Python成长之路【第二篇】:Python基本数据类型
运算符
一、算数运算:

二、比较运算:

三、赋值运算:
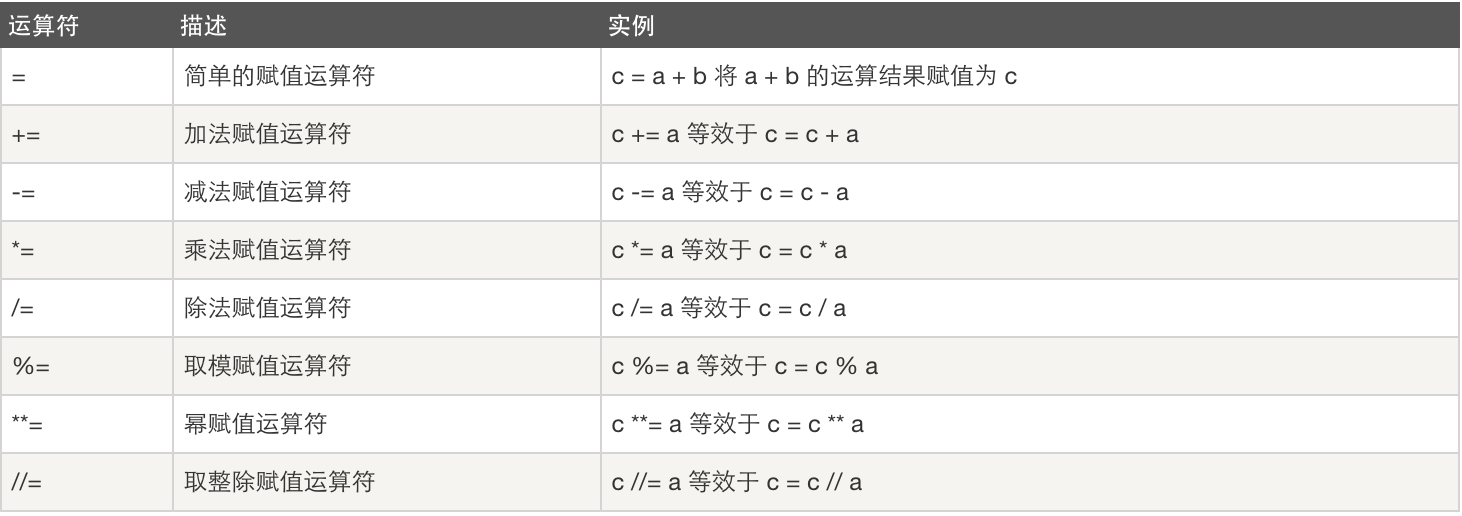
四、逻辑运算:

五、成员运算:

基本数据类型
一、数字
数字:int(整型)
必须掌握:int()
# 例: # a = "123" # print(type(a),a) #输出:<class 'str'> 123 # b = "456" # c = int(b) # print(type(c),c) #输出:<class 'int'> 456 # ps:type代表类型 # 例: # num = "0011" # v = int(num,base = 16) # print(v) # 输出:17 # ps:把"0011当做十六进制转换成整型" # 例: # age = 4 # r = age.bit_length() # print(r) # # 输出:3 # ps:当前数字的二进制数,至少用多少位来表示
二、字符串
字符串:str
必须掌握:replace/ find/ join/ strip/ startswith/ split/ upper/ lower/ format


1 # 字符串一旦创建就不可修改,一旦修改或拼接,都会重新生成字符串 2 3 # 例: 4 # test = "albert" 5 # a = test.capitalize() 6 # print(a) 7 # 输出:Albert 8 # ps:首字母大写 9 10 # 例: 11 # test = "albert" 12 # a = test.upper() 13 # print(a) 14 # 输出:ALBERT 15 # ps:变大写 16 17 # 例: 18 # test = "ALBERT" 19 # a = test.casefold() 20 # print(a) 21 # 输出:albert 22 # ps:所有字母变小写,很多未知的字符也可以变小写 23 24 # b = test.lower() 25 # print(b) 26 # 输出:albert 27 # ps:所有字母变小写 28 29 # 例: 30 # test = "albert" 31 # a = test.center(20,"*") 32 # print(a) 33 # 输出:*******albert******* 34 # ps:设置宽度,并将内容居中,*为空白位置填充,可有可无,只能设置一个字符 35 36 # 例: 37 # test = "albert" 38 # a = test.count("a") 39 # print(a) 40 # 输出:1 41 # ps:去字符串中寻找,寻找子序列出现的次数 42 43 # 例: 44 # test = "albert" 45 # a = test.count("t",2,6) 46 # print(a) 47 # 输出:1 48 # ps:2为起始位置,6为结束位置,固定索引去寻找子序列出现的次数 49 50 # 例: 51 # test = "albert" 52 # a = test.startswith("b") 53 # print(a) 54 # 输出:False 55 # ps:返回布尔值,判断字符串是不是以"b"开头的 56 57 # test = "albert" 58 # a = test.endswith("b") 59 # print(a) 60 # 输出:False 61 # ps:返回布尔值,判断字符串是不是以"b"结尾的 62 63 # 例: 64 # test = "albert" 65 # a = test.find("t") 66 # print(a) 67 # 输出:5 68 # ps:返回索引值,-1代表没找到 69 70 # test = "albert" 71 # a = test.find("t",2,5) 72 # print(a) 73 # 输出:-1 74 # ps:2代表起始索引,5代表结尾索引,左包括右不包括 >= < 75 76 # 例: 77 # test = "i am {name},age{a}" 78 # print(test) 79 # a = test.format(name = "albert",a = 19) 80 # print(a) 81 # 输出:i am {name},age{a} 82 # i am albert,age19 83 # ps:name和a相当于占位符,用来替换 84 85 # test = "i am {0},age {1}" 86 # print(test) 87 # a = test.format("albert","19") 88 # print(a) 89 # 输出:i am {0},age {1} 90 # i am albert,age 19 91 # ps:数字代表出现顺序,填入的参数按占位符数字进行替换 92 93 # test = "i am {name},age {a}" 94 # a = test.format_map({"name":"albert","a":19}) 95 # print(a) 96 # 输出:i am albert,age 19 97 # ps:传入一个字典 98 99 # 例: 100 # test = "123" 101 # a = test.isalnum() 102 # print(a) 103 # 输出:True 104 # ps:返回布尔值,判断字符中是否只包含 字母和数字 105 # 只有字母或数字也会返回True 106 107 # 例: 108 # test = "Albert" 109 # a = test.islower() 110 # print(a) 111 # 输出:False 112 # ps:返回布尔值,判断是否全部为小写 113 114 # test = "Albert" 115 # a = test.isupper() 116 # print(a) 117 # 输出:False 118 # ps:返回布尔值,判断是否全部为大写 119 120 # 例: 121 # test = "Al\tber\nt" 122 # a = test.isprintable() 123 # print(a) 124 # 输出:False 125 # ps:返回布尔值,判断是否存在不可显示字符,Flase代表有不可显示字符,\t代表空格,\n代表换行 126 127 # 例: 128 # test = "" 129 # a = test.isspace() 130 # print(a) 131 # 输出:False 132 # ps:空不代表空格 133 134 # 例: 135 # test = "Albert" 136 # a = test.ljust(20,"*") 137 # print(a) 138 # 输出:Albert************** 139 # ps:20代表总长度,Albert显示完不够20的位置用*补,从左边开始 140 141 # test = "Albert" 142 # a = test.rjust(20,"*") 143 # print(a) 144 # 输出:**************Albert 145 # ps:20代表总长度,Albert显示完不够20的位置用*补,从右边开始 146 147 # 例: 148 # test = "Albert" 149 # a = len(test) 150 # print(a) 151 # 输出:6 152 # ps:统计字符串元素的个数 153 154 # 例: 155 # test = "abcdefghjgklmnopqrstuvwxyz" 156 # 先整一个字符串 157 # m = str.maketrans("aeiou","12345") 158 # 用maketrans做一个对应关系 159 # new_test = test.translate(m) 160 # 用translate将对应关系和字符串进行替换 161 # print(new_test) 162 # 输出:1bcd2fghjgklmn4pqrst5vwxyz 163 # ps:注意逻辑,还有对象 164 165 # 例: 166 # test = "AlbertAlbert" 167 # a = test.replace("er","23") 168 # print(a) 169 # 输出:Alb23tAlb23t 170 # ps:将er替换成23,默认全部替换 171 172 # test = "AlbertAlbert" 173 # a = test.replace("er","23",1) 174 # print(a) 175 # 输出:Alb23tAlbert 176 # ps:将er替换成23,1这个参数代表替换几个 177 178 # 例: 179 # test = "Albsthjhjkssds" 180 # a = test.split("s",2) 181 # print(v) 182 # 输出:['Alb', 'thjhjk', 'sds'] 183 # ps:按照s分割,分割2次,无法获取s 184 185 # test = "Albsthjhjkssds" 186 # a = test.rsplit("s",2) 187 # print(v) 188 # 输出:['Albsthjhjks', 'd', ''] 189 # ps:从右边开始,按照s分割,分割2次,无法获取s 190 191 # 例: 192 # test = "dshjkhklk\ndjshjkjk\nsjdkl" 193 # a = test.splitlines(True) 194 # print(a) 195 # 输出:['dshjkhklk\n', 'djshjkjk\n', 