
面经 cisco
1. 优先级反转问题及解决方法
(1)什么是优先级反转
简单从字面上来说,就是低优先级的任务先于高优先级的任务执行了,优先级搞反了。那在什么情况下会生这种情况呢?
假设三个任务准备执行,A,B,C,优先级依次是A>B>C;
首先:C处于运行状态,获得CPU正在执行,同时占有了某种资源;
其次:A进入就绪状态,因为优先级比C高,所以获得CPU,A转为运行状态;C进入就绪状态;
第三:执行过程中需要使用资源,而这个资源又被等待中的C占有的,于是A进入阻塞状态,C回到运行状态;
第四:此时B进入就绪状态,因为优先级比C高,B获得CPU,进入运行状态;C又回到就绪状态;
第五:如果这时又出现B2,B3等任务,他们的优先级比C高,但比A低,那么就会出现高优先级任务的A不能执行,反而低优先级的B,B2,B3等任务可以执行的奇怪现象,而这就是优先反转。
(2)如何解决优先级反转
高优先级任务A不能执行的原因是C霸占了资源,而C如果不能获得CPU,不释放资源,那A也只好一直等在那,所以解决优先级反转的原则肯定就是让C尽快执行,尽早把资源释放了。基于这个原则产生了两个方法:
2.1 优先级继承
当发现高优先级的任务因为低优先级任务占用资源而阻塞时,就将低优先级任务的优先级提升到等待它所占有的资源的最高优先级任务的优先级。
2.2 优先级天花板
优先级天花板是指将申请某资源的任务的优先级提升到可能访问该资源的所有任务中最高优先级任务的优先级.(这个优先级称为该资源的优先级天花板)
2.3 两者的区别
优先级继承:只有一个任务访问资源时一切照旧,没有区别,只有当高优先级任务因为资源被低优先级占有而被阻塞时,才会提高占有资源任务的优先级;而优先级天花板,不论是否发生阻塞,都提升,即谁先拿到资源,就将这个任务提升到该资源的天花板优先级。
2. 红黑树比一般树好在哪,为什么树要平衡
平衡二叉树和红黑树最差情况分析
1.经典平衡二叉树
平衡二叉树(又称AVL树)是带有平衡条件的二叉查找树,使用最多的定理为:一棵平衡二叉树是其每个节点的左子树和右子树的高度最多差为1的二叉查找树。因为他是二叉树的一种具体应用,所以他同样具有二叉树的性质。例如,一棵满二叉树在第k层最多可拥有
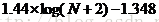
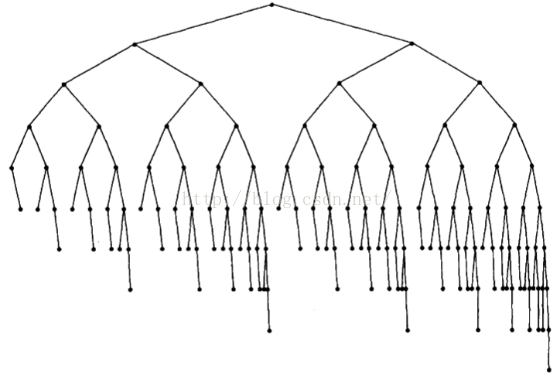
由平衡二叉树的定义可知,左子树和右子树最多可以相差1层高度,那么多个在同一层的子树就可以依次以相差1层的方式来递减子树的高度,如下图所示是一个拥有4棵子树的树的层高最大差情形(图1):
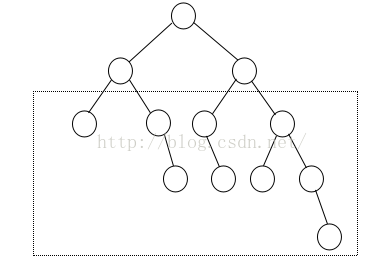
图1 拥有4颗子树的平衡二叉树最大高度差
该图虚线框中的子树,最左端的节点树高度为0,最右端的节点树的高度为2,因此该平衡二叉树的内部子树最大高度差为2。
利用这样的性质,我们就可以依次递推,1棵子树最大高度差为0层,2、3棵子树最大高度差为1层,4、5、6、7棵子树最大高度差为2层,8至15棵子树最大高度差为3层,16至31棵子树最大高度差为4层......
假设n为子树的数量,m为最大高度差,可得:
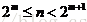
进一步分析,假设一棵高为h的平衡二叉树的最大高度差为m(假设最小的子树高度为0),且m的高度差由n(此处只考虑分界点情形,即n为2的幂级数)棵子树达成。由平衡二叉树的性质(性质1和性质2),可得如下式:
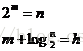
化简后最终可以得到一个简单的结论(似乎这个结论在本文之前没人关注过,此处仅仅考虑了最差情况,不过对于实际应用和性能分析已经完全够用,详细完整的数学证明感兴趣的读者可以尝试证明):
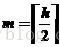
也就是说,一棵高为h的平衡二叉树,其内部子树的最大高度差可以达到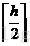
2.红黑树
历史上AVL树流行的一种变种是红黑树(red black tree)。红黑树也是许多编程语言底层实现采纳较多的数据结构(例如Java的TreeSet和TreeMap实现)。红黑树是具有下列着色性质的二叉查找树:
1.每一个节点或为黑色或为红色。
2.根节点时黑色的。
3.一个红色节点的儿子节点必须全部是黑色。
4.从任意一个节点到一个null的每一条路径必须包含相同数目的黑色节点。
以上着色法则的一个结论是:红黑树的高度最多为
由规则4可知,只要在一个节点的一侧子树尽可能多的使用红色节点,而另一侧尽可能少甚至不使用红色节点,就可以拉开左右子树的高度差,如下图所示(图3):
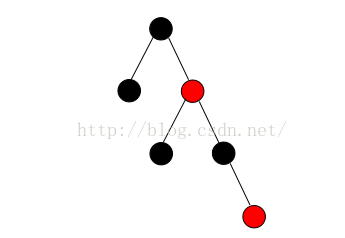
则我们可以显而易见的得到一个结论:一棵含有k个红色节点的红黑树,理论上其内部子树最大高度差就可以达到k。
既然红黑树理论上缺陷如此大,那为什么实际应用中反而采纳较多?深入研究红黑树的具体实现方式,可以发现,红黑树在实际应用中的实现形式已经超出其原本定义的规则。红黑树的理论阐述不够完善,也是其难于理解和新手难以自己动手实现的原因之一。(注:本文采纳Mark Allen Weiss的《Data Structures and Algorithm Analysis in Java》一书当中对于红黑树的实现方式,这也是实际中使用最多的实现方式)。
经过我的归纳总结,现实中的红黑树在实现过程中增加了以下限制条件:
5.新插入的节点必须为红色。
6.任意节点其左右子树最多相差2层红节点。
7.插入过程(仅限于插入点那条路径上)中不允许任一节点有2个红色儿子节点。
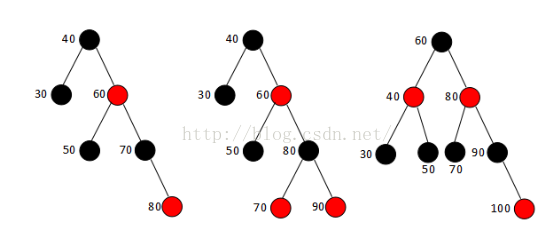
增加了以上三条限制条件的红黑树甚至都不需要再多加分析了。规则6和7建立在规则5和红黑树复杂的插入调整的基础之上,规则6恰巧直接阻止了经典平衡二叉树出现最差情形的可能性,规则7甚至是对红黑树到AA树(AA树实现尚不完善,目前实际性能较差,本文不做深入讨论)的一种过渡。以下图展示了连续向红黑树中插入右节点(依次插入30,40,50,60,70,80,90,100)的变化过程(图4,图5):

3.性能测试
本文的测试环境为Window7操作系统,代码全部使用Java编写,jdk版本为1.8.0,测试均采用随机数生成器产生的九位数数字数据。为尽可能排除编译器优化以及操作系统调度造成的影响,每一项测试均运行100遍取平均时间,例如对于万级测试:生成100次不同的1000个随机九位数,将每次生成的结果分别对平衡二叉树、红黑树、AA树进行树的构造,构造完成后重新循环这10000个数进行平均查找时间的统计,在查找期间还会生成节点数据量十分之一(此处即1000)个假数据来保证查找不到的情况也被统计进查找时间,也就是说万级测试是在操作1100000次后得出的结果。最终测试结果如下:
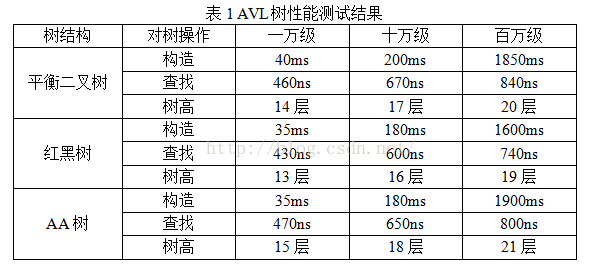
注:AA树的各项性能均介于红黑树和平衡二叉树之间。但是AA树的深度受随机生成的数字影像波动较大(最差情况出现次数多,并且最差情况树高最高)。
由此总结如下(如果前文都没看懂没有关系,记住下面的结论):
性能:红黑树>平衡二叉树>AA树;
编程实现难度:红黑树>平衡二叉树>AA树。
虽然各种树的实现以及具体应用千差万别,但是没有最好的数据结构只有最合适的数据结构,此处比较的三种查找树在实际应用中性能上只有细微的差别(最差情况出现的概率毕竟非常小),在生产实践中完全不会带来性能的明显缺陷,因此选择合理的实现方式,保证程序的功能健全性,才是选择数据结构的最重要选择因素。
红黑树属于平衡二叉树。它不严格是因为它不是严格控制左、右子树高度或节点数之差小于等于1,但红黑树高度依然是平均log(n),且最坏情况高度不会超过2log(n)。
红黑树(red-black tree) 是一棵满足下述性质的二叉查找树:
1. 每一个结点要么是红色,要么是黑色。
2. 根结点是黑色的。
3. 所有叶子结点都是黑色的(实际上都是Null指针,下图用NIL表示)。叶子结点不包含任何关键字信息,所有查询关键字都在非终结点上。
4. 每个红色结点的两个子节点必须是黑色的。换句话说:从每个叶子到根的所有路径上不能有两个连续的红色结点
5. 从任一结点到其每个叶子的所有路径都包含相同数目的黑色结点
红黑树相关定理
1. 从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。
根据上面的性质5我们知道上图的红黑树每条路径上都是3个黑结点。因此最短路径长度为2(没有红结点的路径)。再根据性质4(两个红结点不能相连)和性质1,2(叶子和根必须是黑结点)。那么我们可以得出:一条具有3个黑结点的路径上最多只能有2个红结点(红黑间隔存在)。也就是说黑深度为2(根结点也是黑色)的红黑树最长路径为4,最短路径为2。从这一点我们可以看出红黑树是 大致平衡的。 (当然比平衡二叉树要差一些,AVL的平衡因子最多为1)
2. 红黑树的树高(h)不大于两倍的红黑树的黑深度(bd),即h<=2bd
根据定理1,我们不难说明这一点。bd是红黑树的最短路径长度。而可能的最长路径长度(树高的最大值)就是红黑相间的路径,等于2bd。因此h<=2bd。
3. 一棵拥有n个内部结点(不包括叶子结点)的红黑树的树高h<=2log(n+1)
下面我们首先证明一颗有n个内部结点的红黑树满足n>=2^bd-1。这可以用数学归纳法证明,施归纳于树高h。当h=0时,这相当于是一个叶结点,黑高度bd为0,而内部结点数量n为0,此时0>=2^0-1成立。假设树高h<=t时,n>=2^bd-1成立,我们记一颗树高 为t+1的红黑树的根结点的左子树的内部结点数量为nl,右子树的内部结点数量为nr,记这两颗子树的黑高度为bd'(注意这两颗子树的黑高度必然一 样),显然这两颗子树的树高<=t,于是有nl>=2^bd'-1以及nr>=2^bd'-1,将这两个不等式相加有nl+nr>=2^(bd'+1)-2,将该不等式左右加1,得到n>=2^(bd'+1)-1,很显然bd'+1>=bd,于是前面的不等式可以 变为n>=2^bd-1,这样就证明了一颗有n个内部结点的红黑树满足n>=2^bd-1。
在根据定理2,h<=2bd。即n>=2^(h/2)-1,那么h<=2log(n+1)
从这里我们能够看出,红黑树的查找长度最多不超过2log(n+1),因此其查找时间复杂度也是O(log N)级别的。
红黑树的操作
因为每一个红黑树也是一个特化的二叉查找树,因此红黑树上的查找操作与普通二叉查找树上的查找操作相同。然而,在红黑树上进行插入操作和删除操作会导致不 再符合红黑树的性质。恢复红黑树的属性需要少量(O(log n))的颜色变更(实际是非常快速的)和不超过三次树旋转(对于插入操作是两次)。 虽然插入和删除很复杂,但操作时间仍可以保持为 O(log n) 次 。
红黑树的优势
红黑树能够以O(log2(N))的时间复杂度进行搜索、插入、删除操作。此外,任何不平衡都会在3次旋转之内解决。这一点是AVL所不具备的。
而且实际应用中,很多语言都实现了红黑树的数据结构。比如 TreeMap, TreeSet(Java )、 STL(C++)等。
3. tcp为什么要3次握手,如果不是会出什么问题,举例说明
为什么不能用两次握手进行连接?
我们知道,3次握手完成两个重要的功能,既要双方做好发送数据的准备工作(双方都知道彼此已准备好),也要允许双方就初始序列号进行协商,这个序列号在握手过程中被发送和确认。
现在把三次握手改成仅需要两次握手,死锁是可能发生的。作为例子,考虑计算机S和C之间的通信,假定C给S发送一个连接请求分组,S收到了这个分组,并发
送了确认应答分组。按照两次握手的协定,S认为连接已经成功地建立了,可以开始发送数据分组。可是,C在S的应答分组在传输中被丢失的情况下,将不知道S
是否已准备好,不知道S建立什么样的序列号,C甚至怀疑S是否收到自己的连接请求分组。在这种情况下,C认为连接还未建立成功,将忽略S发来的任何数据分
组,只等待连接确认应答分组。而S在发出的分组超时后,重复发送同样的分组。这样就形成了死锁。
设想:如果只有两次握手,那么第二次握手后服务器只向客户端发送ACK包,此时客户端与服务器端建立连接。在这种握手规则下:
假设:如果发送网络阻塞,由于TCP/IP协议定时重传机制,B向A发送了两次SYN请求,分别是x1和x2,且因为阻塞原因,导致x1连接请求和x2连接请求的TCP窗口大小和数据报文长度不一致,如果最终x1达到A,x2丢失,此时A同B建立了x1的连接,这个时候,因为AB已经连接,B无法知道是请求x1还是请求x2同B连接,如果B默认是最近的请求x2同A建立了连接,此时B开始向A发送数据,数据报文长度为x2定义的长度,窗口大小为x2定义的大小,而A建立的连接是x1,其数据包长度大小为x1,TCP窗口大小为x1定义,这就会导致A处理数据时出错。
很显然,如果A接收到B的请求后,A向B发送SYN请求y3(y3的窗口大小和数据报长度等信息为x1所定义),确认了连接建立的窗口大小和数据报长度为x1所定义,A再次确认回答建立x1连接,然后开始相互传送数据,那么就不会导致数据处理出错了。

