一致性哈希算法浅析
一、前言
一致性哈希算法(Consistent Hashing) 是一种特殊的哈希算法,是分布式系统中常用的算法,在分布式存储、分布式系统负载均衡等场景中经常使用。
一致哈希由MIT的Karger及其合作者提出,现在这一思想已经扩展到其它领域。在这篇1997年发表的学术论文中介绍了“一致哈希”如何应用于用户易变的分布式Web服务中。哈希表中的每一个代表分布式系统中一个节点,在系统添加或删除节点只需要移动{\displaystyle K/n}K/n项。[1]
本文对一致性哈希算法作简洁清晰的分析,从中可以了解到哈希算法的主要关注点。
二、经典取模方式
例如10个用户Id(0,1,2,3,4,5,6,7,8,9),3个节点 :(NODE 1, NODE 2, NODE 3)
如果按照取模的方式,location = hash(key) mod size
那就是:
NODE 1: 0,3,6,9
NODE 2: 1,4,7
NODE 3: 2,5,8
当减少一个节点的时候,数据分布就变更为
NODE 1: 0,2,4,6,8
NODE 2: 1,3,5,7,9
算法伸缩性很差,当新增或者下线服务器的时候,用户id与服务器的映射关系会大量失效。一致性hash则利用hash环对其进行了改进。
三、一致性哈希
一致性哈希到底是什么?可以这样来描述:
它表示某种虚拟环结构(名为哈希环,HashRing)中的资源请求者(我们在本文中简称为“请求”)和服务器节点。
一致性哈希是将整个哈希值空间组织成一个虚拟的圆环,如假设哈希函数H的值空间为0-2^32-1(哈希值是32位无符号整形),整个哈希空间环如下:
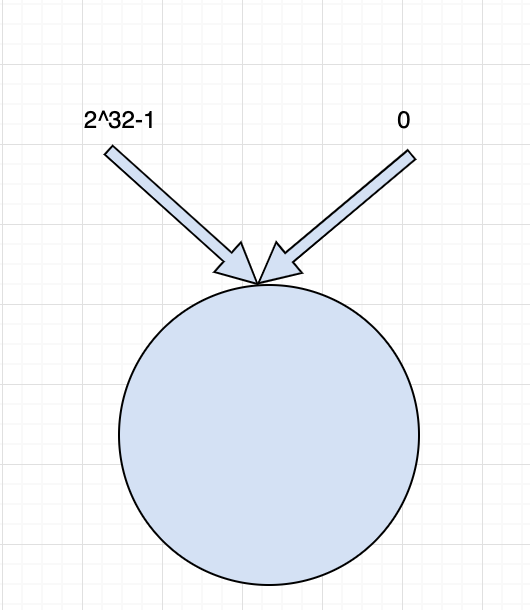
整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到2^32-1,也就是说0点左侧的第一个点代表2^32-1, 0和2^32-1在零点中方向重合,我们把这个由2^32个点组成的圆环称为Hash环。
下一步将各个服务器使用Hash算法进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中几台服务器节点使用IP地址哈希后在环空间的位置如下:
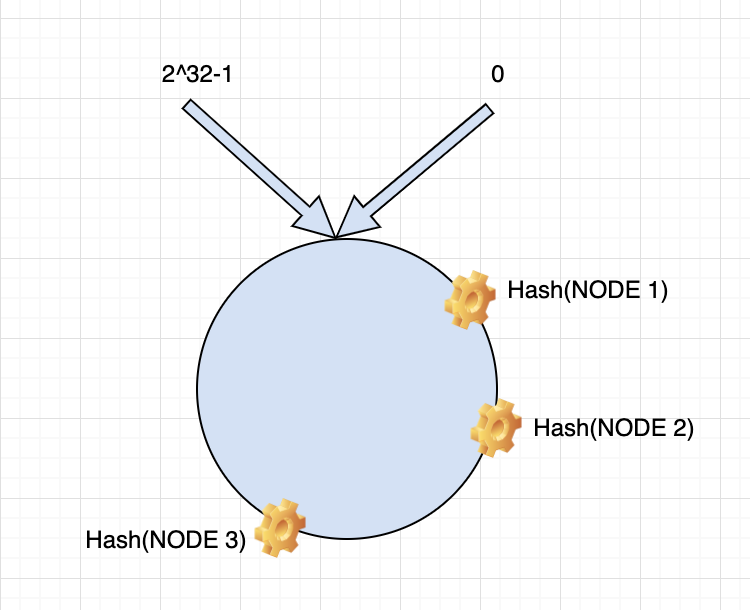
接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
例如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:

根据一致性Hash算法,数据A, C会被定为到Node 1上,B被定为到Node 3上,D被定为到Node 2上。现在我们已经知道数据访问的策略了。
添加server节点
当在server集群中增加一个server节点(NODE 4)时,对数据访问又有什么影响呢。如下图:
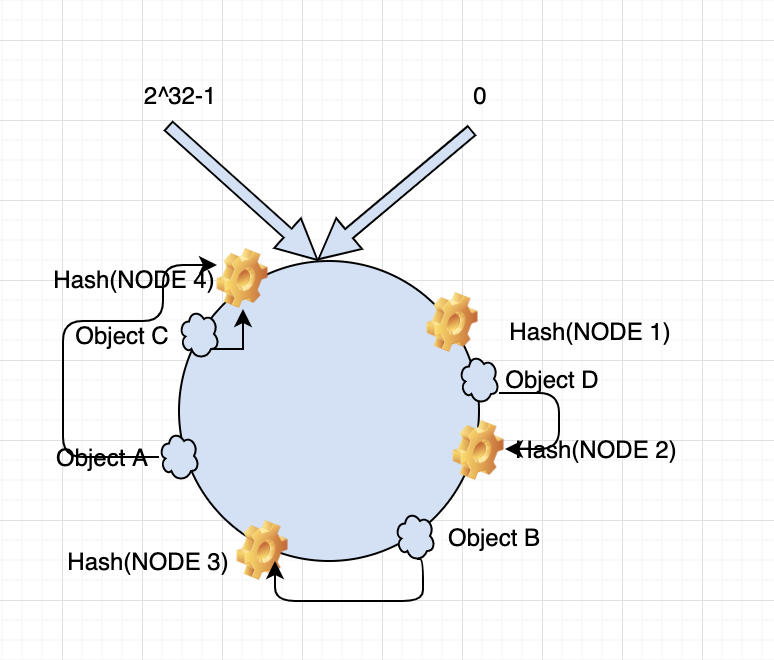
当新增NODE4时,只有Object A,Object C会发生变化,路由到新的节点 NODE 4上。
虚拟节点的引入
我们已经知道,添加和删除节点都会影响缓存数据的分布。尽管hash算法具有分布均匀的特性,但是当集群中server数量很少时,他们可能在环中的分布并不是特别均匀,进而导致缓存数据不能均匀分布到所有的server上,可能会造成少数节点上有大量的数据访问。
这时,我们就需要引入虚拟节点。通过增加虚拟节点,使得服务器节点总数大幅增加,从而散落到hash环上就会更加均匀。
例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node 1#1”、“Node 1#2”、“Node 1#3”、“Node 2#1”、“Node 2#2”、“Node 2#3”、“Node 3#1”、“Node 3#2”、“Node 3#3”、“Node 4#1”、“Node 4#2”、“Node 4#3”的哈希值 ,这样环上就有12个虚拟节点。
小结
你现已了解了为什么分布式系统中需要哈希以均匀地分配负载。然而需要一致性哈希,确保一旦出现环变更,集群中只需要最小的工作量。
此外,节点需要存在于环上的多个位置,确保从统计学上来说负载更可能更均匀地分配。
附Java实现的哈希算法(转):
不带虚拟节点:
