
爬取所有教师信息
此篇主要有
1、XPath解析库的应用
2、re正则表达式的应用
3、selenium的应用,以及无窗口运行。
4、post请求
5、pyinstaller生成exe文件->https://www.cnblogs.com/albert-yzp/p/10186561.html
这个程序是爬去西电所有老师的基本信息 主页:https://faculty.xidian.edu.cn/
源代码:
import requests#这个库用来获取网页内容 from lxml import etree#这个库用来解析网页内容,方便提取需要的信息 import re#这个库用来正则匹配,也是用来提取需要的信息。 import pandas as pd#这个库是用来处理数据,主要为了提取出点赞数前十的老师 #此函数用来获取学院的名字,链接。 #输入:主页urlhttps://faculty.xidian.edu.cn/ #输出:一个字典,key为学院名字,value为不同学院的url链接。 def get_academies(url): response=requests.get(url)#获取网页内容 XpathAnalyze=etree.HTML(response.text)#解析网页结构 urls=XpathAnalyze.xpath('/html/body/div[6]/div/div/div[2]/ul[1]/li[*]/a/@href')#获取所有学院的链接 names=XpathAnalyze.xpath('/html/body/div[6]/div/div/div[2]/ul[1]/li[*]/a/@title')#获取所有学院的名字 academies = {}#此字典用来完整的保存学院的名字,链接信息。 for i in range(len(names)): academies[names[i]] = urls[i + 1]#遍历所有学院,组成字典 return academies #将字典返回 #此函数用来获取学院老师的总页数 #输入:学院的url #输出:int型数字,学院老师的总页数 def get_page_total_numbers(url): response = requests.get(url)#获取学院主页内容 totalNumbers = re.search('totalpage=(\d+)&PAGENUM=', response.text)#利用正则表达式找到总页数 return int(totalNumbers.group(1))#返回int型总页数 #此函数用来获取一页中所有老师的url #输入:一页的url #输出:此页中所有老师主页的url def get_all_teachers(url): response = requests.get(url)#获取当前页的网页内容 XpathAnalyze = etree.HTML(response.text)#解析网页 return XpathAnalyze.xpath('/html/body/div[5]/div/div/div[3]/ul/li[*]/a/@href')#找到所有老师主页的url并返回 #此函数用来提取老师主页的点击次数 #输入:老师主页的网页内容 #输出:字符串,老师主页的点击次数 def get_times(resoposeText): account_homepageid=re.search(r"account':'(\d+)','homepageid':(\d+),",resoposeText)#提取post表单所需要的信息 data={ #构建post表单,因为老师主页的点击次数是js动态获取的,所以必须用post才能获取到。 