4. timewait状态的理解
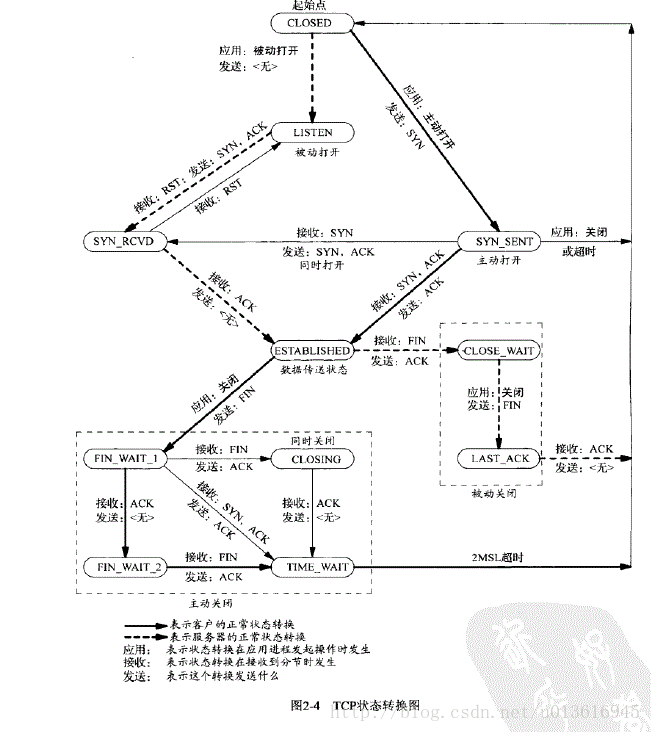
1. time_wait状态如何产生?
由上面的变迁图,首先调用close()发起主动关闭的一方,在发送最后一个ACK之后会进入time_wait的状态,也就说该发送方会保持2MSL时间之后才会回到初始状态。MSL值得是数据包在网络中的最大生存时间。产生这种结果使得这个TCP连接在2MSL连接等待期间,定义这个连接的四元组(客户端IP地址和端口,服务端IP地址和端口号)不能被使用。
2.time_wait状态产生的原因
1)为实现TCP全双工连接的可靠释放
由TCP状态变迁图可知,假设发起主动关闭的一方(client)最后发送的ACK在网络中丢失,由于TCP协议的重传机制,执行被动关闭的一方(server)将会重发其FIN,在该FIN到达client之前,client必须维护这条连接状态,也就说这条TCP连接所对应的资源(client方的local_ip,local_port)不能被立即释放或重新分配,直到另一方重发的FIN达到之后,client重发ACK后,经过2MSL时间周期没有再收到另一方的FIN之后,该TCP连接才能恢复初始的CLOSED状态。如果主动关闭一方不维护这样一个TIME_WAIT状态,那么当被动关闭一方重发的FIN到达时,主动关闭一方的TCP传输层会用RST包响应对方,这会被对方认为是有错误发生,然而这事实上只是正常的关闭连接过程,并非异常。
2)为使旧的数据包在网络因过期而消失
为说明这个问题,我们先假设TCP协议中不存在TIME_WAIT状态的限制,再假设当前有一条TCP连接:(local_ip, local_port, remote_ip,remote_port),因某些原因,我们先关闭,接着很快以相同的四元组建立一条新连接。本文前面介绍过,TCP连接由四元组唯一标识,因此,在我们假设的情况中,TCP协议栈是无法区分前后两条TCP连接的不同的,在它看来,这根本就是同一条连接,中间先释放再建立的过程对其来说是“感知”不到的。这样就可能发生这样的情况:前一条TCP连接由local peer发送的数据到达remote peer后,会被该remot peer的TCP传输层当做当前TCP连接的正常数据接收并向上传递至应用层(而事实上,在我们假设的场景下,这些旧数据到达remote peer前,旧连接已断开且一条由相同四元组构成的新TCP连接已建立,因此,这些旧数据是不应该被向上传递至应用层的),从而引起数据错乱进而导致各种无法预知的诡异现象。作为一种可靠的传输协议,TCP必须在协议层面考虑并避免这种情况的发生,这正是TIME_WAIT状态存在的第2个原因。
3)总结
具体而言,local
peer主动调用close后,此时的TCP连接进入TIME_WAIT状态,处于该状态下的TCP连接不能立即以同样的四元组建立新连接,即发起active
close的那方占用的local
port在TIME_WAIT期间不能再被重新分配。由于TIME_WAIT状态持续时间为2MSL,这样保证了旧TCP连接双工链路中的旧数据包均因过期(超过MSL)而消失,此后,就可以用相同的四元组建立一条新连接而不会发生前后两次连接数据错乱的情况。
3.time_wait状态如何避免
首先服务器可以设置SO_REUSEADDR套接字选项来通知内核,如果端口忙,但TCP连接位于TIME_WAIT状态时可以重用端口。在一个非常有用的场景就是,如果你的服务器程序停止后想立即重启,而新的套接字依旧希望使用同一端口,此时SO_REUSEADDR选项就可以避免TIME_WAIT状态。
关于tcp中time_wait状态的4个问题
time_wait是个常问的问题。tcp网络编程中最不easy理解的也是它的time_wait状态,这也说明了tcp/ip四次挥手中time_wait状态的重要性。
以下通过4个问题来描写叙述它
问题
1.time_wait状态是什么
2.为什么会有time_wait状态
3.哪一方会有time_wait状态
4.怎样避免time_wait状态占用资源
1.time_wait状态是什么
简单来说:time_wait状态是四次挥手中server向client发送FIN终止连接后进入的状态。
下图为tcp四次挥手过程
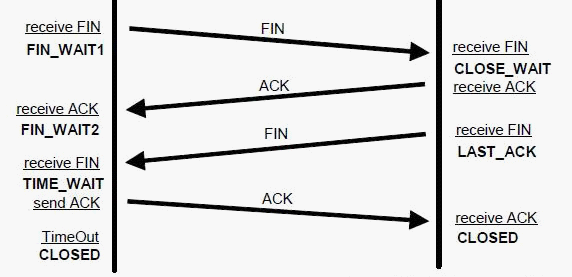
能够看到time_wait状态存在于client收到serverFin并返回ack包时的状态
当处于time_wait状态时,我们无法创建新的连接,由于port被占用。
2.为什么会有time_wait状态
time_wait存在的原因有两点
1.可靠的终止TCP连接。
2.保证让迟来的TCP报文段有足够的时间被识别并丢弃。
1.可靠的终止TCP连接,若处于time_wait的client发送给server确认报文段丢失的话,server将在此又一次发送FIN报文段,那么client必须处于一个可接收的状态就是time_wait而不是close状态。
2.保证迟来的TCP报文段有足够的时间被识别并丢弃,linux 中一个TCPport不能打开两次或两次以上。当client处于time_wait状态时我们将无法使用此port建立新连接,假设不存在time_wait状态,新连接可能会收到旧连接的数据。
3.哪一方会有time_wait状态
time_wait状态是一般有client的状态。
并且会占用port
有时产生在server端,由于server主动断开连接或者发生异常
4.怎样避免time_wait状态占用资源
假设是client,我们一般不用操心,由于client一般选用暂时port。再次创建连接会新分配一个port。
除非指定client使用某port,只是一般不须要这么做。
假设是server主动关闭连接后异常终止。则由于它总是使用用一个知名serverport号,所以连接的time_wait状态将导致它不能重新启动。只是我们能够通过socket的选项SO_REUSEADDR来强制进程马上使用处于time_wait状态的连接占用的port。
通过socksetopt设置后,即使sock处于time_wait状态,与之绑定的socket地址也能够马上被重用。
此外也能够通过改动内核參数/proc/sys/net/ipv4/tcp_tw/recycle来高速回收被关闭的socket,从而是tcp连接根本不进入time_wait状态,进而同意应用程序马上重用本地的socket地址。
谈谈TCP中的TIME_WAIT
在服务端可能会经常遇到有很多处于TIMEWAIT状态的TCP连接。如果上网一搜索,可以找到有很多关于处理TIMEWAIT不正确的博文(包括本文),很多文章就放了几个调整参数。至于这些参数有什么用,为什么要调整为那个值就没有深入地介绍了。这就好像生了病不去找医生了解病情,而是随便从别人的药箱里面找点药来吃,看看有没有效果,也不管别人的药是否过期,是否对症。所以,本文也来凑个热闹,来谈谈TIME_WAIT。
为什么要有TIME_WAIT?
TIME_WAIT是TCP主动关闭连接一方的一个状态,TCP断开连接的时序图如下:
当主动断开连接的一方(Initiator)发送FIN包给对方,且对方回复了ACK+FIN,然后Initiator回复了ACK后就进入TIME_WAIT状态,一直将持续2MSL后进入CLOSED状态。
那么,我们来看如果Initiator不进入TIME_WAIT状态而是直接进入CLOSED状态会有什么问题?
考虑这种情况,服务器运行在80端口,客户端使用的连接端口是12306,数据传输完毕后服务端主动关闭连接,但是没有进入TIME_WAIT,而是直接计入CLOSED了。这时,客户端又通过同样的端口12306与服务端建立了一个新的连接。假如上一个连接过程中网络出现了异常,导致了某个包重传并延时到达了服务端,这时服务端就无法区分这个包是上一个连接的还是这个连接的。所以,主动关闭连接一方要等待2MSL,然后才能CLOSE,保证连接中的IP包都要么传输完成,要么被丢弃了。
TIME_WAIT会带来什么问题
系统中TIME_WAIT的连接数很多,会导致什么问题呢?这要分别针对客户端和服务器端来看的。
首先,如果是客户端发起了连接,传输完数据然后主动关闭了连接,这时这个连接在客户端就会处于TIMEWAIT状态,同时占用了一个本地端口。如果客户端使用短连接请求服务端的资源或者服务,客户端上将有大量的连接处于TIMEWAIT状态,占用大量的本地端口。最坏的情况就是,本地端口都被用光了,这时将无法再建立新的连接。
针对这种情况,对应的解决办法有2个:
1. 使用长连接,如果是http,可以使用keepalive
2. 增加本地端口可用的范围,比如Linux中调整内核参数:net.ipv4.ip_local_port_range
对于服务器而已,由于服务器是被动等待客户端建立连接的,因此即使服务器端有很多TIME_WAIT状态的连接,也不存在本地端口耗尽的问题。大量的TIME_WAIT的连接会导致如下问题:
1. 内存占用:因为每一个TCP连接都会有占用一些内存。
2.
在某些Linux版本上可能导致性能问题,因为数据包到达服务器的时候,内核需要知道数据包是属于哪个TCP连接的,在某些Linux版本上可能会遍历所有的TCP连接,所以大量TIME_WAIT的连接将导致性能问题。不过,现在的内核都对此进行了优化(待确认)。
那系统中处于TIME_WAIT状态的TCP连接数有上限吗?有的,这是通过net.ipv4.tcp_max_tw_buckets参数来控制的,默认值为180000。当超过了以后,系统就开始关闭这些连接,同时会在系统日志中打印日志。此时,可以将这个值调大一些,从这个参数的默认值就可以看出,对服务器而已,处于TIME_WAIT状态的TCP连接多点也没有什么关系,只是多占用些内存而已。
常见的TIMEWAIT错误参数
如果用TIME_WAIT作为关键字到网络上搜索,会得到很多关于如何减少TIME_WAIT数量的建议,其中有些建议是有错误或者有风险的,列举如下:
- net.ipv4.tcp_syncookies = 1,这个参数表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击。这个和TIME_WAIT没有什么关系。
- net.ipv4.tcp_tw_reuse = 1,这个参数表示重用TIME_WAIT的连接,重用的条件是TCP的4元组(源地址、源端口、目标地址、目标端口)要完全一致,而且开启了net.ipv4.tcp_timestamps,且新建立连接的使用的timestamp要大于当前连接的timestamp。所以,开启了这个参数对减少TIME_WAIT的TCP连接有点用,但条件太苛刻,所以实际用处不大。
- net.ipv4.tcp_tw_recycle = 1,这个参数表示开启TIME_WAIT回收功能,开启了这个参数后,将大大减小TIME_WAIT进入CLOSED状态的时间。但是开启了这个功能了风险很大,可能会导致处于NAT后面的某些客户端无法建立连接。因为,开启这个功能后,它要求来自同一个IP的TCP新连接的timestamp要大于之前连接的timestamp。
TIMEWAIT的“正确”处理方法
简单总结一下我对于TIME_WAIT状态TCP连接的理解和处理方法:
1. TIME_WAIT状态的设计初衷是为了保护我们的。服务端不必担心系统中有几w个处于TIME_WAIT状态的TCP连接。可以调大net.ipv4.tcp_max_tw_buckets这个参数。
2. 使用短连接的客户端,需要关注TIME_WAIT状态的TCP连接,建议是采用长连接,同时调节参数net.ipv4.ip_local_port_range,增加本地可用端口的范围。
3. 可以开启net.ipv4.tcp_tw_reuse这个参数,但是实际用处有限。
4. 不要开启net.ipv4.tcp_tw_recycle这个参数,它带来的问题比用处大。
5. 某些Linux的发行版可以调节TIME_WAIT到CLOSED的等待时间(比如Ali的Linux内核提供了参数net.ipv4.tcp_tw_timeout
),可以稍微调小一点这个参数。
5. linux内核进程调度
1. Linux进程和线程如何创建、退出?进程退出的时候,自己没有释放的资源(如内存没有free)会怎样?
解答:
Linux进程通过fork来创建
Linux线程通过pthread_create创建,
2. 什么是写时拷贝?
解答:
写时拷贝(copy-on-write, COW)就是等到修改数据时才真正分配内存空间,这是对程序性能的优化,可以延迟甚至是避免内存拷贝,当然目的就是避免不必要的内存拷贝。
Linux 的fork系统调用就使用了写时拷贝技术,具体细节如下:
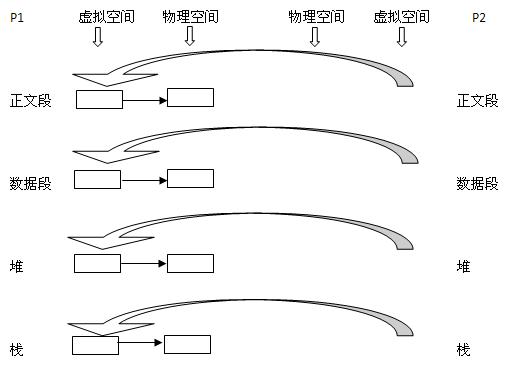
现在有一个父进程P1,这是一个主体,那么它是有灵魂也是有身体的。现在在其虚拟地址空间(有相应的数据结构表示)上有:正文段,数据段,堆,栈这四个部分,相应地,内核要为这四个部分分配给自的物理块。即正文段块、数据段块、堆块、栈块。
1)现在P1用fork()函数为进程创建一个子进程P2
内核:
(1) 复制P1的正文段,数据段,堆,栈这四个部分,注意是其内容相同。
(2) 为这四个部分分配物理块,P2的:正文段(为P1的正文段的物理块,其实就是不为P2分配正文段块,让P2的正文段指向P1的正文段块),数据段(P2自己的数据段块,为其分配对应的块),堆(P2自己的堆块),栈(P2自己的栈块)。如下图所示,同左到右大的方向箭头表示复制内容:
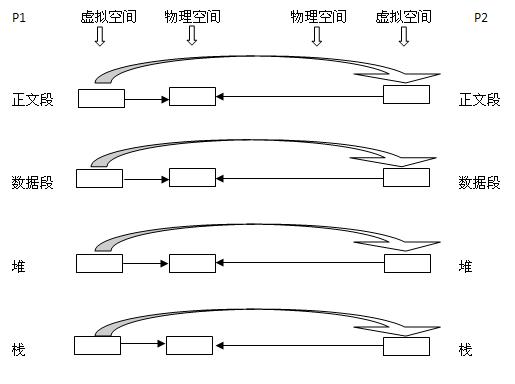
2)写时复制技术
写时复制技术:内核只为新生成的子进程创建虚拟空间结构,它们复制于父进程的虚拟空间结构,但是不为这些段分配物理内存,它们共享父进程的物理空间,当父子进程中有更改相应的段的行为发生时,再为子进程相应的段分配物理空间。
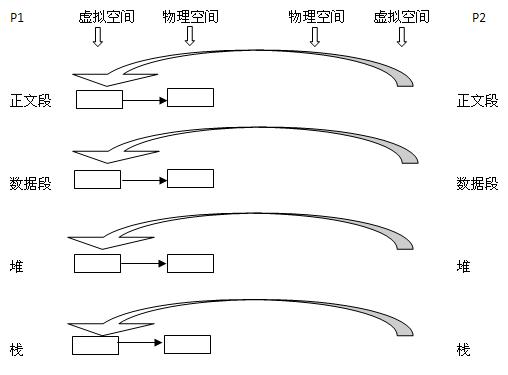
3)vfork
vfork的做法更加简单粗暴,内核连子进程的虚拟地址空间也不创建了,直接共享了父进程的虚拟空间,当然了,这种做法就顺水推舟的共享了父进程的物理空间
总结
传统的fork()系统调用直接把所有的资源复制给新创建的进程。这种实现过于简单并且效率低下,因为它拷贝的数据也许并不共享,更糟的情况是,如果新进程打算立即执行一个新的映像,那么所有的拷贝将是无用功。
Linux的fork()使用写时拷贝(copy-on-write)页实现。写时拷贝是一种可以推迟甚至免除拷贝数据的技术。内核此时并不复制整个地址空间,而是让父进程和子进程共享一个拷贝。只有在需要写入的时候,数据才会复制,从而使各个进程拥有各自的拷贝。也就是说,资源的复制只有在需要写入的时候才进行,在此之前,只是以只读方式共享。这种技术使地址空间的页的拷贝被推迟到实际发生写入的时候。
3. Linux的线程如何实现,与进程的本质区别是什么?
解答:
进程是资源分配和管理的单位,线程是调度的基本单位,进程有独立的地址空间,拥有PCB,其中包含进程标识符(非负整数)、进程资源、进程调度信息、进程间通信相关资源、处理机状态(便于调度后恢复原状态)等,线程具有单独的堆栈和寄存器,保存自己允许的相关上下文,具有TCB。各线程还共享以下进程资源和环境:
1)文件描述符表
2)每种信号的处理方式(SIG_IGN,SIG_DFL,用户自定义)
3)当前工作目录
4)用户id和组id
但有些资源是线程独享的:
1)线程id
2)上下文,包括各种寄存器的值,程序计数器和栈指针
3)栈空间
4)errno变量
5)信号屏蔽字
6)调度优先级
4. Linux能否满足硬实时的需求?
5. 进程如何睡眠等资源,此后又如何被唤醒?
6. 进程的调度延时是多少?
7. 调度器追求的吞吐率和响应延迟之间是什么关系?CPU消耗型和I/O消耗型进程的诉求?
8. Linux怎么区分进程优先级?实时的调度策略和普通调度策略有什么区别?
9. nice值的作用是什么?nice值低有什么优势?
10. Linux可以被改造成硬实时吗?有什么方案?
11. 多核、多线程的情况下,Linux如何实现进程的负载均衡?
12. 这么多线程,究竟哪个线程在哪个CPU核上跑?有没有办法把某个线程固定到某个CPU跑?
13. 多核下如何实现中断、软中断的负载均衡?
14. 如何利用cgroup对进行进程分组,并调控各个group的CPU资源?
15. CPU利用率和CPU负载之间的关系?CPU负载高一定用户体验差吗?
带着问题上路
一切的学习都是为了解决问题,而不是为了学习而学习。为了学习而学习,这种行为实在是太傻了,因为最终也学不好。所以我们要弄清楚进程调度和内存管理究竟能解决什么样的问题。
Linux进程调度以及配套的进程管理回答如下问题:
1. Linux进程和线程如何创建、退出?进程退出的时候,自己没有释放的资源(如内存没有free)会怎样?
2. 什么是写时拷贝?
3. Linux的线程如何实现,与进程的本质区别是什么?
4. Linux能否满足硬实时的需求?
5. 进程如何睡眠等资源,此后又如何被唤醒?
6. 进程的调度延时是多少?
7. 调度器追求的吞吐率和响应延迟之间是什么关系?CPU消耗型和I/O消耗型进程的诉求?
8. Linux怎么区分进程优先级?实时的调度策略和普通调度策略有什么区别?
9. nice值的作用是什么?nice值低有什么优势?
10. Linux可以被改造成硬实时吗?有什么方案?
11. 多核、多线程的情况下,Linux如何实现进程的负载均衡?
12. 这么多线程,究竟哪个线程在哪个CPU核上跑?有没有办法把某个线程固定到某个CPU跑?
13. 多核下如何实现中断、软中断的负载均衡?
14. 如何利用cgroup对进行进程分组,并调控各个group的CPU资源?
15. CPU利用率和CPU负载之间的关系?CPU负载高一定用户体验差吗?
Linux内存管理回答如下问题:
1. Linux系统的内存用掉了多少,还剩余多少?下面这个free命令每一个数字是什么意思?

