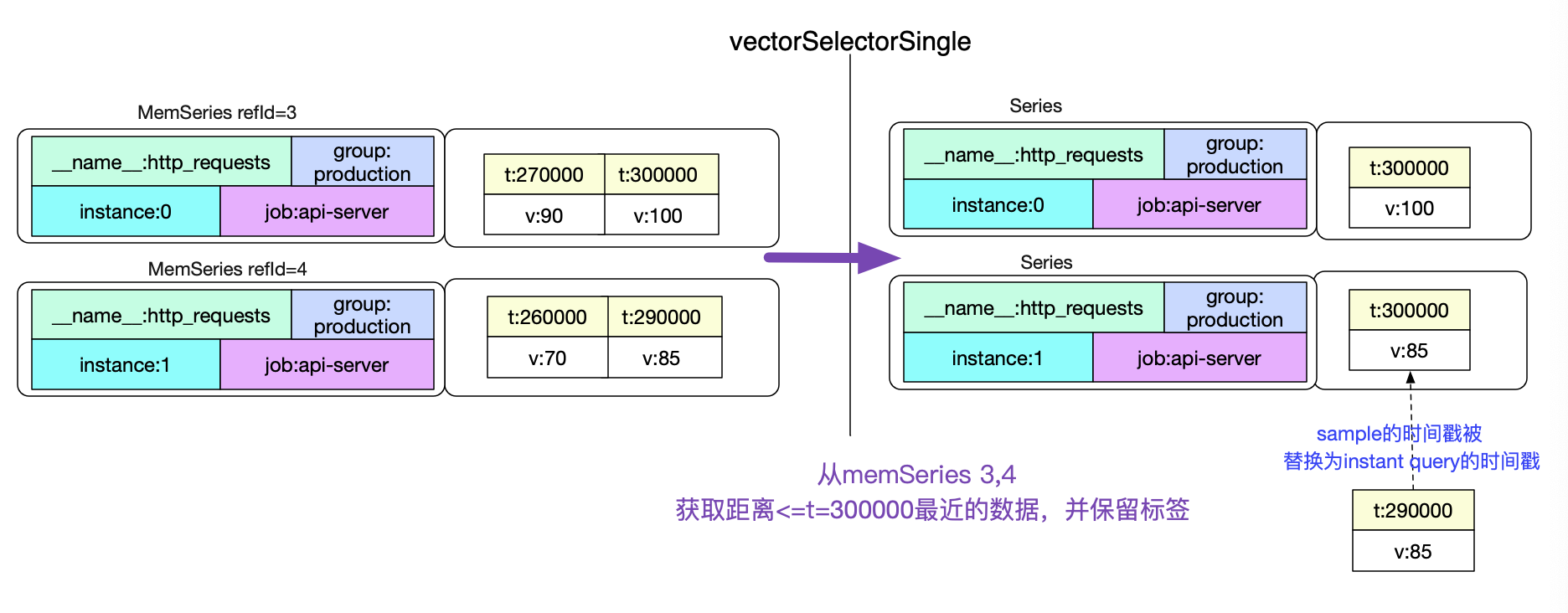
有了matchers我们很容易的就能够通过倒排索引取到对应的series。为了篇幅起见,我们假设数据都在headBlock(也就是内存里面)。那么我们对于倒排的计算就如下图所示:
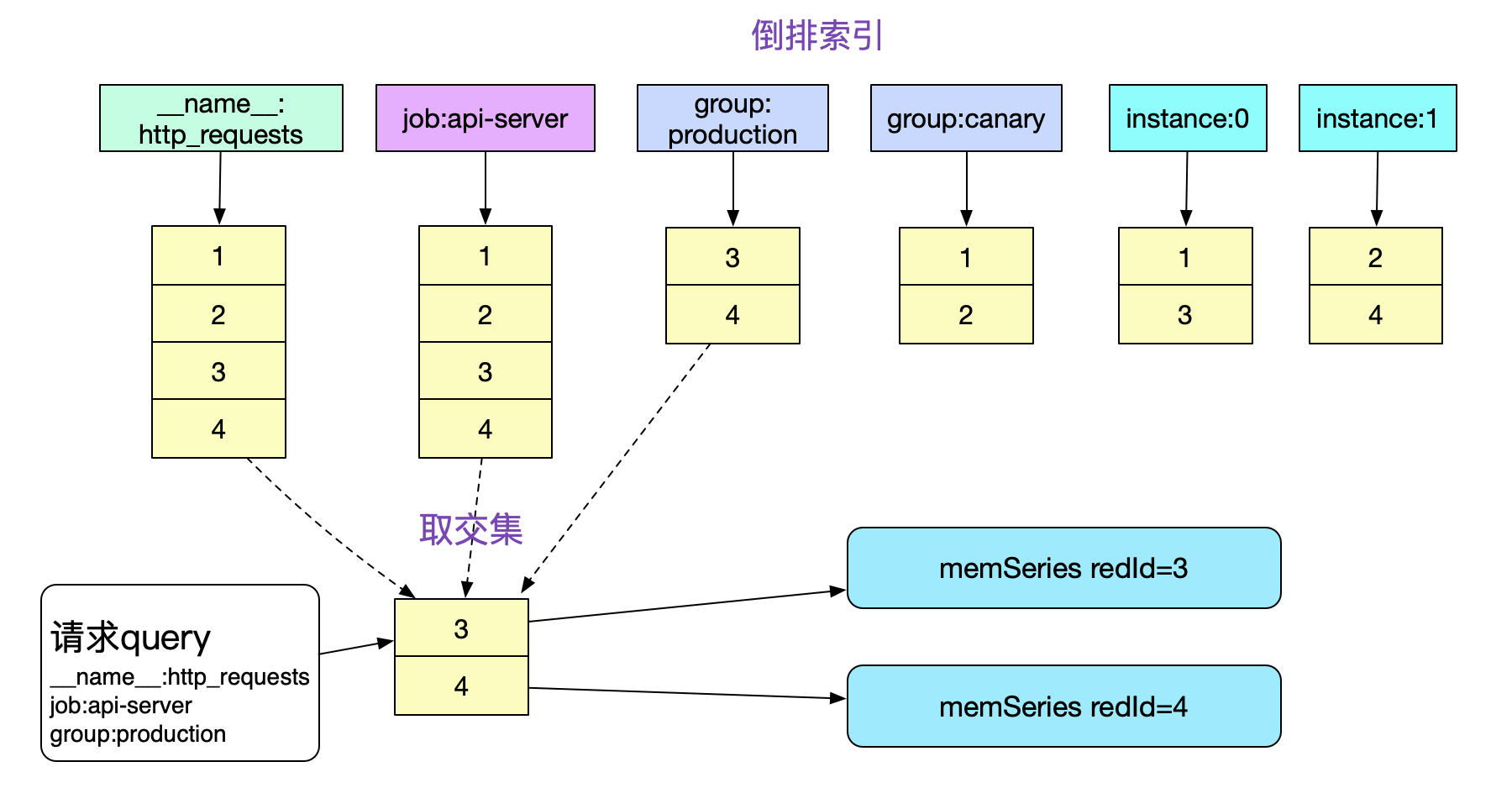
这样,我们的VectorSelector节点就已经有了最终的数据存储地址信息了,例如图中的memSeries refId=3和4。
如果想了解在磁盘中的数据寻址,可以详见笔者之前的博客
<<Prometheus时序数据库-磁盘中的存储结构>>
evaluator.Eval
通过populateSeries找到对应的数据,那么我们就可以通过evaluator.Eval获取最终的结果了。计算采用后序遍历,等下层节点返回数据后才开始上层节点的计算。那么很自然的,我们先计算VectorSelector。
func (ev *evaluator) eval(expr Expr) Value {
......
case *VectorSelector:
// 通过refId拿到对应的Series
checkForSeriesSetExpansion(ev.ctx, e)
// 遍历所有的series
for i, s := range e.series {
// 由于我们这边考虑的是instant query,所以只循环一次
for ts := ev.startTimestamp; ts <= ev.endTimestamp; ts += ev.interval {
// 获取距离ts最近且小于ts的最近的sample
_, v, ok := ev.vectorSelectorSingle(it, e, ts)
if ok {
if ev.currentSamples < ev.maxSamples {
// 注意,这边的v对应的原始t被替换成了ts,也就是instant query timeStamp
ss.Points = append(ss.Points, Point{V: v, T: ts})
ev.currentSamples++
} else {
ev.error(ErrTooManySamples(env))
}
}
......
}
}
}
如代码注释中看到,当我们找到一个距离ts最近切小于ts的sample时候,只用这个sample的value,其时间戳则用ts(Instant Query指定的时间戳)代替。
其中vectorSelectorSingle值得我们观察一下:
func (ev *evaluator) vectorSelectorSingle(it *storage.BufferedSeriesIterator, node *VectorSelector, ts int64) (int64, float64, bool){
......
