
Kubeadm安装Kubernetes高可用集群
一、首先配置k8s(master)主节点和node节点 修改/etc/hosts配置文件如下:
192.168.3.123 k8s-master1 192.168.3.124 k8s-master2 192.168.3.125 k8s-master3 192.168.3.128 k8s-vip #如果不是高可用集群,该IP为k8s-master1的IP地址 192.168.3.126 node-1 192.168.3.127 node-2
二、所有k8s-master节点和node节点安装yum源如下
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo sed -i -e '/mirrors.cloud.aliyuncs.com/d' -e '/mirrors.aliyuncs.com/d' /etc/yum.repos.d/CentOS-Base.repo yum clean all yum makecache yum -y install yum-utils device-mapper-persistent-data lvm2 wget psmisc net-tools telnet git yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF
yum 报错问题和解决问题如下
1、报错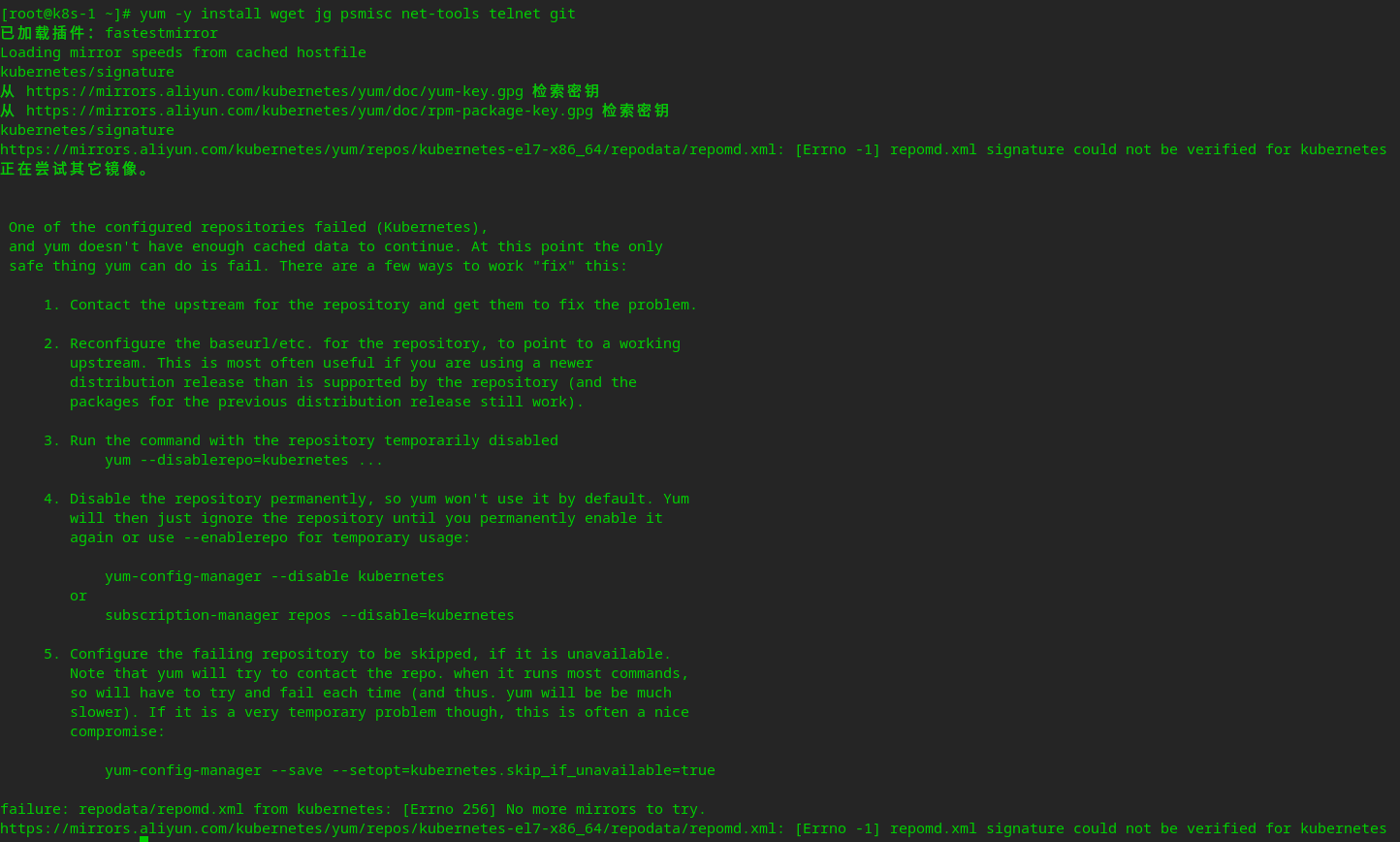
解决报错问题:
修改/etc/yum.repos.d/kubernetes.repo 里面的repo_gpgcheck=1 改为repo_gpgcheck=0
三、所有k8s-master节点和node节点关闭所有节点防火墙,selinux NetworkManager swap 服务配置
# 关闭防火墙 systemctl disable firewalld systemctl stop firewalld systemctl disable NetworkManager systemctl stop NetworkManager # 关闭selinux # 临时禁用selinux setenforce 0 # 永久关闭 修改/etc/sysconfig/selinux文件设置 sed -i 's/SELINUX=permissive/SELINUX=disabled/' /etc/sysconfig/selinux sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config # 禁用交换分区 swapoff -a # 永久禁用,打开/etc/fstab注释掉swap那一行。 sed -i 's/.*swap.*/#&/' /etc/fstab
四、所有节点配置limit
#临时生效 ulimit -SHn 65535 #永久生效 vim /etc/security/limits.conf * soft nofile 655360 * hard nofile 131072 * soft nproc 655350 * hard nproc 655350 * soft memlock unlimited * hard memlock unlimited
五、k8s-master1(主master-1)节点上面登陆其它节点,安装过程中生成配置文件和证书均在k8s-master1(主master-1)上操作,集群管理也在k8s-master1上操作。阿里云或其它云服务器上需要单独的一台kubectl服务器。密钥配置如下
ssh-keygen -t rsa for i in k8s-master1 k8s-master2 k8s-master3 node-1 node-2;do ssh-copy-id -i .ssh/id_rsa.pub $i;done
六、下载安装所有的源码文件
cd /root; git clone https://github.com/dotbalo/k8s-ha-install.git
七、所有节点升级系统并重启
yum update -y --exclude=kernel* && reboot
八、内核升级,本地升级内核版本为4.19
1、在k8s-master1节点下载内核
#下载到root目录下面 cd /root wget http://193.49.22.109/elrepo/kernel/el7/x86_64/RPMS/kernel-ml-devel-4.19.12-1.el7.elrepo.x86_64.rpm wget http://193.49.22.109/elrepo/kernel/el7/x86_64/RPMS/kernel-ml-4.19.12-1.el7.elrepo.x86_64.rpm
2、从k8s-master1节点传到其它节点/root目录下面
for i in k8s-master2 k8s-master3 node-1 node-2; do scp kernel-ml-devel-4.19.12-1.el7.elrepo.x86_64.rpm kernel-ml-4.19.12-1.el7.elrepo.x86_64.rpm $i:/root/; done
3、所有节点安装内核
cd /root && yum localinstall -y kernel-ml-*
4、所有节点更改内核启动顺序(注:保留原来内核防止升级内核升级不能启动可用修改为原来内核)
[root@k8s-master1 ~]# grub2-set-default 0 && grub2-mkconfig -o /etc/grub2.cfg Generating grub configuration file ... Found linux image: /boot/vmlinuz-4.19.12-1.el7.elrepo.x86_64 Found initrd image: /boot/initramfs-4.19.12-1.el7.elrepo.x86_64.img Found linux image: /boot/vmlinuz-3.10.0-1160.el7.x86_64 Found initrd image: /boot/initramfs-3.10.0-1160.el7.x86_64.img Found linux image: /boot/vmlinuz-0-rescue-159c5700b90c473598c0d0d88f656997 Found initrd image: /boot/initramfs-0-rescue-159c5700b90c473598c0d0d88f656997.img done [root@k8s-master1 ~]# grubby --args="user namespace.enable=1" --update-kernel="$(grubby --default-kernel)"
5、检查节点内核是不是4.19
[root@k8s-master1 ~]# grubby --default-kernel /boot/vmlinuz-4.19.12-1.el7.elrepo.x86_64
6、所有节点重启reboot,检查内核是不是4.19
[root@k8s-master1 ~]# uname -a Linux k8s-master1 4.19.12-1.el7.elrepo.x86_64 #1 SMP Fri Dec 21 11:06:36 EST 2018 x86_64 x86_64 x86_64 GNU/Linux
九、所有节点安装ipvsadm
1、安装ipvsadm
yum -y install ipvsadm ipset sysstat conntrack libseccomp
2、所有节点配置ipvs模块,内核4.19+版本nf_conntrack_ipv4 已经 改为nf_conntrack。4.18以下的版本内核使用nf_conntrack_ipv4 即可
[root@k8s-master1 ~]# vim /etc/modules-load.d/ipvs.conf ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_fo ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack ip_tables ip_set xt_set ipt_set ipt_rpfilter ipt_REJECT ipip
