

https://blog.csdn.net/daaikuaichuan/article/details/83862311
https://blog.csdn.net/songchuwang1868/article/details/89877739
设想一个场景:有100万用户同时与一个进程保持着TCP连接,而每一时刻只有几十个或几百个TCP连接是活跃的(接收TCP包),也就是说在每一时刻进程只需要处理这100万连接中的一小部分连接。那么,如何才能高效的处理这种场景呢?进程是否在每次询问操作系统收集有事件发生的TCP连接时,把这100万个连接告诉操作系统,然后由操作系统找出其中有事件发生的几百个连接呢?实际上,在Linux2.4版本以前,那时的select或者poll事件驱动方式是这样做的。
这里有个非常明显的问题,即在某一时刻,进程收集有事件的连接时,其实这100万连接中的大部分都是没有事件发生的。因此如果每次收集事件时,都把100万连接的套接字传给操作系统(这首先是用户态内存到内核态内存的大量复制),而由操作系统内核寻找这些连接上有没有未处理的事件,将会是巨大的资源浪费,然后select和poll就是这样做的,因此它们最多只能处理几千个并发连接。而epoll不这样做,它在Linux内核中申请了一个简易的文件系统,把原先的一个select或poll调用分成了3部分:
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout); 1. 调用epoll_create建立一个epoll对象(在epoll文件系统中给这个句柄分配资源);
2. 调用epoll_ctl向epoll对象中添加这100万个连接的套接字;
3. 调用epoll_wait收集发生事件的连接。
这样只需要在进程启动时建立1个epoll对象,并在需要的时候向它添加或删除连接就可以了,因此,在实际收集事件时,epoll_wait的效率就会非常高,因为调用epoll_wait时并没有向它传递这100万个连接,内核也不需要去遍历全部的连接。
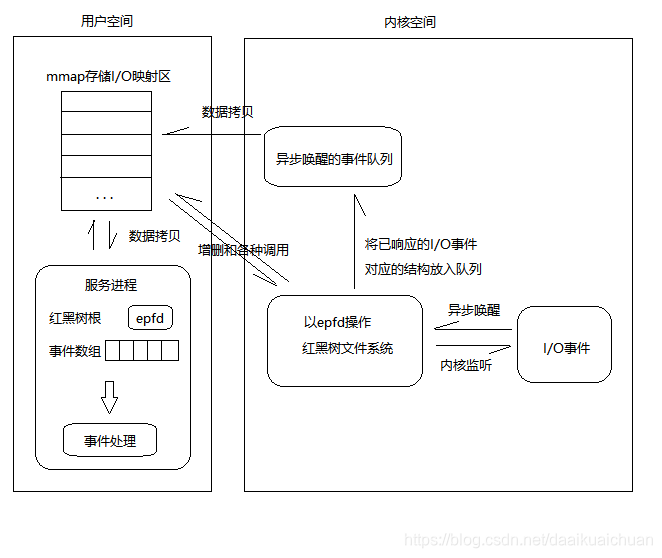
一、epoll原理详解
当某一进程调用epoll_create方法时,Linux内核会创建一个eventpoll结构体,这个结构体中有两个成员与epoll的使用方式密切相关,如下所示:
struct eventpoll {
...
/*红黑树的根节点,这棵树中存储着所有添加到epoll中的事件,
也就是这个epoll监控的事件*/
struct rb_root rbr;
/*双向链表rdllist保存着将要通过epoll_wait返回给用户的、满足条件的事件*/
struct list_head rdllist;
...
};我们在调用epoll_create时,内核除了帮我们在epoll文件系统里建了个file结点,在内核cache里建了个红黑树用于存储以后epoll_ctl传来的socket外,还会再建立一个rdllist双向链表,用于存储准备就绪的事件,当epoll_wait调用时,仅仅观察这个rdllist双向链表里有没有数据即可。有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回。所以,epoll_wait非常高效。
所有添加到epoll中的事件都会与设备(如网卡)驱动程序建立回调关系,也就是说相应事件的发生时会调用这里的回调方法。这个回调方法在内核中叫做ep_poll_callback,它会把这样的事件放到上面的rdllist双向链表中。
在epoll中对于每一个事件都会建立一个epitem结构体,如下所示:
struct epitem {
...
