解Bug之路-记一次存储故障的排查过程
解Bug之路-记一次存储故障的排查过程
高可用真是一丝细节都不得马虎。平时跑的好好的系统,在相应硬件出现故障时就会引发出潜在的Bug。偏偏这些故障在应用层的表现稀奇古怪,很难让人联想到是硬件出了问题,特别是偶发性出现的问题更难排查。今天,笔者就给大家带来一个存储偶发性故障的排查过程。
Bug现场
我们的积分应用由于量非常大,所以需要进行分库分表,所以接入了我们的中间件。一直稳定运行,但应用最近确经常偶发连接建立不上的报错。报错如下:
GetConnectionTimeOutException
而笔者中间件这边收到的确是:
NIOReactor - register err java.nio.channels.CloasedChannelException
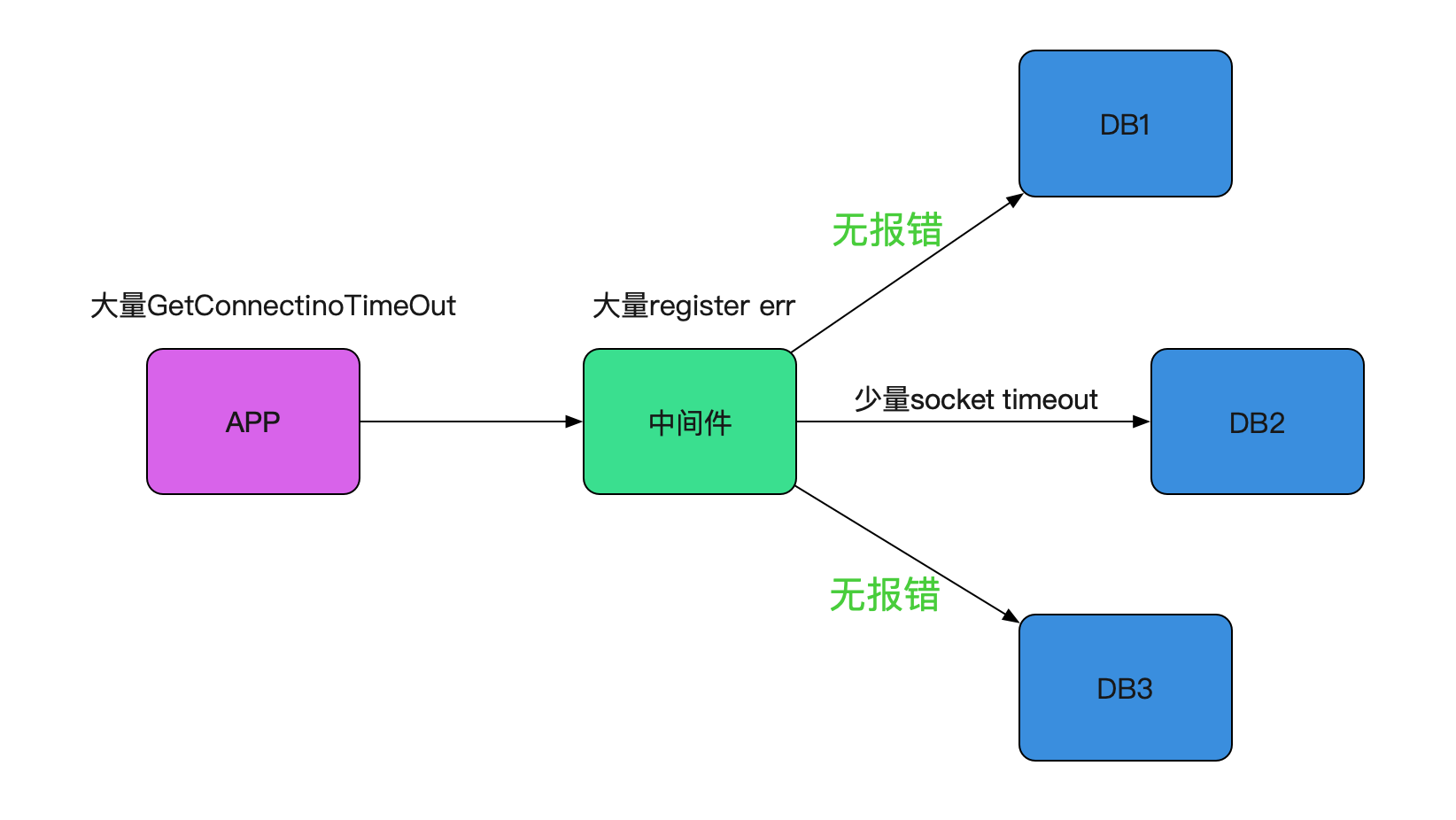
这样的告警。整个Bug现场如下图所示:
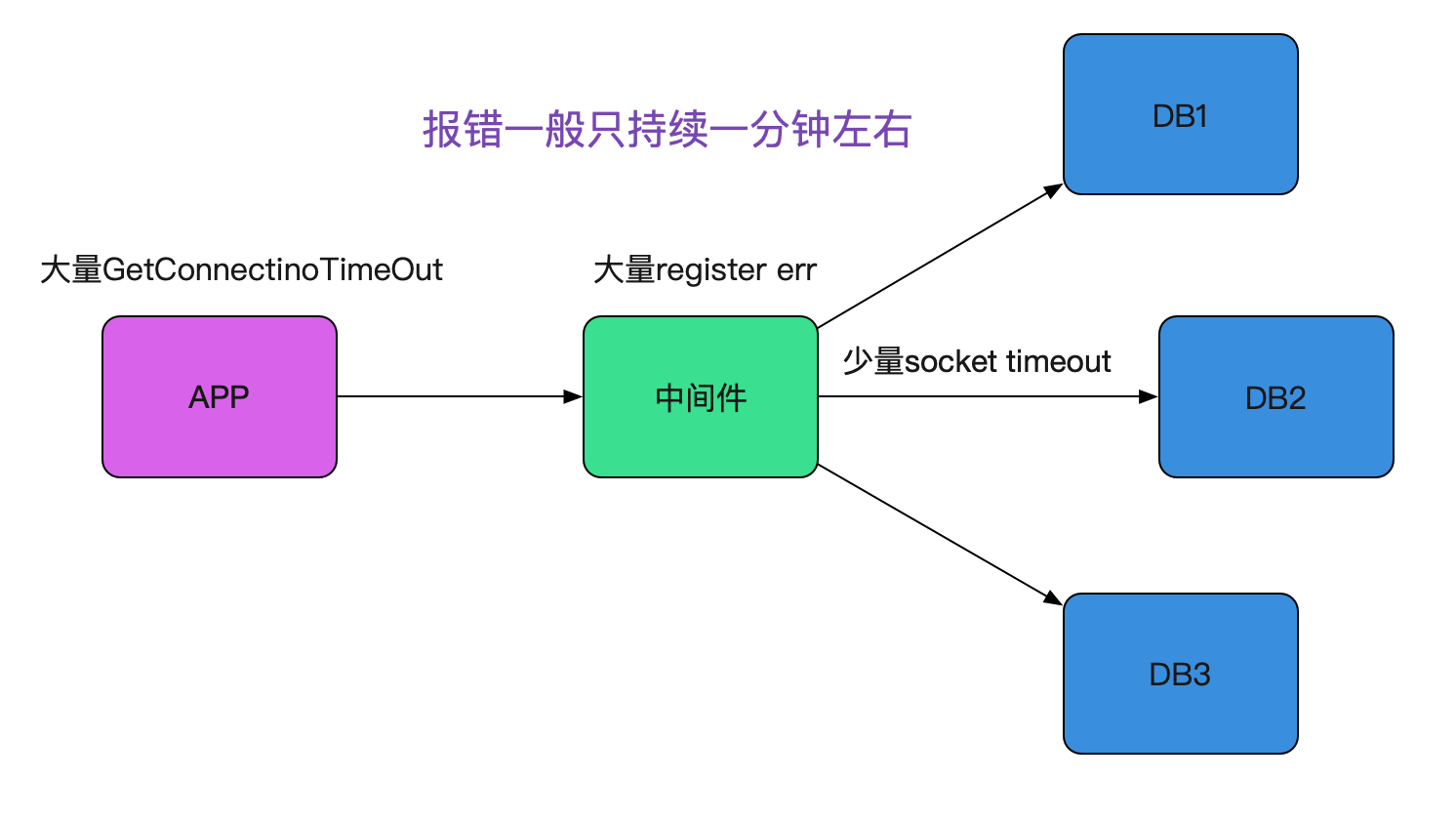
偶发性错误
之前出过类似register err这样的零星报警,最后原因是安全扫描,并没有对业务造成任何影响。而这一次,类似的报错造成了业务的大量连接超时。由于封网,线上中间件和应用已经稳定在线上跑了一个多月,代码层面没有任何改动!突然出现的这个错误感觉是环境出现了某些问题。而且由于线上的应用和中间件都是集群,出问题时候都不是孤立的机器报错,没道理所有机器都正好有问题。如下图所示:
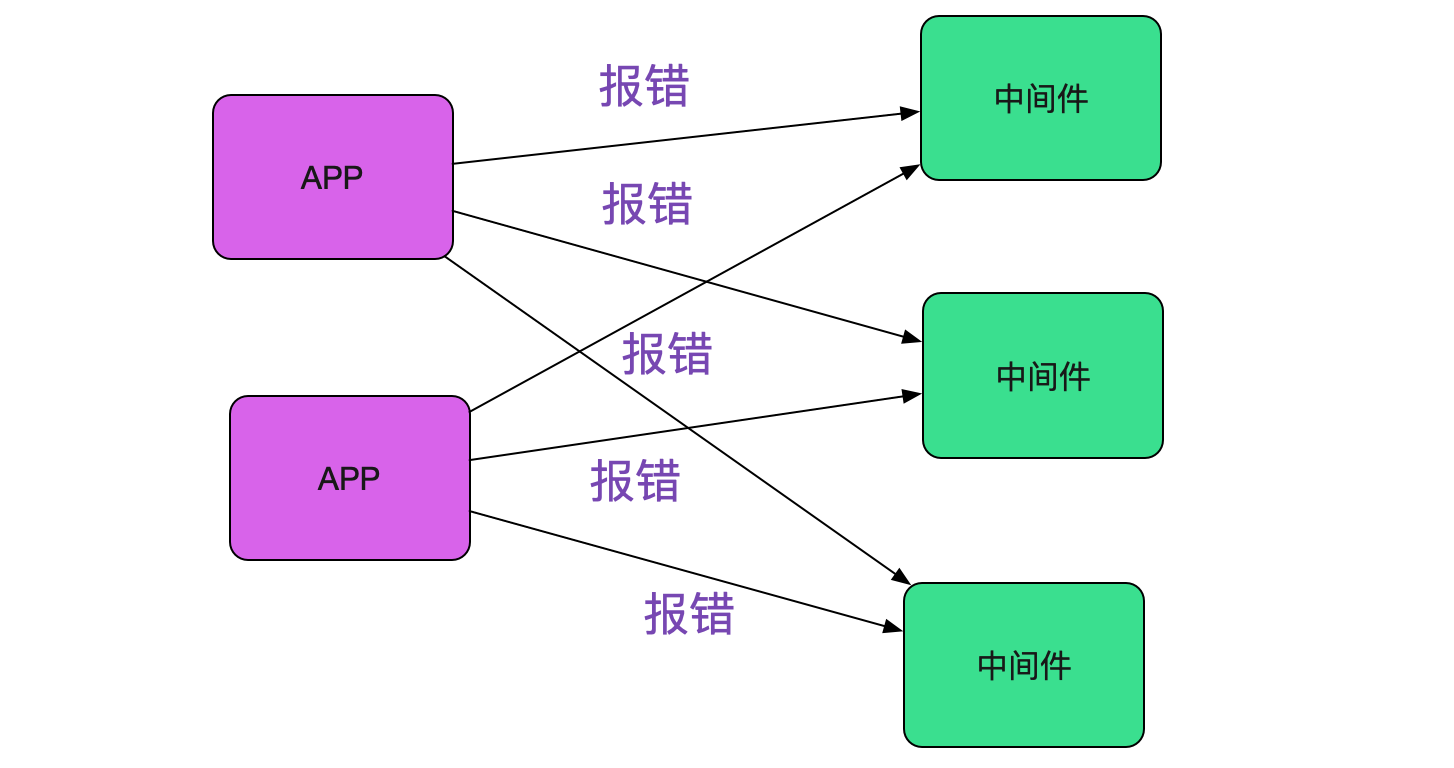
开始排查是否网络问题
遇到这种连接超时,笔者最自然的想法当然是网络出了问题。于是找网工进行排查,
在监控里面发现网络一直很稳定。而且如果是网络出现问题,同一网段的应用应该也都会报错
才对。事实上只有对应的应用和中间件才报错,其它的应用依旧稳稳当当。
又发生了两次
就在笔者觉得这个偶发性问题可能不会再出现的时候,又开始抖了。而且是一个下午连抖了两次。脸被打的啪啪的,算了算了,先重启吧。重启中间件后,以为能消停一会,没想到半个小时之内又报了。看来今天不干掉这个Bug是下不了班了!