1)然后执行systemctl enable --now systemd-modules-load.service 命令即可。检查是否加载(注:需要重启系统才会生效)
3、开启k8s集群中内核参数,所有节点配置k8s内核(注:需要重启系统reboot)
cat <<EOF > /etc/sysctl.d/k8s.conf vm.panic_on_oom=0 vm.overcommit_memory=1 fs.file-max=52706963 fs.nr_open=52706963 fs.may_detach_mounts = 1 fs.inotify.max_user_watches=89100 net.ipv4.ip_forward = 1 net.ipv4.ip_conntrack_max = 65536 net.ipv4.tcp_keepalive_time = 600 net.ipv4.tcp_keepalive_probes = 3 net.ipv4.tcp_keepalive_intvl =15 net.ipv4.tcp_max_tw_buckets = 36000 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_max_orphans = 327680 net.ipv4.tcp_orphan_retries = 3 net.ipv4.tcp_syncookies = 1 net.ipv4.tcp_max_syn_backlog = 16384 net.ipv4.tcp_max_syn_backlog = 16384 net.ipv4.tcp_timestamps = 0 net.ipv4.conf.all.route_localnet = 1 net.bridge.bridge-nf-call-iptables = 1 net.bridge.bridge-nf-call-ip6tables = 1 net.core.somaxconn = 16384 net.netfilter.nf_conntrack_max=2310720 EOF
4、所有节点配置后,重启服务器,保证重启后内核依据加载
[root@k8s-master1 ~]# lsmod |grep --color=auto -e ip_vs -e nf_conntrack ip_vs_ftp 16384 0 nf_nat 32768 1 ip_vs_ftp ip_vs_sed 16384 0 ip_vs_nq 16384 0 ip_vs_fo 16384 0 ip_vs_sh 16384 0 ip_vs_dh 16384 0 ip_vs_lblcr 16384 0 ip_vs_lblc 16384 0 ip_vs_wrr 16384 0 ip_vs_rr 16384 0 ip_vs_wlc 16384 0 ip_vs_lc 16384 0 ip_vs 151552 24 ip_vs_wlc,ip_vs_rr,ip_vs_dh,ip_vs_lblcr,ip_vs_sh,ip_vs_fo,ip_vs_nq,ip_vs_lblc,ip_vs_wrr,ip_vs_lc,ip_vs_sed,ip_vs_ftp nf_conntrack 143360 2 nf_nat,ip_vs nf_defrag_ipv6 20480 1 nf_conntrack nf_defrag_ipv4 16384 1 nf_conntrack libcrc32c 16384 4 nf_conntrack,nf_nat,xfs,ip_vs
5、相关内核一些参数说明
net.ipv4.ip_forward=1 # 其值为0,说明禁止进行IP转发;如果是1,则说明IP转发功能已经打开。 net.ipv4.tcp_keepalive_time=600 #此参数表示TCP发送keepalive探测消息的间隔时间(秒) net.ipv4.tcp_keepalive_probes=3 #tcp检查次数(如果对方不予应答,探测包的发送次数) net.ipv4.tcp_keepalive_intvl=15 #tcp检查间隔时间(keepalive探测包的发送间隔) net.ipv4.tcp_max_tw_buckets=36000 #配置服务器 TIME_WAIT 数量 net.ipv4.tcp_tw_reuse = 1 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭; net.ipv4.tcp_max_orphans=327680 net.ipv4.tcp_orphans_retries=3 net.ipv4.tcp_syncookies=1 #此参数应该设置为1,防止SYN Flood net.ipv4.tcp_max_syn_backlog = 16384 # 第一个积压队列长度 net.ipv4.tcp_timestamps=0 net.ipv4.ip_conntrack_max=65536 net.core.somaxconn = 32768 # 第二个积压队列长度 net.netfilter.nf_conntrack_max=2310720 #连接跟踪表的大小,建议根据内存计算该值CONNTRACK_MAX = RAMSIZE (in bytes) / 16384 / (x / 32),并满足nf_conntrack_max=4*nf_conntrack_buckets,默认262144 net.bridge.bridge-nf-call-iptables=1 # 二层的网桥在转发包时也会被iptables的FORWARD规则所过滤,这样有时会出现L3层的iptables rules去过滤L2的帧的问题 net.bridge.bridge-nf-call-ip6tables=1 # 是否在ip6tables链中过滤IPv6包 vm.overcommit_memory=1 # 不检查物理内存是否够用 vm.panic_on_oom=0 # 开启 OOM fs.may.detach_mounts=1 fs.file-max=52706963 # 文件描述符的最大值 fs.nr_open=52706963 #设置最大微博号打开数 fs.inotify.max_user_watches=524288 # 同一用户同时可以添加的watch数目,默认8192。
十、docker安装
1、所有节点安装docker-ce-19.03
yum install -y docker-ce-19.03.*
2、注:由于新版kubelet建议使用systemd,所以可以把docker的CgroupDriver改成systemd
mkdir /etc/docker
cat > /etc/docker/daemon.json << EOF
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF
3、所有节点设置开机自动启动docker
#启动docker [root@k8s-master1 ~]# systemctl start docker #设置开机启动 [root@k8s-master1 ~]# systemctl enable docker Created symlink from /etc/systemd/system/multi-user.target.wants/docker.service to /usr/lib/systemd/system/docker.service. #查看docker启动信息版本 [root@k8s-master1 ~]# docker info Client: Context: default Debug Mode: false Plugins: app: Docker App (Docker Inc., v0.9.1-beta3) buildx: Docker Buildx (Docker Inc., v0.8.2-docker) scan: Docker Scan (Docker Inc., v0.17.0) Server: Containers: 0 Running: 0 Paused: 0 Stopped: 0 Images: 0 Server Version: 19.03.15 Storage Driver: overlay2 Backing Filesystem: xfs Supports d_type: true Native Overlay Diff: true Logging Driver: json-file Cgroup Driver: systemd .....等.......
