

02 2023 档案
摘要:前言 神经网络的历史和背景 神经网络是一种模拟人类神经系统的计算模型,它由大量简单的神经元单元组成,通过它们之间的连接和传递信息来模拟人脑的学习和推理过程。神经网络起源于上世纪40年代,当时Warren McCulloch和Walter Pitts提出了一种可模拟生物神经元的数学模型,这是第一个神经
阅读全文
摘要:I.前言 介绍RNN的概念和应用 RNN(Recurrent Neural Network,循环神经网络)是一类能够处理序列数据的神经网络,它在处理时考虑了之前的状态,因此能够对序列数据中的每个元素进行建模和预测。 RNN的应用非常广泛,特别是在自然语言处理和时间序列分析方面。以下是RNN在各个领域
阅读全文
摘要: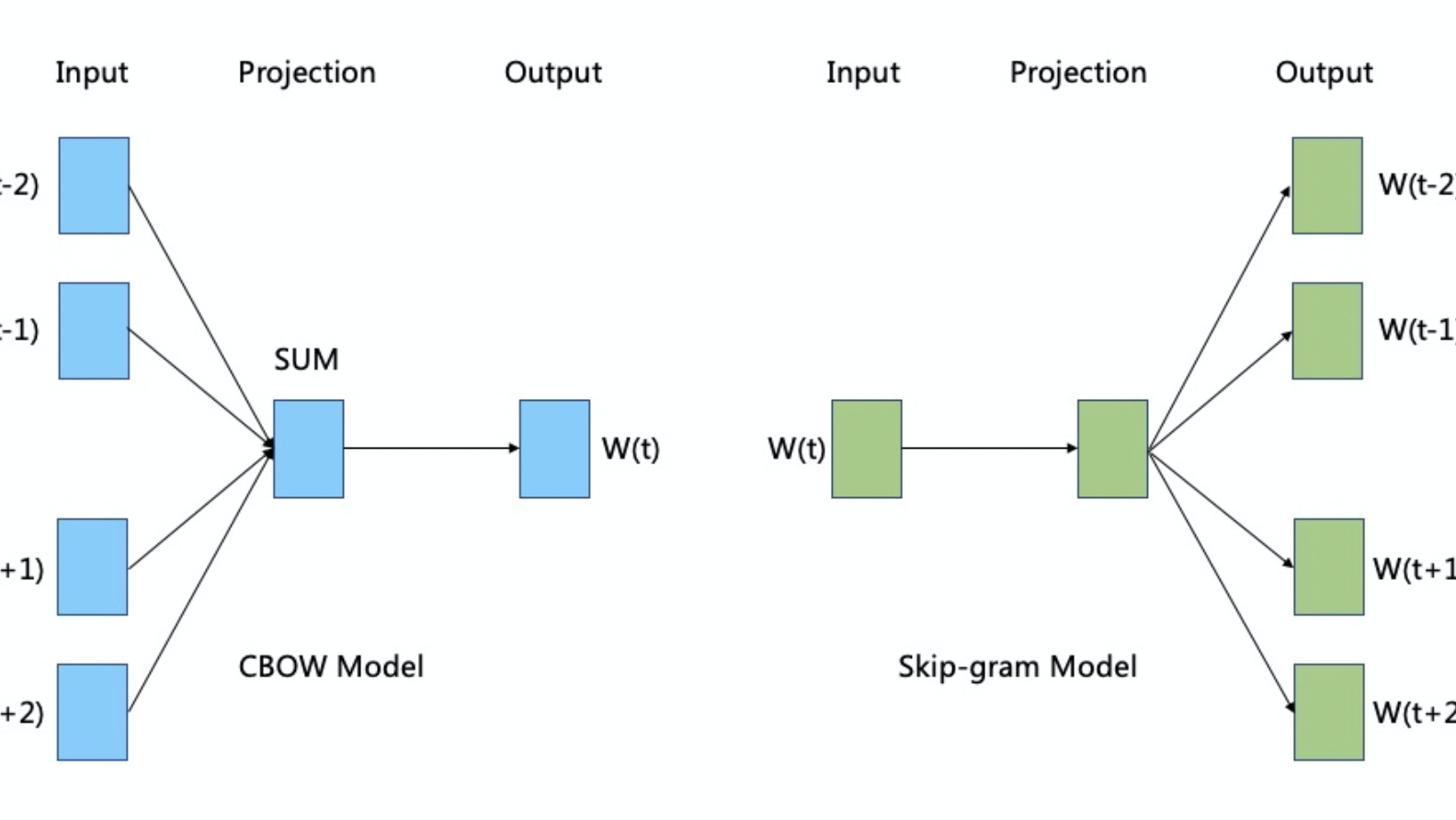 前言 Word2Vec是一种用于将自然语言文本中的单词转换为向量表示的技术,它被广泛应用于自然语言处理和深度学习领域。本文将介绍Word2Vec的基本原理、应用场景和使用方法。 基本原理 Word2Vec是由Google的Tomas Mikolov等人在2013年提出的,它是一种浅层神经网络模型,可
阅读全文
前言 Word2Vec是一种用于将自然语言文本中的单词转换为向量表示的技术,它被广泛应用于自然语言处理和深度学习领域。本文将介绍Word2Vec的基本原理、应用场景和使用方法。 基本原理 Word2Vec是由Google的Tomas Mikolov等人在2013年提出的,它是一种浅层神经网络模型,可
阅读全文
前言 Word2Vec是一种用于将自然语言文本中的单词转换为向量表示的技术,它被广泛应用于自然语言处理和深度学习领域。本文将介绍Word2Vec的基本原理、应用场景和使用方法。 基本原理 Word2Vec是由Google的Tomas Mikolov等人在2013年提出的,它是一种浅层神经网络模型,可
阅读全文
摘要: 前言 LightGBM 是微软开发的一个强大的开源梯度提升框架。它旨在高效和可扩展,能够处理大型数据集和高维特征。LightGBM结合使用基于梯度的单边采样(GOSS)和独占特征捆绑(EFB)来降低计算成本并提高模型的准确性。 LightGBM 支持各种目标函数,可用于回归和分类问题。它还提供了一些
阅读全文
前言 LightGBM 是微软开发的一个强大的开源梯度提升框架。它旨在高效和可扩展,能够处理大型数据集和高维特征。LightGBM结合使用基于梯度的单边采样(GOSS)和独占特征捆绑(EFB)来降低计算成本并提高模型的准确性。 LightGBM 支持各种目标函数,可用于回归和分类问题。它还提供了一些
阅读全文
