Python成长之路【第八篇】:Python基础之模块
模块&包
模块(module)的概念:
在计算机程序开发的过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。为了编写可维护的代码,我们把很多函数分组,分别放在不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的存在。在Python中,一个.py文件就称之为一个模块(module)
使用模块有什么好处?
最大的好处是大大提高了代码的可维护性。
其次,编写代码不必从零开始,当一个模块编写完毕,就可以被其他地方利用,我们在编写程序的时候,也经常引用其他的模块,包括Python内置的模块和来自第三方的模块。
模块一共分三种:
- Python标准库
- 第三方模块
- 应用程序自定义模块
另外,使用模块还可以避免函数名和变量名冲突,相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突,但是也要注意,不要与内置函数名字冲突
模块导入方法
1、import 语句
import 模块名,模块名
当我们使用import语句的时候,Python解释器是怎样找到对应的文件呢?答案就是解释器有自己的搜索路径,存在sys.path里
2、from...import 语句
from modname import 函数名
这个声明不会把整个modname模块导入当前的名字空间中,只会将某个函数单个引入到大当前
3、from...import * 语句
from modname import *
这提供了一个简单的方法来导入一个模块中的所有函数,功能,然而这种方法不推荐使用,很多Python程序员都不会使用这种方法,因为引入其他来源的命名,很有可能覆盖了已有的定义
4、运行本质
# 1 import test # 2 from test import add
无论是1 还是2 ,首先通过sys.path找到test.py,然后执行test脚本(全部执行),区别是1 会将test这个变量名加载到名字空间,而2 只会将add这个变量名加载进来
包(package)
如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称其为“包”(package)
举个例子,一个abc.py的文件就是一个名字叫做abc的模块,一个xyz.py的文件就是一个名字叫xyz的模块
现在,假设我们的abc和xyz这两个模块名字与其他模块冲突了,于是我们通过包来组织模块,避免冲突,方法是选择一个顶层包名:
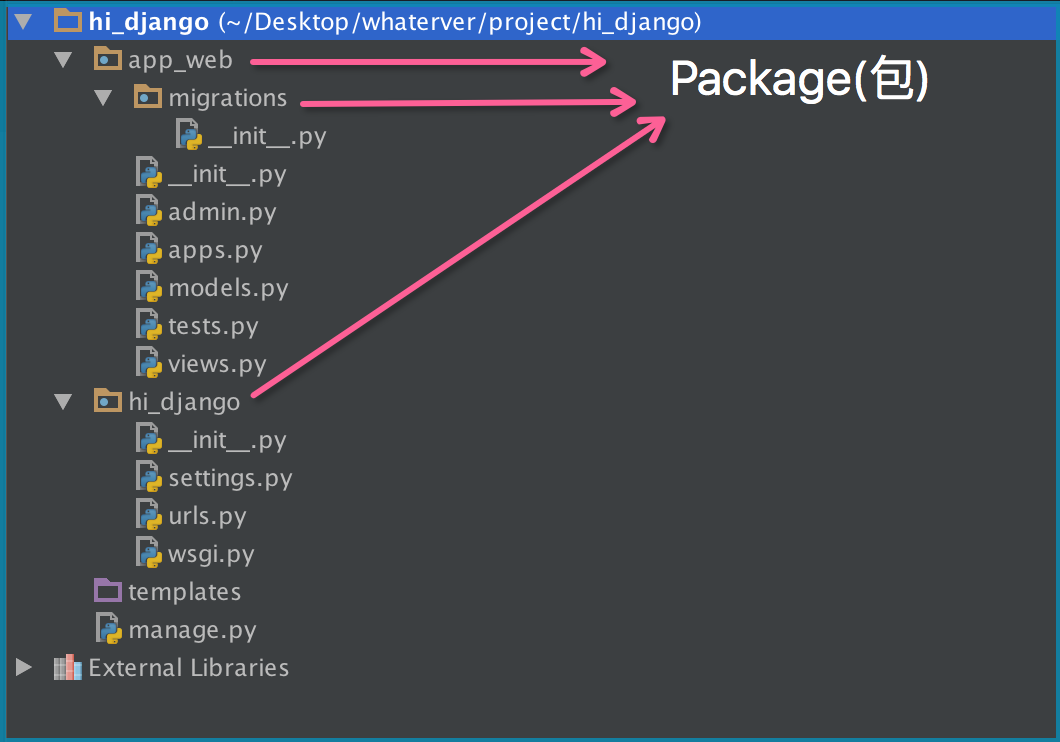
请注意,每一个包目录下面就会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录(文件夹),而不是一个包。__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是对应包的名字
调用包就是执行包下的__init__.py文件
注意点(important)
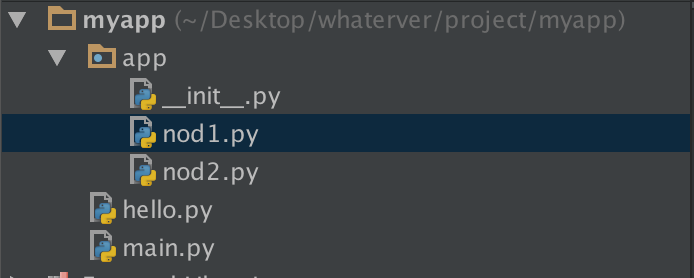
1 >>>>>>>>>>>>>
在nod1里import hello是找不到的,有的人说可以找到啊,那是因为你的pycharm为你把myapp这一层路径加入了sys.path里面,所以可以找到,然而程序一旦在命令行执行,则报错,有的人问那怎么办?简单啊,自己把这个路径加进去不就ok了吗
import sys, os BASE_DIR = os.path.dirname(os.path.dirname(os.path.dirname(__file__))) sys.path.append(BASE_DIR) import hello hello.hello()
2 >>>>>>>>>>>>>
if __name__ == "__main__":
print("ok")
“Make a .py both importable and executable”
如果我们是直接执行某个.py文件的时候,该文件中那么”__name__ == '__main__'“是True,但是我们如果从另外一个.py文件通过import导入该文件的时候,这时__name__的值就是我们这个py文件的名字而不是__main__。
这个功能还有一个用处:调试代码的时候,在”if __name__ == '__main__'“中加入一些我们的调试代码,我们可以让外部模块调用的时候不执行我们的调试代码,但是如果我们想排查问题的时候,直接执行该模块文件,调试代码能够正常运行!
time模块
三种时间表示
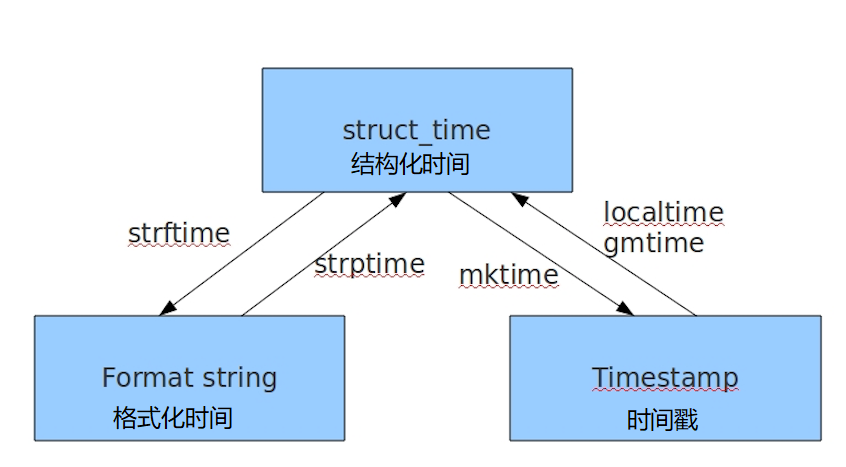
在Python中,通常有这几种方法方式来表示时间:
时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量
我们运行“type(time.time())”,返回的是float类型
格式化的时间字符串
元组(struct_time):struct_time元组共有9个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)


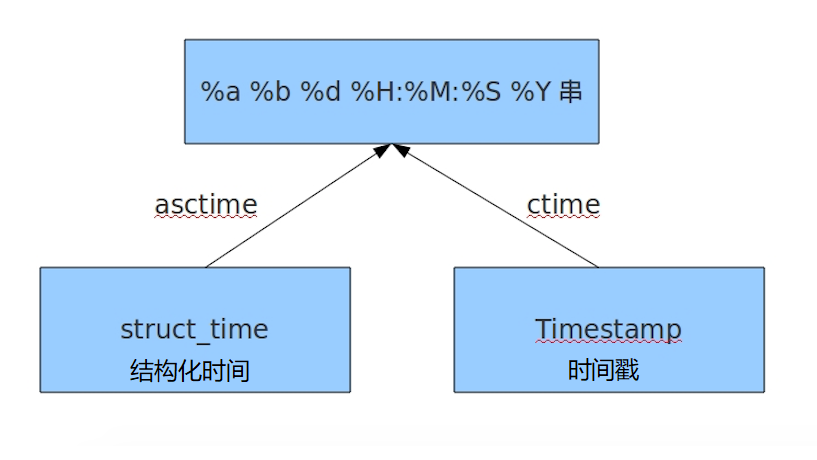