注:查看docker信息的时候注意不要有警告信息
十一、安装Kubernetes(K8s)
1、查看k8s版本
[root@k8s-master1 ~]# yum list kubeadm.x86_64 --showduplicates | sort -r
2、所有节点安装k8s组件
#直接安装kubeadm会安装最新的版本 yum install -y kubeadm #对安装 kubeadm,kubectl,kubelet 指定1.20.6版本安装 yum install -y kubeadm-1.20.6-0.x86_64 kubectl-1.20.6-0.x86_64 kubelet-1.20.6-0.x86_64
3、所有节点配置。默认使用pause镜像使用gcr.io仓库,国内可能无法访问,所以这里配置Kubelet使用阿里云的pause镜像
cat > /etc/sysconfig/kubelet<<EOF KUBELET_EXTRA_ARGS="--cgroup-driver=systemd --pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.2" EOF
4、设置Kubelet开机自动启动
[root@k8s-master1 ~]# systemctl daemon-reload [root@k8s-master1 ~]# systemctl enable --now kubelet Created symlink from /etc/systemd/system/multi-user.target.wants/kubelet.service to /usr/lib/systemd/system/kubelet.service.
十二、高可用组件安装(注:如果不是高可用集群,haproxy和keepalived无需安装)
1、所有k8s-master主节点(主节点:k8s-master1,k8s-master2,k8s-master3)通过yum安装HAProxy和KeepAlived
yum install -y keepalived haproxy
2、所有k8s-master主节点(主节点:k8s-master1,k8s-master2,k8s-master3)节点配置HAProxy(详细配置参考HAProxy文档,所有k8s主节点的HAProxy配置相同)
[root@k8s-master1 ~]# vim /etc/haproxy/haproxy.cfg
global
maxconn 2000
ulimit-n 16384
log 127.0.0.1 local0 err
stats timeout 30s
defaults
mode http
log global
option httplog
timeout connect 5000
timeout client 50000
timeout server 50000
timeout http-request 15s
timeout http-keep-alive 15s
frontend monitor-in
bind *:33305
mode http
option httplog
monitor-uri /monitor
frontend k8s-master
bind 0.0.0.0:16443
bind 127.0.0.1:16443
mode tcp
option tcplog
tcp-request inspect-delay 5s
default_backend k8s-master
backend k8s-master
mode tcp
option tcplog
option tcp-check
balance roundrobin
default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100
server k8s-master1 192.168.3.123:6443 check
server k8s-master2 192.168.3.124:6443 check
server k8s-master3 192.168.3.125:6443 check
3、所有k8s主节点配置KeepAlived,配置文件不一样,注意区分每个k8s-master节点的IP地址和网卡(interface)
1)k8s-master1主节点配置文件(MASTER)
[root@k8s-master1 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
script_user root
enable_script_security
}
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 5
weight -5
fall 2
rise 1
}
vrrp_instance VI_1 {
state MASTER
interface ens33
mcast_src_ip 192.168.3.123
virtual_router_id 51
priority 100
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
192.168.3.128
}
track_script {
chk_apiserver
}
}
2)k8s-master2节点配置文件(BACKUP)
[root@k8s-master2 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
script_user root
enable_script_security
}
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 5
weight -5
fall 2
rise 1
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
mcast_src_ip 192.168.3.124
virtual_router_id 51
priority 99
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
192.168.3.128
}
track_script {
chk_apiserver
}
}
3)k8s-master3节点配置文件(BACKUP)
[root@k8s-master3 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
script_user root
enable_script_security
}
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 5
weight -5
fall 2
rise 1
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
mcast_src_ip 192.168.3.125
virtual_router_id 51
priority 99
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
192.168.3.128
}
track_script {
chk_apiserver
}
}
注:
- vrrp_script chk_apiserver {script "/etc/keepalived/check_apiserver.sh"} 这里是指定健康检测脚本路径
- mcast_src_ip 192.168.3.123 这里 192.168.3.125 IP地址指的是本机IP地址
- priority 100 这里指的是运行优先级(数字越大优先级越高)
- virtual_ipaddress {192.168.3.128} 这里指的是vip地址(192.168.3.128)
4)所k8s-master节点配置KeepAlived健康检查脚本
[root@k8s-master1 ~]# vim /etc/keepalived/check_apiserver.sh
#!/bin/bash
#检测haproxy状态3次失败,关闭keepalived跳转到其它keepalived节点上面
err=0
for k in $(seq 1 3)
do
check_code=$(pgrep haproxy)
if [[ $check_code == "" ]]; then
err=$(expr $err + 1)
sleep 1
continue
else
err=0
break
fi
done
if [[ $err != "0" ]]; then
echo "systemctl stop keepalived"
/usr/bin/systemctl stop keepalived
exit 1
else
exit 0
fi
注:
1、通过KeepAlived虚拟出一个vip。vip会配置到k8s-master1节点上面(为虚拟主master)
2、健康检测会通过$(pgrep haproxy)检测haproxy端口。反带到haproxy配置文件设置bind 0.0.0.0:16443再反带到backend k8s-master1下面设置 三个server节点上面
5)启动haproxy和keepalived
[root@k8s-master1 ~]# systemctl daemon-reload [root@k8s-master1 ~]# systemctl enable --now haproxy [root@k8s-master1 ~]# systemctl enable --now keepalived
检查haproxy和keepalived是否启动正常
#检查Haproxy