'basenum': 0, 'len': 10, 'type': 'homepage_total', 'account': 0, 'homepageid': 0, 'ac': 'getHomepageClickByType', } if account_homepageid: #此处加个判断,因为可能上面没找到post表单所需要的信息 data['account']=int(account_homepageid.group(1))#找到了才正常把表单信息补充完整 data['homepageid']=int(account_homepageid.group(2)) response=requests.post('https://faculty.xidian.edu.cn/system/resource/tsites/click.jsp',data=data)#提交post请求 return response.text[10:20].lstrip('0')#提取出返回信息中的老师主页的点击次数并返回 #此函数用来获取老师主页中所有的基本信息 #输入:老师主页的url #输出:字典,老师的基本信息 def get_teacher_detail(url): try:#捕捉异常,因为在调试的过程中发现,此处获取老师主页内容的时候会抛出异常 response = requests.get(url)#获取老师主页网页内容 except requests.exceptions.ChunkedEncodingError:#如果出现异常,就重新进入这个函数,反复重试。相当于点刷新 return get_teacher_detail response.encoding = 'utf-8'#修改网页字符编码为'utf-8',因为Python默认'utf-8',不修改的话或显示乱码。 times = get_times(response.text)#调用上面的函数获取老师主页点击次数 XpathAnalyze = etree.HTML(response.text)#解析网页 name = XpathAnalyze.xpath('/html/body/div[2]/div/div[3]/div[1]/div[1]/div[1]/span/text()')#提取老师姓名 details = []#这个列表用来储存所有获取到的老师基本信息 for i in range(1, 16):#因为老师的基本信息最多可以有15个,所以,我循环获取15次,能保证获取到所有老师信息 detail = temp = XpathAnalyze.xpath('/html/body/div[2]/div/div[3]/div[1]/div[2]/div/p[' + str(i) + ']/text()')#获取老师的基本信息 if detail:#如果成功的获取到了 detail = detail[0].replace('\n', '')#去除所有换行符 detail = detail.replace(' ', '')#去除所有空格 details.append(detail)#添加到上面新建的列表中 detailsResult = {#此字典用来统一保存老师的所有基本信息,如果某项基本信息没有,就置为空。 '姓名': '', '职称': '', '性别': '', '出生年月': '', '毕业院校': '', '学历': '', '学位': '', '在职信息': '', '所在单位': '', '入职时间': '', '所属院系': '', '职务': '', '学科': '', '办公地点': '', '联系方式': '', '点击次数': ''} if name:#如果成功获取到了老师姓名 detailsResult['姓名'] = name[0]#报存到字典中 if details:#如果成功获取到了其他基本信息 detailsResult['职称'] = details[0]#保存职称,(因为第一个肯定为职称,所以直接赋值) detailsResult['点击次数'] = times.lstrip('0')#保存点击次数 for detail in details[1:]:#报错其他基本信息 split = detail.find(':')#获取key,value的分割点 detailsResult[detail[:split]] = detail[split + 1:]#保存到字典 return detailsResult#将此老师基本信息返回 #主函数开始 #函数从此处开始运行,上面相当于声明函数。 