1 import time 2 3 # 1 time():返回当前时间的时间戳 4 print(time.time()) # 1523883504.826997 5 6 # ------------------------------------------------ 7 8 # 2 localtime([secs]) 9 # 将一个时间戳转换为当前时区的结构化时间 ,secs参数未提供,则以当前时间为准 10 print(time.localtime()) 11 # time.struct_time(tm_year=2018, tm_mon=4, tm_mday=16, tm_hour=21, tm_min=3, tm_sec=2, tm_wday=0, tm_yday=106, tm_isdst=0) 12 print(time.localtime(1523883504.826997)) 13 # time.struct_time(tm_year=2018, tm_mon=4, tm_mday=16, tm_hour=20, tm_min=58, tm_sec=24, tm_wday=0, tm_yday=106, tm_isdst=0) 14 15 # ------------------------------------------------ 16 17 # 3 gmtime([secs]) 和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区的(0时区)的结构化时间 18 19 # ------------------------------------------------ 20 21 # 4 mktime(t) 将一个结构化时间转换为时间戳 22 print(time.mktime(time.localtime())) # 1523884187.0 23 24 # ------------------------------------------------ 25 26 # 5 asctime([t1]) 把一个表示时间的元组或者结构化时间表示为这种形式:"Sun Jun 20 23:21:05 1993" 27 # 如果没有参数,将会将time.localtime()作为参数传入 28 print(time.asctime()) # Mon Apr 16 21:11:51 2018 29 30 # ------------------------------------------------ 31 32 # 6 ctime([secs]) 把一个时间戳(按秒计算的浮点数)转换为time.asctime()的形式 33 # 如果参数未给或者为None的时候,将会默认time.time()为参数。它的作用相当于time.asctime(time.localtime(secs)) 34 print(time.ctime()) # Mon Apr 16 21:17:31 2018 35 36 print(time.ctime(time.time())) # Mon Apr 16 21:18:14 2018 37 38 # ------------------------------------------------ 39 40 # 7 strftime(format[, t]) 把一个代表时间的元组或者结构化时间(如由time.localtime()和time.gmtime()返回)转化为格式化的时间字符串,如果t未指定,将传入time.localtime()。如果元组中任何一个元素越界,ValueError的错误将会抛出 41 print(time.strftime("%y-%m-%d %X",time.localtime())) # 18-04-16 21:22:37 42 43 # ------------------------------------------------ 44 45 # 8 time.strftime(string[, format]) 46 # 把一个格式化时间字符串转换为结构化时间,实际上它和strftime()是逆操作 47 print(time.strptime("2020-05-05 16:57:55", "%Y-%m-%d %X")) 48 # time.struct_time(tm_year=2020, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=57, tm_sec=55, tm_wday=1, tm_yday=126, tm_isdst=-1) 49 # 在这个函数中,format默认为:“%a %b %d %H:%M:%S %Y” 50 51 # ------------------------------------------------ 52 53 # 9 sleep(secs) 54 # 线程推迟指定的时间运行,单位为秒 55 time.sleep(2) 56 57 # ------------------------------------------------ 58 59 # 10 clock() 60 # 这个需要注意,在不同的系统上含义不同。在UNIX系统上,它返回的是“进程时间”,它是用秒表示的浮点数(时间戳) 61 # 而在windows中,第一次调用,返回的是进程运行的实际时间,而第二次之后的调用是自第一次调用后到现在的运行时间,即两次的时间差
random模块