[root@k8s-master1 ~]# systemctl status haproxy
● haproxy.service - HAProxy Load Balancer
Loaded: loaded (/usr/lib/systemd/system/haproxy.service; enabled; vendor preset: disabled)
Active: active (running) since 二 2022-08-23 20:01:33 CST; 59min ago
Main PID: 5802 (haproxy-systemd)
Tasks: 3
Memory: 2.6M
CGroup: /system.slice/haproxy.service
├─5802 /usr/sbin/haproxy-systemd-wrapper -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid
├─5803 /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -Ds
└─5804 /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -Ds
#检查KeepAlived
[root@k8s-master1 ~]# systemctl status keepalived
● keepalived.service - LVS and VRRP High Availability Monitor
Loaded: loaded (/usr/lib/systemd/system/keepalived.service; enabled; vendor preset: disabled)
Active: active (running) since 二 2022-08-23 19:14:00 CST; 1h 48min ago
Process: 3647 ExecStart=/usr/sbin/keepalived $KEEPALIVED_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 3648 (keepalived)
Tasks: 3
Memory: 7.0M
CGroup: /system.slice/keepalived.service
├─3648 /usr/sbin/keepalived -D
├─3649 /usr/sbin/keepalived -D
└─3650 /usr/sbin/keepalived -D
8月 23 19:14:04 k8s-master1 Keepalived_vrrp[3650]: Sending gratuitous ARP on ens33 for 192.168.3.128
8月 23 19:14:04 k8s-master1 Keepalived_vrrp[3650]: Sending gratuitous ARP on ens33 for 192.168.3.128
检查vip IP:192.168.3.128是否正常,出现以下情况说明VIP IP地址正常
#用ping检查vip地址 [root@k8s-master1 ~]# ping 192.168.3.128 PING 192.168.3.128 (192.168.3.128) 56(84) bytes of data. 64 bytes from 192.168.3.128: icmp_seq=1 ttl=64 time=0.102 ms 64 bytes from 192.168.3.128: icmp_seq=2 ttl=64 time=0.079 ms 64 bytes from 192.168.3.128: icmp_seq=3 ttl=64 time=0.057 ms 64 bytes from 192.168.3.128: icmp_seq=4 ttl=64 time=0.298 ms #通过telnet 检查16443端口vip IP地址 [root@k8s-master1 ~]# telnet 192.168.3.128 16443 Trying 192.168.3.128... Connected to 192.168.3.128. Escape character is '^]'. Connection closed by foreign host.
注:
1、如果ping vip IP地址不通,且telnet不通,则认为VIP不可以,不可在继续往下执行,需要排查keepalived的问题,比如防火墙selinux , haproxy和keepalived的状态,监
听端口等。所有节点查看防火墙状态必须是disable和inactive; systemctl stauts firewalld所有节点查看selinux状态,必须为disable; getenforce
master 节点查看haproxy和keepalived状态:systemctl status keepalived/haproxy。master节点查看监听端口netstat -lntp是否正常开启
十三、集群初始化
1、生成 kubeadm 配置文件:
kubeadm config print init-defaults > kubeadm-config.yaml
2、对生成的 kubeadm-config.yaml配置文件修改,所有节点配置 kubeadm-config.yaml。所有节点修改后如下:
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.3.123
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: k8s-master1
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
certSANs:
- 192.168.3.128
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: 192.168.3.128:16443
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.20.6
networking:
dnsDomain: cluster.local
podSubnet: 172.100.0.0/12
serviceSubnet: 10.96.0.0/12
scheduler: {}
注:
- 1、advertiseAddress: 192.168.3.123 绑定的是k8s-master1主节点IP地址
- 192.168.3.128 绑定的是vip IP地址
- controlPlaneEndpoint: 192.168.3.128:16443 这里指定的是VIP地址:haproxy端口
- imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers 指定阿里云下载镜像
- kubernetesVersion: v1.20.6 指的是kubernetes安装运行的版本号
-
如果不是高可用集群,192.168.3.128:16443改为k8s-master1的地址,16443改为apiserver的端口,默认是6443,注意更改v1.20.6为自己服务器kubeadm的版本:kubeadm version
3、更新kubeadm文件转换成最新的(注:这里是把上面创建的kubeadm-config.yaml文件转换成新的new.yaml。如果kubeadm-config.yaml是最新的不需要执行下面的命令)
kubeadm config migrate --old-config kubeadm-config.yaml --new-config new.yaml
注:
- 转换为new.yaml后在下载镜像的时候,需要将new.yaml文件复制到其它k8s(master)节点之后在下载镜像。new.yaml下载镜像如下
kubeadm config images pull --config /root/new.yaml
- kubeadm-config.yaml配置文件位转换更新下载镜像命令如下:
kubeadm config images pull --config /root/kubeadm-config.yaml
4、所有节点设置开机自动启动kubeadm(注:如果上面设置kubelet开机自动启动,这里不需要在设置)
systemctl enable --now kubelet
注:如果启动失败无需管理,初始化成功以后即可启动
5、k8s-master1(master)节点初始化,初始化以后会在/etc/kubernetes目录下生产对应证书和配置文件,之后其它k8s(master)节点加入k8s-master1节点即可
kubeadm init --config /root/kubeadm-config.yaml --upload-certs
注:
- 初始化成功以后,会产生Token值,用于其它节点加入使用,因此要记录下初始化成功生成的token值(令牌值)。Token记录
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 192.168.3.128:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:e9b6b8bbe90be69f0176623ccb1ed77c06efeea1caa7e3da97d341776d6bc189 \
--control-plane --certificate-key 49ecba55a13c8386a3d4446ed6a0c2187dcd8c63a9cc94214bc858cfce64966f