mainUrl='https://faculty.xidian.edu.cn/'#这个是网站的主页url。 baseStr='totalpage={}&PAGENUM={}&'#这个字符串为了方便构建不同页数的网址,相当于翻页 comma=','#这个字符串为了方便保存csv文件时使用 allAcademies=get_academies(mainUrl)#调用函数获取所有学院名字与url for name,url in allAcademies.items():#遍历所有学院 if name=='电子工程学院':#这个是为了只爬电院,如果想爬整个学校,这一行注释即可。 nowTeacherNumber=1#这个变量用来保存爬到第几个老师了 academiesUrl=mainUrl+url#此学院主页的url totalPageNumbers=get_page_total_numbers(academiesUrl)#调用函数获取学院教师的总页数 with open(name+'.csv','w') as f:#打开csv文件,用来保存爬取到的所有老师的信息,以学院名命名 for pageNumber in range(1,totalPageNumbers+1):#遍历所有页数 pageUrl=academiesUrl[:41]+baseStr.format(str(totalPageNumbers),str(pageNumber))+academiesUrl[41:]#不同页数的url print('正在爬取' + name + '第' + str(pageNumber) + '页:', pageUrl)#打印状态信息,正在爬取哪个学院第几页 allTeachersUrls=get_all_teachers(pageUrl)#调用函数获取到当前页的所有老师的url for teacherUrl in allTeachersUrls:#遍历当前所有老鼠的的url print('正在爬取' + name + '第' + str(nowTeacherNumber) + '位老师:',teacherUrl)#输出状态信息,正在爬取哪个学院第几个老师 teachersdetails=get_teacher_detail(teacherUrl)#调用函数获取老师的基本信息 if(nowTeacherNumber==1): f.write(comma.join(teachersdetails.keys())+'\n')#csv文件第一行保存的是’姓名职称等’这一列保存的什么信息 if(teachersdetails['姓名']): f.write(comma.join(teachersdetails.values()) + '\n')#保存该老师的所有基本信息 nowTeacherNumber=nowTeacherNumber+1#正在爬取第几个老师数加1 print("数据爬取完成,接下来对点击次数进行排序") for academy in allAcademies.keys():#遍历所有学院 if academy == '电子工程学院':#这一个也是,为了值处理电院,如果想处理所有学院,把这一行注释掉 academyData=pd.read_csv(open(academy+'.csv'),error_bad_lines=False)#读取csv文件的所有老师信息 academyData_Sorted = academyData.sort_values(by='点击次数', ascending=False)#按照点击次数排序 academyData_Sorted.to_csv(academy+'(sorted).csv', index=False, sep=',', encoding="gbk")#将排序完的数据也保存为csv文件,命名为学院名称加(sorted) print(academy+'点击次数前10位老师') for i in range(10):#打印输出点击次数前十位老师 print('第'+str(i+1),'名:',academyData_Sorted.iloc[i]['姓名'], academyData_Sorted.iloc[i]['点击次数']) while(input("输入exit退出")!='exit'): continue