2. 为什么要有DMA、NORMAL、HIGHMEM zone?每个zone的大小是由谁决定的?
3. 系统的内存是如何被内核和应用瓜分掉的?
4. 底层的内存管理算法buddy是怎么工作的?它和内核里面的slab分配器是什么关系?
5. 频繁的内存申请和释放是否会导致内存的碎片化?它的后果是什么?
6. Linux内存耗尽后,系统会发生怎样的情况?
7. 应用程序的内存是什么时候拿到的?malloc()成功后,是否真的拿到了内存?应用程序的malloc()与free()与内核的关系究竟是什么?
8. 什么是lazy分配机制?应用的内存为什么会延后以最懒惰的方式拿到?
9. 我写的应用究竟耗费了多少内存?进程的vss/rss/pss/uss分别是什么概念?虚拟的,真实的,共享的,独占的,究竟哪个是哪个?
10. 内存为什么要做文件系统的缓存?如何做?缓存何时放弃?
11. Free命令里面显示的buffers和cached分别是什么?二者有何区别?
12. 交换分区、虚拟内存究竟是什么鬼?它们针对的是什么性质的内存?什么是匿名页?
13. 进程耗费的内存、文件系统的缓存何时回收?回收的算法是不是类似LRU?
14. 怎样追踪和判决发生了内存泄漏?内存泄漏后如何查找泄漏源?
15. 内存大小这样影响系统的性能?CPU、内存、I/O三角如何互动?它们如何综合决定系统的一些关键性能?
以上问题,如果您都能回答,那么恭喜您,您是一个概念清楚的人,Linux出现吞吐低、延迟大、响应慢等问题的时候,你可以找到一个可能的方向。如果您只能回答低于1/3的问题,那么,Linux对您仍然是一片空白,出现问题,您只会陷入瞎猫子乱抓,而捞不到耗子的困境,或者胡乱地意测问题,陷入不断的低水平重试。
试图回答这些问题
本文的目的不是回答这些问题,因为回答这些问题,需要洋洋洒洒数百页的文档,而本文档不会超过10页。所以,本文的目的是试图给出一个回答这些问题的思考问题的出发点,我们倡导面对任何问题的时候,先要弄明白系统的设计目标。
吞吐vs.响应
首先我们在思考调度器的时候,我们要理解任何操作系统的调度器设计只追求2个目标:吞吐率大和延迟低。这2个目标有点类似零和游戏,因为吞吐率要大,势必要把更多的时间放在做真实的有用功,而不是把时间浪费在频繁的进程上下文切换;而延迟要低,势必要求优先级高的进程可以随时抢占进来,打断别人,强行插队。但是,抢占会引起上下文切换,上下文切换的时间本身对吞吐率来讲,是一个消耗,这个消耗可以低到2us或者更低(这看起来没什么?),但是上下文切换更大的消耗不是切换本身,而是切换会引起大量的cache miss。你明明weibo跑的很爽,现在切过去微信,那么CPU的cache是不太容易命中微信的。


越往上面选,吞吐越好,越好下面选,响应越好。服务器你一个月也难得用一次鼠标,而桌面则显然要求一定的响应,这样可以保证UI行为的表现较好。但是Linux即便选择的是最后一个选项“Preemptible Kernel (Low-Latency Desktop)”,它仍然不是硬实时的。因为,在Linux有三类区间是不可以抢占调度的,这三类区间是:
- 中断
- 软中断
- 持有类似spin_lock这样的锁而锁住该CPU核调度的情况

Linux的preempt-rt补丁试图把中断、软中断线程化,变成可以被抢占的区间,而把会关本核调度器的spin_lock替换为可以调度的mutex,它实现了在T3时刻唤醒RT进程的时刻,RT进程可以立即抢占调度进入的目标,避免了T3-T5之间延迟的非确定性。
CPU消耗型 vs. I/O消耗型
在Linux运行的进程,分为2类,一类是CPU消耗型(狂算),一类是I/O消耗型(狂睡,等I/O),前者CPU利用率高,后者CPU利用率低。一般而言,I/O消耗型任务对延迟比较敏感,应该被优先调度。比如,你正在疯狂编译安卓,而等鼠标行为的用户界面老不工作(正在狂睡),但是鼠标一点,我们应该优先打断正在编译的进程,而去响应鼠标这个I/O,这样电脑的用户体验才符合人性。
Linux的进程,对于RT进程而言,按照SCHED_FIFO和SCHED_RR的策略,优先级高先执行;优先级高的睡眠了后优先级的执行;同等优先级的SCHED_FIFO先ready的跑到睡,后ready的接着跑;而同等优先级的RR则进行时间片轮转。比如Linux存在如下4个进程,T1~T4(内核里面优先级数字越低,优先级越高):

那么它们在Linux的跑法就是:

其中NICE_0_LOAD是1024,也就是NICE是0的进程的weight。vruntime是进程的虚拟运行时间,pruntime是物理运行时间,weight是权重,权重完全由nice决定,如下表:

比如有4个普通进程,如下表,目前显然T1的vruntime最小(这是它喜欢睡的结果),然后T1被调度到。
|
pruntime |
Weight |
vruntime |
|
|
T1 |
8 |
1024(nice=0) |
8*1024/1024=8 |
|
T2 |
10 |
526(nice=3) |
10*1024/526 =19 |
|
T3 |
20 |
1024(nice=0) |
20*1024/1024=20 |
|
T4 |
20 |
820(nice=1) |
20*1024/820=24 |
所以,普通进程的调度,是一个综合考虑你喜欢干活还是喜欢睡和你的nice值是多少的结果。鉴于此,我们去问一个普通进程的调度延迟究竟有多大,这个问题,本身意义就不是特别大,它完全取决于当前的系统里面还有谁在跑,取决于你唤醒的进程的nice和它前面喜欢不喜欢睡觉。
明白了这一点,你就不会在Linux里面问一些让回答的人吐血的问题。比如,一个普通进程多久被调度到?明确地说,不知道!装逼的说法,就是“depend on …”,依赖的东西太多。再装逼的说法,就是“一言难尽”,但这也是大实话。
分配vs. 占据
Linux作为一个把应用程序员当傻逼的操作系统,它必须允许应用程序犯错。所以这类问题就不要问了:进程malloc()了内存,还没有free()就挂了,那么我前面分配的内存没有释放,是不是就泄漏掉了?明确的说,这是不可能的,Linux内核如果这么傻,它是无法应付乱七八糟的各种开源有漏洞软件的,所以进程死的时候,肯定是资源皆被内核释放的,这类傻问题,你明白Linux的出发点,就不会再去问了。
同样的,你在应用程序里面malloc()成功的一刻,也不要以为真的拿到了内存,这个时候你的vss(虚拟地址空间,Virtual Set Size)会增大,但是你的rss(驻留在内存条上的内存,Resident SetSize)内存会随着写到每一页而缓慢增大。所以,分配成功的一刻,顶多只是被忽悠了,和你实际占有还是不占有,暂时没有半毛钱关系。
如下图,最初的堆是8KB,这8KB也写过了,所以堆的vss和rss都是8KB。此后我们调用brk()把堆变大到16KB,但是实际上它占据的内存rss还是8KB,因为第3页还没有写,根本没有真正从内存条上拿到内存。直到写第3页,堆的rss才变为12KB。这就是Linux针对app的lazy分配机制,它的出发点,当然也是防止应用程序傻逼了。

代码段的内存、堆的内存、栈的内存都是这样懒惰地拿到,demanding page。
我们有一台1GB内存的32位Linux系统,我们关闭swap,同时透过修改overcommit_memory为1来允许申请不超过进程虚拟地址空间的内存:
$ sudo swapoff -a
$ sudo sh -c 'echo 1 >/proc/sys/vm/overcommit_memory'
此后,我们的应用可以申请一个超级大的内存(比实际内存还大):

上述程序在1GB的电脑上面运行,申请2GB内存可以申请成功,但是在写到一定程度后,系统出现out-of-memory,上述程序对应的进程作为oom_score最大(最该死的)的进程被系统杀死。
隔离vs. 共享
Linux进程究竟耗费了多少内存,是一个非常复杂的概念,除了上面的vss, rss外,还有pss和uss,这些都是Linux不同于RTOS的显著特点之一。Linux各个进程既要做到隔离,但是隔离中又要实现共享,比如1000个进程都用libc,libc的代码段显然在内存只应该有一份。
下面的一幅图上有3个进程,pid为1044的 bash、pid为1045的 bash和pid为1054的 cat。每个进程透过自己的页表,把虚拟地址空间指向内存条上面的物理地址,每次切换一个进程,即切换一份独特的页表。