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.3.128:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:e9b6b8bbe90be69f0176623ccb1ed77c06efeea1caa7e3da97d341776d6bc189
6、如果初始化失败,重置后再次初始化,命令如下:
kubeadm reset -f ; ipvsadm --clear ; rm -fr ~/.kube
7、k8s-master1节点配置环境变量,用于访问Kubernetes集群
cat <<EOF >> /root/.bashrc export KUBECONFIG=/etc/kubernetes/admin.conf EOF source /root/.bashrc
注:/etc/kubernetes/admin.conf 文件用于集群通信
8、查看集群是否创建成功
[root@k8s-master1 ~]# kubectl get node NAME STATUS ROLES AGE VERSION k8s-master1 NotReady control-plane,master 7m11s v1.20.6 [root@k8s-master1 ~]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 7m25s #查看集群状态 [root@k8s-master1 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master1 NotReady control-plane,master 11m v1.20.6
10、采用初始化安装方式,所有的系统组件均以容器的方式运行并且在kube-system命令空间内,此时可以查看Pod状态
[root@k8s-master1 ~]# kubectl get pods -n kube-system -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES coredns-54d67798b7-6z2hl 0/1 Pending 0 7m44s <none> <none> <none> <none> coredns-54d67798b7-gwdsn 0/1 Pending 0 7m44s <none> <none> <none> <none> etcd-k8s-master1 1/1 Running 0 8m2s 192.168.3.123 k8s-master1 <none> <none> kube-apiserver-k8s-master1 1/1 Running 0 8m2s 192.168.3.123 k8s-master1 <none> <none> kube-controller-manager-k8s-master1 1/1 Running 0 8m2s 192.168.3.123 k8s-master1 <none> <none> kube-proxy-psfdp 1/1 Running 0 7m44s 192.168.3.123 k8s-master1 <none> <none> kube-scheduler-k8s-master1 1/1 Running 0 8m2s 192.168.3.123 k8s-master1 <none> <none>
注:系统组件都是在/etc/kubernetes/manifests/文件下面
11、k8s-master1初始化完成后对,把k8s-master2,k8s-master3, node-1,node-2节点加入k8s-mster1里面,需要使用的命令是初始化后记录的数据中一段命令。
- 首先把k8s-master2,k8s-master3加入k8s-master1里面命令如下(在k8s-mster1,k8s-master2上面运行):
kubeadm join 192.168.3.128:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:e9b6b8bbe90be69f0176623ccb1ed77c06efeea1caa7e3da97d341776d6bc189 \
--control-plane --certificate-key 49ecba55a13c8386a3d4446ed6a0c2187dcd8c63a9cc94214bc858cfce64966f
注:初始化生成的时候每条命令不一样,需以自己生成的为准进行操作
- node-1,node-2节点加入k8s-master1里面,在node节点上面运行如下相关命令:
kubeadm join 192.168.3.128:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:e9b6b8bbe90be69f0176623ccb1ed77c06efeea1caa7e3da97d341776d6bc189 \
注:node-1,node-2节点加入时没有--control-plane --certificate-key 这段参数值,只需按照上面把kubeadm jion ...等... --token ...等... --discovery-token-ca-cert-hash这段在node节点上输入运行
- 查看节点插入后命令
[root@k8s-master1 ~]# kubectl get node NAME STATUS ROLES AGE VERSION k8s-master1 NotReady control-plane,master 20m35s v1.20.6 k8s-master2 NotReady control-plane,master 15m10s v1.20.6 k8s-master3 NotReady control-plane,master 10m20s v1.20.6 node-1 NotReady <none> 7m11s v1.20.6 node-2 NotReady <none> 7m45s v1.20.6
12、Token过期后生成新的Token,在k8s-master1主节点上执行一些命令
kubeadm token create --print-join-command
k8s节点需要生成 --certificate-key
kubeadm init phase upload-certs --upload-certs
把生成新的token和--certificate-key替换一起保存的相关信息,重新执行即可

十四、Calico安装
1、以下步骤只在k8s-master1执行
cd /root; git clone https://github.com/dotbalo/k8s-ha-install.git cd k8s-ha-install git checkout manual-installation-v1.20.x
2、修改calico-etcd.yaml配置文件
- 修改etcd的节点
cd /root/k8s-ha-install/calico/ sed -i 's#etcd_endpoints: "http://<ETCD_IP>:<ETCD_PORT>"#etcd_endpoints: "https://192.168.3.123:2379,https://192.168.3.124:2379,https://192.168.3.125:2379"#g' calico-etcd.yaml
- 证书解析加密添加到配置文件中
ETCD_CA=`cat /etc/kubernetes/pki/etcd/ca.crt | base64 | tr -d '\n'`
ETCD_CERT=`cat /etc/kubernetes/pki/etcd/server.crt | base64 | tr -d '\n'`
ETCD_KEY=`cat /etc/kubernetes/pki/etcd/server.key | base64 | tr -d '\n'`
sed -i "s@# etcd-key: null@etcd-key: ${ETCD_KEY}@g; s@# etcd-cert: null@etcd-cert: ${ETCD_CERT}@g; s@# etcd-ca: null@etcd-ca: ${ETCD_CA}@g" calico-etcd.yaml
- 把 etcd_key 放到 secret 里面,secret 会挂载到 calico 容器的 pod 里面,挂载的名称就是 ETCD_CA,这样 calico 就能找到证书,就可以连接到 etcd,就可以把 pod 信息存储到 etcd 里面
sed -i 's#etcd_ca: ""#etcd_ca: "/calico-secrets/etcd-ca"#g; s#etcd_cert: ""#etcd_cert: "/calico-secrets/etcd-cert"#g; s#etcd_key: "" #etcd_key: "/calico-secrets/etcd-key" #g' calico-etcd.yaml
- 修改 pod 网段
POD_SUBNET=`cat /etc/kubernetes/manifests/kube-controller-manager.yaml | grep cluster-cidr= | awk -F= '{print $NF}'`
sed -i 's@# - name: CALICO_IPV4POOL_CIDR@- name: CALICO_IPV4POOL_CIDR@g; s@# value: "192.168.0.0/16"@ value: '"${POD_SUBNET}"'@g' calico-etcd.yaml