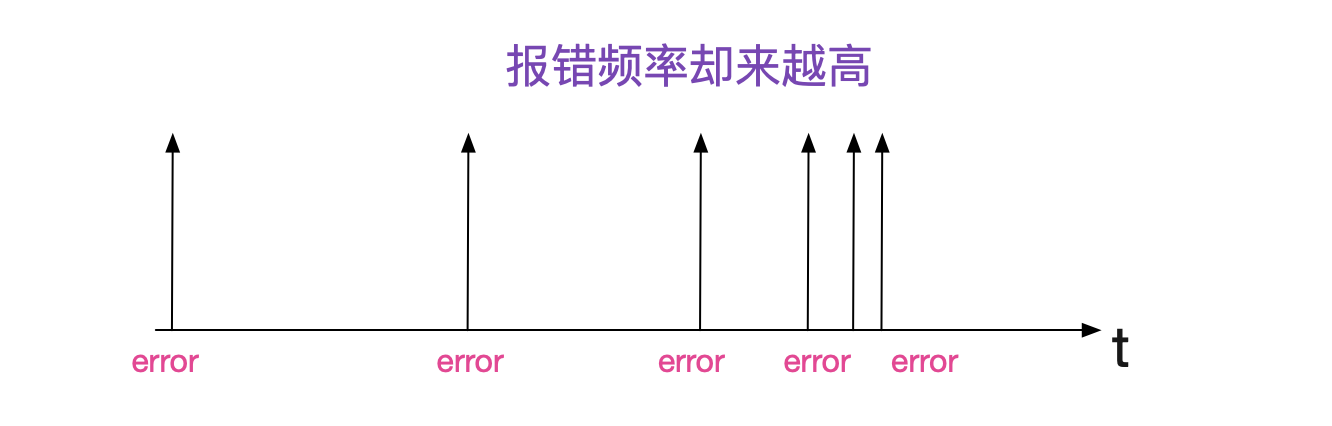
开始排查日志
事实上,笔者一开始就发现中间件有调用后端数据库慢SQL的现象,由于比较偶发,所以将这个现象发给DBA之后就没有继续跟进,DBA也反馈SQL执行没有任何异常。笔者开始认真分析日志之后,发现一旦有 中间件的register err 必定会出现中间件调用后端数据库的sql read timeout的报错。
但这两个报错完全不是在一个线程里面的,一个是处理前端的Reactor线程,一个是处理后端SQL的Worker线程,如下图所示:
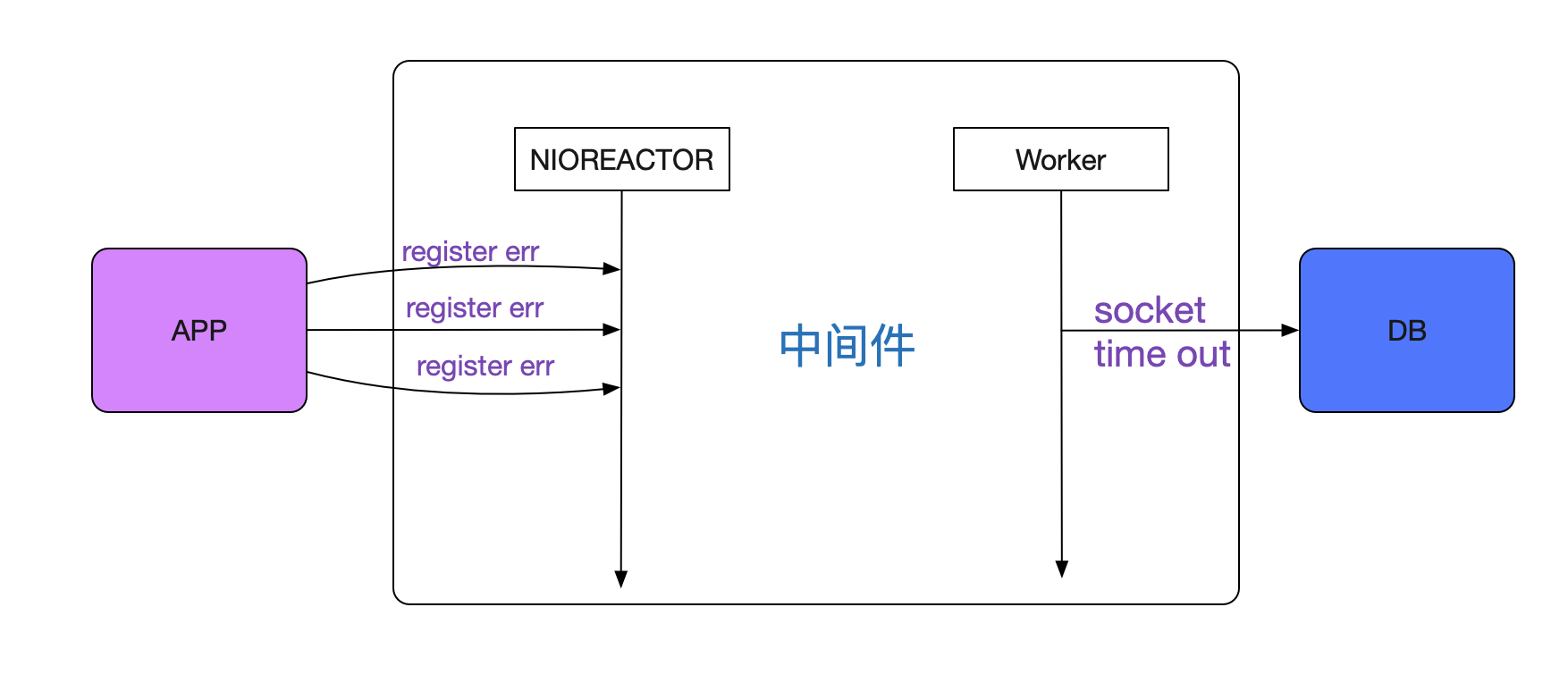
这两个线程是互相独立的,代码中并没有发现任何机制能让这两个线程互相影响。难道真是这些机器本身网络出了问题?前端APP失败,后端调用DB超时,怎么看都像网络的问题!