// 这一步是获取>=refTime的数据,也就是我们instant query传入的
ok := it.Seek(refTime)
......
if !ok || t > refTime {
// 由于我们需要的是<=refTime的数据,所以这边回退一格,由于同一memSeries同一时间的数据只有一条,所以回退的数据肯定是<=refTime的
t, v, ok = it.PeekBack(1)
if !ok || t < refTime-durationMilliseconds(LookbackDelta) {
return 0, 0, false
}
}
}
就这样,我们找到了series 3和4距离Instant Query时间最近且小于这个时间的两条记录,并保留了记录的标签。这样,我们就可以在上层进行聚合。
SUM by聚合
叶子节点VectorSelector得到了对应的数据后,我们就可以对上层节点AggregateExpr进行聚合计算了。代码栈为:
evaluator.rangeEval
|->evaluate.eval.func2
|->evelator.aggregation grouping key为group
具体的函数如下图所示:
func (ev *evaluator) aggregation(op ItemType, grouping []string, without bool, param interface{}, vec Vector, enh *EvalNodeHelper) Vector {
......
// 对所有的sample
for _, s := range vec {
metric := s.Metric
......
group, ok := result[groupingKey]
// 如果此group不存在,则新加一个group
if !ok {
......
result[groupingKey] = &groupedAggregation{
labels: m, // 在这里我们的m=[group:production]
value: s.V,
mean: s.V,
groupCount: 1,
}
......
}
switch op {
// 这边就是对SUM的最终处理
case SUM:
group.value += s.V
.....
}
}
.....
for _, aggr := range result {
enh.out = append(enh.out, Sample{
Metric: aggr.labels,
Point: Point{V: aggr.value},
})
}
......
return enh.out
}
好了,有了上面的处理,我们聚合的结果就变为:
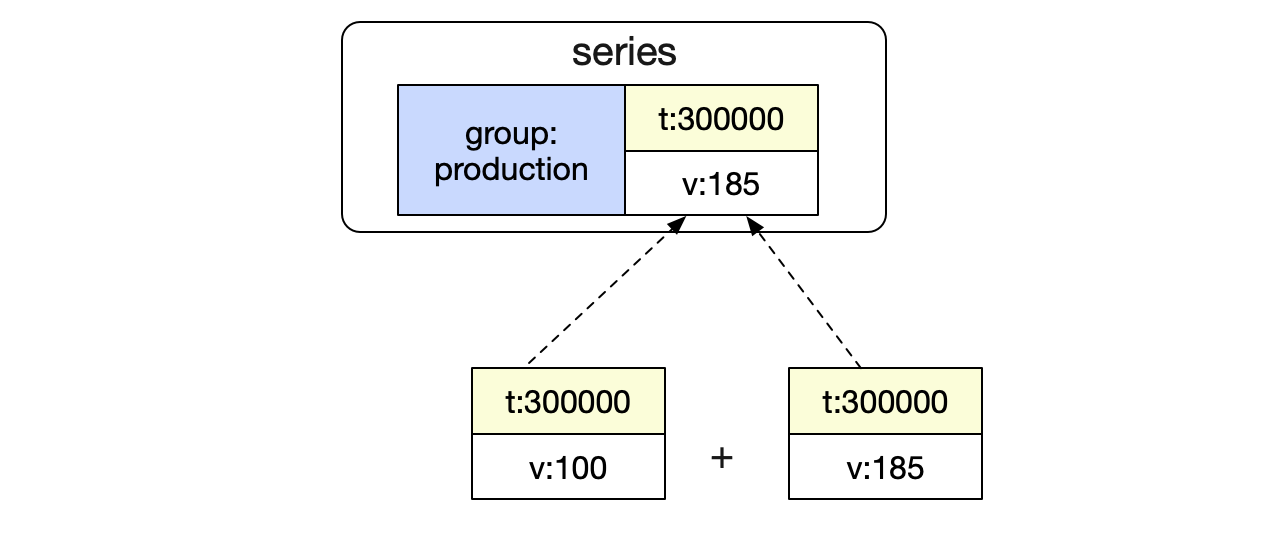
这个和我们的预期结果一致,一次查询的过程就到此结束了。
总结
Promql是非常强大的,可以满足我们的各种需求。其运行原理自然也激起了笔者的好奇心,本篇文章虽然只分析了一条简单的Promql,但万变不离其宗,任何Promql都是类似的运行逻辑。希望本文对读者能有所帮助。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号