import random print(random.random()) # 默认为0 - 1 的float # 0.6151876730225738 print(random.randint(1, 3)) # [1,3]两个参数范围的随机整型 print(random.randrange(1, 3)) # [1,3),左包右不包,两个参数范围的随机整型 print(random.choice([1, "23", [4, 5]])) # 23 # 随机元素 print(random.sample([1, "23", [4, 5]], 2)) # ['23', [4, 5]] # 随机两个元素 print(random.uniform(1, 3)) # 2.992648254719755 # 两个参数范围内的float item = [1, 3, 5, 7, 9] random.shuffle(item) print(item) # [1, 9, 5, 7, 3] # 打乱顺序
1 import random 2 def v_code(): 3 code = '' 4 for i in range(5): 5 num = random.randint(0, 9) 6 alf = chr(random.randint(65, 90)) 7 add = random.choice([num, alf]) 8 code += str(add) 9 return code 10 print(v_code())
os模块
os模块是与操作系统交互的一个接口
1 # os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 2 # os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd 3 # os.curdir 返回当前目录: ('.') 4 # os.pardir 获取当前目录的父目录字符串名:('..') 5 # os.makedirs('dirname1/dirname2') 可生成多层递归目录 6 # os.removedirs('dirname1') 递归删除,若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 7 # os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname 8 # os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname 9 # os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 10 # os.remove() 删除一个文件 11 # os.rename("oldname","newname") 重命名文件/目录 12 # os.stat('path/filename') 获取文件/目录信息 13 # os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" 14 # os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" 15 # os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为: 16 # os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' 17 # os.system("bash command") 运行shell命令,直接显示 18 # os.environ 获取系统环境变量 19 # os.path.abspath(path) 返回path规范化的绝对路径 20 # os.path.split(path) 将path分割成目录和文件名二元组返回 21 # os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 22 # os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 23 # os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False 24 # os.path.isabs(path) 如果path是绝对路径,返回True 25 # os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False 26 # os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False 27 # os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 28 # os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 29 # os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称
1 import sys,time 2 for i in range(100): 3 sys.stdout.write('#') 4 time.sleep(0.3) 5 sys.stdout.flush() # 刷新
json&pickle
之前我们用过eval内置方法可以将一个字符串转换成Python对象,不过,eval方法是有局限性对的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值
import json a = "[1, 2, 3]" x = eval(a) print(x) print(type(x)) y = json.loads(a) print(y) print(type(y))
什么是序列化?