前言 LightGBM 是微软开发的一个强大的开源梯度提升框架。它旨在高效和可扩展,能够处理大型数据集和高维特征。LightGBM结合使用基于梯度的单边采样(GOSS)和独占特征捆绑(EFB)来降低计算成本并提高模型的准确性。 LightGBM 支持各种目标函数,可用于回归和分类问题。它还提供了一些
阅读全文
摘要: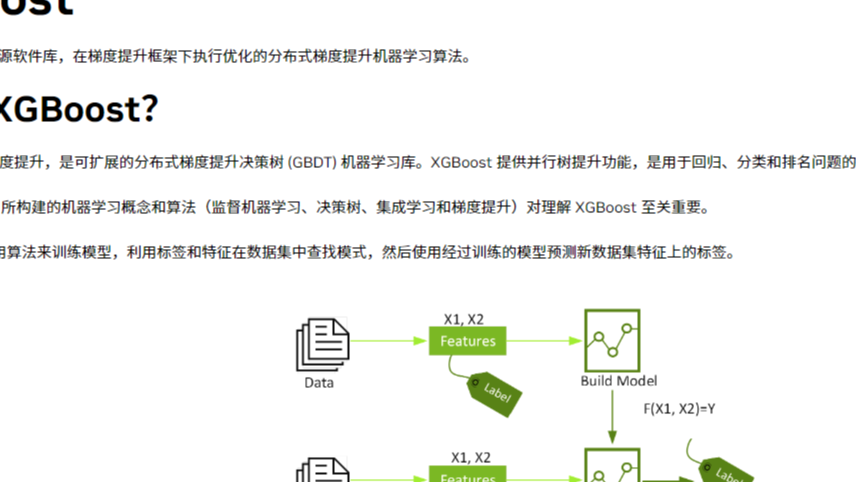 前言 XGBoost (eXtreme Gradient Boosting) 是一种流行的机器学习算法,用于解决各种预测问题,例如分类、回归和排名。在本文中,我们将介绍 XGBoost 的基本原理、常见的应用和一些实践经验. 基本原理 XGBoost 是一种基于梯度提升决策树 (Gradient B
阅读全文
前言 XGBoost (eXtreme Gradient Boosting) 是一种流行的机器学习算法,用于解决各种预测问题,例如分类、回归和排名。在本文中,我们将介绍 XGBoost 的基本原理、常见的应用和一些实践经验. 基本原理 XGBoost 是一种基于梯度提升决策树 (Gradient B
阅读全文
前言 XGBoost (eXtreme Gradient Boosting) 是一种流行的机器学习算法,用于解决各种预测问题,例如分类、回归和排名。在本文中,我们将介绍 XGBoost 的基本原理、常见的应用和一些实践经验. 基本原理 XGBoost 是一种基于梯度提升决策树 (Gradient B
阅读全文
摘要: 前言 GBDT(Gradient Boosting Decision Trees)是一种基于决策树的集成学习算法,它通过逐步地训练多个决策树模型来提高预测性能。具体来说,GBDT采用加法模型(additive model)的思想,每次训练一个新的决策树来拟合残差(预测误差),然后将所有决策树的预
阅读全文
前言 GBDT(Gradient Boosting Decision Trees)是一种基于决策树的集成学习算法,它通过逐步地训练多个决策树模型来提高预测性能。具体来说,GBDT采用加法模型(additive model)的思想,每次训练一个新的决策树来拟合残差(预测误差),然后将所有决策树的预
阅读全文
前言 GBDT(Gradient Boosting Decision Trees)是一种基于决策树的集成学习算法,它通过逐步地训练多个决策树模型来提高预测性能。具体来说,GBDT采用加法模型(additive model)的思想,每次训练一个新的决策树来拟合残差(预测误差),然后将所有决策树的预
阅读全文
摘要: 前言 随机森林(Random Forest)是一种基于决策树的集成学习方法,它通过构建多个决策树来提高预测准确性和稳定性。在本文中,我们将介绍随机森林的原理、优点和缺点,以及它在机器学习中的应用。 原理 随机森林是由多个决策树组成的集成学习模型。它的核心思想是通过构建多个决策树来提高预测准确性和稳定
