记一次翻译工具的开发-有了它,实现实时翻译还远吗?
有了它,实现实时翻译还远吗?
最近,某水果手机厂在万众期待中开了一场没有发布万众期待的手机产品的发布会,发布了除手机外的其他一些产品,也包括最新的水果14系统。几天后,更新了系统的吃瓜群众经过把玩突然发现新系统里一个超有意思的功能——翻译,比如这种:

奇怪的翻译知识增加了!
相比常见的翻译工具,同声翻译工具更具有实用价值,想想不精通其他语言就能和歪果朋友无障碍交流的场景,真是一件美事,不如自己动手实现个工具备用!一个同声翻译工具,逻辑大概可以是先识别,而后翻译,翻译能否成功,识别的准确率是个关键因素。为了降低难度,我决定分两次完成工具开发。首先来实现试试语音识别的部分。
轻车熟路,本次的demo继续调用有道智云API,实现实时语音识别。
效果展示
先看看界面和结果哈:
可以选择多种语音,这里只写了四种常见的:
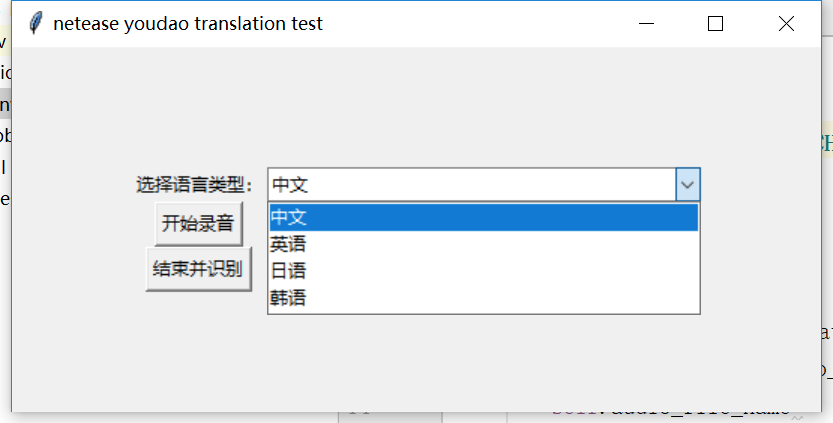
偶分别测试的中文、韩文、英文。看着还不错哦~

调用API接口的准备工作
首先,是需要在有道智云的个人页面上创建实例、创建应用、绑定应用和实例,获取调用接口用到的应用的id和密钥。具体个人注册的过程和应用创建过程详见文章分享一次批量文件翻译的开发过程
开发过程详细介绍
下面介绍具体的代码开发过程。
首先是根据实时语音识别文档来分析接口的输入输出。接口设计的目的是对连续音频流的实时识别,转换成文本信息并返对应文字流,因此通信采用websocket,调用过程分为认证、实时通信两阶段。
在认证阶段,需发送以下参数:
| 参数 | 类型 | 必填 | 说明 | 示例 |
|---|---|---|---|---|
| appKey | String | 是 | 已申请的应用ID | ID |
| salt | String | 是 | UUID | UUID |
| curtime | String | 是 | 时间戳(秒) | TimeStamp |
| sign | String | 是 | 加密数字签名。 | sha256 |
| signType | String | 是 | 数字签名类型 | v4 |
| langType | String | 是 | 语言选择,参考支持语言列表 | zh-CHS |
| format | String | 是 | 音频格式,支持wav | wav |
| channel | String | 是 | 声道,支持1(单声道) | 1 |
| version | String | 是 | api版本 | v1 |
| rate | String | 是 | 采样率 | 16000 |
签名
sign生成方法如下:
signType=v4;
sign=sha256(应用ID+salt+curtime+应用密钥)。
认证之后,就进入了实时通信阶段,发送音频流,获取识别结果,最后发送结束标志结束通信,这里需要注意的是,发送的音频最好是16bit位深的单声道、16k采样率的清晰的wav音频文件,这里我开发时最开始因为音频录制设备有问题,导致音频效果极差,接口一直返回错误码304(手动捂脸)。
Demo开发:
这个demo使用python3开发,包括maindow.py,audioandprocess.py,recobynetease.py三个文件。界面部分,使用python自带的tkinter库,来进行语言选择、录音开始、录音停止并识别的操作。audioandprocess.py实现了录音、音频处理的逻辑,最后通过recobynetease.py中的方法来调用实时语音识别API。
-
界面部分:
主要元素:
root=tk.Tk() root.title("netease youdao translation test") frm = tk.Frame(root) frm.grid(padx='80', pady='80') # label1=tk.Label(frm,text="选择待翻译文件:") # label1.grid(row=0,column=0) label=tk.Label(frm,text='选择语言类型:') label.grid(row=0,column=0) combox=ttk.Combobox(frm,textvariable=tk.StringVar(),width=38) combox["value"]=lang_type_dict combox.current(0) combox.bind("<<ComboboxSelected>>",get_lang_type) combox.grid(row=0,column=1) btn_start_rec = tk.Button(frm, text='开始录音', command=start_rec) btn_start_rec.grid(row=2, column=0) lb_Status = tk.Label(frm, text='Ready', anchor='w', fg='green') lb_Status.grid(row=2,column=1) btn_sure=tk.Button(frm,text="结束并识别",command=get_result) btn_sure.grid(row=3,column=0) root.mainloop()
2、音频录制部分,引入pyaudio库(需通过pip安装)来调用音频设备,录制接口要求的wav文件,并通过wave库存储文件:
def __init__(self, audio_path, language_type,is_recording):
self.audio_path = audio_path,
self.audio_file_name=''
self.language_type = language_type,