public class ConsistentHashingWithoutVirtualNode { /** * 待添加入Hash环的服务器列表 */ private static String[] servers = {"192.168.0.0:111", "192.168.0.1:111", "192.168.0.2:111", "192.168.0.3:111", "192.168.0.4:111"}; /** * key表示服务器的hash值,value表示服务器的名称 */ private static SortedMap<Integer, String> sortedMap = new TreeMap<Integer, String>(); /** * 程序初始化,将所有的服务器放入sortedMap中 */ static { for (int i = 0; i < servers.length; i++) { int hash = getHash(servers[i]); System.out.println("[" + servers[i] + "]加入集合中, 其Hash值为" + hash); sortedMap.put(hash, servers[i]); } System.out.println(); } /** * 使用FNV1_32_HASH算法计算服务器的Hash值,这里不使用重写hashCode的方法,最终效果没区别 */ // BKDRHash private static int getHash(String str) { final int p = 16777619; int hash = (int) 2166136261L; for (int i = 0; i < str.length(); i++) hash = (hash ^ str.charAt(i)) * p; hash += hash << 13; hash ^= hash >> 7; hash += hash << 3; hash ^= hash >> 17; hash += hash << 5; // 如果算出来的值为负数则取其绝对值 if (hash < 0) hash = Math.abs(hash); return hash; } /** * 得到应当路由到的结点 */ private static String getServer(String node) { // 得到带路由的结点的Hash值 int hash = getHash(node); // 得到大于该Hash值的所有Map SortedMap<Integer, String> subMap = sortedMap.tailMap(hash); // 第一个Key就是顺时针过去离node最近的那个结点 Integer i = subMap.firstKey(); // 返回对应的服务器名称 return subMap.get(i); } public static void main(String[] args) { String[] nodes = {"127.0.0.1:1111", "221.226.0.1:2222", "10.211.0.1:3333"}; for (int i = 0; i < nodes.length; i++) { System.out.println("[" + nodes[i] + "]的hash值为" + getHash(nodes[i]) + ", 被路由到结点[" + getServer(nodes[i]) + "]"); } } }
带虚拟节点:
public class ConsistentHashingWithVirtualNode { /** * 待添加入Hash环的服务器列表 */ private static String[] servers = {"192.168.0.0:111", "192.168.0.1:111", "192.168.0.2:111", "192.168.0.3:111", "192.168.0.4:111"}; /** * 真实结点列表,考虑到服务器上线、下线的场景,即添加、删除的场景会比较频繁,这里使用LinkedList会更好 */ private static List<String> realNodes = new LinkedList<String>(); /** * 