'sjdkl'] 196 # ps:根据换行分割,可设置是否保留换行,默认为False 197 198 # 例: 199 # test = "xadsadadfss" 200 # a = test.strip("asx") 201 # print(a) 202 # 输出:dsadadf 203 # ps:移除指定字符,优先按最长匹配 204 205 # test = "xadsadadfss" 206 # a = test.rstrip("asx") 207 # print(a) 208 # 输出:xadsadadf 209 # ps:移除指定字符,优先按最长匹配,从右边开始 210 211 # 例: 212 # test = " \n Albert \t " 213 # a = test.strip() 214 # print(a) 215 # 输出:Albert 216 # ps:移除左右 \n \t 空格 217 218 # test = " \n Albert \t " 219 # a = test.lstrip() 220 # print(a) 221 # 输出:Albert 222 # ps:移除左 \n \t 空格 223 224 # test = " \n Albert \t " 225 # a = test.rstrip() 226 # print(a) 227 # 输出: 228 # Albert 229 # ps:移除右 \n \t 空格 230 231 # 例: 232 # test = "Albert" 233 # a = test.swapcase() 234 # print(a) 235 # 输出:aLBERT 236 # ps:大写换小写,小写换大写 237 238 # 例: 239 # test = "Return True IF " 240 # a = test.istitle() 241 # print(a) 242 # 输出:False 243 # ps:返回布尔值,判断是否为标题,只有每个单词首字母大写的字符串才是标题样式 244 245 # test = "shj jdksjkd sj jkopp jl jljlsj" 246 # a = test.title() 247 # print(a) 248 # 输出:Shj Jdksjkd Sj Jkopp Jl Jljlsj 249 # ps:将一个字符串转换成标题,也就是每个单词首字母大写 250 251 # 例: 252 # test = "谁把我灌醉" 253 # a = "_".join(test) 254 # print(a) 255 # 输出:谁_把_我_灌_醉 256 # ps:内部用的循环 257 258 # 例: 259 260 # test = "testsdjlslljj" 261 # a = test.partition("s") 262 # print(a) 263 # 输出:('te', 's', 'tsdjlslljj') 264 # ps:永远只分割成三份,一为分割后左边的字符串,二为以什么字符串分割的字符串,三为分割后右边的字符串 265 266 # test = "testsdjlslljj" 267 # a = test.rpartition("s") 268 # print(a) 269 # 输出:('testsdjl', 's', 'lljj') 270 # ps:从右边开始,永远只分割成三份,一为分割后左边的字符串,二为以什么字符串分割的字符串,三为分割后右边的字符串 271 272 # 例: 273 274 # test = "username\temail\tpasswd\nAlbert\t123456\tqwer" 275 # a = test.expandtabs(20) 276 # print(a) 277 # 输出: 278 # username email passwd 279 # Albert 123456 qwer 280 # ps:输出字符串,遇到\t,计算前方字符串字符数量,不够20个则补齐,遇到\n换行 281 282 # 例: 283 # test = "周Albert2" 284 # a = test.isalpha() 285 # print(a) 286 # 输出:False 287 # ps:返回布尔值,判断是否只有字母和汉字 288 289 # 例: 290 # test = "②" 291 # a = test.isdigit() 292 # print(a) 293 # 输出:True 294 # ps:返回布尔值,可以识别特殊数字 295 296 # 例: 297 # test = "Albert" 298 # a = test[2] 299 # print(a) 300 # 输出:b 301 # ps:切片,根据索引获取字符串元素 302 303 # test = "Albert" 304 # a = test[2:4] 305 # print(a) 306 # 输出:be 307 # ps:切片,根据索引获取字符串元素,2代表起始位置,4代表终止位置,左包右不包,2=< <4 308 309 #############字符串操作>>>必须要记下来的6个基本方法######## 310 311 # join split find strip upper lower