我们把对象(变量)从内存中变成可储存或传输过程称之为序列化,在Python中叫pickling,在其他语言中也被称为serialization,marshalling,flattening等等,都是一个意思,序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling
json
如果我们在不同的编程语言之间传递对象,就必须把对象序列化标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来的就是一个字符串,可以被所有语言读取也可以方便地存储到磁盘或者通过网络传输,JSON不仅是标准格式,并且比XML更快,而且可以直接在web页面读取,非常方便
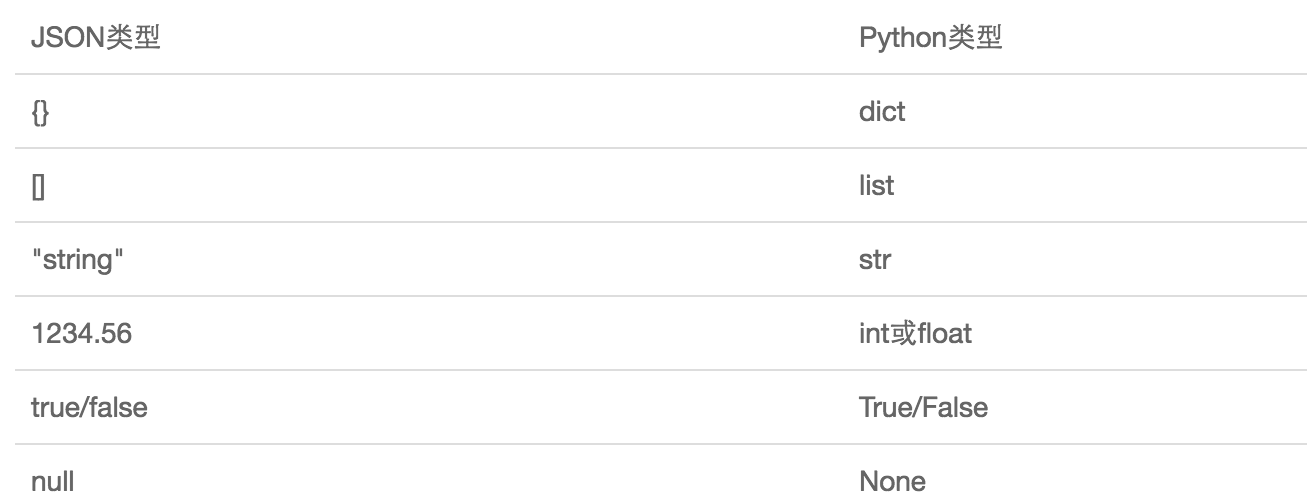
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置得到数据类型对应如下:
import json
dic = {'name':'albert','age':19,'sex':'male'}
print(type(dic)) # <class 'dict'>
j = json.dumps(dic)
print(type(j)) # <class 'str'>
f = open("a.txt","w")
f.write(j) # -------等价于json.dump(dic,f)
f.close()
# ----------反序列化
f = open("a.txt")
data = json.loads(f.read()) # ------等价于data = json.load(f)
print(data)
print(type(data))
1 import json 2 # dct="{'1':111}" # json 不认单引号 3 # dct=str({"1":111}) # 报错,因为生成的数据还是单引号:{'one': 1} 4 5 dct='{"1":"111"}' 6 print(json.loads(dct)) 7 8 # conclusion: 9 # 无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads
pickle
##----------------------------序列化
import pickle
dic = {'name': 'alvin', 'age': 23, 'sex': 'male'}
print(type(dic)) # <class 'dict'>
j = pickle.dumps(dic)
print(type(j)) # <class 'bytes'>
f = open('序列化对象_pickle', 'wb') # 注意是w是写入str,wb是写入bytes,j是'bytes'
f.write(j) # -------------------等价于pickle.dump(dic,f)
f.close()
# -------------------------反序列化
import pickle
f = open('序列化对象_pickle', 'rb') # 当时以bytes写入的,就要以b模式打开
data = pickle.loads(f.read()) # 等价于data=pickle.load(f)
print(data['age'])
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是他只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系
shelve模块
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写,key必须为字符串,而值可以是Python所支持的数据类型
import shelve
f = shelve.open(r'shelve.txt')
# f['stu1_info']={'name':'alex','age':'18'}
# f['stu2_info']={'name':'alvin','age':'20'}
# f['school_info']={'website':'oldboyedu.com','city':'beijing'}
#
#
# f.close()
print(f.get('stu_info')['age'])
xml模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,之前,在json还没有诞生的黑暗时代,大家只能选择用xml,至今很多传统公司,如金融行业的很多系统的接口主要还是xml
xml的格式如下,就是通过<>节点来区别数据结构的:
1 <?xml version="1.0"?> 2 <data> 3 <country name="Liechtenstein"> 4 <rank updated="yes">2</rank> 5 <year>2008</year> 6 <gdppc>141100</gdppc> 7 <neighbor name="Austria" direction="E"/> 8 <neighbor name="Switzerland" direction="W"/> 9 </country> 10 <country name="Singapore"> 11 <rank updated="yes">5</rank> 12 <year>2011</year> 13 <gdppc>59900</gdppc> 14 <neighbor name="Malaysia" direction="N"/> 15 </country> 16 <country name="Panama"> 17 <rank updated="yes">69</rank> 18 <year>2011</year> 19 <gdppc>13600</gdppc> 20 <neighbor name="Costa Rica" direction="W"/> 21 <neighbor name="Colombia" direction="E"/> 22 </country> 23 </data>
xml协议在各个语言里都是支持的,在python中可以用以下模块操作xml:
1 import xml.etree.ElementTree as ET 2 3 tree = ET.parse("xmltest.xml") 4 root = tree.getroot() 5 print(root.tag) 6 7 # 遍历xml文档 8 for child in root: 9 print(child.tag, child.attrib) 10 for i in child: 11 print(i.tag, i.text) 12 13 # 只遍历year 节点 14 for node in root.iter('year'): 15 print(node.tag, node.text) 16 # --------------------------------------- 17 18 import xml.etree.ElementTree as ET 19 20 tree = ET.parse("xmltest.xml") 21 root = tree.getroot() 22 23 # 修改 24 for node in root.iter('year'): 25 new_year = int(node.text) + 1 26 node.text = str(new_year) 27 node.set("updated", "yes") 28 29 tree.write("xmltest.xml") 30 31 # 删除node 32 for country in root.findall('country'): 33 rank = int(country.find('rank').text) 34 if rank > 50: 35 root.remove(country) 36 37 tree.write('output.xml')
自己创建xml文档:
1 import xml.etree.ElementTree as ET 2 3 new_xml = ET.Element("namelist") 4 name = ET.SubElement(new_xml, "name", attrib={"enrolled": "yes"}) 5 age = ET.SubElement(name, "age", attrib={"checked": "no"}) 6 sex = ET.SubElement(name, "sex") 7 sex.text = '33' 8 name2 = ET.SubElement(new_xml, "name", attrib={"enrolled": "no"}) 9 age = ET.SubElement(name2, "age") 10 age.text = '19' 11 12 et = ET.ElementTree(new_xml) # 生成文档对象 13 et.write("test.xml", encoding="utf-8", xml_declaration=True) 14 15 ET.dump(new_xml) # 打印生成的格式
re模块
就本质而言,正则表达式(或RE)是一种小型的、高度专业化的编程语言,在Python中,它内嵌在Python中,并通过re模块实现,正则表达模式被编译成一系列的字节码,然后由用C编写的匹配引擎执行
字符匹配(普通字符,元字符):
普通字符:
大多数字符和字母都会和自身匹配
>>>re.findall("albert","albertseven")
["albert"]
元字符:
. ^ $ * + ? {} [] | \
元字符之 . ^ $ * + ? {}
import re
ret = re.findall("a..ert","helloablert") # 通配符
print(ret) # ['ablert']
ret1 = re.findall("^a..ert","alberthello") # 开头
print(ret1) # ['ablert']
ret2 = re.findall("a..ert$","alberthelloawwert") # 结尾
print(ret2) # ['awwert']
ret3 = re.findall("abc*","abcccc") # 贪婪匹配 [0,+oo]
print(ret3) # ['abcccc']
ret4 = re.findall("abc+","abccc") # 贪婪匹配 [1,+oo]
print(ret4) # ['abccc']
ret5 = re.findall("abc?","abccc") # 贪婪匹配 [0,1]
print(ret5) # ['abc']
ret6 = re.findall("abc{1,4}","abccc") # 贪婪匹配 [1,4] 自定义
print(ret6) # ['abccc']
注意:前面的*,+,?,{}等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
import re
ret = re.findall("abc*?","abcccc") # 惰性匹配
print(ret) # ['ab']
元字符之字符集[]:
# -----字符集-----
# 字符集[]里是或的意思
import re
ret0 = re.findall("a[bc]d","acd") # bc 在[]中是或的关系
print(ret0) # ['acd']
ret1 = re.findall("[a-z]","acd") # - 在字符集中有特殊功能,指定范围
print(ret1) # ['a', 'c', 'd']
ret2 = re.findall("[.*+]","a.cd+") # .*+在字符集中就是普通字符
print(ret2) # ['.', '+']
# ->>在字符集里有功能的符号: - ^ \
ret3 = re.findall("[1-9]","45dssd3") # - 指定范围
print(ret3) # ['4', '5', '3']
ret4 = re.findall("[^ab]","4545abab66") # ^ 非
print(ret4) # ['4', '5', '4', '5', '6', '6']
ret5 = re.findall("[\d]","dsa455") # \ 让有功能的字符变没有功能,让没有功能的变有功能,
print(ret5) # ['4', '5', '5']
元字符之转义符\
反斜杠后边跟元字符去除特殊功能,比如\.