self.language=language_dict[language_type]
print(language_dict[language_type])
self.is_recording=is_recording
self.audio_chunk_size=1600
self.audio_channels=1
self.audio_format=pyaudio.paInt16
self.audio_rate=16000
def record_and_save(self):
self.is_recording = True
# self.audio_file_name=self.audio_path+'/recordtmp.wav'
self.audio_file_name='/recordtmp.wav'
threading.Thread(target=self.record,args=(self.audio_file_name,)).start()
def record(self,file_name):
print(file_name)
p=pyaudio.PyAudio()
stream=p.open(
format=self.audio_format,
channels=self.audio_channels,
rate=self.audio_rate,
input=True,
frames_per_buffer=self.audio_chunk_size
)
wf = wave.open(file_name, 'wb')
wf.setnchannels(self.audio_channels)
wf.setsampwidth(p.get_sample_size(self.audio_format))
wf.setframerate(self.audio_rate)
# 读取数据写入文件
while self.is_recording:
data = stream.read(self.audio_chunk_size)
wf.writeframes(data)
wf.close()
stream.stop_stream()
stream.close()
p.terminate()
3、翻译接口调用部分:
def recognise(filepath,language_type):
global file_path
file_path=filepath
nonce = str(uuid.uuid1())
curtime = str(int(time.time()))
signStr = app_key + nonce + curtime + app_secret
print(signStr)
sign = encrypt(signStr)
uri = "wss://openapi.youdao.com/stream_asropenapi?appKey=" + app_key + "&salt=" + nonce + "&curtime=" + curtime + \
"&sign=" + sign + "&version=v1&channel=1&format=wav&signType=v4&rate=16000&langType=" + language_type
print(uri)
start(uri, 1600)
def encrypt(signStr):
hash = hashlib.sha256()
hash.update(signStr.encode('utf-8'))
return hash.hexdigest()
def on_message(ws, message):
result=json.loads(message)
try:
resultmessage1 = result['result'][0]
resultmessage2 = resultmessage1["st"]['sentence']
print(resultmessage2)
except Exception as e:
print('')
def on_error(ws, error):
print(error)
def on_close(ws):
print("### closed ###")
def on_open(ws):
count = 0
file_object = open(file_path, 'rb')
while True:
chunk_data = file_object.read(1600)
ws.send(chunk_data, websocket.ABNF.OPCODE_BINARY)
time.sleep(0.05)
count = count + 1
if not chunk_data:
break
print(count)
ws.send('{\"end\": \"true\"}', websocket.ABNF.OPCODE_BINARY)
def start(uri,step):
websocket.enableTrace(True)
ws = websocket.WebSocketApp(uri,
on_message=on_message,
on_error=on_error,
on_close=on_close)
ws.on_open = on_open
ws.run_forever()
总结
有道智云提供的接口一如既往的好用,这次开发主要的精力全都浪费在了由于我自己录制的音频质量差而识别失败的问题上,音频质量ok后,识别结果准确无误,下一步就是拿去翻译了,有了有道智云API,实现实时翻译也可以如此简单!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号