虚拟节点,key表示虚拟节点的hash值,value表示虚拟节点的名称 */ private static SortedMap<Integer, String> virtualNodes = new TreeMap<Integer, String>(); /** * 虚拟节点的数目,这里写死,为了演示需要,一个真实结点对应5个虚拟节点 */ private static final int VIRTUAL_NODES = 5; static { // 先把原始的服务器添加到真实结点列表中 for (int i = 0; i < servers.length; i++) { realNodes.add(servers[i]); } // 再添加虚拟节点,遍历LinkedList使用foreach循环效率会比较高 for (String str : realNodes) { for (int i = 0; i < VIRTUAL_NODES; i++) { String virtualNodeName = str + "&&VN" + String.valueOf(i); int hash = getHash(virtualNodeName); System.out.println("虚拟节点[" + virtualNodeName + "]被添加, hash值为" + hash); virtualNodes.put(hash, virtualNodeName); } } System.out.println(); } /** * 使用FNV1_32_HASH算法计算服务器的Hash值,这里不使用重写hashCode的方法,最终效果没区别 */ private static int getHash(String str) { final int p = 16777619; int hash = (int) 2166136261L; for (int i = 0; i < str.length(); i++) hash = (hash ^ str.charAt(i)) * p; hash += hash << 13; hash ^= hash >> 7; hash += hash << 3; hash ^= hash >> 17; hash += hash << 5; // 如果算出来的值为负数则取其绝对值 if (hash < 0) hash = Math.abs(hash); return hash; } /** * 得到应当路由到的结点 */ private static String getServer(String node) { // 得到带路由的结点的Hash值 int hash = getHash(node); // 得到大于该Hash值的所有Map SortedMap<Integer, String> subMap = virtualNodes.tailMap(hash); // 第一个Key就是顺时针过去离node最近的那个结点 Integer i = subMap.firstKey(); // 返回对应的虚拟节点名称,这里字符串稍微截取一下 String virtualNode = subMap.get(i); return virtualNode.substring(0, virtualNode.indexOf("&&")); } public static void main(String[] args) { String[] nodes = {"127.0.0.1:1111", "221.226.0.1:2222", "10.211.0.1:3333"}; for (int i = 0; i < nodes.length; i++) { System.out.println("[" + nodes[i] + "]的hash值为" + getHash(nodes[i]) + ", 被路由到结点[" + getServer(nodes[i]) + "]"); } } }
参考资料:https://zh.wikipedia.org/wiki/%E4%B8%80%E8%87%B4%E5%93%88%E5%B8%8C#cite_note-KargerEtAl1999-2
http://www.cnblogs.com/xrq730/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号