反斜杠后边跟普通字符实现特殊功能,比如\d
\d 匹配任何十进制数,它相当于类[0-9]
\D 匹配任何非数字字符,它相当于类[^0-9]
\s 匹配任何空白字符,它相当于类[\t\n\r\f\v]
\S 匹配任何非空白字符,它相当于类[^\t\n\r\f\v]
\w 匹配任何字母数字字符,它相当于类[a-zA-Z0-9_]
\W 匹配任何非字母数字字符,它相当于类[^a-zA-Z0-9_]
\b 匹配一个特殊字符边界,比如空格,&,#等
import re
ret = re.findall("I\b","I am LIST")
print(ret) # []
ret1 = re.findall(r"I\b","I am LIST")
print(ret1) # ['I']
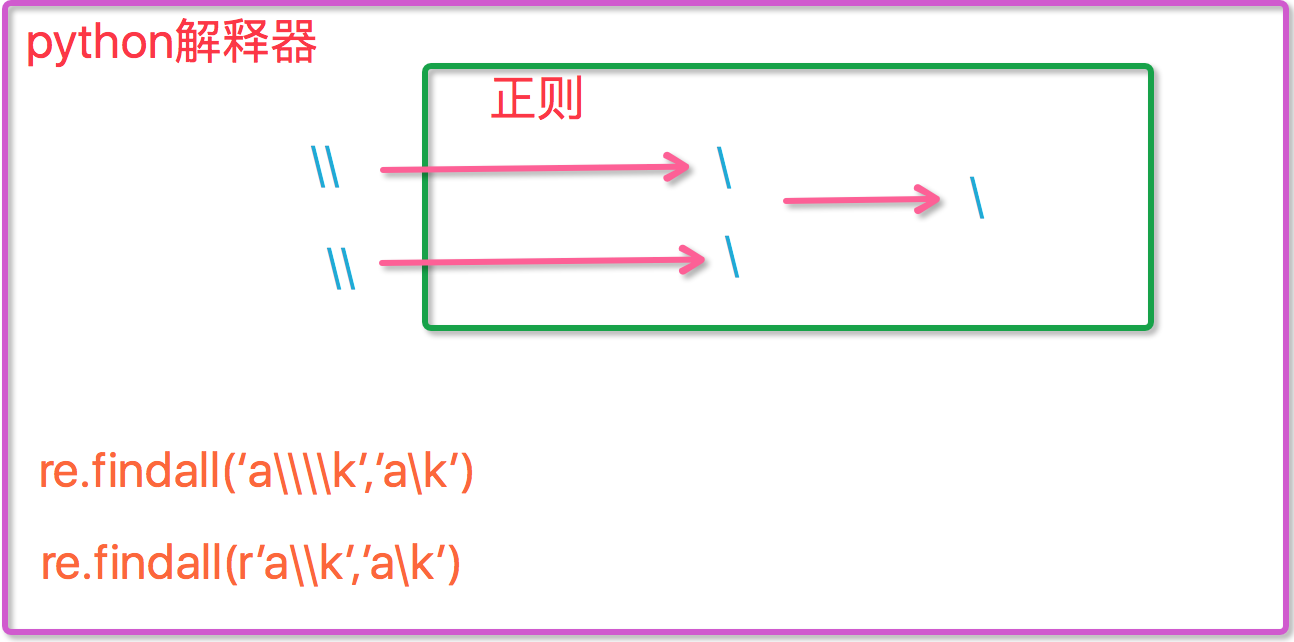
现在我们聊聊\,先看下面两个匹配:
# ---(一):
import re
ret=re.findall('c\l','abc\le')
print(ret)#[]
ret=re.findall('c\\l','abc\le')
print(ret)#[]
ret=re.findall('c\\\\l','abc\le')
print(ret)#['c\\l']
ret=re.findall(r'c\\l','abc\le')
print(ret)#['c\\l']
# ---(二):
#之所以选择\b是因为\b在ASCII表中是有意义的
m = re.findall('\bblow', 'blow')
print(m)
m = re.findall(r'\bblow', 'blow') # 前面加上r代表传到re那一层的是原生字符串
print(m)
元字符之分组()
# 分组
import re
m = re.findall('(ad)+', 'add')
print(m)
# 有名分组
ret = re.search("(?P<id>\d{2})/(?P<name>\w{3})","163/com") # search 惰性匹配 找到一个就不找了
print(ret.group()) # 63/com
print(ret.group("name")) # com 可以通过名字取结果
元字符之|
import re
ret = re.search("(ab)|\d","rabdsds5")
print(ret.group()) # ab
re模块下的常用方法
import re
# 1
re.findall('a', 'alvin yuan') # 返回所有满足匹配条件的结果,放在列表里
# 2
re.search('a', 'alvin yuan').group() # 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以
# 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,在group()之前打印,则返回None。
# 3
re.match('a', 'abc').group() # 同search,不过在字符串开始处进行匹配
# 4
ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
print(ret) # ['', '', 'cd']
# 5
ret2 = re.sub('\d', 'abc', 'alvin5yu6', 1) # 替换规则,替换成的字符串,被替换的字符串,次数
print(ret2) # alvinabcyuan6
ret3 = re.subn('\d', 'abc', 'alvin5yu6')
print(ret3) # ('alvinabcyuanabc', 2) 显示:替换完成的字符串,次数
# 6
obj = re.compile('\d{3}') # 把规则封装在对象中
ret4 = obj.search('abc123eeee') # 用这个对象调用search
print(ret4.group()) # 123
# 7
ret = re.finditer('\d', 'ds3sy4784a') # 将匹配到的结果放入一个对象中
print(ret) # <callable_iterator object at 0x10195f940>
print(next(ret).group()) # 先next拿到一个值得对象,在group出来
print(next(ret).group())
注意点:
import re
ret = re.findall("www\.(baidu|souhu)\.com","www.baidu.com")
print(ret) # ['baidu'] 这是因为findall会优先把匹配结果组里的内容返回,如果想要所有的匹配结果,取消权限即可
ret = re.findall("www\.(?:baidu|souhu)\.com","www.baidu.com")
print(ret) # ['www.baidu.com']
1 import re 2 ret = re.findall("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>") # 有名规则可以重复用 3 print(ret) 4 print(re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>").group()) 5 print(re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>").group())
1 # 匹配出所有的整数 2 import re 3 4 ret=re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))") 5 ret.remove("") 6 print(ret) # 利用()优先级显示,所有没有小数
configparser模块
来看一个好多软件的常见文档格式如下:
[DEFAULT] ServerAliveInterval = 45 Compression = yes CompressionLevel = 9 ForwardX11 = yes [bitbucket.org] User = hg [topsecret.server.com] Port = 50022 ForwardX11 = no