仅从此图而言,进程1044的vss和rss分别是:
vss= 1+2+3
rss= 4+5+6
但是是不是“4+5+6”就是1044这个进程耗费的内存呢?这显然也是不准确的,因为4明显被3个进程指向,5明显被2个进程指向,坏事是大家一起干的,不能1044一个人背黑锅。这个时候,就衍生出了一个pss(按比例计算的驻留内存, Proportional Set Size )的概念,仅从这一幅图而言,进程1044的pss为:
rss= 4/3 +5/2 +6
最后,还有进程1044独占且驻留的内存uss(Unique Set Size ),仅从此图而言,
Uss = 6。
所以,分析Linux,我们不能模棱两可地停留于表面,或者想当然地说:“Linux的进程耗费了多少内存?”因为这个问题,又是一个要靠装逼来回答的问题,“dependon…”。坦白讲,每次当我问到老外问题,老外第一句话就是“depend on…”的时候,我就想上去抽他了,但是我又抑制了这个冲动,因为,很多问题,不是简单的0和1问题,正反问题,黑白问题,它确实是一个“depend on …”的问题。
有时候,小白问大拿一个问题,大拿实在是无法正面回答,于是就支支吾吾一番。这个时候小白会很生气,觉得大拿态度不好,或者在装逼。你实际上,明白很多问题不是简单的0与1问题之后,你就会理解,他真的不是在装逼。这个时候,我们要反过来检讨自己,是不是我们自己问的问题太LOW逼了?
思考大于接受
我们前面提出了30个问题,而本文也仅仅只是回答了其中极少的一部分。此文的目的在于建立思维,导入方向,而不是洋洋洒洒地把所有问题回答掉,因为哥确实没有时间写个几百页的文档来一一回答这些问题。很多事情,用口头描述,比直接写冗长地文档要更加容易也轻松。
最后,我仍然想要强调的一个观点是,我们在思维Linux的时候,更多地可以把自己想象成Linus Torvalds,如果你是Linus Torvalds,你要设计Linux,你碰到某个诉求,比如调度器和内存方面的诉求,你应该如何解决。我们不是被动地接受“是什么”,更多地要思考“为什么”,“怎么办”。
如果你是Linus Torvalds,有个傻逼应用程序员要申请1GB内存,你是直接给他,还是假装给他,但是实际没有给他,直到它写的时候再给他?
如果你是Linus Torvalds,有个家伙打开了串口,然后进程就做个1/0运算或者访问空指针挂了,你要不要在这个进程挂的时候给它关闭串口?
如果你是Linus Torvalds,你是要让nice值低(优先级高)的普通进程在睡眠前一直堵着nice值高的进程,还是虽然它优先级高,但是由于跑的时间比较长后,也要让给优先级低(nice值高)的进程?如果你认为nice值低的应该一直跑,那么如何照顾喜欢睡觉的I/O消耗型进程?万一nice值低的进程有bug,进入死循环,那么nice高的进程岂不是丝毫机会都没有?这样的设计,是不是反人类?
…
当你带着这些思考,武装这些concept,再去看Linux的时候,你就从被动的“接受”,变成了主动地“思考”,这正好是任何一个优秀程序员都具备的品质,也是打通进程调度和内存管理任督二脉的关键。
linux进程调度浅析
操作系统要实现多进程,进程调度必不可少。
进程调度是对TASK_RUNNING状态的进程进行调度(参见《linux进程状态浅析》)。如果进程不可执行(正在睡眠或其他),那么它跟进程调度没多大关系。
所以,如果你的系统负载非常低,盼星星盼月亮才出现一个可执行状态的进程。那么进程调度也就不会太重要。哪个进程可执行,就让它执行去,没有什么需要多考虑的。
反之,如果系统负载非常高,时时刻刻都有N多个进程处于可执行状态,等待被调度运行。那么进程调度程序为了协调这N个进程的执行,必定得做很多工作。协调得不好,系统的性能就会大打折扣。这个时候,进程调度就是非常重要的。
尽管我们平常接触的很多计算机(如桌面系统、网络服务器、等)负载都比较低,但是Linux作为一个通用操作系统,不能假设系统负载低,必须为应付高负载下的进程调度做精心的设计。
当然,这些设计对于低负载(且没有什么实时性要求)的环境,没多大用。极端情况下,如果CPU的负载始终保持0或1(永远都只有一个进程或没有进程需要在CPU上运行),那么这些设计基本上都是徒劳的。
优先级
现在的操作系统为了协调多个进程的“同时”运行,最基本的手段就是给进程定义优先级。定义了进程的优先级,如果有多个进程同时处于可执行状态,那么谁优先级高谁就去执行,没有什么好纠结的了。
那么,进程的优先级该如何确定呢?有两种方式:由用户程序指定、由内核的调度程序动态调整。(下面会说到)
linux内核将进程分成两个级别:普通进程和实时进程。实时进程的优先级都高于普通进程,除此之外,它们的调度策略也有所不同。
实时进程的调度
实时,原本的涵义是“给定的操作一定要在确定的时间内完成”。重点并不在于操作一定要处理得多快,而是时间要可控(在最坏情况下也不能突破给定的时间)。
这样的“实时”称为“硬实时”,多用于很精密的系统之中(比如什么火箭、导弹之类的)。一般来说,硬实时的系统是相对比较专用的。
像linux这样的通用操作系统显然没法满足这样的要求,中断处理、虚拟内存、等机制的存在给处理时间带来了很大的不确定性。硬件的cache、磁盘寻道、总线争用、也会带来不确定性。
比如考虑“i++;”这么一句C代码。绝大多数情况下,它执行得很快。但是极端情况下还是有这样的可能:
1、i的内存空间未分配,CPU触发缺页异常。而linux在缺页异常的处理代码中试图分配内存时,又可能由于系统内存紧缺而分配失败,导致进程进入睡眠;
2、代码执行过程中硬件产生中断,linux进入中断处理程序而搁置当前进程。而中断处理程序的处理过程中又可能发生新的硬件中断,中断永远嵌套不止……;等等……
而像linux这样号称实现了“实时”的通用操作系统,其实只是实现了“软实时”,即尽可能地满足进程的实时需求。
如果一个进程有实时需求(它是一个实时进程),则只要它是可执行状态的,内核就一直让它执行,以尽可能地满足它对CPU的需要,直到它完成所需要做的事情,然后睡眠或退出(变为非可执行状态)。
而如果有多个实时进程都处于可执行状态,则内核会先满足优先级最高的实时进程对CPU的需要,直到它变为非可执行状态。于是,只要高优先级的实时进程一直处于可执行状态,低优先级的实时进程就一直不能得到CPU;只要一直有实时进程处于可执行状态,普通进程就一直不能得到CPU。
(后来,内核添加了/proc/sys/kernel/sched_rt_runtime_us和/proc/sys/kernel/sched_rt_period_us两个参数,限定了在以sched_rt_period_us为周期的时间内,实时进程最多只能运行sched_rt_runtime_us这么多时间。这样就在一直有实时进程处于可执行状态的情况下,给普通进程留了一点点能够得到执行的机会。参阅《linux组调度浅析》。)
那么,如果多个相同优先级的实时进程都处于可执行状态呢?这时就有两种调度策略可供选择:
1、SCHED_FIFO:先进先出。直到先被执行的进程变为非可执行状态,后来的进程才被调度执行。在这种策略下,先来的进程可以行sched_yield系统调用,自愿放弃CPU,以让权给后来的进程;
2、SCHED_RR:轮转调度。内核为实时进程分配时间片,在时间片用完时,让下一个进程使用CPU;
强调一下,这两种调度策略仅仅针对于相同优先级的多个实时进程同时处于可执行状态的情况。
在linux下,用户程序可以通过sched_setscheduler系统调用来设置进程的调度策略以及相关调度参数;sched_setparam系统调用则只用于设置调度参数。这两个系统调用要求用户进程具有设置进程优先级的能力(CAP_SYS_NICE,一般来说需要root权限)(参阅capability相关的文章)。
通过将进程的策略设为SCHED_FIFO或SCHED_RR,使得进程变为实时进程。而进程的优先级则是通过以上两个系统调用在设置调度参数时指定的。
对于实时进程,内核不会试图调整其优先级。因为进程实时与否?有多实时?这些问题都是跟用户程序的应用场景相关,只有用户能够回答,内核不能臆断。
综上所述,实时进程的调度是非常简单的。进程的优先级和调度策略都由用户定死了,内核只需要总是选择优先级最高的实时进程来调度执行即可。唯一稍微麻烦一点的只是在选择具有相同优先级的实时进程时,要考虑两种调度策略。
普通进程的调度
实时进程调度的中心思想是,让处于可执行状态的最高优先级的实时进程尽可能地占有CPU,因为它有实时需求;而普通进程则被认为是没有实时需求的进程,于是调度程序力图让各个处于可执行状态的普通进程和平共处地分享CPU,从而让用户觉得这些进程是同时运行的。
与实时进程相比,普通进程的调度要复杂得多。内核需要考虑两件麻烦事:
一、动态调整进程的优先级
按进程的行为特征,可以将进程分为“交互式进程”和“批处理进程”:
交互式进程(如桌面程序、服务器、等)主要的任务是与外界交互。这样的进程应该具有较高的优先级,它们总是睡眠等待外界的输入。而在输入到来,内核将其唤醒时,它们又应该很快被调度执行,以做出响应。比如一个桌面程序,如果鼠标点击后半秒种还没反应,用户就会感觉系统“卡”了;
批处理进程(如编译程序)主要的任务是做持续的运算,因而它们会持续处于可执行状态。这样的进程一般不需要高优先级,比如编译程序多运行了几秒种,用户多半不会太在意;
如果用户能够明确知道进程应该有怎样的优先级,可以通过nice、setpriority(非实时进程优先级的设置)系统调用来对优先级进行设置。(如果要提高进程的优先级,要求用户进程具有CAP_SYS_NICE能力。)
然而应用程序未必就像桌面程序、编译程序这样典型。程序的行为可能五花八门,可能一会儿像交互式进程,一会儿又像批处理进程。以致于用户难以给它设置一个合适的优先级。再者,即使用户明确知道一个进程是交互式还是批处理,也多半碍于权限或因为偷懒而不去设置进程的优先级。(你又是否为某个程序设置过优先级呢?)
于是,最终,区分交互式进程和批处理进程的重任就落到了内核的调度程序上。
调度程序关注进程近一段时间内的表现(主要是检查其睡眠时间和运行时间),根据一些经验性的公式,判断它现在是交互式的还是批处理的?程度如何?最后决定给它的优先级做一定的调整。
进程的优先级被动态调整后,就出现了两个优先级:
1、用户程序设置的优先级(如果未设置,则使用默认值),称为静态优先级。这是进程优先级的基准,在进程执行的过程中往往是不改变的;
2、优先级动态调整后,实际生效的优先级。这个值是可能时时刻刻都在变化的;
二、调度的公平性
在支持多进程的系统中,理想情况下,各个进程应该是根据其优先级公平地占有CPU。而不会出现“谁运气好谁占得多”这样的不可控的情况。
linux实现公平调度基本上是两种思路:
1、给处于可执行状态的进程分配时间片(按照优先级),用完时间片的进程被放到“过期队列”中。等可执行状态的进程都过期了,再重新分配时间片;
2、动态调整进程的优先级。随着进程在CPU上运行,其优先级被不断调低,以便其他优先级较低的进程得到运行机会;
后一种方式有更小的调度粒度,并且将“公平性”与“动态调整优先级”两件事情合而为一,大大简化了内核调度程序的代码。因此,这种方式也成为内核调度程序的新宠。
强调一下,以上两点都是仅针对普通进程的。而对于实时进程,内核既不能自作多情地去动态调整优先级,也没有什么公平性可言。
普通进程具体的调度算法非常复杂,并且随linux内核版本的演变也在不断更替(不仅仅是简单的调整),所以本文就不继续深入了。有兴趣的朋友可以参考下面的链接:《Linux
调度器发展简述》
调度程序的效率
“优先级”明确了哪个进程应该被调度执行,而调度程序还必须要关心效率问题。调度程序跟内核中的很多过程一样会频繁被执行,如果效率不济就会浪费很多CPU时间,导致系统性能下降。
在linux 2.4时,可执行状态的进程被挂在一个链表中。每次调度,调度程序需要扫描整个链表,以找出最优的那个进程来运行。复杂度为O(n);
在linux
2.6早期,可执行状态的进程被挂在N(N=140)个链表中,每一个链表代表一个优先级,系统中支持多少个优先级就有多少个链表。每次调度,调度程序只需要从第一个不为空的链表中取出位于链表头的进程即可。这样就大大提高了调度程序的效率,复杂度为O(1);
在linux 2.6近期的版本中,可执行状态的进程按照优先级顺序被挂在一个红黑树(可以想象成平衡二叉树)中。每次调度,调度程序需要从树中找出优先级最高的进程。复杂度为O(logN)。
那么,为什么从linux 2.6早期到近期linux 2.6版本,调度程序选择进程时的复杂度反而增加了呢?
这是因为,与此同时,调度程序对公平性的实现从上面提到的第一种思路改变为第二种思路(通过动态调整优先级实现)。而O(1)的算法是基于一组数目不大的链表来实现的,按我的理解,这使得优先级的取值范围很小(区分度很低),不能满足公平性的需求。而使用红黑树则对优先级的取值没有限制(可以用32位、64位、或更多位来表示优先级的值),并且O(logN)的复杂度也还是很高效的。
调度触发的时机
调度的触发主要有如下几种情况:
1、当前进程(正在CPU上运行的进程)状态变为非可执行状态。
进程执行系统调用主动变为非可执行状态。比如执行nanosleep进入睡眠、执行exit退出、等等;
进程请求的资源得不到满足而被迫进入睡眠状态。比如执行read系统调用时,磁盘高速缓存里没有所需要的数据,从而睡眠等待磁盘IO;
进程响应信号而变为非可执行状态。比如响应SIGSTOP进入暂停状态、响应SIGKILL退出、等等;
2、抢占。进程运行时,非预期地被剥夺CPU的使用权。这又分两种情况:进程用完了时间片、或出现了优先级更高的进程。
优先级更高的进程受正在CPU上运行的进程的影响而被唤醒。如发送信号主动唤醒,或因为释放互斥对象(如释放锁)而被唤醒;
内核在响应时钟中断的过程中,发现当前进程的时间片用完;
内核在响应中断的过程中,发现优先级更高的进程所等待的外部资源的变为可用,从而将其唤醒。比如CPU收到网卡中断,内核处理该中断,发现某个socket可读,于是唤醒正在等待读这个socket的进程;再比如内核在处理时钟中断的过程中,触发了定时器,从而唤醒对应的正在nanosleep系统调用中睡眠的进程;
其他问题
1、内核抢占
理想情况下,只要满足“出现了优先级更高的进程”这个条件,当前进程就应该被立刻抢占。但是,就像多线程程序需要用锁来保护临界区资源一样,内核中也存在很多这样的临界区,不大可能随时随地都能接收抢占。
linux 2.4时的设计就非常简单,内核不支持抢占。进程运行在内核态时(比如正在执行系统调用、正处于异常处理函数中),是不允许抢占的。必须等到返回用户态时才会触发调度(确切的说,是在返回用户态之前,内核会专门检查一下是否需要调度);
linux 2.6则实现了内核抢占,但是在很多地方还是为了保护临界区资源而需要临时性的禁用内核抢占。
也有一些地方是出于效率考虑而禁用抢占,比较典型的是spin_lock。spin_lock是这样一种锁,如果请求加锁得不到满足(锁已被别的进程占有),则当前进程在一个死循环中不断检测锁的状态,直到锁被释放。
为什么要这样忙等待呢?因为临界区很小,比如只保护“i+=j++;”这么一句。如果因为加锁失败而形成“睡眠-唤醒”这么个过程,就有些得不偿失了。那么既然当前进程忙等待(不睡眠),谁又来释放锁呢?其实已得到锁的进程是运行在另一个CPU上的,并且是禁用了内核抢占的。这个进程不会被其他进程抢占,所以等待锁的进程只有可能运行在别的CPU上。(如果只有一个CPU呢?那么就不可能存在等待锁的进程了。)
而如果不禁用内核抢占呢?那么得到锁的进程将可能被抢占,于是可能很久都不会释放锁。于是,等待锁的进程可能就不知何年何月得偿所望了。
对于一些实时性要求更高的系统,则不能容忍spin_lock这样的东西。宁可改用更费劲的“睡眠-唤醒”过程,也不能因为禁用抢占而让更高优先级的进程等待。比如,嵌入式实时linux
montavista就是这么干的。
由此可见,实时并不代表高效。很多时候为了实现“实时”,还是需要对性能做一定让步的。
2、多处理器下的负载均衡
前面我们并没有专门讨论多处理器对调度程序的影响,其实也没有什么特别的,就是在同一时刻能有多个进程并行地运行而已。那么,为什么会有“多处理器负载均衡”这个事情呢?
如果系统中只有一个可执行队列,哪个CPU空闲了就去队列中找一个最合适的进程来执行。这样不是很好很均衡吗?
的确如此,但是多处理器共用一个可执行队列会有一些问题。显然,每个CPU在执行调度程序时都需要把队列锁起来,这会使得调度程序难以并行,可能导致系统性能下降。而如果每个CPU对应一个可执行队列则不存在这样的问题。
另外,多个可执行队列还有一个好处。这使得一个进程在一段时间内总是在同一个CPU上执行,那么很可能这个CPU的各级cache中都缓存着这个进程的数据,很有利于系统性能的提升。
所以,在linux下,每个CPU都有着对应的可执行队列,而一个可执行状态的进程在同一时刻只能处于一个可执行队列中。
于是,“多处理器负载均衡”这个麻烦事情就来了。内核需要关注各个CPU可执行队列中的进程数目,在数目不均衡时做出适当调整。什么时候需要调整,以多大力度进程调整,这些都是内核需要关心的。当然,尽量不要调整最好,毕竟调整起来又要耗CPU、又要锁可执行队列,代价还是不小的。
另外,内核还得关心各个CPU的关系。两个CPU之间,可能是相互独立的、可能是共享cache的、甚至可能是由同一个物理CPU通过超线程技术虚拟出来的……CPU之间的关系也是实现负载均衡的重要依据。关系越紧密,进程在它们之间迁移的代价就越小。参见《linux内核SMP负载均衡浅析》。
3、优先级继承
由于互斥,一个进程(设为A)可能因为等待进入临界区而睡眠。直到正在占有相应资源的进程(设为B)退出临界区,进程A才被唤醒。
可能存在这样的情况:A的优先级非常高,B的优先级非常低。B进入了临界区,但是却被其他优先级较高的进程(设为C)抢占了,而得不到运行,也就无法退出临界区。于是A也就无法被唤醒。
A有着很高的优先级,但是现在却沦落到跟B一起,被优先级并不太高的C抢占,导致执行被推迟。这种现象就叫做优先级反转。
出现这种现象是很不合理的。较好的应对措施是:当A开始等待B退出临界区时,B临时得到A的优先级(还是假设A的优先级高于B),以便顺利完成处理过程,退出临界区。之后B的优先级恢复。这就是优先级继承的方法。
为了实现优先级继承,内核又得做很多事情。更细节的东西可以参考一下关于“优先级反转”或“优先级继承”的文章。
4、中断处理线程化
在linux下,中断处理程序运行于一个不可调度的上下文中。从CPU响应硬件中断自动跳转到内核设定的中断处理程序去执行,到中断处理程序退出,整个过程是不能被抢占的。
一个进程如果被抢占了,可以通过保存在它的进程控制块(task_struct)中的信息,在之后的某个时间恢复它的运行。而中断上下文则没有task_struct,被抢占了就没法恢复了。
中断处理程序不能被抢占,也就意味着中断处理程序的“优先级”比任何进程都高(必须等中断处理程序完成了,进程才能被执行)。但是在实际的应用场景中,可能某些实时进程应该得到比中断处理程序更高的优先级。
于是,一些实时性要求更高的系统就给中断处理程序赋予了task_struct以及优先级,使得它们在必要的时候能够被高优先级的进程抢占。但是显然,做这些工作是会给系统造成一定开销的,这也是为了实现“实时”而对性能做出的一种让步。
6. 程序运行时内存布局
我们在写程序时,既有程序的逻辑代码,也有在程序中定义的变量等数据,那么当我们的程序进行时,我们的代码和数据究竟是存放在哪里的呢?下面就来总结一下。
一、程序运行时的内存空间情况
-
-
-
-
int main()
-
{
-
printf("%d\n", getpid());
-
while(1);
-
return 0;
-
}
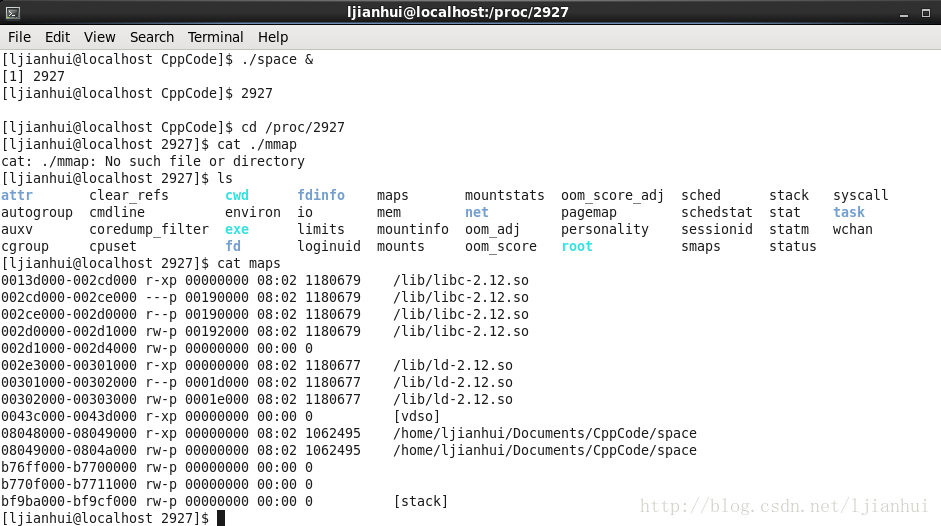
从上图我们可以非常形象地看到一个程序进行时的内存分布情况。下面我们将会结合上图,进行更加深入的对内存中的数据段的解说。
该段用来存放没有被初始化或初始化为0的全局变量,因为是全局变量,所以在程序运行的整个生命周期内都存在于内存中。有趣的是这个段中的变量只占用程序运行时的内存空间,而不占用程序文件的储存空间。可以用以下程序来说明这点(通过符号表可以看到未初始化的全局变量没有被存放在任何段,只是一个未定义的“COMMON符号”,这其实是跟不同的语言与不同的编译器实现有关,有些编译器会将全局未初始化变量存放在.bss段,有些则不放,只是预留一个未定义的全局变量符号,等到最终连接成可执行文件的时候再在.bss段分配空间。)
文件名为bss.c
-
-
-
int bss_data[1024 * 1024];
-
-
int main()
-
{
-
return 0;
-
}

-
-
-
int data_data[1024 * 1024] = {1};
-
-
int main()
-
{
-
return 0;
-
}

-
void func()
-
{
-
int a = 0;
-
int *n_ptr = malloc(sizeof(int));
-
char *c_ptr = new char;
-
}
-
-
-
-
-
int main()
-
{
-
int *n_ptr = malloc(sizeof(int));
-
printf("%d\n", getpid());
-
while(1);
-
free(n_ptr);
-
return 0;
-
}
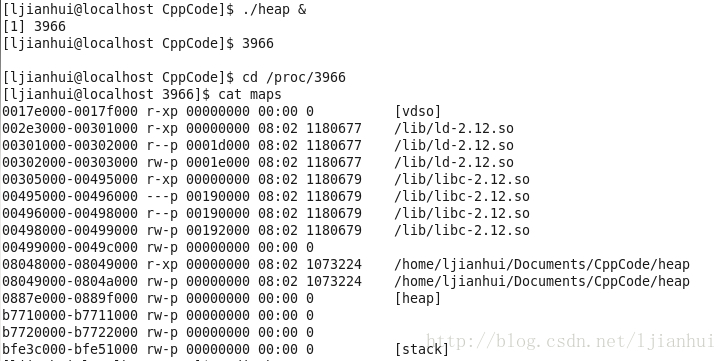
C语言内存模型及运行时内存布局
我们知道,C程序开发并编译完成后,要载入内存(主存或内存条)才能运行(请查看:载入内存,让程序运行起来),变量名、函数名都会对应内存中的一块区域。
内存中运行着很多程序,我们的程序只占用一部分空间,这部分空间又可以细分为以下的区域:
| 内存分区 | 说明 |
|---|---|
| 程序代码区(code area) | 存放函数体的二进制代码 |
| 静态数据区(data area) | 也称全局数据区,包含的数据类型比较多,如全局变量、静态变量、一般常量、字符串常量。其中:
注意:静态数据区的内存在程序结束后由操作系统释放。 |
| 堆区(heap area) | 一般由程序员分配和释放,若程序员不释放,程序运行结束时由操作系统回收。malloc()、calloc()、free()
等函数操作的就是这块内存,这也是本章要讲解的重点。 注意:这里所说的堆区与数据结构中的堆不是一个概念,堆区的分配方式倒是类似于链表。 |
| 栈区(stack area) | 由系统自动分配释放,存放函数的参数值、局部变量的值等。其操作方式类似于数据结构中的栈。 |
| 命令行参数区 | 存放命令行参数和环境变量的值,如通过main()函数传递的值。 |