阅读全文
前言 随机森林(Random Forest)是一种基于决策树的集成学习方法,它通过构建多个决策树来提高预测准确性和稳定性。在本文中,我们将介绍随机森林的原理、优点和缺点,以及它在机器学习中的应用。 原理 随机森林是由多个决策树组成的集成学习模型。它的核心思想是通过构建多个决策树来提高预测准确性和稳定
阅读全文
前言 随机森林(Random Forest)是一种基于决策树的集成学习方法,它通过构建多个决策树来提高预测准确性和稳定性。在本文中,我们将介绍随机森林的原理、优点和缺点,以及它在机器学习中的应用。 原理 随机森林是由多个决策树组成的集成学习模型。它的核心思想是通过构建多个决策树来提高预测准确性和稳定
阅读全文
摘要: 前言 决策树是一种常用的机器学习算法,用于分类和回归问题。其主要思想是根据已知数据构建一棵树,通过对待分类或回归的样本进行逐步的特征判断,最终将其分类或回归至叶子节点 关键概念 节点:决策树由许多节点组成,其中分为两种类型:内部节点和叶子节点。内部节点表示某个特征,而叶子节点表示某个类别或回归值。
阅读全文
前言 决策树是一种常用的机器学习算法,用于分类和回归问题。其主要思想是根据已知数据构建一棵树,通过对待分类或回归的样本进行逐步的特征判断,最终将其分类或回归至叶子节点 关键概念 节点:决策树由许多节点组成,其中分为两种类型:内部节点和叶子节点。内部节点表示某个特征,而叶子节点表示某个类别或回归值。
阅读全文
前言 决策树是一种常用的机器学习算法,用于分类和回归问题。其主要思想是根据已知数据构建一棵树,通过对待分类或回归的样本进行逐步的特征判断,最终将其分类或回归至叶子节点 关键概念 节点:决策树由许多节点组成,其中分为两种类型:内部节点和叶子节点。内部节点表示某个特征,而叶子节点表示某个类别或回归值。
阅读全文
摘要: TIOBE 编程语言排行前10中,各个编程语言的优缺点如下: Python: 优点:易学易用,具有大量的第三方库和工具支持,适用于数据分析、人工智能等领域。 缺点:运行速度相对较慢,不适用于需要高性能计算的应用程序。 Java: 优点:具有较好的跨平台性能,适用于大型应用程序的开发,提供了强大的面向
阅读全文
TIOBE 编程语言排行前10中,各个编程语言的优缺点如下: Python: 优点:易学易用,具有大量的第三方库和工具支持,适用于数据分析、人工智能等领域。 缺点:运行速度相对较慢,不适用于需要高性能计算的应用程序。 Java: 优点:具有较好的跨平台性能,适用于大型应用程序的开发,提供了强大的面向
阅读全文