注:
这个步骤是把calico-etcd.yaml文件里面的CALICO_IPV4POOL_CIDR下的网段改成自己的Pod网段,也就是把192.168.x.x/16改成自己的集群网段。
并打开注释,所以更改的时候请确保这个步骤的这个网段没有被统一替换掉,如果被替换掉了,还请改回来
3、创建calico
cd /root/k8s-ha-install/calico/ kubectl apply -f calico-etcd.yaml
4、查看容器是否启动完成
[root@k8s-master1 dashboard]# kubectl get po -A NAMESPACE NAME READY STATUS RESTARTS AGE kube-system calico-kube-controllers-5f6d4b864b-cwk6p 1/1 Running 1 18m kube-system calico-node-2j75v 1/1 Running 2 18m kube-system calico-node-66vdj 1/1 Running 0 18m kube-system calico-node-j9scc 1/1 Running 1 18m kube-system calico-node-tkjdj 1/1 Running 0 18m kube-system calico-node-v9v7x 1/1 Running 0 18m kube-system coredns-54d67798b7-wtlfb 1/1 Running 0 31m kube-system coredns-54d67798b7-zzn5g 1/1 Running 0 31m kube-system etcd-k8s-master1 1/1 Running 0 31m kube-system etcd-k8s-master2 1/1 Running 0 28m kube-system etcd-k8s-master3 1/1 Running 0 27m kube-system kube-apiserver-k8s-master1 1/1 Running 0 31m kube-system kube-apiserver-k8s-master2 1/1 Running 0 28m kube-system kube-apiserver-k8s-master3 1/1 Running 0 27m kube-system kube-controller-manager-k8s-master1 1/1 Running 2 31m kube-system kube-controller-manager-k8s-master2 1/1 Running 0 28m kube-system kube-controller-manager-k8s-master3 1/1 Running 1 27m kube-system kube-proxy-6w5z6 1/1 Running 0 31m kube-system kube-proxy-9dnxj 1/1 Running 0 24m kube-system kube-proxy-dhdcj 1/1 Running 0 25m kube-system kube-proxy-q28hc 1/1 Running 0 28m kube-system kube-proxy-q67fk 1/1 Running 0 27m kube-system kube-scheduler-k8s-master1 1/1 Running 2 31m kube-system kube-scheduler-k8s-master2 1/1 Running 0 28m kube-system kube-scheduler-k8s-master3 1/1 Running 0 27m kube-system metrics-server-545b8b99c6-mgfjr 1/1 Running 0 14m kubernetes-dashboard dashboard-metrics-scraper-7645f69d8c-mxwq2 1/1 Running 0 13m kubernetes-dashboard kubernetes-dashboard-78cb679857-qvvwx 1/1 Running 0 13m
十五、Metrics Server部署
说明:在Kubernetes中系统资源的采集均使用Metrics-server,可以通过Metrics采集节点和Pod的内存、磁盘、CPU和网络的使用率。
1、将k8s-master1节点的front-proxy-ca.crt复制到所有Node节点
[root@k8s-master1 calico]# scp /etc/kubernetes/pki/front-proxy-ca.crt node-1:/etc/kubernetes/pki/front-proxy-ca.crt [root@k8s-master1 calico]# scp /etc/kubernetes/pki/front-proxy-ca.crt node-2:/etc/kubernetes/pki/front-proxy-ca.crt
2、关于配置文件修改(注:证书和镜像地址配置文件已经做好了修改可以直接使用。如果这两项在运行中失效再进行修改)
- 添加证书,不然可能导致获取不到度量指标
- --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem # change to front-proxy-ca.crt for kubeadm
- 修改了镜像地址为阿里云
image: registry.cn-beijing.aliyuncs.com/dotbalo/metrics-server:v0.4.1
3、安装metrics server
cd /root/k8s-ha-install/metrics-server-0.4.x-kubeadm/ [root@k8s-master1 metrics-server-0.4.x-kubeadm]# kubectl create -f comp.yaml serviceaccount/metrics-server created clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created clusterrole.rbac.authorization.k8s.io/system:metrics-server created rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created service/metrics-server created deployment.apps/metrics-server created apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
4、等待kube-system命令空间下的Pod全部启动后,查看状态
[root@k8s-master1 metrics-server-0.4.x-kubeadm]# kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% k8s-master1 495m 24% 1184Mi 63% k8s-master2 434m 21% 1120Mi 59% k8s-master3 467m 23% 1220Mi 65% node-1 246m 12% 784Mi 41% node-2 212m 10% 712Mi 38%
十六、Dashboard部署
查看配置文件修改镜像地址(下载的dashboard配置文件已经把镜像地址修改为了下方地址。这里可以不对dashboard配置文件做任何修改直接使用即可,如果镜像地址不能连接在进行修改)
image: registry.cn-beijing.aliyuncs.com/dotbalo/dashboard:v2.0.4 imagePullPolicy: Always image: registry.cn-beijing.aliyuncs.com/dotbalo/metrics-scraper:v1.0.4
1、安装
cd /root/k8s-ha-install/dashboard/ [root@k8s-master1 dashboard]# kubectl create -f . serviceaccount/admin-user created clusterrolebinding.rbac.authorization.k8s.io/admin-user created namespace/kubernetes-dashboard created serviceaccount/kubernetes-dashboard created service/kubernetes-dashboard created secret/kubernetes-dashboard-certs created secret/kubernetes-dashboard-csrf created secret/kubernetes-dashboard-key-holder created configmap/kubernetes-dashboard-settings created role.rbac.authorization.k8s.io/kubernetes-dashboard created clusterrole.rbac.authorization.k8s.io/kubernetes-dashboard created rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created deployment.apps/kubernetes-dashboard created service/dashboard-metrics-scraper created deployment.apps/dashboard-metrics-scraper created