//红黑树节点
struct rb_node rbn;
//双向链表节点
struct list_head rdllink;
//事件句柄等信息
struct epoll_filefd ffd;
//指向其所属的eventepoll对象
struct eventpoll *ep;
//期待的事件类型
struct epoll_event event;
...
}; // 这里包含每一个事件对应着的信息。 当调用epoll_wait检查是否有发生事件的连接时,只是检查eventpoll对象中的rdllist双向链表是否有epitem元素而已,如果rdllist链表不为空,则这里的事件复制到用户态内存(使用共享内存提高效率)中,同时将事件数量返回给用户。因此epoll_waitx效率非常高。epoll_ctl在向epoll对象中添加、修改、删除事件时,从rbr红黑树中查找事件也非常快,也就是说epoll是非常高效的,它可以轻易地处理百万级别的并发连接。
【总结】:
一颗红黑树,一张准备就绪句柄链表,少量的内核cache,就帮我们解决了大并发下的socket处理问题。
-
执行epoll_create()时,创建了红黑树和就绪链表;
-
执行epoll_ctl()时,如果增加socket句柄,则检查在红黑树中是否存在,存在立即返回,不存在则添加到树干上,然后向内核注册回调函数,用于当中断事件来临时向准备就绪链表中插入数据;
-
执行epoll_wait()时立刻返回准备就绪链表里的数据即可。
![在这里插入图片描述]()
二、epoll的两种触发模式
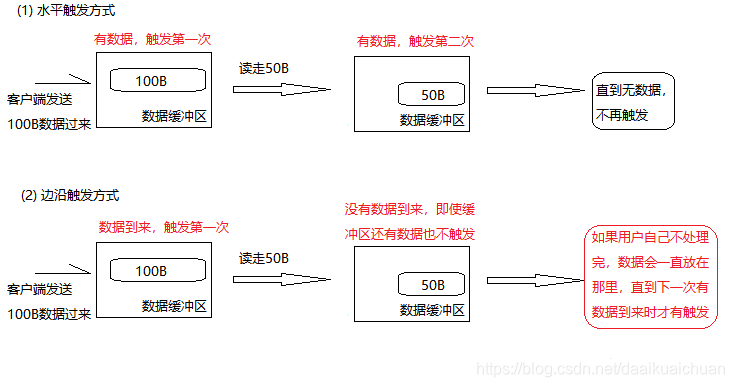
epoll有EPOLLLT和EPOLLET两种触发模式,LT是默认的模式,ET是“高速”模式。
-
LT(水平触发)模式下,只要这个文件描述符还有数据可读,每次 epoll_wait都会返回它的事件,提醒用户程序去操作;
-
ET(边缘触发)模式下,在它检测到有 I/O 事件时,通过 epoll_wait 调用会得到有事件通知的文件描述符,对于每一个被通知的文件描述符,如可读,则必须将该文件描述符一直读到空,让 errno 返回 EAGAIN 为止,否则下次的 epoll_wait 不会返回余下的数据,会丢掉事件。如果ET模式不是非阻塞的,那这个一直读或一直写势必会在最后一次阻塞。
还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知。
【epoll为什么要有EPOLLET触发模式?】:
如果采用EPOLLLT模式的话,系统中一旦有大量你不需要读写的就绪文件描述符,它们每次调用epoll_wait都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率.。而采用EPOLLET这种边缘触发模式的话,当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!!!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符。
【总结】:
-
ET模式(边缘触发)只有数据到来才触发,不管缓存区中是否还有数据,缓冲区剩余未读尽的数据不会导致epoll_wait返回;
-
LT 模式(水平触发,默认)只要有数据都会触发,缓冲区剩余未读尽的数据会导致epoll_wait返回。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号