三、列表
列表:list
必须掌握:append/extend/insert >>>索引、切片、循环
# 例: # li = [11,22,33,44] # li.append(55) # li.append("Albert") # li.append(["a","b"]) # li.append((66,77,)) # li.append({"k1":"v1"}) # li.append(True) # print(li) # 输出:[11, 22, 33, 44, 55, 'Albert', ['a', 'b'], (66, 77), {'k1': 'v1'}, True] # ps:追加,可追加数字,字符串,列表,元组,字典,布尔值数据类型 # 例: # li = [11,22,33,44] # li.clear() # print(li) # 输出:[] # ps:清空列表 # 例: # li = [11,22,22,33,44] # v = li.count(22) # print(v) # 输出:2 # ps:计算列表其中一个元素出现的次数 # 例: # li = [11,22,22,33,44] # li.extend([77,"wo"]) # print(li) # 输出:[11, 22, 22, 33, 44, 77, 'wo'] # ps:扩展原列表,参数:可迭代对象,内部利用for循环追加 # 例: # li = [11,22,22,33,44] # v = li.index(33) # print(v) # 输出:3 # ps:获取当前值得索引位置,左边优先 # 例: # li = [11,22,22,33,44] # li.insert(1,99) # print(li) # 输出:[11, 99, 22, 22, 33, 44] # ps:在指定索引位置插入元素,1代表索引,99代表元素 # 例: # li = [11,22,22,33,44] # v = li.pop() # print(li) # print(v) # 输出: # [11, 22, 22, 33] # 44 # ps:删除并可以拿到删除的值,默认删除最后一个 # 例: # li = [11,22,22,33,44] # li.remove(22) # print(li) # 输出:[11, 22, 33, 44] # ps:根据值删除列表元素,左边优先 # 例: # li = [11,22,22,33,44] # li.reverse() # print(li) # 输出:[44, 33, 22, 22, 11] # ps:列表内容反向排序 # 例: # li = [11,22,22,33,44] # li.sort() # print(li) # 输出:[11, 22, 22, 33, 44] # ps:由小到大排序 # li = [11,22,22,33,44] # li.sort(reverse=True) # print(li) # 输出:[44, 33, 22, 22, 11] # ps:由大到小排序 # 例: # li = [11,22,22,33,44] # v = li.copy() # print(v) # 输出:[11, 22, 22, 33, 44] # ps:浅拷贝 # 例: # li = [11,22,22,33,44] # v = 12 in li # print(v) # 输出:False # ps:返回布尔值,判断一个元素是否在列表中 # 例: # li = [11,22,22,33,44] # li[2] = 77 # print(li) # 输出:[11, 22, 77, 33, 44] # ps:通过索引修改列表中的元素 # 例: # li = [11,22,22,33,44] # li[1:3] = [77,88] # print(li) # 输出:[11, 77, 88, 33, 44] # ps:通过切片的方式修改列表中的元素 # 例: # li = ["wo","ai","ni"] # v = "".join(li) # print(v) # 输出:woaini # ps:利用join方法将列表转换成字符串,注意:列表中的元素只有字符串才可以,内部用也是for循环 # 例: # li = [11,22,"12","是"] # s = "" # for i in li: # s += str(i) # print(s) # 输出:112212是 # ps:在列表中既有数字,又有字符串的时候,利用for循环,可以将列表转换成字符串 # 例: # li = [11,22,22,33,44] # del li[3] # print(li) # 输出:[11, 22, 22, 44] # ps:根据索引删除列表中的元素 # 例: # li = [11,22,22,33,44] # del li[2:4] # print(li) # 输出:[11, 22, 44] # ps:通过切片的方式删除列表中的元素 # 例: # li = [11,22,22,33,44] # v = li[3] # print(a) # 输出:33 # ps:通过索引取值 # 例: # li = [11,22,22,33,44] # v = li[2:4] # print(v) # 输出:[22, 33] # ps:通过切片取值 # 例: # li = "艾伯特" # v = list(li) # print(v) # 输出:['艾', '伯', '特'] # ps:字符串转换成列表,内部用的for循环
ps:
1、列表中可以嵌套任何类型
2、索引取值
3、切片取值
4、通过for循环取值
5、通过索引进行修改和删除
6、通过切片进行修改和删除
7、in操作
8、列表,有序,元素可以被修改
四、元组
元组:tuple
必须掌握:索引、切片、循环 一级元素不能被修改
# 例: # tu = (11,22,22,33,44) # v = tu.count(22) # print(v) # 输出:2 # ps:获取指定元素在元组中出现的次数 # 例: # tu = (11,22,22,33,44) # v = tu.index(22) # print(v) # 输出:1 # ps:获取指定元素在元组中的索引,左边优先
ps:
1、索引取值
2、切片取值
3、可for循环
4、可迭代对象
5、元组可转列表,列表可转元组,字符串可转元组
6、元组可通过join转换为字符串(必须全部是字符串)
7、元组也是有序的
8、元组的一级元素不可被修改,不能被增加或者删除,创建元组的时候最后一个参数的后边推荐加一个逗号
五、字典(无序)
字典:dict
必须掌握:get/ update/ keys/ values/ items >>>for,索引,in操作
# 例: # v = dict.fromkeys(["k1",123,"999"],123) # print(v) # 输出:{'k1': 123, 123: 123, '999': 123} # ps:根据序列,创建字典,并指定统一的值 # 例: # dic = { # "k1":"v1", # "k2":"v2" # } # v = dic["k1111"] # print(v) # 输出:报错 # ps:根据key取值,key不存在会报错 # dic = { # "k1":"v1", # "k2":"v2" # } # v = dic.get("k11",123) # print(v) # 输出:123 # ps:根据key取值,key不存在,将会返回第二个参数 # 例: # dic = { # "k1":"v1", # "k2":"v2" # } # v = dic.pop("k111",123) # print(v) # 输出:123 # ps:key不存在会返回第二个参数 # 例: # dic = { # "k1":"v1", # "k2":"v2" # } # k, v = dic.popitem() # print(k, v) # 输出:k2 v2 # ps:随机删除键值对 # 例: # dic = { # "k1":"v1", # "k2":"v2" # } # v = dic.setdefault("k111","123") # print(dic,v) # 输出:{'k1': 'v1', 'k2': 'v2', 'k111': '123'} 123 # ps:已存在,不设置,获取当前key对应的值。不存在,设置,获取当前key的值 # 例: # dic = { # "k1":"v1", # "k2":"v2" # } # dic.update({"k1":"1111","k3":123}) # print(dic) # 输出:{'k1': '1111', 'k2': 'v2', 'k3': 123} # ps:第一种更新字典值的方式,有则修改,无则创建 # 例: # dic = { # "k1":"v1", # "k2":"v2" # } # dic.update(k1=123,k3=345,k5="sds") # print(dic) # 输出:{'k1': 123, 'k2': 'v2', 'k3': 345, 'k5': 'sds'} # ps:第二种更新字典值的方式,有则修改,无则创建 # 例: # dic = { # "k1":"v1", # "k2":"v2" # } # for i in dic.items(): # print(i) # 输出: # ('k1', 'v1') # ('k2', 'v2') # ps:同时获取key和value
ps:
1、字典的value可以是任何值
2、列表,字典不能作为字典的key
3、字典是无序的
4、字典支持del
5、key不能重复,重复会只保留一个
6、布尔值True和1会重复 False和0会重复
六、布尔值
必须掌握:None/ ""/ ()/ []/ {}/ 0/ >>>都是False
# 例: # v = "1" # a = bool(v) # print(a) # 输出:True # ps:返回布尔值
七、set(集合)- 可用三种方式分类
一、可变不可变
1、可变:列表,字典
2、不可变:字符串、数字、元组
二、访问顺序
1、直接访问:数字
2、顺序访问:字符串,列表,元组
三、存放元素个数
1、容器类型:列表、元组、字典
2、原子:数字、字符串
1、集合的定义:由不同元素组成的集合,集合中是一组无序排列的可hash值,可以作为字典的key。 2、特性:集合的目的是将不同的值存放到一起,不同的集合间用来做关系运算,无需纠结于集合中单个值 3、集合的创建: {1,2,3,1} 或 定义可变集合set >>> set_test=set('hello') >>> set_test {'l', 'o', 'e', 'h'} 改为不可变集合frozenset >>> f_set_test=frozenset(set_test) >>> f_set_test frozenset({'l', 'e', 'h', 'o'}) 4、集合常用操作:关系运算 in not in == != <,<= >,>= |,|=:合集 &.&=:交集 -,-=:差集 ^,^=:对称差分
1 # set(集合)方法 2 # 集合特点:无序,去重 3 4 # 创建不可变集合 5 # 例: 6 # a = frozenset("hello") 7 # print(a) 8 # 输出:frozenset({'e', 'h', 'o', 'l'}) 9 10 # 例: 11 # s = {1,2,3,4,5} 12 # s.add("s") 13 # print(s) 14 # 输出:{1, 2, 3, 4, 5, 's'} 15 16 # 例: 17 # s = {1,2,3,4,5} 18 # s.clear() 19 # print(s) 20 # 输出:set() 21 22 # 例: 23 # s = {1,2,3,4,5} 24 # s1 = s.copy() 25 # print(s1) 26 # 输出:{1, 2, 3, 4, 5} 27 28 # 例: 29 # s = {"s", 1, 2, 3, 4, 5} 30 # s.pop() 31 # print(s) 32 # 输出:{2, 3, 4, 5, 's'} 33 # ps:随机删除,因为集合是无序的 34 35 # 例: 36 # s = {"s", 1, 2, 3, 4, 5} 37 # s.remove("s") 38 # print(s) 39 # 输出:{1, 2, 3, 4, 5} 40 # ps:删除元素不存在会报错 41 42 # 例: 43 # s = {"s", 1, 2, 3, 4, 5} 44 # s.discard("sdasdas") 45 # print(s) 46 # 输出:{1, 2, 3, 4, 5, 's'} 47 # ps:删除元素不存在,不会报错 48 49 # 将列表转换为集合 50 # 例: 51 # python_l = ["lcg", "szw", "zjw", "lcg"] 52 # p_s = set(python_l) 53 # print(p_s) 54 # 输出:{'lcg', 'szw', 'zjw'} 55 56 # 交集 57 # 例: 58 # a = {'lcg', 'szw', 'zjw', "lcg"} 59 # b = {"lcg", "szw"} 60 # 61 # print(a.intersection(b)) #和 & 符号用法是一样的 62 # print(a&b) 63 # 输出: 64 # {'szw', 'lcg'} 65 # {'szw', 'lcg'} 66 # ps:交集就是两方都有的参数 67 68 # 并集 69 # 例: 70 # a = {'lcg', 'szw', 'zjw', "lcg"} 71 # b = {"lcg", "szw"} 72 # 73 # print(a.union(b)) # 和 | 符号用法是一样的 74 # print(a|b) 75 # 输出: 76 # {'lcg', 'szw', 'zjw'} 77 # {'lcg', 'szw', 'zjw'} 78 # ps:计算的是 a 和 b 加在一起有多少不重复的元素 79 80 # 差集 81 # 例: 82 # a = set([1, 2, 3, 4, 5]) 83 # b = set([5, 6, 7, 8, 9]) 84 # print(a-b) #a 有 b 没有的 85 # print(a.difference(b)) 同 a - b 用法一样 86 # print(b-a) #b 有 a 没有的 87 # print(b.difference(a)) 同 b - a 用法一样 88 # 输出: 89 # {1, 2, 3, 4} 90 # {1, 2, 3, 4} 91 # {8, 9, 6, 7} 92 # {8, 9, 6, 7} 93 94 # 交叉补集 95 # 例: 96 # a = set([1, 2, 3, 4, 5]) 97 # b = set([5, 6, 7, 8, 9]) 98 # print(a.symmetric_difference(b)) 同 a ^ b 用法一样 99 # print(a^b) 100 # 输出: 101 # {1, 2, 3, 4, 6, 7, 8, 9} 102 # {1, 2, 3, 4, 6, 7, 8, 9} 103 # ps:计算 a 和 b 加在一起没有重复过的参数 104 105 # 以上是必须练熟的操作************* 106 107 # 差集高阶用法之重新赋值 108 # 例: 109 # a = set([1, 2, 3, 4, 5]) 110 # b = set([5, 6, 7, 8, 9]) 111 # a.difference_update(b) 112 # print(a) 113 # 输出:{1, 2, 3, 4} 114 # ps:操作完后重新赋值 115 116 # 例: 117 # s1 = set([1, 2]) 118 # s2 = set([3, 5]) 119 # print(s1.isdisjoint(s2)) 120 # 输出:True 121 # ps:返回布尔值,没有交集返回True,有交集返回False 122 123 # 例: 124 # a = {1, 2} 125 # b = {1, 2, 3} 126 # print(a.issubset(b)) # 判断 a 是不是 b 的子集 127 # print(b.issubset(a)) # 判断 b 是不是 a 的子集 128 # 输出: 129 # True 130 # False 131 132 # 例: 133 # a = {1, 2} 134 # b = {1, 2, 3} 135 # print(b.issuperset(a)) 136 # 输出:True 137 # ps:返回布尔值,判断 b 是不是 a 的父级 138 139 # 例: 140 # a = {1, 2, 3} 141 # a.update([3, 4, 5]) 142 # print(a) 143 # 输出:{1, 2, 3, 4, 5} 144 # ps:向 a 中传值,可迭代对象也可以传 145 146 # 例: 147 # a = {1, 2, 3} 148 # print(a.union([3, 4, 5])) 149 # print(a) 150 # 输出: 151 # {1, 2, 3, 4, 5} 152 # {1, 2, 3} 153 # ps:并不更新 a 中的值 154 155 # 例: 156 # a = [1, 2, 3, 4, 4, 5] 157 # print(list(set(a))) 158 # 输出:[1, 2, 3, 4, 5] 159 # ps:将列表转换为集合去重,然后再转换为列表
补充:
一、编码
unicode、utf8、gbk 之间的关系
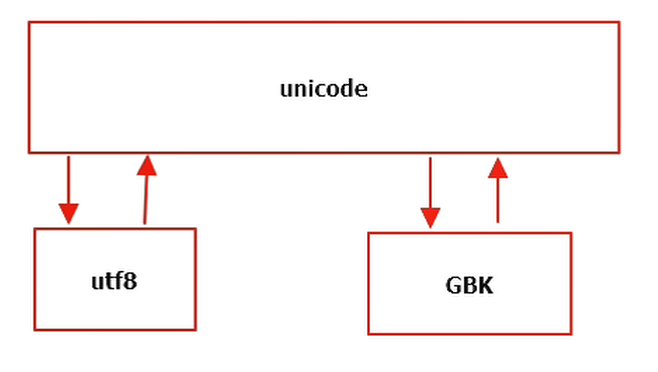
在utf8中一个汉字用三个字节表示,在gbk中一个汉字用两个字节表示
二、字节、位
八个二进制位为一个字节,字节的单位为Byte,所以一个字节是1B
三、range用法
# 例: # test = range(0,20,5) # for i in test: # print(i) # 输出: # 0 # 5 # 10 # 15 # ps:创建连续数字,通过步长指定不连续间隔 # 例: # test = "Albert" # for i in test: # print(i) # 输出: # A # l # b # e # r # t # ps:内部用的循环
小练习题
小练习(1):自定义一个字符串,输出字符串中的每一个字符
# test = "你是风儿我是沙" # index = 0 # while index < len(test): # print(test[index]) # index += 1
小练习(2):用户输入一个字符串,输出对应索引和字符
# test = input(">>>")
# a = len(test)
# for i in range(a):
# print(i,test[i])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号