2、更改dashboard的svc为NodePort:
kubectl edit svc kubernetes-dashboard -n kubernetes-dashboard
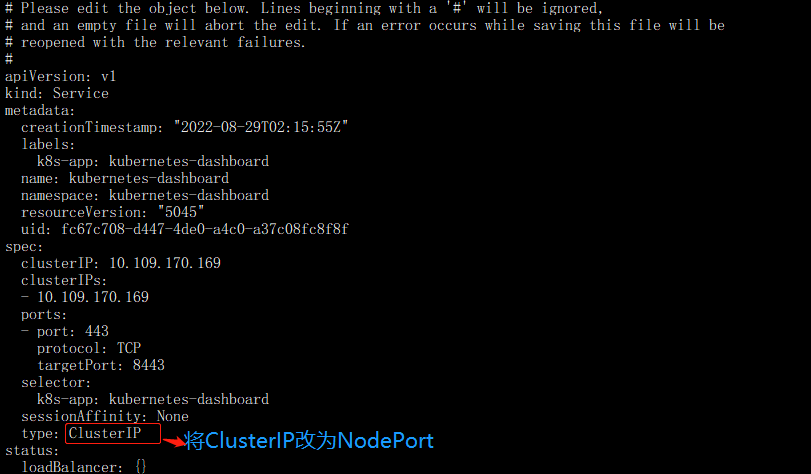
注:将ClusterIP更改为NodePort(如果已经为NodePort忽略此步骤)
3、查看端口号
[root@k8s-master1 dashboard]# kubectl get svc kubernetes-dashboard -n kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes-dashboard NodePort 10.97.80.76 <none> 443:31191/TCP 12m
注:端口31191是随机创建
4、查看容器是否启动完成
[root@k8s-master1 dashboard]# kubectl get po -A NAMESPACE NAME READY STATUS RESTARTS AGE kube-system calico-kube-controllers-5f6d4b864b-cwk6p 1/1 Running 1 18m kube-system calico-node-2j75v 1/1 Running 2 18m kube-system calico-node-66vdj 1/1 Running 0 18m kube-system calico-node-j9scc 1/1 Running 1 18m kube-system calico-node-tkjdj 1/1 Running 0 18m kube-system calico-node-v9v7x 1/1 Running 0 18m kube-system coredns-54d67798b7-wtlfb 1/1 Running 0 31m kube-system coredns-54d67798b7-zzn5g 1/1 Running 0 31m kube-system etcd-k8s-master1 1/1 Running 0 31m kube-system etcd-k8s-master2 1/1 Running 0 28m kube-system etcd-k8s-master3 1/1 Running 0 27m kube-system kube-apiserver-k8s-master1 1/1 Running 0 31m kube-system kube-apiserver-k8s-master2 1/1 Running 0 28m kube-system kube-apiserver-k8s-master3 1/1 Running 0 27m kube-system kube-controller-manager-k8s-master1 1/1 Running 2 31m kube-system kube-controller-manager-k8s-master2 1/1 Running 0 28m kube-system kube-controller-manager-k8s-master3 1/1 Running 1 27m kube-system kube-proxy-6w5z6 1/1 Running 0 31m kube-system kube-proxy-9dnxj 1/1 Running 0 24m kube-system kube-proxy-dhdcj 1/1 Running 0 25m kube-system kube-proxy-q28hc 1/1 Running 0 28m kube-system kube-proxy-q67fk 1/1 Running 0 27m kube-system kube-scheduler-k8s-master1 1/1 Running 2 31m kube-system kube-scheduler-k8s-master2 1/1 Running 0 28m kube-system kube-scheduler-k8s-master3 1/1 Running 0 27m kube-system metrics-server-545b8b99c6-mgfjr 1/1 Running 0 14m kubernetes-dashboard dashboard-metrics-scraper-7645f69d8c-mxwq2 1/1 Running 0 13m kubernetes-dashboard kubernetes-dashboard-78cb679857-qvvwx 1/1 Running 0 13m
注:
根据自己的实例端口号,通过任意安装了kube-proxy的宿主机或者VIP的IP+端口即可访问到dashboard:
访问Dashboard:https://192.168.3.123:31191(请更改31191为自己的端口),选择登录方式为令牌(即token方式)
也可以通过宿主机的ip访问:https://192.168.3.128:31191
5、查看token值,登录dashboard
[root@k8s-master1 dashboard]# kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}')
Name: admin-user-token-c9ct2
Namespace: kube-system
Labels: <none>
Annotations: kubernetes.io/service-account.name: admin-user
kubernetes.io/service-account.uid: bf5ba786-6bbe-437f-b35f-61279becd61d
Type: kubernetes.io/service-account-token
Data
====
namespace: 11 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IkR1LU03eDRiYWNad2dMaWUyUkE4dmloNy1kRWdmMjdNREpmdVR2aG8wU0EifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOi
JrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLWM5Y3QyIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm
5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiJiZjViYTc4Ni02YmJlLTQzN2YtYjM1Zi02MTI3OWJlY2Q2MWQiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZS1zeXN0ZW06YWRtaW4tdXNlciJ9.pRqv35ab291R0nEkbwKFF
WWfawJ6B-eXpF_3SgNI1-1DC9YwWV7PJ32jprwEKQlp7EoHj6Z39xRV5JnyodyeiEYPzLUupUX_B9irt8XoiaGUl2plMpgog-EXQr5qJiRE7D8dKyvjS84vvAHDjjEyq6Nl4-N4qxBv0OphVKwCZ7YMhxsi3uEqjwZ0Pzw-unkKl036dGtmy9XuX4vcOLBtO9Ruib_G0OCwV
VNqksDidJi4Twzj9LOXxil7G4R2X88Qm7AEy1SpOnonXum9SUYGpCAFmvpcYVYHrgpB0nl-zUAyD2u7ZiYxNVe79edy-yhLp0dokEIKad7H6ztkKiWcLQ
ca.crt: 1066 bytes
注:token:后面是查看到的token值,在登录dashboard的时候输入使用
访问dashboard输入图下
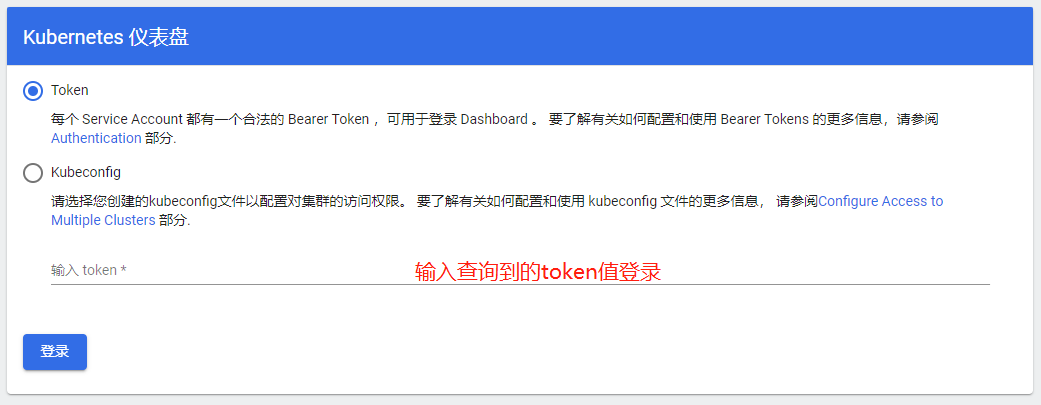
登录界面为kube-system
十七、一些必须修改的配置更改(再k8s-master1节点执行)
1、再k8s-master1节点执行。将Kube-proxy改为ipvs模式,因为在初始化集群的时候注释了ipvs配置,所以需要自行修改一下命令如下:
kubectl edit cm kube-proxy -n kube-system
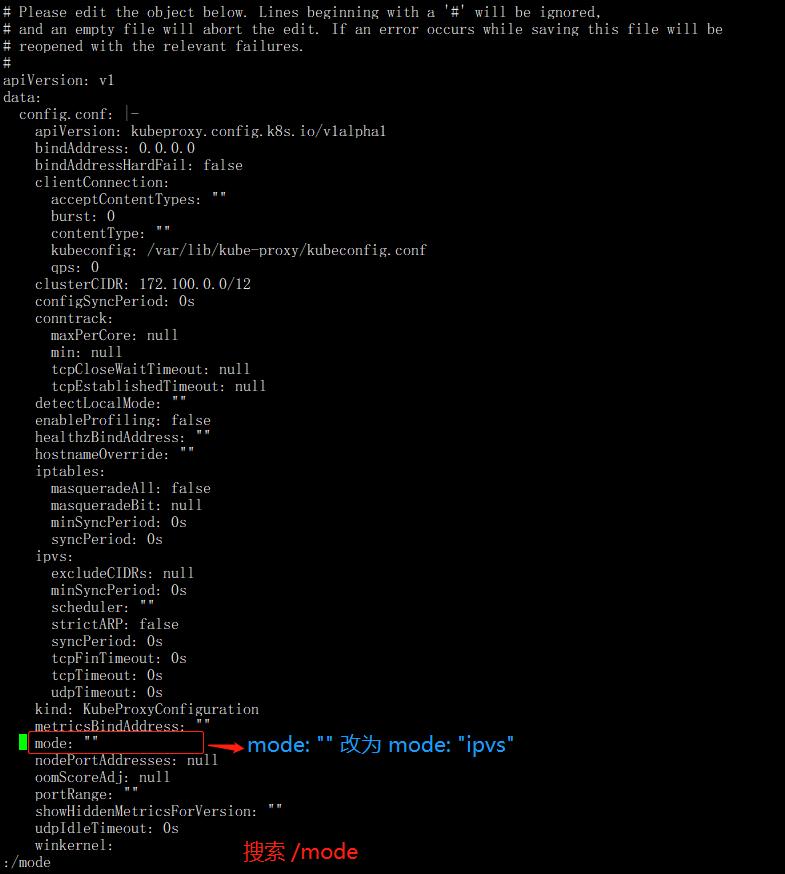
注:mode: ""修改为 mode: "ipvs"
2、更新 Kube-Proxy 的 Pod:(pod就会滚动更新)
[root@k8s-master1 dashboard]# kubectl patch daemonset kube-proxy -p "{\"spec\":{\"template\":{\"metadata\":{\"annotations\":{\"date\":\"`date +'%s'`\"}}}}}" -n kube-system
daemonset.apps/kube-proxy patched
3、查看 pod 滚动更新