如果想用python生成一个这样的文档怎么做呢?
import configparser
config = configparser.ConfigParser()
config["DEFAULT"] = {'ServerAliveInterval': '45',
'Compression': 'yes',
'CompressionLevel': '9'}
config['bitbucket.org'] = {}
config['bitbucket.org']['User'] = 'hg'
config['topsecret.server.com'] = {}
topsecret = config['topsecret.server.com']
topsecret['Host Port'] = '50022' # mutates the parser
topsecret['ForwardX11'] = 'no' # same here
config['DEFAULT']['ForwardX11'] = 'yes'
with open('example.ini', 'w') as configfile:
config.write(configfile)
1 import configparser 2 3 config = configparser.ConfigParser() 4 5 #---------------------------------------------查 6 print(config.sections()) #[] 7 8 config.read('example.ini') 9 10 print(config.sections()) #['bitbucket.org', 'topsecret.server.com'] 11 12 print('bytebong.com' in config)# False 13 14 print(config['bitbucket.org']['User']) # hg 15 16 print(config['DEFAULT']['Compression']) #yes 17 18 print(config['topsecret.server.com']['ForwardX11']) #no 19 20 21 for key in config['bitbucket.org']: 22 print(key) 23 24 # user 25 # serveraliveinterval 26 # compression 27 # compressionlevel 28 # forwardx11 29 30 31 print(config.options('bitbucket.org'))#['user', 'serveraliveinterval', 'compression', 'compressionlevel', 'forwardx11'] 32 print(config.items('bitbucket.org')) #[('serveraliveinterval', '45'), ('compression', 'yes'), ('compressionlevel', '9'), ('forwardx11', 'yes'), ('user', 'hg')] 33 34 print(config.get('bitbucket.org','compression'))#yes 35 36 37 #---------------------------------------------删,改,增(config.write(open('i.cfg', "w"))) 38 39 40 config.add_section('albert') # 添加块 41 42 config.remove_section('topsecret.server.com') # 删块 43 config.remove_option('bitbucket.org','user') # 删块内的键值对 44 45 config.set('albert','k1','11111') # 给albert这个块添加键值对 46 47 config.write(open('i.cfg', "w")) # 修改完需要重新写入
hashlib模块
用于加密相关操作,3.x里代替了md5模块和sha模块,主要提供SHA1,SHA224,SHA256,SHA384,SHA512,MD5算法
import hashlib
m=hashlib.md5()# m=hashlib.sha256()
m.update('hello'.encode('utf8'))
print(m.hexdigest()) # 5d41402abc4b2a76b9719d911017c592
m.update('alvin'.encode('utf8')) # 在hello的基础上在给alvin加密
print(m.hexdigest()) # 92a7e713c30abbb0319fa07da2a5c4af
m2 = hashlib.md5()
m2.update('helloalvin'.encode('utf8'))
print(m2.hexdigest()) # 92a7e713c30abbb0319fa07da2a5c4af
以上加密算法虽然很厉害,但存在缺陷,即:通过撞库可以反解,所以,有必要对加密算法中添加自定义key再来做加密
import hashlib
# ######## 256 ######## 算法更复杂,用的时间自然增加
hash = hashlib.sha256('898oaFs09f'.encode('utf8')) # 防止撞库,加盐
hash.update('alvin'.encode('utf8'))
print(hash.hexdigest()) # e79e68f070cdedcfe63eaf1a2e92c83b4cfb1b5c6bc452d214c1b7e77cdfd1c7
Python还有一个hmac模块,它内部对我们创建key和内容再进行处理然后再加密
import hmac
h = hmac.new('alvin'.encode('utf8'))
h.update('hello'.encode('utf8'))