图1:C语言内存模型示意图
提示:关于局部的字符串常量是存放在全局的常量区还是栈区,不同的编译器有不同的实现,VC 将局部常量像局部变量一样对待,存储于栈(⑥区)中,TC则存储在静态数据区的常量区(②区)。
注意:未初始化的全局变量的默认值是 0,而未初始化的局部变量的值却是垃圾值(任意值)。请看下面的代码:
-
-
-
int global;
-
int main()
-
{
-
int local;
-
printf("global = %d\n", global);
-
printf("local = %d\n", local);
-
getch();
-
return 0;
-
}
运行结果:
global = 0
local = 1912227604
为了更好的理解内存模型,请大家看下面一段代码:
-
-
-
-
int a = 0; // 全局初始化区(④区)
-
char *p1; // 全局未初始化区(③区)
-
int main()
-
{
-
int b; // 栈区
-
char s[] = "abc"; // 栈区
-
char *p2; // 栈区
-
char *p3 = "123456"; // 123456\0 在常量区(②),p3在栈上,体会与 char s[]="abc"; 的不同
-
static int c = 0; // 全局初始化区
-
p1 = (char *)malloc(10), // 堆区
-
p2 = (char *)malloc(20); // 堆区
-
// 123456\0 放在常量区,但编译器可能会将它与p3所指向的"123456"优化成一个地方
-
strcpy(p1, "123456");
-
}
1 内存模型
在C语言中,内存可分用五个部分:
1. BSS段(Block Started by Symbol): 用来存放程序中未初始化的全局变量的内存区域。
2. 数据段(data segment): 用来存放程序中已初始化的全局变量的内存区域。
3. 代码段(text segment): 用来存放程序执行代码的内存区域。
4. 堆(heap):用来存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc分配内存时,新分配的内存就被动态添加到堆上,当进程调用free释放内存时,会从堆中剔除。
5. 栈(stack):存放程序中的局部变量(但不包括static声明的变量,static变量放在数据段中)。同时,在函数被调用时,栈用来传递参数和返回值。由于栈先进先出特点。所以栈特别方便用来保存/恢复调用现场。
APUE中的一个典型C内存空间分布图
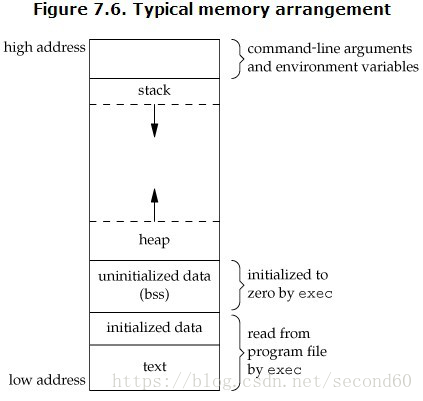
如下往上,分别是text段,data段,BSS段,堆,栈
Linux下32位环境的用户空间内存分布情况
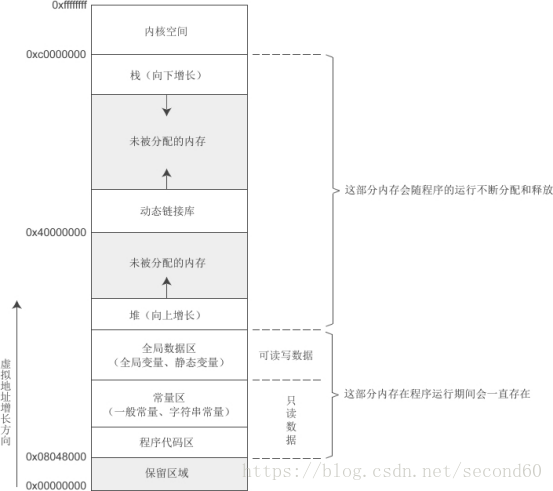
由上图可知:
0x0000 0000:保留区域, 最底层
代码区:用来存放程序代码和常量,只读(运行期会一直存在)
常量区:一般常量,字符常量,只读(运行期会一直存在)
全局数据区:全局变量和静态变量,可读写(运行期会一直存在)
堆段:malloc/free的内存,malloc时分配,free时释放(向上增长)
未分配堆内存
0x4000 0000:动态链接库
未分配栈内存
栈段:局部变量,函数调用参数返回值(向上增长)
0xc000 0000 ~ 0xffff ffff:内核空间(1G)
2栈详解
栈(stack): 是由系统自动分配和释放,存放函数的参数值,返回值,局部变量等。其操作方式类似于数据结构中的栈。
2.1栈的申请
1. 当在函数或块内部声明一个局部变量时,如:int nTmp; 系统会判断申请的空间是否足够,足够,在栈中开辟空间,提供内存;不够空间,报异常提示栈溢出。
2. 当调用一个函数时,系统会自动为参数当局部变量,压进栈中,当函数调用结束时,会自动提升堆栈。(可查看汇编中的函数调用机制)
2.2栈的大小
栈是有一定大小的,通常情况下,栈只有2M,不同系统栈的大小可能不同。
在linux中,查看进程/线程栈大小,命令: ulimit -s
$ ulimit -s
$ 8192
我的系统中栈大小为 8192, 有些系统为 10240, 具体查看自已系统栈大小
设置栈大小:
1. 临时改变栈大小:ulimit -s 10240
2. 开机设置栈大小:在/etc/rc.local中加入 ulimit -s 10240
3. 改变栈大小: 在/etc/security/limits.conf中加入
* soft stack 10240
所以,在声明局部变量时,新手要特别注意栈的大小:
1. 对于局部变量,尽量不定义大的变量,如大数组(大于2*1024*1024字节)
char buf[2*1024*1024]; // 可能会导致栈溢出
2. 对于内存较大或不知大小的变量,用堆分配,局部变量用指针,注意要释放
char* pBuf = (char*)malloc(2*1024*1024); // char* 为局部变量 malloc的内存在堆
free(pBuf);
3. 或定义在全局区中,static变量 或常量区中
static char buf[2*1024*1024];
2.3栈的生长方向
栈的生长方向和存放数据的方向相反,自顶向下
2.4 栈分配例子
int function( int var1 ,int var2)
{
int var3;
int var4;
}
var1,var2,var3在栈中的图如下:
|
0xc000 0000 |
var1 |
|
0xc000 0000 - 4 |
var2 |
|
0xc000 0000 - 8 |
var3 |
|
0xc000 0000 - 12 |
var4 |
3 堆详解
堆(heap):是用来存放动态申请或释放的区域。需要程序员分配和释放,系统不会自动管理,如果用完不释放,将会造成内存泄露,直到进程结速后,系统自动回收。
3.1 堆的目的
为什么在堆呢?原因很简单,在栈中,大小是有限制的,能常大小为2M,如果需要更大的空间,那么就要用到堆了,堆的目的就是为了分配使用更大的空间。
3.2申请和释放
int function()
{
char *pTmp = (char*) malloc(1024); // malloc在堆中分配1024字节空间
//pTmp 为局部变量,只占四字节
free(pTmp); // free为手动释放堆中空间
pTmp = NULL; // 防止pTmp变野指针误用
}
3.3堆的大小
堆是可以申请大块内存的区域,但堆的大小到底有多大,下面分析下,以32位系统为例。
在linux中,堆区的内存申请,在32位系统中,理论上:2^32=4G,但如上面的内存分布图可知:内核占用1G空间。
|
0xFFFF FFFF |
1G内核空间 |
|
0xC000 0000 |
|
|
0XBFFF FFF |
3G用户空间(包text段,data段,BSS段,堆,栈) |
|
0x0000 0000 |
如上所知,理论上,使用malloc最大能够申请空间大约3G。但这是理论值,因为实际中,还会包含代码区,全局变量区和栈区。
char *buf = (char*) malloc(3GB); // 理论上
3.4 堆的生长方向
如上面的图可知,堆是由低地址向高地址生长的
3.5 堆的注意事项
堆虽然可以分配较大的空间,但有一些要注意的地方,否则会出现问题。
1. 释放问题:分配了堆内存,一定要记得手动释放,否则将会导致内存泄露
void* alloc(int size)
{
char* ptr = (char*)malloc(size);
return ptr;
}
上面函数如果外部调用,没有释放,将内存不会释放造成泄露
2. 碎片问题:如果频繁地调用内存分配和释放,将会使堆内存造成很多内存碎片,从而造成空间浪费和效率低下。
a) 对于比较固定,或可预测大小的,可以程序启动时,即分配好空间,如:某个对象不会超过500个,那个可先生成,object *ptr = (object*)malloc(object_size*500);
b) 结构对齐,尽量使结构不浪费内存
3. 超堆大小问题:如果申请内存超过堆大小,会出现虚拟内存不足等问题
a) 尽量不要申请很大的内存,如直需要,可采用内存数据库等
4. 分配是否成功问题:申请内存后,都在判断内存是否分配成功,分配成功后才能使用,否则会出现段错误
char * pTmp = (char*)malloc(102400);
if(pTmp == 0) // 一定在记得判断
{
return false;
}
5. 释放后野指针问题:释放指针后,一定要记得把指针的值设置成NULL,防止指针被释放后误用
free(pTmp);
pTmp = NULL; // 防止变野指针
6. 多次释放问题:如果第5并没置NULL,多次释放将会出现问题。
8. Linux的IPC都有哪些
为什么要进行进程间的通讯(IPC (Inter-process communication))
数据传输:一个进程需要将它的数据发送给另一个进程,发送的数据量在一个字节到几M字节之间
共享数据:多个进程想要操作共享数据,一个进程对共享数据的修改,别的进程应该立刻看到。
通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
资源共享:多个进程之间共享同样的资源。为了作到这一点,需要内核提供锁和同步机制。
进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
linux常用的进程间的通讯方式
(1)、管道(pipe):管道可用于具有亲缘关系的进程间的通信,是一种半双工的方式,数据只能单向流动,允许一个进程和另一个与它有共同祖先的进程之间进行通信。
(2)、命名管道(named pipe):命名管道克服了管道没有名字的限制,同时除了具有管道的功能外(也是半双工),它还允许无亲缘关系进程间的通信。命名管道在文件系统中有对应的文件名。命名管道通过命令mkfifo或系统调用mkfifo来创建。
(3)、信号(signal):信号是比较复杂的通信方式,用于通知接收进程有某种事件发生了,除了进程间通信外,进程还可以发送信号给进程本身;linux除了支持Unix早期信号语义函数sigal外,还支持语义符合Posix.1标准的信号函数sigaction(实际上,该函数是基于BSD的,BSD为了实现可靠信号机制,又能够统一对外接口,用sigaction函数重新实现了signal函数)。
(4)、消息队列:消息队列是消息的链接表,包括Posix消息队列system V消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺
(5)、共享内存:使得多个进程可以访问同一块内存空间,是最快的可用IPC形式。是针对其他通信机制运行效率较低而设计的。往往与其它通信机制,如信号量结合使用,来达到进程间的同步及互斥。
(6)、内存映射:内存映射允许任何多个进程间通信,每一个使用该机制的进程通过把一个共享的文件映射到自己的进程地址空间来实现它。
(7)、信号量(semaphore):主要作为进程间以及同一进程不同线程之间的同步手段。
(8)、套接字(Socket):更为一般的进程间通信机制,可用于不同机器之间的进程间通信。起初是由Unix系统的BSD分支开发出来的,但现在一般可以移植到其它类Unix系统上:Linux和System V的变种都支持套接字。
linux进程间通信(IPC)有几种方式
一。管道(pipe)
管道是Linux支持的最初IPC方式,管道可分为无名管道,有名管道等。
(一)无名管道,它具有几个特点:
1) 管道是半双工的,只能支持数据的单向流动;两进程间需要通信时需要建立起两个管道;
2) 无名管道使用pipe()函数创建,只能用于父子进程或者兄弟进程之间;
3) 管道对于通信的两端进程而言,实质上是一种独立的文件,只存在于内存中;
4) 数据的读写操作:一个进程向管道中写数据,所写的数据添加在管道缓冲区的尾部;
另一个进程在管道中缓冲区的头部读数据。
(二)有名管道
有名管道也是半双工的,不过它允许没有亲缘关系的进程间进行通信。具体点说就是,有名管道提供了一个路径名与之进行关联,以FIFO(先进先出)的形式存在于文件系统中。这样即使是不相干的进程也可以通过FIFO相互通信,只要他们能访问已经提供的路径。
值得注意的是,只有在管道有读端时,往管道中写数据才有意义。否则,向管道写数据的进程会接收到内核发出来的SIGPIPE信号;应用程序可以自定义该信号处理函数,或者直接忽略该信号。
管道是*nix系统进程间通信的最古老形式,所有*nix都提供这种通信方式。管道是一种半双工的通信机制,也就是说,它只能一端用来读,另外一端用来写;另外,管道只能用来在具有公共祖先的两个进程之间通信。管道通信遵循先进先出的原理,并且数据只能被读取一次,当此段数据被读取后,马上会从数据中消失,这一点很重要。
Linux上,创建管道使用pipe函数,当它执行后,会产生两个文件描述符,分别为读端和写端。单个进程中的管道几乎没有任何作用,通常会先调用pipe,然后调用fork,从而创建从父进程到子进程的IPC通道。
------------------------------
waitpid()会暂时停止目前进程的执行,直到有信号来到或子进程结束。
#include<sys/types.h>
#include<sys/wait.h>
定义函数 pid_t waitpid(pid_t pid, int * status, int options);
---------------------------------------------------------------------------------------------------------------------------
二。信号量(semophore)
信号量是一种计数器,可以控制进程间多个线程或者多个进程对资源的同步访问,它常实现为一种锁机制。实质上,信号量是一个被保护的变量,并且只能通过初始化和两个标准的原子操作(P/V)来访问。(P,V操作也常称为wait(s),signal(s))
三。信号(Signal)
信号是Unix系统中使用的最古老的进程间通信的方法之一。操作系统通过信号来通知某一进程发生了某一种预定好的事件;接收到信号的进程可以选择不同的方式处理该信号,一是可以采用默认处理机制-进程中断或退出,一是忽略该信号,还有就是自定义该信号的处理函数,执行相应的动作。
内核为进程生产信号,来响应不同的事件,这些事件就是信号源。信号源可以是:异常,其他进程,终端的中断(Ctrl-C,Ctrl+\等),作业的控制(前台,后台进程的管理等),分配额问题(cpu超时或文件过大等),内核通知(例如I/O就绪等),报警(计时器)。
四。消息队列(Message Queue)
消息队列就是消息的一个链表,它允许一个或者多个进程向它写消息,一个或多个进程向它读消息。Linux维护了一个消息队列向量表:msgque,来表示系统中所有的消息队列。
消息队列克服了信号传递信息少,管道只能支持无格式字节流和缓冲区受限的缺点。
五。共享内存(shared memory)
共享内存映射为一段可以被其他进程访问的内存。该共享内存由一个进程所创建,然后其他进程可以挂载到该共享内存中。共享内存是最快的IPC机制,但由于linux本身不能实现对其同步控制,需要用户程序进行并发访问控制,因此它一般结合了其他通信机制实现了进程间的通信,例如信号量。
五。套接字(socket)
socket也是一种进程间的通信机制,不过它与其他通信方式主要的区别是:它可以实现不同主机间的进程通信。一个套接口可以看做是进程间通信的端点(endpoint),每个套接口的名字是唯一的;其他进程可以访问,连接和进行数据通信
9.共享内存的本质
进程间通信---共享内存
------->双向通信
------->仅是一块内存,可以随意写入数据
------->无同步互斥
------->生命周期随内核
-----共享内存是最快的IPC形式.共享内存的本质是物理内存,一旦这样的内存映射到共享它的进程的地址空间,这些空间不涉及内核.
进程是一个独立的资源管理单元,不同进程间的资源是独立的,不能在一个进程中访问另一个进程的用户空间和内存空间。但是,进程不是孤立的,不同进程之间需要信息的交互和状态的传递,因此需要进程间数据的传递、同步和异步的机制。
当然,这些机制不能由哪一个进程进行直接管理,只能由操作系统来完成其管理和维护,Linux提供了大量的进程间通信机制,包括同一个主机下的不同进程和网络主机间的进程通信,如下图所示:
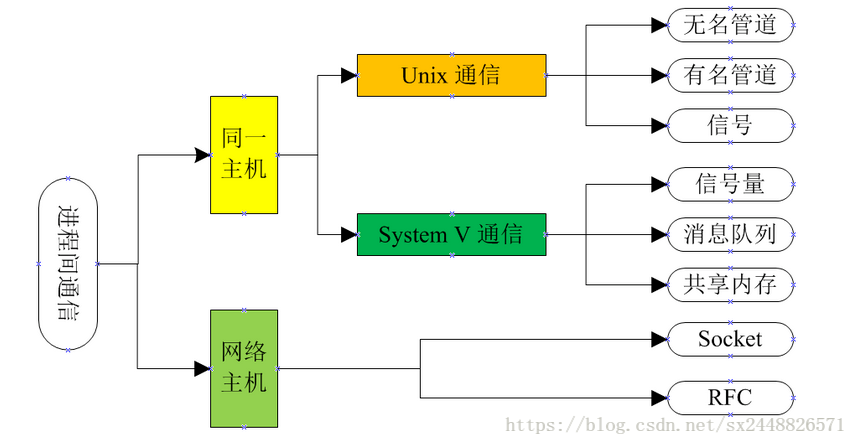
共享内存是进程间通信中最简单的方式之中的一个。
共享内存是系统出于多个进程之间通讯的考虑,而预留的的一块内存区。
共享内存同意两个或很多其他进程訪问同一块内存,就如同 malloc() 函数向不同进程返回了指向同一个物理内存区域的指针。
当一个进程改变了这块地址中的内容的时候,其他进程都会察觉到这个更改
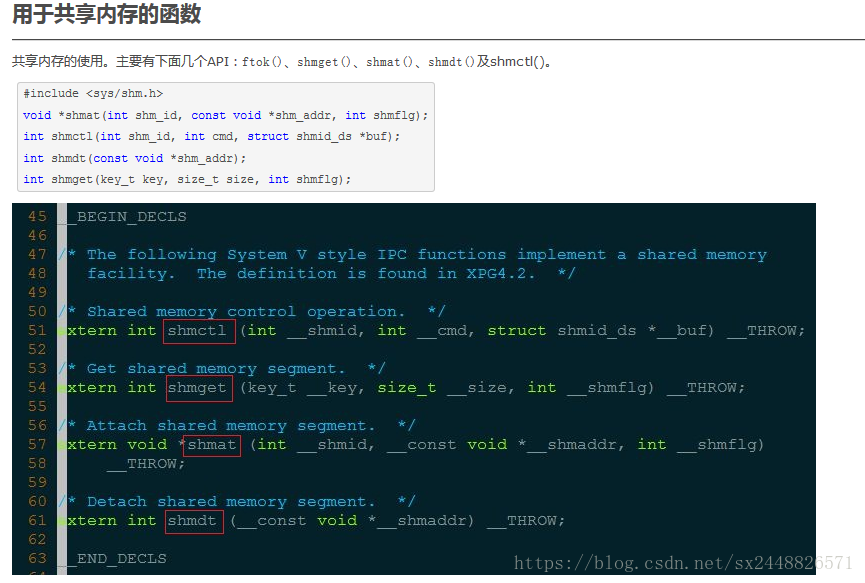
用ftok()函数获得一个ID号
应用说明,在IPC中,我们经经常使用用key_t的值来创建或者打开信号量,共享内存和消息队列。
key_t ftok(const char *pathname, int proj_id);| 參数 | 描写叙述 |
|---|---|
| pathname | 一定要在系统中存在而且进程能够訪问的 |
| proj_id | 一个1-255之间的一个整数值,典型的值是一个ASCII值。 |
当成功运行的时候,一个key_t值将会被返回。否则-1被返回。我们能够使用strerror(errno)来确定详细的错误信息。
考虑到应用系统可能在不同的主机上应用,能够直接定义一个key,而不用ftok获得:
#define IPCKEY 0x344378创建共享内存
进程通过调用shmget(Shared Memory GET,获取共享内存)来分配一个共享内存块。
int shmget(key_t key ,int size,int shmflg)| 參数 | 描写叙述 |
|---|---|
| key | 一个用来标识共享内存块的键值 |
| size | 指定了所申请的内存块的大小 |
| shmflg | 操作共享内存的标识 |
返回值:假设成功,返回共享内存表示符,假设失败,返回-1。
该函数的第一个參数key是一个用来标识共享内存块的键值。