进一步进行排查
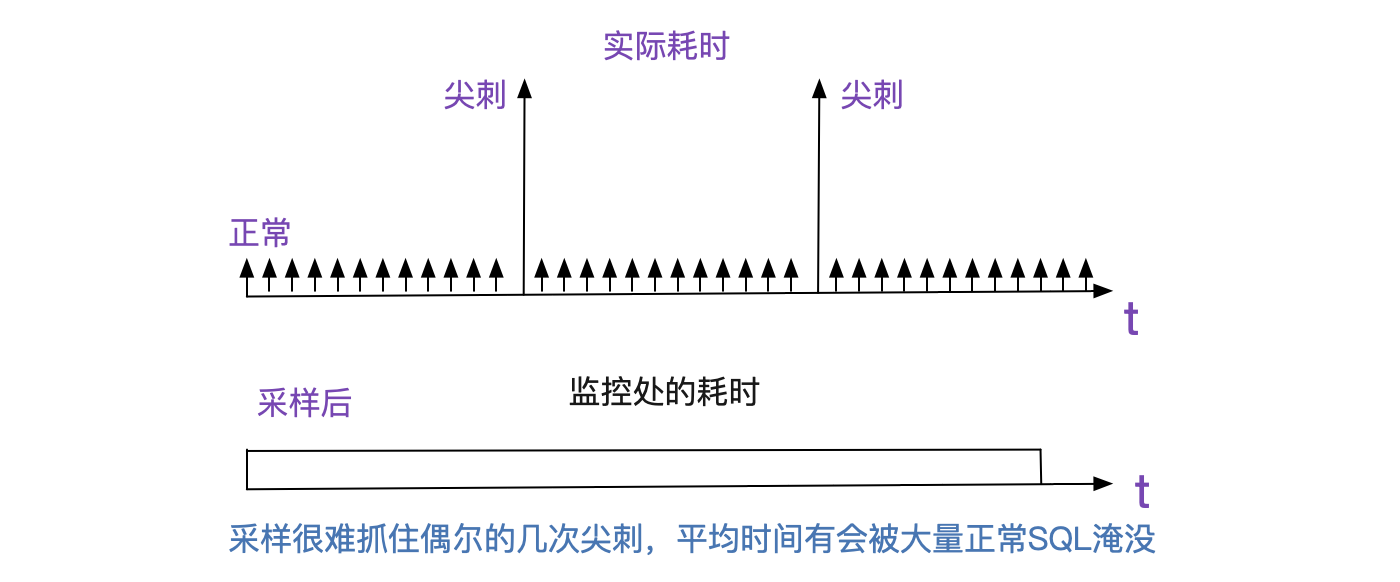
既然有DB(数据库)超时,笔者就先看看调用哪个DB超时吧,毕竟后面有一堆DB。笔者突然发现,和之前的慢SQL一样,都是调用第二个数据库超时,而DBA那边却说SQL执行没有任何异常,
笔者感觉明显SQL执行有问题,只不过DBA是采样而且将采样耗时平均的,偶尔的几笔耗时并不会在整体SQL的耗时里面有所体现。
只能靠日志分析了
既然找不到什么头绪,那么只能从日志入手,好好分析推理了。REACTOR线程和Worker线程同时报错,但两者并无特殊的关联,说明可能是同一个原因引起的两种不同现象。笔者在线上报错日志里面进行细细搜索,发现在大量的
NIOReactor-1-RW register err java.nio.channels.CloasedChannelException
日志中会掺杂着这个报错:
NIOReactor-1-RW Socket Read timed out
at XXXXXX . doCommit
at XXXXXX Socket read timedout
这一看就发现了端倪,Reactor作为一个IO线程,怎么会有数据库调用呢?于是翻了翻源码,原来,我们的中间件在处理commit/rollback这样的操作时候还是在Reactor线程进行的!很明显Reactor线程卡主是由于commit慢了!笔者立马反应过来,而这个commit慢也正是导致了regsiter err以及客户端无法创建连接的元凶。如下面所示:
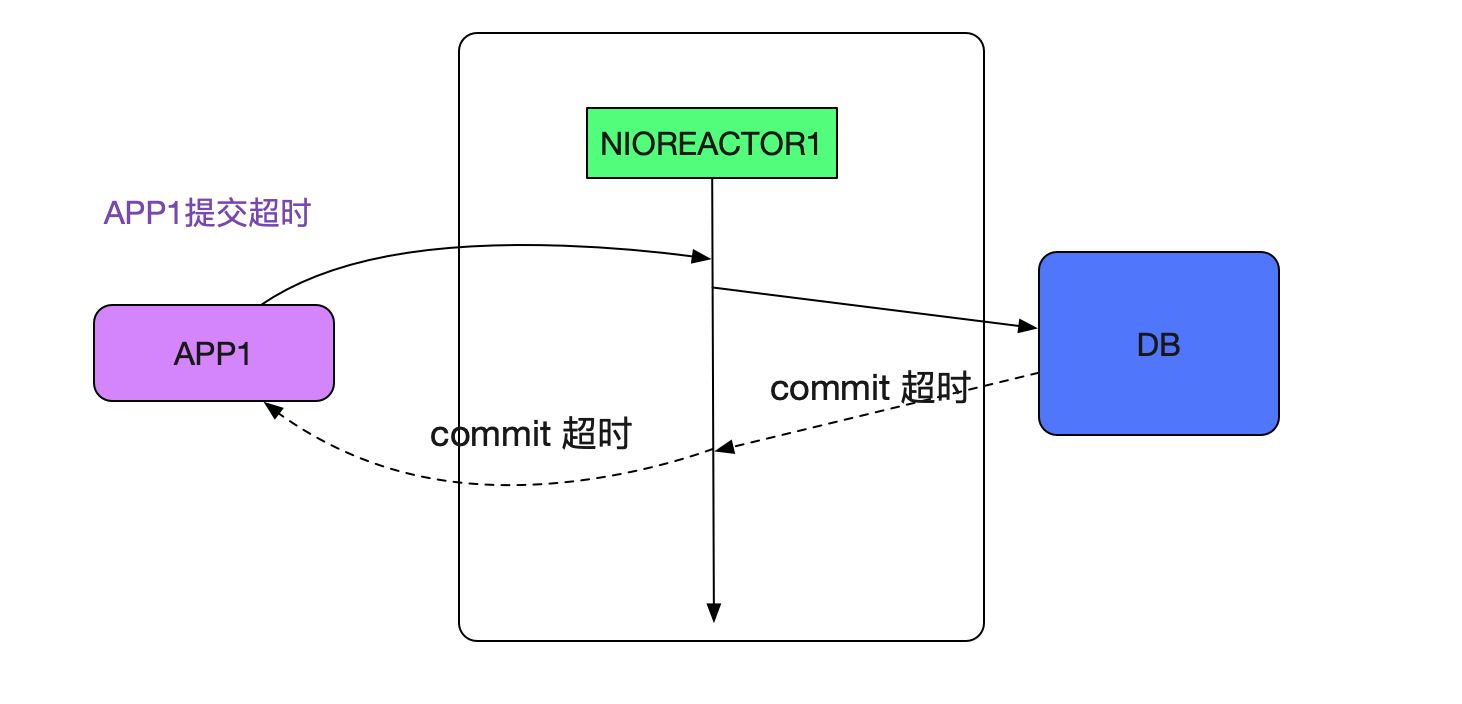
由于app1的commit特别慢而卡住了reactor1线程,从而落在reactor1线程上的握手操作都会超时!如下图所示:
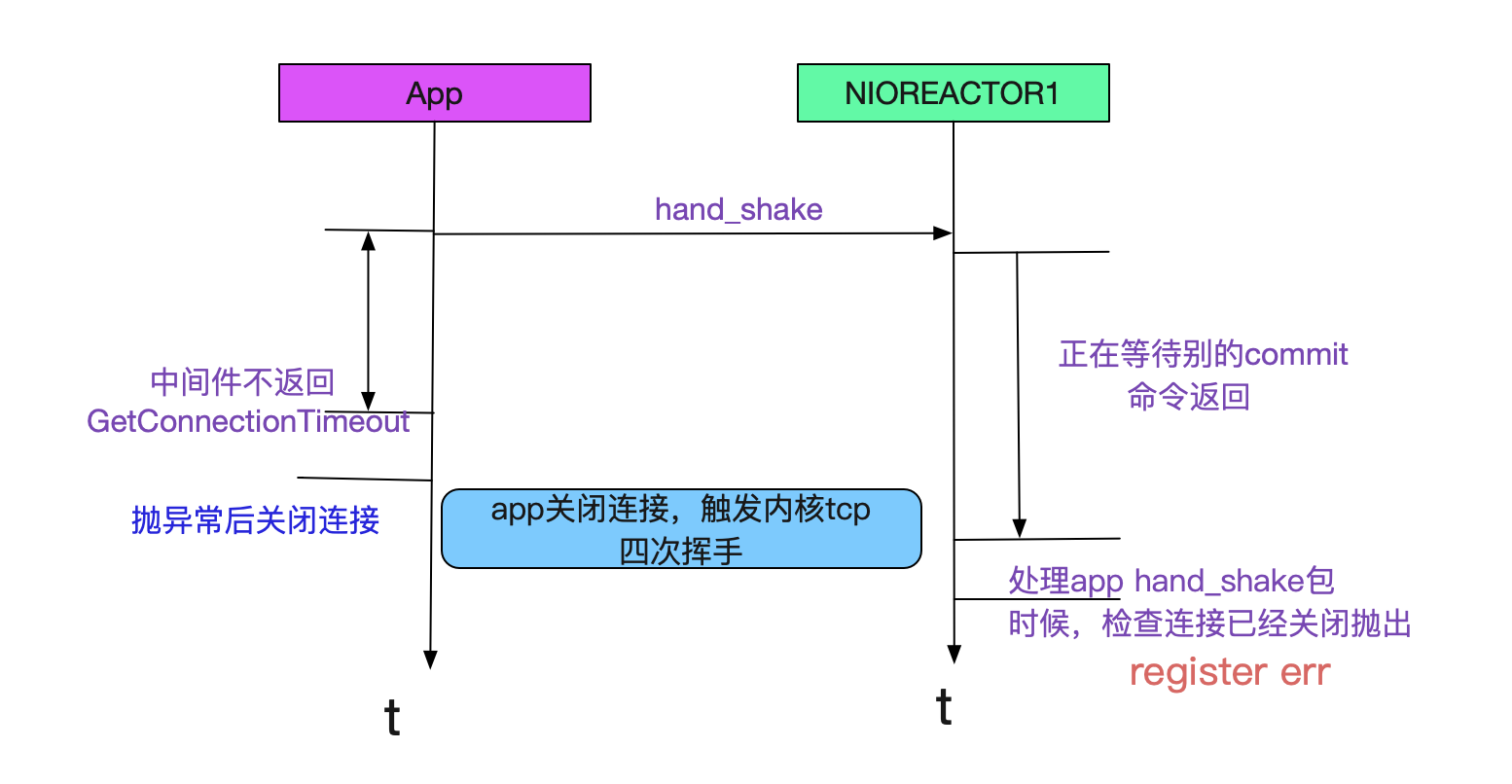