TIOBE 编程语言排行前10中,各个编程语言的优缺点如下: Python: 优点:易学易用,具有大量的第三方库和工具支持,适用于数据分析、人工智能等领域。 缺点:运行速度相对较慢,不适用于需要高性能计算的应用程序。 Java: 优点:具有较好的跨平台性能,适用于大型应用程序的开发,提供了强大的面向
阅读全文
摘要:###### 前言 * 朴素贝叶斯是一种基于贝叶斯定理的分类算法,属于生成式模型的范畴。它的基本思想是基于贝叶斯定理和特征独立性假设。它假设每个特征之间相互独立,因此名称为“朴素”。 * 在朴素贝叶斯分类中,我们假设给定数据点属于某个类别,可以通过对该类别中各个特征的条件概率进行乘积计算,以计算该数
阅读全文
摘要: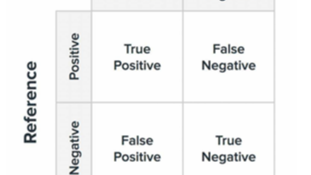 前言 SVM(支持向量机)是一种常用的机器学习算法,用于分类和回归分析。它的主要目的是寻找一个最优超平面,将不同属性的数据分成不同的类别。SVM是一种有效的分类器,因为它可以处理高维数据,并且可以使用核函数处理非线性可分的数据。 SVM思想 它的核心思想是通过将数据映射到高维空间来找到一个最优的超平
阅读全文
前言 SVM(支持向量机)是一种常用的机器学习算法,用于分类和回归分析。它的主要目的是寻找一个最优超平面,将不同属性的数据分成不同的类别。SVM是一种有效的分类器,因为它可以处理高维数据,并且可以使用核函数处理非线性可分的数据。 SVM思想 它的核心思想是通过将数据映射到高维空间来找到一个最优的超平
阅读全文
前言 SVM(支持向量机)是一种常用的机器学习算法,用于分类和回归分析。它的主要目的是寻找一个最优超平面,将不同属性的数据分成不同的类别。SVM是一种有效的分类器,因为它可以处理高维数据,并且可以使用核函数处理非线性可分的数据。 SVM思想 它的核心思想是通过将数据映射到高维空间来找到一个最优的超平
阅读全文
摘要: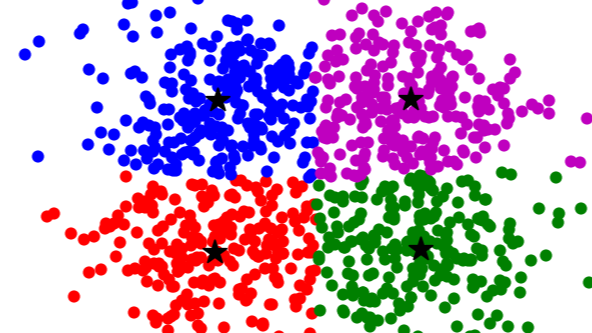 前言 K-means是一种经典的无监督学习算法,用于对数据进行聚类。K-means算法将数据集视为具有n个特征的n维空间,并尝试通过最小化簇内平方误差的总和来将数据点划分为簇。本文将介绍K-means算法的原理、实现和应用。 定义 K-means是一种无监督学习算法, 用于对数据进行聚类。该算法将数
阅读全文
前言 K-means是一种经典的无监督学习算法,用于对数据进行聚类。K-means算法将数据集视为具有n个特征的n维空间,并尝试通过最小化簇内平方误差的总和来将数据点划分为簇。本文将介绍K-means算法的原理、实现和应用。 定义 K-means是一种无监督学习算法, 用于对数据进行聚类。该算法将数
阅读全文