该函数的第二个參数size指定了所申请的内存块的大小
第三个參数shmflg是一组标志。通过特定常量的按位或操作来shmget
映射共享内存
shmat()是用来同意本进程訪问一块共享内存的函数。将这个内存区映射到本进程的虚拟地址空间。
int shmat(int shmid,char *shmaddr,int flag)| 參数 | 描写叙述 |
|---|---|
| shmid | 那块共享内存的ID。是shmget函数返回的共享存储标识符 |
| shmaddr | 是共享内存的起始地址,假设shmaddr为0,内核会把共享内存映像到调用进程的地址空间中选定位置。假设shmaddr不为0,内核会把共享内存映像到shmaddr指定的位置。所以一般把shmaddr设为0。 |
| shmflag | 是本进程对该内存的操作模式。假设是SHM_RDONLY的话,就是仅仅读模式。
其他的是读写模式 |
成功时,这个函数返回共享内存的起始地址。失败时返回-1。
共享内存解除映射
当一个进程不再须要共享内存时,须要把它从进程地址空间中多里。
int shmdt(char *shmaddr)| 參数 | 描写叙述 |
|---|---|
| shmaddr | 那块共享内存的起始地址 |
成功时返回0。失败时返回-1。
应通过调用 shmdt(Shared Memory Detach。脱离共享内存块)函数与该共享内存块脱离。
将由 shmat 函数返回的地址传递给这个函数。假设当释放这个内存块的进程是最后一个使用该内存块的进程,则这个内存块将被删除。
控制释放
shmctl控制对这块共享内存的使用
函数原型
int shmctl( int shmid , int cmd , struct shmid_ds *buf );| 參数 | 描写叙述 |
|---|---|
| shmid | 是共享内存的ID。 |
| cmd | 控制命令 |
| buf | 一个结构体指针。
IPC_STAT的时候,取得的状态放在这个结构体中。假设要改变共享内存的状态,用这个结构体指定。 |
当中cmd的取值例如以下
| cmd | 描写叙述 |
|---|---|
| IPC_STAT | 得到共享内存的状态 |
| IPC_SET | 改变共享内存的状态 |
| IPC_RMID | 删除共享内存 |
返回值: 成功:0 失败:-1
可以看到内存映射中需要的一个参数是int fd(文件的标识符),可见函数是通过fd将文件内容映射到一个内存空间, 我需要创建另一个映射来得到文件内容并统计或修改,这时我创建这另一个映射用的仍是mmap函数, 它仍需要用到fd这个文件标识,那我不等于又重新打开文件读取文件里的数据 1.既然这样那同对文件的直接操作有什么区别呢? 2.映射到内存后通过映射的指针addr来修改内容的话是修改共享内存里的内容还是文件的内容呢? 3.解决上面2个问题,我还是想确切知道共享内存有什么用??? 一种回答|: 1、访问共享内存的执行速度比直接访问文件的快N倍(N》10),这对于要求快速输入输出的场合非常有效。 2、通过addr修改的内容是修改的是共享内容中的内容。至于是否修改了文件中的内容,要看文件的类型。 对于显示设备等文件来说,修改的也是文件的内容,因为他直接写到了显存中。对于普通文件, 在close文件时,kernel会将数据更新到硬盘等存储设备中。 3、共享内存主要是为了提高程序的执行速度,方便多个进程进行快速的大数据量的交换。 第二种回答: 对于是修改文件内容的内存映射: 1、你的这个说法不确切。举个例子来说:对显示设备文件(显卡)进行内存的映射,并不会在内存中新分配一块内存, 而是直接将显存地址通过addr参数传给应用程序。这样应用程序通过内存映射修改文件时, 其实就是直接修改显存中的内容(也就是改变显示内容)。 2、感觉你把内存映射和共享内存搞混了。内存映射是用来加快对文件/设备的访问。 (如果是大文件,而且还想提高读写速度的话,建议使用内存映射。) 共享内存是用来在多个进程间进行快速的大数据量的交换。 3、fd是文件描述符。它和内存映射没有直接的关系。只有做过内存映射后,它和映射到的内存才存在对应关系。 对于不修改文件内容的内存映射 1、不一定,可以在程序中指定要将文件内容映射到哪块内存。对于多个进程打开同一个文件, 不同的内存映射可以开辟多块内存区域。更新文件内容的顺序依照关闭文件的进程的顺序执行,因此,存在脏读的问题。 2、:-),一定要记住,内存映射是为了加快对文件/设备的访问速度,不是用来进行数据通信的。 转载自:http://bbs.csdn.net/topics/340203684 我对内存映射的理解就是通过操作内存来实现对文件的操作,这样可以加快执行速度,因为操作内存比操作文件的速度快多了! 共享内存,顾名思义,就是预留出的内存区域,它允许一组进程对其访问。 共享内存是system vIPC中三种通信机制最快的一种,也是最简单的一种。对于进程来说, 获得共享内存后,他对内存的使用和其他的内存是一样的。由一个进程对共享内存所进行的 操作对其他进程来说都是立即可见的,因为每个进程只需要通过一个指向共享内存空间的指针就可以来读取 共享内存中的内容(说白了就好比申请了一块内存,每个需要的进程都有一个指针指向这个内存) 就可以轻松获得结果。使用共享内存要注意的问题:共享内存不能确保对内存操作的互斥性。 一个进程可以向共享内存中的给定地址写入,而同时另一个进程从相同的地址读出,这将会导致不一致的数据。 因此使用共享内存的进程必须自己保证读操作和写操作的的严格互斥。 可使用锁和原子操作解决这一问题。也可使用信号量保证互斥访问共享内存区域。 共享内存在一些情况下可以代替消息队列,而且共享内存的读/写比使用消息队列要快!
共享内存可以说是最有用的进程间通信方式,也是最快的IPC形式。两个不同进程A、B共享内存的意思是,同一块物理内存被映射到进程A、B各自的进程地址空间。进程A可以即时看到进程B对共享内存中数据的更新,反之亦然。由于多个进程共享同一块内存区域,必然需要某种同步机制,互斥锁和信号量都可以。
采用共享内存通信的一个显而易见的好处是效率高,因为进程可以直接读写内存,而不需要任何数据的拷贝。对于像管道和消息队列等通信方式,则需要在内核和用户空间进行四次的数据拷贝,而共享内存则只拷贝两次数据[1]:一次从输入文件到共享内存区,另一次从共享内存区到输出文件。实际上,进程之间在共享内存时,并不总是读写少量数据后就解除映射,有新的通信时,再重新建立共享内存区域。而是保持共享区域,直到通信完毕为止,这样,数据内容一直保存在共享内存中,并没有写回文件。共享内存中的内容往往是在解除映射时才写回文件的。因此,采用共享内存的通信方式效率是非常高的。
Linux的2.2.x内核支持多种共享内存方式,如mmap()系统调用,Posix共享内存,以及系统V共享内存。linux发行版本如Redhat 8.0支持mmap()系统调用及系统V共享内存,但还没实现Posix共享内存,本文将主要介绍mmap()系统调用及系统V共享内存API的原理及应用。
1、page cache及swap cache中页面的区分:一个被访问文件的物理页面都驻留在page cache或swap cache中,一个页面的所有信息由struct page来描述。struct page中有一个域为指针mapping ,它指向一个struct address_space类型结构。page cache或swap cache中的所有页面就是根据address_space结构以及一个偏移量来区分的。
2、文件与address_space结构的对应:一个具体的文件在打开后,内核会在内存中为之建立一个struct inode结构,其中的i_mapping域指向一个address_space结构。这样,一个文件就对应一个address_space结构,一个address_space与一个偏移量能够确定一个page cache 或swap cache中的一个页面。因此,当要寻址某个数据时,很容易根据给定的文件及数据在文件内的偏移量而找到相应的页面。
3、进程调用mmap()时,只是在进程空间内新增了一块相应大小的缓冲区,并设置了相应的访问标识,但并没有建立进程空间到物理页面的映射。因此,第一次访问该空间时,会引发一个缺页异常。
4、对于共享内存映射情况,缺页异常处理程序首先在swap cache中寻找目标页(符合address_space以及偏移量的物理页),如果找到,则直接返回地址;如果没有找到,则判断该页是否在交换区(swap area),如果在,则执行一个换入操作;如果上述两种情况都不满足,处理程序将分配新的物理页面,并把它插入到page cache中。进程最终将更新进程页表。
注:对于映射普通文件情况(非共享映射),缺页异常处理程序首先会在page
cache中根据address_space以及数据偏移量寻找相应的页面。如果没有找到,则说明文件数据还没有读入内存,处理程序会从磁盘读入相应的页面,并返回相应地址,同时,进程页表也会更新。
5、所有进程在映射同一个共享内存区域时,情况都一样,在建立线性地址与物理地址之间的映射之后,不论进程各自的返回地址如何,实际访问的必然是同一个共享内存区域对应的物理页面。
注:一个共享内存区域可以看作是特殊文件系统shm中的一个文件,shm的安装点在交换区上。
上面涉及到了一些数据结构,围绕数据结构理解问题会容易一些。
mmap()系统调用使得进程之间通过映射同一个普通文件实现共享内存。普通文件被映射到进程地址空间后,进程可以向访问普通内存一样对文件进行访问,不必再调用read(),write()等操作。
注:实际上,mmap()系统调用并不是完全为了用于共享内存而设计的。它本身提供了不同于一般对普通文件的访问方式,进程可以像读写内存一样对普通文件的操作。而Posix或系统V的共享内存IPC则纯粹用于共享目的,当然mmap()实现共享内存也是其主要应用之一。
1、mmap()系统调用形式如下:
void* mmap ( void * addr , size_t len , int prot , int flags ,
int fd , off_t offset )
参数fd为即将映射到进程空间的文件描述字,一般由open()返回,同时,fd可以指定为-1,此时须指定flags参数中的MAP_ANON,表明进行的是匿名映射(不涉及具体的文件名,避免了文件的创建及打开,很显然只能用于具有亲缘关系的进程间通信)。len是映射到调用进程地址空间的字节数,它从被映射文件开头offset个字节开始算起。prot
参数指定共享内存的访问权限。可取如下几个值的或:PROT_READ(可读) , PROT_WRITE (可写), PROT_EXEC
(可执行), PROT_NONE(不可访问)。flags由以下几个常值指定:MAP_SHARED , MAP_PRIVATE ,
MAP_FIXED,其中,MAP_SHARED ,
MAP_PRIVATE必选其一,而MAP_FIXED则不推荐使用。offset参数一般设为0,表示从文件头开始映射。参数addr指定文件应被映射到进程空间的起始地址,一般被指定一个空指针,此时选择起始地址的任务留给内核来完成。函数的返回值为最后文件映射到进程空间的地址,进程可直接操作起始地址为该值的有效地址。这里不再详细介绍mmap()的参数,读者可参考mmap()手册页获得进一步的信息。
2、系统调用mmap()用于共享内存的两种方式:
(1)使用普通文件提供的内存映射:适用于任何进程之间;此时,需要打开或创建一个文件,然后再调用mmap();典型调用代码如下:
fd=open(name, flag, mode); if(fd<0) ...
ptr=mmap(NULL, len , PROT_READ|PROT_WRITE, MAP_SHARED , fd , 0); 通过mmap()实现共享内存的通信方式有许多特点和要注意的地方,我们将在范例中进行具体说明。
(2)使用特殊文件提供匿名内存映射:适用于具有亲缘关系的进程之间;由于父子进程特殊的亲缘关系,在父进程中先调用mmap(),然后调用fork()。那么在调用fork()之后,子进程继承父进程匿名映射后的地址空间,同样也继承mmap()返回的地址,这样,父子进程就可以通过映射区域进行通信了。注意,这里不是一般的继承关系。一般来说,子进程单独维护从父进程继承下来的一些变量。而mmap()返回的地址,却由父子进程共同维护。
对于具有亲缘关系的进程实现共享内存最好的方式应该是采用匿名内存映射的方式。此时,不必指定具体的文件,只要设置相应的标志即可,参见范例2。
3、系统调用munmap()
int munmap( void * addr, size_t len )
该调用在进程地址空间中解除一个映射关系,addr是调用mmap()时返回的地址,len是映射区的大小。当映射关系解除后,对原来映射地址的访问将导致段错误发生。
4、系统调用msync()
int msync ( void * addr , size_t len, int flags)
一般说来,进程在映射空间的对共享内容的改变并不直接写回到磁盘文件中,往往在调用munmap()后才执行该操作。可以通过调用msync()实现磁盘上文件内容与共享内存区的内容一致
下面将给出使用mmap()的两个范例:范例1给出两个进程通过映射普通文件实现共享内存通信;范例2给出父子进程通过匿名映射实现共享内存。系统调用mmap()有许多有趣的地方,下面是通过mmap()映射普通文件实现进程间的通信的范例,我们通过该范例来说明mmap()实现共享内存的特点及注意事项。
范例1:两个进程通过映射普通文件实现共享内存通信
范例1包含两个子程序:map_normalfile1.c及map_normalfile2.c。编译两个程序,可执行文件分别为map_normalfile1及map_normalfile2。两个程序通过命令行参数指定同一个文件来实现共享内存方式的进程间通信。map_normalfile2试图打开命令行参数指定的一个普通文件,把该文件映射到进程的地址空间,并对映射后的地址空间进行写操作。map_normalfile1把命令行参数指定的文件映射到进程地址空间,然后对映射后的地址空间执行读操作。这样,两个进程通过命令行参数指定同一个文件来实现共享内存方式的进程间通信。
从程序的运行结果中可以得出的结论
1、 最终被映射文件的内容的长度不会超过文件本身的初始大小,即映射不能改变文件的大小;
2、 可以用于进程通信的有效地址空间大小大体上受限于被映射文件的大小,但不完全受限于文件大小。打开文件被截短为5个people结构大小,而在map_normalfile1中初始化了10个people数据结构,在恰当时候(map_normalfile1输出initialize over 之后,输出umap ok之前)调用map_normalfile2会发现map_normalfile2将输出全部10个people结构的值,后面将给出详细讨论。
注:在linux中,内存的保护是以页为基本单位的,即使被映射文件只有一个字节大小,内核也会为映射分配一个页面大小的内存。当被映射文件小于一个页面大小时,进程可以对从mmap()返回地址开始的一个页面大小进行访问,而不会出错;但是,如果对一个页面以外的地址空间进行访问,则导致错误发生,后面将进一步描述。因此,可用于进程间通信的有效地址空间大小不会超过文件大小及一个页面大小的和。
3、 文件一旦被映射后,调用mmap()的进程对返回地址的访问是对某一内存区域的访问,暂时脱离了磁盘上文件的影响。所有对mmap()返回地址空间的操作只在内存中有意义,只有在调用了munmap()后或者msync()时,才把内存中的相应内容写回磁盘文件,所写内容仍然不能超过文件的大小。
前面对范例运行结构的讨论中已经提到,linux采用的是页式管理机制。对于用mmap()映射普通文件来说,进程会在自己的地址空间新增一块空间,空间大小由mmap()的len参数指定,注意,进程并不一定能够对全部新增空间都能进行有效访问。进程能够访问的有效地址大小取决于文件被映射部分的大小。简单的说,能够容纳文件被映射部分大小的最少页面个数决定了进程从mmap()返回的地址开始,能够有效访问的地址空间大小。超过这个空间大小,内核会根据超过的严重程度返回发送不同的信号给进程。可用如下图示说明:
注意:文件被映射部分而不是整个文件决定了进程能够访问的空间大小,另外,如果指定文件的偏移部分,一定要注意为页面大小的整数倍。
9. socket是怎么回事,演绎从应用层到最底层的通信
在说socket之前。我们先了解下相关的网络知识;
端口
在Internet上有很多这样的主机,这些主机一般运行了多个服务软件,同时提供几种服务。每种服务都打开一个Socket,并绑定到一个端口上,不同的端口对应于不同的服务(应用程序)。
例如:http 使用80端口 ftp使用21端口 smtp使用 25端口
端口用来标识计算机里的某个程序 1)公认端口:从0到1023 2)注册端口:从1024到49151 3)动态或私有端口:从49152到65535
Socket相关概念
socket的英文原义是“孔”或“插座”。作为进程通信机制,取后一种意思。通常也称作“套接字”,用于描述IP地址和端口,是一个通信链的句柄。(其实就是两个程序通信用的。)
socket非常类似于电话插座。以一个电话网为例。电话的通话双方相当于相互通信的2个程序,电话号码就是IP地址。任何用户在通话之前,
首先要占有一部电话机,相当于申请一个socket;同时要知道对方的号码,相当于对方有一个固定的socket。然后向对方拨号呼叫,
相当于发出连接请求。对方假如在场并空闲,拿起电话话筒,双方就可以正式通话,相当于连接成功。双方通话的过程,
是一方向电话机发出信号和对方从电话机接收信号的过程,相当于向socket发送数据和从socket接收数据。通话结束后,一方挂起电话机相当于关闭socket,撤消连接。
Socket有两种类型
流式Socket(STREAM): 是一种面向连接的Socket,针对于面向连接的TCP服务应用,安全,但是效率低;
数据报式Socket(DATAGRAM): 是一种无连接的Socket,对应于无连接的UDP服务应用.不安全(丢失,顺序混乱,在接收端要分析重排及要求重发),但效率高.
TCP/IP协议
TCP/IP(Transmission Control Protocol/Internet Protocol)即传输控制协议/网间协议,是一个工业标准的协议集,它是为广域网(WANs)设计的。
UDP协议
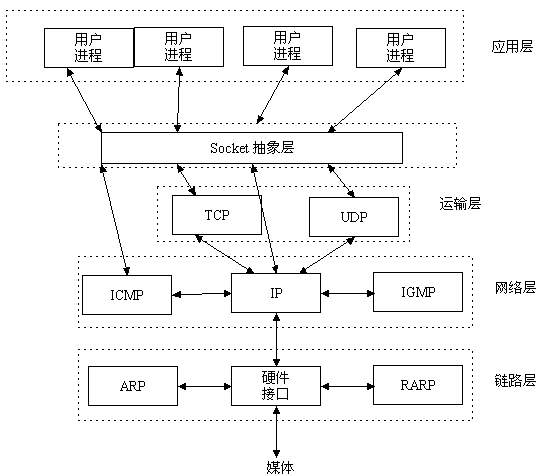
UDP(User Data Protocol,用户数据报协议)是与TCP相对应的协议。它是属于TCP/IP协议族中的一种。