1、re的使用
account_homepageid=re.search(r"account':'(\d+)','homepageid':(\d+),",resoposeText)
(1)\d+是匹配多个数字
(2)用account_homepageid.groups()访问匹配到的结果
(3)re.search()是匹配第一个,re.findall()是匹配所有符合的结果。参数是差不多的。
2、XPath的使用
from lxml import etree XpathAnalyze = etree.HTML(response.text)#解析网页 XpathAnalyze.xpath('/html/body/div[5]/div/div/div[3]/ul/li[*]/a/@href')#寻找需要的内容
用这个模板,能爬取绝大部分静态网页内容
3、selenium的使用
from selenium import webdriver option = webdriver.ChromeOptions() option.add_argument('headless')#option 是用来设置不弹出chrome界面的 driver = webdriver.Chrome(chrome_options=option) driver.get(url) response = driver.page_source#获得动态加载后的网页源代码 #在进行解析就行了 XpathAnalyze = etree.HTML(response) #不过driver有自己的CSS选择器,不太好记,我也就没用
selenium能解决几乎所有动态加载的的网页,完全能做到看到什么爬什么。
但是selenium确实运行太慢了。。。。所以还是要优先考虑分析网络请求。看看有没有动态加载的包储存的是我们需要的内容
下面的post请求就是一种获取动态加载内容的方法
4、post请求
data={ #构建post表单,因为老师主页的点击次数是js动态获取的,所以必须用post才能获取到。
'basenum': 0,
'len': 10,
'type': 'homepage_total',
'account': 0,
'homepageid': 0,
'ac': 'getHomepageClickByType',
}
response=requests.post('https://faculty.xidian.edu.cn/system/resource/tsites/click.jsp',data=data)#提交post请求
1、找到需要的内容所在的位置
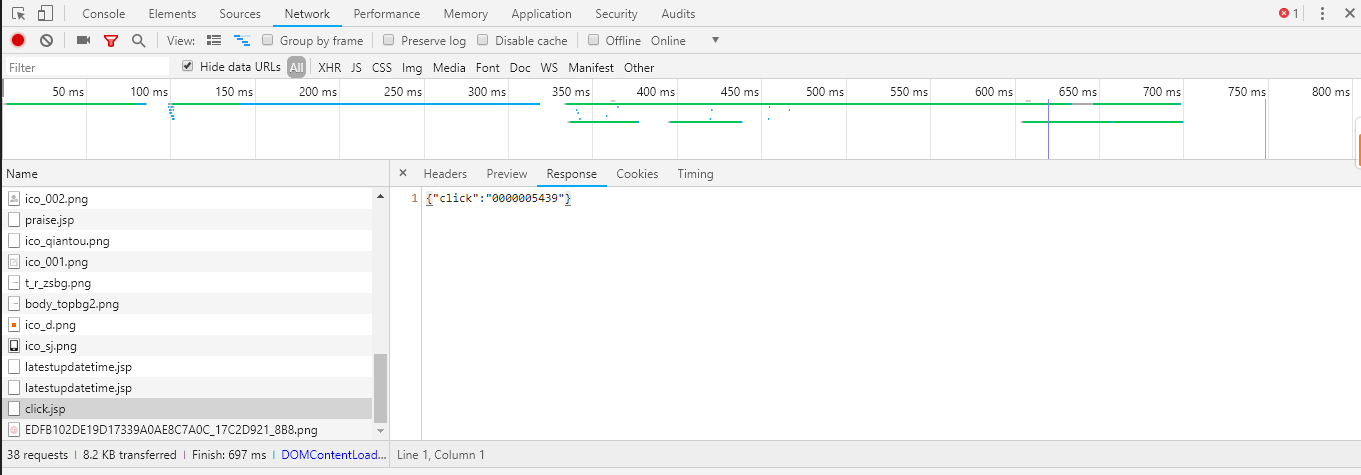
2、分析请求

3、可以看到是向一个固定的网站提交post请求
查看post表单,就是上面代码里的data
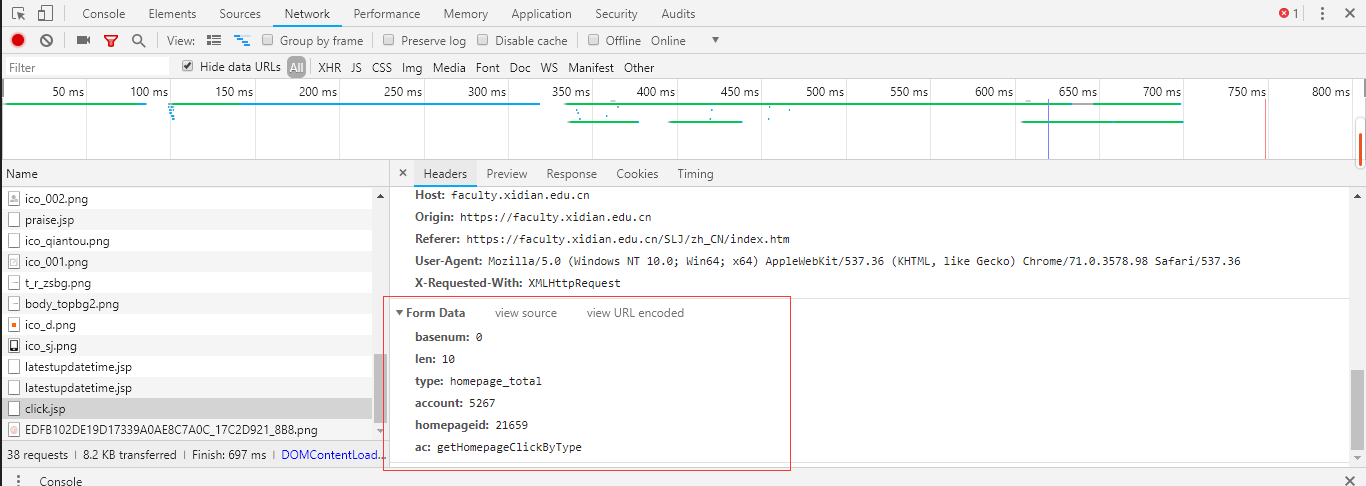
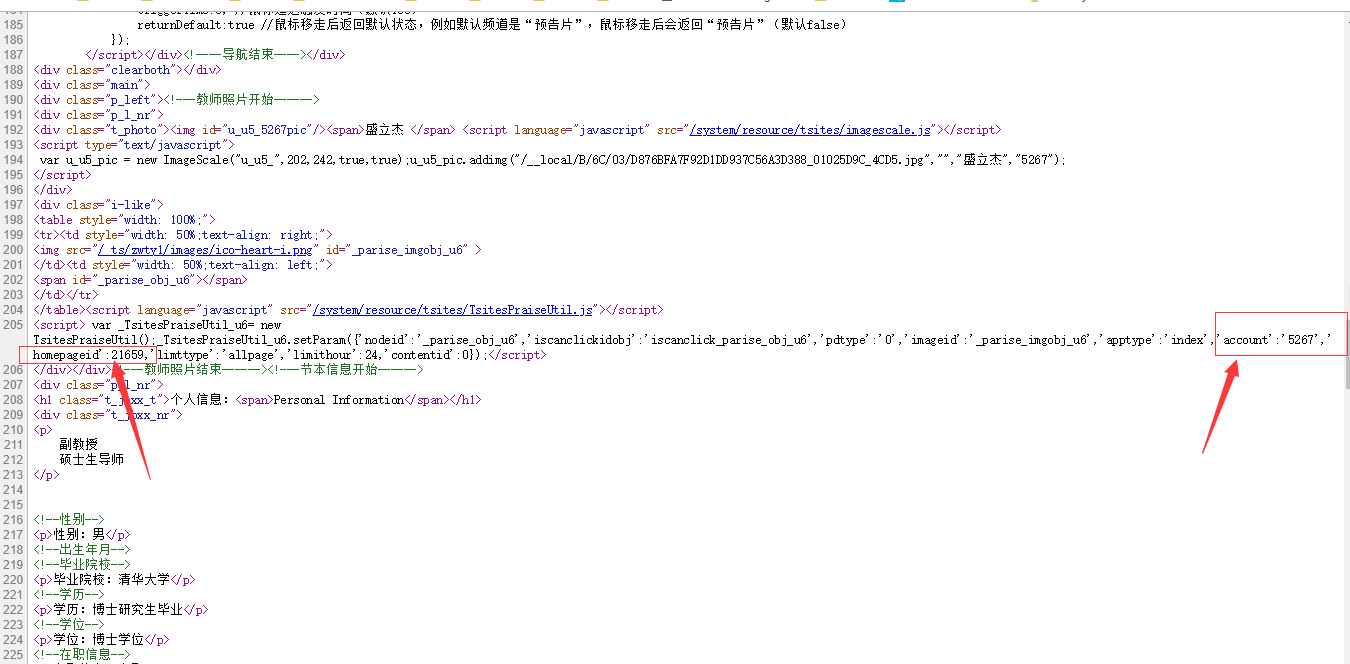
4、经分析不同教师主页的post表单,发现只是account以及homepageid不一样。
而这两个参数可以在教师主页的源代码里的js里的找到
将他们提取出来赋值再提交post请求就可以获得自己想要的内容啦
这个程序是给别人写的,花了半天多点的时间赚了50块钱,虽然有点少,但是我也学到了很多东西。也是我第一次用写代码赚钱哦。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号