前言 K-means是一种经典的无监督学习算法,用于对数据进行聚类。K-means算法将数据集视为具有n个特征的n维空间,并尝试通过最小化簇内平方误差的总和来将数据点划分为簇。本文将介绍K-means算法的原理、实现和应用。 定义 K-means是一种无监督学习算法, 用于对数据进行聚类。该算法将数
阅读全文
摘要:前言 PCA(Principal Component Analysis)是一种常用的数据降维方法,它的主要思想是将高维数据降维到一个低维空间,同时保留尽可能多的原始数据的信息。 定义 PCA (Principal Component Analysis) 是一种常用的数据降维算法,用于对高维数据进行降
阅读全文
摘要:前言 KNN可以说是最简单的分类算法之一,同时也是最常用的分类算法之一。KNN算法是有监督学习的分类算法,与机器学习算法Kmeans有点像,但却是有本质区别的 定义 一个样本a在特征空间中离它最近的K个最近的样本中,大多数属于某个类别,则a样本也属于这个类别 如何计算其他样本与a样本的距离? 一般时
阅读全文
摘要:前言 逻辑回归虽然叫回归,实际上是一个二分类模型,要知道回归模型是连续的,而分类模型是离散的,逻辑回归简单点理解就是在线性回归的基础上增加了一个 sigmoid 函数 逻辑回归 = 线性回归 + sigmoid 函数 回顾线性回归 表达式:
摘要:ChatGPT保姆级注册教程 最近几天OpenAI发布的ChatGPT聊天机器人火出天际了,连着上了各个平台的热搜榜。这个聊天机器人最大的特点是模仿人类说话风格同时回答大量问题。 有人说ChatGPT是真正的人工智能,它不仅能和你聊天,还是写小作文,回答问题,甚至帮你写代码。 ChatGPT可以做什
阅读全文
摘要:机器学习-线性回归 前言 线性回归是机器学习中基础的模型之一,是有监督模型。 定义:线性回归是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法 表达式:
摘要:学习路径 语言 python 数学基础 数学基础公式:http://www.ai-start.com/dl2017/html/math.html 线性代数:http://www.ai-start.com/CS229/1.CS229-LinearAlgebra.html#cs229-%E6%9C%BA
阅读全文
摘要:机器学习绪论 机器学习概念 机器学习 有监督学习 如:回归,分类 无监督学习 如:聚类,降维 什么是机器学习 程序通过不断的学习达到一定的性能,可以完成指定的任务 定义 (1)机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验 学习中改善具体算法的性能。 (2)机器学习是
阅读全文