应用层 (Application):应用层是个很广泛的概念,有一些基本相同的系统级 TCP/IP 应用以及应用协议,也有许多的企业商业应用和互联网应用。 解释:我们的应用程序
传输层 (Transport):传输层包括 UDP 和 TCP,UDP 几乎不对报文进行检查,而 TCP 提供传输保证。 解释;保证传输数据的正确性
网络层 (Network):网络层协议由一系列协议组成,包括 ICMP、IGMP、RIP、OSPF、IP(v4,v6) 等。 解释:保证找到目标对象,因为里面用的IP协议,ip包含一个ip地址
链路层 (Link):又称为物理数据网络接口层,负责报文传输。 解释:在物理层面上怎么去传递数据
你可以cmd打开命令窗口。输入
netstat -a
查看当前电脑监听的端口,和协议。有TCP和UDP


TCP/IP与UDP有什么区别呢?该怎么选择?
UDP可以用广播的方式。发送给每个连接的用户 而TCP是做不到的
TCP需要3次握手,每次都会发送数据包(但不是我们想要发送的数据),所以效率低 但数据是安全的。因为TCP会有一个校验和。就是在发送的时候。会把数据包和校验和一起 发送过去。当校验和和数据包不匹配则说明不安全(这个安全不是指数据会不会 别窃听,而是指数据的完整性)
UDP不需要3次握手。可以不发送校验和
web服务器用的是TCP协议
那什么时候用UDP协议。什么时候用TCP协议呢? 视频聊天用UDP。因为要保证速度?反之相反
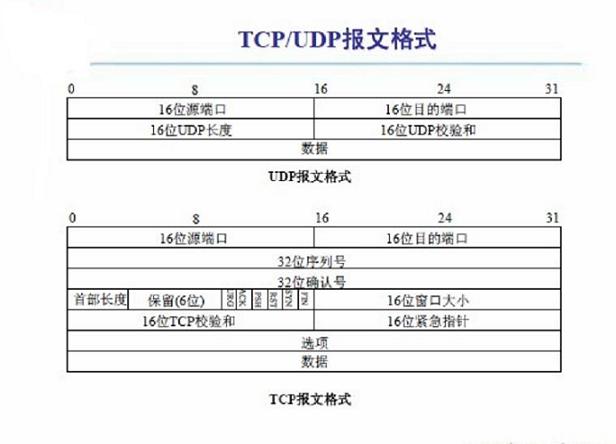
下图显示了数据报文的格式
Socket一般应用模式(服务器端和客户端)

服务端跟客户端发送信息的时候,是通过一个应用程序 应用层发送给传输层,传输层加头部 在发送给网络层。在加头 在发送给链路层。在加帧
然后在链路层转为信号,通过ip找到电脑 链路层接收。去掉头(因为发送的时候加头了。去头是为了找到里面的数据) 网络层接收,去头 传输层接收。去头 在到应用程序,解析协议。把数据显示出来
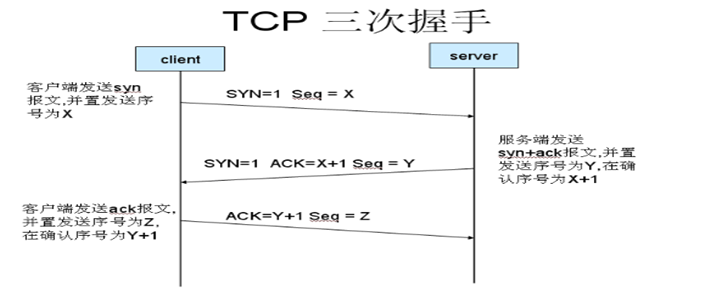
TCP3次握手
在TCP/IP协议中,TCP协议提供可靠的连接服务,采用三次握手建立一个连接。 第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认;SYN:同步序列编号(Synchronize SequenceNumbers)。 第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态; 第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
看一个Socket简单的通信图解

1.服务端welcoming socket 开始监听端口(负责监听客户端连接信息)
2.客户端client socket连接服务端指定端口(负责接收和发送服务端消息)
3.服务端welcoming socket 监听到客户端连接,创建connection socket。(负责和客户端通信)
服务器端的Socket(至少需要两个)
一个负责接收客户端连接请求(但不负责与客户端通信)
每成功接收到一个客户端的连接便在服务端产生一个对应的负责通信的Socket 在接收到客户端连接时创建. 为每个连接成功的客户端请求在服务端都创建一个对应的Socket(负责和客户端通信).
客户端的Socket
客户端Socket 必须指定要连接的服务端地址和端口。 通过创建一个Socket对象来初始化一个到服务器端的TCP连接。
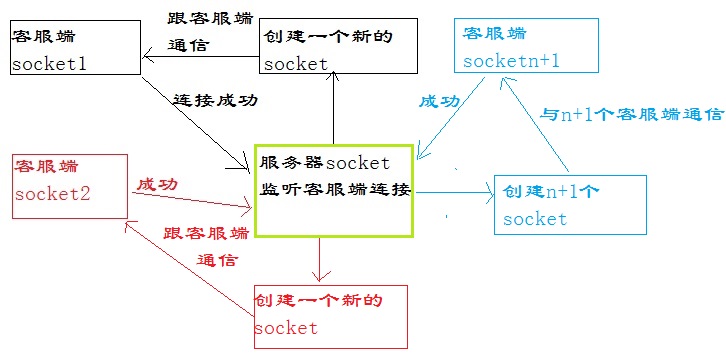
Socket的通讯过程
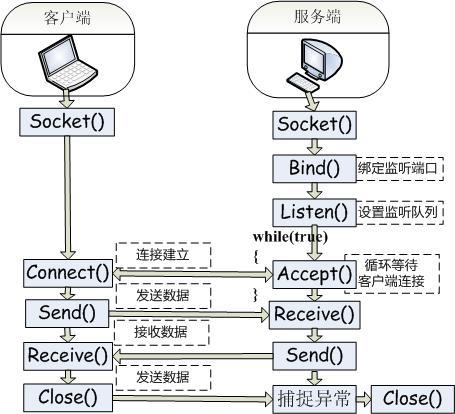
服务器端:
申请一个socket 绑定到一个IP地址和一个端口上 开启侦听,等待接授连接
客户端: 申请一个socket 连接服务器(指明IP地址和端口号)
服务器端接到连接请求后,产生一个新的socket(端口大于1024)与客户端建立连接并进行通讯,原监听socket继续监听。
socket是一个很抽象的概念。来看看socket的位置
好吧。我承认看一系列的概念是非常痛苦的,现在开始编码咯
看来编码前还需要看下sokcet常用的方法
Socket方法: 1)IPAddress类:包含了一个IP地址 例:IPAddress ip = IPAddress.Parse(txtServer.Text);//将IP地址字符串转换后赋给ip 2) IPEndPoint类:包含了一对IP地址和端口号 例:IPEndPoint point = new IPEndPoint(ip, int.Parse(txtPort.Text));//将指定的IP地址和端口初始化后赋给point 3)Socket (): 创建一个Socket 例:Socket socket = new Socket(AddressFamily.InterNetwork, SocketType.Stream, ProtocolType.Tcp);//创建监听用的socket 4) Bind(): 绑定一个本地的IP和端口号(IPEndPoint) 例:socket.Bind(point);//绑定ip和端口 5) Listen(): 让Socket侦听传入的连接尝试,并指定侦听队列容量 例: socket.Listen(10); 6) Connect(): 初始化与另一个Socket的连接 7) Accept(): 接收连接并返回一个新的socket 例:Socket connSocket =socket .Accept (); 8 )Send(): 输出数据到Socket 9) Receive(): 从Socket中读取数据 10) Close(): 关闭Socket (销毁连接)
首先创建服务端,服务端是用来监听客户端请求的。
创建服务器步骤: 第一步:创建一个Socket,负责监听客户端的请求,此时会监听一个端口 第二步:客户端创建一个Socket去连接服务器的ip地址和端口号 第三步:当连接成功后。会创建一个新的socket。来负责和客户端通信


1 public static void startServer()
2 {
3
4 //第一步:创建监听用的socket
5 Socket socket = new Socket
6 (
7 AddressFamily.InterNetwork, //使用ip4
8 SocketType.Stream,//流式Socket,基于TCP
9 ProtocolType.Tcp //tcp协议
10 );
11
12 //第二步:监听的ip地址和端口号
13 //ip地址
14 IPAddress ip = IPAddress.Parse(_ip);
15 //ip地址和端口号
16 IPEndPoint point = new IPEndPoint(ip, _point);
17
18 //绑定ip和端口
19 //端口号不能占用:否则:以一种访问权限不允许的方式做了一个访问套接字的尝试
20 //通常每个套接字地址(协议/网络地址/端口)只允许使用一次。
21 try
22 {
23 socket.Bind(point);
24 }
25 catch (Exception)
26 {
27
28 if (new IOException().InnerException is SocketException)
29 Console.WriteLine("端口被占用");
30 }
31 //socket.Bind(point);
32
33 //第三步:开始监听端口
34
35 //监听队列的长度
36 /*比如:同时有3个人来连接该服务器,因为socket同一个时间点。只能处理一个连接
37 * 所以其他的就要等待。当处理第一个。然后在处理第二个。以此类推
38 *
39 * 这里的10就是同一个时间点等待的队列长度为10,即。只能有10个人等待,当第11个的时候。是连接不上的
40 */
41 socket.Listen(10);
42
43 string msg = string.Format("服务器已经启动........\n监听ip为:{0}\n监听端口号为:{1}\n", _ip, _point);
44 showMsg(msg);
45
46 Thread listen = new Thread(Listen);
47 listen.IsBackground = true;
48 listen.Start(socket);
49
50 }
观察上面的代码。开启了一个多线程。去执行Listen方法,Listen是什么?为什么要开启一个多线程去执行?
回到上面的 "Socket的通讯过程"中提到的那个图片,因为有两个地方需要循环执行
第一个:需要循环监听来自客户端的请求
第二个:需要循环获取来自客服端的通信(这里假设是客户端跟服务器聊天)
额。这跟使用多线程有啥关系?当然有。因为Accept方法。会阻塞线程。所以用多线程,避免窗体假死。你说呢?
看看Listen方法
1 /// <summary>
2 /// 多线程执行
3 /// Accept方法。会阻塞线程。所以用多线程
4 /// </summary>
5 /// <param name="o"></param>
6 static void Listen(object o)
7 {
8 Socket socket = o as Socket;
9
10 //不停的接收来自客服端的连接
11 while (true)
12 {
13 //如果有客服端连接,则创建通信用是socket
14 //Accept方法。会阻塞线程。所以用多线程
15 //Accept方法会一直等待。直到有连接过来
16 Socket connSocket = socket.Accept();
17
18 //获取连接成功的客服端的ip地址和端口号
19 string msg = connSocket.RemoteEndPoint.ToString();
20 showMsg(msg + "连接");
21
22 //获取本机的ip地址和端口号
23 //connSocket.LocalEndPoint.ToString();
24
25 /*
26 如果不用多线程。则会一直执行ReceiveMsg
27 * 就不会接收客服端连接了
28 */
29 Thread th = new Thread(ReceiveMsg);
30 th.IsBackground = true;
31 th.Start(connSocket);
32
33 }
34 }
细心的你在Listen方法底部又看到了一个多线程。执行ReceiveMsg,对,没错。这就是上面说的。循环获取消息
ReceiveMsg方法定义:
1 /// <summary>
2 /// 接收数据
3 /// </summary>
4 /// <param name="o"></param>
5 static void ReceiveMsg(object o)
6 {
7 Socket connSocket = o as Socket;
8 while (true)
9 {
10
11 //接收数据
12 byte[] buffer = new byte[1024 * 1024];//1M
13 int num = 0;
14 try
15 {
16 //接收数据保存发送到buffer中
17 //num则为实际接收到的字节个数
18
19 //这里会遇到这个错误:远程主机强迫关闭了一个现有的连接。所以try一下
20 num = connSocket.Receive(buffer);
21 //当num=0.说明客服端已经断开
22 if (num == 0)
23 {
24 connSocket.Shutdown(SocketShutdown.Receive);
25 connSocket.Close();
26 break;
27 }
28 }
29 catch (Exception ex)
30 {
31 if (new IOException().InnerException is SocketException)
32 Console.WriteLine("网络中断");
33 else
34 Console.WriteLine(ex.Message);
35 break;
36 }
37
38 //把实际有效的字节转化成字符串
39 string str = Encoding.UTF8.GetString(buffer, 0, num);
40 showMsg(connSocket.RemoteEndPoint + "说:\n" + str);
41
42
43
44 }
45 }
提供服务器的完整代码如下:

1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Net.Sockets;
6 using System.Net;
7 using System.Threading;
8 using System.IO;
9 namespace CAServer
10 {
11 class Program
12 {
13
14 //当前主机ip
15 static string _ip = "192.168.1.2";
16 //端口号
17 static int _point = 8000;
18
19 static void Main(string[] args)
20 {
21 //Thread thread = new Thread(startServer);
22 //thread.Start();
23
24 startServer();
25
26 Console.ReadLine();
27
28 }
29
30 public static void startServer()
31 {
32
33 //第一步:创建监听用的socket
34 Socket socket = new Socket
35 (
36 AddressFamily.InterNetwork, //使用ip4
37 SocketType.Stream,//流式Socket,基于TCP
38 ProtocolType.Tcp //tcp协议
39 );
40
41 //第二步:监听的ip地址和端口号
42 //ip地址
43 IPAddress ip = IPAddress.Parse(_ip);
44 //ip地址和端口号
45 IPEndPoint point = new IPEndPoint(ip, _point);
46
47 //绑定ip和端口
48 //端口号不能占用:否则:以一种访问权限不允许的方式做了一个访问套接字的尝试
49 //通常每个套接字地址(协议/网络地址/端口)只允许使用一次。
50 try
51 {
52 socket.Bind(point);
53 }
54 catch (Exception)
55 {
56
57 if (new IOException().InnerException is SocketException)
58 Console.WriteLine("端口被占用");
59 }
60 //socket.Bind(point);
61
62 //第三步:开始监听端口
63
64 //监听队列的长度
65 /*比如:同时有3个人来连接该服务器,因为socket同一个时间点。只能处理一个连接
66 * 所以其他的就要等待。当处理第一个。然后在处理第二个。以此类推
67 *
68 * 这里的10就是同一个时间点等待的队列长度为10,即。只能有10个人等待,当第11个的时候。是连接不上的
69 */
70 socket.Listen(10);
71
72 string msg = string.Format("服务器已经启动........\n监听ip为:{0}\n监听端口号为:{1}\n", _ip, _point);
73 showMsg(msg);
74
75 Thread listen = new Thread(Listen);
76 listen.IsBackground = true;
77 listen.Start(socket);
78
79 }
80 /// <summary>
81 /// 多线程执行
82 /// Accept方法。会阻塞线程。所以用多线程
83 /// </summary>
84 /// <param name="o"></param>
85 static void Listen(object o)
86 {
87 Socket socket = o as Socket;
88
89 //不停的接收来自客服端的连接
90 while (true)
91 {
92 //如果有客服端连接,则创建通信用是socket
93 //Accept方法。会阻塞线程。所以用多线程
94 //Accept方法会一直等待。直到有连接过来
95 Socket connSocket = socket.Accept();
96
97 //获取连接成功的客服端的ip地址和端口号
98 string msg = connSocket.RemoteEndPoint.ToString();
99 showMsg(msg + "连接");
100
101 //获取本机的ip地址和端口号
102 //connSocket.LocalEndPoint.ToString();
103
104 /*
105 如果不用多线程。则会一直执行ReceiveMsg
106 * 就不会接收客服端连接了
107 */
108 Thread th = new Thread(ReceiveMsg);
109 th.IsBackground = true;
110 th.Start(connSocket);
111
112 }
113 }
114 /// <summary>
115 /// 接收数据
116 /// </summary>
117 /// <param name="o"></param>
118 static void ReceiveMsg(object o)
119 {
120 Socket connSocket = o as Socket;
121 while (true)
122 {
123
124 //接收数据
125 byte[] buffer = new byte[1024 * 1024];//1M
126 int num = 0;
127 try
128 {
129 //接收数据保存发送到buffer中
130 //num则为实际接收到的字节个数
131
132 //这里会遇到这个错误:远程主机强迫关闭了一个现有的连接。所以try一下
133 num = connSocket.Receive(buffer);
134 //当num=0.说明客服端已经断开
135 if (num == 0)
136 {
137 connSocket.Shutdown(SocketShutdown.Receive);
138 connSocket.Close();
139 break;
140 }
141 }
142 catch (Exception ex)
143 {
144 if (new IOException().InnerException is SocketException)
145 Console.WriteLine("网络中断");
146 else
147 Console.WriteLine(ex.Message);
148 break;
149 }
150
151 //把实际有效的字节转化成字符串
152 string str = Encoding.UTF8.GetString(buffer, 0, num);
153 showMsg(connSocket.RemoteEndPoint + "说:\n" + str);
154
155
156
157 }
158 }
159 /// <summary>
160 /// 显示消息
161 /// </summary>
162 static void showMsg(string msg)
163 {
164 Console.WriteLine(msg);
165 //Console.ReadKey();
166 }
167 }
168 }
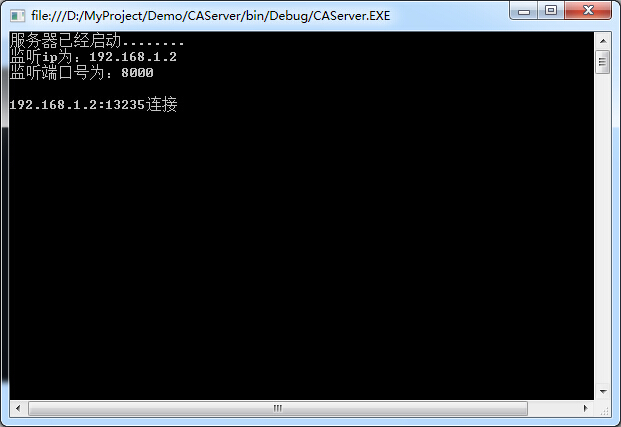
运行代码。显示如下
是不是迫不及待的想试试看效果。好吧其实我也跟你一样,cmd打开dos命令提示符,输入
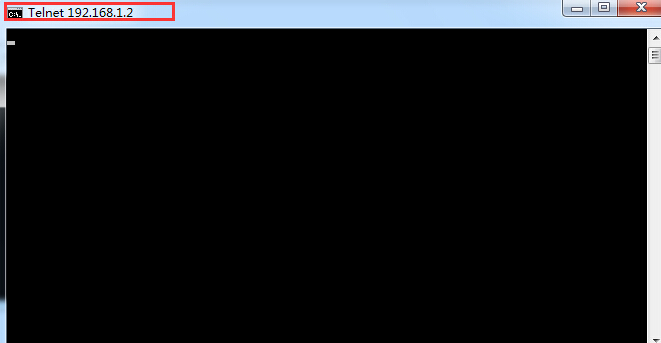
telnet 192.168.1.2 8000
回车,会看到窗体名称变了
然后看到服务器窗口
然后在客户端输入数字试试
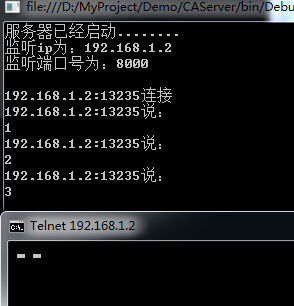
我输入了1 2 3 。当然,在cmd窗口是不显示的。这不影响测试。
小技巧:为了便于测试,可以创建一个xx.bat文件。里面写命令
telnet 192.168.1.2 8000
这样只有每次打开就会自动连接了。
当然。这仅仅是测试。现在写一个客户端,
创建一个winfrom程序,布局如下显示
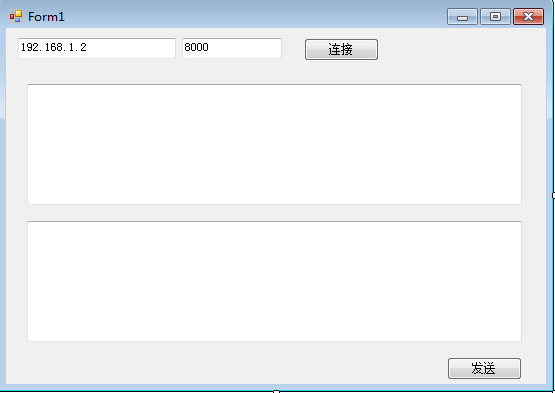
请求服务器代码就很容易了。直接附上代码
1 using System;
2 using System.Collections.Generic;
3 using System.ComponentModel;
4 using System.Data;
5 using System.Drawing;
6 using System.Linq;
7 using System.Text;
8 using System.Windows.Forms;
9 using System.Net;
10 using System.Net.Sockets;
11
12 namespace WFAClient
13 {
14 public partial class Form1 : Form
15 {
16 public Form1()
17 {
18 InitializeComponent();
19 }
20 Socket socket;
21 private void btnOk_Click(object sender, EventArgs e)
22 {
23 //客户端连接IP
24 IPAddress ip = IPAddress.Parse(tbIp.Text);
25
26 //端口号
27 IPEndPoint point = new IPEndPoint(ip, int.Parse(tbPoint.Text));
28
29 socket = new Socket(AddressFamily.InterNetwork, SocketType.Stream, ProtocolType.Tcp);
30
31 try
32 {
33 socket.Connect(point);
34 msg("连接成功");
35 btnOk.Enabled = false;
36 }
37 catch (Exception ex)
38 {
39 msg(ex.Message);
40 }
41 }
42 private void msg(string msg)
43 {
44 tbMsg.AppendText(msg);
45
46 }
47
48 private void btnSender_Click(object sender, EventArgs e)
49 {
50 //发送信息
51 if (socket != null)
52 {
53 byte[] buffer = Encoding.UTF8.GetBytes(tbContent.Text);
54 socket.Send(buffer);
55 /*
56 * 如果不释放资源。当关闭连接的时候
57 * 服务端接收消息会报如下异常:
58 * 远程主机强迫关闭了一个现有的连接。
59 */
60 //socket.Close();
61 //socket.Disconnect(true);
62 }
63 }
64 }
65 }
运行测试,这里需要同时运行客户端和服务器,
首先运行服务器,那怎么运行客户端呢。
右键客户端项目。调试--》启用新实例
好了。一个入门的过程就这样悄悄的完成了。
以上内容来自:http://www.cnblogs.com/nsky/p/4501782.html
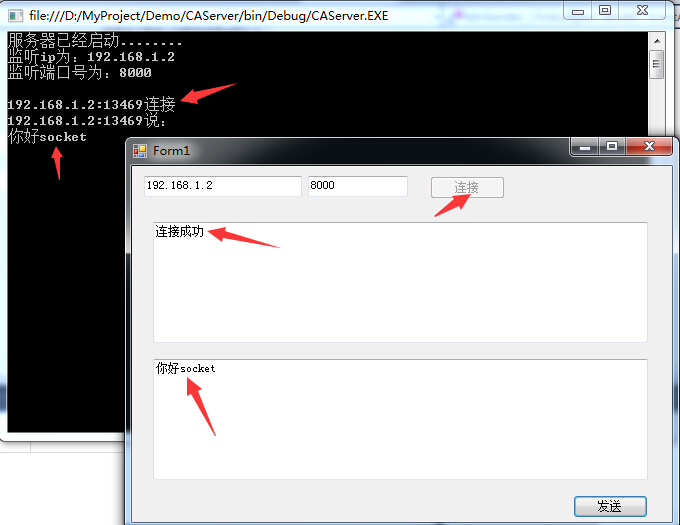
根据上面的内容,已经可以开发出一个可以正常通信的Socket示例了,
接下来首先要考虑的就是服务器性能问题
1)在服务器接收数据的时候,定义了一个1M的Byte Buffer,有些设计的更大。更大Buffer可以保证客户端发送数据量很大的情况全部能接受完全。但是作为一个服务器每收到一条客户端请求,都要申请一个1M的Buffer去装客户端发送的数据。如果客户端的并发量很大的情况,还没等到网络的瓶颈,服务器内存开销已经吃不消了。
对于这个问题的解决思路是:
定义一个小Buffer,每次接受客户端请求用:
byte[] bufferTemp = new byte[1024];
和一个大Buffer,装客户端的所有数据,其中用到了strReceiveLength,是客户端发送的总长度,稍后再解释:
byte[] buffer = new byte[Convert.ToInt32(strReceiveLength)];
改写while (true)循环,每次接受1K的数据,然后用Array.Copy方法,把bufferTemp中的数据复制给buffer:
num = connSocket.Receive(bufferTemp, SocketFlags.None);
ArrayUtil.ArrayCopy(bufferTemp, buffer, check, num);
check += num;
这个Array.Copy是重点,因为TCP数据流在传输过程中也是一个包一个包的传送,最大不超过8K。所以每次接受到的数据,也就是bufferTemp这个变量有可能装满,也有可能装不满。所以在拷贝的时候一定按照这次接受的长度顺序的放入buffer中。等到客户端全部数据发送完成后,再把buffer转换:
strReceive = Encoding.UTF8.GetString(buffer, 0, buffer.Length);
而不能够每次都转换,再strReceive += 一个Byte数组。这样做的后果就是中文会被截断,因为中文在UTF-8编码下占3-4个字节,很容易出现乱码。
2)数据长度校验
TCP在传输过程中难免会有数据发送不全或者丢失的情况。所以在客户端发送数据的时候一定带上校验长度:
byte[] btyLength = Encoding.UTF8.GetBytes(strContent);
string strLength = btyLength.Length.ToString().PadLeft(8, '0');
string sendData = strLength + strContent;
byte[] buffer = Encoding.UTF8.GetBytes(sendData);
socketClient.Send(buffer);
这样在服务器端,先把要接受的长度收到:
byte[] bufferLength = new byte[8];
num = connSocket.Receive(bufferLength);
strReceiveLength = Encoding.UTF8.GetString(bufferLength, 0, bufferLength.Length);
在循环里用下面的判断,来校验和判断是否已经接受完毕:
if (check == Convert.ToInt32(strReceiveLength))
3)设计上一些方式
很多局域网的部署是分层的,也就是分内网和外网。服务器部署一定要在外网上部署,这里的外网指的是在客户端之上的网段上。
比如192.168.1.22下有个无线路由,无线连接的IP段为192.168.2.1~254
服务器搭建在192.168.1网段下,192.168.2的客户端是可以访问的。但是相反则不行,192.168.1网段下的设备无法主动找到192.168.2的服务器。
10. 数据报从源主机到达目标主机的过程

主机A需要发送一个数据包到主机B,在整个传输流程中,源和目的IP地址是保持不变的(不考虑NAT),源和目的MAC地址是随着具体链路的变化而变化。
这里只考虑三种基本情形:A和B通过网线直连,A和B通过路由器连接,A和B通过交换机连接。真实网络中A和B的连接关系可能很复杂,但无非就是这三种基本情形的组合。
传输流程
-
主机A在本机的路由表中查询匹配主机B的IP的网络号;
-
如果能够查询到,说明主机B和主机A在同一网段(通常是在同一局域网内),则下一跳即为主机B。主机A在ARP缓存中查找主机B的MAC地址(如没有则先发送ARP广播),然后将数据包封装成帧发送至通信线路上。该帧的源MAC是主机A的MAC地址,目的MAC是主机B的MAC地址。
-
如果主机A和主机B是网线直连的,那么主机B直接收到主机A发来的帧。
-
如果主机A和B是通过交换机相连的,交换机的某个端口收到主机A发来的帧,然后根据帧中的目的MAC地址在MAC地址表中查询对应的转发端口。如果找到了,直接从该端口转发出去;如果没找到,则在除了接收到数据包以外的所有端口进行转发(广播)。
-
如果主机A和B是通过路由器相连的,路由器的某个端口收到主机A发来的帧,其后的处理流程见步骤4。
-
-
如果不能查询到,说明主机A和主机B不处于同一网络中,需要通过网关来进行跨网络的通信。主机A会通过默认网关(通常是路由器)来提交报文,即下一跳是路由器。主机A根据网关的IP在自己的ARP缓存中查找对应的MAC地址(如没有则先发送ARP广播),然后将数据包封装成帧发送至通信线路上。该帧的源MAC是主机A的MAC,目的MAC是路由器的MAC。
-
当网关路由器接收到数据帧时,首先提取包头中的目的MAC地址,在MAC表进行查询。如果找到对应项,则按对应的端口进行转发(这一步实现了与交换机一样的功能);如果没找到对应项,则提取数据包包头中的目的IP。
-
如果目的IP是自己(这是可能的,比如ping路由器),则交由上层处理。
-
如果目的IP不是自己,则需要进行转发,在路由表中查询目的IP的转发端口和下一跳IP。若找到了对应的路由表项,则按照路由表项转发;若没找到对应的路由表项,则按照缺省路由进行转发。转发时,源和目的IP地址不变,源MAC地址改为转发端口的MAC地址,目的MAC地址改为下一跳IP的MAC地址。
-
Attention
如果主机A和主机B位于同一网络,并通过路由器相连,主机A发送数据包至主机B,目的MAC地址是主机B。路由器接收到主机A发送的包,取目的MAC地址在自身MAC表中查询,通常情况下是能查到的。但如果查不到,路由器不会进行广播(在每个端口都转发),因为它不知道这个MAC地址是本网段的还是外网的。路由器会进一步查询目的IP,确定转发端口,修改源和目的MAC地址,然后转发出去。所以说,路由器是包含交换机功能的,并且也首先进行交换机应做的工作(但不会进行广播),这使得内网之间的数据传输更快。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架