根据堆栈日志定位内存泄漏
【问题描述】:服务后端是3节点集群,凌晨出现2节点磁盘打满告警并导致业务中断,定位发现是jvm堆栈日志hprof,该文件比较大(大概10G+)。恢复线上业务后,刚好另一节点磁盘没有满,并打出堆栈日志,可以用来定位此次故障原因。
工具:MemoryAnalyzer-1.8.1.20180910-win32.win32.x86_64
tomcat bin/setenv.sh配置堆栈日志:
export CATALINA_OPTS="$CATALINA_OPTS -XX:+HeapDumpOnOutOfMemoryError"
export CATALINA_OPTS="$CATALINA_OPTS -XX:HeapDumpPath=/opt/admin/logs/CloudNetmonitor-Computer"
【定位过程】:
第一步 从线上导出堆栈日志到本地分析
由于公司安全策略,线上与本地网络隔离,需要堡垒机传送文件并且限制大小,在linux服务器上需要拆分日志文件:
拆包: tar czf - sourcefile | split -b 90m - dest_split.
合并:cat dest_split.* >> dest.tar.gz
解包:tar zxvf dest.tar.gz
第二步 启动MAT工具
启动前配置MemoryAnalyzer文件,调大内存 -Xmx12g
MAT工具 File- Open Head Dump 导入hprof文件,大文件可能持续一段时间,导入后
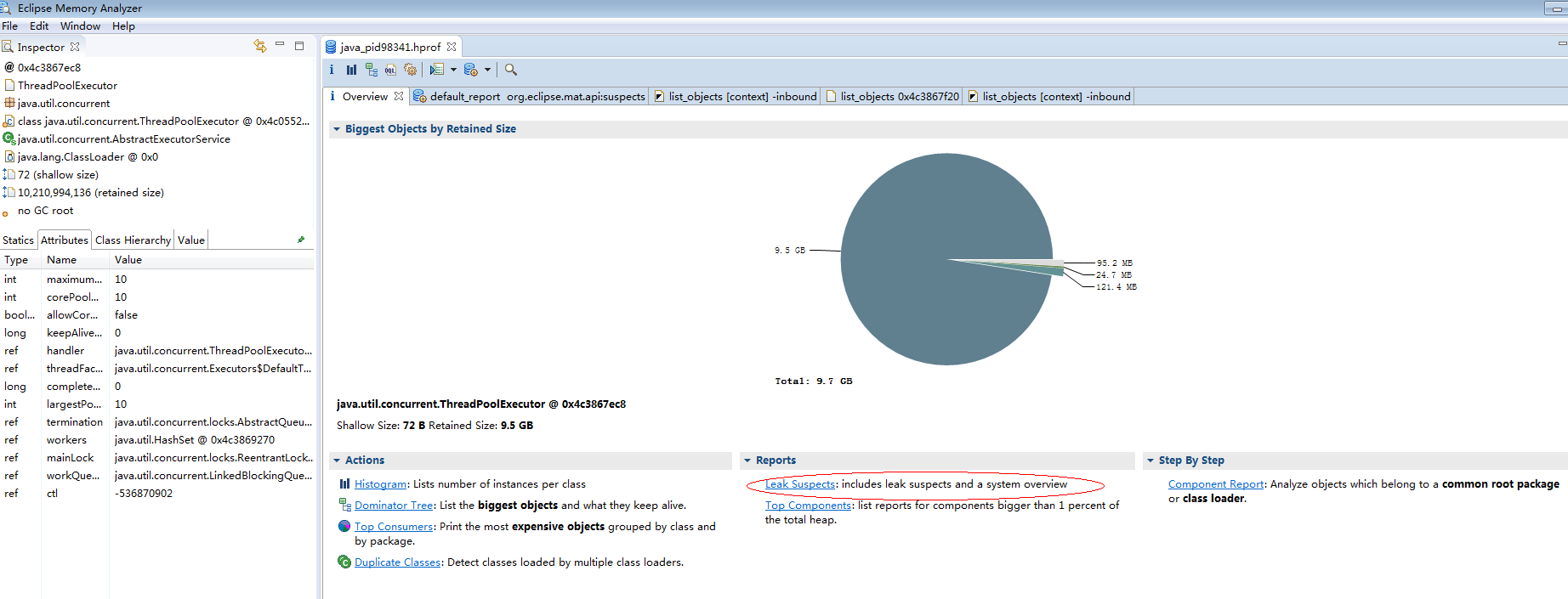
第三步 分析内存泄漏
首先根据 饼状图可以直观的发现,有内存泄漏9.7G,点击 leak suspecks 可以查看可疑泄漏位置,点击查看详细,可发现是RedisListenerPool这个类中定义的 固定线程池引用变量堆内存过大。

MAT工具提供的分析还是比较全面,查看“Accumulated Objects in Dominator Tree”,发现是线程池队列长度打满,而且该队列是个链表阻塞队列,转到对应代码位置

问题代码位置:
private ExecutorService fixedThreadPool = Executors.newFixedThreadPool(10);
查看固定线程池源码:

找到问题了,这里默认定义的是不指定容量大小的阻塞队列,意味着是无限大小。作为开发者,我们需要注意的是,如果构造一个LinkedBlockingQueue对象,而没有指定其容量大小,LinkedBlockingQueue会默认一个类似无限大小的容量(Integer.MAX_VALUE),这样的话,如果生产者的速度一旦大于消费者的速度,也许还没有等到队列满阻塞产生,系统内存就有可能已被消耗殆尽了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号