为什么之前的模拟宕机测试发现不了这一点
因为模拟宕机的时候,在事务开始的第一条SQL就会报错,而执行SQL都是在Worker线程里面,
所以并不会触发reactor线程中commit超时这种现象,所以测试的时候就遗漏了这一点。
为什么commit会变慢?
系统一直跑的好好的,为什么突然commit就变慢了呢,而且笔者发现,这个commit变慢所关联的DB正好也是出现慢SQL的那个DB。于是笔者立马就去找了DBA,由于我们应用层和数据库层都没有commit时间的监控(因为一般都很快,很少出现慢的现象)。DBA在数据库打的日志里面进行了统计,发现确实变慢了,而且变慢的时间和我们应用报错的时间相符合!
顺藤摸瓜,我们又联系了SA,发现其中和存储相关的HBA卡有报错!如下图所示:
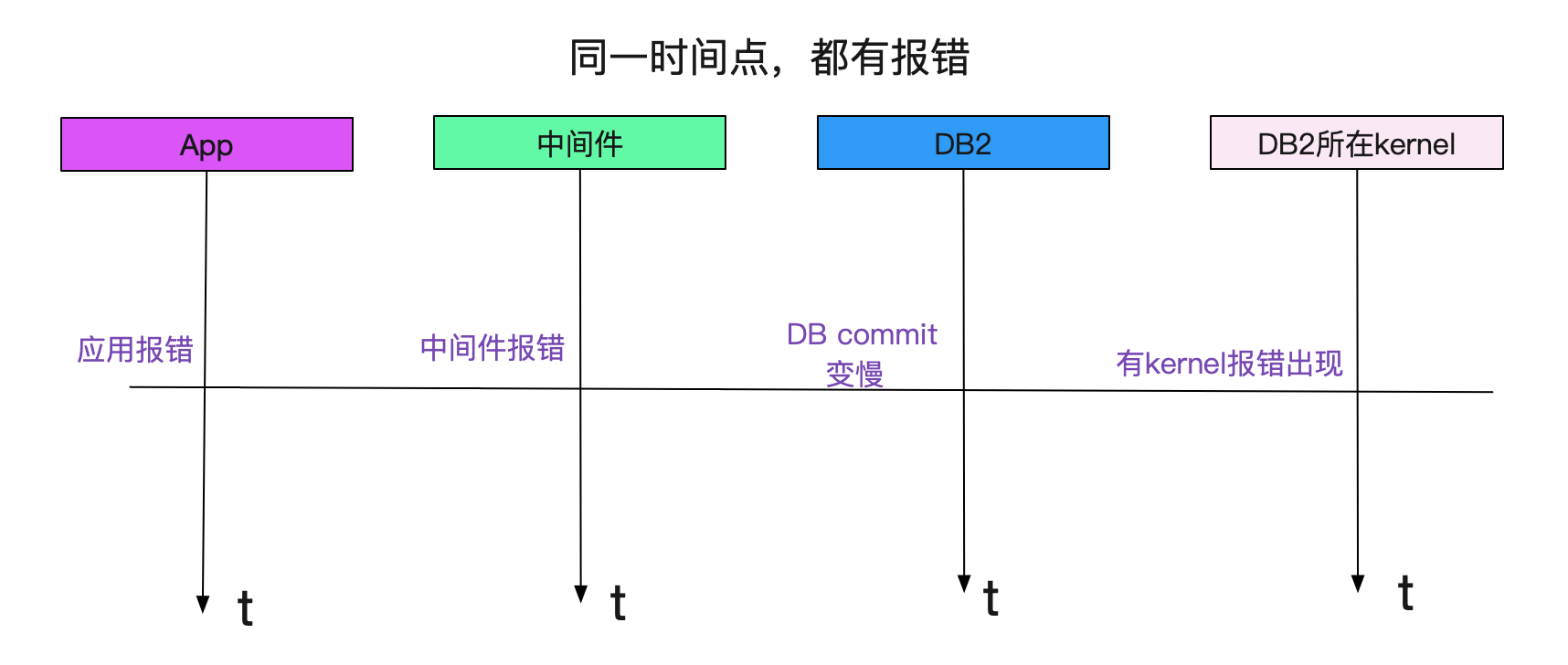
报错时间都是一致的!