[root@k8s-master1 dashboard]# kubectl get po -n kube-system -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES calico-kube-controllers-5f6d4b864b-cwk6p 1/1 Running 1 151m 192.168.3.123 k8s-master1 <none> <none> calico-node-2j75v 1/1 Running 2 151m 192.168.3.123 k8s-master1 <none> <none> calico-node-66vdj 1/1 Running 0 151m 192.168.3.126 node-1 <none> <none> calico-node-j9scc 1/1 Running 5 151m 192.168.3.124 k8s-master2 <none> <none> calico-node-tkjdj 1/1 Running 0 151m 192.168.3.127 node-2 <none> <none> calico-node-v9v7x 1/1 Running 2 151m 192.168.3.125 k8s-master3 <none> <none> coredns-54d67798b7-wtlfb 1/1 Running 0 164m 172.106.159.129 k8s-master1 <none> <none> coredns-54d67798b7-zzn5g 1/1 Running 0 164m 172.106.159.130 k8s-master1 <none> <none> etcd-k8s-master1 1/1 Running 3 164m 192.168.3.123 k8s-master1 <none> <none> etcd-k8s-master2 1/1 Running 1 162m 192.168.3.124 k8s-master2 <none> <none> etcd-k8s-master3 1/1 Running 0 161m 192.168.3.125 k8s-master3 <none> <none> kube-apiserver-k8s-master1 1/1 Running 6 164m 192.168.3.123 k8s-master1 <none> <none> kube-apiserver-k8s-master2 1/1 Running 2 162m 192.168.3.124 k8s-master2 <none> <none> kube-apiserver-k8s-master3 1/1 Running 1 161m 192.168.3.125 k8s-master3 <none> <none> kube-controller-manager-k8s-master1 1/1 Running 3 164m 192.168.3.123 k8s-master1 <none> <none> kube-controller-manager-k8s-master2 1/1 Running 1 162m 192.168.3.124 k8s-master2 <none> <none> kube-controller-manager-k8s-master3 1/1 Running 1 161m 192.168.3.125 k8s-master3 <none> <none> kube-proxy-7wg2x 1/1 Running 0 17s 192.168.3.123 k8s-master1 <none> <none> kube-proxy-8g6rt 1/1 Running 0 36s 192.168.3.124 k8s-master2 <none> <none> kube-proxy-bw682 1/1 Running 0 30s 192.168.3.126 node-1 <none> <none> kube-proxy-r4hgv 1/1 Running 0 50s 192.168.3.127 node-2 <none> <none> kube-proxy-xdthg 1/1 Running 0 41s 192.168.3.125 k8s-master3 <none> <none> kube-scheduler-k8s-master1 1/1 Running 3 164m 192.168.3.123 k8s-master1 <none> <none> kube-scheduler-k8s-master2 1/1 Running 1 162m 192.168.3.124 k8s-master2 <none> <none> kube-scheduler-k8s-master3 1/1 Running 0 161m 192.168.3.125 k8s-master3 <none> <none> metrics-server-545b8b99c6-mgfjr 1/1 Running 2 148m 172.104.247.1 node-2 <none> <none>
AGE时间显示的30s 50s 已经显示pod滚动更新完成
3、验证pod滚动更新为ipvs命令(node-2验证)
curl 127.0.0.1:10249/proxyMode
十八、注意事项
1、kubeadm安装的集群,证书有效期默认是一年。master节点的kube-apiserver、kube-scheduler、kube-controller-manager、etcd都是以容器运行的。可以通过kubectl get po -n kube-system查看
2、启动和二进制的区别
- kubelet的配置文件在/etc/sysconfig/kubelet和/var/lib/kubelet/config.yaml,修改后需要重启kubelet进程
- 其他组件的配置文件在/etc/kubernetes/manifests目录下,比如kube-apiserver.yaml,该yaml文件更改后,kubelet会自动刷新配置,也就是会重启pod。不能再次创建该文件
3、Kubeadm安装后,master节点默认不允许部署pod,会占用资源,在学习过程中可以通过以下方式打开:
- 查看Taints产生的污点,命令如下
[root@k8s-master1 ~]# kubectl describe node -l node-role.kubernetes.io/master= | grep Taints Taints: node-role.kubernetes.io/master:NoSchedule Taints: node-role.kubernetes.io/master:NoSchedule Taints: node-role.kubernetes.io/master:NoSchedule
注;通过命令查看到了有三个污点
- 删除Taints污点命令如下
[root@k8s-master1 ~]# kubectl taint node -l node-role.kubernetes.io/master node-role.kubernetes.io/master:NoSchedule- node/k8s-master1 untainted node/k8s-master2 untainted node/k8s-master3 untainted
- 删除Taints污点,再查看是否删除完成
[root@k8s-master1 ~]# kubectl describe node -l node-role.kubernetes.io/master= | grep Taints Taints: <none> Taints: <none> Taints: <none>
注:通过用查看污点命令,三个污点已经删除
十九、安装Kuboard
说明:Kuboard 是 Kubernetes 的一款图形化管理界面
1、安装
kubectl apply -f https://kuboard.cn/install-script/kuboard.yaml
2、查看 Kuboard 运行状态
[root@k8s-master1 ~]# kubectl get pods -l k8s.kuboard.cn/name=kuboard -n kube-system NAME READY STATUS RESTARTS AGE kuboard-74c645f5df-xj9fs 1/1 Running 0 100s
3、会生成一个svc,查看svc创建的端口
[root@k8s-master1 ~]# kubectl get svc -n kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 29h kuboard NodePort 10.107.67.103 <none> 80:32567/TCP 8m54s metrics-server ClusterIP 10.97.217.111 <none> 443/TCP 29h
注:kuboard 这行 80:32567/TCP。32567端口是访问kuboard到时候使用的
vip虚拟主机IP访问:192.168.3.128:32567
k8s-master1真是主机IP地址访问:192.168.3.123:32567
4、查看Token值作为登录密码,查看命令
[root@k8s-master1 ~]# echo $(kubectl -n kube-system get secret $(kubectl -n kube-system get secret | grep ^kuboard-user | awk '{print $1}') -o go-template='{{.data.token}}' | base64 -d)
5、kuboard官网安装连接地址:https://www.kuboard.cn/install/v3/install.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号