print(h.hexdigest())# 320df9832eab4c038b6c1d7ed73a5940
logging模块
一、简单应用
import logging
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message')
输出:
WARNING:root:warning message
ERROR:root:error message
CRITICAL:root:critical message
可见,默认情况下Python的logging模块将日志打印到标准输出中,且只显示大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL>ERROR>WARNING>INFO>DEBUG>NOTSET)
,默认的日志格式为日志级别:logger名称:用户输出消息
二、灵活配置日志级别,日志格式,输出位置
import logging
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s', # 文字格式
datefmt='%a, %d %b %Y %H:%M:%S', # 日期格式
filename='F:\PyCharmProject\\fullstack_s3\day23\\test.log', # 文件保存路径
filemode='w' # 写模式
)
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message')
查看输出:
Sun, 22 Apr 2018 13:57:33 logging_module.py[line:18] DEBUG debug message
Sun, 22 Apr 2018 13:57:33 logging_module.py[line:19] INFO info message
Sun, 22 Apr 2018 13:57:33 logging_module.py[line:20] WARNING warning message
Sun, 22 Apr 2018 13:57:33 logging_module.py[line:21] ERROR error message
Sun, 22 Apr 2018 13:57:33 logging_module.py[line:22] CRITICAL critical message
可见在logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open('test.log','w')),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
三、logger对象
上述几个例子中我们了解到了logging.debug()、logging.info()、logging.warning()、logging.error()、logging.critical()(分别用以记录不同级别的日志信息),logging.basicConfig()(用默认日志格式(Formatter)为日志系统建立一个默认的流处理器(StreamHandler),设置基础配置(如日志级别等)并加到root logger(根Logger)中)这几个logging模块级别的函数,另外还有一个模块级别的函数是logging.getLogger([name])(返回一个logger对象,如果没有指定名字将返回root logger)
先看一个最简单的过程:
import logging
logger = logging.getLogger()
# 创建一个handler,用于写入日志文件
fh = logging.FileHandler('test1.log')
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # 设置日志格式
fh.setFormatter(formatter)
ch.setFormatter(formatter)
logger.addHandler(fh) #logger对象可以添加多个fh和ch对象
logger.addHandler(ch)
logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
先简单介绍一下,logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。
(1)
Logger是一个树形层级结构,输出信息之前都要获得一个Logger(如果没有显示的获取则自动创建并使用root Logger,如第一个例子所示)
logger = logging.getLogger()返回一个默认的Logger也即root Logger,并应用默认的日志级别、Handler和Formatter设置。
当然也可以通过Logger.setLevel(lel)指定最低的日志级别,可用的日志级别有logging.DEBUG、logging.INFO、logging.WARNING、logging.ERROR、logging.CRITICAL。
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical()输出不同级别的日志,只有日志等级大于或等于设置的日志级别的日志才会被输出。
logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
只输出了
2018-04-22 14:00:00,222 - root - WARNING - logger warning message
2018-04-22 14:00:00,223 - root - ERROR - logger error message
2018-04-22 14:00:00,224 - root - CRITICAL - logger critical message
从这个输出可以看出logger = logging.getLogger()返回的Logger名为root。这里没有用logger.setLevel(logging.Debug)显示的为logger设置日志级别,所以使用默认的日志级别WARNIING,故结果只输出了大于等于WARNIING级别的信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号