紧急修复方案
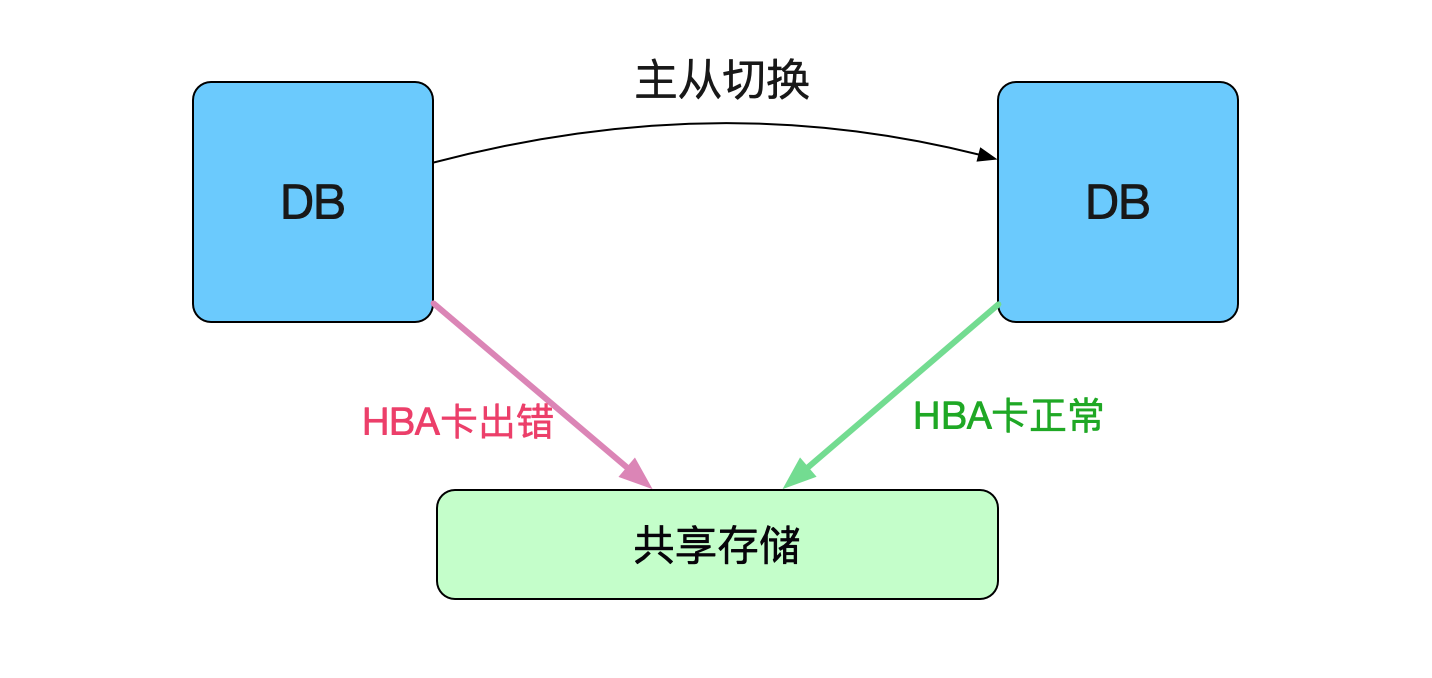
由于是HBA卡报错了,属于硬件故障,而硬件故障并不是很快就能进行修复的。所以DBA做了一次紧急的主从切换,进而避免这一问题。
一身冷汗
之前就有慢sql慢慢变多,而后突然数据库存储hba卡宕机导致业务不可用的情况。
而这一次到最后主从切换前为止,报错越来越频繁,感觉再过一段时间,HBA卡过段时间就完全不可用,重蹈之前的覆辙了!
中间件修复
我们在中间件层面将commit和rollback操作挪到Worker里面。这样,commit如果卡住就不再会引起创建连接失败这种应用报错了。
总结
由于软件层面其实是比较信任硬件的,所以在硬件出问题时,就会产生很多诡异的现象,而且和硬件最终的原因在表面上完全产生不了关联。只有通过抽丝剥茧,慢慢的去探寻现象的本质才会解决最终的问题。要做到高可用真的是要小心评估各种细节,才能让系统更加健壮!
公众号
关注笔者公众号,获取更多干货文章:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号